THE GUY THAT MADE THE FIRST TOOL FOR QFO AND MADE IT OPEN SOURCE, BUT NONE OF THE MAJOR SEO SOFTWARE COMPANIES HAVE ONE YET, WTF. Michael King Founder and CEO iPullRank
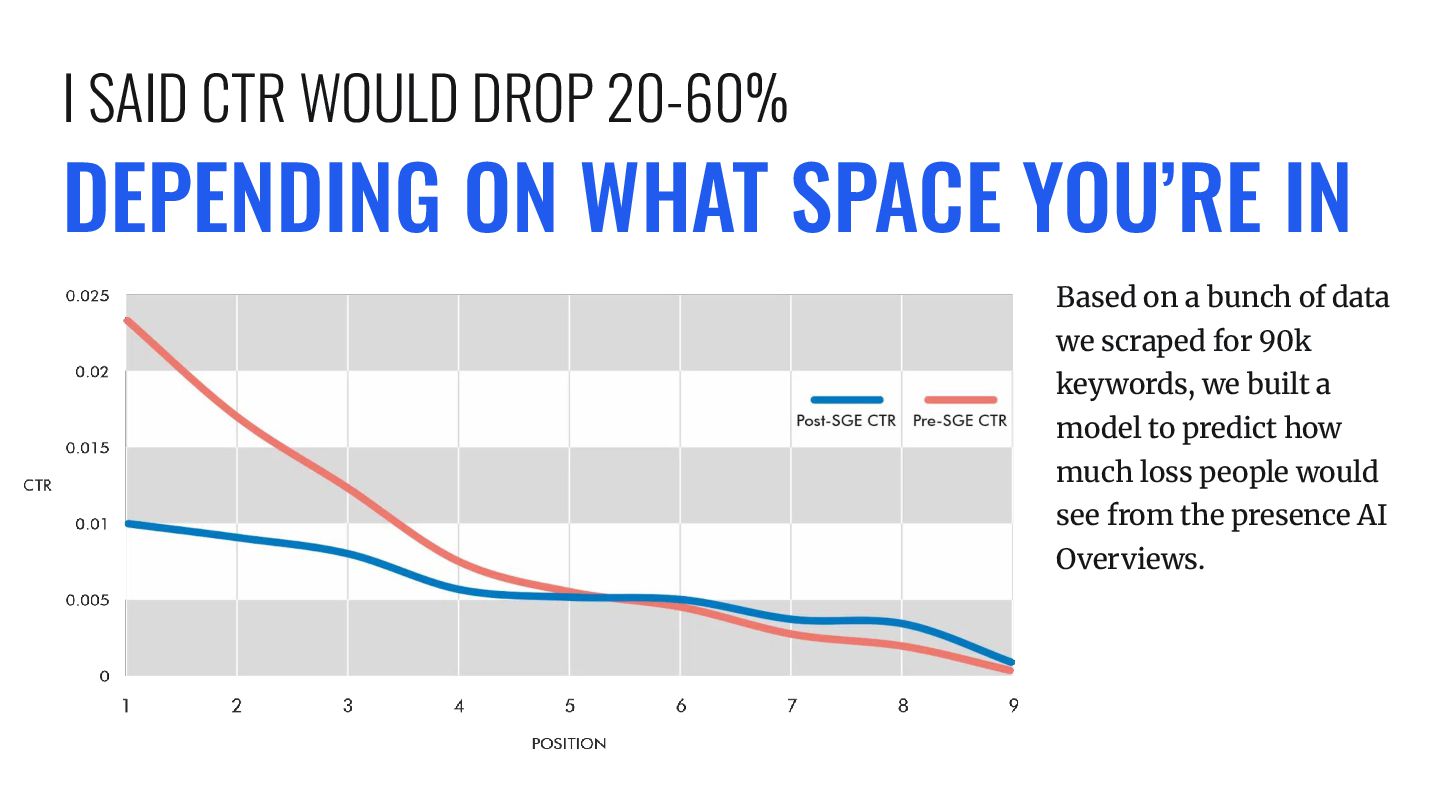
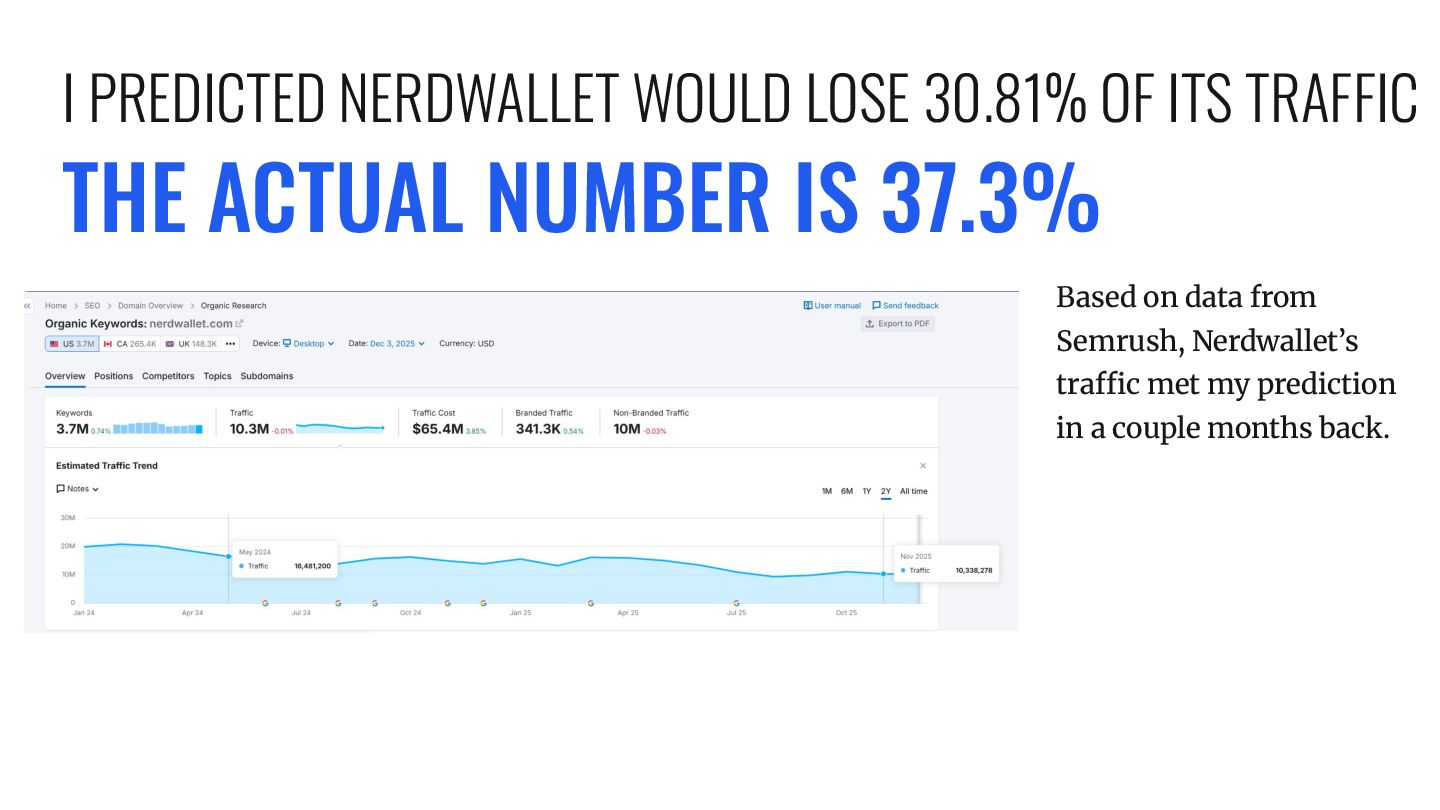
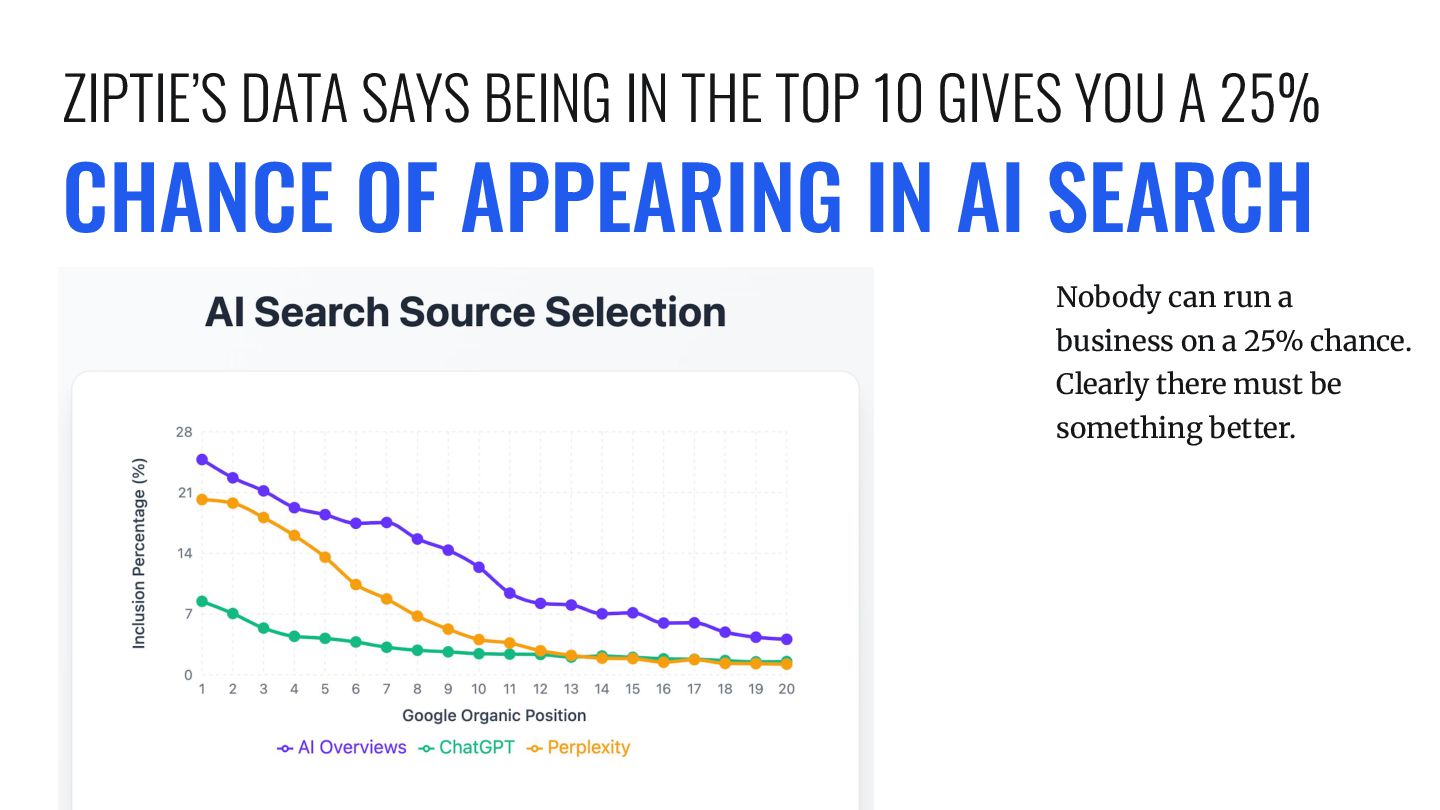
DROP 20-60% Based on a bunch of data we scraped for 90k keywords, we built a model to predict how much loss people would see from the presence AI Overviews.
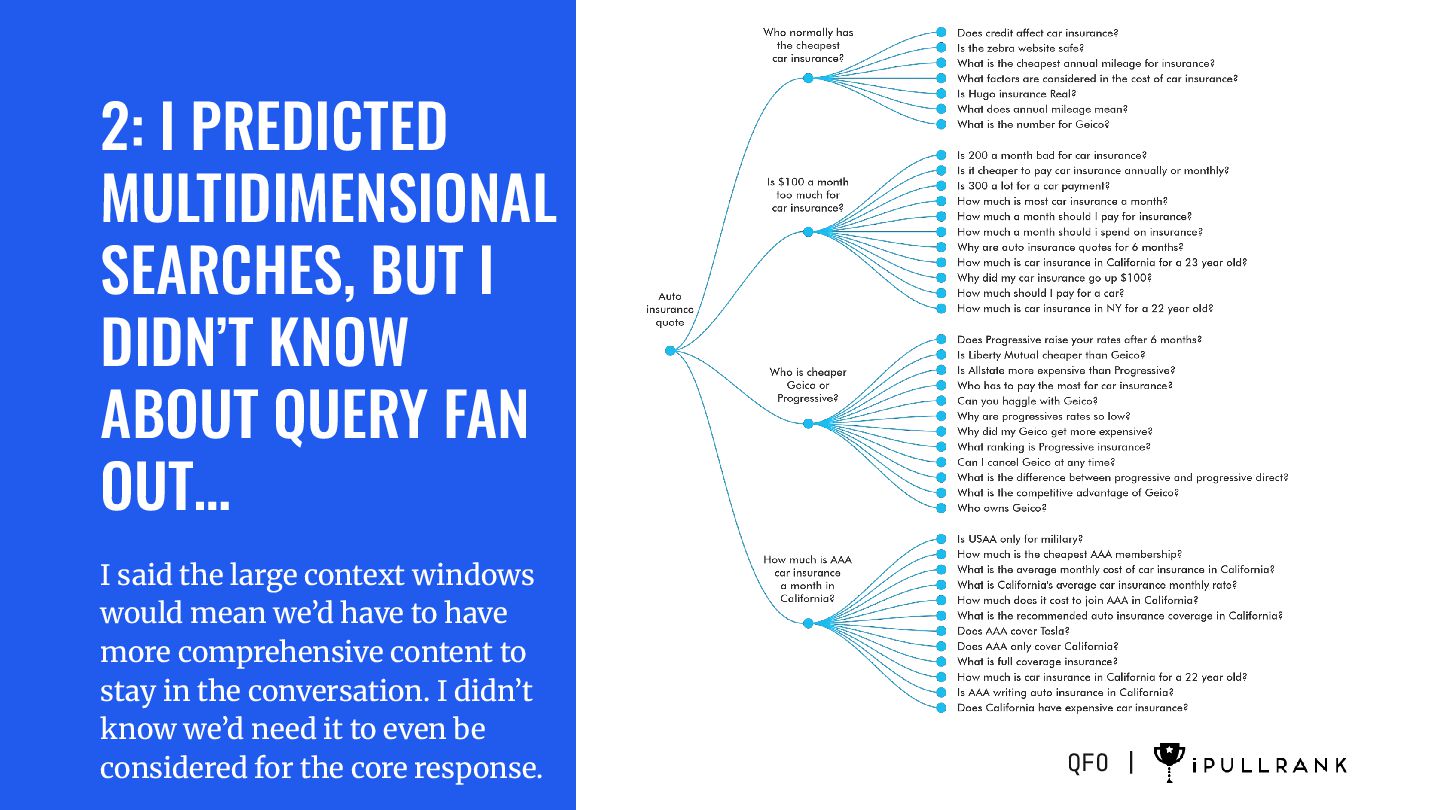
QUERY FAN OUT… I said the large context windows would mean we’d have to have more comprehensive content to stay in the conversation. I didn’t know we’d need it to even be considered for the core response. QFO |
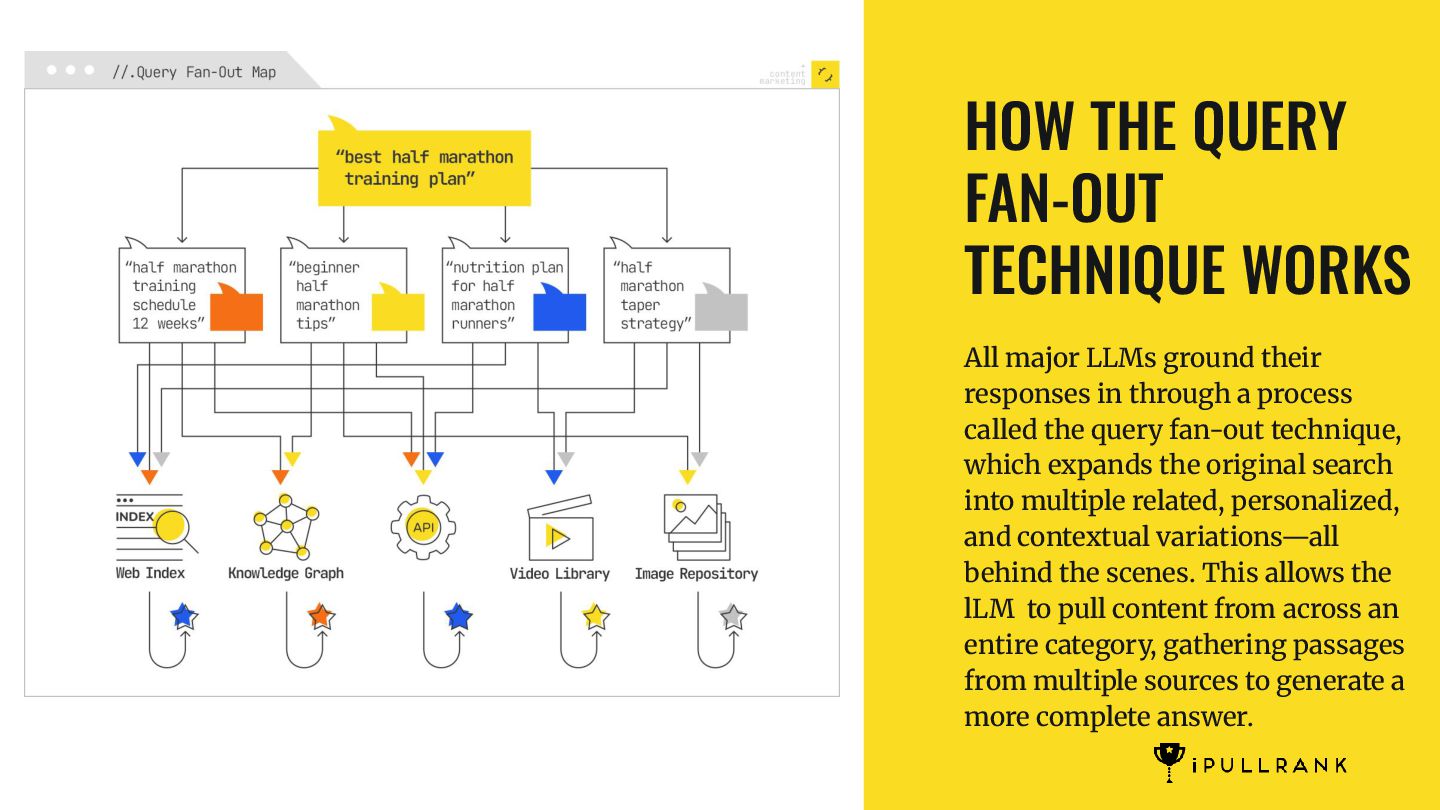
their responses in through a process called the query fan-out technique, which expands the original search into multiple related, personalized, and contextual variations—all behind the scenes. This allows the lLM to pull content from across an entire category, gathering passages from multiple sources to generate a more complete answer.
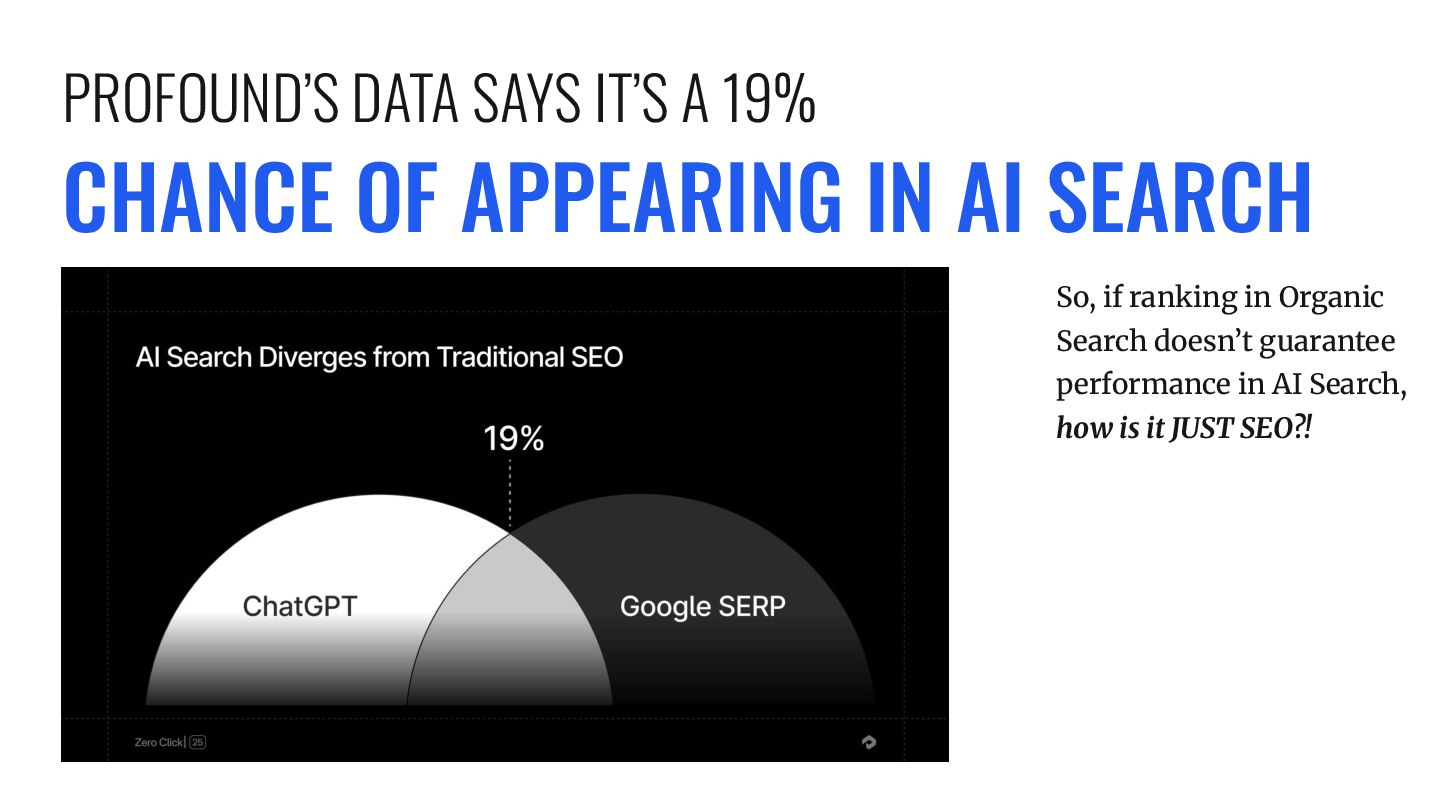
control over the synthesis pipeline, but if you appear for as many of the inputs as possible, you are improving your chances of being the final choice. WHY DO I CARE SO MUCH ABOUT THIS?
