research topics ◼Anomalous sound detection ◼(Unsupervised) speech enhancement Our ASD team ◼Prof. Tomoki Toda ◼Mr. Ibuki Kuroyanagi (2nd year Ph.D. student) ◼Me Co-researcher ◼Assoc. Prof. Keisuke Imoto Me Prof. Toda Mr. Kuroyanagi
I’ll be talking mainly about my recent work, which has focused on practical challenges. T. Fujimura, K. Imoto, T. Toda, "Discriminative neighborhood smoothing for generative anomalous sound detection," Proc. EUSIPCO, Aug. 2024. [arxiv: https://arxiv.org/abs/2403.11508] T. Fujimura, I. Kuroyanagi, T. Toda, "Improvements of Discriminative Feature Space Training for Anomalous Sound Detection in Unlabeled Conditions,” arXiv e-prints: 2409.09332, 2024. [arxiv: https://arxiv.org/abs/2409.09332]
approaches: Generative and Discriminative Practical challenge 1: Instability ◼“Discriminative neighborhood smoothing for generative anomalous sound detection” Practical challenge 2: Data collection (annotation) costs ◼“Improvements of Discriminative Feature Space Training for Anomalous Sound Detection in Unlabeled Conditions” Summary
sound ◼Calculate an anomaly score from machine sound ◼Detect anomalies based on the anomaly score Problem setting ◼Difficult to collect anomalous sound samples → Develop ASD systems using only normal sound data Basic approaches ◼Generative and Discriminative Normal or Anomalous Anomaly score ASD system Thresh- olding
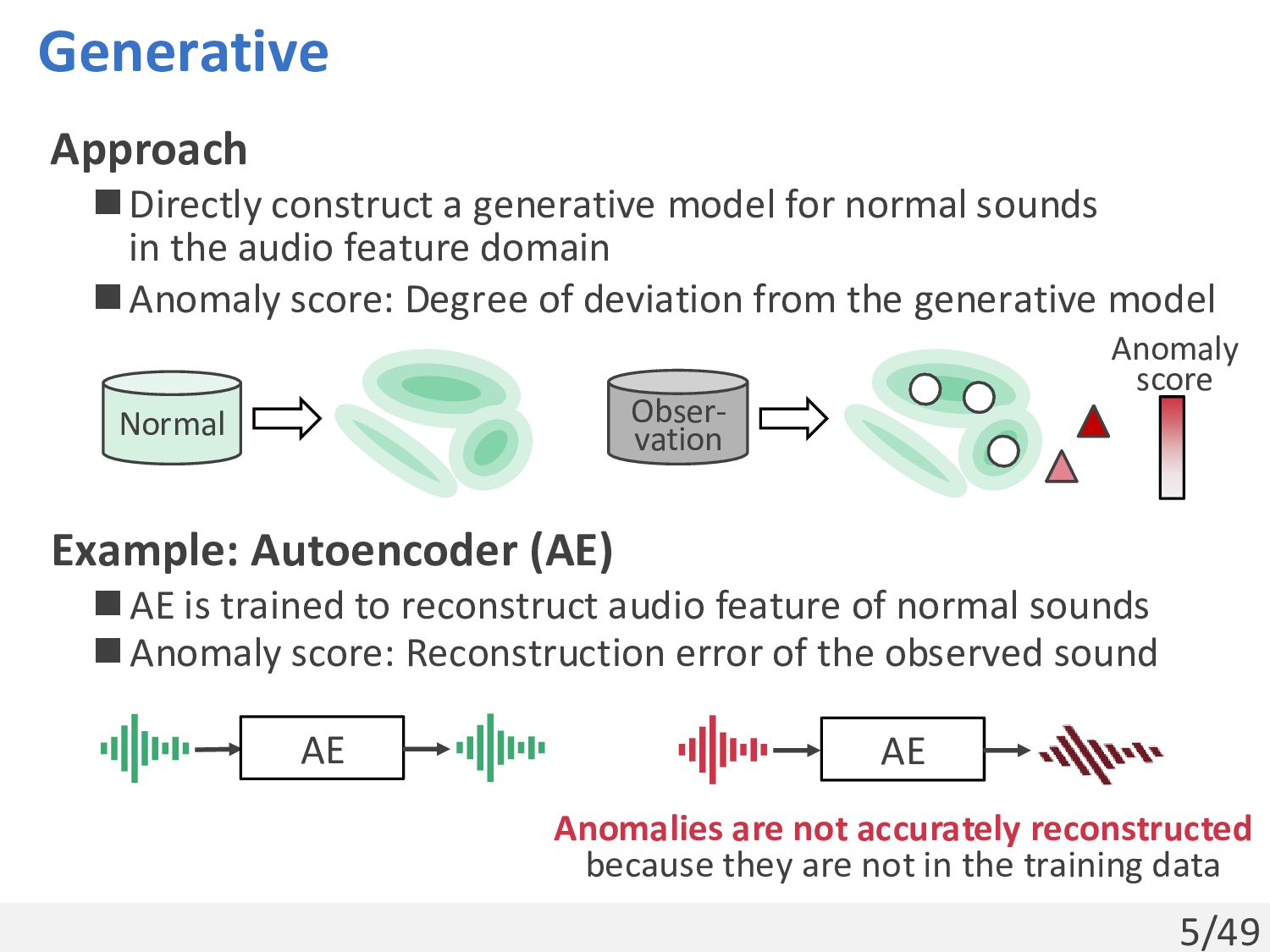
