moved to ZOZO, Inc. after going through a complicated business reason (M&A). Immediately after that, I was suddenly summoned by the boss at the time and started to launch the data infrastructure in a complete trial and error situation, and here I am. I was a backend engineer, however, as an infrastructure specialist who worked together in those days was assigned to another project, leaving me a message, “Shio-chan can do infrastructure all right”, I started working for infrastructure. ZOZO, Inc. Technology Division ML / Data Department Data Platform Section Techlead Takehiro Shiozaki
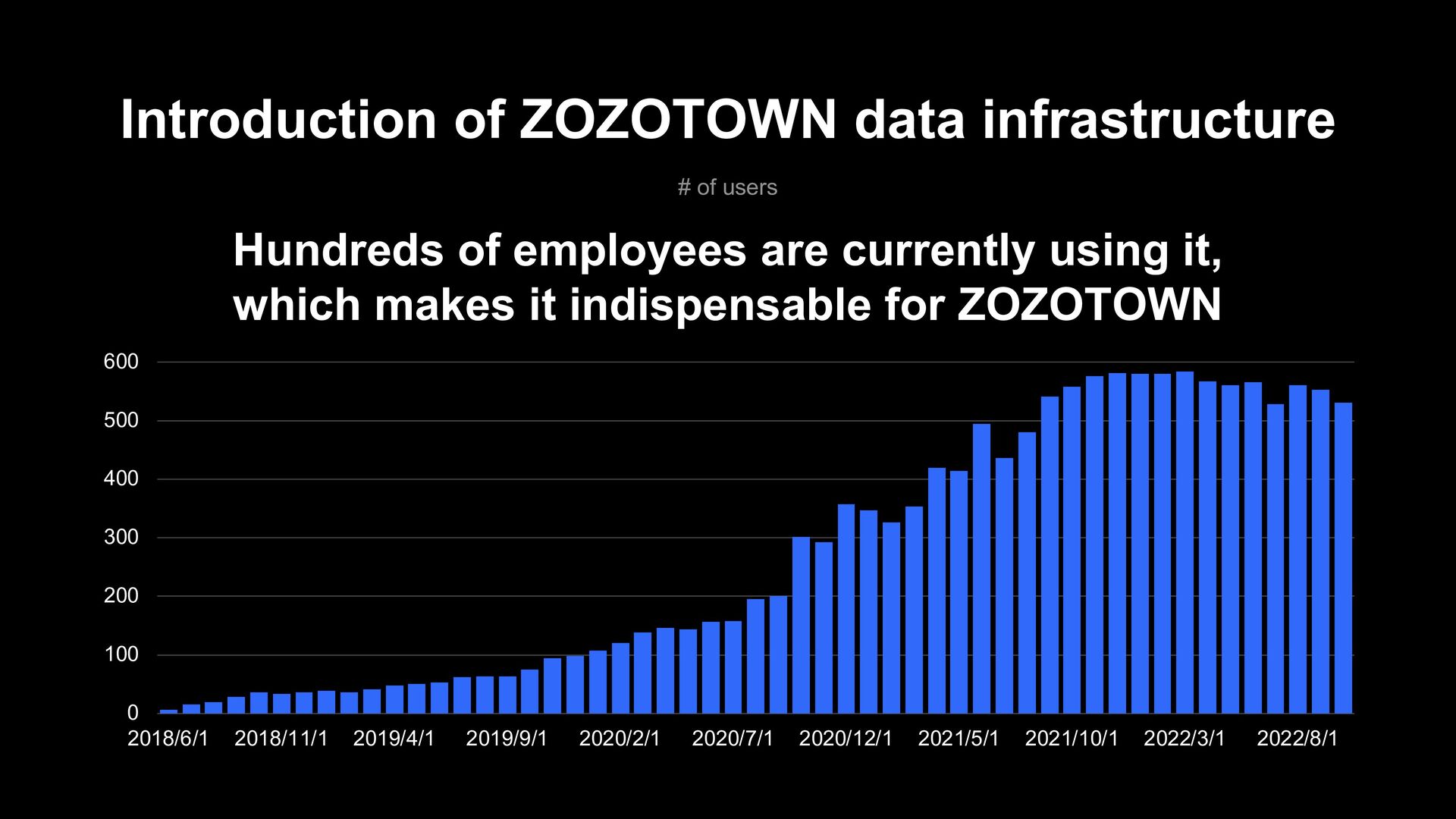
200 300 400 500 600 2018/6/1 2018/11/1 2019/4/1 2019/9/1 2020/2/1 2020/7/1 2020/12/1 2021/5/1 2021/10/1 2022/3/1 2022/8/1 Hundreds of employees are currently using it, which makes it indispensable for ZOZOTOWN
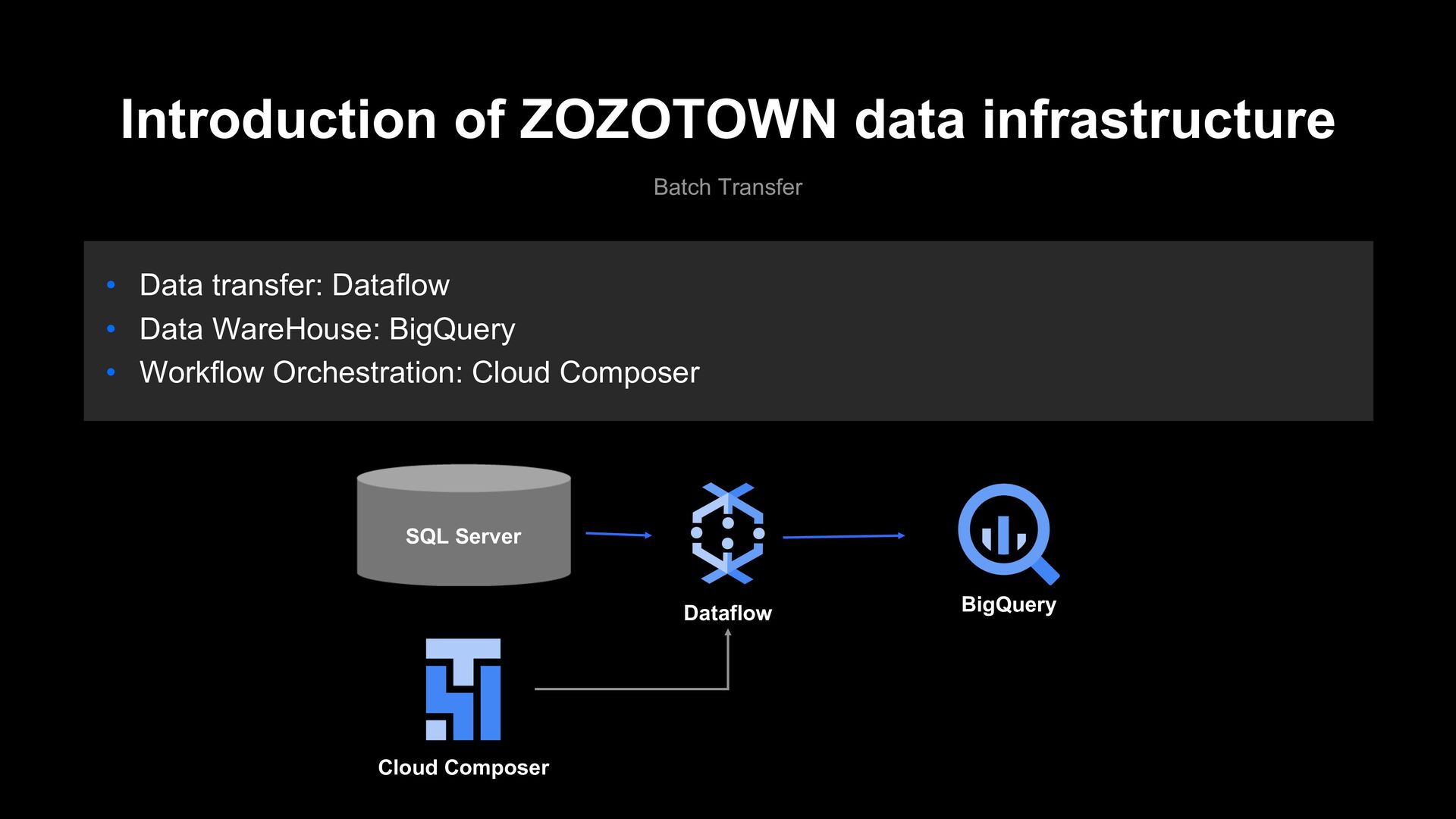
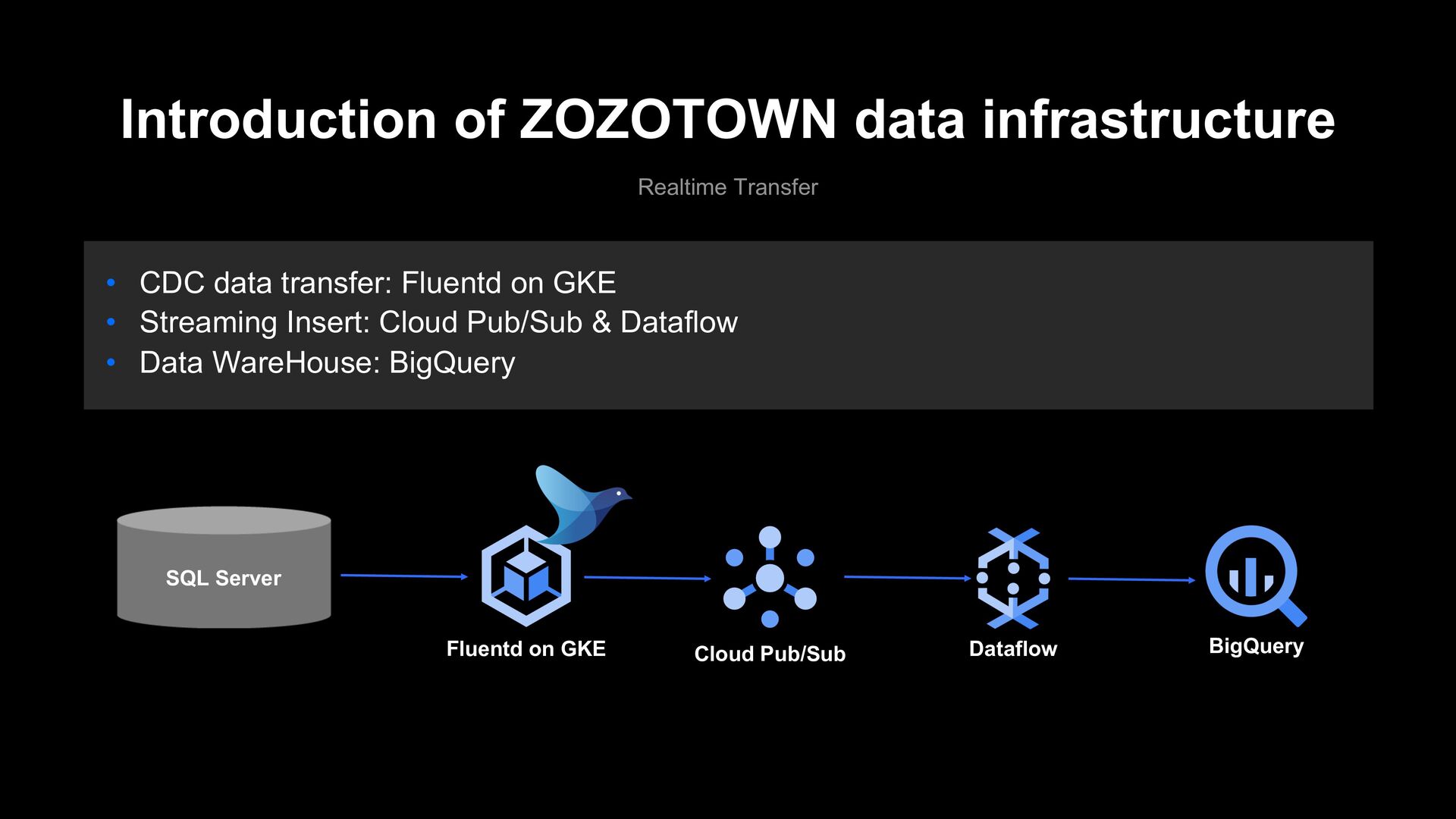
technical choice mistake made in the beginning." • Data infrastructure was small in the very early days • We started building a data infrastructure on GCP in April 2018 • The “current” architecture is a simple one, however, the early