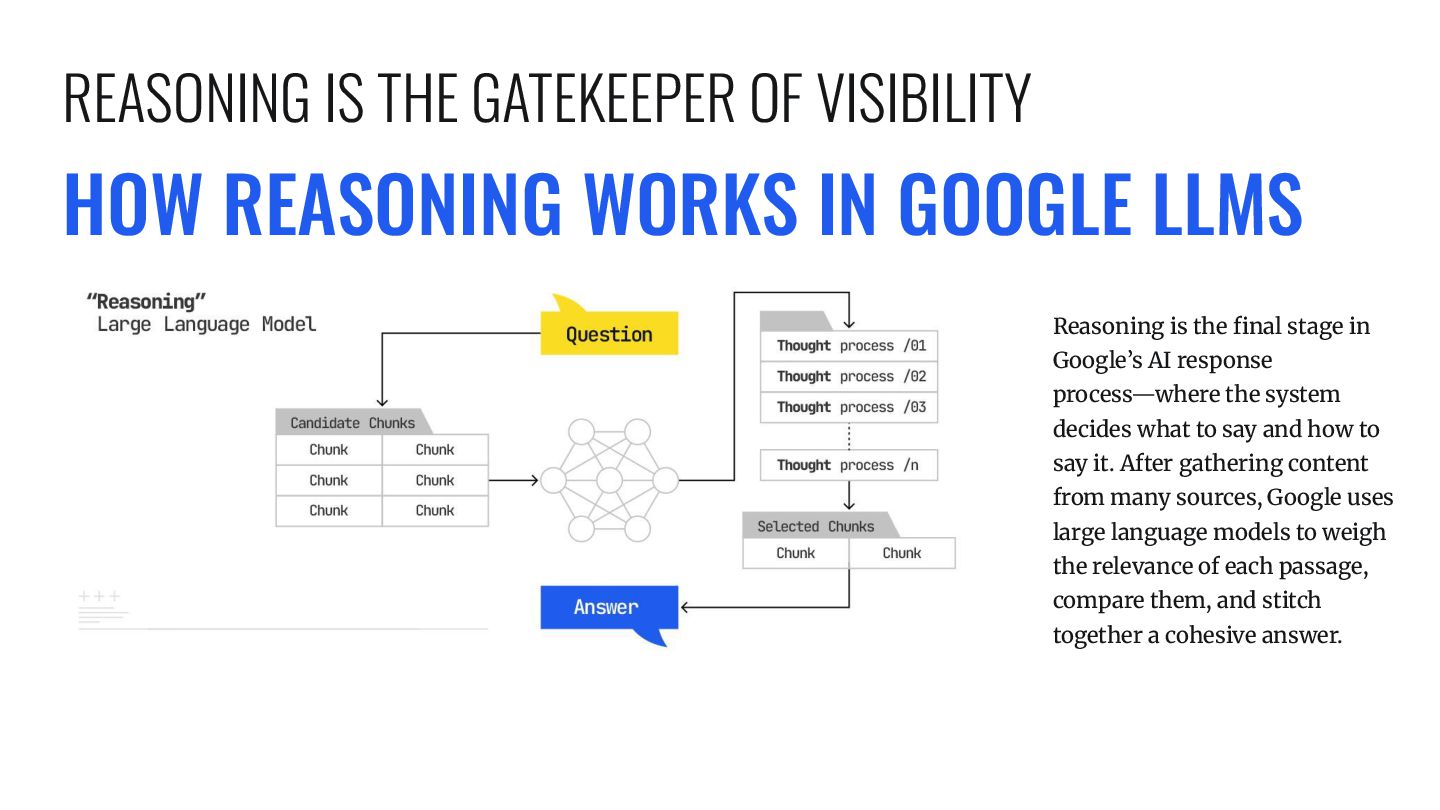
stage in Google’s AI response process—where the system decides what to say and how to say it. After gathering content from many sources, Google uses large language models to weigh the relevance of each passage, compare them, and stitch together a cohesive answer. REASONING IS THE GATEKEEPER OF VISIBILITY
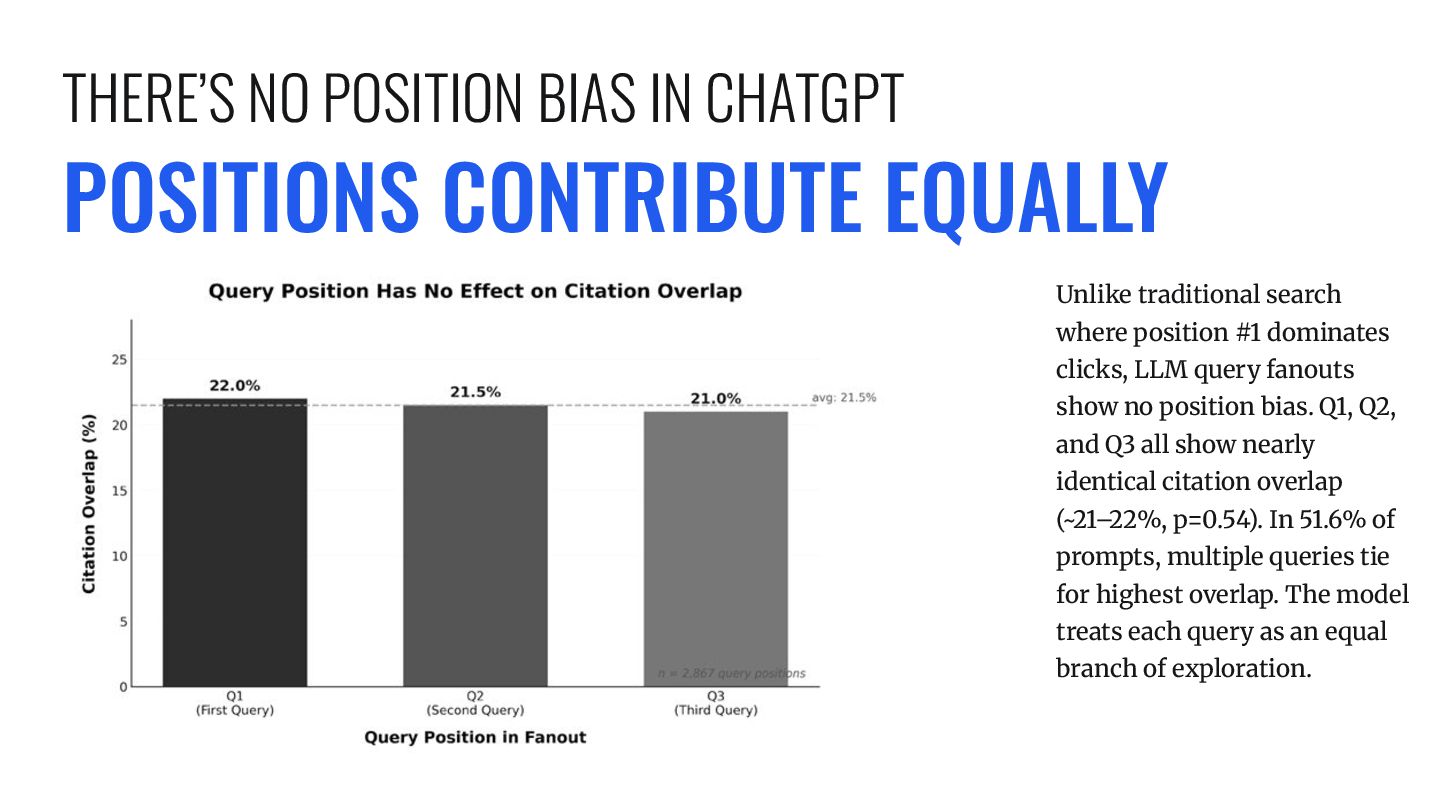
clicks, LLM query fanouts show no position bias. Q1, Q2, and Q3 all show nearly identical citation overlap (~21–22%, p=0.54). In 51.6% of prompts, multiple queries tie for highest overlap. The model treats each query as an equal branch of exploration. THERE’S NO POSITION BIAS IN CHATGPT
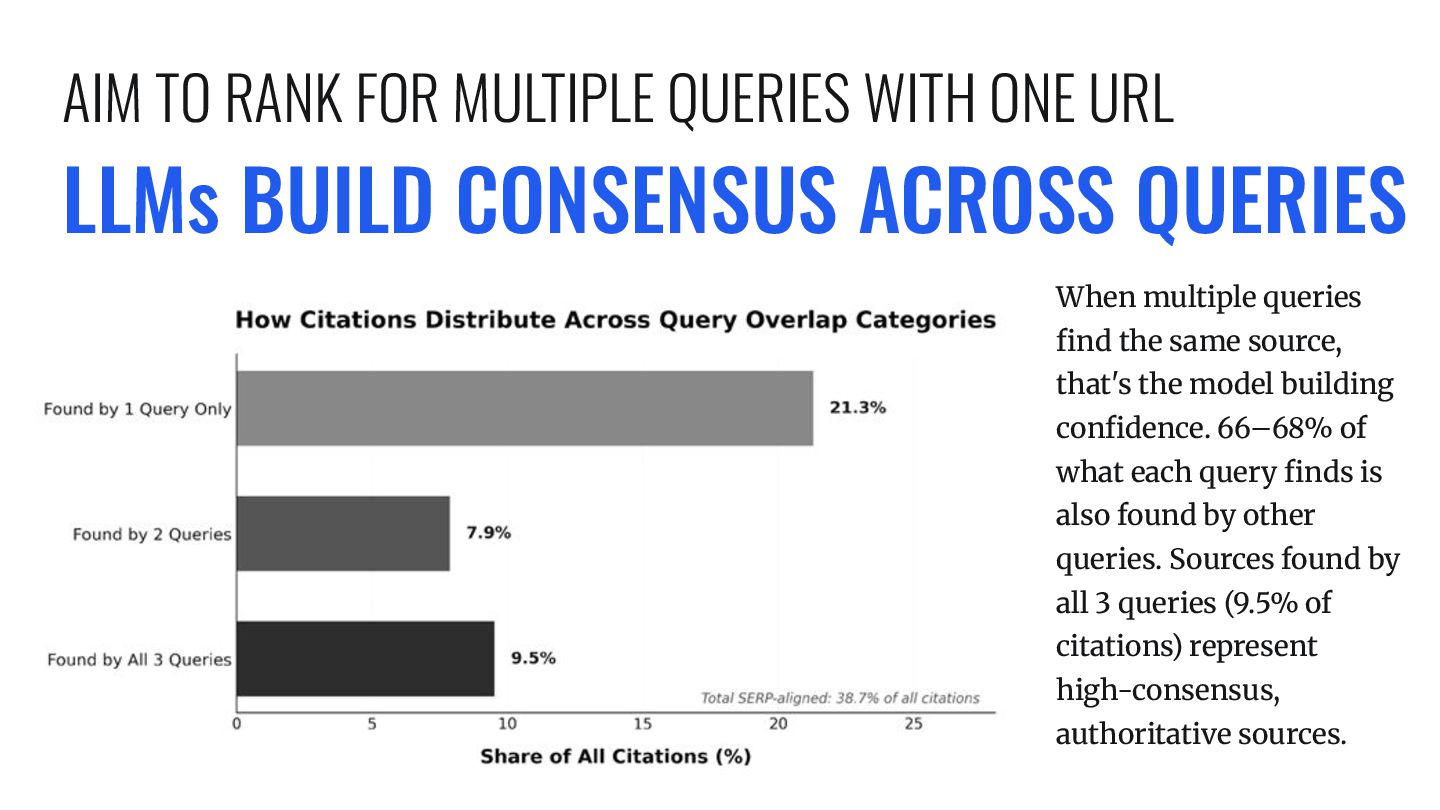
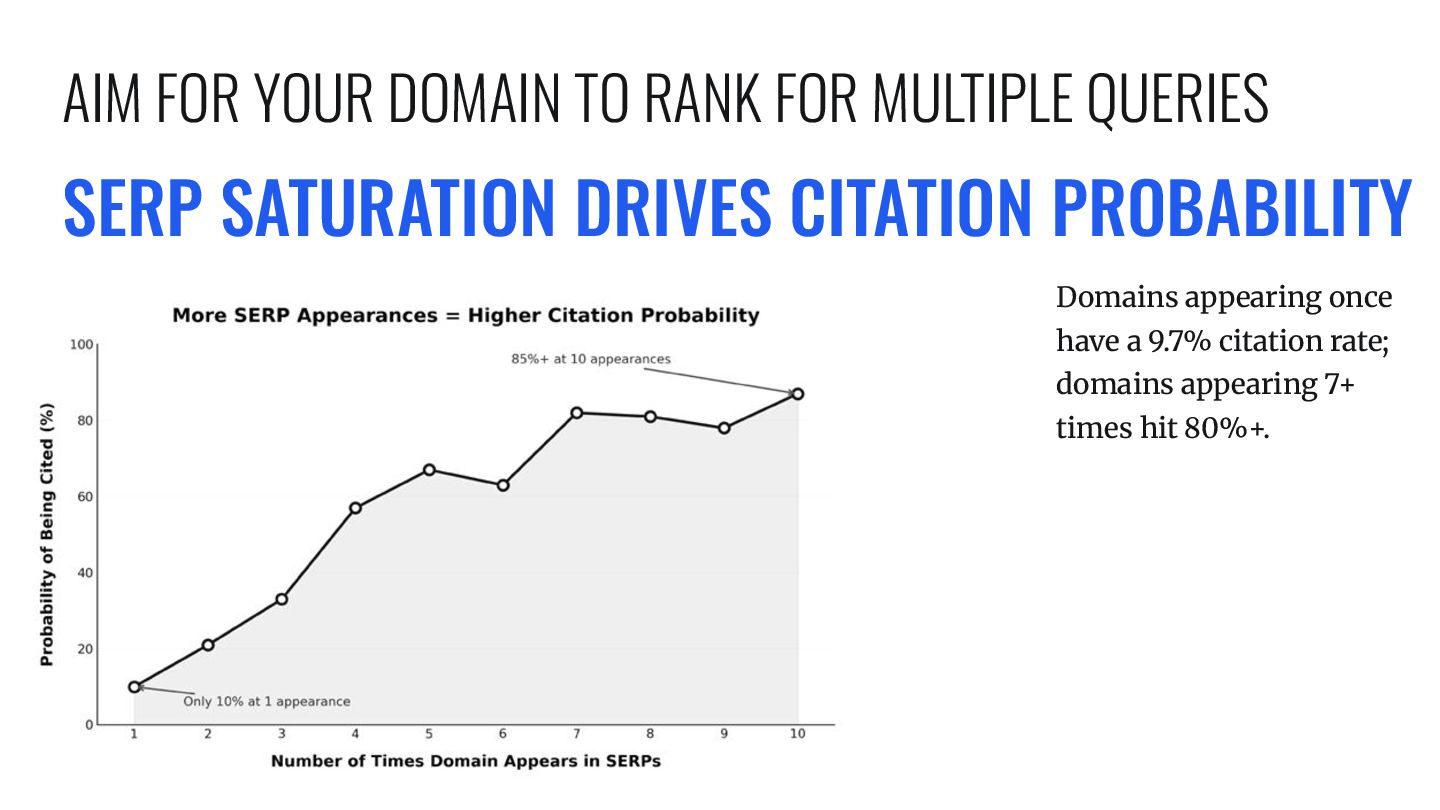
same source, that's the model building confidence. 66–68% of what each query finds is also found by other queries. Sources found by all 3 queries (9.5% of citations) represent high-consensus, authoritative sources. AIM TO RANK FOR MULTIPLE QUERIES WITH ONE URL
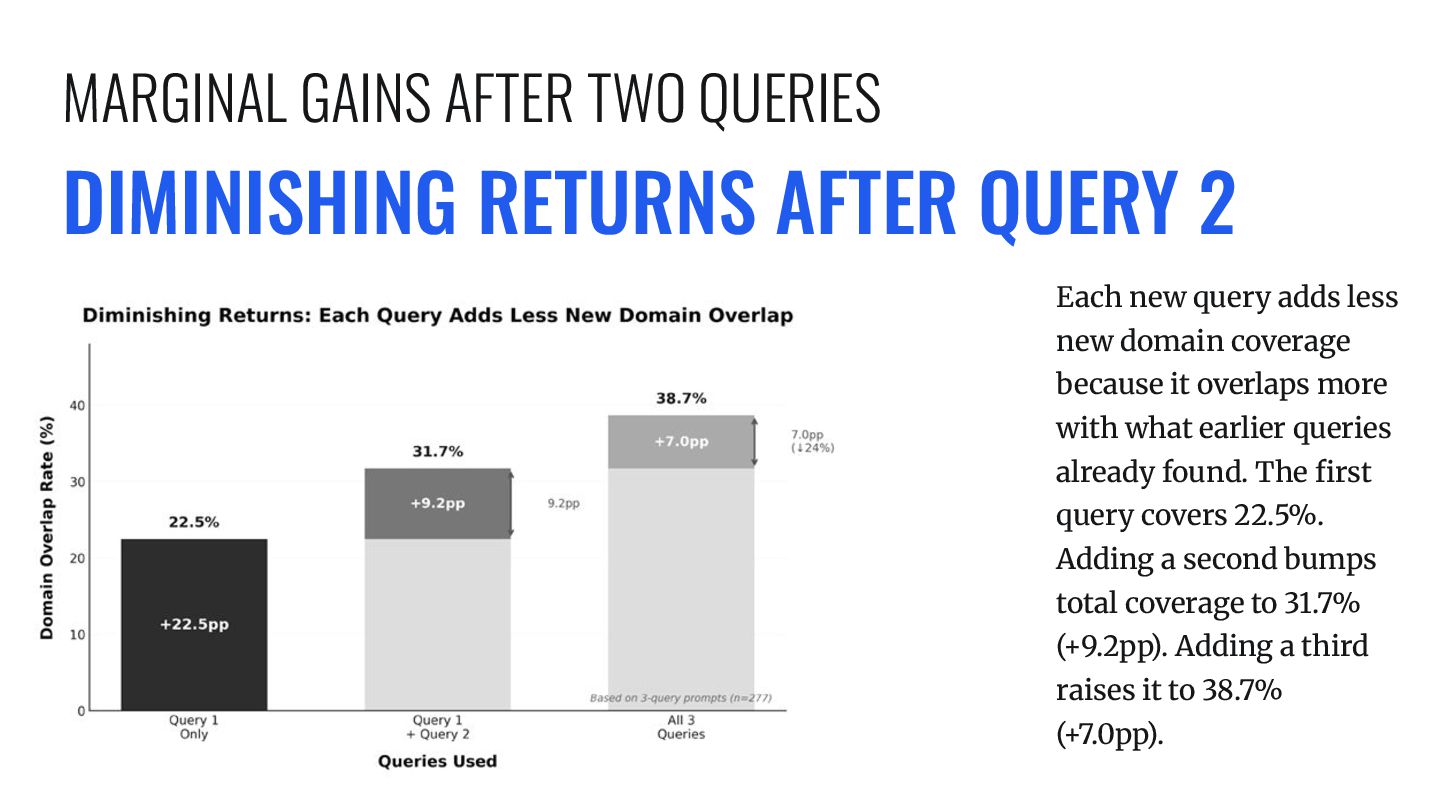
new domain coverage because it overlaps more with what earlier queries already found. The first query covers 22.5%. Adding a second bumps total coverage to 31.7% (+9.2pp). Adding a third raises it to 38.7% (+7.0pp). MARGINAL GAINS AFTER TWO QUERIES
