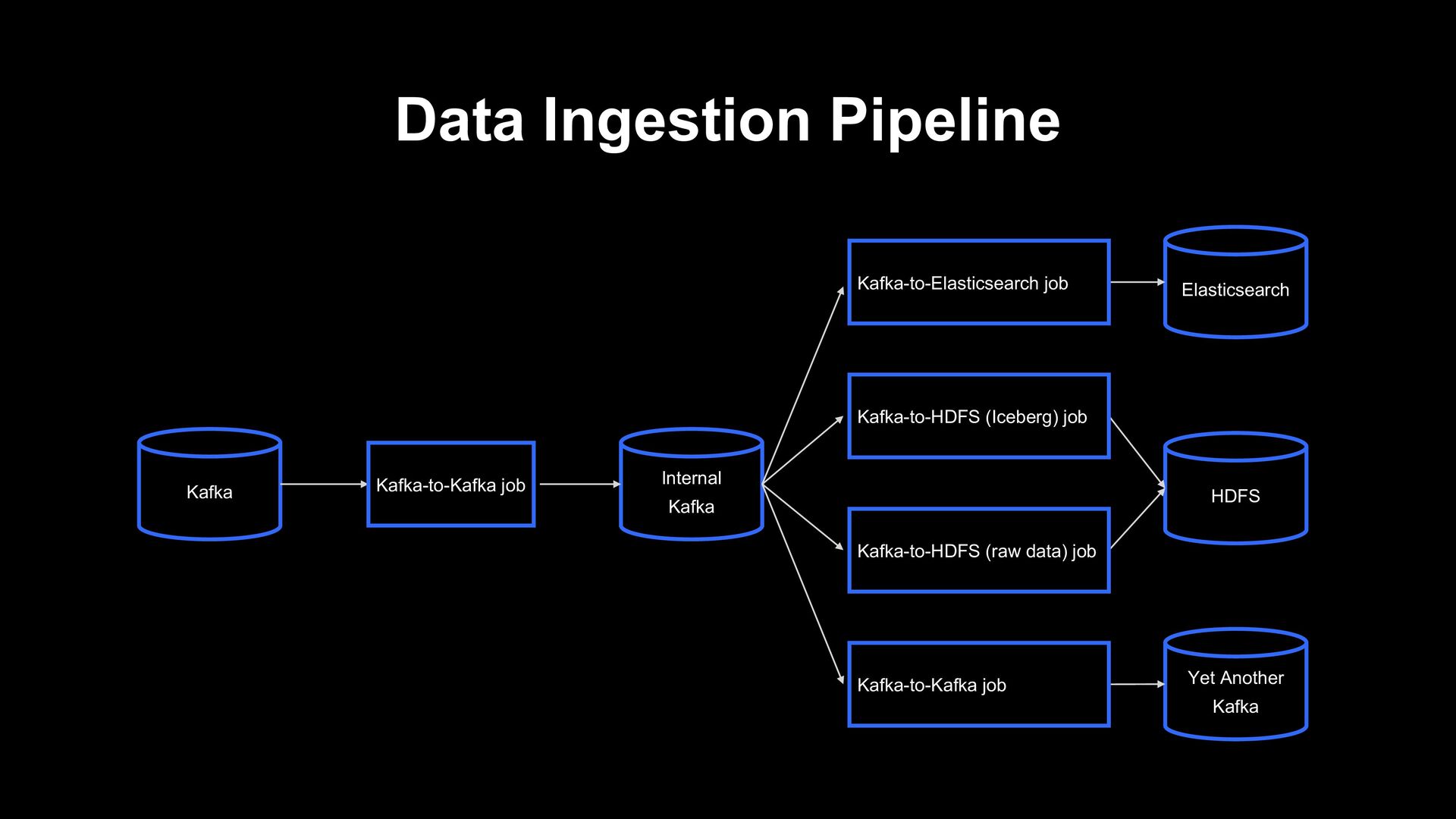
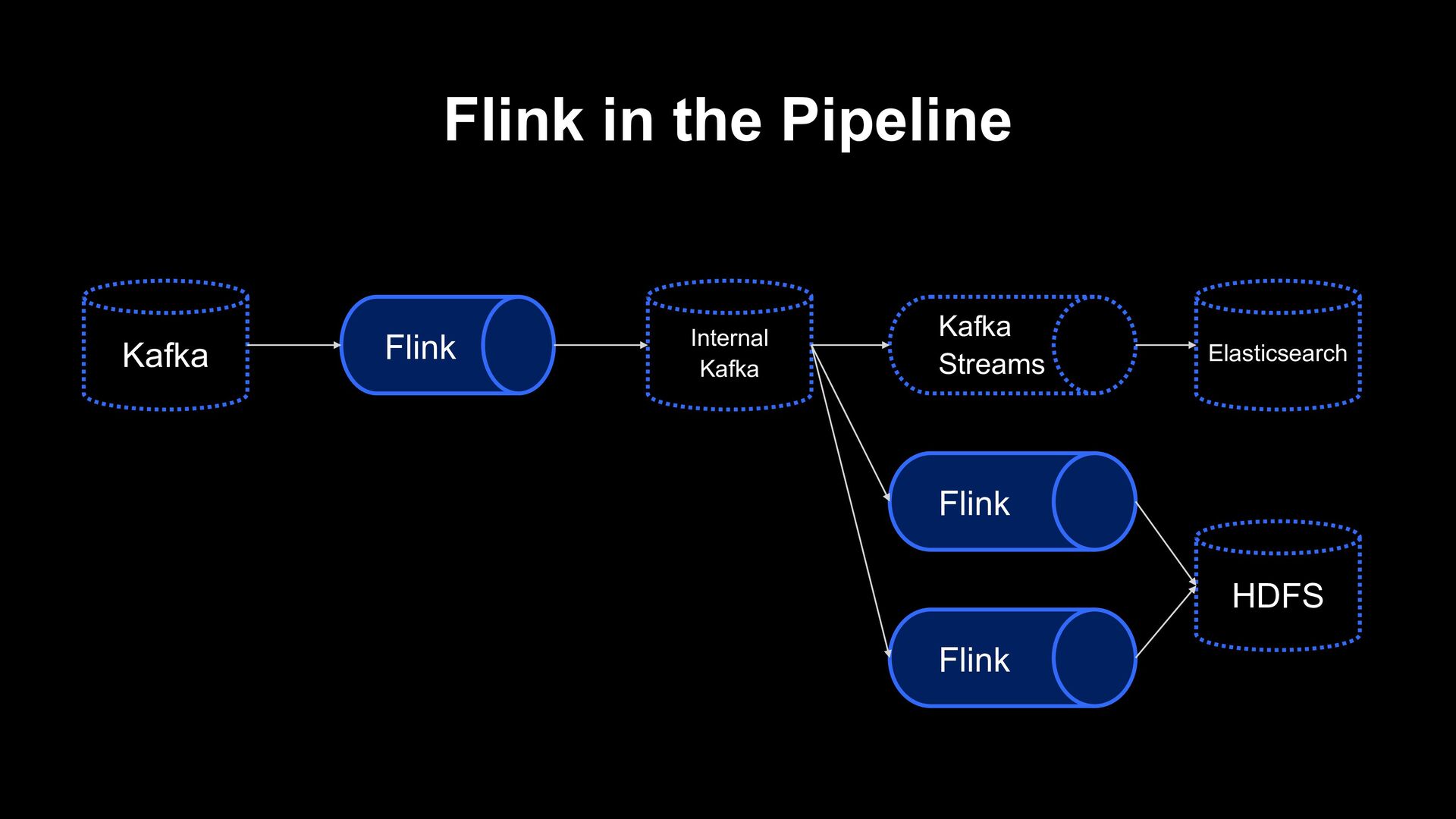
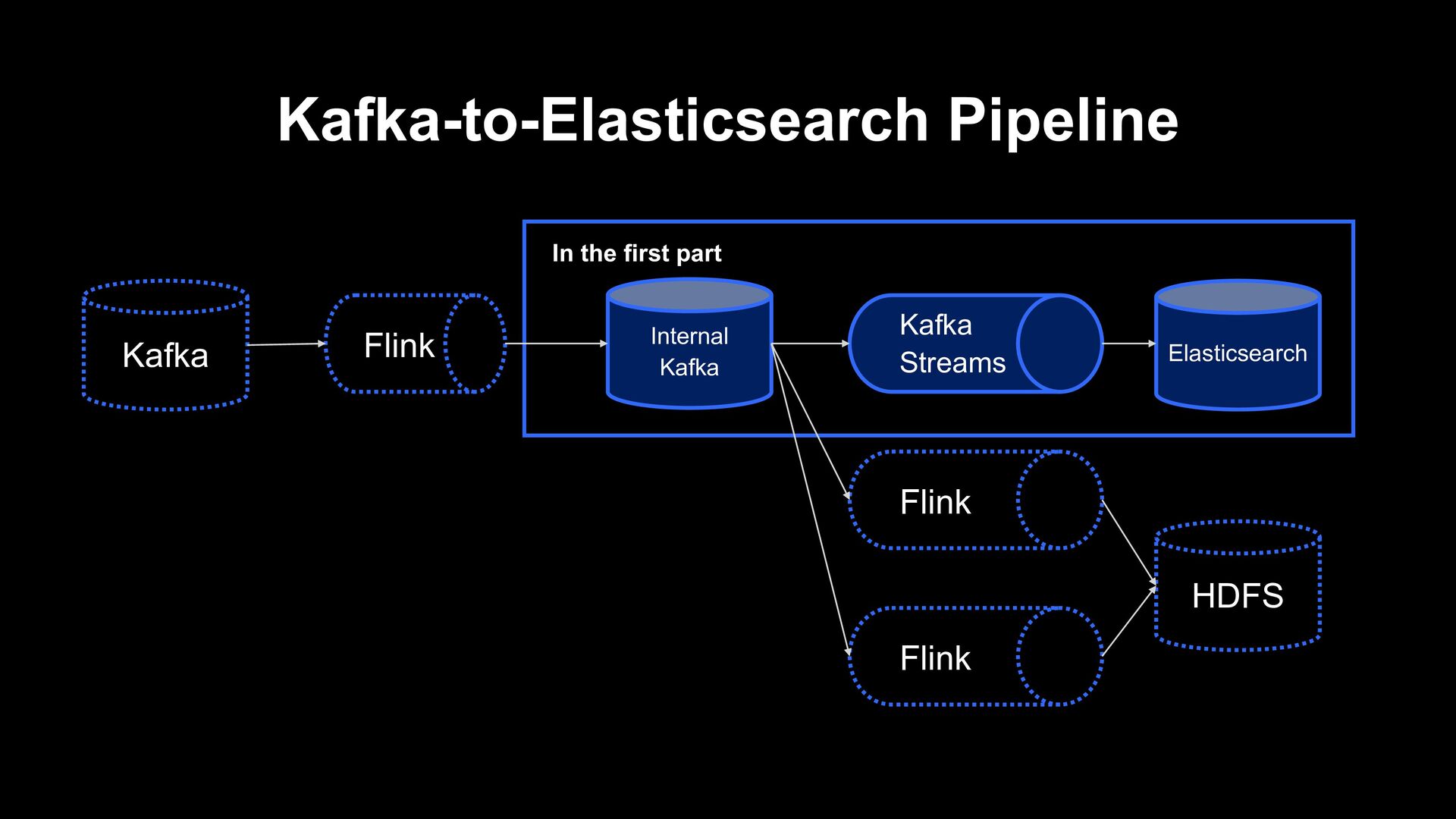
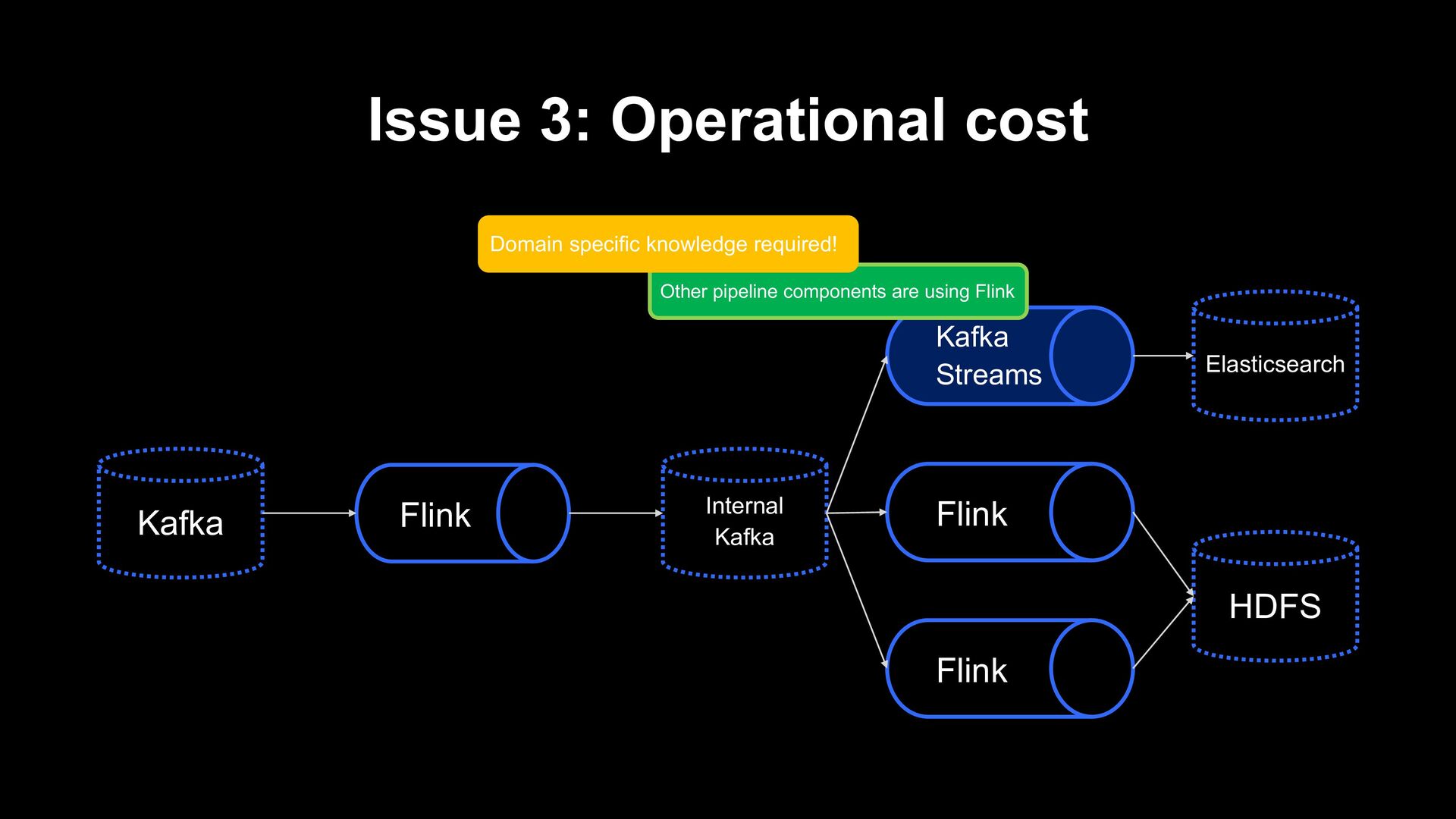
Pipeline in LINE’s Data Platform • Kafka-to-Elasticsearch pipeline redesign with Apache Flink - Second part • Auto Scaling implementation on Kubernetes
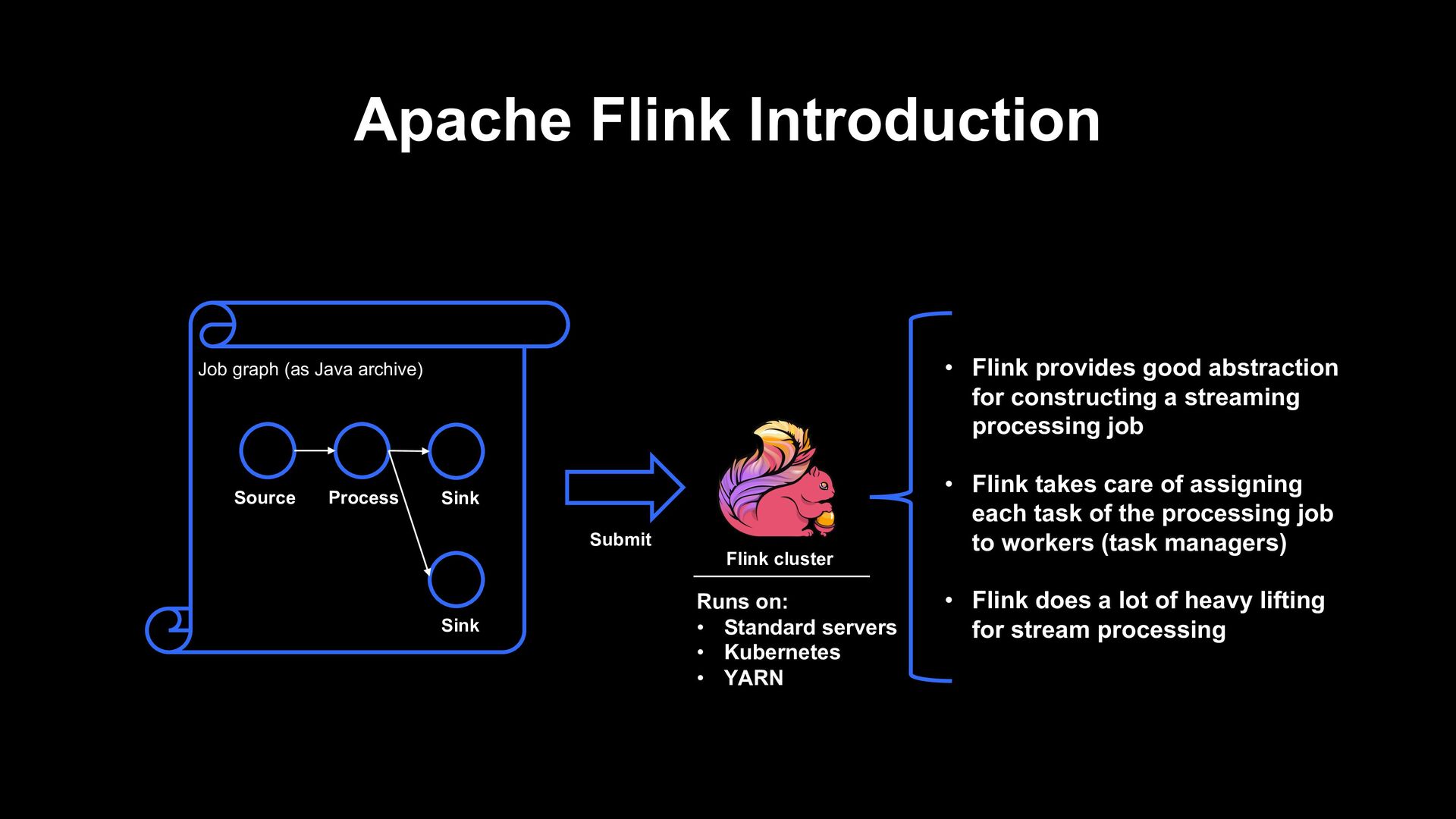
Sink Sink Submit • Flink provides good abstraction for constructing a streaming processing job • Flink takes care of assigning each task of the processing job to workers (task managers) • Flink does a lot of heavy lifting for stream processing Flink cluster Runs on: • Standard servers • Kubernetes • YARN
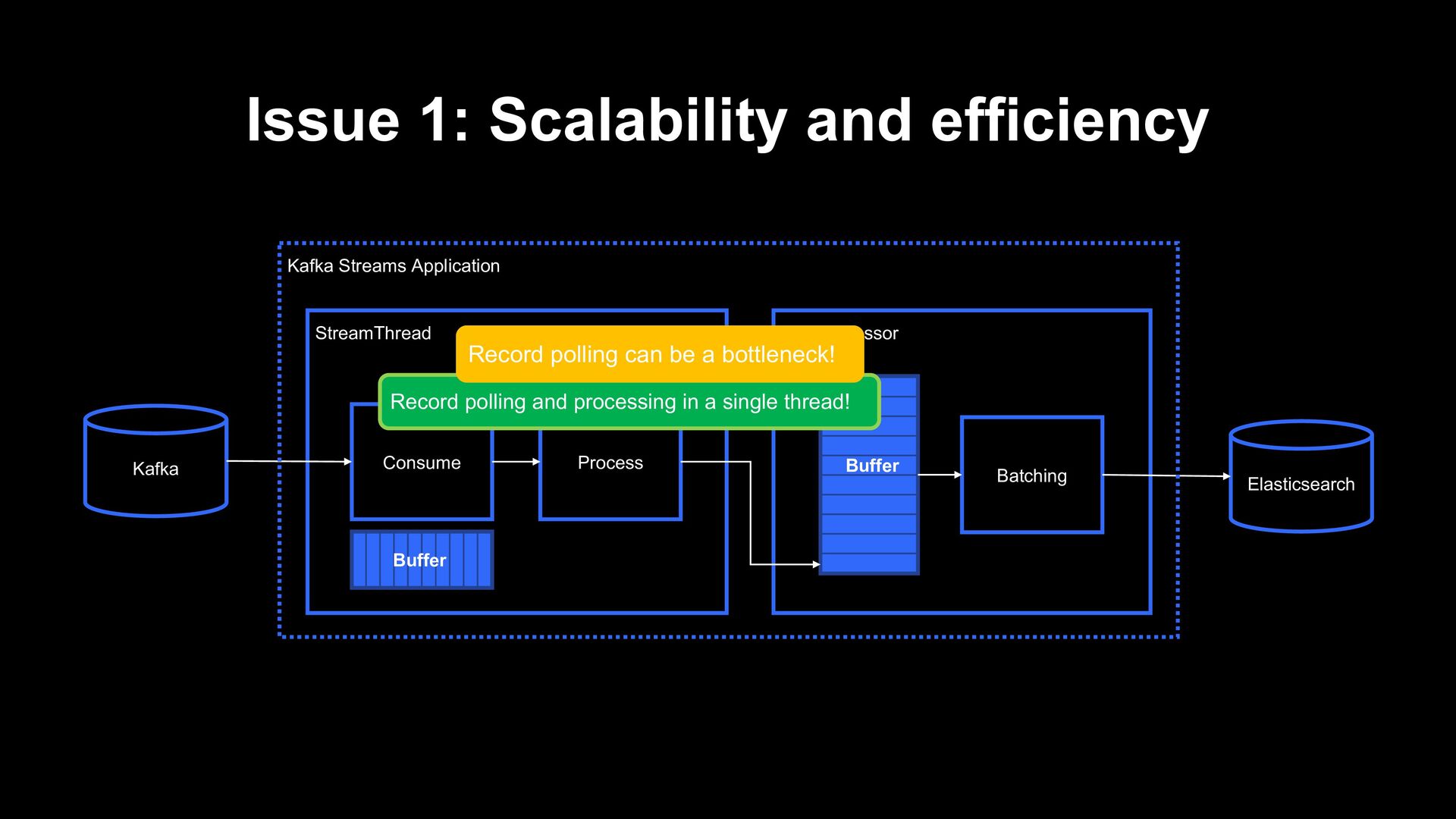
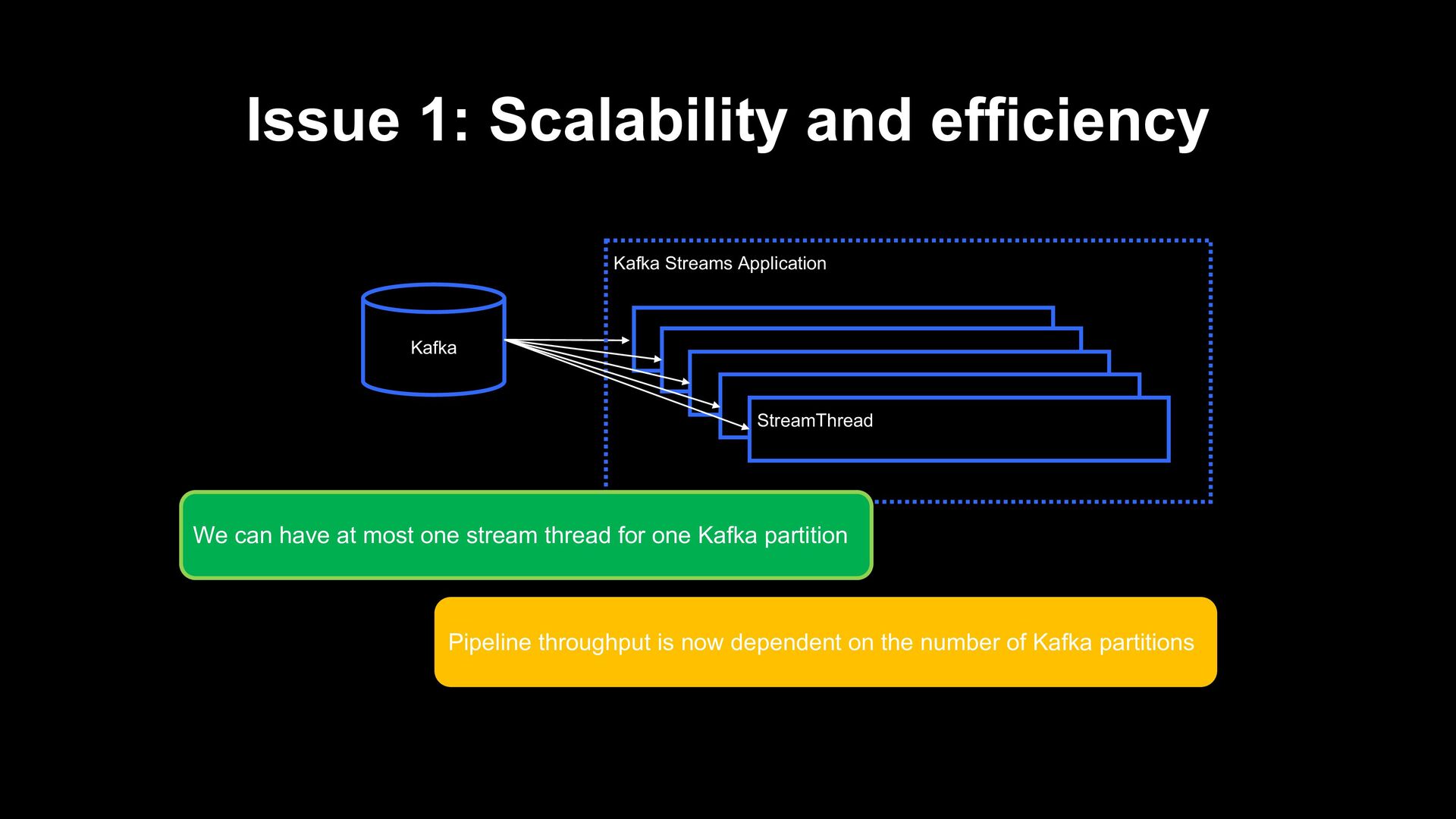
