Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_201909_Sentence Mover’s Similarity_ Automa...
Search
T.Tada
September 24, 2019
Technology
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
T.Tada
September 24, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
76
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
文献紹介201905_Context-Aware Cross-Lingual Mapping
tad
0
110
Other Decks in Technology
See All in Technology
Claude Codeとハーネスについて考えてみる
oikon48
18
8.9k
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
Zoom2Youtube.Claude
kawaguti
PRO
3
470
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.9k
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
620
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
280
NDIAS CTF 2026 問題解説会資料
bata_24
0
180
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.3k
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
110
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
0
150
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
120
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
210
Featured
See All Featured
KATA
mclloyd
PRO
35
15k
Marketing to machines
jonoalderson
1
5.6k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
A Soul's Torment
seathinner
6
3k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Site-Speed That Sticks
csswizardry
13
1.2k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
290
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Automating Front-end Workflow
addyosmani
1370
210k
We Are The Robots
honzajavorek
0
270
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Transcript
- 文献紹介 2019 Sep 24 - Sentence Mover’s Similarity: Automatic
Evaluation for Multi-Sentence Texts 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference:
Abstract ・複数文のテキスト間の類似性を自動評価したい ・BLEUやROUGEなどの一般的に用いられる自動評価 →単語のマッチングを用い柔軟性がない →単語と文の埋め込みを利用する自動評価手法を提案 ・人手との相関において、ベースラインの手法よりも優れていることを確認 ・要約タスクの生成モデルの報酬として使用しベースラインを超えた 3
Introduction ・複数文のテキスト間における人手評価を削減したい ・既存のテキスト間の自動評価手法には課題がある 既存の手法(ROUGE等)は単語一致に基づく手法が一般的で柔軟性にかける →人手との相関が弱い Word Mover’s Distance(WMD)はこの点で優れる →しかし、長い文の評価が難しい ・文埋め込みを用いWMDを改良、複数文のテキスト間での類似性の評価に対応
4
Sentence Mover’s Similarity Metrics ・文埋め込みを使用してWMD ( WMD into a similarity:WMS
)を改良 ・2つのドキュメント間の類似度評価手法を提案 1. Sentence Mover’s Similarity (SMS) WMSの単語の埋め込みを文の埋め込みに置き換えて使用 2. Sentence and Word Mover’s Similarity (S + WMS) 単語埋め込みと文埋め込みの両方を使用 5
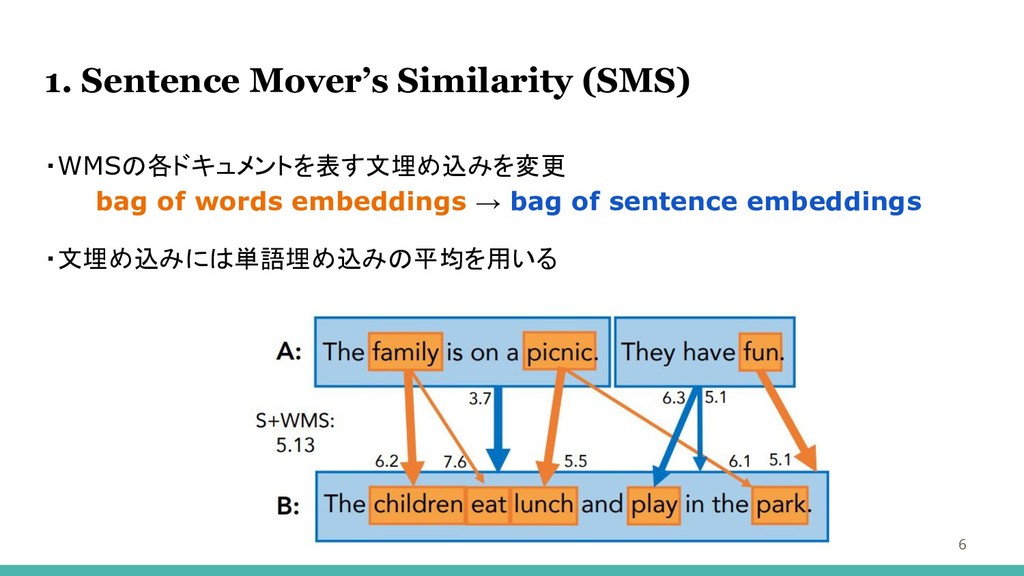
1. Sentence Mover’s Similarity (SMS) ・WMSの各ドキュメントを表す文埋め込みを変更 bag of words embeddings
→ bag of sentence embeddings ・文埋め込みには単語埋め込みの平均を用いる 6
2. Sentence and Word Mover’s Similarity (S + WMS) ・WMSとSMSを組み合わせ、各ドキュメントの単語と文の情報を使い距離を累積
bag of words embeddingsとbag of sentence embeddingsを併用 ・文の埋め込みは単語の埋め込みと同様に扱う 7