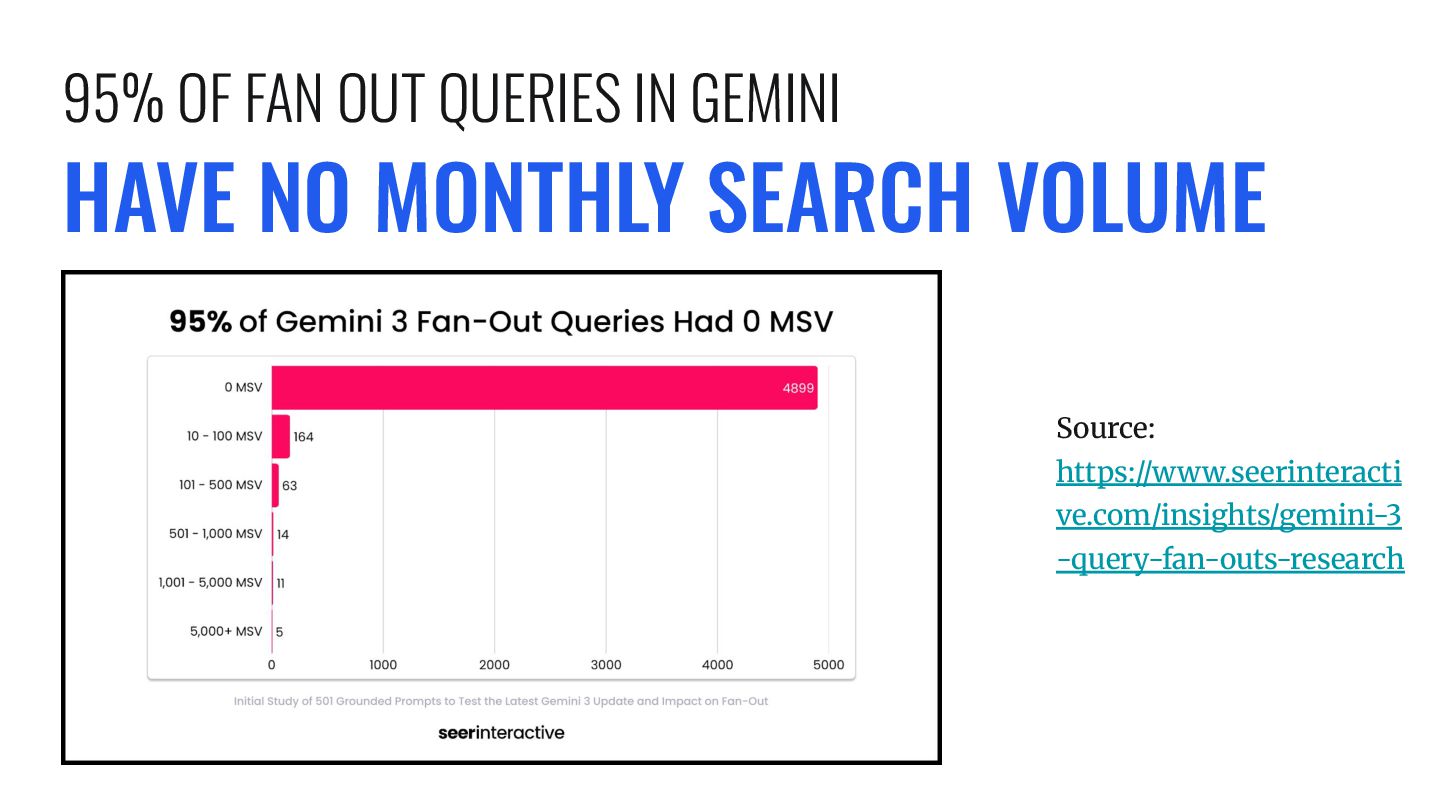
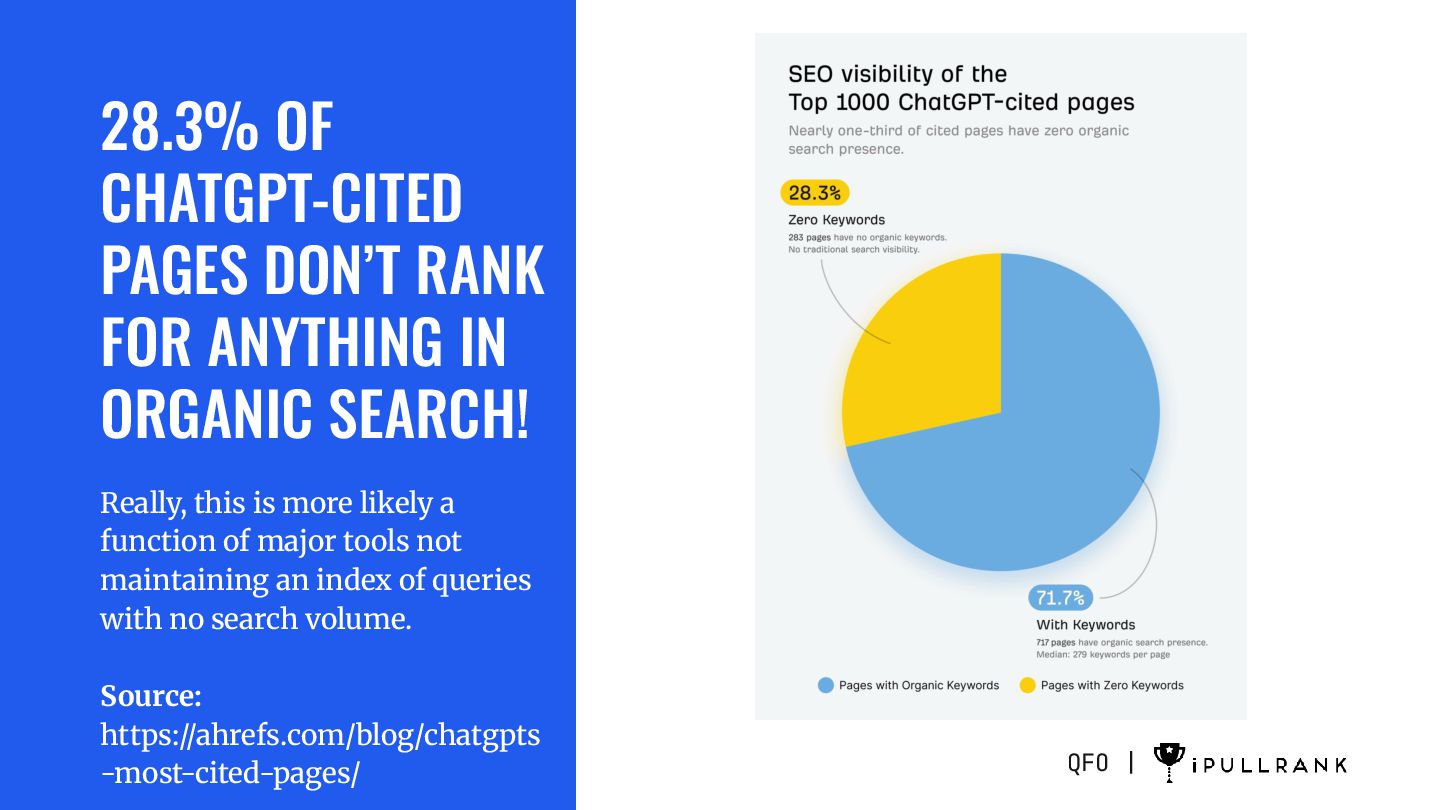
SEARCH! Really, this is more likely a function of major tools not maintaining an index of queries with no search volume. Source: https://ahrefs.com/blog/chatgpts -most-cited-pages/ QFO |
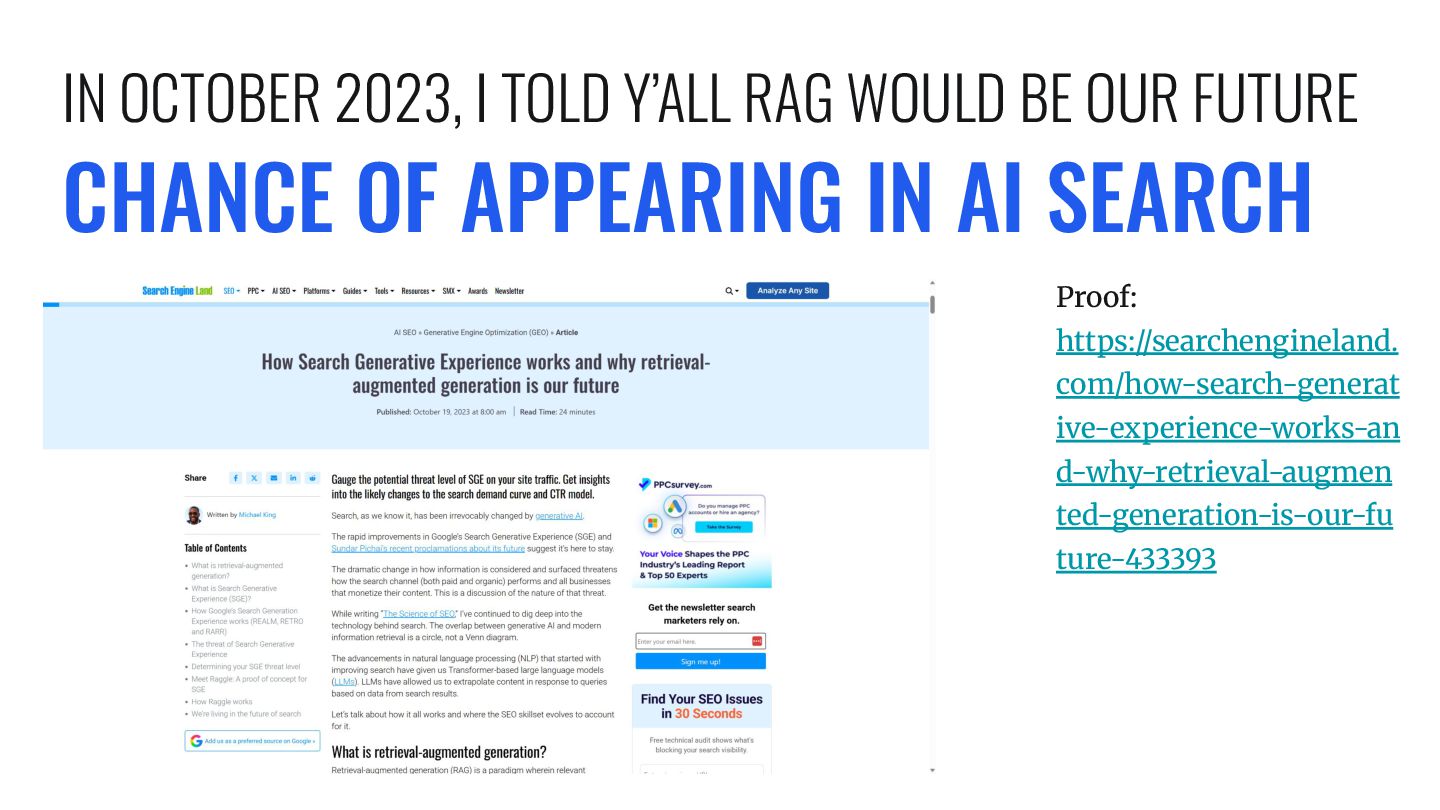
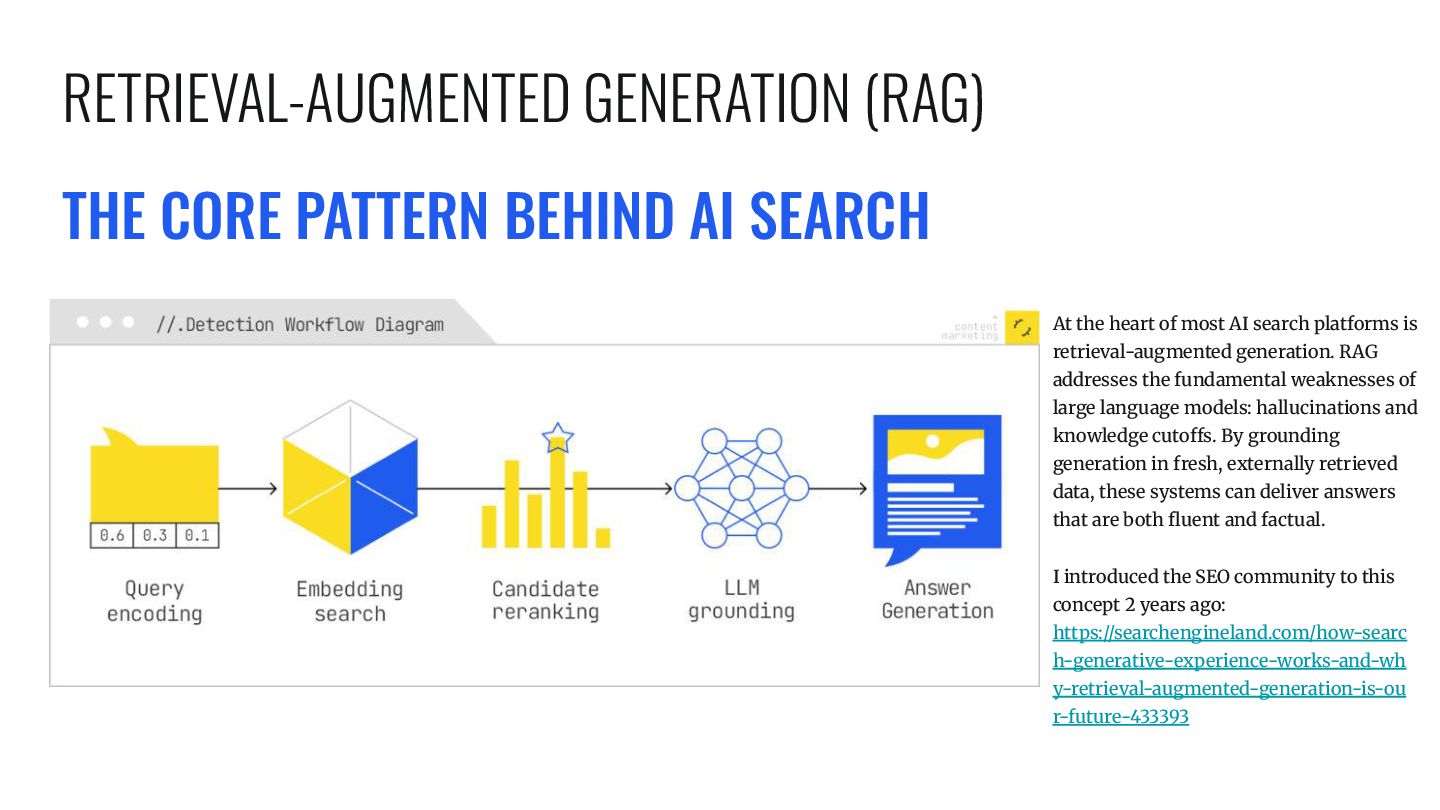
most AI search platforms is retrieval-augmented generation. RAG addresses the fundamental weaknesses of large language models: hallucinations and knowledge cutoffs. By grounding generation in fresh, externally retrieved data, these systems can deliver answers that are both fluent and factual. I introduced the SEO community to this concept 2 years ago: https://searchengineland.com/how-searc h-generative-experience-works-and-wh y-retrieval-augmented-generation-is-ou r-future-433393 RETRIEVAL-AUGMENTED GENERATION (RAG)
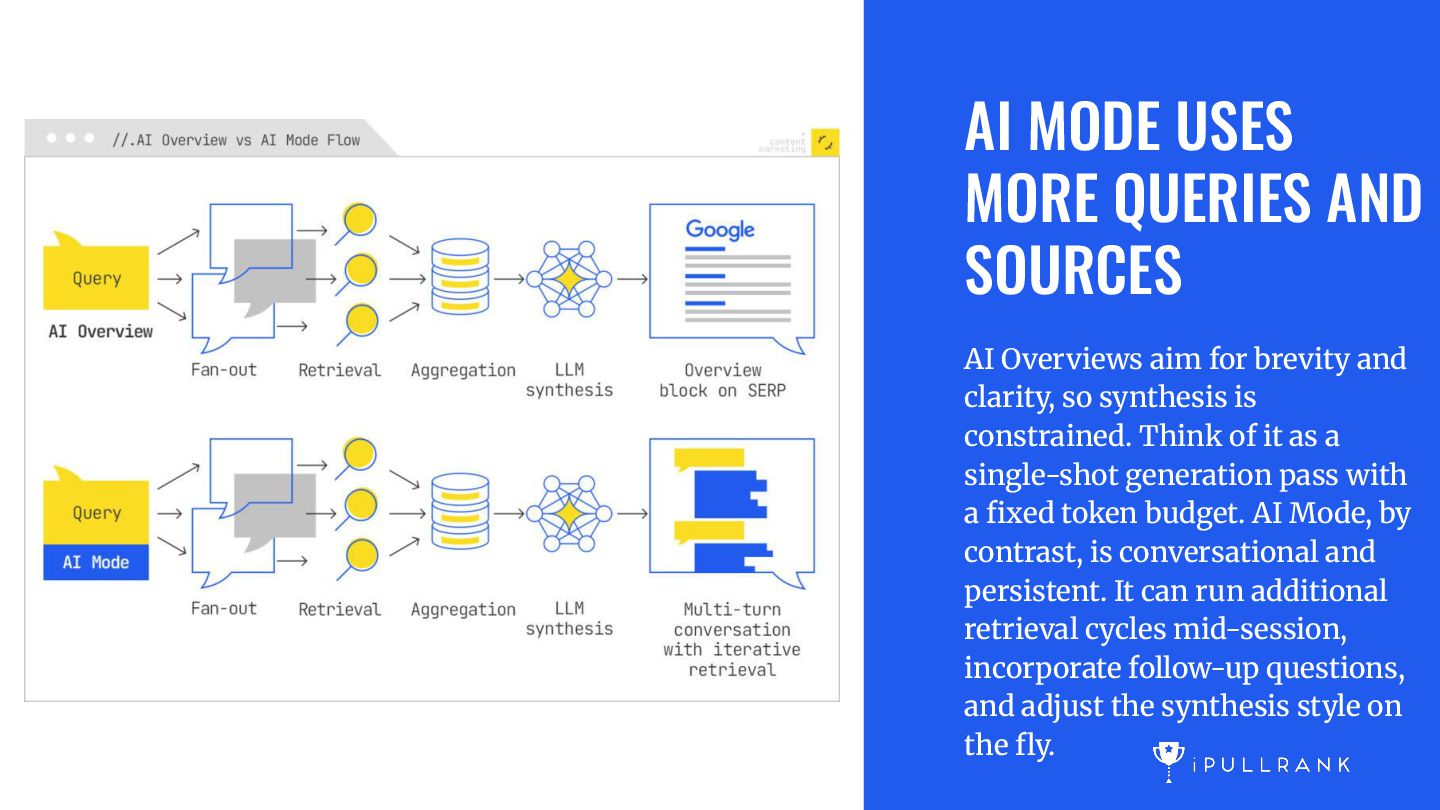
for brevity and clarity, so synthesis is constrained. Think of it as a single-shot generation pass with a fixed token budget. AI Mode, by contrast, is conversational and persistent. It can run additional retrieval cycles mid-session, incorporate follow-up questions, and adjust the synthesis style on the fly.