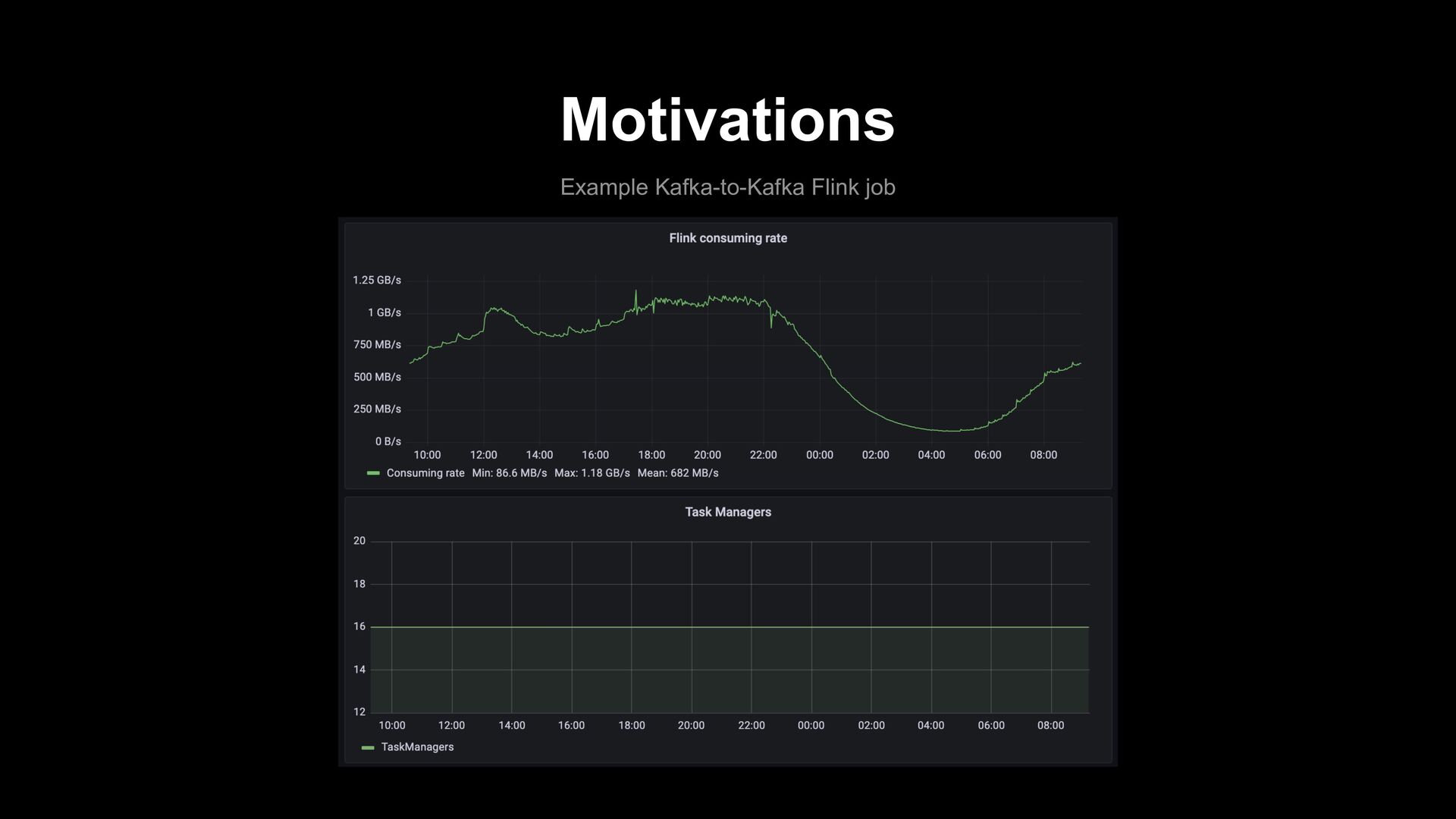
result of a StreamThread while the pipeline is lagging This thread is spending ~75% of time waiting for new data Partially due to bad configurations, but anyways, not desirable w.r.t. resource efficiency
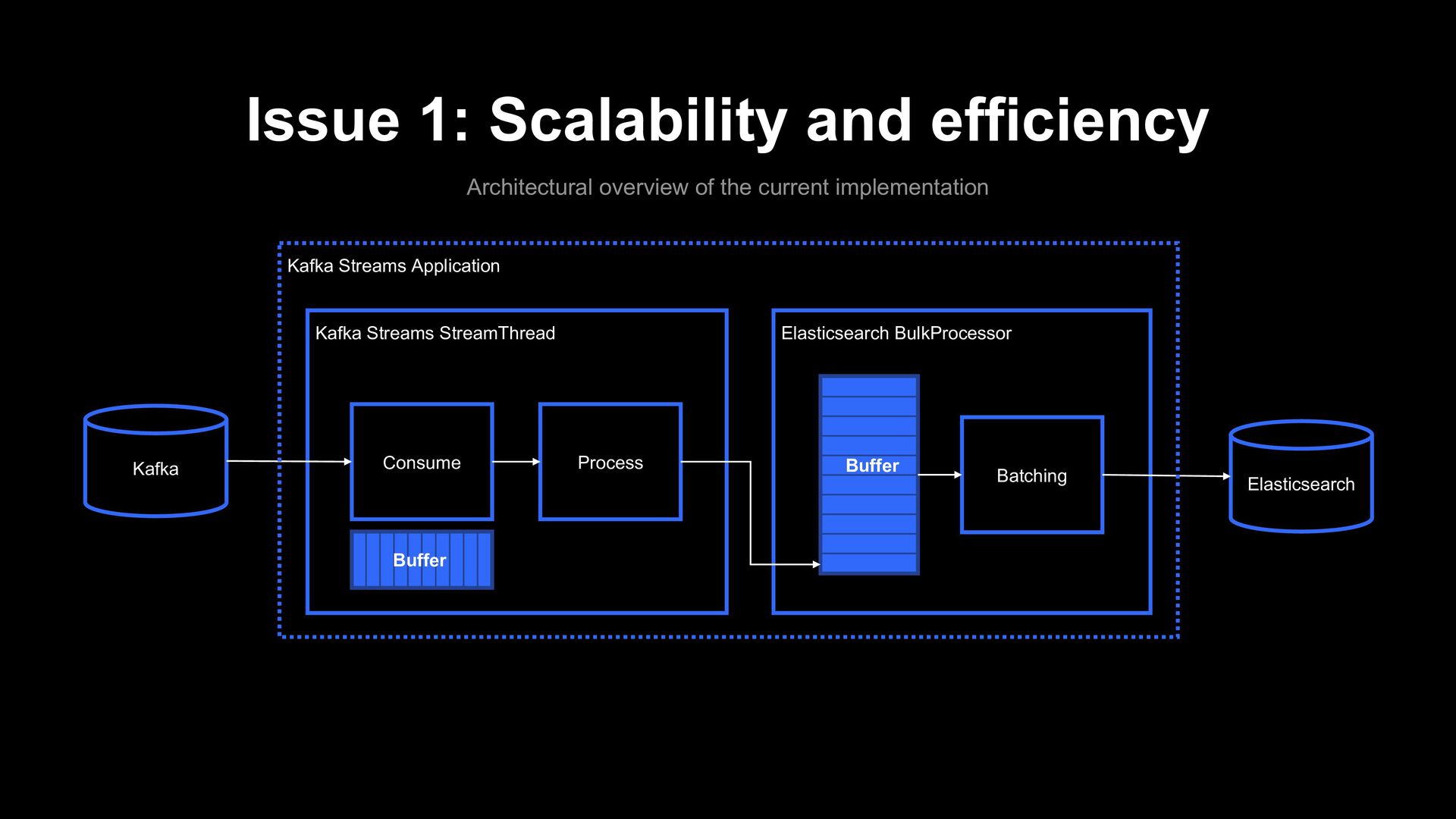
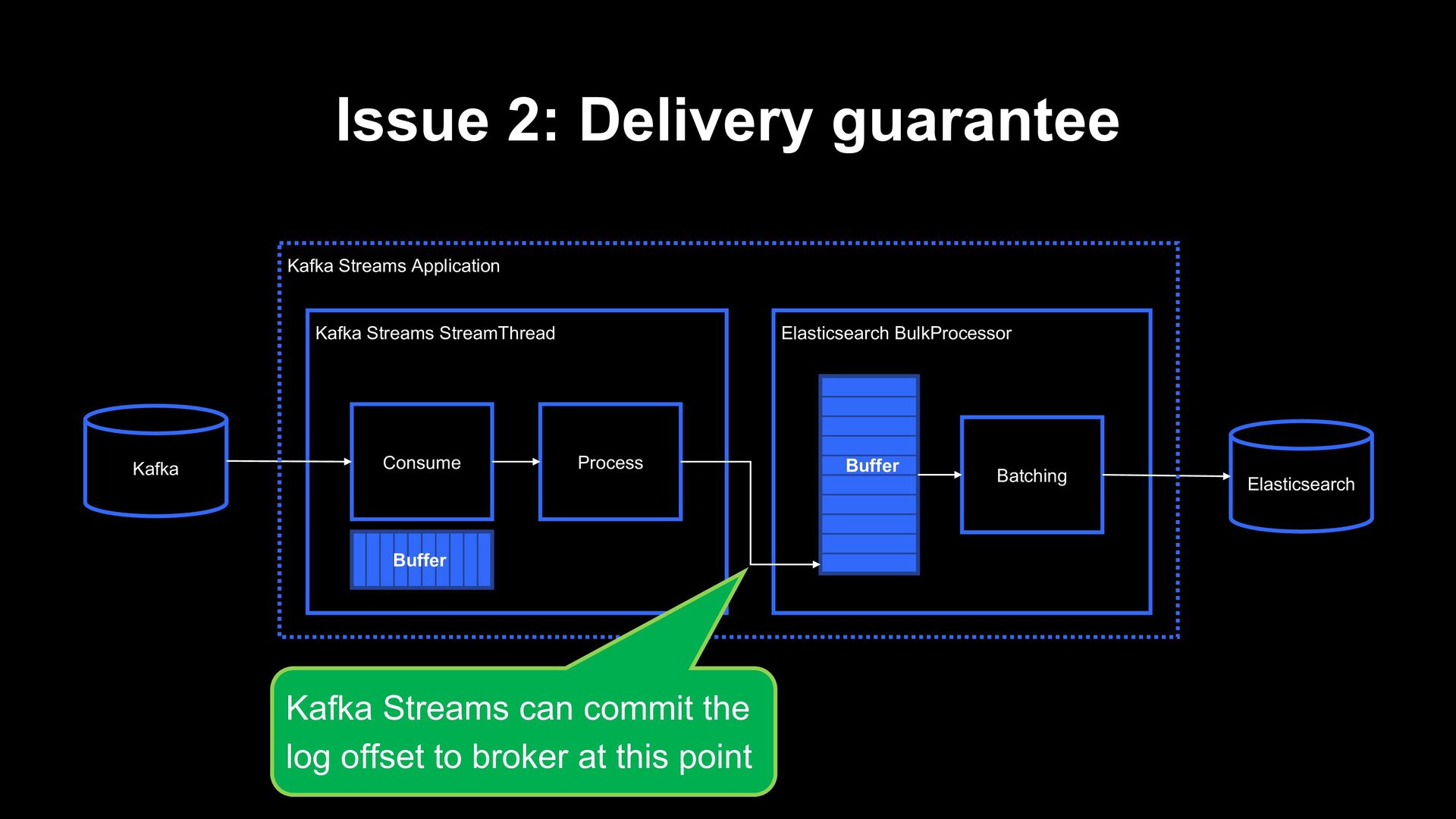
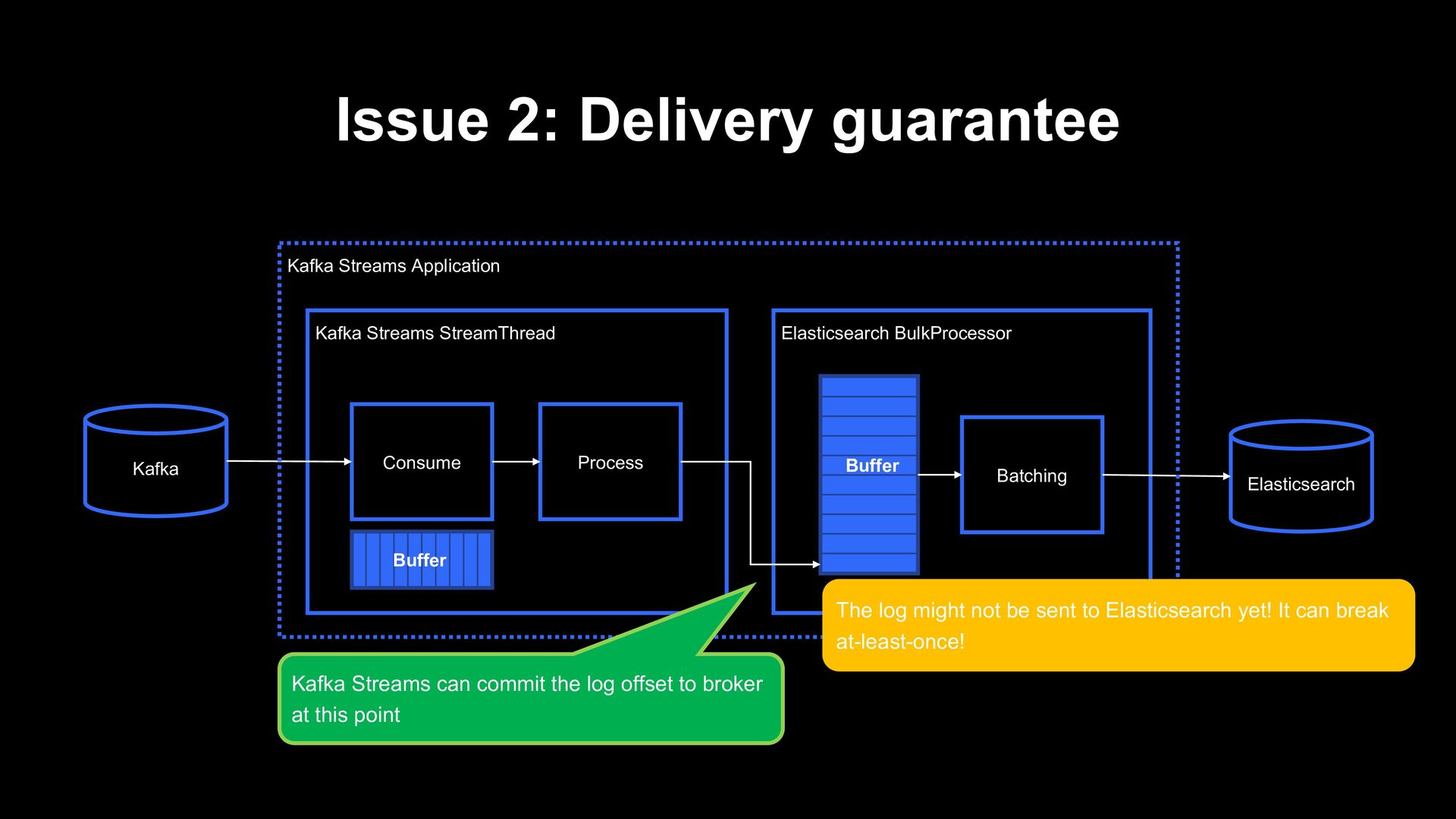
Consume Process Buffer Elasticsearch Kafka Kafka Streams Application Buffer The log might not be sent to Elasticsearch yet! It can break at-least-once! Kafka Streams can commit the log offset to broker at this point
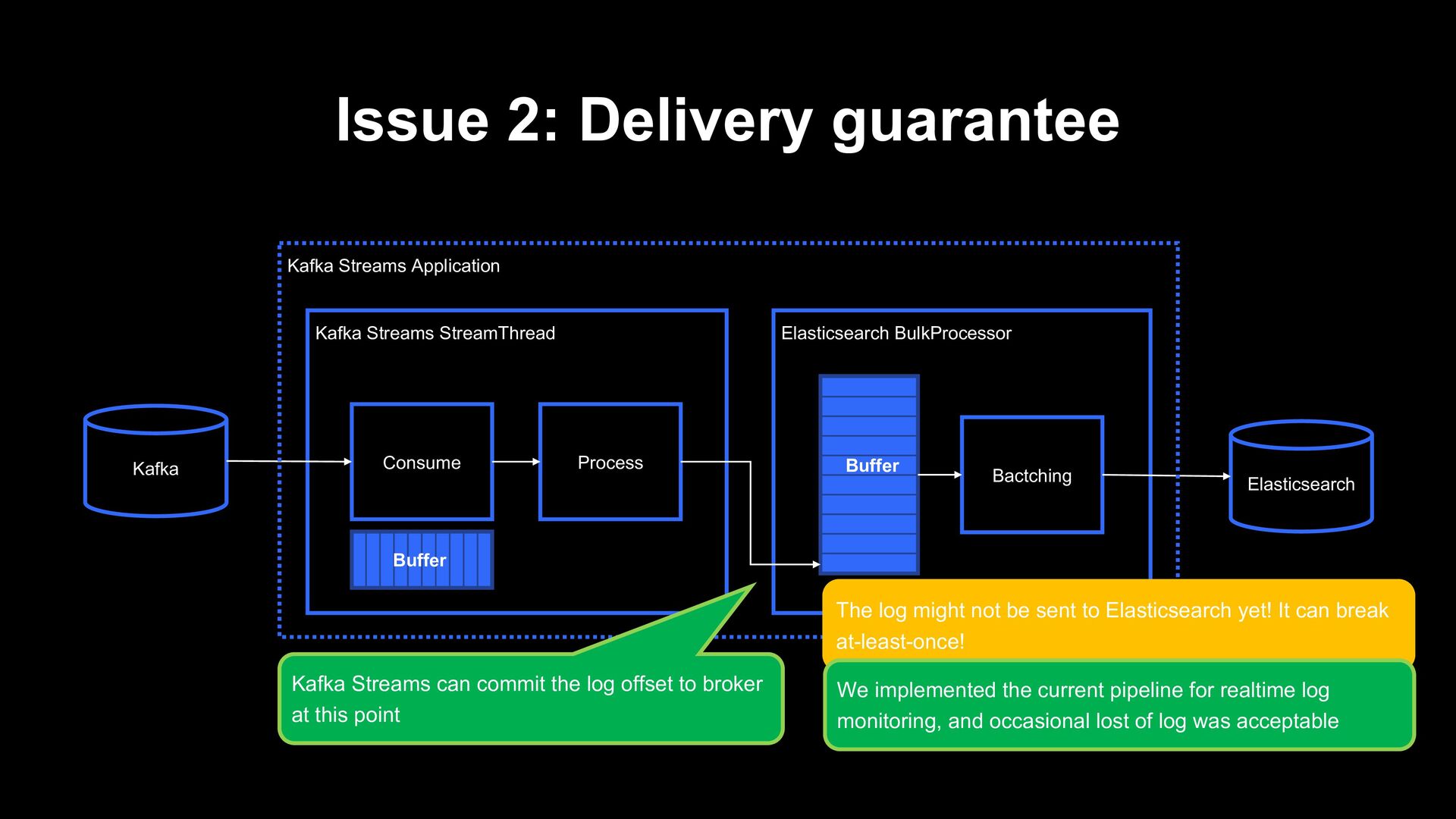