sounds in the audio feature domain ◼Anomaly score: Degree of deviation from the generative model Normal Obser- vation Anomaly score AE Anomalies are not accurately reconstructed because they are not in the training data AE Example: Autoencoder (AE) ◼AE is trained to reconstruct audio feature of normal sounds ◼Anomaly score: Reconstruction error of the observed sound
in normal sounds using annotated labels ◼Anomaly score: Distance between observation and training data in the discriminative feature space (i.e., decrease in the posterior probability of the correct class) Normal Labels (e.g., machine types and operation parms.) Feature Extractor Valve (pat 02) Valve (pat 01) Slide rail (vel 300, ac 0.30)
in normal sounds using annotated labels ◼Anomaly score: Distance between observation and training data in the discriminative feature space (i.e., decrease in the posterior probability of the correct class) Normal Labels (e.g., machine types and operation parms.) Feature Extractor Valve (pat 02) Valve (pat 01) Slide rail (vel 300, ac 0.30) Labels (e.g., machine types and operation parms.) … … Labels provided in DCASE Challenge Task2
in normal sounds using annotated labels ◼Anomaly score: Distance between observation and training data in the discriminative feature space (i.e., decrease in the posterior probability of the correct class) Normal Labels (e.g., machine types and operation parms.) Feature Extractor Valve (pat 02) Valve (pat 01) Slide rail (vel 300, ac 0.30)