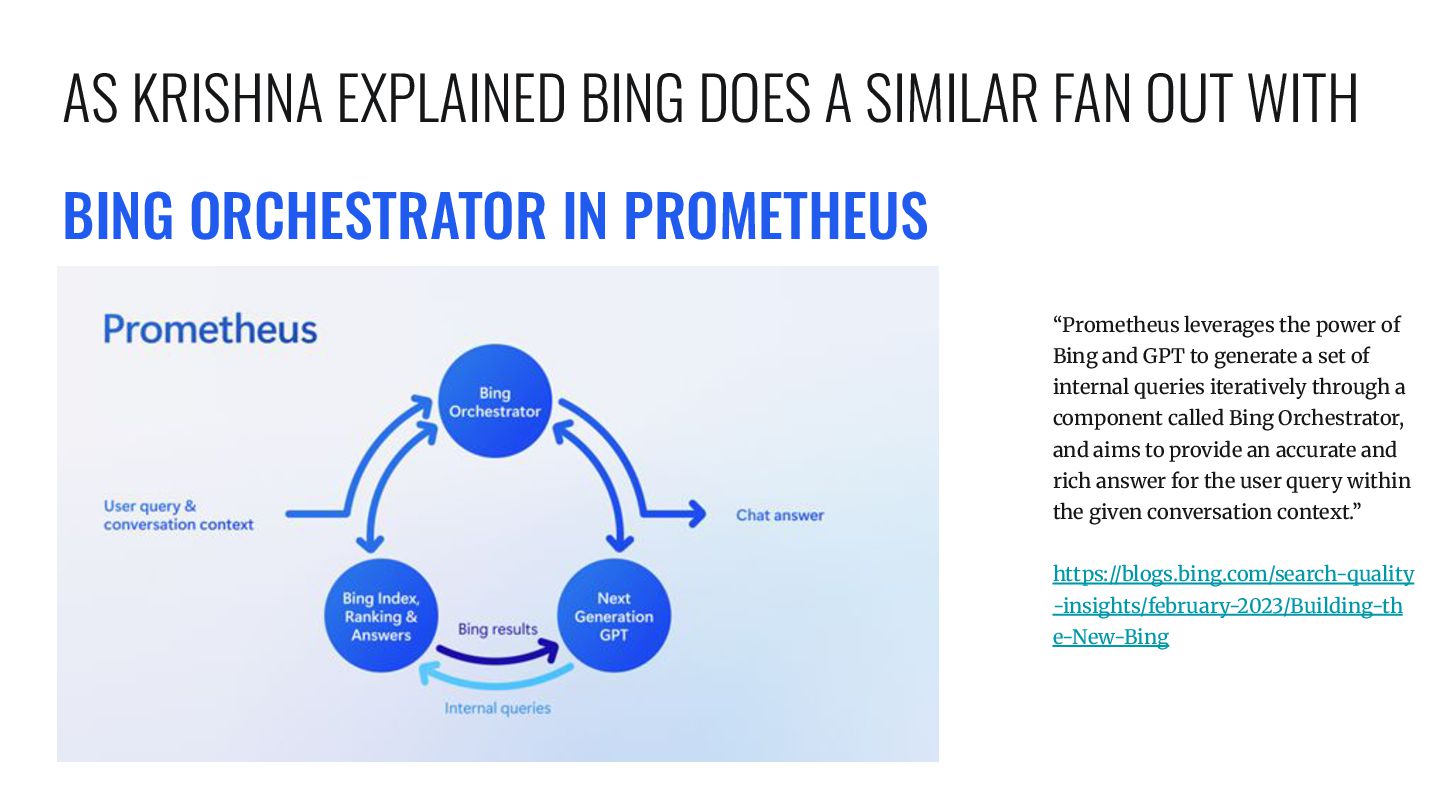
and GPT to generate a set of internal queries iteratively through a component called Bing Orchestrator, and aims to provide an accurate and rich answer for the user query within the given conversation context.” https://blogs.bing.com/search-quality -insights/february-2023/Building-th e-New-Bing AS KRISHNA EXPLAINED BING DOES A SIMILAR FAN OUT WITH
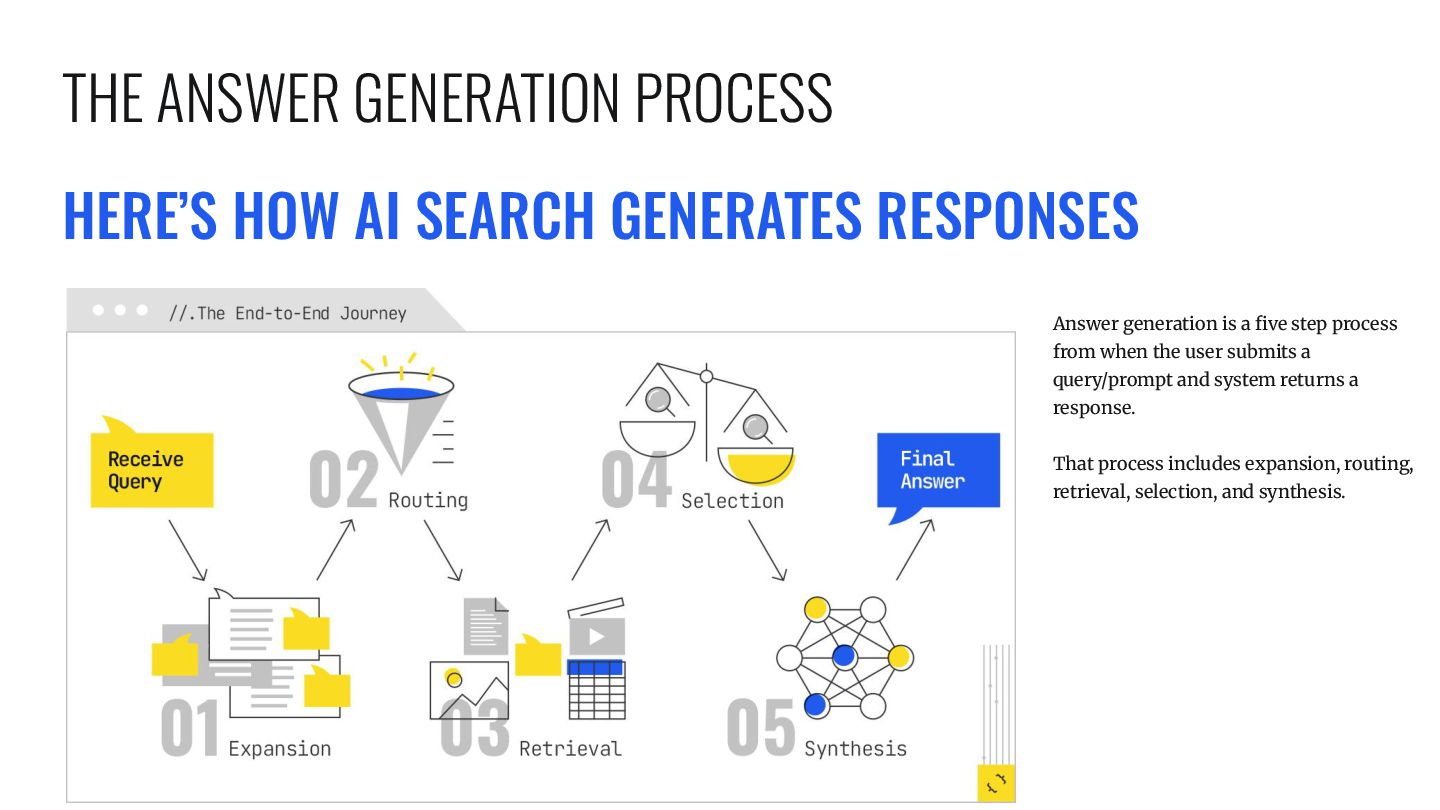
five step process from when the user submits a query/prompt and system returns a response. That process includes expansion, routing, retrieval, selection, and synthesis. THE ANSWER GENERATION PROCESS
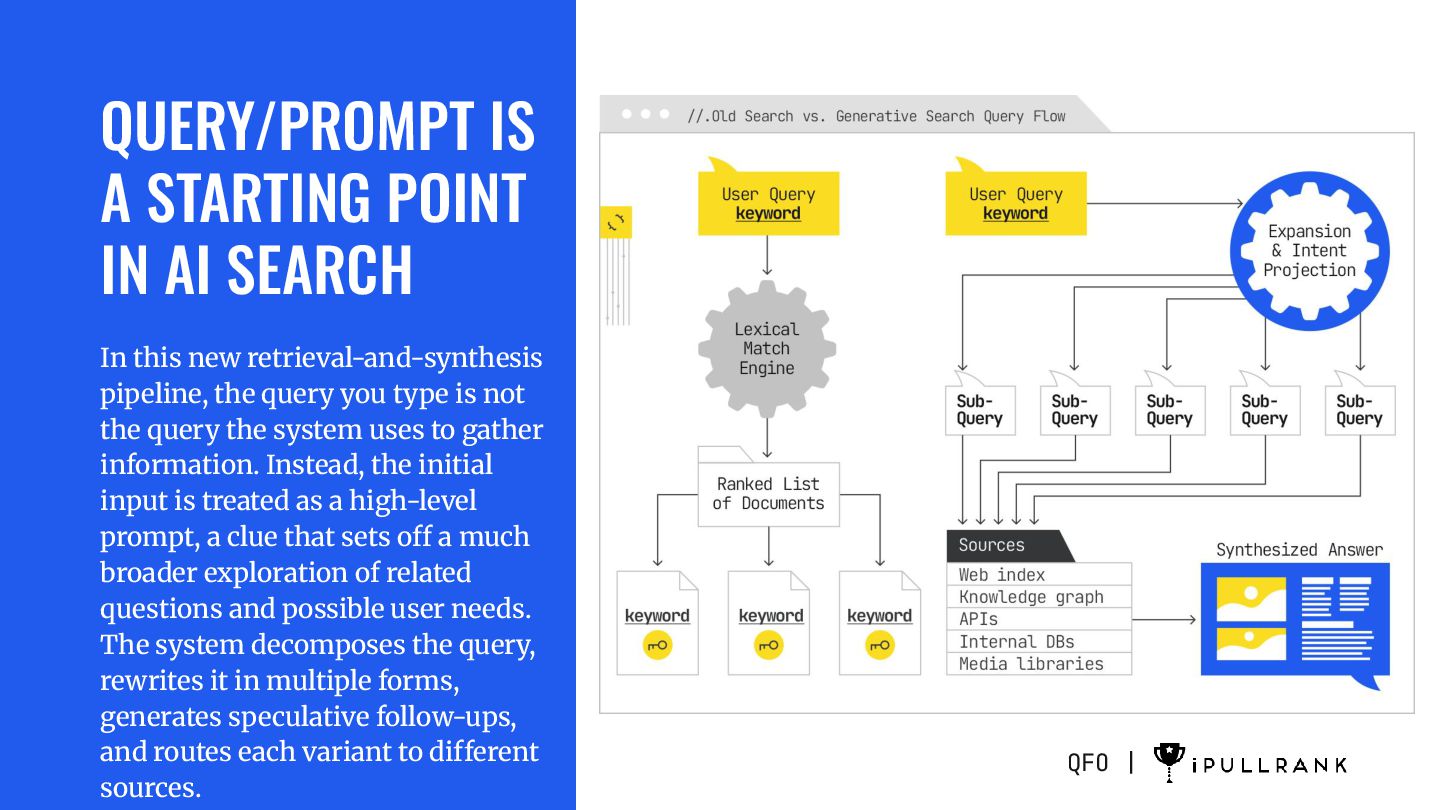
new retrieval-and-synthesis pipeline, the query you type is not the query the system uses to gather information. Instead, the initial input is treated as a high-level prompt, a clue that sets off a much broader exploration of related questions and possible user needs. The system decomposes the query, rewrites it in multiple forms, generates speculative follow-ups, and routes each variant to different sources. QFO |
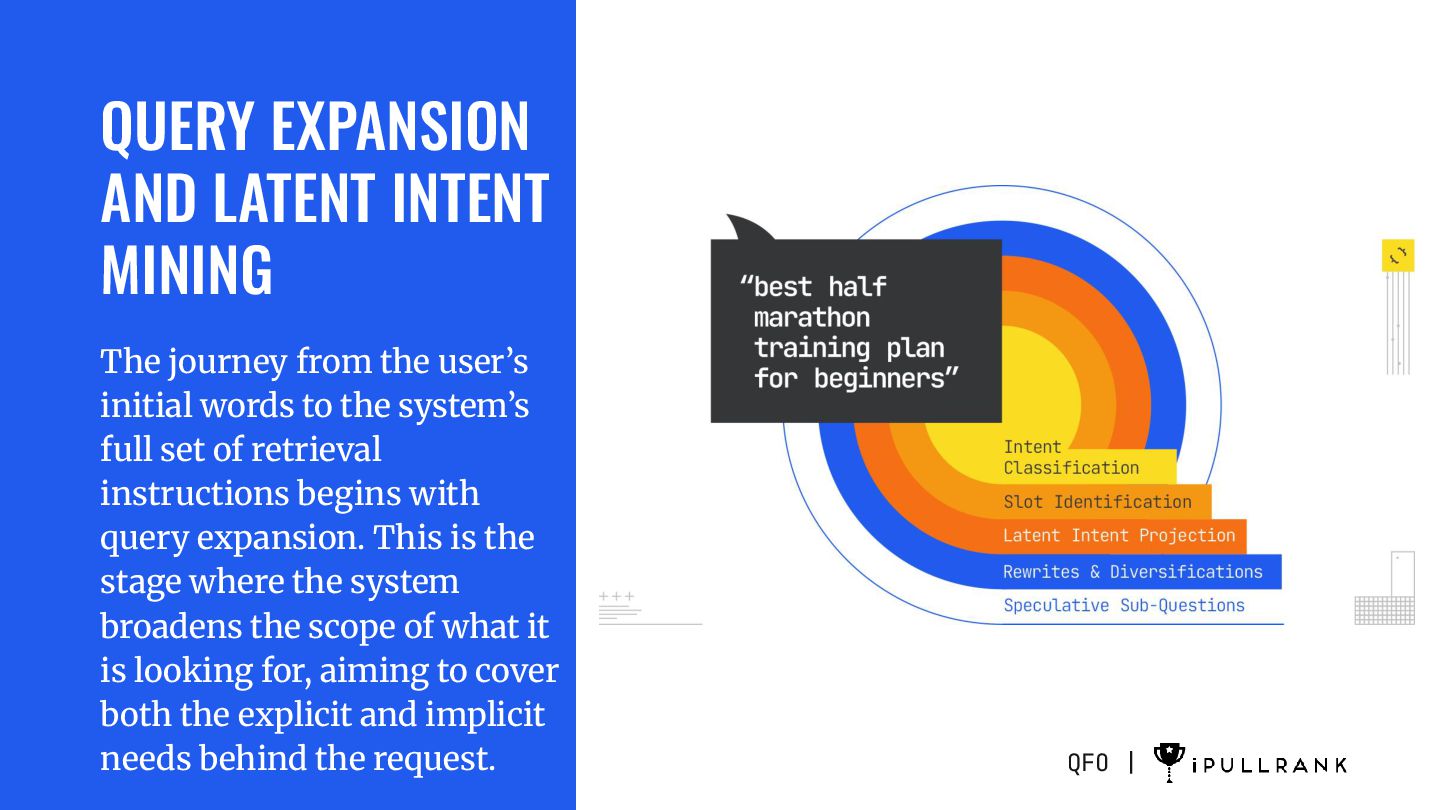
user’s initial words to the system’s full set of retrieval instructions begins with query expansion. This is the stage where the system broadens the scope of what it is looking for, aiming to cover both the explicit and implicit needs behind the request. QFO |
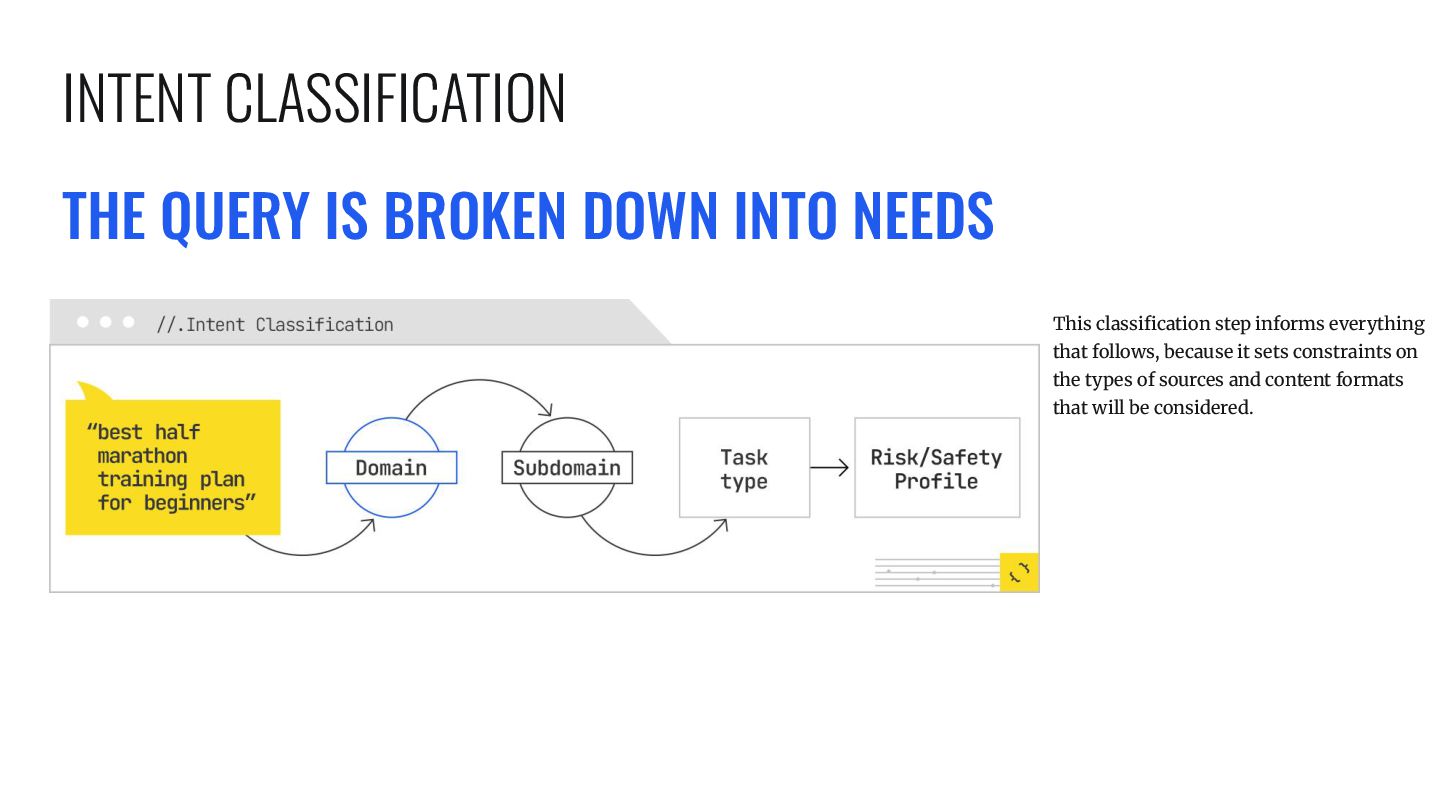
informs everything that follows, because it sets constraints on the types of sources and content formats that will be considered. INTENT CLASSIFICATION
expects to fill in order to produce a useful answer. Some slots are explicit. For example “half marathon” sets the distance, “beginners” sets the audience. Others are implicit. The system may want to know the available training timeframe, the runner’s current fitness level, age group, and goal (finish vs. personal record). These slots may not all be populated immediately, but knowing they exist allows the system to search for content that can fill them. SLOT IDENTIFICATION
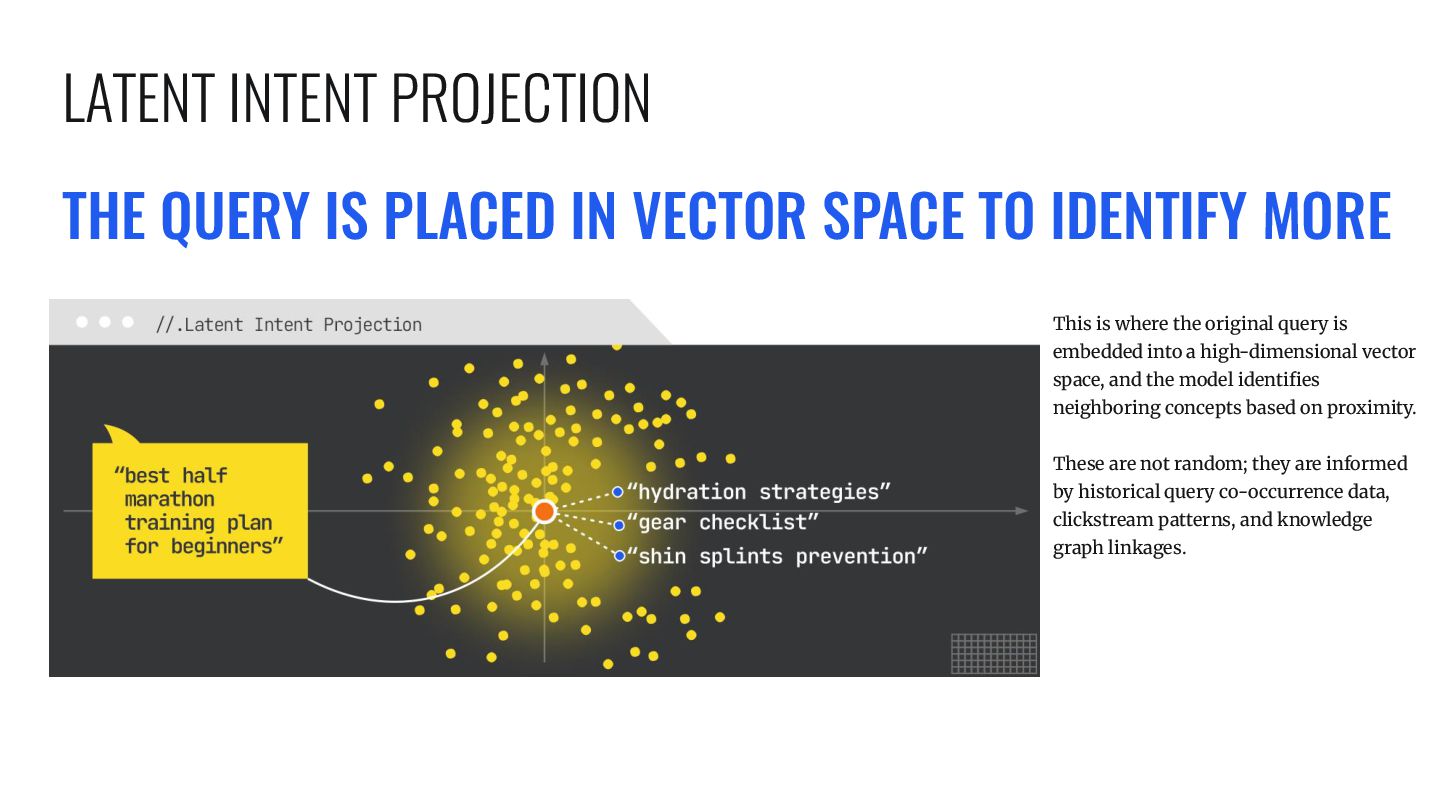
This is where the original query is embedded into a high-dimensional vector space, and the model identifies neighboring concepts based on proximity. These are not random; they are informed by historical query co-occurrence data, clickstream patterns, and knowledge graph linkages. LATENT INTENT PROJECTION
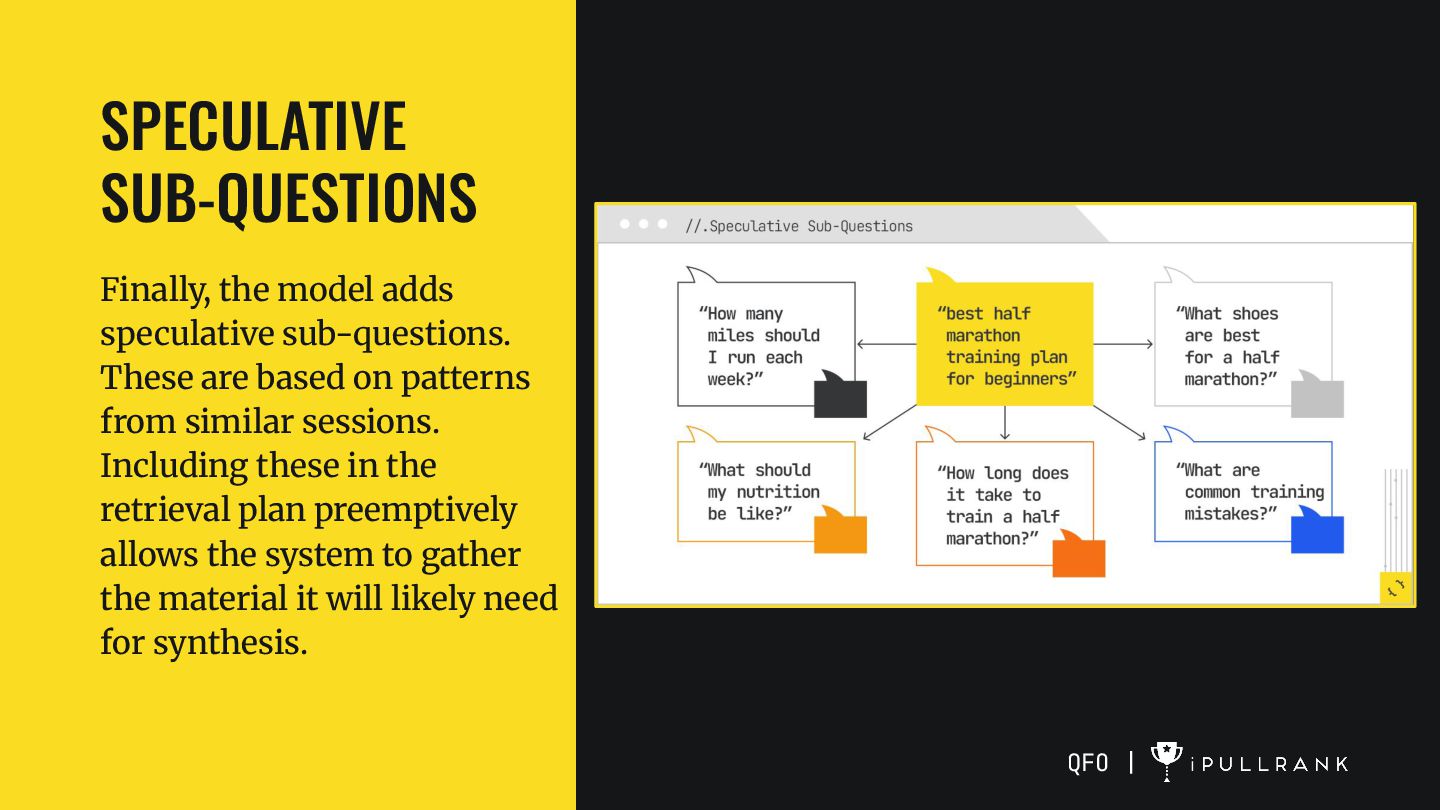
of the original query. These might include narrowing variations (“12-week half marathon plan for beginners over 40”) or format variations (“printable beginner half marathon schedule”). Each rewrite is designed to maximize the chance of finding a relevant content chunk that might not match the original phrasing.