Consume Process Buffer Elasticsearch Kafka Kafka Streams Application Buffer The log might not be sent to Elasticsearch yet! It can break at-least-once! Kafka Streams can commit the log offset to broker at this point We implemented the current pipeline for realtime log monitoring, and occasional lost of log was acceptable
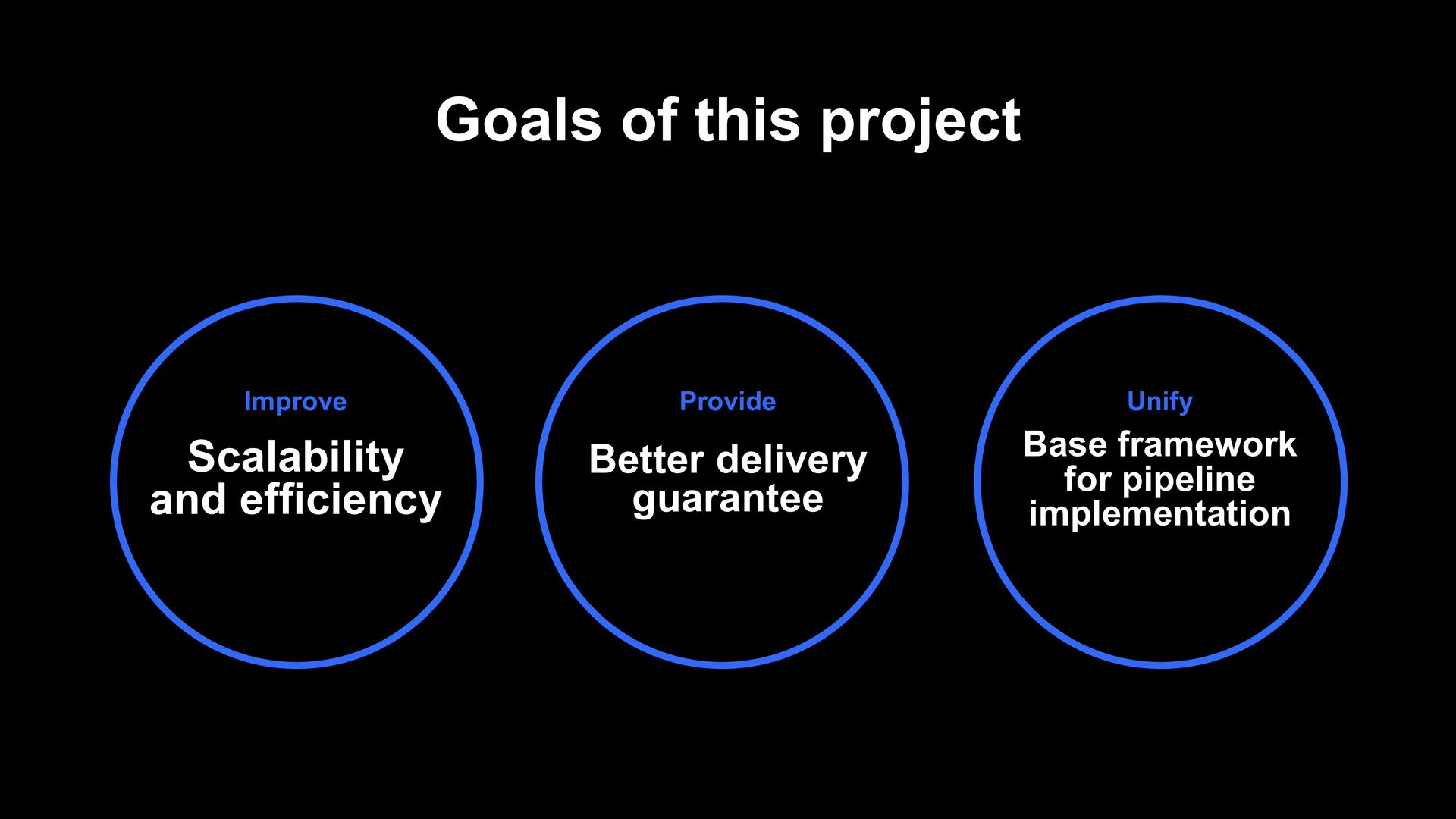
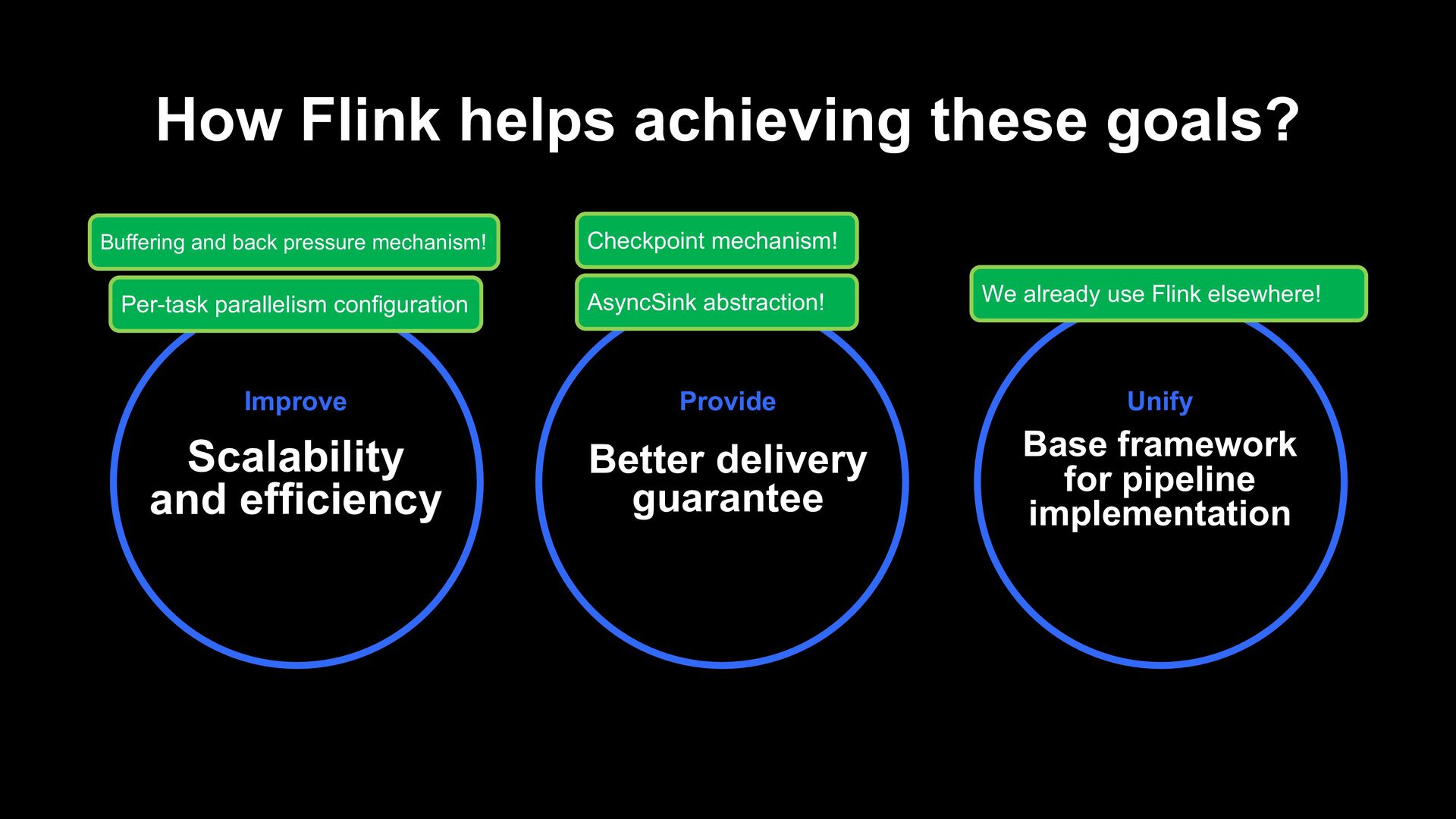
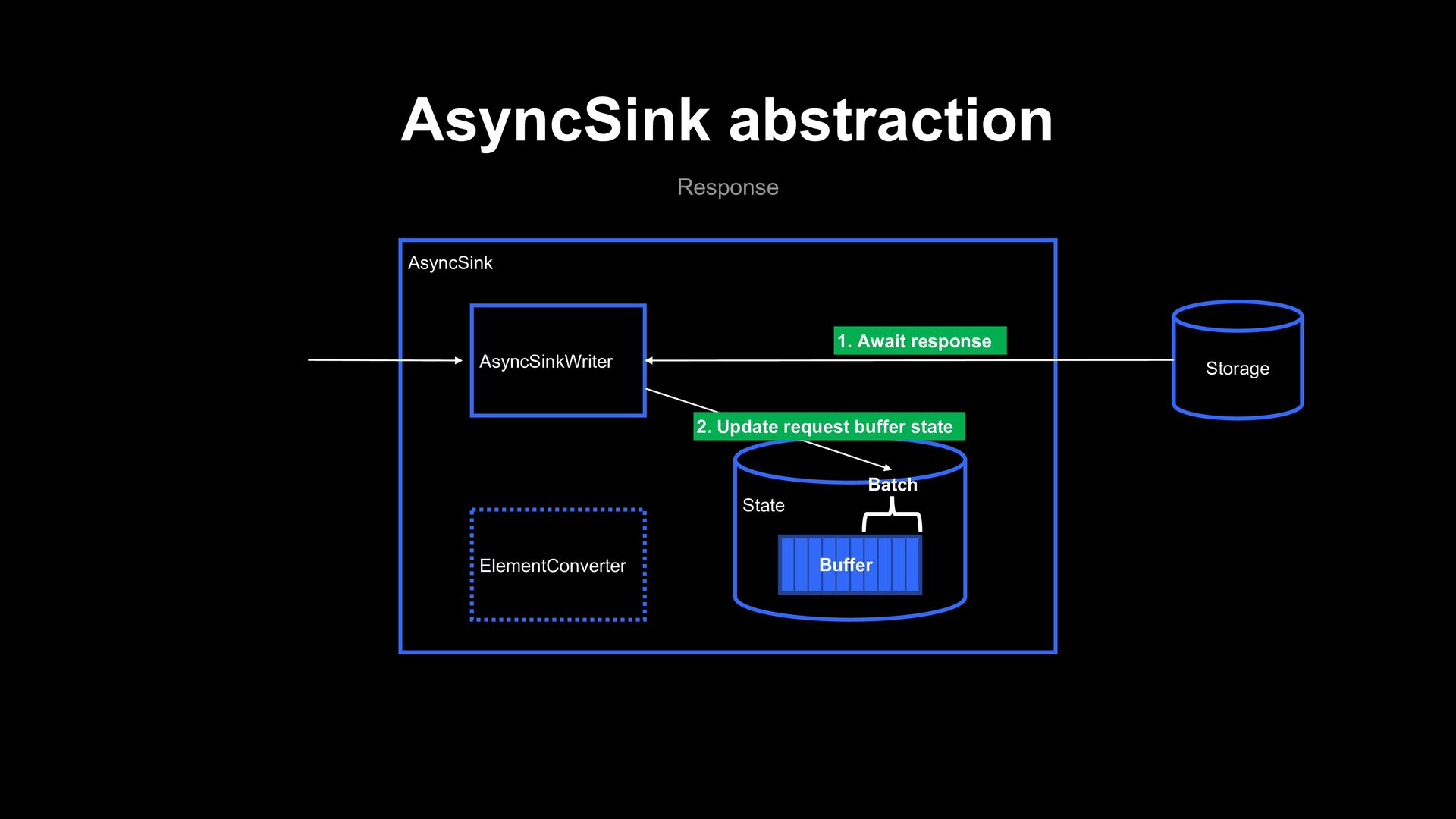
Provide Better delivery guarantee Unify Base framework for pipeline implementation Buffering and back pressure mechanism! Checkpoint mechanism! We already use Flink elsewhere! AsyncSink abstraction! Per-task parallelism configuration
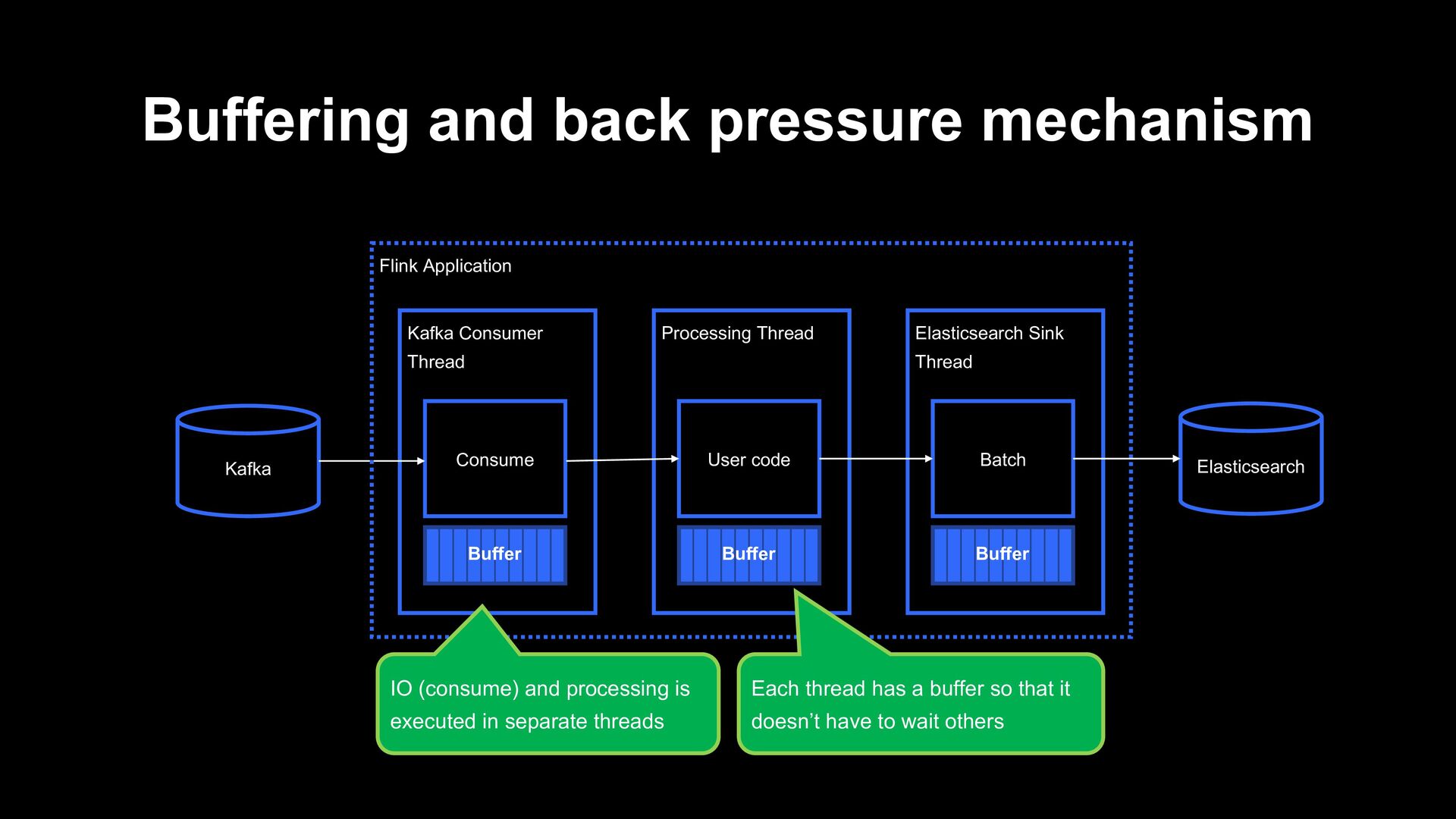
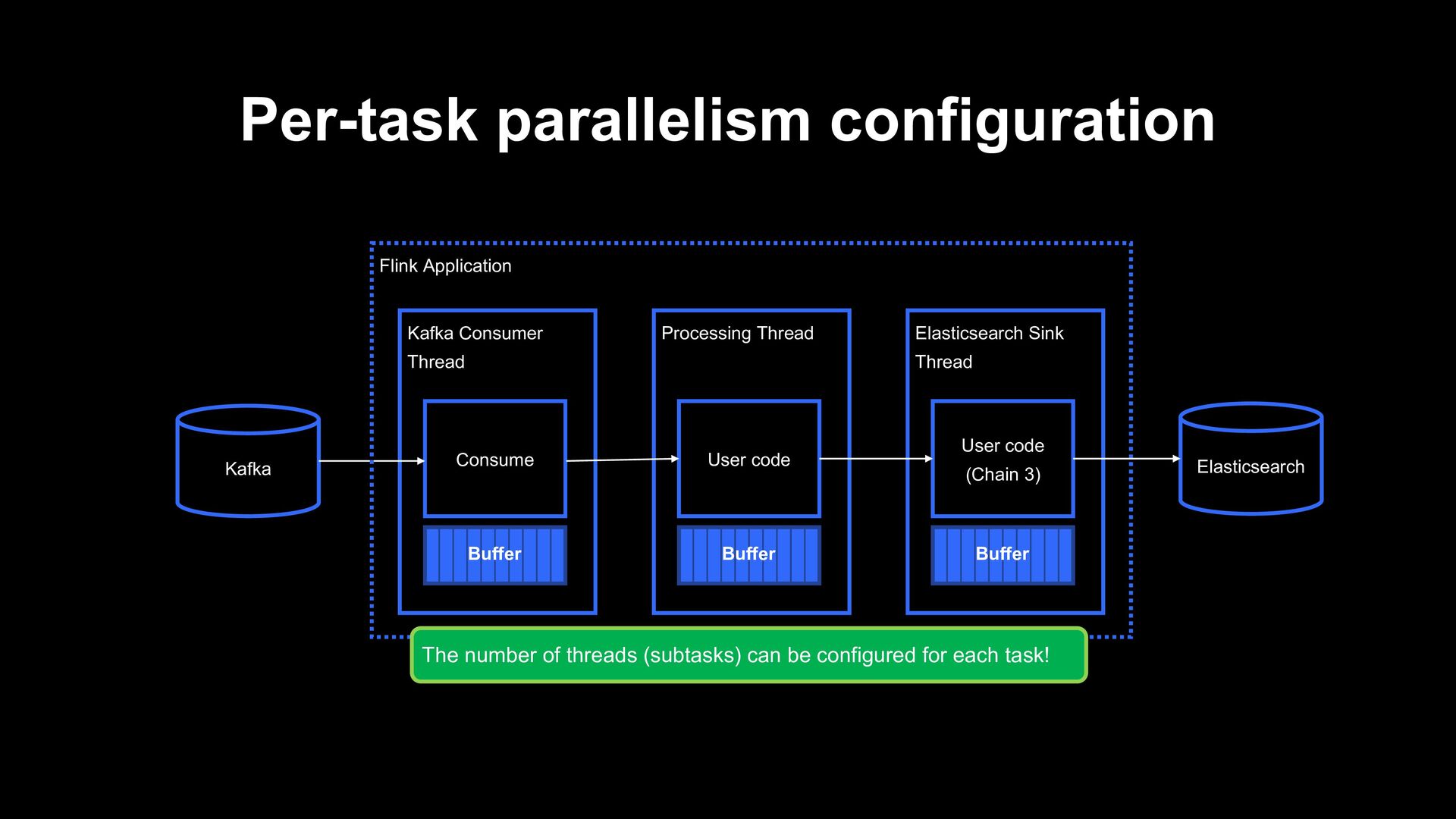