days architecture had its “original sin” • From here, I will explain the original sin we have committed and how we have atoned for them • I hope whoever builds the data infrastructure in the future does not commit the same sin
systems have appeared compared to the current architecture • Both AWS and GCP are used • Repeated copying of copies • the architecture was complicated, and operation was difficult • Why did this happen…? SQL Server BigQuery SQL Server EC2 S3 EC2
very moment of committing the original sin. • Initially, data was collected into Redshift • However, since we did not have the know-how or personnel to do database tuning, we migrated to BigQuery. • Understanding of data flow at that time • S3: We had reasonable understanding • SQL Server(Intermediate database): We knew it existed, but we were not familiar with it • Upstream: Unknown land, must have existed somewhere • Our Original Sin: Acquired data where it was easy to do so • Under normal circumstances, we should have stepped into an unknown land bravely SQL Server SQL Server Redshift S3 EC2
• Some tables’ rows were physically deleted, and some tables’ row were not Long transfer time • The transfer process, which should normally be done only once, was being performed multiple times Long lead time to add new tables • A different team managed the intermediate system • it was necessary to work across multiple teams Various negative effects caused by the Original Sin These were barriers that prevented data utilization
whether the data infrastructure was really useful • We had limited man-hours and personnel • We did not have know-how to build a data infrastructure • I was originally a backend engineer who wrote Web API by Ruby on Rails • I believed the self-proclaimed copy • It was a complete copy "within the data used in their work” • Everyone was a liar in the end, but no one was to be blamed In the phase of give it a shot, it was a rational decision to make it (I want to believe it)
rebuilt from scratch • In the state of NewGame+ • From ETL to ELT • Abolished conversion process during transfer • Transform after storing raw data in BigQuery • Redesigning at security level • For Systems that handle PII, such as mail magazine distribution systems • Implemented pinpointed viewing restrictions by column-level permission management