in normal sounds using annotated labels ◼Anomaly score: Distance between observation and training data in the discriminative feature space (i.e., decrease in the posterior probability of the correct class) Anomalies are not accurately classified because they are not in the training data Obser- vation Valve (pat 02) Valve (pat 01) Slide rail (vel 300, ac 0.30) Feature Extractor
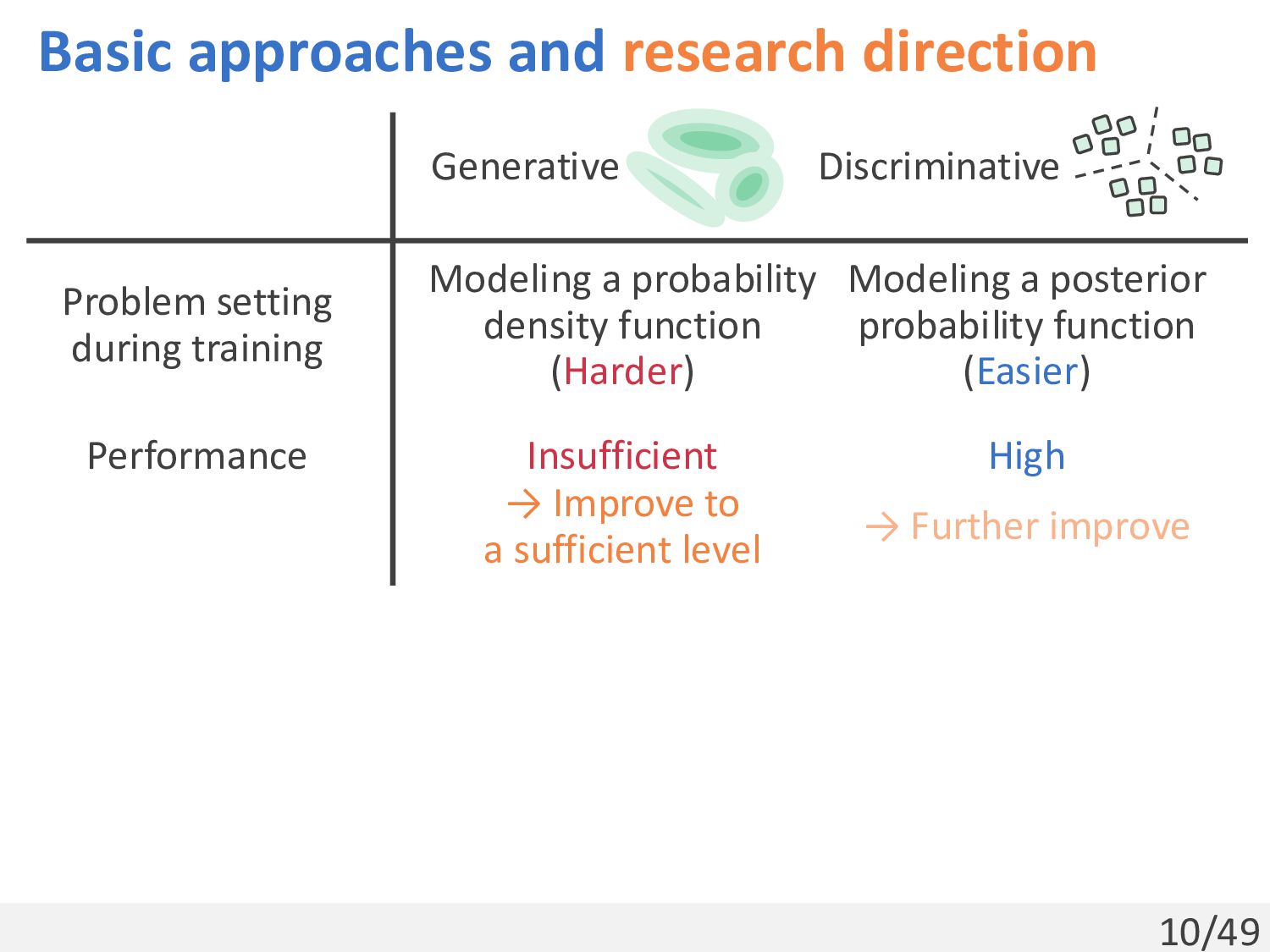
Modeling a probability density function (Harder) Modeling a posterior probability function (Easier) Performance Insufficient High Generative Discriminative → Improve to a sufficient level → Further improve
Modeling a probability density function (Harder) Modeling a posterior probability function (Easier) Performance Insufficient High Generative Discriminative → Improve to a sufficient level → Further improve Stability Relatively stable Unstable Useful but the annotation is costly Use of labels → Reduce the annotation cost → Improve stability → Further improve
approaches: Generative and Discriminative Practical challenge 1: Instability ◼“Discriminative neighborhood smoothing for generative anomalous sound detection” Practical challenge 2: Data collection (annotation) costs ◼“Improvements of Discriminative Feature Space Training for Anomalous Sound Detection in Unlabeled Conditions” Summary
Dis. approaches Machine A B C D Basic performance Stability Gen. 60 65 55 58 ✗ ✓ Dis. 80 85 30 86 ✓ ✗ In practical applications, stability under various conditions is important
Dis. approaches Machine A B C D Basic performance Stability Gen. 60 65 55 58 ✗ ✓ Dis. 80 85 30 86 ✓ ✗ Goal 68 70 72 70 ✓ ✓ Goal: To achieve stable and (moderately) good performance Specific goals 1. To outperform Gen. 2. To avoid critical performance degradation seen in Dis.