Kafka Flink Application Buffer Processing Thread User code Buffer Elasticsearch Sink Thread Batch Buffer IO (consume) and processing is executed in separate threads Each thread has a buffer so that it doesn’t have to wait others
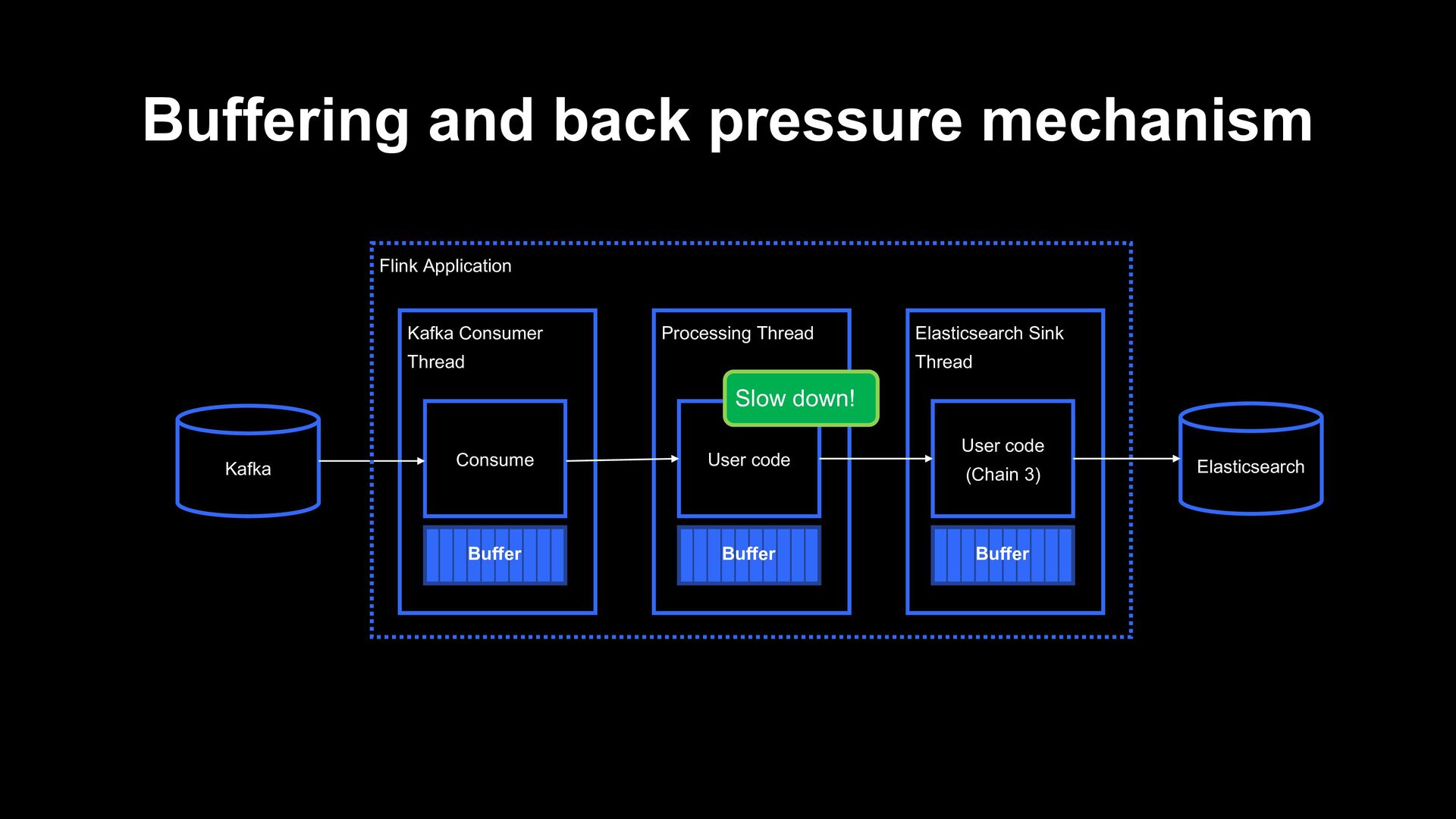
Application Buffer Processing Thread User code Buffer Elasticsearch Sink Thread User code (Chain 3) Buffer The number of threads (subtasks) can be configured for each task!
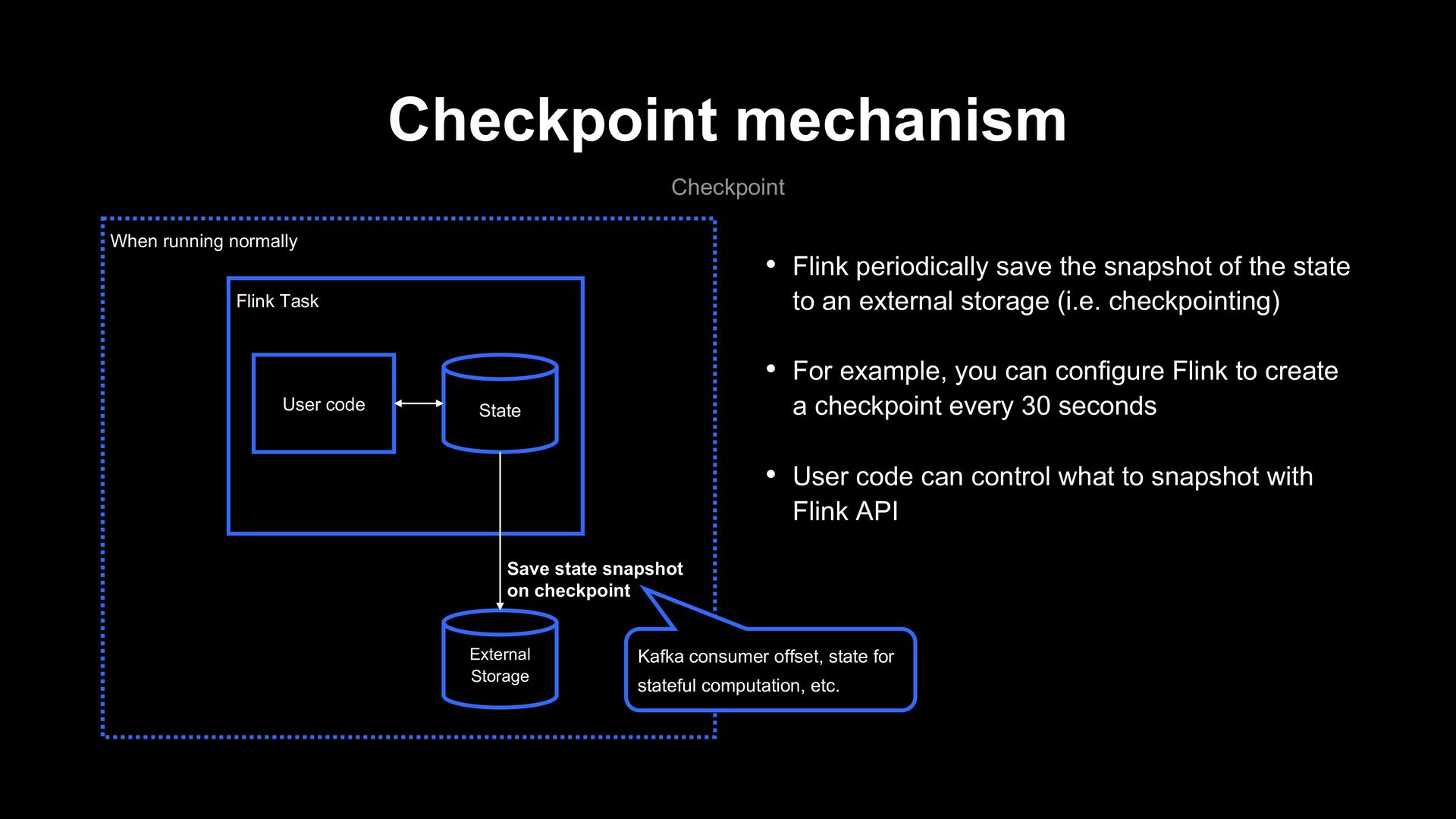
the state to an external storage (i.e. checkpointing) • For example, you can configure Flink to create a checkpoint every 30 seconds • User code can control what to snapshot with Flink API Flink Task User code State External Storage When running normally Save state snapshot on checkpoint Kafka consumer offset, state for stateful computation, etc.
