Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201906_Predicting Annotation Difficulty to...
Search
T.Tada
June 05, 2019
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
T.Tada
June 05, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
サイバーエージェントにおけるAI推進戦略と変革への取り組み
shotatsuge
0
610
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
130
5分でわかるDuckDB Quack
chanyou0311
4
260
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
2
1.1k
Fabricをフル活用する AI Agent Hub -製造業特化AIエージェントの設計
iotcomjpadmin
0
150
AIエージェントとPhysical AIが拓く製造業の変革(ハノーバーメッセリキャップ)
iotcomjpadmin
0
160
自作お家AIエージェントスタックチャンFWで困っている所紹介
74th
0
130
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
0
100
組織における AI-DLC 実践
askul
0
150
コミットの「なぜ」を読む
ota1022
0
120
從開發到部署全都交給 AI:實作 AI 驅動的自動化流程
appleboy
0
180
Hatena Engineer Seminar 37 jj1uzh
jj1uzh
0
150
Featured
See All Featured
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
340
Code Review Best Practice
trishagee
74
20k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
170
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
200
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
220
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
570
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
290
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Transcript
- 文献紹介 2019 Jun 5 - Predicting Annotation Difficulty to
Improve Task Routing and Model Performance for Biomedical Information Extraction 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference: NAACL 2019
Abstract ・最近のNLPシステムには、高品質の注釈付きデータが必要 ・専門分野によっては注釈はコストが高い ・アノテーション作業の難易度を直接モデル化することでパフォーマンスを向上 ・インスタンスを適切な注釈者に割り当て可能なことを実証 ・専門家とクラウドワーカーの注釈による影響について 3
Introduction 4 ・専門家による注釈は高価になりがち ・クラウドワーカーの注釈は専門的なコンテンツによってはノイズとなる ・医学文献のクラウドワーカーアノテーションを含むコーパスでの実験を報告 (EBM-NLPコーパス) ・データへのアノテーションの難易度に注目する
Application Domain 5 ・医療記事のアブストラクトへの注釈について ・この分野の実験はEBM-NLPのリリースで容易に(Nye et al., 2018) Population(p), Interventions
(i), and Outcome (o)の要素を記述した クラウドワーカーの注釈付きの4,741医療記事アブストラクト 医療専門家によってラベルが付けられたテストセット 医療記事アブストラクトが191 3人の医療専門家からの注釈
Application Domain 6
Application Domain 7
Quantifying Task Difficulty 8 ・テストセットには、クラウドワーカーとド専門家の注釈が含まれる 専門家の注釈をground truthとして扱う 専門家とクラウドワーカー間での一致により文の困難さを定義 アノテーションタスク :