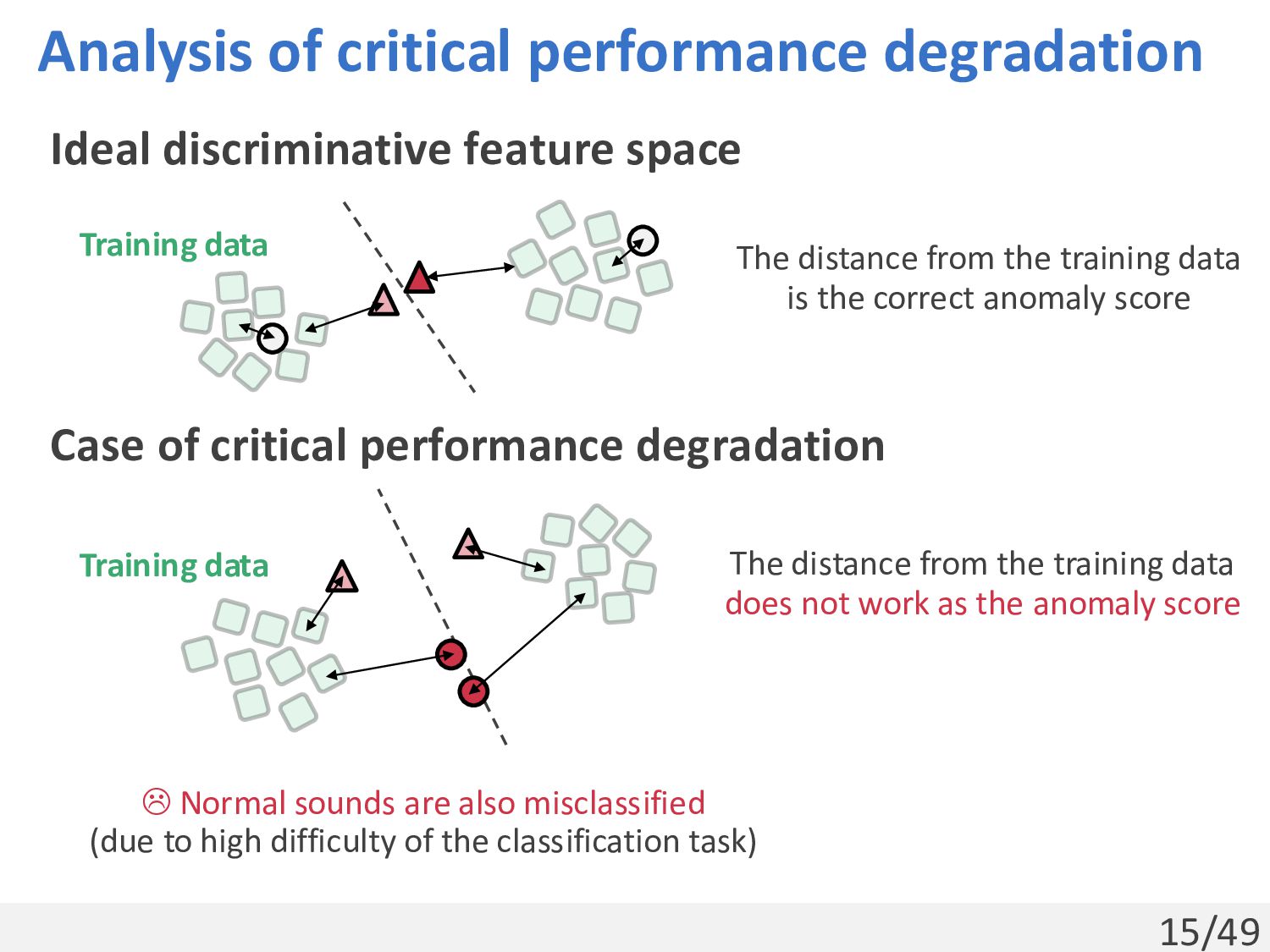
The distance from the training data is the correct anomaly score Training data Normal sounds are also misclassified (due to high difficulty of the classification task) Case of critical performance degradation Training data The distance from the training data does not work as the anomaly score
To avoid critical performance degradation seen in Dis. Two important observation 1. Gen. is relatively stable, but its performance is insufficient 2. Even in a discriminative feature space that leads to critical performance degradation, normal and anomalous samples still tend to be distinguished (i.e., although the distance from the training data does not work, the space still provides useful information) Training data
critical performance degradation seen in Dis. Discriminative neighborhood smoothing of generative anomaly scores ↑ Improve the performance of the original Gen. in an ensemble manner utilizing the discriminative space (Note: this method utilizes test data) ↑Remove the risk by not measuring the distance from the training data in the discriminative feature space Training data
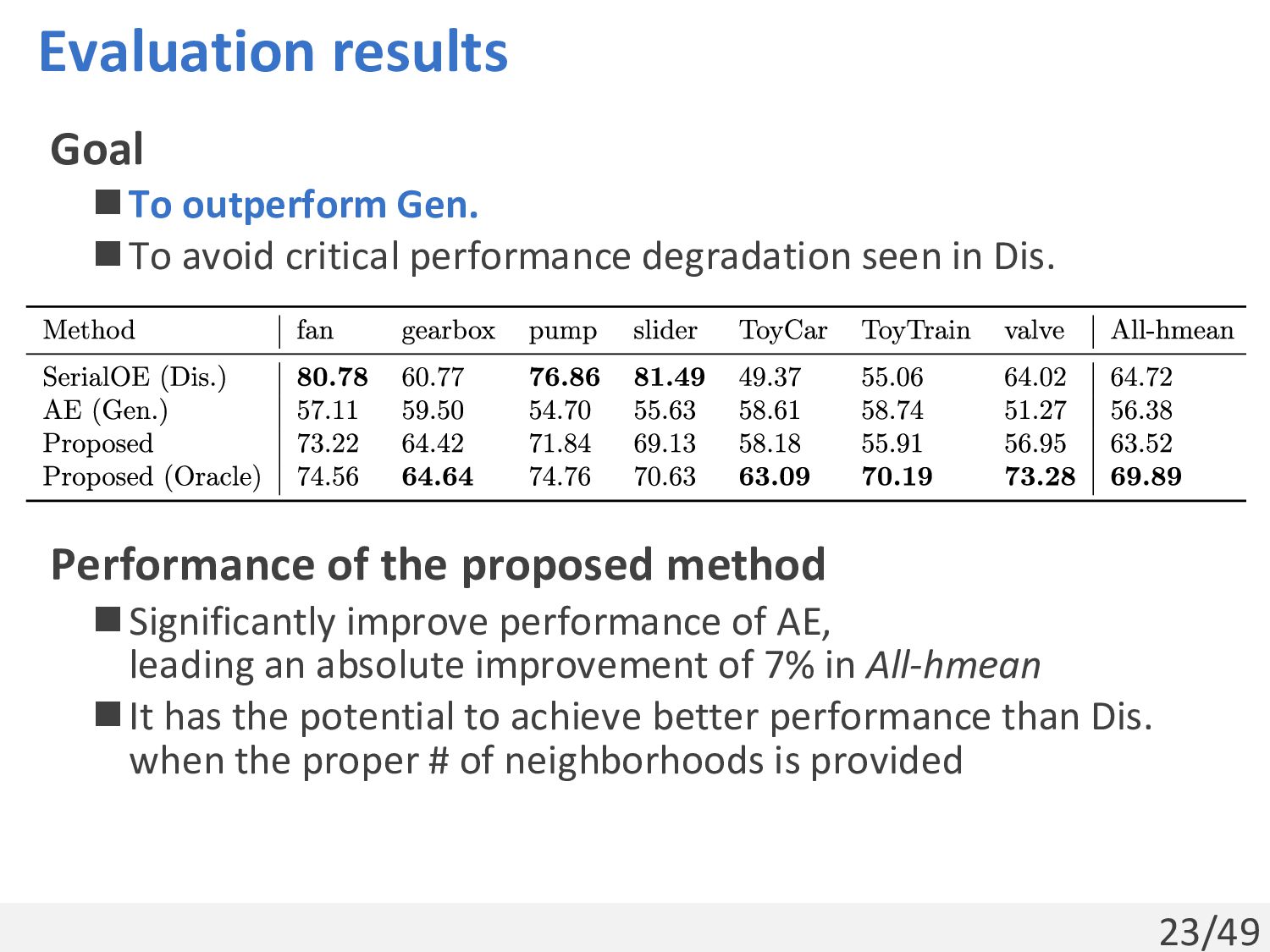
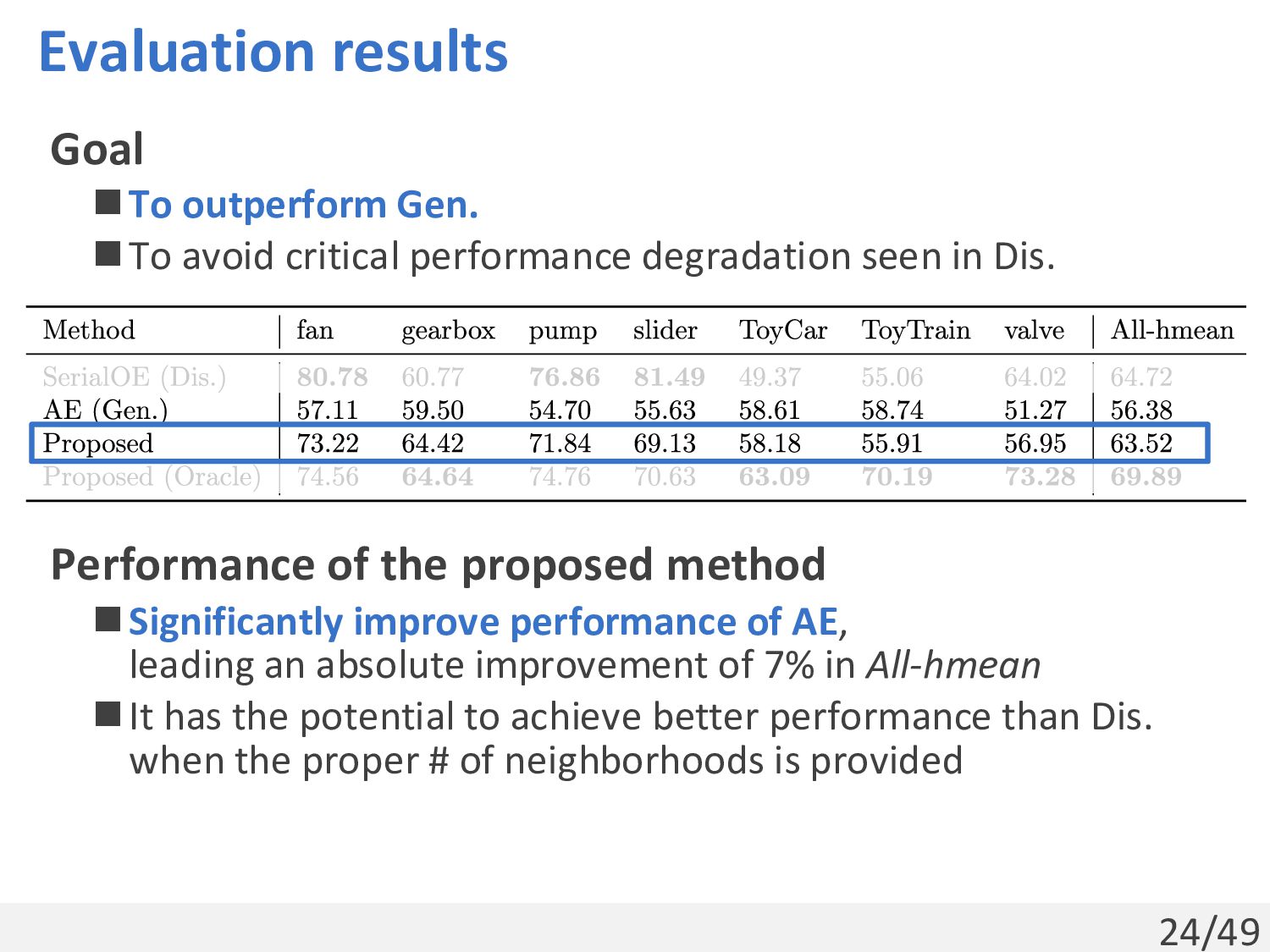
performance degradation seen in Dis. Comparison methods ◼Gen.: AE[Koizumi+, 2020] ◼Dis.: SerialOE[Kuroyanagi+, 2022] ◼Proposed method: Combines generative anomaly scores calculated by AE and the discriminative feature extractor of SerialOE Setups ◼Dataset: DCASE2021 Task2 ◼Metric: Harmonic mean of AUC and pAUC in the source domain (0 to 100, higher is better)