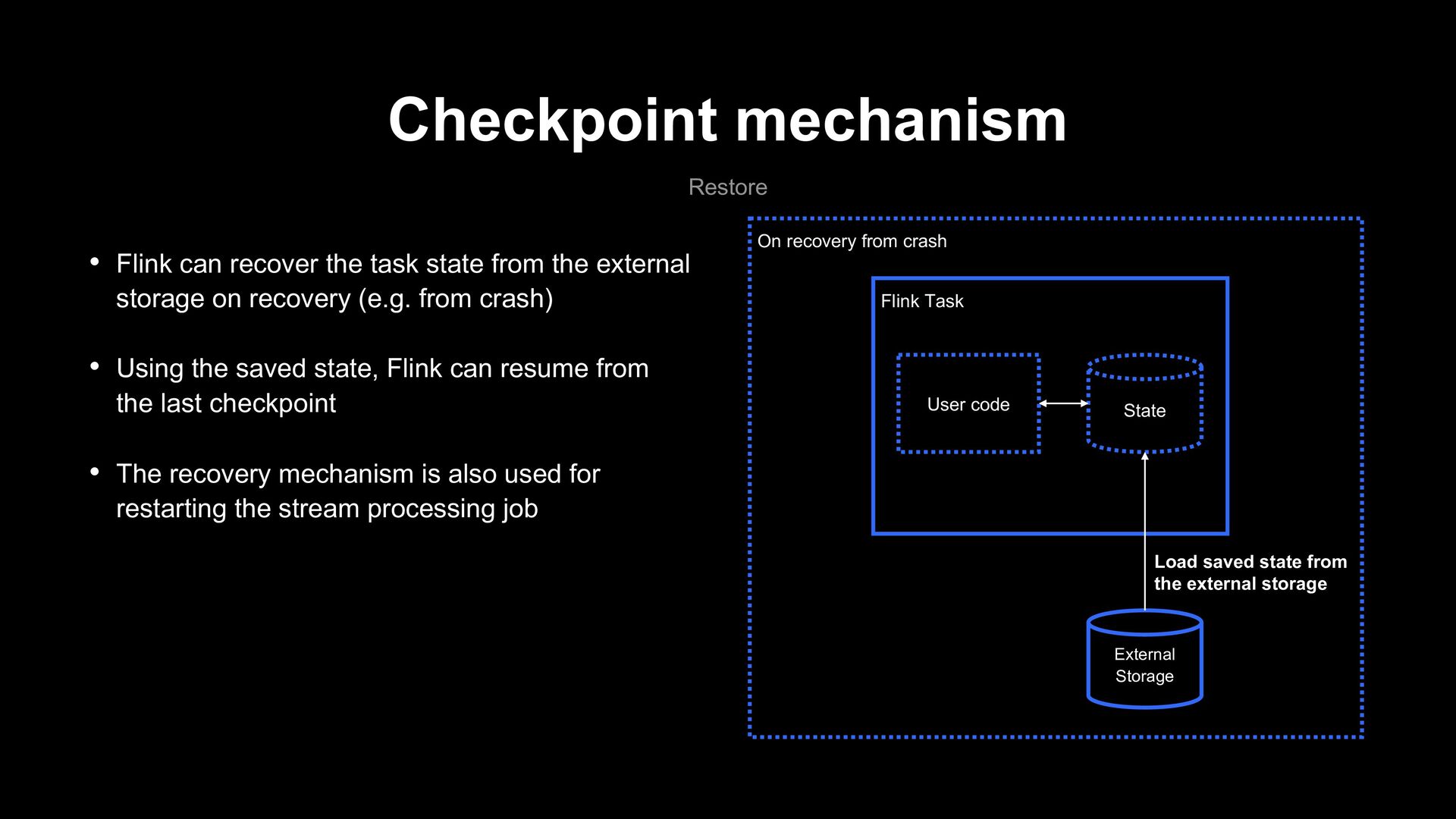
storage on recovery (e.g. from crash) • Using the saved state, Flink can resume from the last checkpoint • The recovery mechanism is also used for restarting the stream processing job Checkpoint mechanism Restore Flink Task User code State External Storage On recovery from crash Load saved state from the external storage
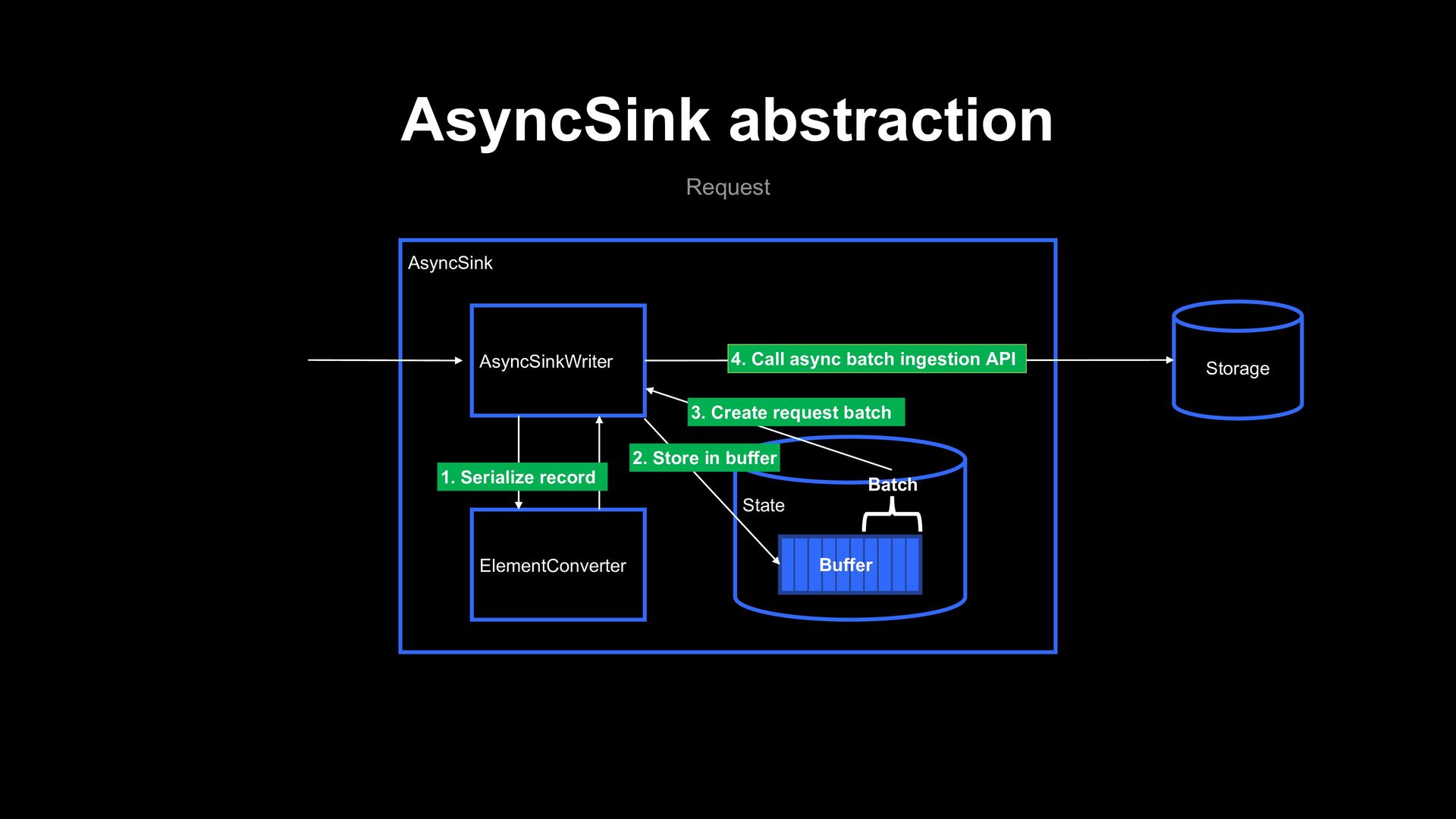
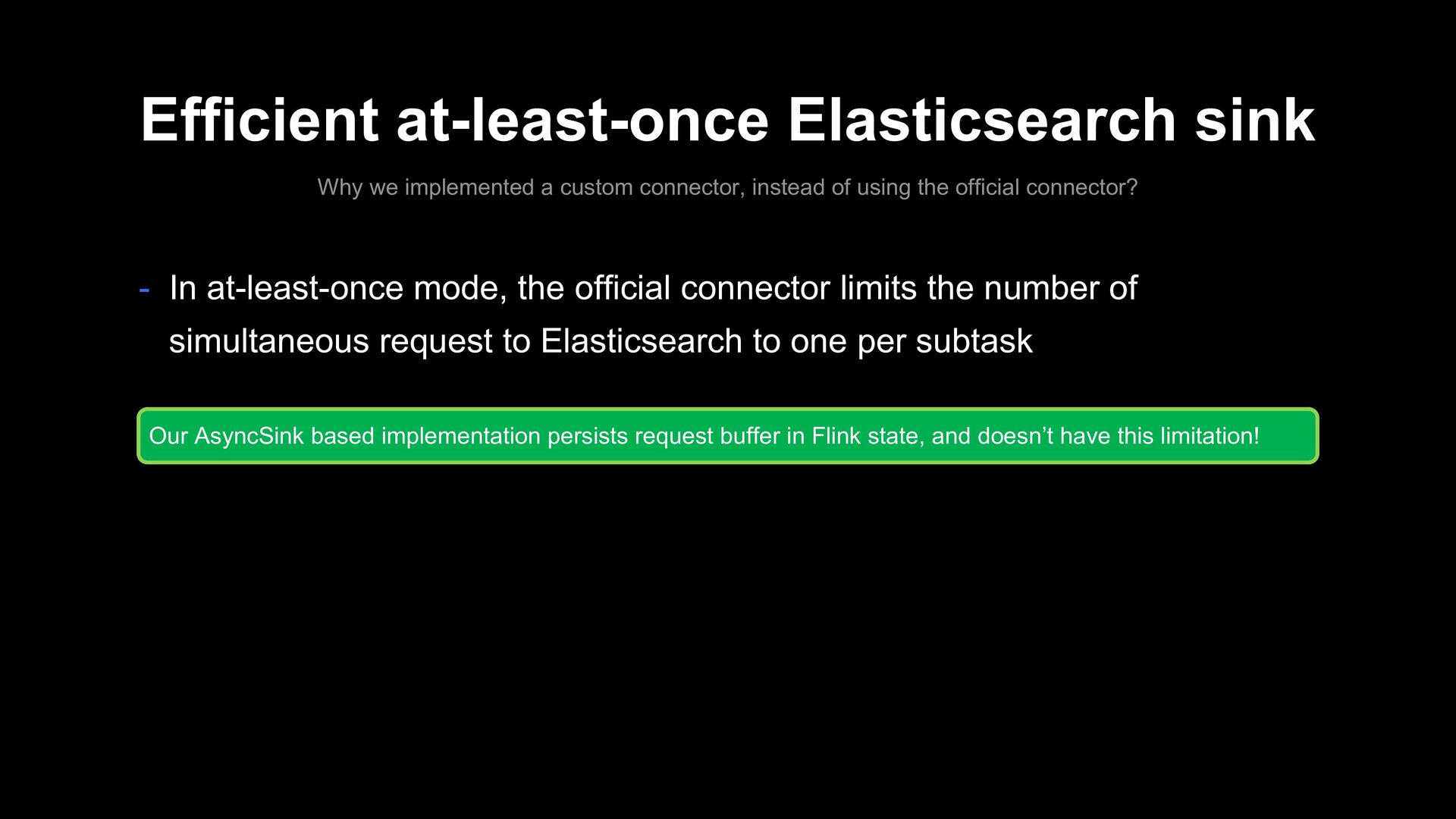
instead of using the official connector? - In at-least-once mode, the official connector limits the number of simultaneous request to Elasticsearch to one per subtask Our AsyncSink based implementation persists request buffer in Flink state, and doesn’t have this limitation!