based on patterns from similar sessions. Including these in the retrieval plan preemptively allows the system to gather the material it will likely need for synthesis. QFO |
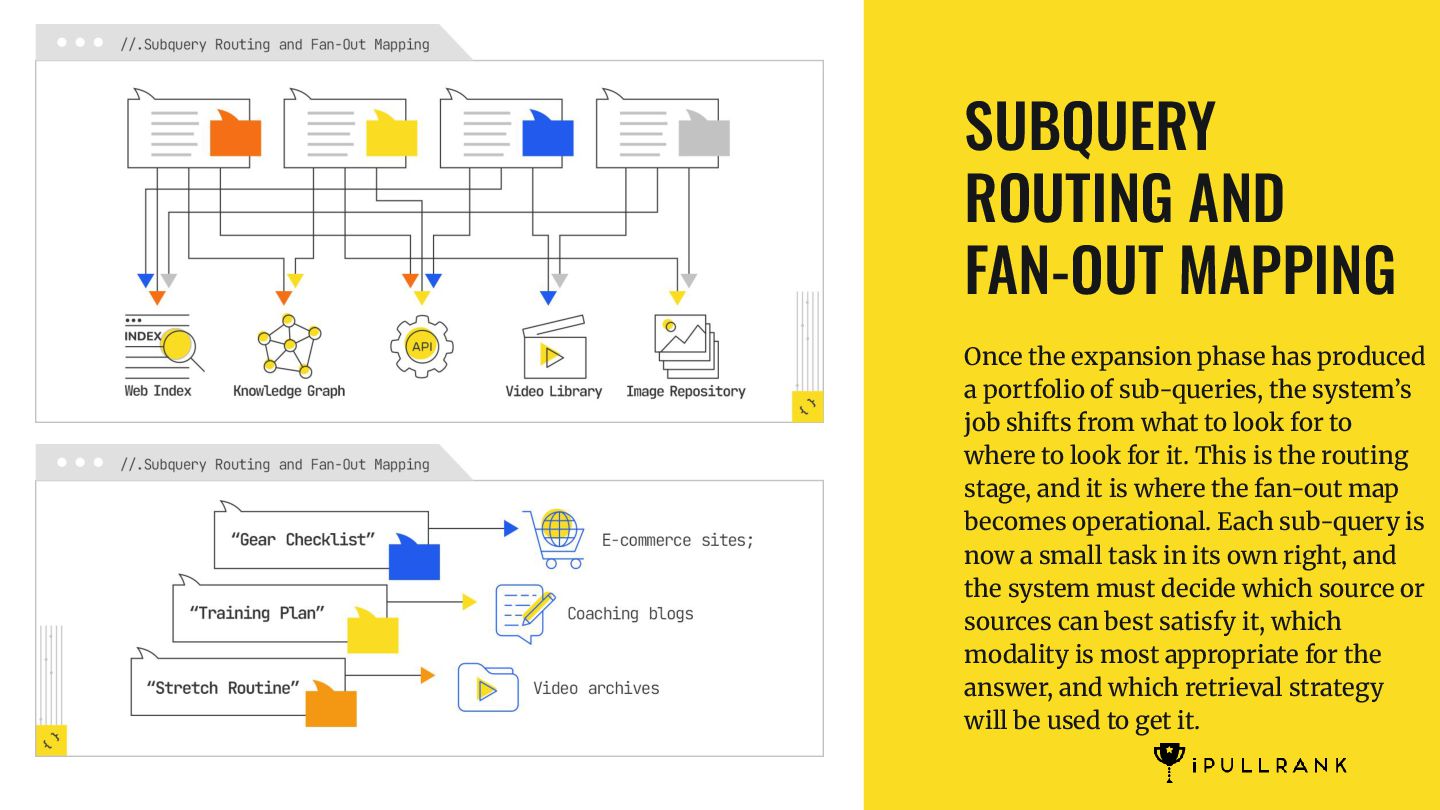
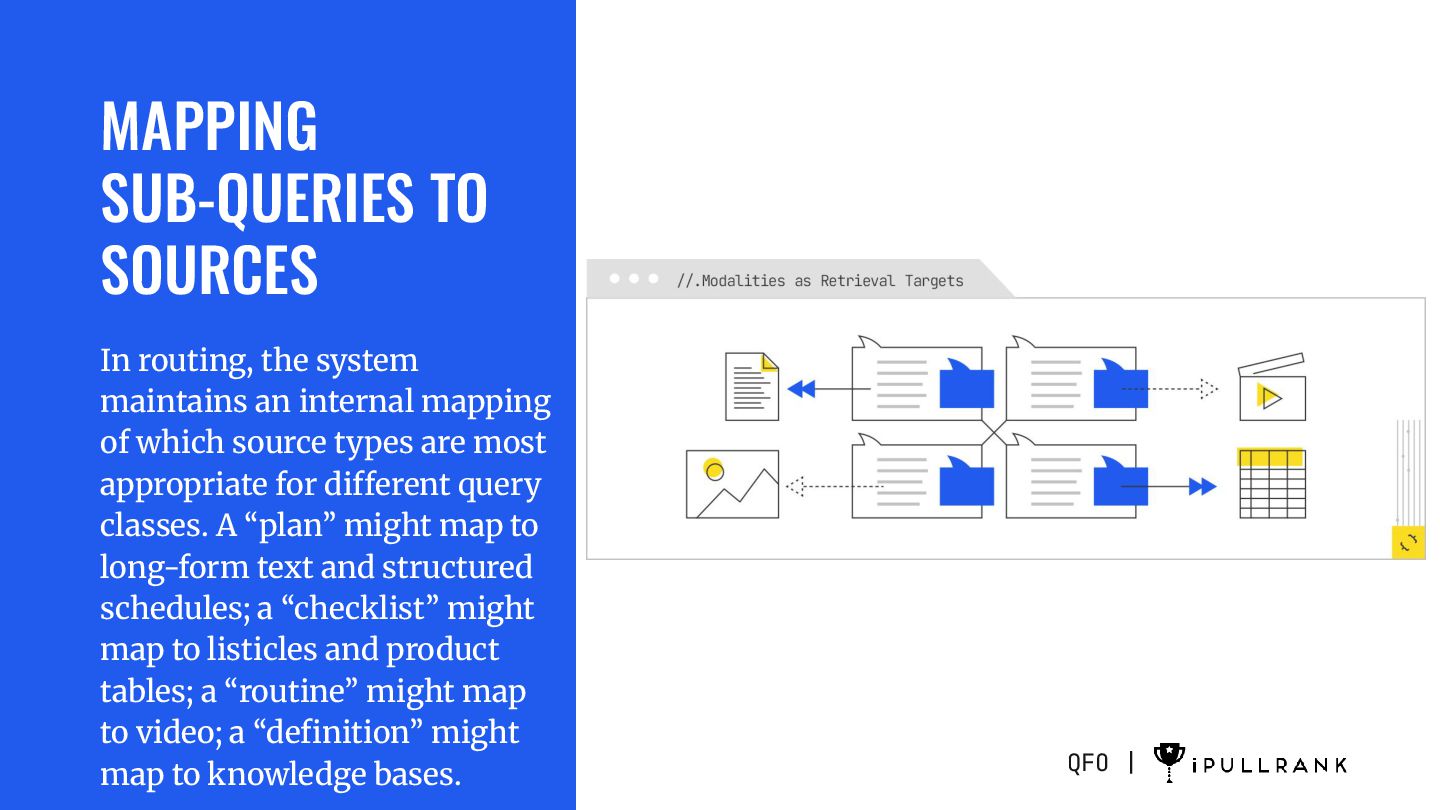
produced a portfolio of sub-queries, the system’s job shifts from what to look for to where to look for it. This is the routing stage, and it is where the fan-out map becomes operational. Each sub-query is now a small task in its own right, and the system must decide which source or sources can best satisfy it, which modality is most appropriate for the answer, and which retrieval strategy will be used to get it.
internal mapping of which source types are most appropriate for different query classes. A “plan” might map to long-form text and structured schedules; a “checklist” might map to listicles and product tables; a “routine” might map to video; a “definition” might map to knowledge bases. QFO |
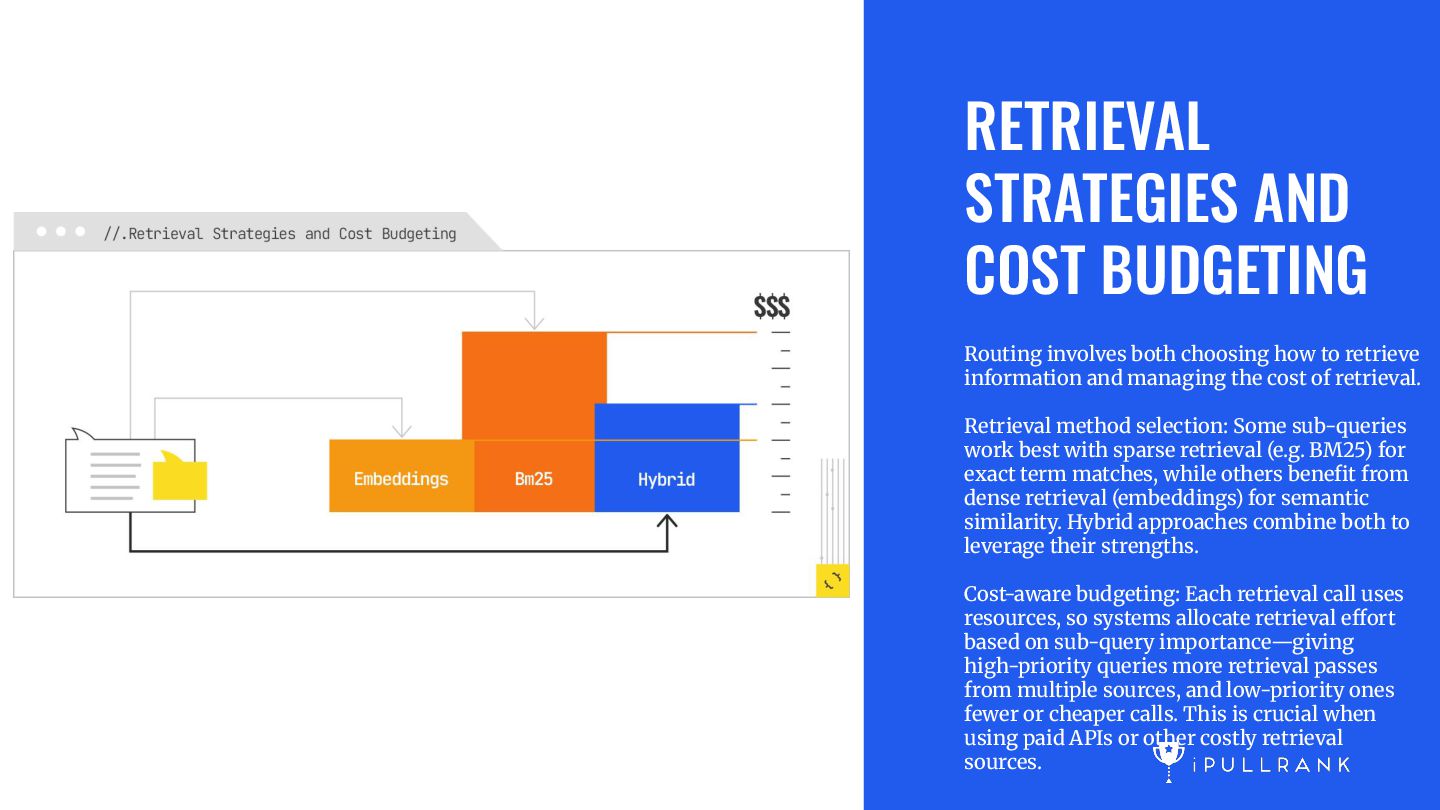
to retrieve information and managing the cost of retrieval. Retrieval method selection: Some sub-queries work best with sparse retrieval (e.g. BM25) for exact term matches, while others benefit from dense retrieval (embeddings) for semantic similarity. Hybrid approaches combine both to leverage their strengths. Cost-aware budgeting: Each retrieval call uses resources, so systems allocate retrieval effort based on sub-query importance—giving high-priority queries more retrieval passes from multiple sources, and low-priority ones fewer or cheaper calls. This is crucial when using paid APIs or other costly retrieval sources.
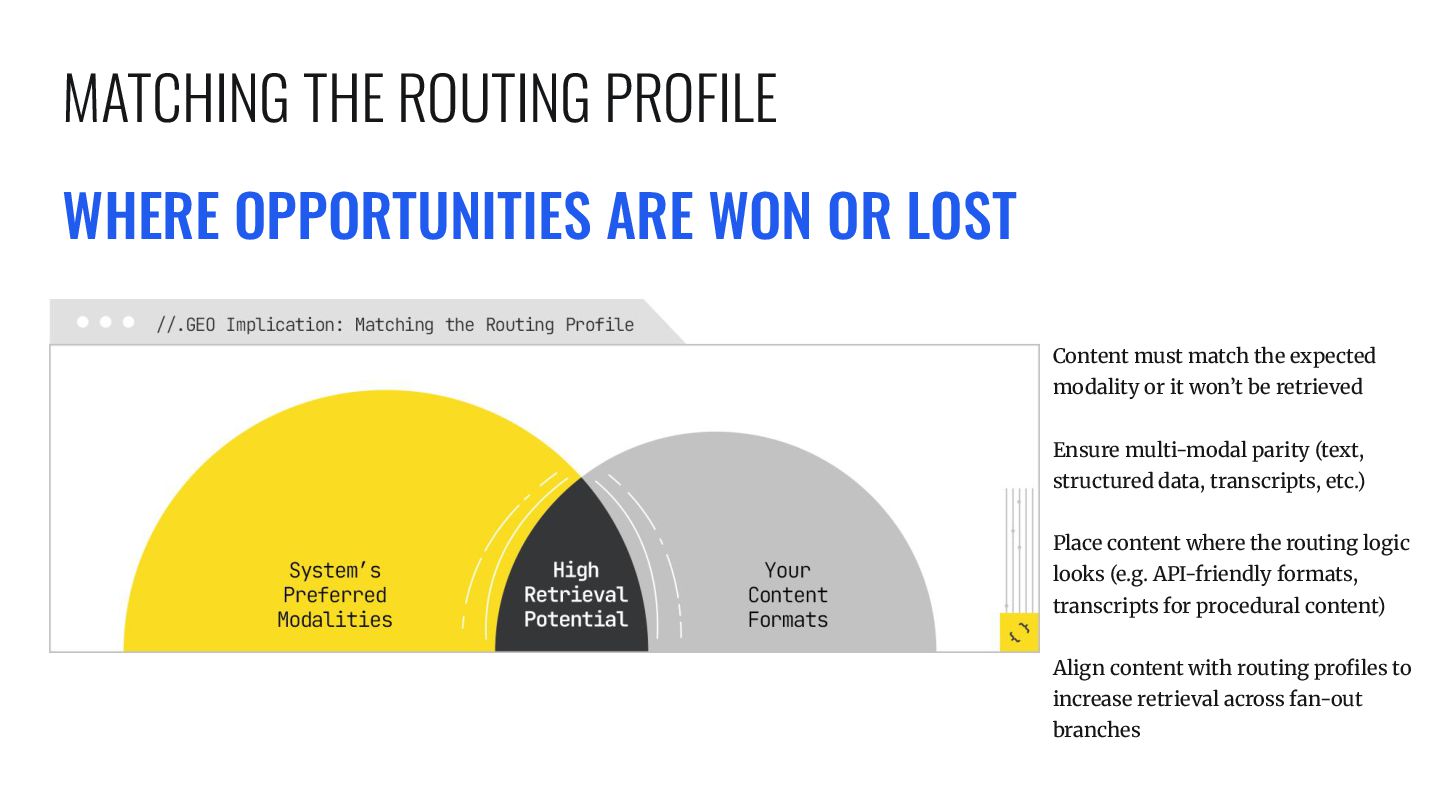
expected modality or it won’t be retrieved Ensure multi-modal parity (text, structured data, transcripts, etc.) Place content where the routing logic looks (e.g. API-friendly formats, transcripts for procedural content) Align content with routing profiles to increase retrieval across fan-out branches MATCHING THE ROUTING PROFILE
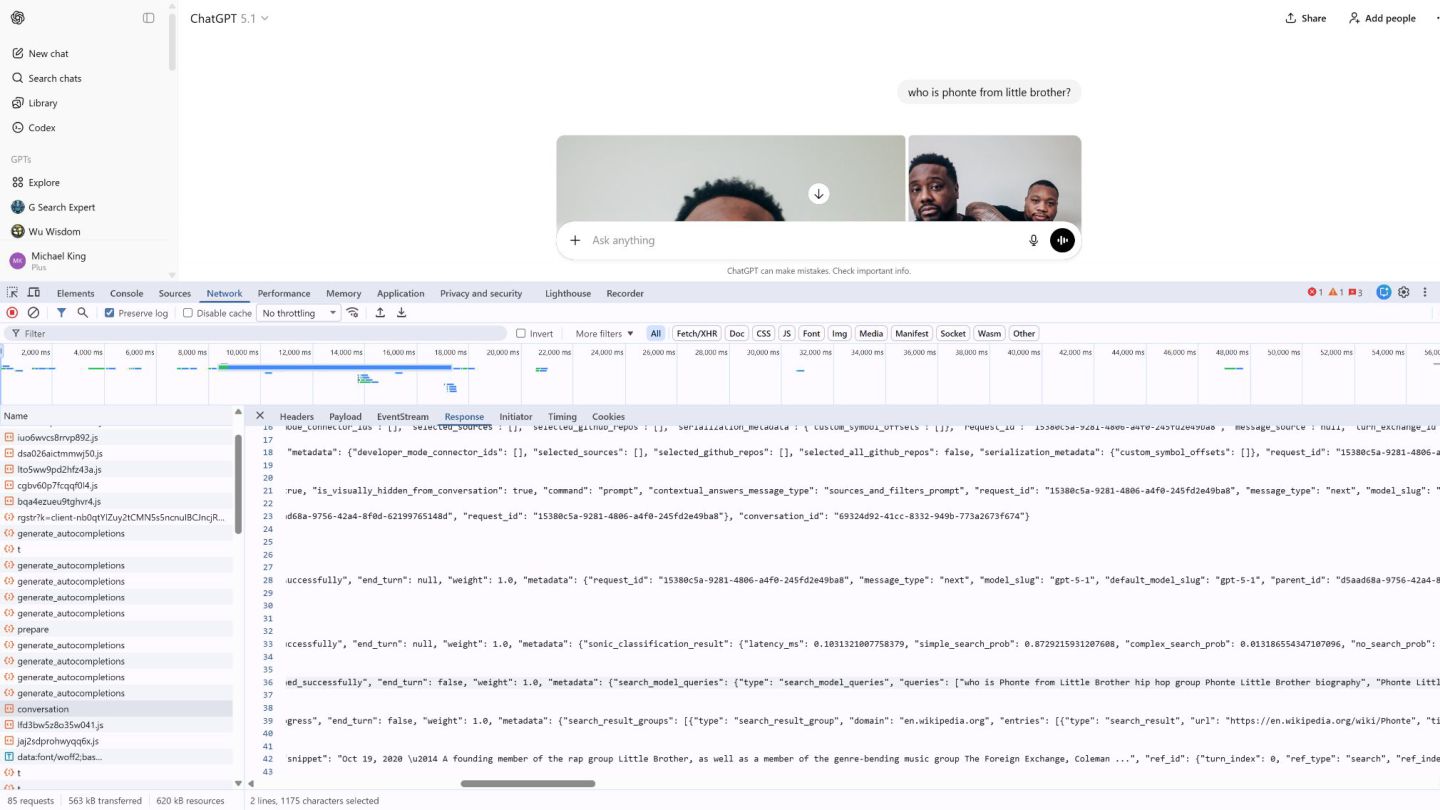
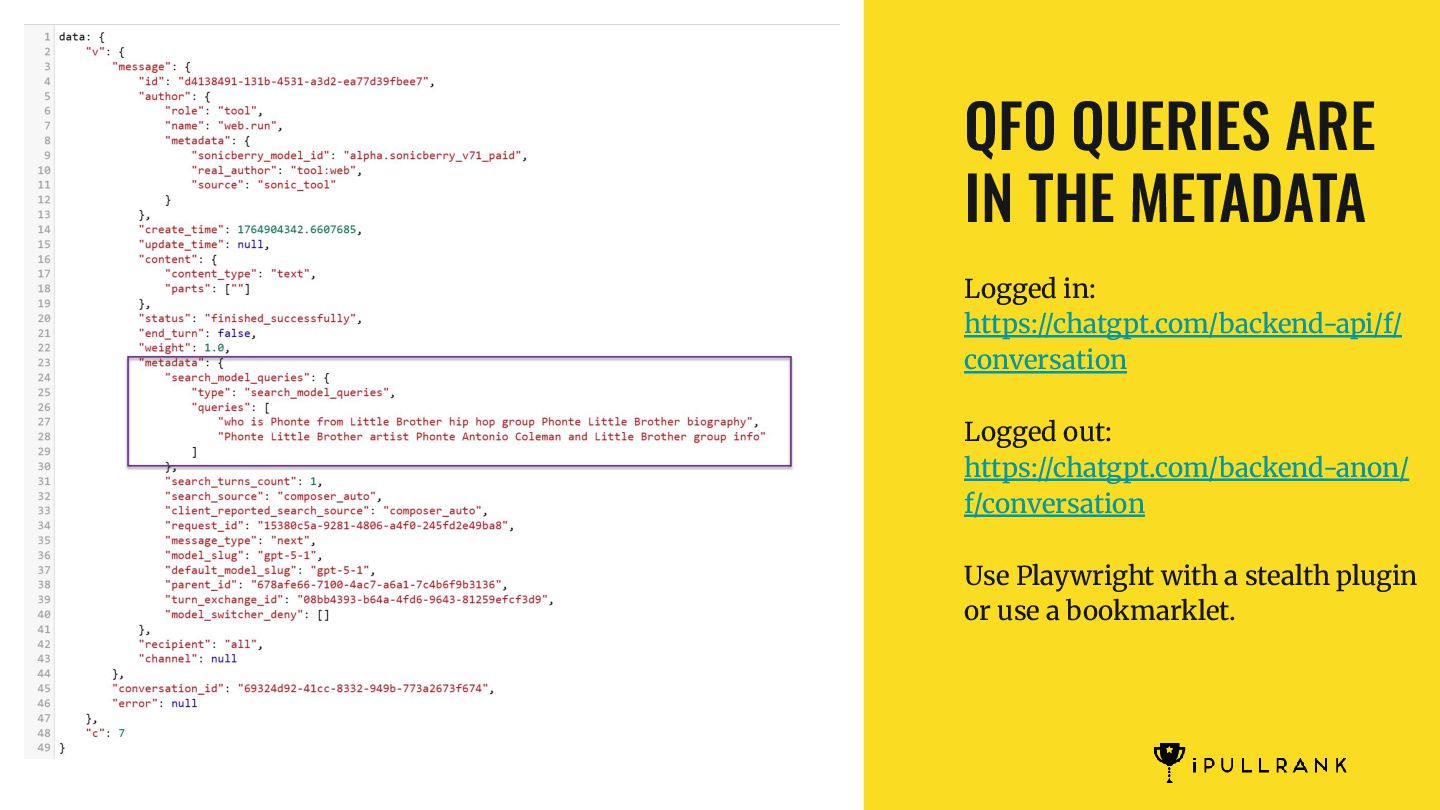
to see what results it used to inform the response, you can also extract that from the conversation endpoint. You can see the domain, URL, title, and snippet in the response.