performance degradation seen in Dis. Performance of the proposed method ◼Significantly improve performance of AE, leading an absolute improvement of 7% in All-hmean ◼It has the potential to achieve better performance than Dis. when the proper # of neighborhoods is provided
performance degradation seen in Dis. Performance of the proposed method ◼Significantly improve performance of AE, leading an absolute improvement of 7% in All-hmean ◼It has the potential to achieve better performance than Dis. when the proper # of neighborhoods is provided
performance degradation seen in Dis. Performance of the proposed method ◼Significantly improve performance of AE, leading an absolute improvement of 7% in All-hmean ◼It has the potential to achieve better performance than Dis. when the proper # of neighborhoods is provided
performance degradation seen in Dis. Training, Normal Test, Anomalous Test, Normal Normal sounds are also misclassified ToyCar-5 ☺ Even if such a feature space is formed, Proposed avoids performance degradation → Dis. results in Performance degradation
stability ◼The performance of Gen. is insufficient ◼Dis. can sometimes causes critical performance degradation Proposed method 1. Improve the performance of Gen. by utilizing the discriminative feature space 2. Remove the risk by not measuring the distance from the training data in the discriminative space Results ◼Significantly improved the performance of the original Gen. ◼Robustly worked even when Dis. faced critical performance degradation problem