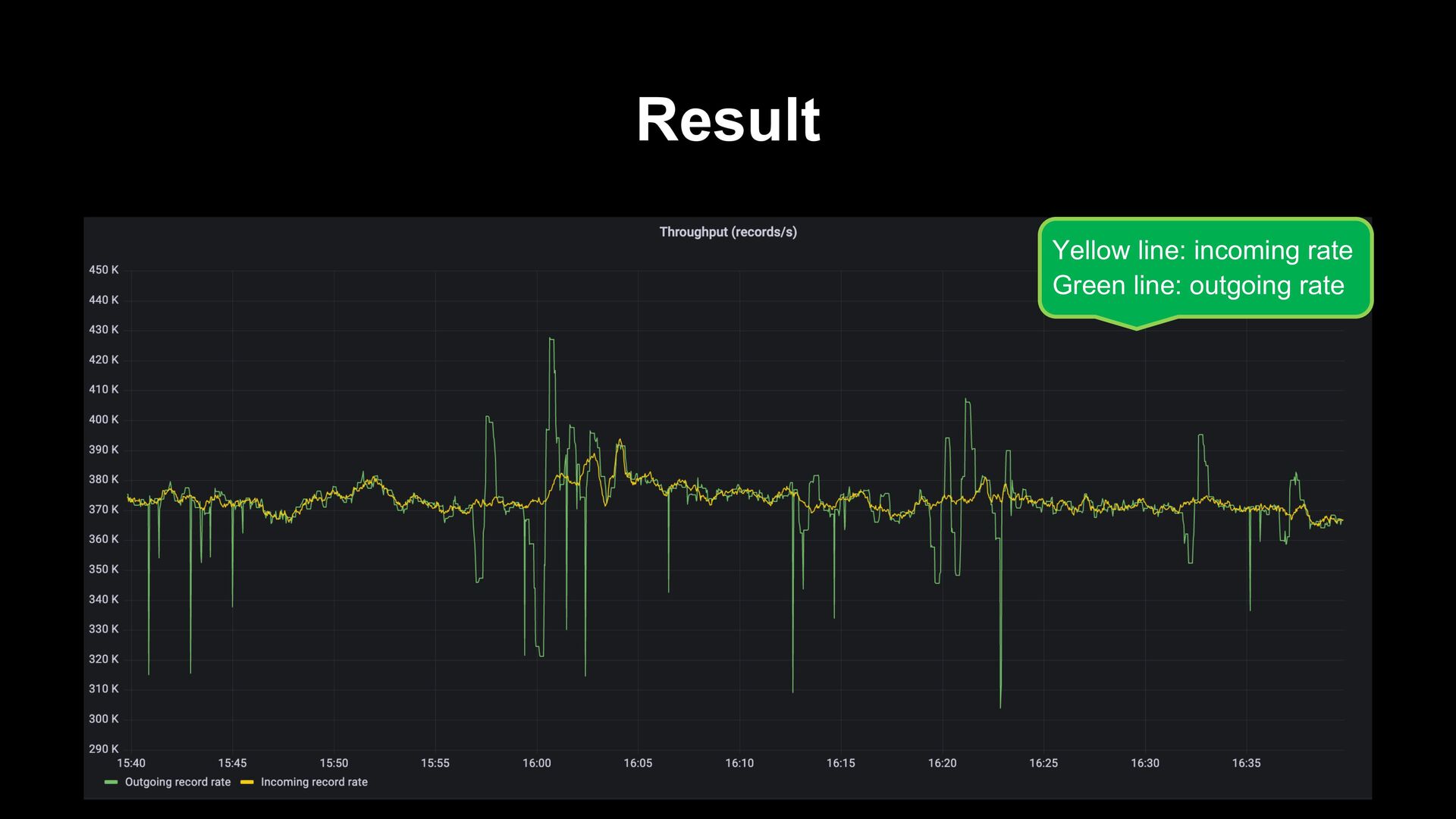
Elasticsearch Flink Kafka • Test cluster • Hot-warm architecture • 45 hot nodes, 21 warm nodes • Production cluster • Use one of topics used in production for test • 375k records/s, ~85MB/s • 64 partitions • Test cluster on Kubernetes • 8 workers, each with 8 CPU cores and 8GB RAM
and maintainability of our Kafka-to-Elasticsearch pipeline Summary In the near future, we’d like to roll out the new version to production The experiment showed the Flink based implementation can process production-level workload providing better delivery guarantee
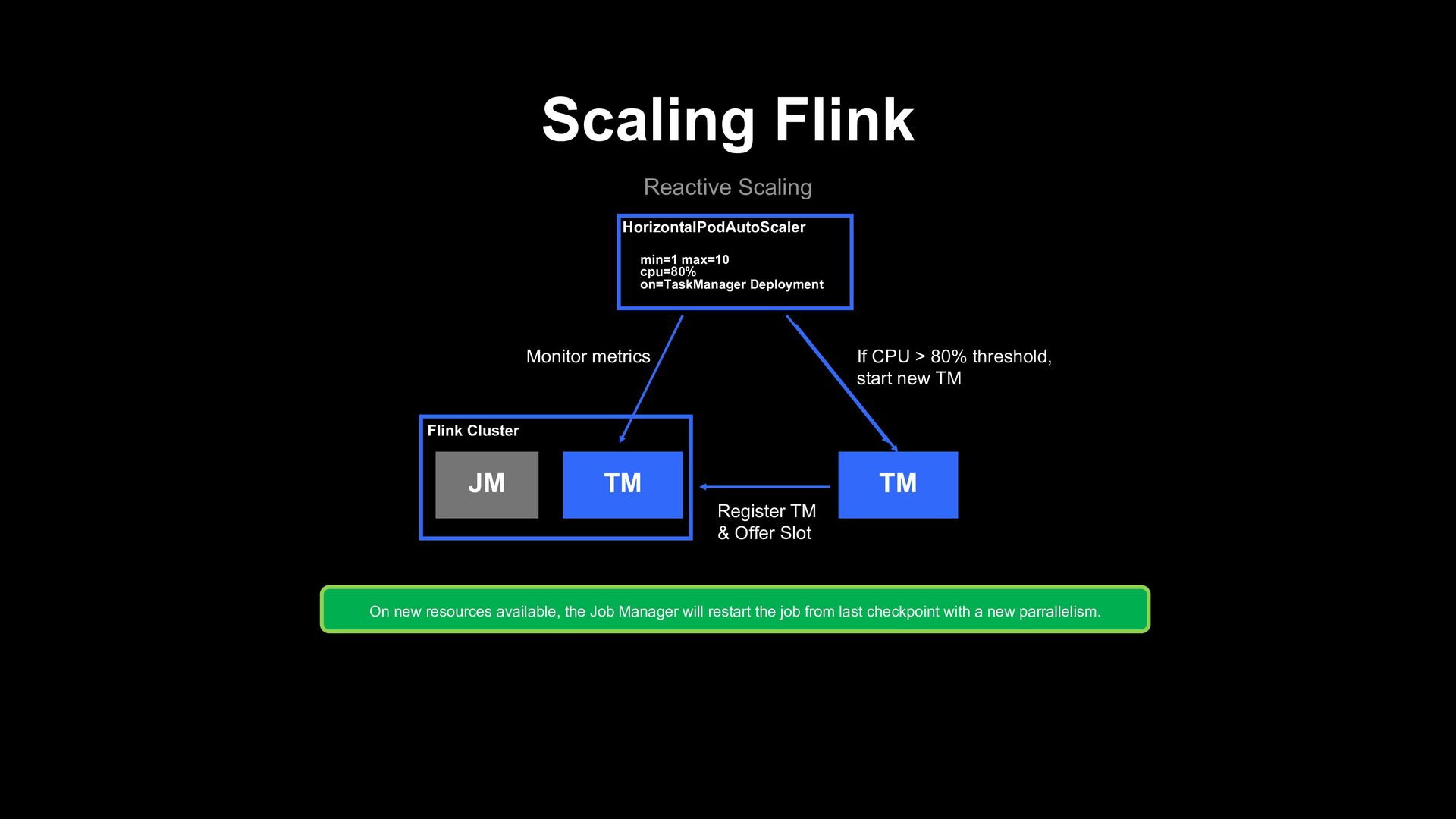
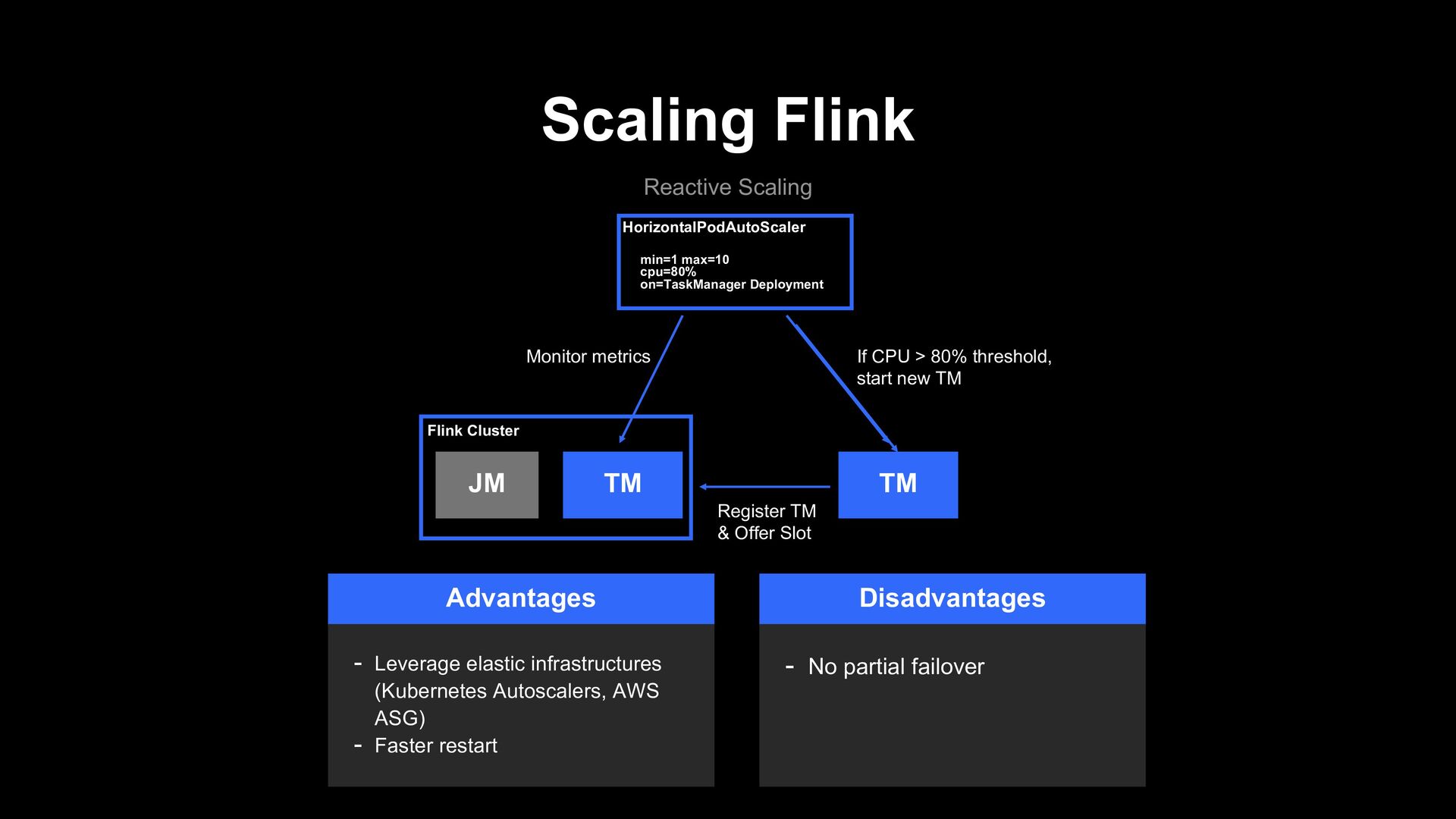
JM TM Flink Cluster TM Monitor metrics If CPU > 80% threshold, start new TM Register TM & Offer Slot On new resources available, the Job Manager will restart the job from last checkpoint with a new parrallelism.