Intrinsic Evaluation ・ドキュメント間の評価手法としての有用性を確認(自動生成文と人手と両方で) Summaries Dataset (CNN/Daily Mail news datasetから自動生成) Essays
Dataset (学生のエッセイ) ・単語埋め込み手法:学習データ GloVe: Common Crawl ELMo: 1B Word Benchmark ・評価: 人手とのスピアマン相関 Williams (1959)で優位性を評価 8
Intrinsic Evaluation -Summaries Dataset Evaluation- ・データ・セット 自動生成された要約文の人手評価 ( -1〜1 )
2名以上でアノテート、スコアの平均を使用 ・提案手法で人手要約と自動生成要約の類似度を算出 人手評価と相関をみる ・SMSは人間の判断と最もよく相関 ・GloVeとELMoのスコアの差はそれほど大きくない 9
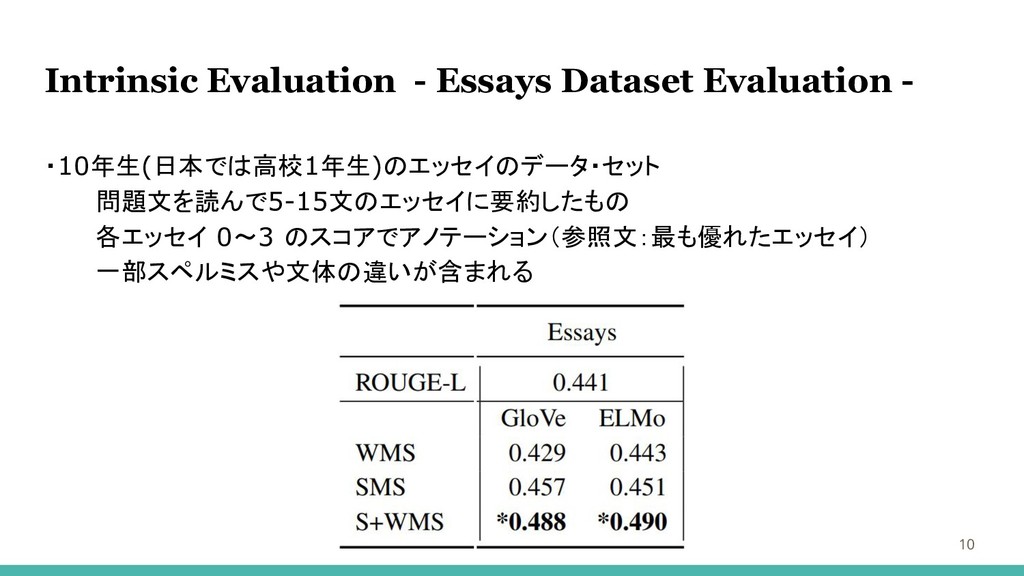
Intrinsic Evaluation - Essays Dataset Evaluation - ・10年生(日本では高校1年生)のエッセイのデータ・セット 問題文を読んで5-15文のエッセイに要約したもの 各エッセイ
0〜3 のスコアでアノテーション(参照文:最も優れたエッセイ) 一部スペルミスや文体の違いが含まれる 10
Extrinsic Evaluation テキスト生成モデルを学習する際の報酬として使用し評価 ・学習データ: CNN / Daily Mailデータセット ・モデル: エンコーダーデコーダーモデル、強化学習を使用
エンコーダ:2層 bidirectiona LSTM、デコーダ:2層 LSTM policy gradient 強化学習、評価手法を最大化するように学習等(詳細は論文参照) 11
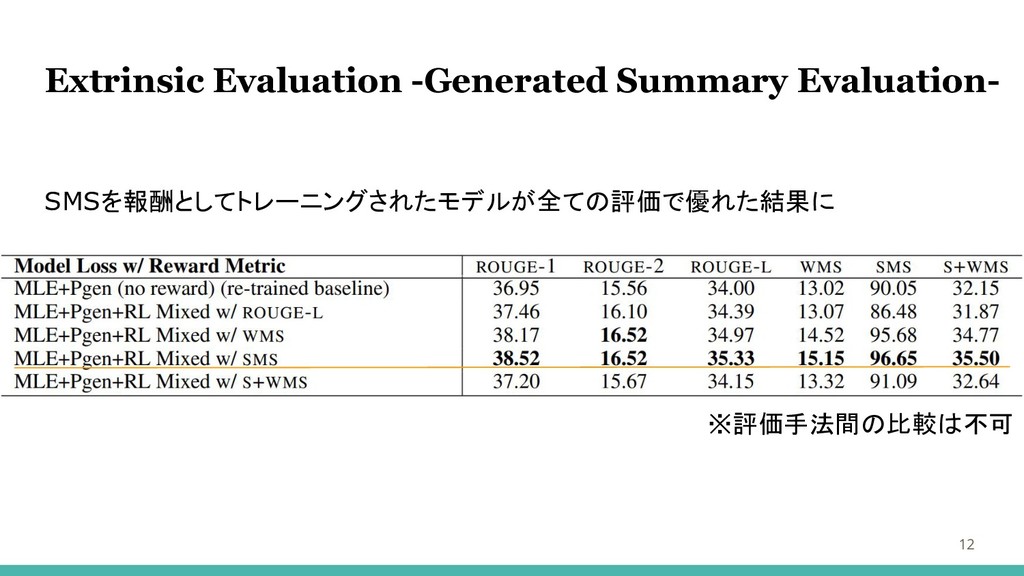
Extrinsic Evaluation -Generated Summary Evaluation- SMSを報酬としてトレーニングされたモデルが全ての評価で優れた結果に 12 ※評価手法間の比較は不可
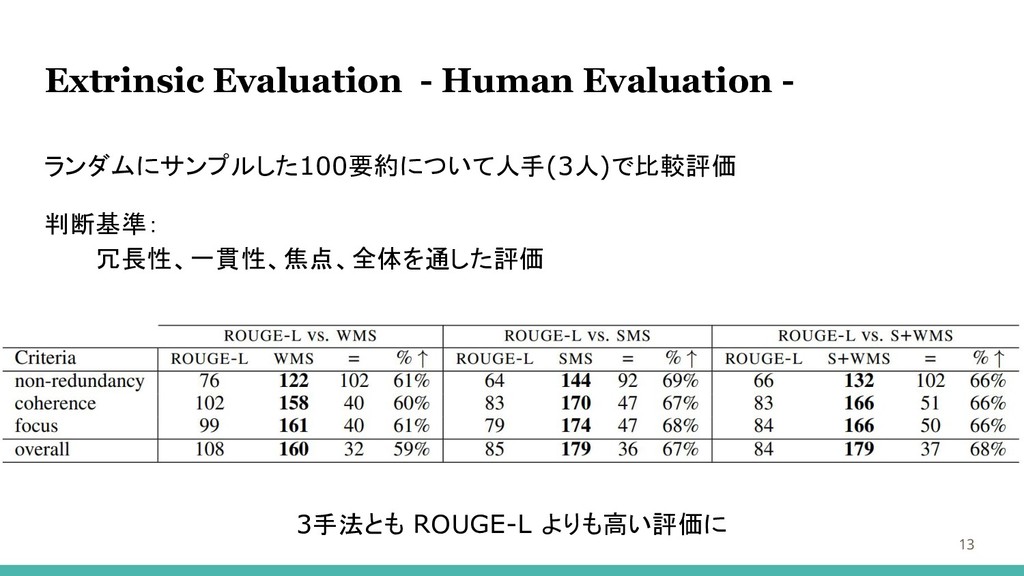
Extrinsic Evaluation - Human Evaluation - ランダムにサンプルした100要約について人手(3人)で比較評価 判断基準: 冗長性、一貫性、焦点、全体を通した評価 3手法とも
ROUGE-L よりも高い評価に 13
Conclusion ・複数文からなるドキュメントに対応した類似度の自動評価手法を提案 ・既存の手法と比較し人手との相関が向上 ・自動生成の報酬として用いた際にもベースラインを上回った ・コード(既存のWMD実装の拡張)とデータセットは公開 14
Example of output (Summaries Dataset Evaluation) 15
Example of output (generated summary) 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}