approaches: Generative and Discriminative Practical challenge 1: Instability ◼“Discriminative neighborhood smoothing for generative anomalous sound detection” Practical challenge 2: Data collection (annotation) costs ◼“Improvements of Discriminative Feature Space Training for Anomalous Sound Detection in Unlabeled Conditions” Summary
the discriminative approach Annotating operation params is costly 10:00 speed 30 10:05 speed 20 10:10 speed 25 … Annotation Information of labels Effectiveness Operation param. Capture differences in machine sounds → ☺ Detect anomalies based on differences in machine sounds Detailed param. Capture more detailed differences → ☺ Detect more subtle anomalies Noise type Capture differences in noise → Detect anomalies based on differences in noise
the discriminative approach Annotating operation params is costly 10:00 speed 30 10:05 speed 20 10:10 speed 25 … Annotation Information of labels Effectiveness Operation param. Capture differences in machine sounds → ☺ Detect anomalies based on differences in machine sounds Detailed param. Capture more detailed differences → ☺ Detect more subtle anomalies Noise type Capture differences in noise → Detect anomalies based on differences in noise Goal: To improve performance without relying on annotated labels
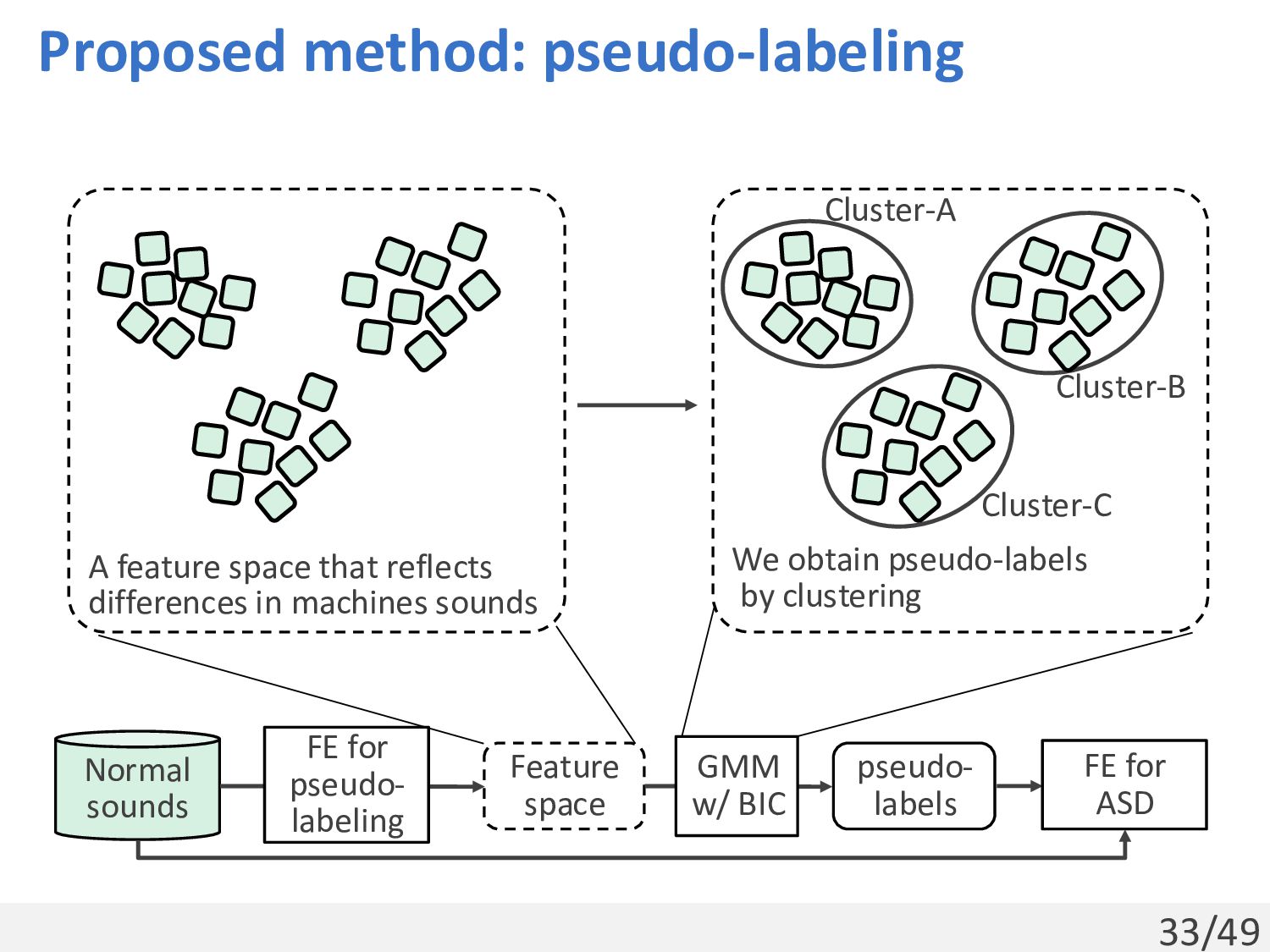
Feature space GMM w/ BIC pseudo- labels FE for ASD A feature space that reflects differences in machines sounds Cluster-B Cluster-C Cluster-A We obtain pseudo-labels by clustering