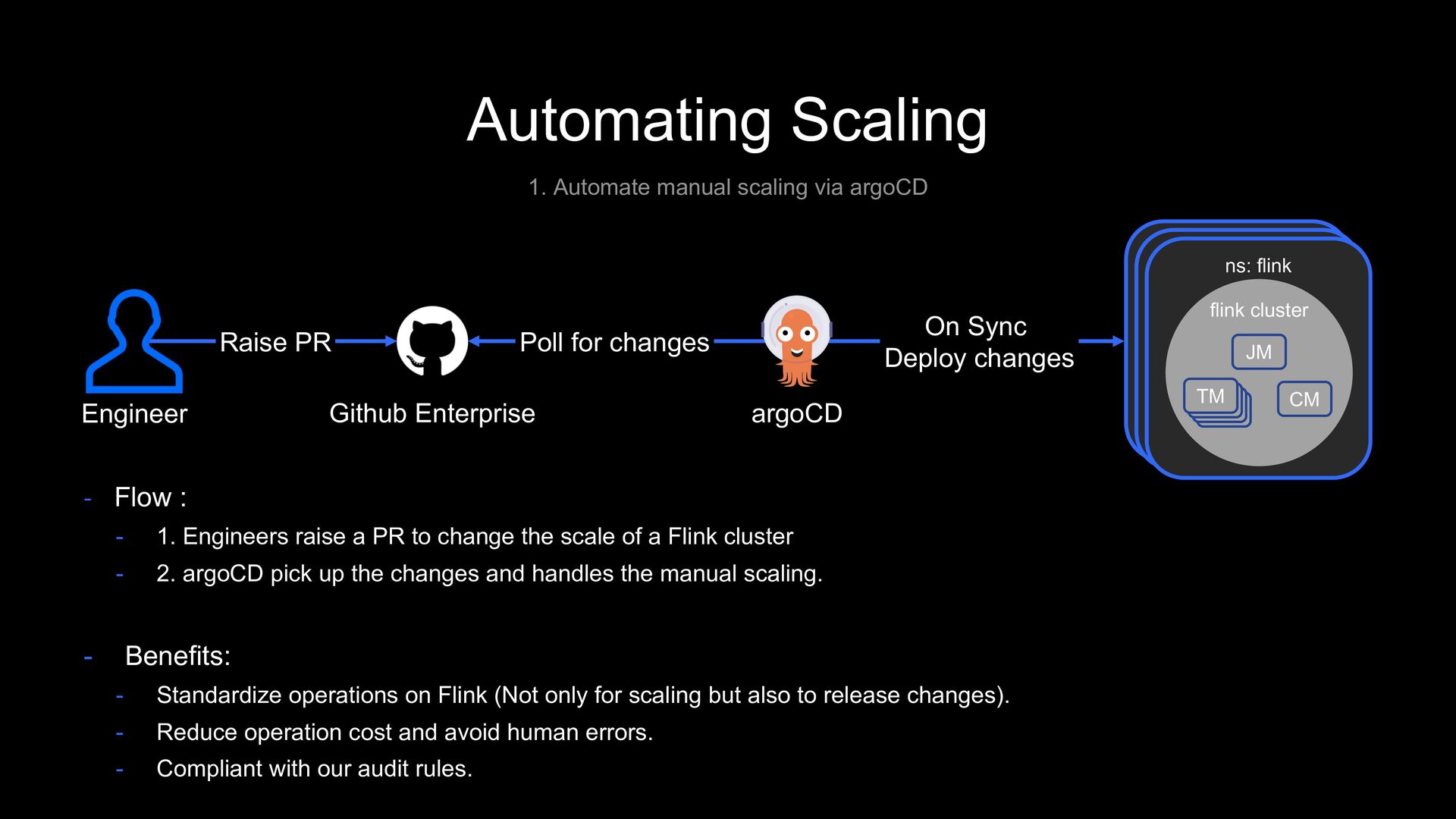
: - 1. Engineers raise a PR to change the scale of a Flink cluster - 2. argoCD pick up the changes and handles the manual scaling. - Benefits: - Standardize operations on Flink (Not only for scaling but also to release changes). - Reduce operation cost and avoid human errors. - Compliant with our audit rules. Engineer Raise PR Github Enterprise Poll for changes argoCD On Sync Deploy changes ns: flink flink cluster JM CM TM
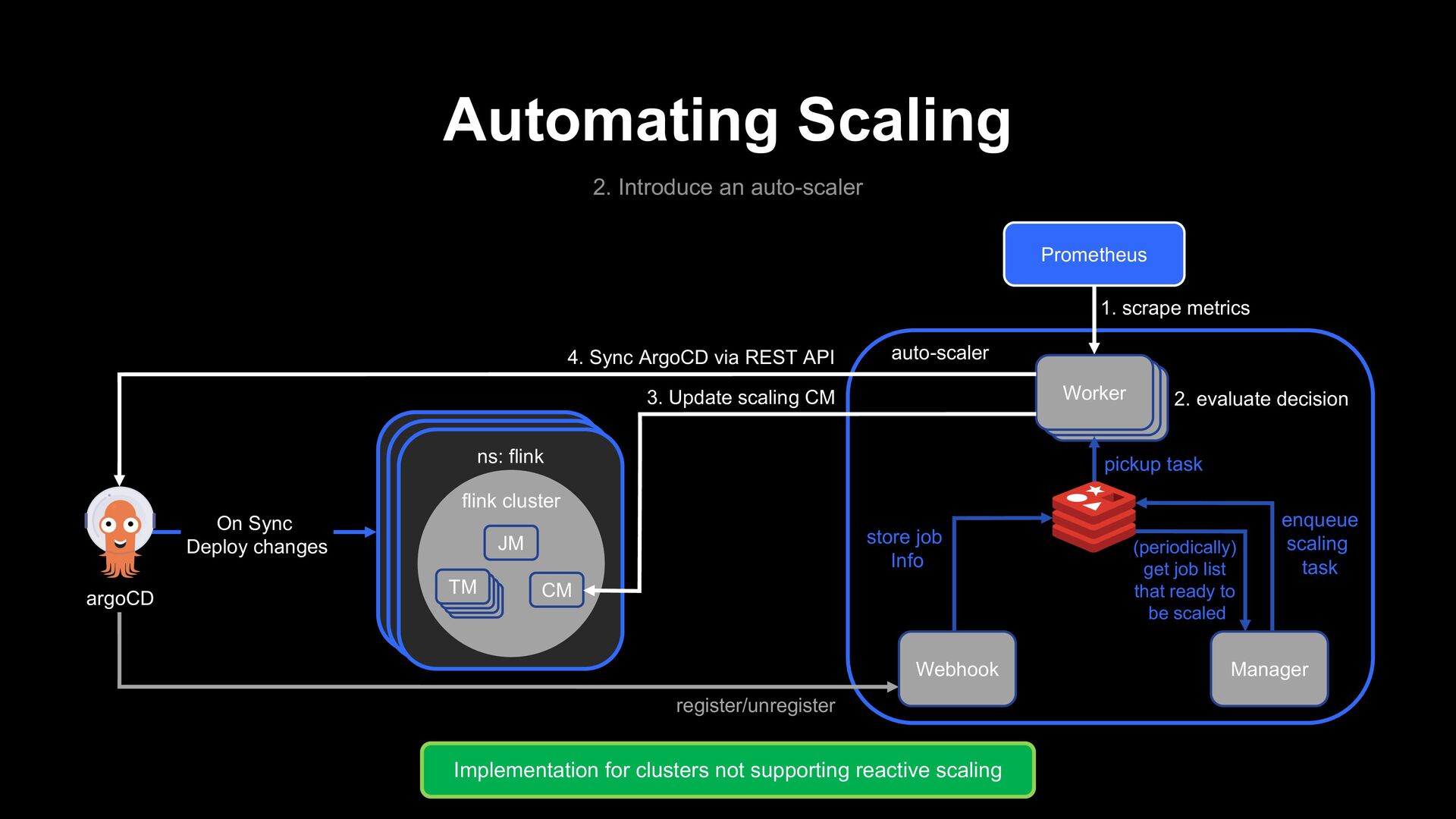
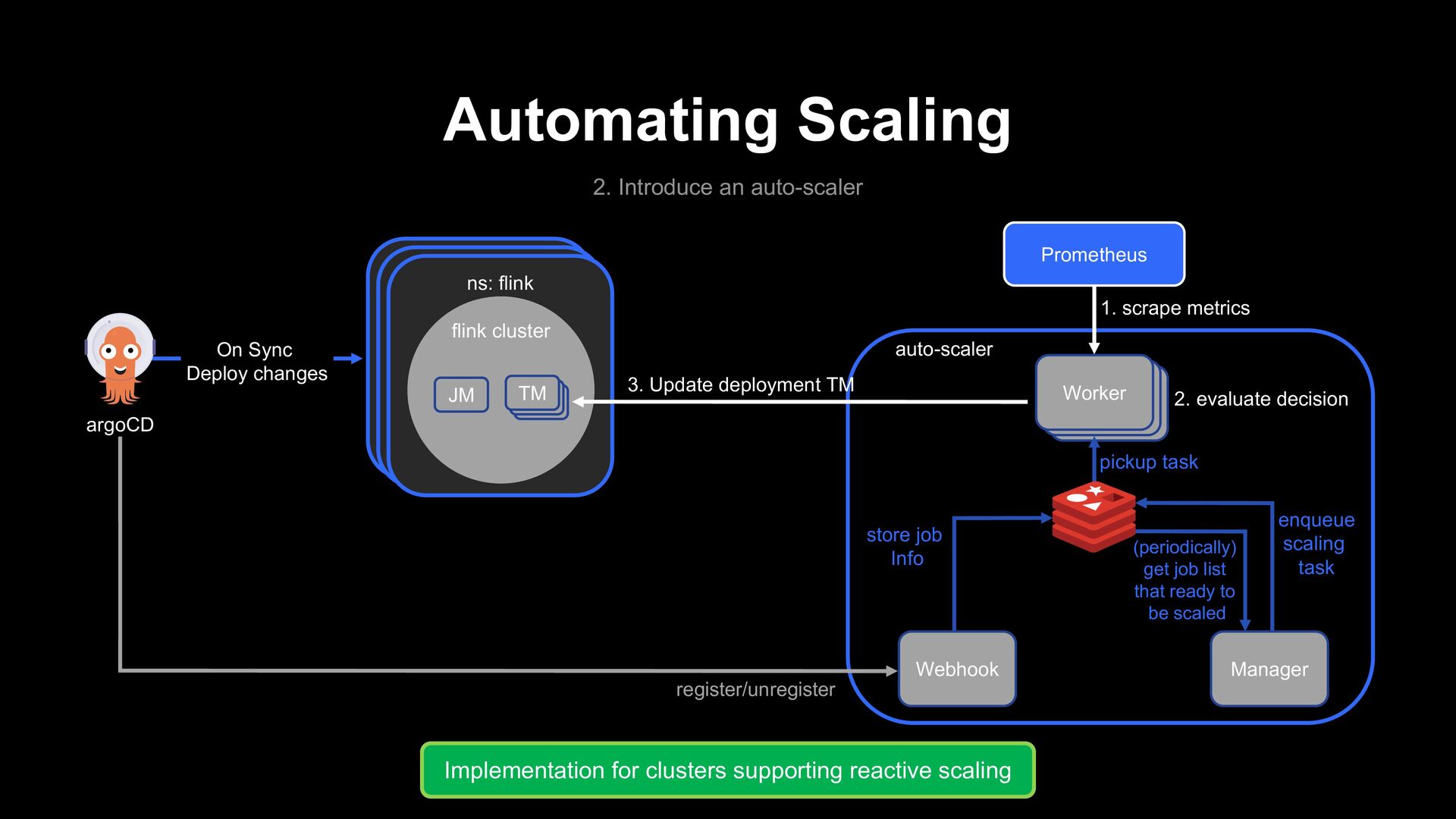
changes ns: flink flink cluster JM CM TM Prometheus Worker register/unregister 4. Sync ArgoCD via REST API 3. Update scaling CM store job Info (periodically) get job list that ready to be scaled enqueue scaling task 2. evaluate decision 1. scrape metrics pickup task auto-scaler Manager Webhook Implementation for clusters not supporting reactive scaling
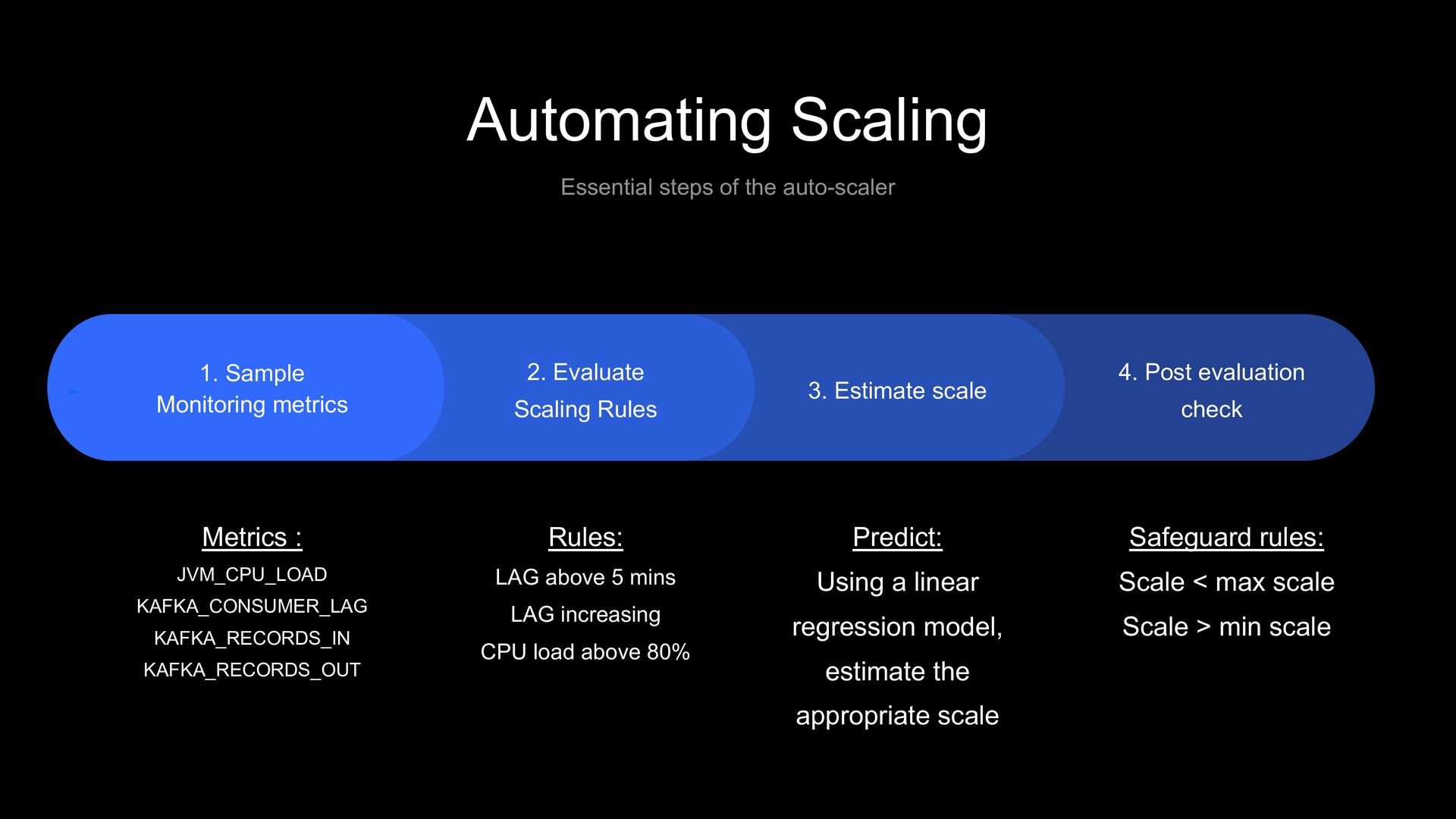
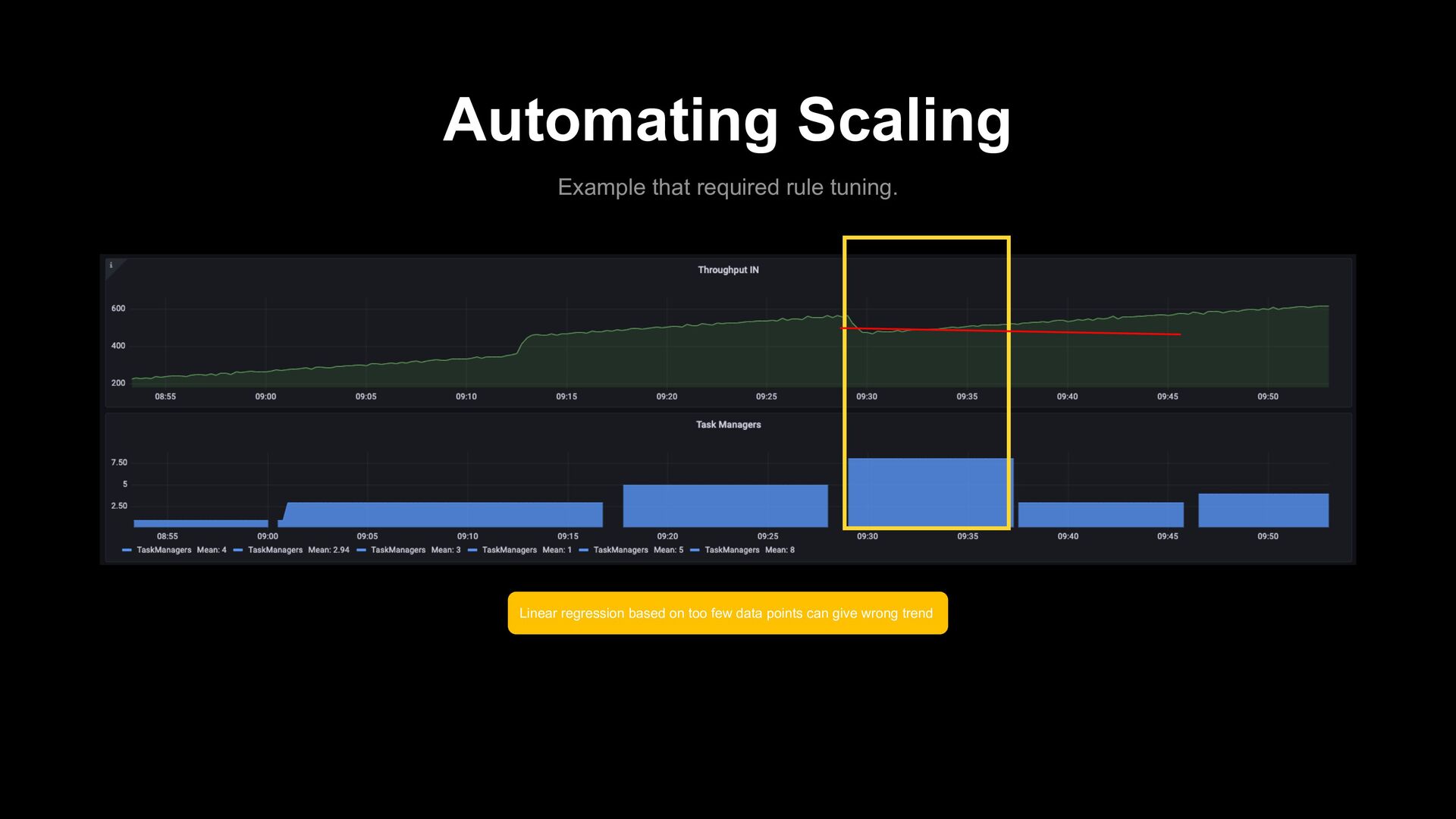