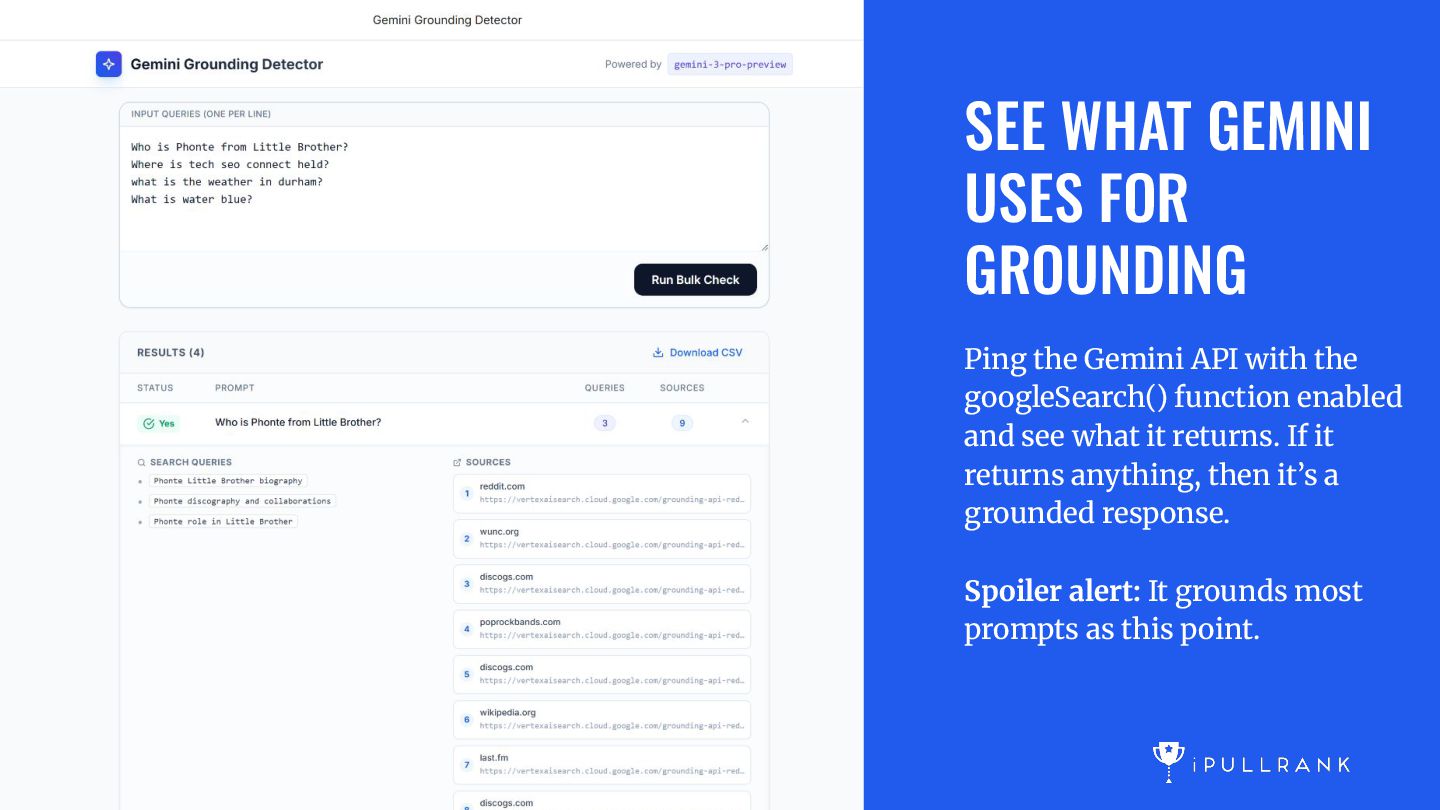
with the googleSearch() function enabled and see what it returns. If it returns anything, then it’s a grounded response. Spoiler alert: It grounds most prompts as this point.
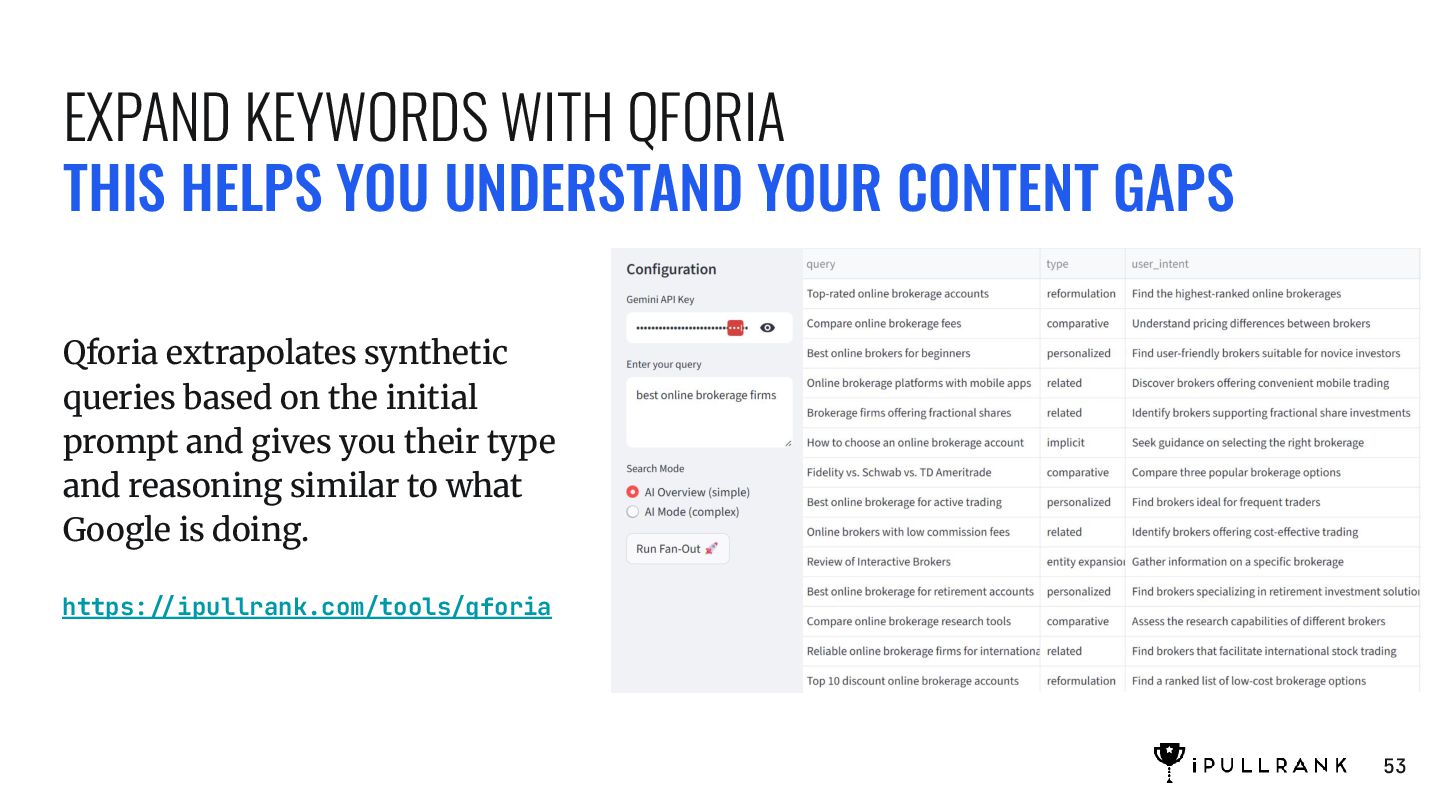
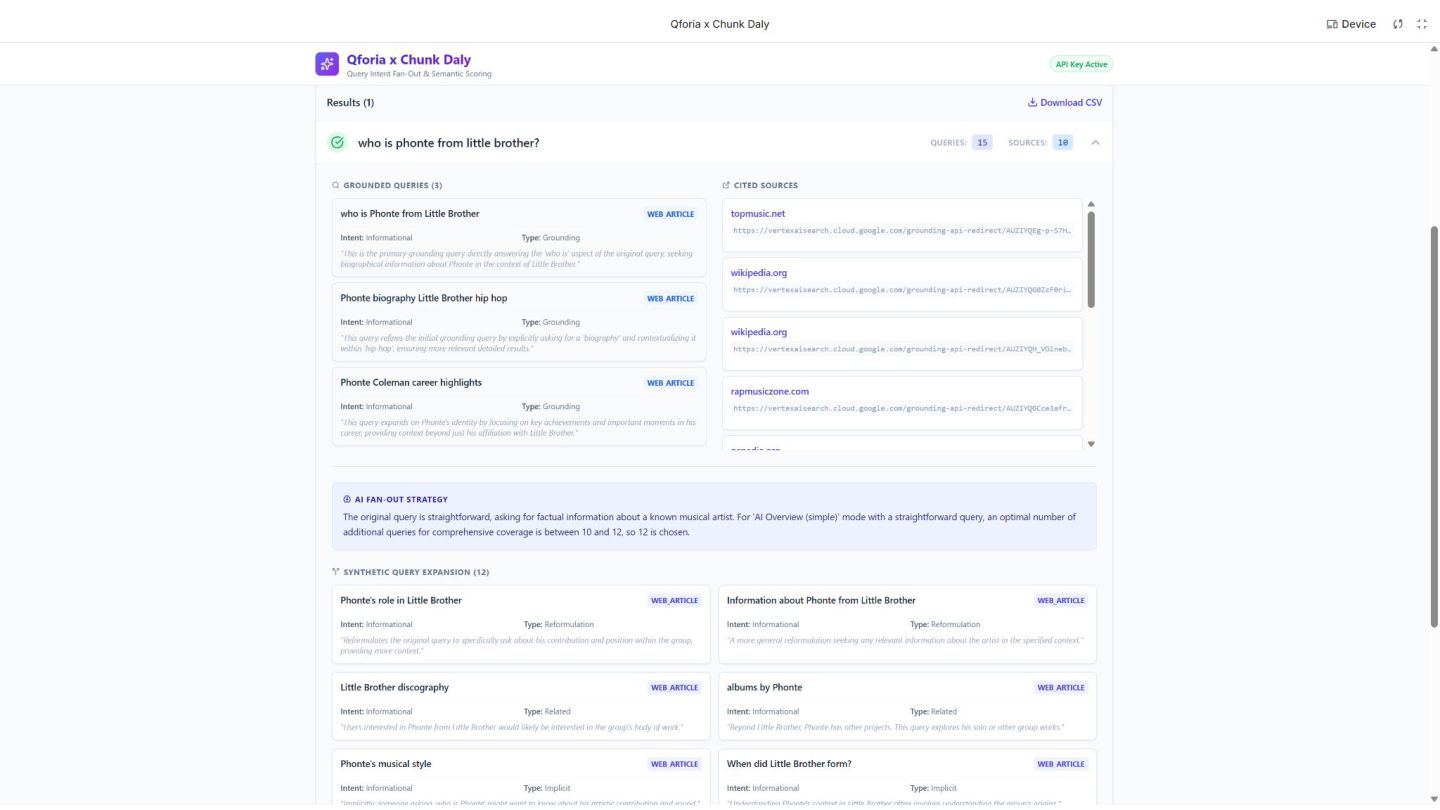
GAPS Qforia extrapolates synthetic queries based on the initial prompt and gives you their type and reasoning similar to what Google is doing. 53 https://ipullrank.com/tools/qforia
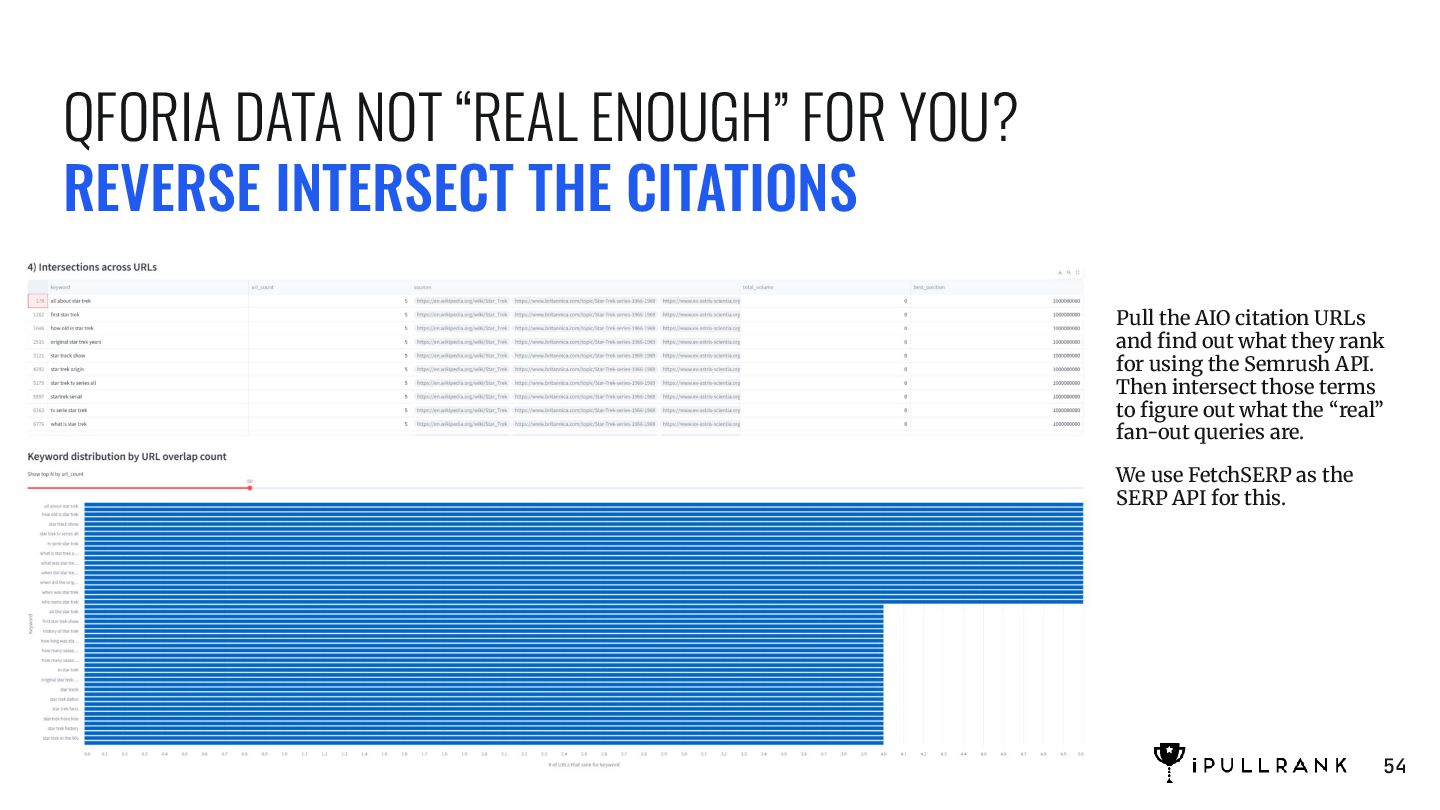
CITATIONS Pull the AIO citation URLs and find out what they rank for using the Semrush API. Then intersect those terms to figure out what the “real” fan-out queries are. We use FetchSERP as the SERP API for this. 54
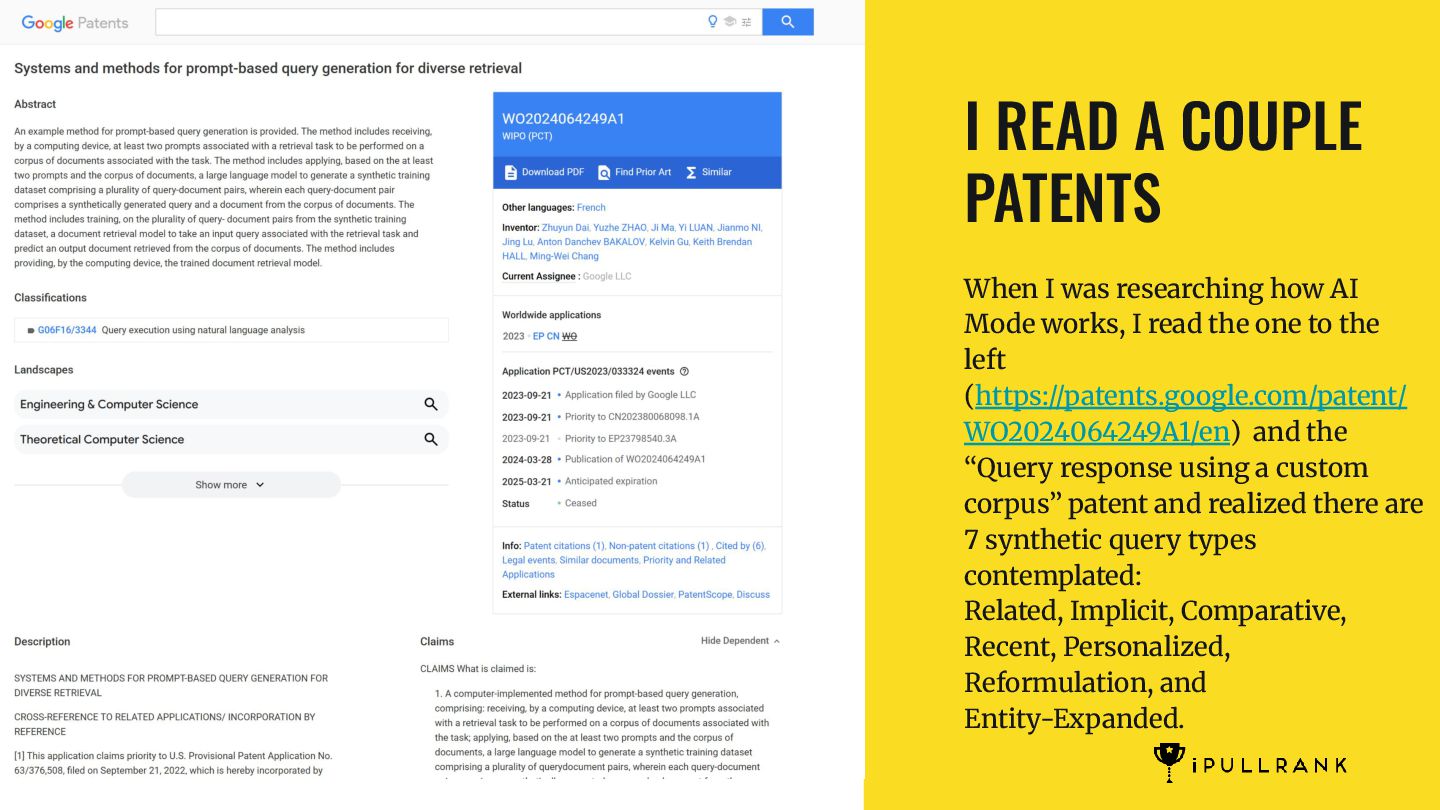
AI Mode works, I read the one to the left (https://patents.google.com/patent/ WO2024064249A1/en) and the “Query response using a custom corpus” patent and realized there are 7 synthetic query types contemplated: Related, Implicit, Comparative, Recent, Personalized, Reformulation, and Entity-Expanded.