t インスタンス : i ワーカー : j ground truth 注釈 : yi ワーカーの数 : n スコアリング関数 f : スピアマンの相関係数
Quantifying Task Difficulty 9 ・トレーニングセットはクラウドワーカーによる注釈のみを使用 ・LSTM-CRF-Pattern sequence tagge(Patel et al.,
2018) でラベルを予測 データを分割しvalidationデータに用いる ・予測結果と専門家注釈を利用して難易度スコアを算出 ピアソンの相関係: Populationで0.57、Interventionsで0.71, Outcomeで0.68 Interventions and Outcomesへの注釈付けが Populationへの注釈付けよりも困難である
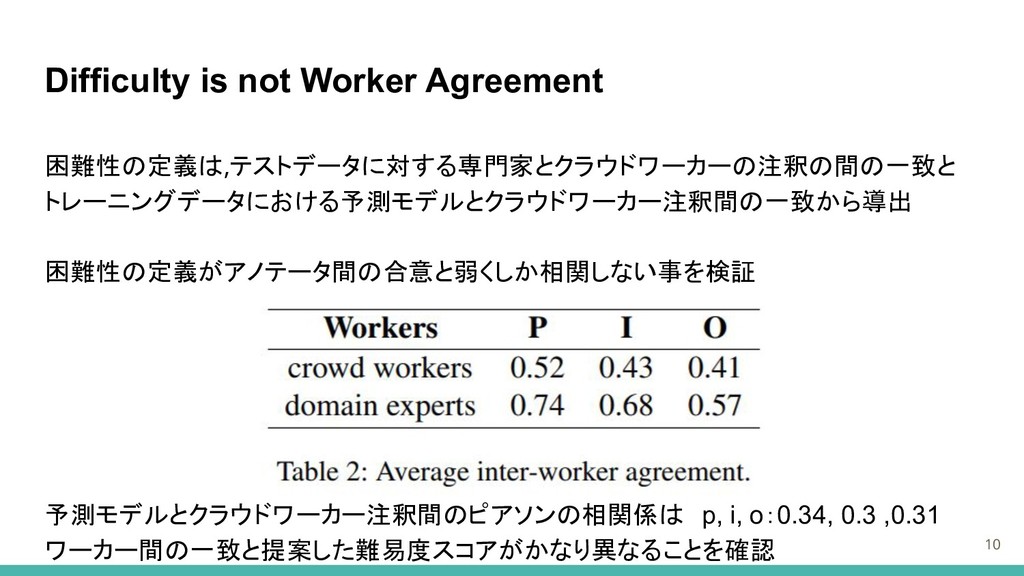
Difficulty is not Worker Agreement 10 困難性の定義は,テストデータに対する専門家とクラウドワーカーの注釈の間の一致と トレーニングデータにおける予測モデルとクラウドワーカー注釈間の一致から導出 困難性の定義がアノテータ間の合意と弱くしか相関しない事を検証 予測モデルとクラウドワーカー注釈間のピアソンの相関係は p,
i, o:0.34, 0.3 ,0.31 ワーカー間の一致と提案した難易度スコアがかなり異なることを確認
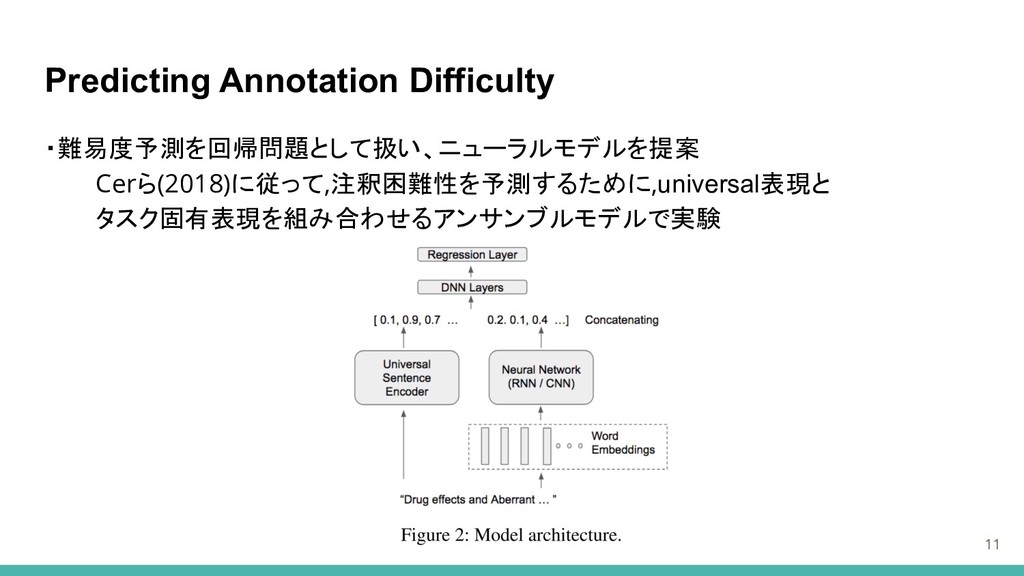
Predicting Annotation Difficulty 11 ・難易度予測を回帰問題として扱い、ニューラルモデルを提案 Cerら(2018)に従って,注釈困難性を予測するために,universal表現と タスク固有表現を組み合わせるアンサンブルモデルで実験
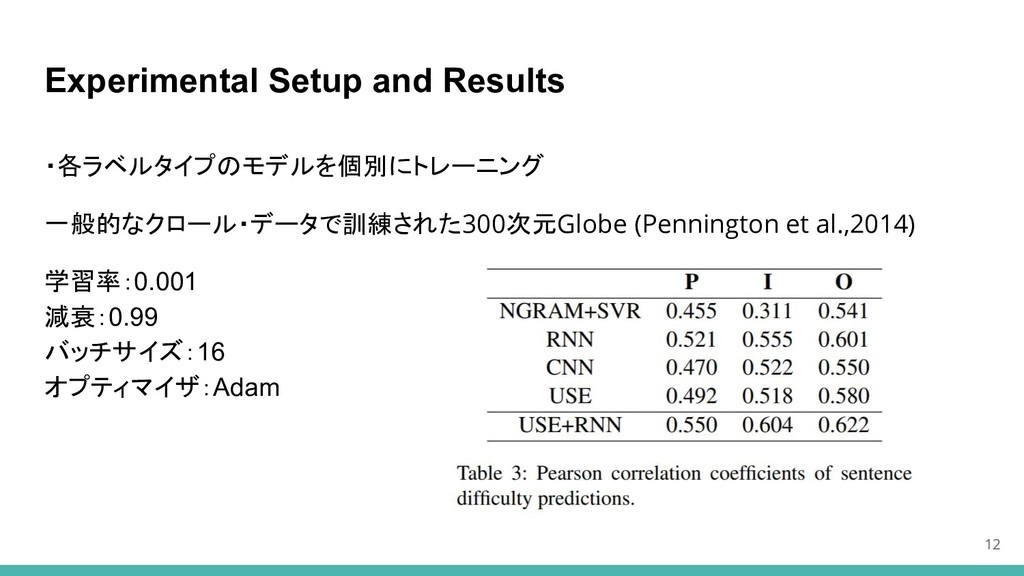
Experimental Setup and Results 12 ・各ラベルタイプのモデルを個別にトレーニング 一般的なクロール・データで訓練された300次元Globe (Pennington et al.,2014)
学習率:0.001 減衰:0.99 バッチサイズ:16 オプティマイザ:Adam
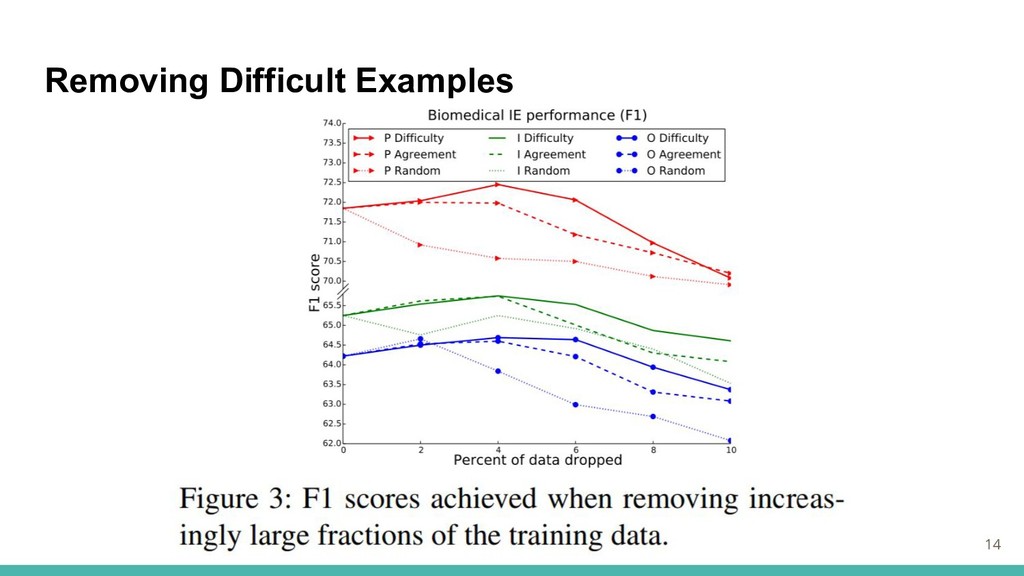