for pseudo- labeling Feature space GMM w/ BIC pseudo- labels FE for ASD Method name Training task Training data Class Classification of available labels (supervised) DCASE: Small-scale machine sound dataset (including target machine sounds) Triplet Triplet learning (self-supervised) PANNs Audio event classification (supervised) Audioset: Large-scale audio event dataset (not including target machine sounds) OpenL3 Audio-video clip correspondence prediction (self-supervised)
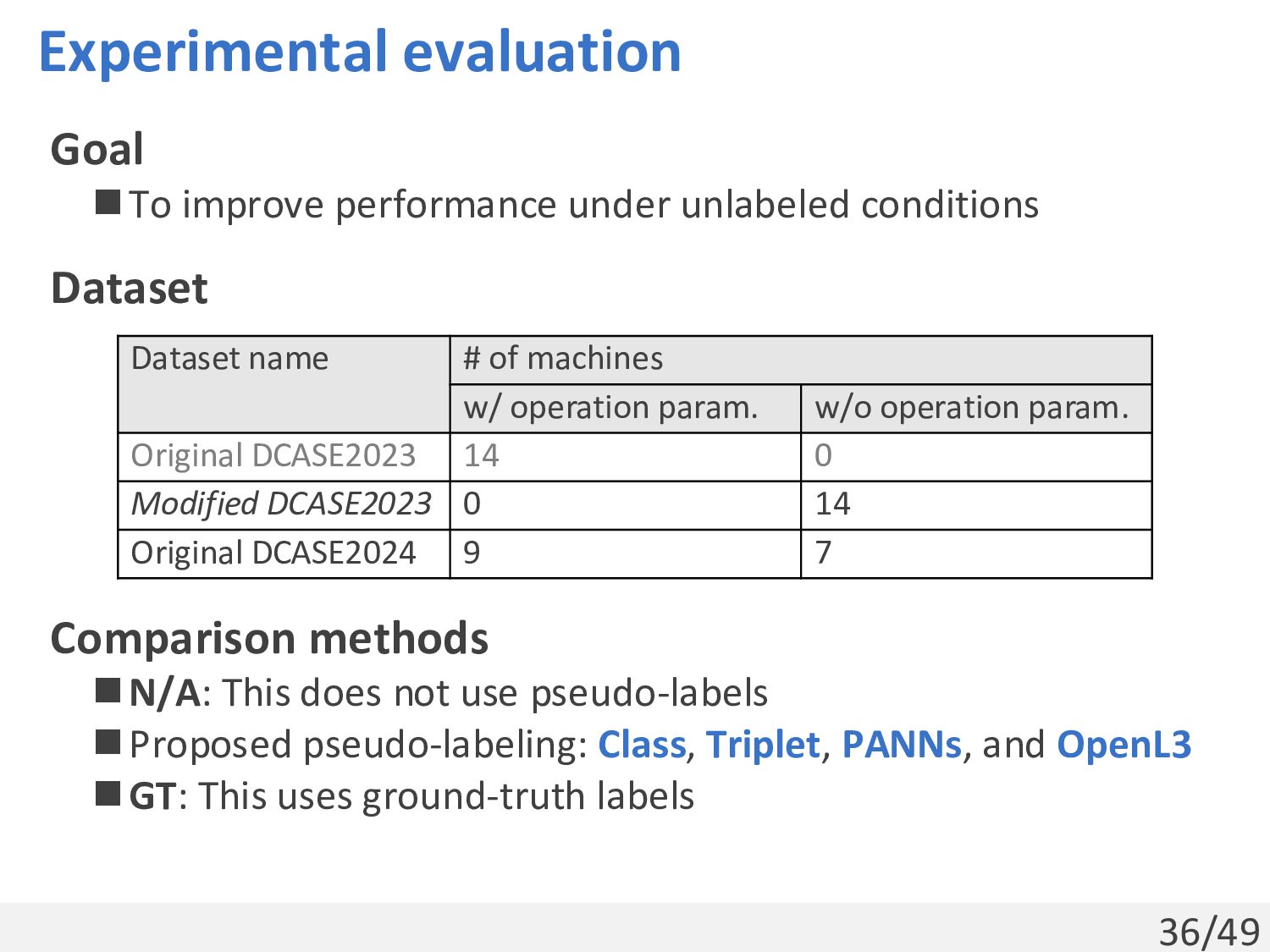
Dataset Comparison methods ◼N/A: This does not use pseudo-labels ◼Proposed pseudo-labeling: Class, Triplet, PANNs, and OpenL3 ◼GT: This uses ground-truth labels Dataset name # of machines w/ operation param. w/o operation param. Original DCASE2023 14 0 Modified DCASE2023 0 14 Original DCASE2024 9 7
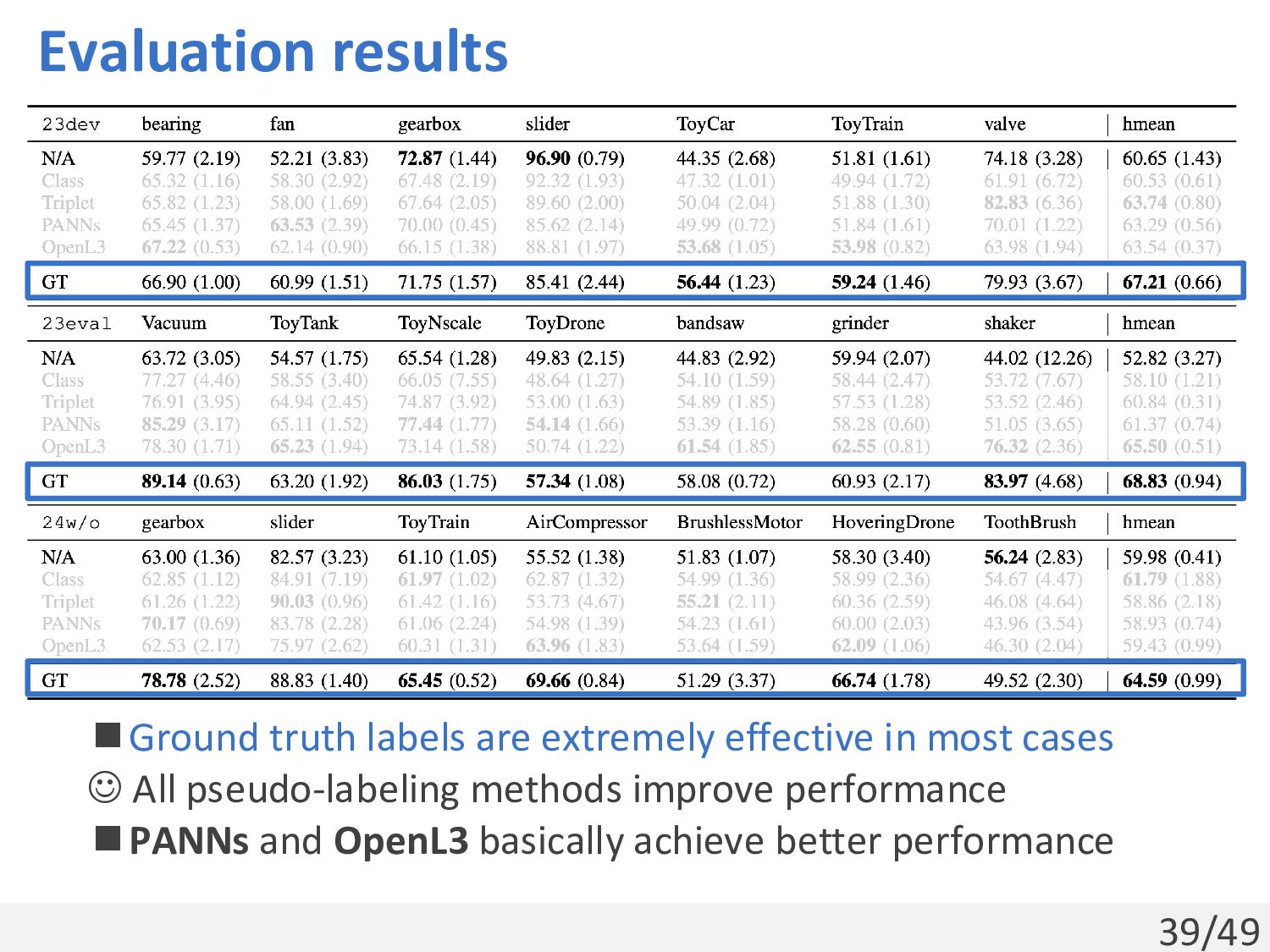
operation param. from DCASE 2024 (Results were almost the same) ◼Metric: the harmonic mean of AUC and pAUC over all domains ◼Show the arithmetic mean and standard deviation across 5 trials 7 machines w/o operation param. (DCASE 2023) 7 other machines w/o operation param. (DCASE 2023) 7 machines w/o operation param. (DCASE 2024)
most cases ☺ All pseudo-labeling methods improve performance ◼PANNs and OpenL3 basically achieve better performance For example, OpenL3 achieved an absolute improvement of 30%
N/A was 44.02) ◼OpenL3 successfully reflected the ground-truth labels ☺ It significantly improved the performance Feature spaces colored by ground truth labels