Overviews or AI Mode, determines the number of prompts to generate, and gives a reason why it chose that number. FIRST WE DETERMINE HOW MANY PROMPTS WE WANT
types and gives reasons why. It specifically does not account for geolocation and does not attempt to account for user history. Then it returns the data as JSON. THEN IT SIMULATES THE QUERY FAN OUT AND
OF CONTENT PER TERM The concept of routing content is now used as part of the pipeline so it tells you the type of content Gemini would consider the best match for that subquery. 60
THOUGHTFUL AND ACTIONABLE FORK Tyler took it further with the comparison against the SERP, some cool visualizations, and some actionable advice on how to optimize your content. 65
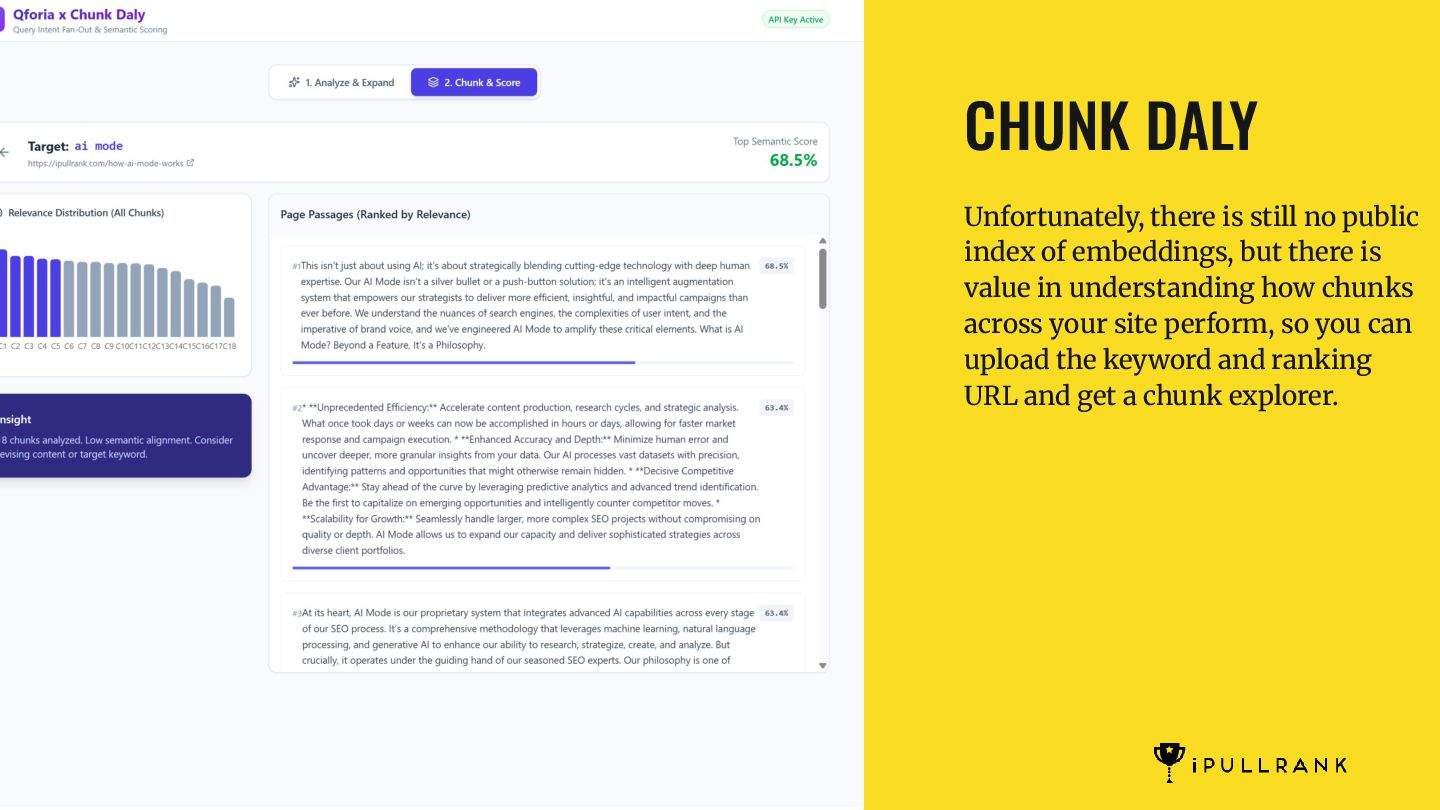
embeddings, but there is value in understanding how chunks across your site perform, so you can upload the keyword and ranking URL and get a chunk explorer.
FUNCTIONALITY TO QFORIA MarketBrew has a Content Booster tool that is what an SEO content editing tool should be. They both generate synthetic queries with Gemini and reverse intersect the rankings. 79
GENERATE CONTENT TO CLOSE THE GAP Content Booster allows you to automate the generation of content to close the semantic gaps between your content and your competitors based on the query fan out data. 80
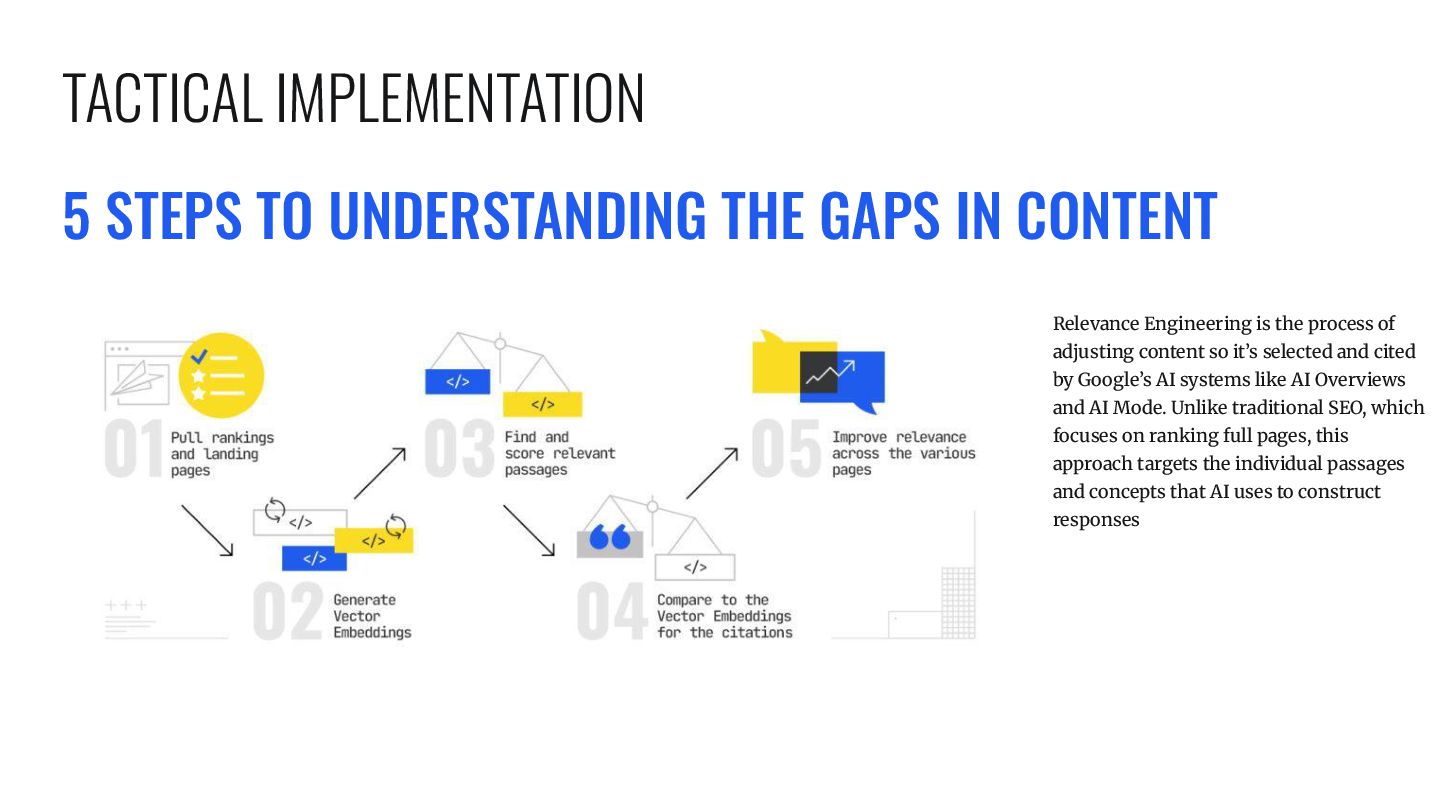
is the process of adjusting content so it’s selected and cited by Google’s AI systems like AI Overviews and AI Mode. Unlike traditional SEO, which focuses on ranking full pages, this approach targets the individual passages and concepts that AI uses to construct responses TACTICAL IMPLEMENTATION
consistent terminology Include modifiers and descriptors: Qualifiers like size, function, location, and purpose help differentiate similar entities. QFO |
modern retrieval systems, it’s essential to structure it in a way that is both machine-readable and human-friendly. Embedding models rely on clean, well-defined “chunks” or semantic units of information to generate precise and relevant results. QFO |
BE USED Metehan figured out from testing Google’s Discovery Engine API that chunks can be up to 500 tokens and can include the preceding header hierarchy to inform topical context. Source: https://metehan.ai/blog/reverse-engineerin g-google-ai-mode/ 89
tool that scores passages of content in a layout aware format. This will improve your ability to be considered and extracted. 90 https://ipullrank.com/tools/relevance-doctor
organized into easily defined sections. Headings and subheadings should be clear, and passages should answer queries directly and succinctly. The combination of query/passage is defined as a semantic unit, and these units are used to power AI search. QFO |