Better IE with Difficulty Prediction 13 ・難易度のさらなる使用を試みる実験 1.困難な文を除去した訓練セット 2.全ての訓練セットを難易度スコアに比例して再加重した場合 で訓練
Removing Difficult Examples 14
Re-weighting by Difficulty 15 訓練中の文を,それらの予測された難易度で再重み付け 再重み付けは、困難な文をダウンサンプリングすることに等しくなる
Involving Expert Annotators 16 困難な事例に関する専門家による注釈が抽出モデルに与える影響を確認 難しいインスタンスを専門家に,より簡単なインスタンスをクラウドワーカーに ルーティングする注釈戦略をシミュレート
Expert annotations of Random and Difficult Instances 17 ・最も困難なインスタンスのサブセットとのランダムなインスタンスを専門家が再注釈 ・五人の医療専門家を採用
・各要約には、1人の専門家によってのみ注釈が付けられる。 ・再注釈したデータ 最も難しいインスタンス:1000件 ランダムなインスタンス:1000件
Expert annotations of Random and Difficult Instances 18
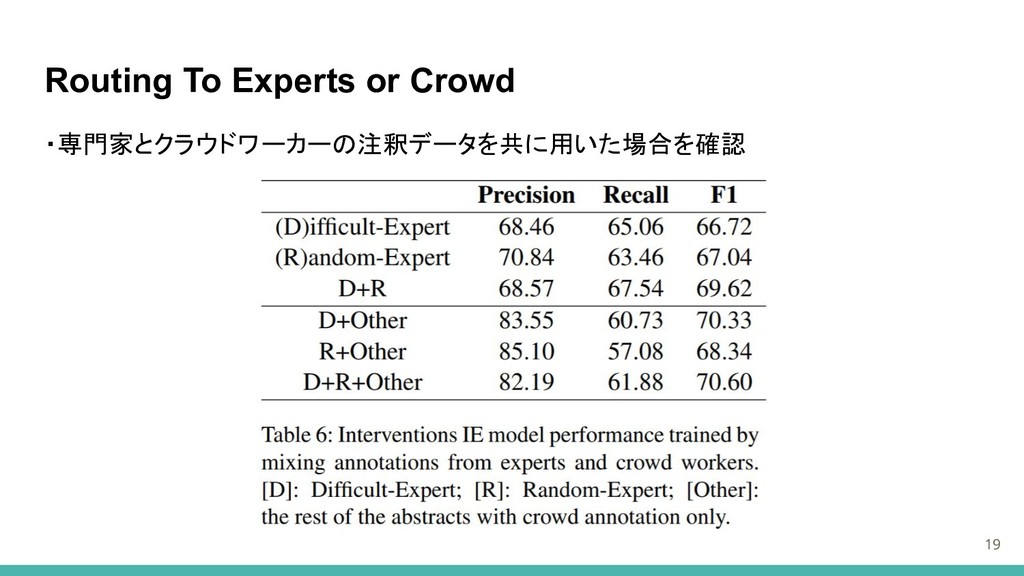
Routing To Experts or Crowd 19 ・専門家とクラウドワーカーの注釈データを共に用いた場合を確認
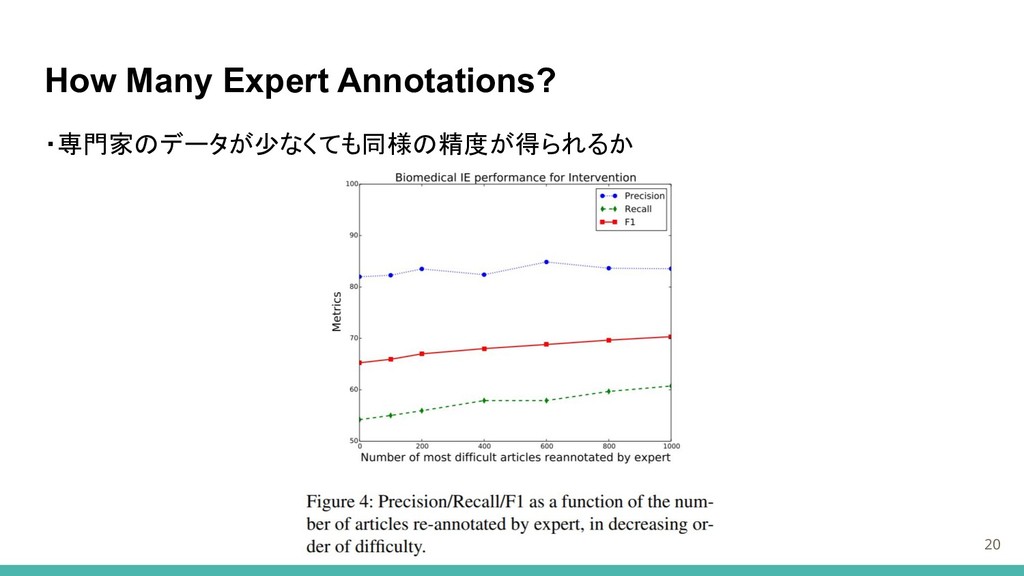
How Many Expert Annotations? 20 ・専門家のデータが少なくても同様の精度が得られるか
Conclusions 21 ・生物医学情報抽出のための注釈難易度を予測するタスクを導入、難易度をスコア化 ・モデルからの結果は,ほとんどすべての評価でPearsonの相関係数がより高く,この作 業の実行可能性を示した ・実験では,最も難易度が高いと予測された文の~10%を除去してもモデル性能は低下 せず,訓練中の難易度スコアによる再重み付けは予測性能を改善することを示した ・難易度により注釈者を選択するシミュレートでは、良いの結果を得ることが出来、デー タをランダムに選択する手法の精度を超え、クラウドワーカーのアノテータに依存するア プローチを大幅に改善できる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}