or phenotypes), ideally random • Attribute a score each solution using a fitness function • The only place with specific business knowledge • Apply genetic operators to create a new generation • Cross-breeding to retain best characteristics from each parent • Mutation to maintain diversity and to avoid converging to a local optima too quickly • Stop when you want!
you can use a mapping framework, such as Spring Data Neo4j • For data-centric applications, you should stay as close as possible to the graph model • In any case, don’t try to hide the graph!
resources (or ids) to chain queries. • Robustness principal: “Be conservative in what you do, be liberal in what you accept from others” • Use assertions as preconditions • Assertions document intent • Fail fast if data doesn’t match
use cases • Write simple unit tests using these datasets to support design and implementation • These tests tend to become less useful when requirements are better understood • Throw them away!
need to be correct and sufficiently performant • Existing queries’s performance can degrade as the underlying model changes • Assertions on timeouts should be part of the test suite to detect loops and poor performance • JUnit’s @Test(timeout=5) • Spring’s @Timeout(value=5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
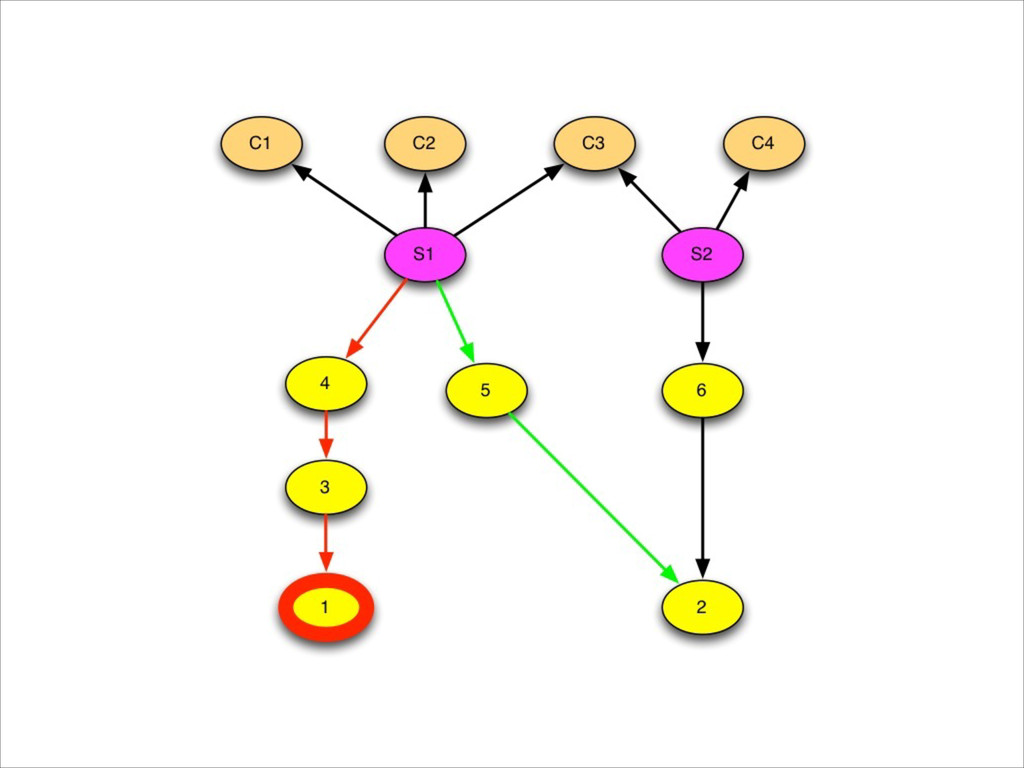{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
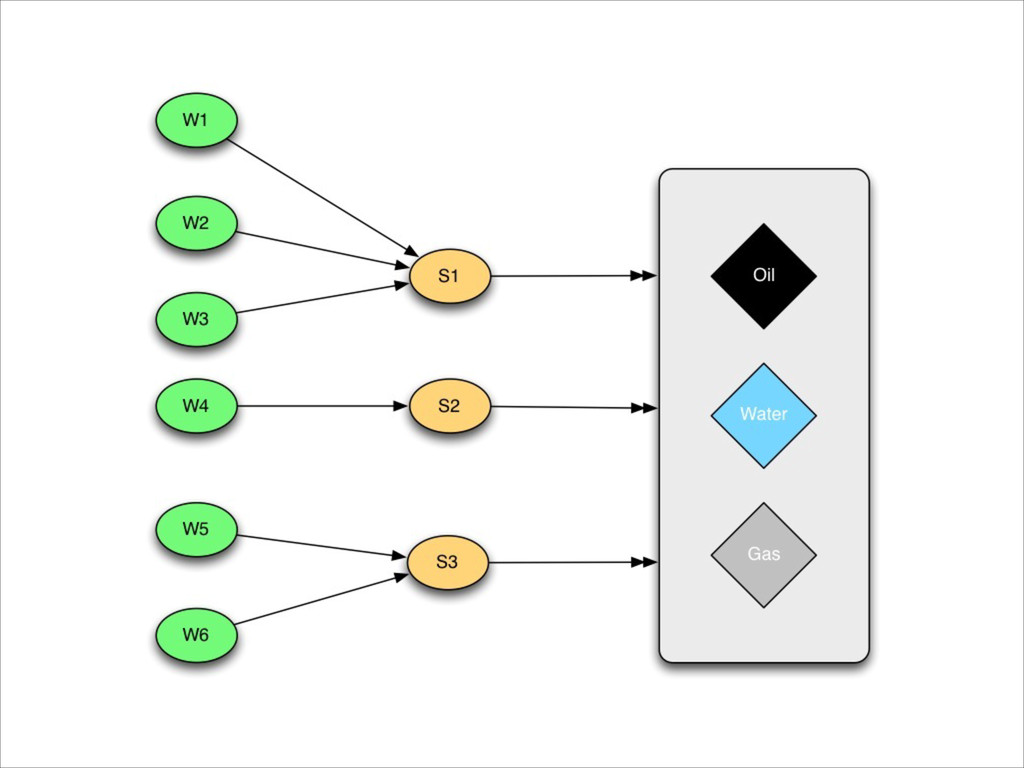{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
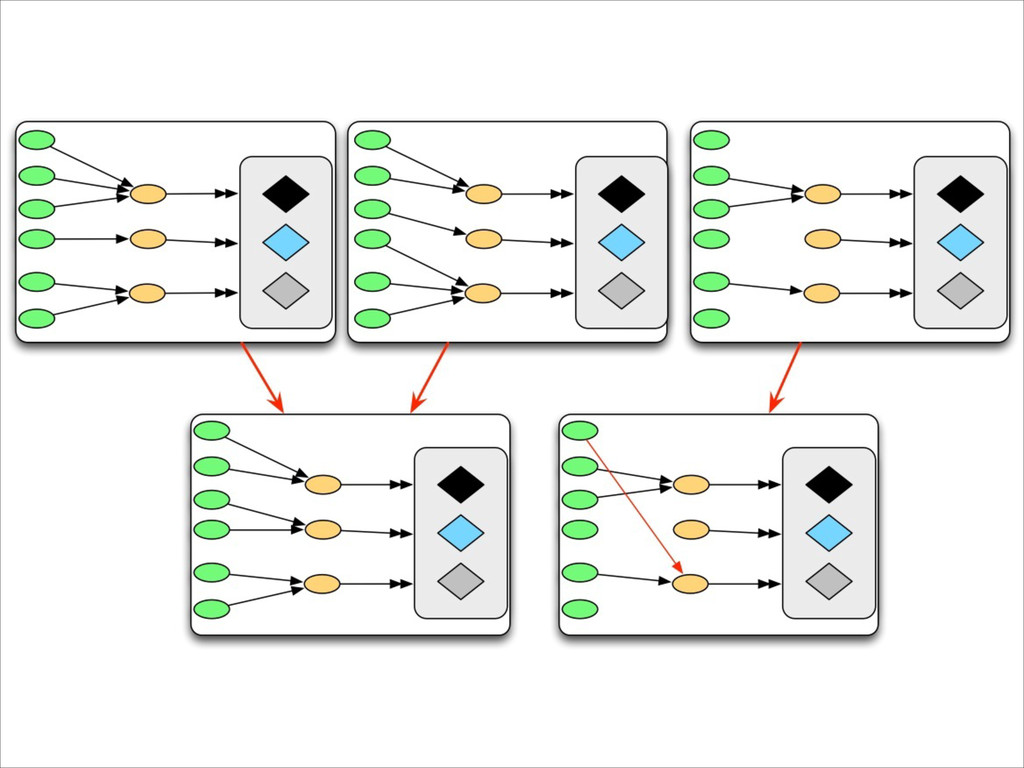{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}