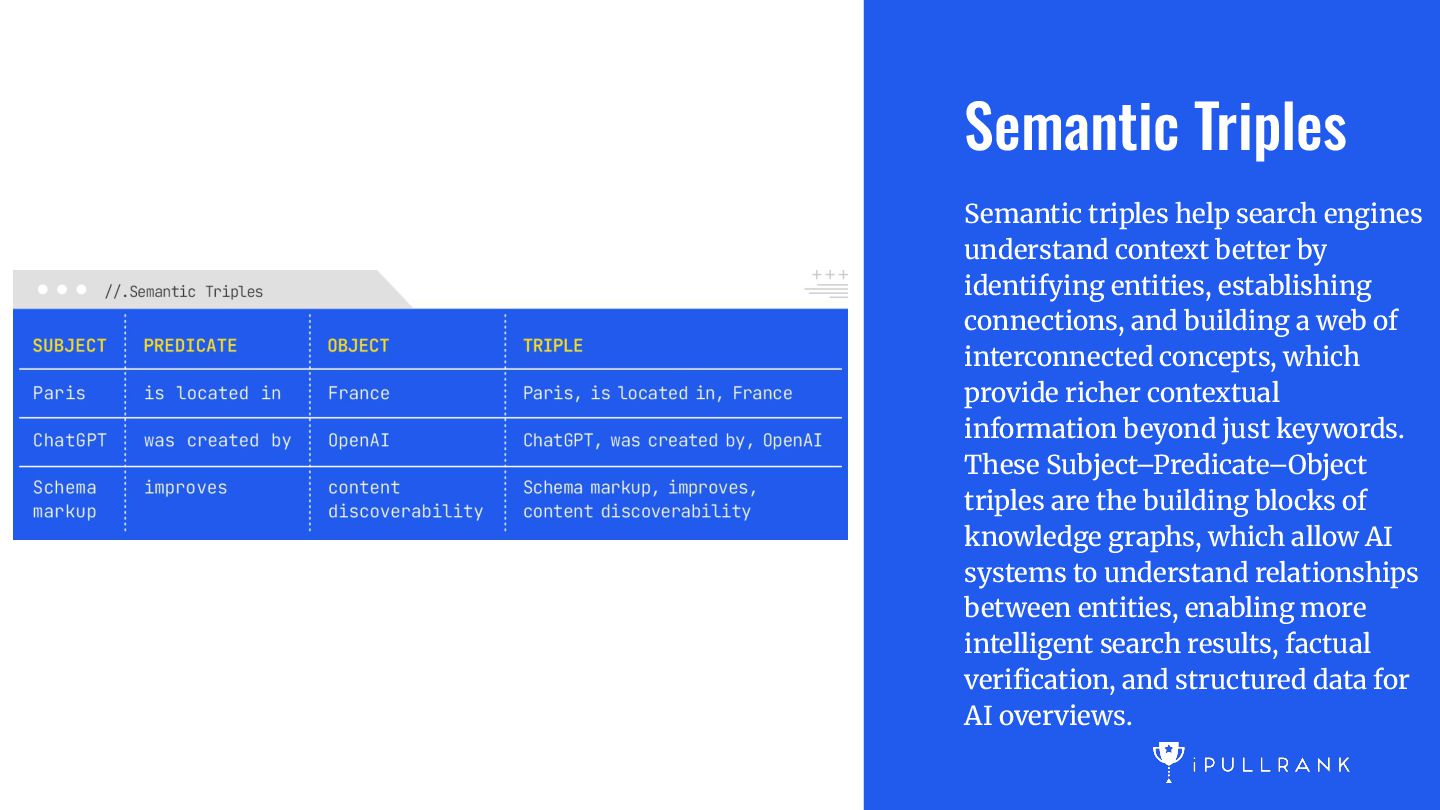
by identifying entities, establishing connections, and building a web of interconnected concepts, which provide richer contextual information beyond just keywords. These Subject–Predicate–Object triples are the building blocks of knowledge graphs, which allow AI systems to understand relationships between entities, enabling more intelligent search results, factual verification, and structured data for AI overviews.
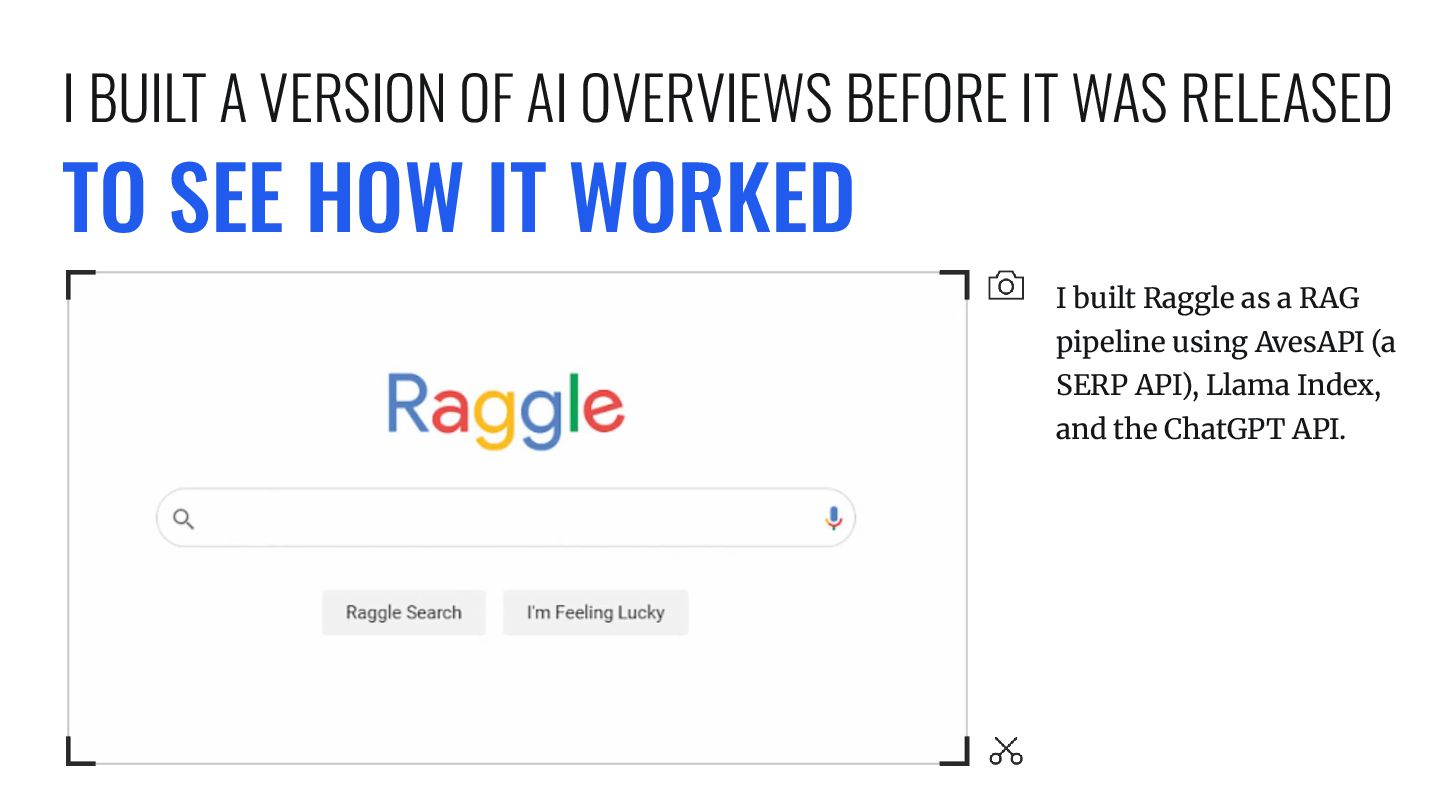
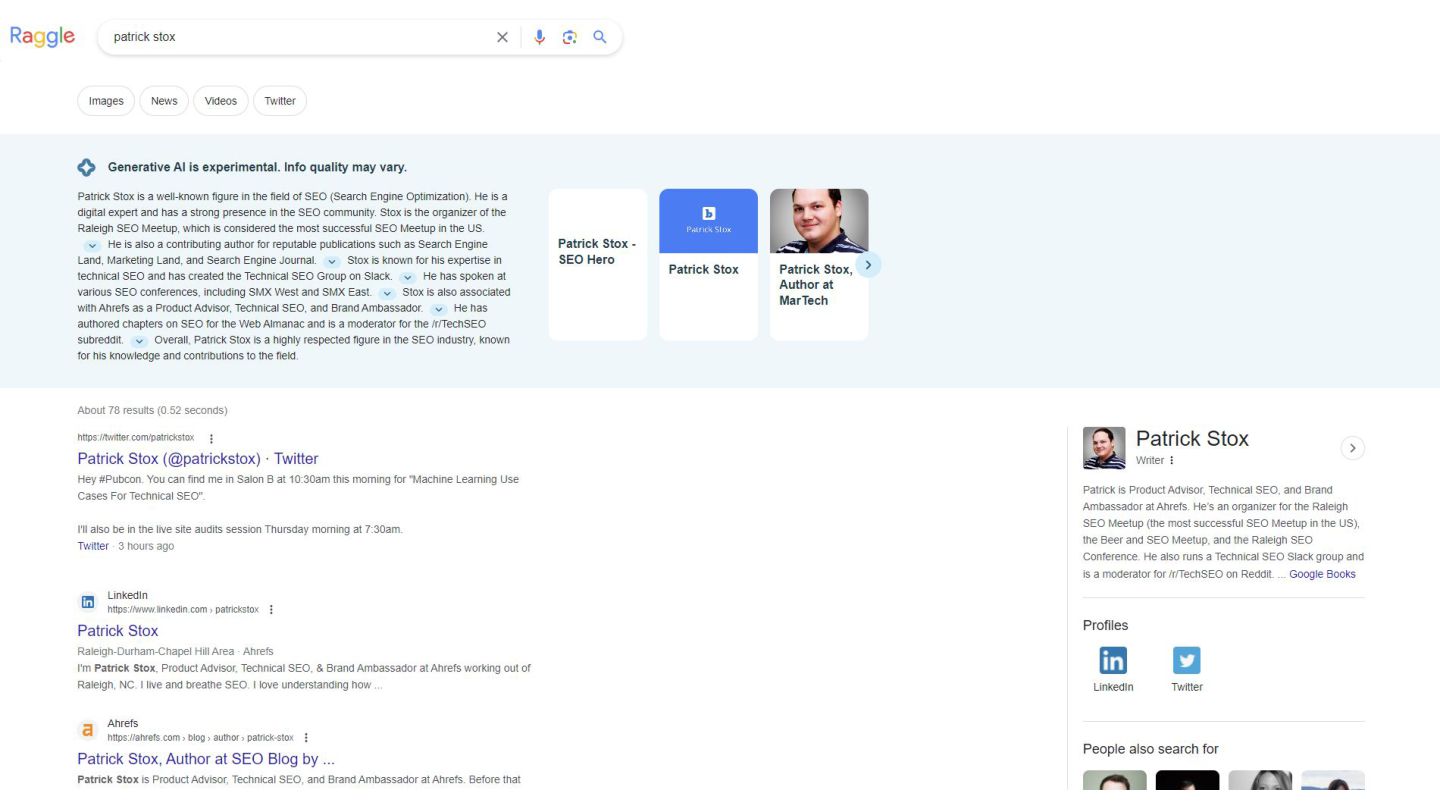
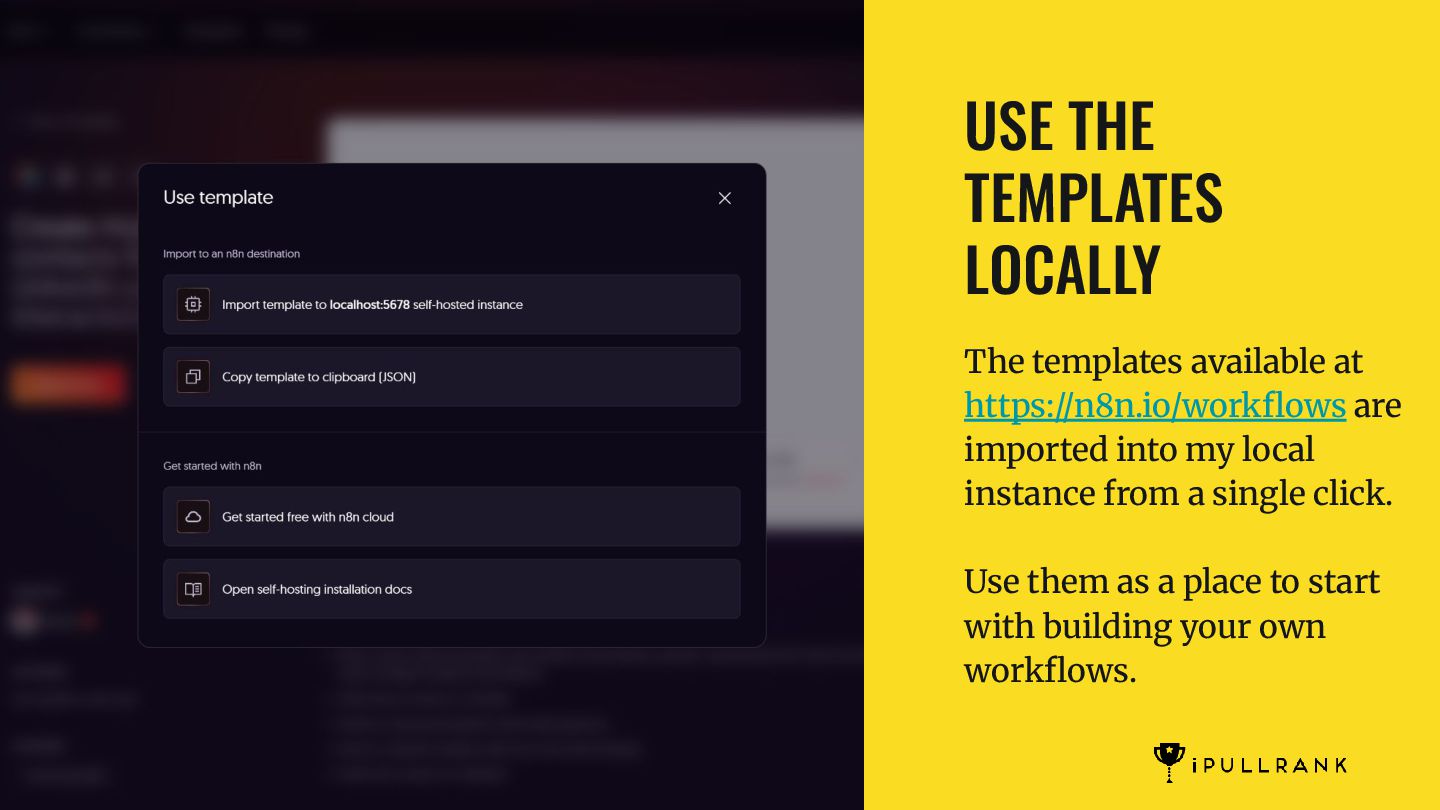
an AI Overview simulator that runs a RAG pipeline and takes updated content to see what would be returned. It also makes recommendations on what to do in order to improve the retrievability. With so much being open source, there is no reason that all SEO software companies cannot offer something similar. MarketBrew is a company that focuses on this idea across SEO generally. SIMULATE YOUR RANKINGS BASED ON CHANGES
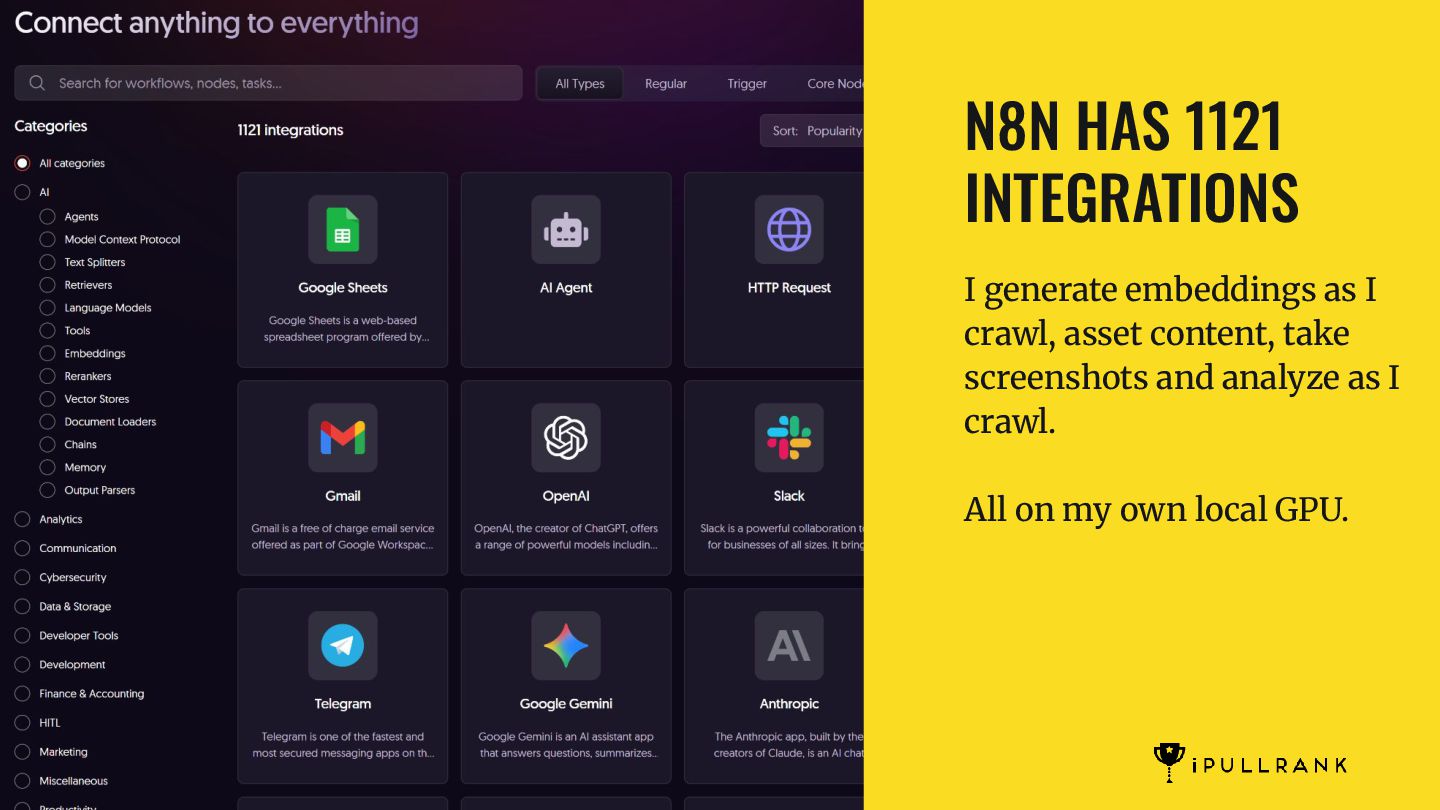
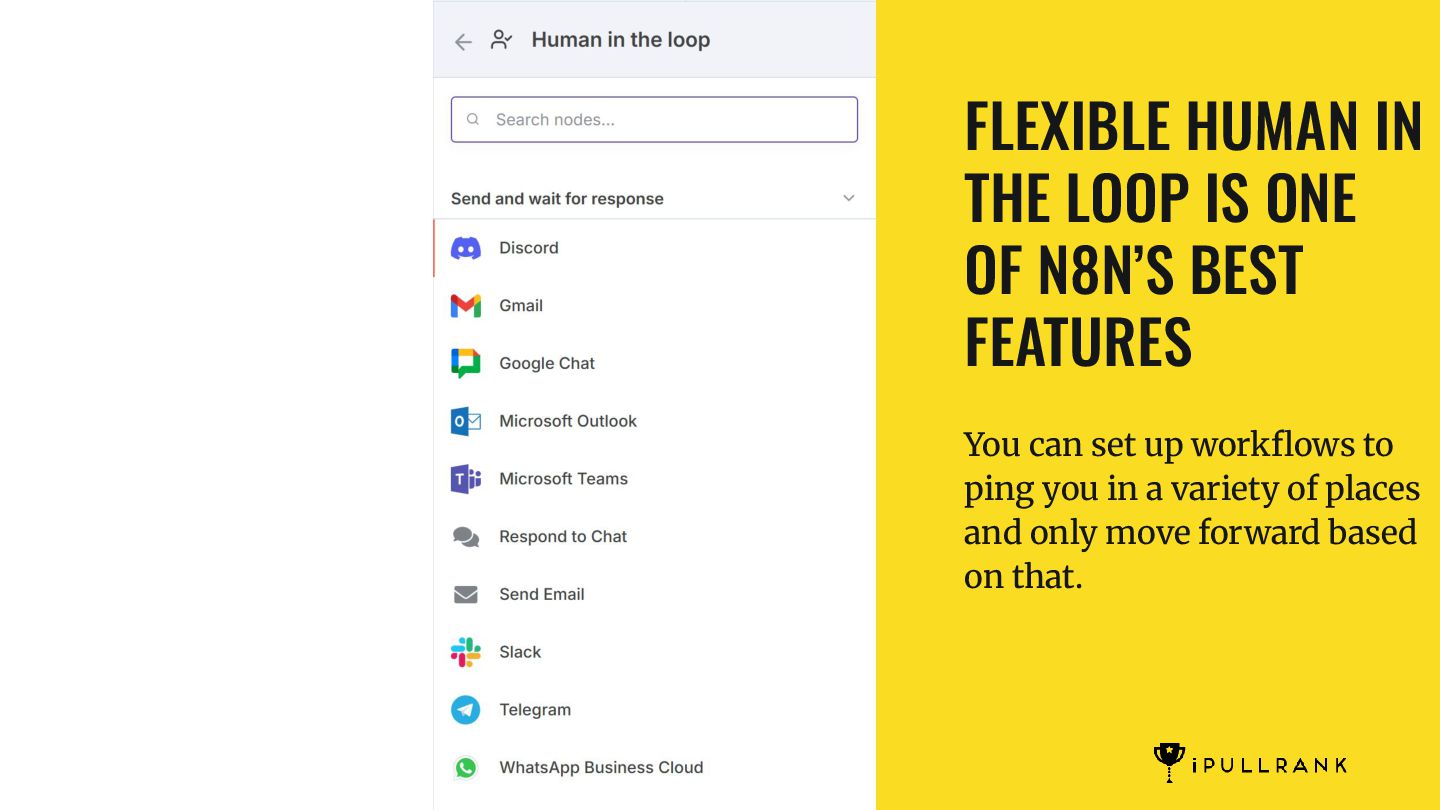
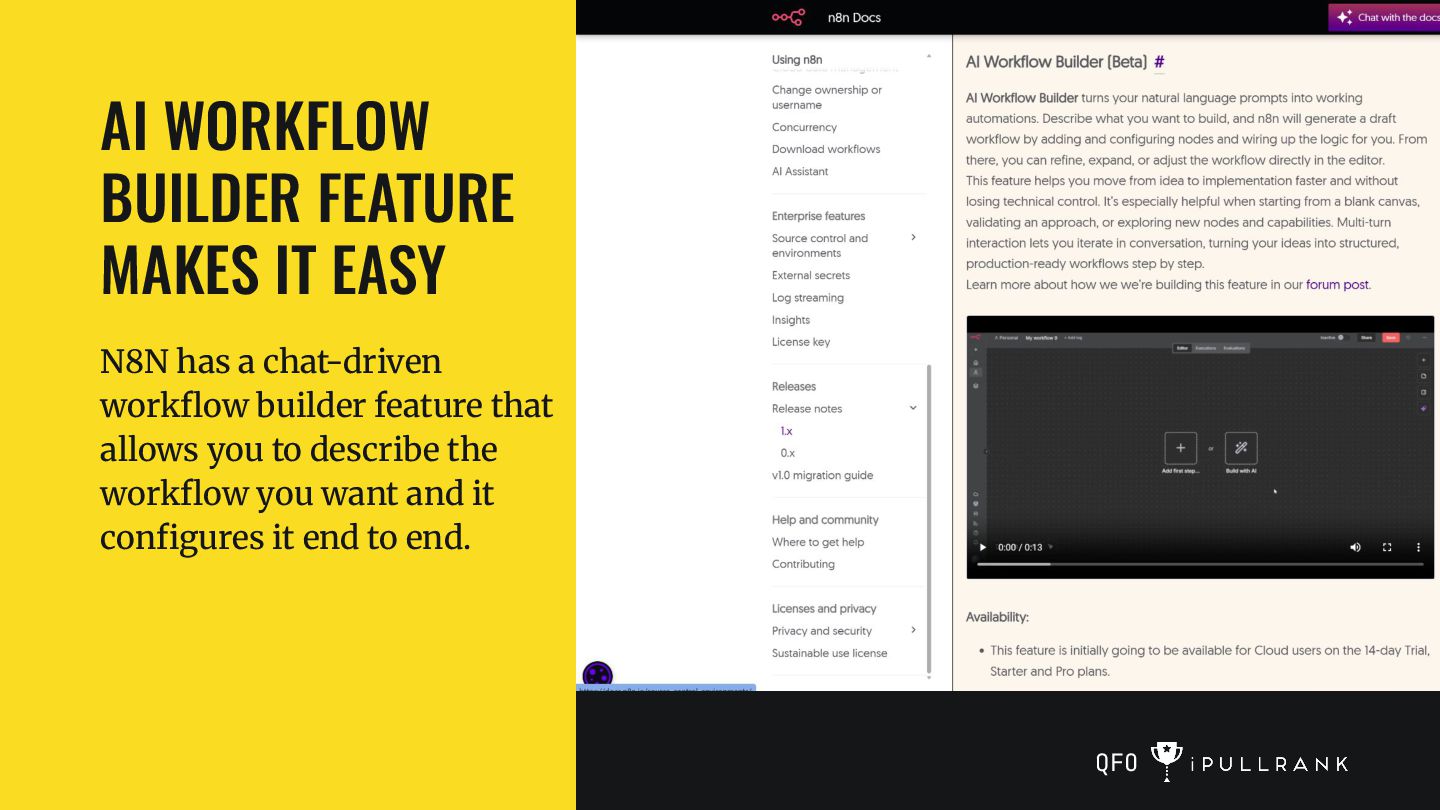
simulator that runs a RAG pipeline and takes updated content to see what would be returned. It also makes recommendations on what to do in order to improve the retrievability. With so much being open source, there is no reason that all SEO software companies cannot offer something similar. MarketBrew is a company that focuses on this idea across SEO generally. N8N IS A MUST HAVE TO CLOSE THE GAPS
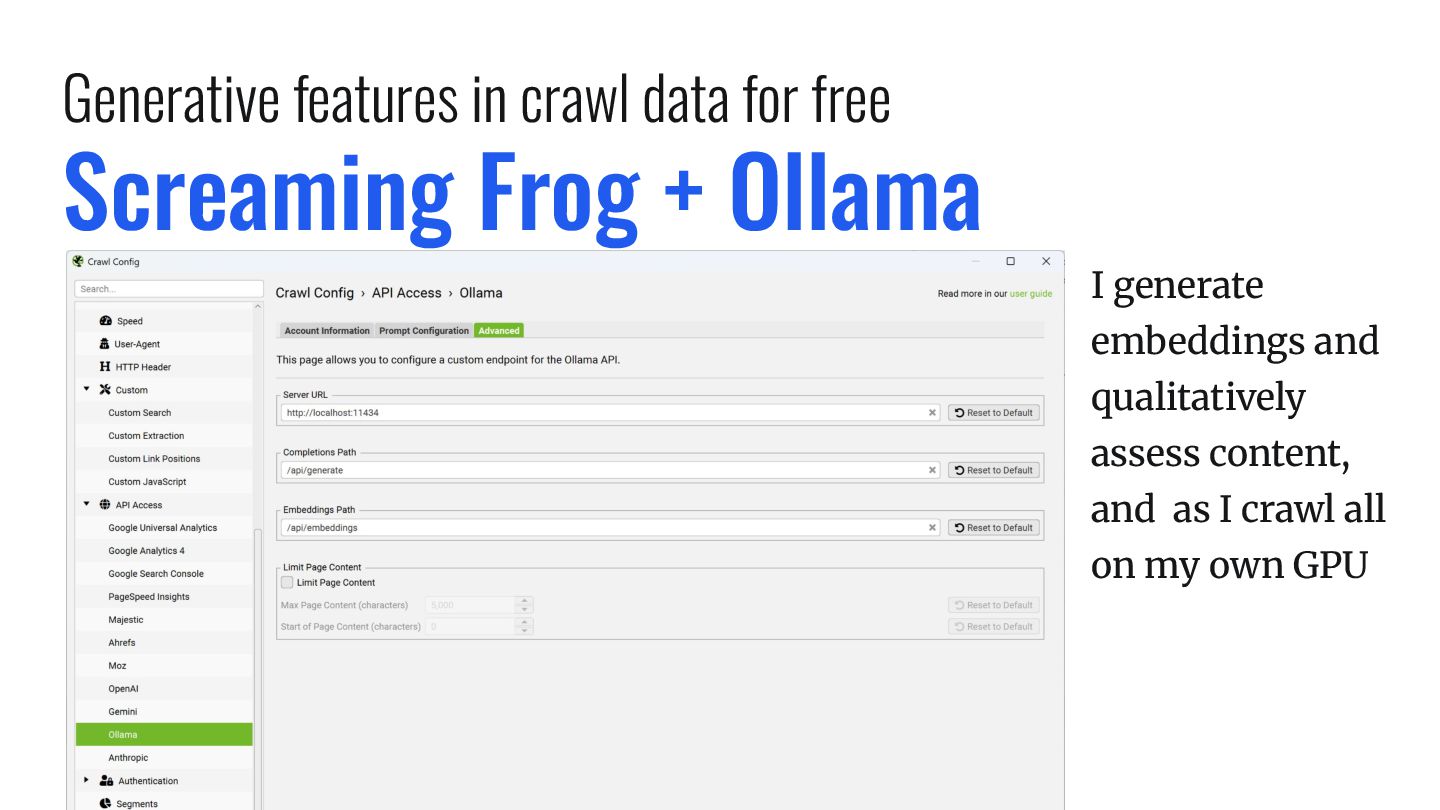
open source models. I use it for pretty much everything y’all use the closed models for unless I need fidelity with Google. https://ollama.com No Code, All Flow |
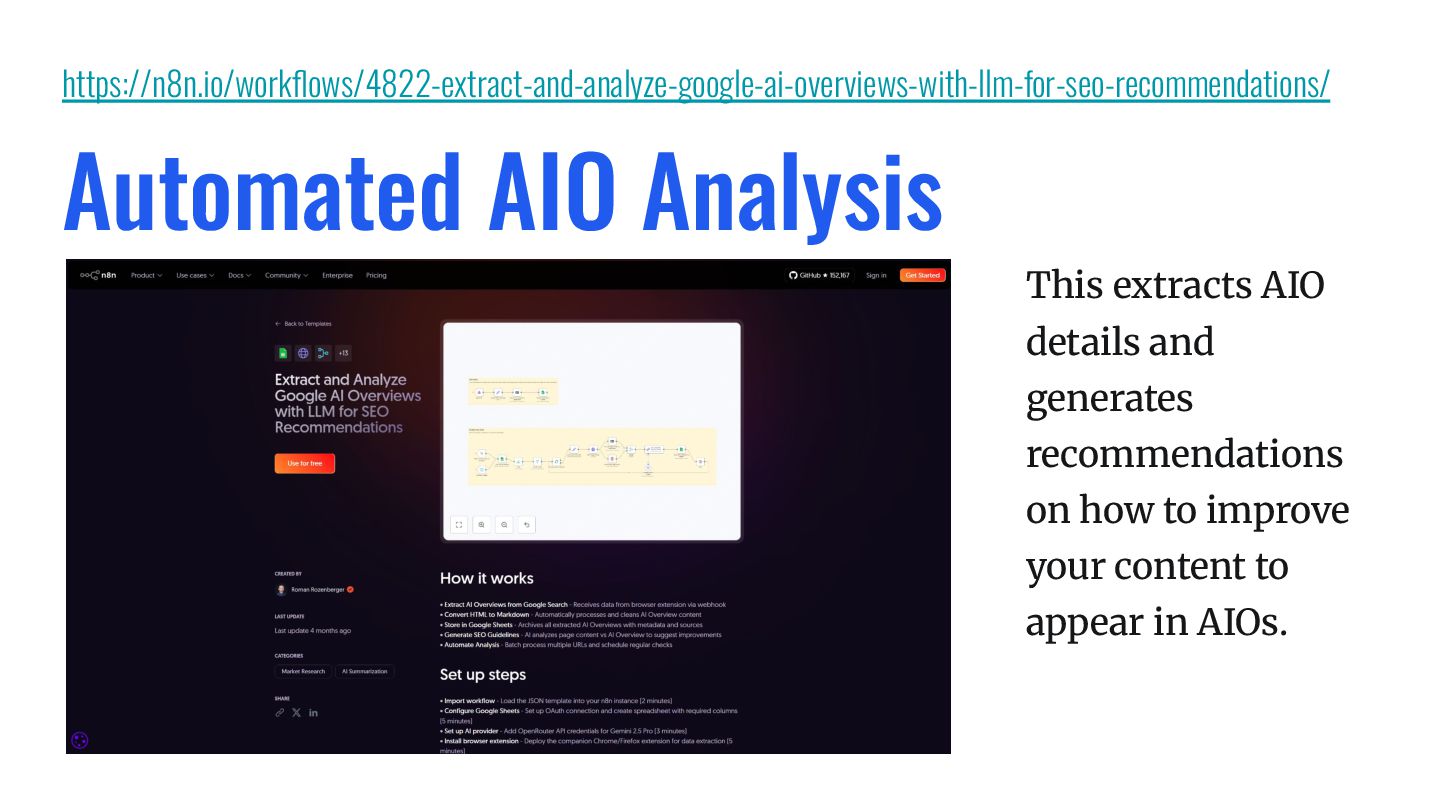
on how to improve your content to appear in AIOs. https://n8n.io/workflows/4822-extract-and-analyze-google-ai-overviews-with-llm-for-seo-recommendations/
as a cloud-based application or open source. You can code your agents from scratch or describe what you want in the chat interface and quickly develop a series of agents to help you scale you work. https://www.crewai.com IF YOU’RE CONSIDERING AGENTS CHECK OUT CREW.AI
Learn how the systems work so you can discover new opportunities It will take more than SEO to get you visibility in the future Search technology and behavior has changed irrevocably. Most of your SEO tools will not help you get where you need to go. This is an opportunity to define the future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mike King Founder / CEO @iPullRank [email protected] Tap in with](https://files.speakerdeck.com/presentations/4d2f7ab5c5f64d098ca46d2d68e13ad1/slide_120.jpg){kind=link}
{kind=link}