(AUC of N/A was 74.18) ◼The clusters also reflected differences in types of noise → unhelpful pseudo-labels Contain similar noise Contain similar noise Machine sound Machine sound
N/A was 74.18) ◼Resize(⋅) effectively captured differences in machine sounds ☺ The generated pseudo-labels improved the performance Machine sound Noise Machine sound Noise No noise No noise
Proposed method: Pseudo-labeling Results ◼All types of our pseudo-labeling methods were effective ◼PANNs and OpenL3 trained on Audioset especially provided useful pseudo-labels, but they sometimes suffered from noise ◼In some machines, Resize(⋅) very effectively captured differences in machine sounds Future work ◼More detailed analysis (e.g., differences between PANNs and OpenL3, further ablation studies) ◼Noise-robust pseudo-labeling method
approaches: Generative and Discriminative Practical challenge 1: Instability ◼“Discriminative neighborhood smoothing for generative anomalous sound detection” Practical challenge 2: Data collection (annotation) costs ◼“Improvements of Discriminative Feature Space Training for Anomalous Sound Detection in Unlabeled Conditions” Summary
◼Combine or selectively use Gen. and Dis. ◼Develop noise-robust pseudo-labels ◼There is still room for improvement in Domain shift and stability (first-shot) problems Performance Insufficient High Generative Discriminative Stability Relatively stable Unstable Useful but the annotation is costly Use of labels ↑ 2nd topic ↑ 1st topic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}