- Metrics : JVM_CPU_LOAD KAFKA_CONSUMER_LAG KAFKA_RECORDS_IN KAFKA_RECORDS_OUT Rules: LAG above 5 mins LAG increasing CPU load above 80% Safeguard rules: Scale < max scale Scale > min scale 2. Evaluate Scaling Rules 3. Estimate scale 4. Post evaluation check 1. Sample Monitoring metrics Predict: Using a linear regression model, estimate the appropriate scale
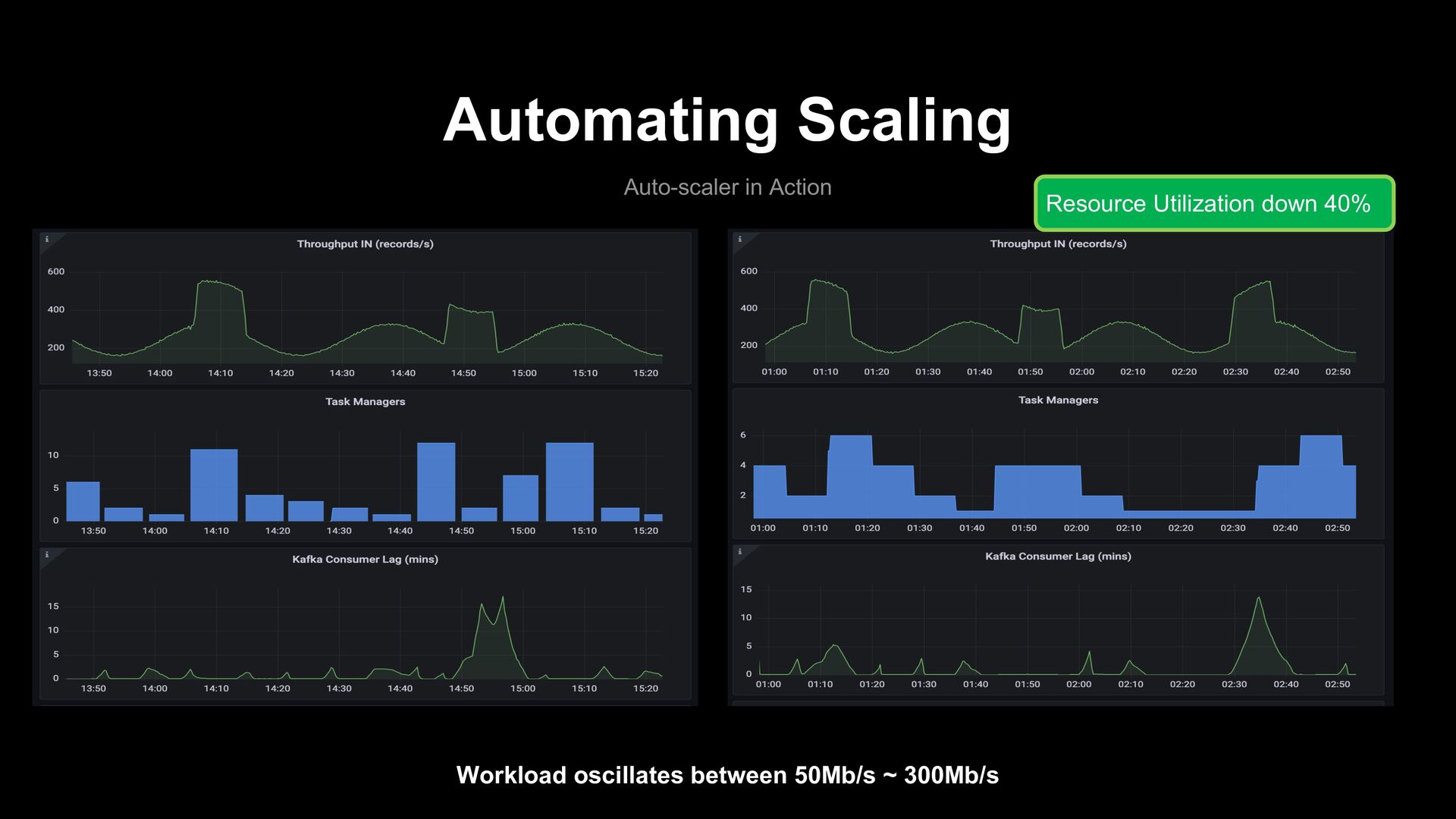
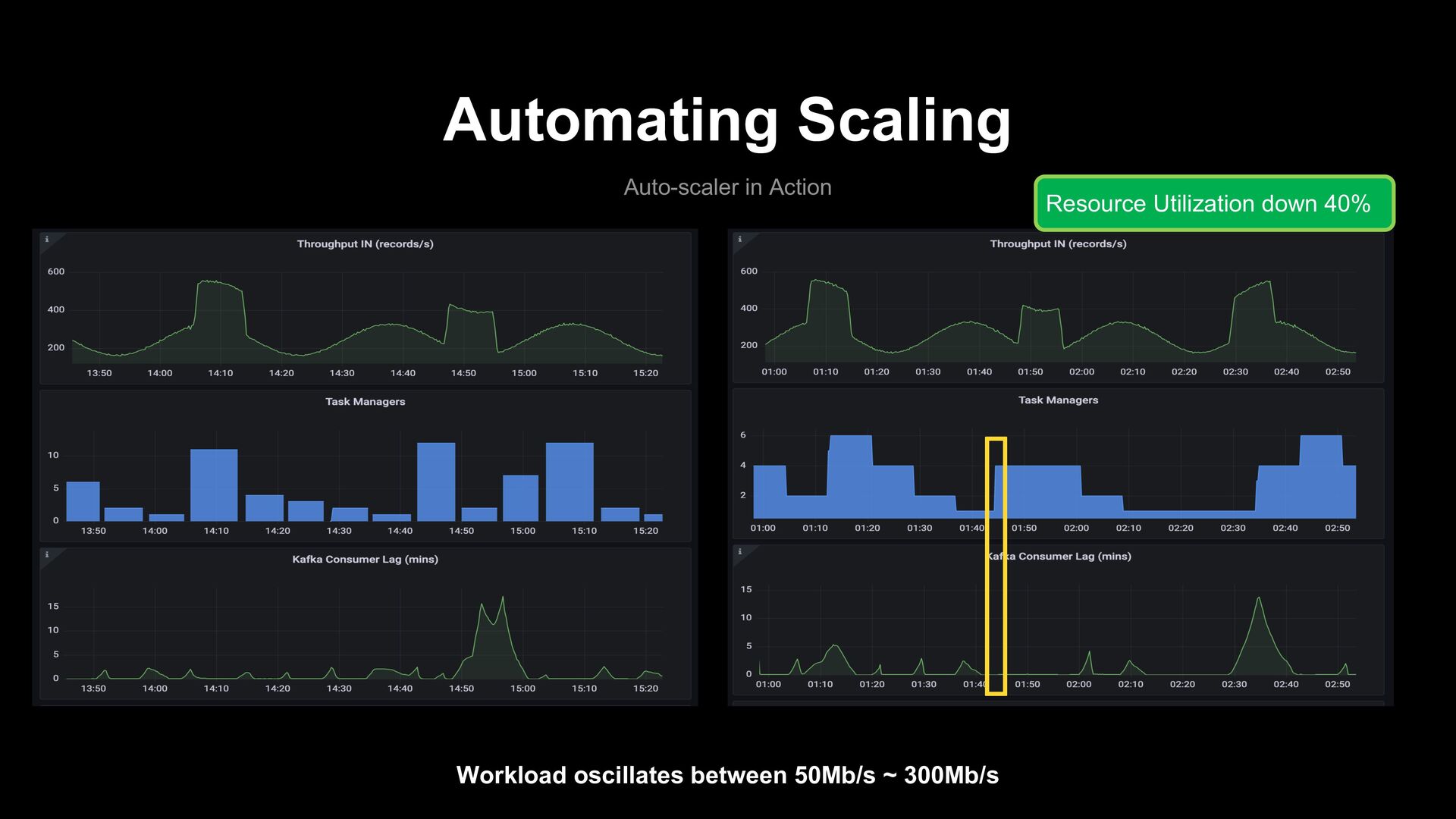
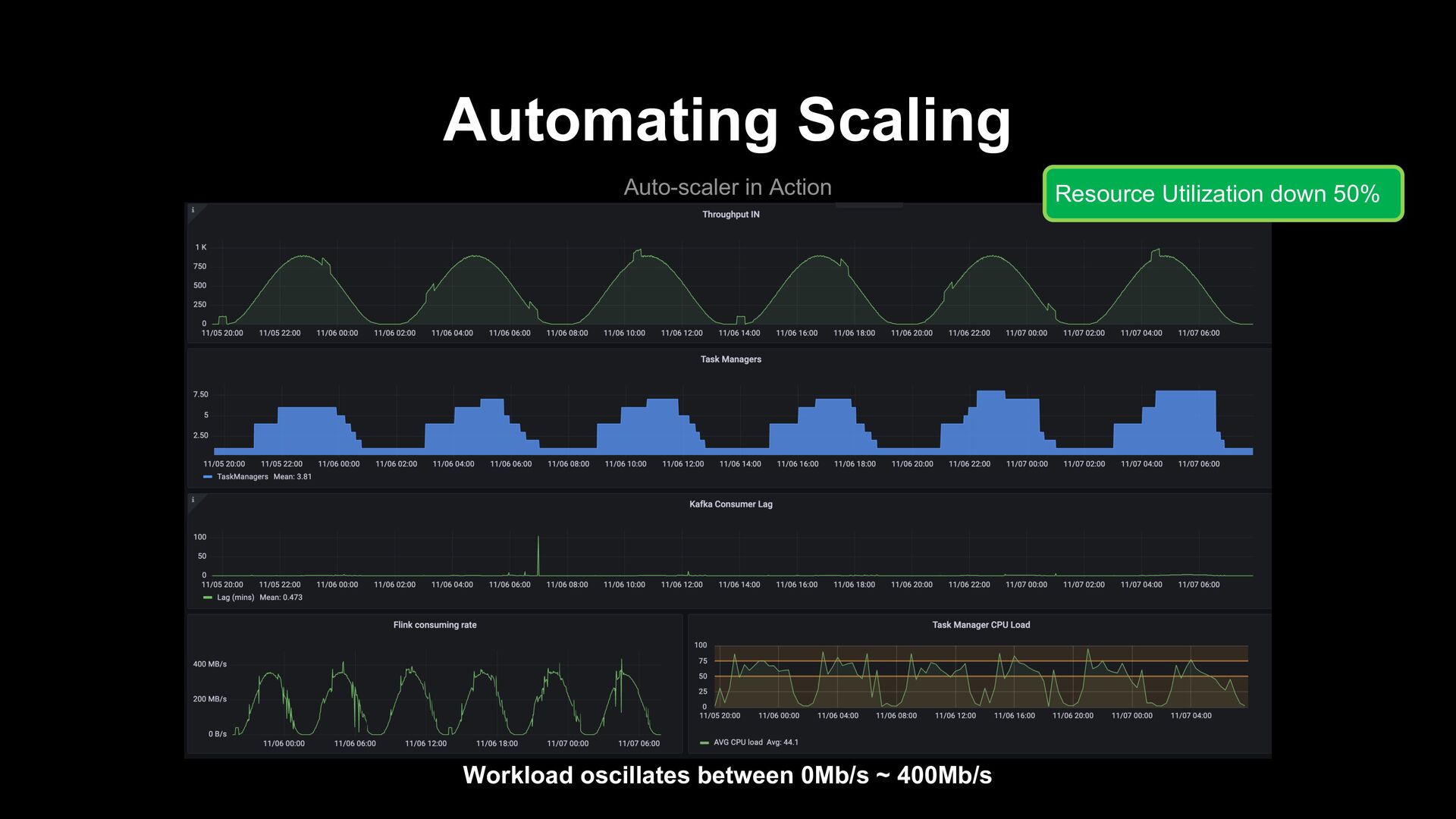
Any Flink cluster can subscribe to the auto-scaler. - Easily configurable and extendable. - Ability to setup predictive rules. Disadvantages - Can require some tuning to get best scaling performances.
: - 1. Automate Flink operations via CD pipeline - 2. Introduce an auto-scaler that also integrate with the CD pipeline • Future work: • Improve the prediction model • Integrate the auto-scaler with other technologies (e.g Spark Streaming)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}