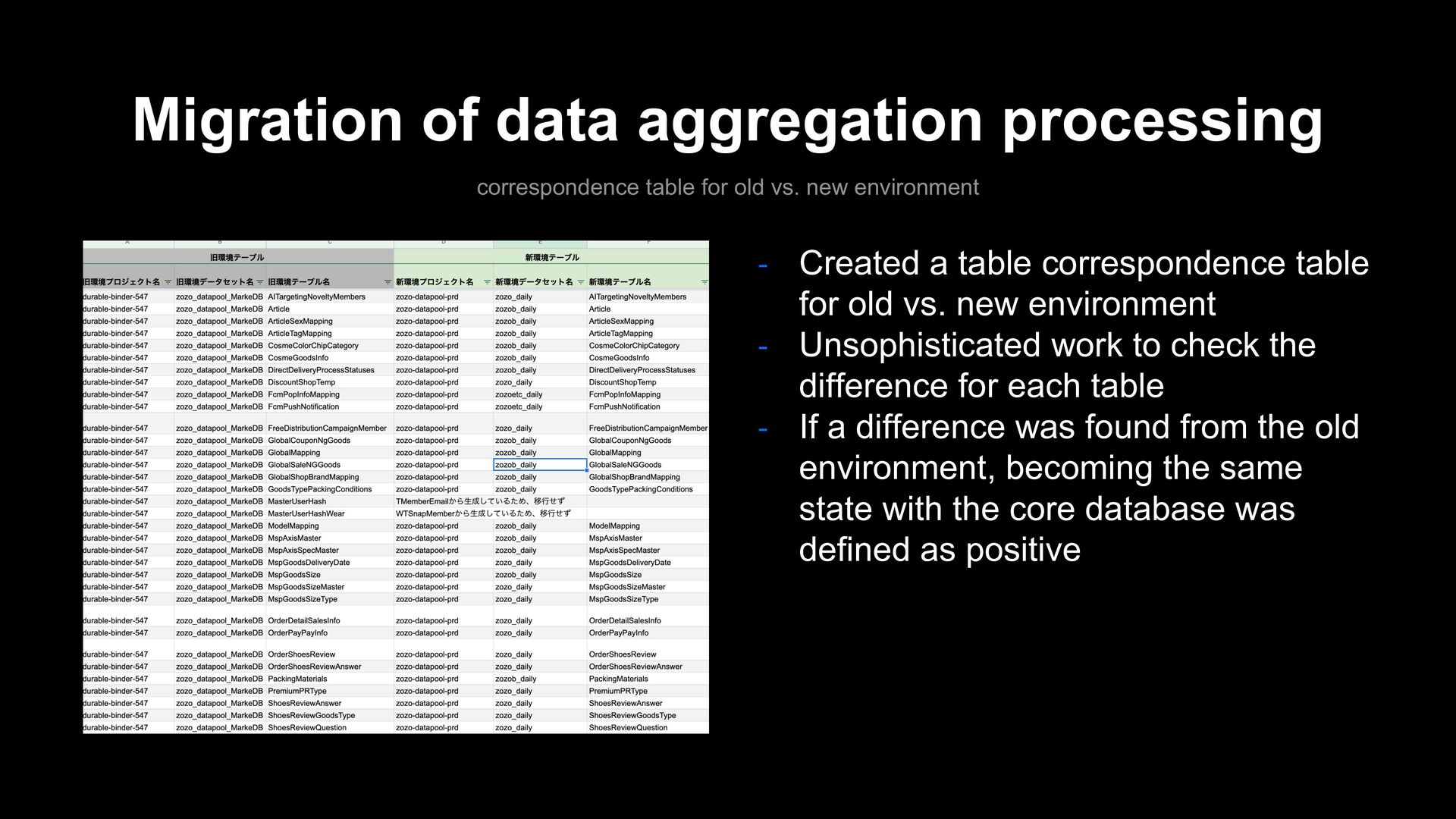
new environment - Created a table correspondence table for old vs. new environment - Unsophisticated work to check the difference for each table - If a difference was found from the old environment, becoming the same state with the core database was defined as positive
there are too many users and user departments, it was impossible to identify the exact scope of impact • A system created by an engineer who left the company was working without handing over • Aggregation processing which was not noticed even by the user - Using audit logs l JOBS_BY_ORGANIZATION was used to accurately grasp places where the old system was used
- Found the keystone by visualizing the data aggregation processing - Find mart (keystone) referenced by many data aggregation processing - Separated data marts that should be migrated with priority and data marts that can be postponed without problems - Batches and BIs with no administrators were also terminated as soon as they were found
possible - Retired the old systems gradually - Tables for which reference was not made for a certain period were deleted from the old system - Separate GCP project was provided for those who want to refer to the data of the old system - Only a limited number of people were granted viewing permission - To avoid referencing data from the old system without realizing it
specific examples that cannot be introduced here, please see the tech blog - There are many examples of using GCP and BigQuery in addition to migration stories - https://techblog.zozo.com/entry/data- infrastructure-replacement
only data that is absolutely guaranteed to be correct • Acquire data from upstream whenever possible • Make friends with the person in charge of the system that generates the data • Don’t ask people, ask audit Logs • People make mistakes and leave the company • Audit logs illuminate the truth • Don't mix up, it's dangerous • A spoonful of dirty water in a barrel full of wine is still dirty water • Schopenhauer's Law Of Entropy • Distinguish between quality-assured and non-quality-assured data
• However, we suffered for several years due to a big selection mistake (original sin) we made in the early stages of building it • Atonement took years • I hope this story is used as a teacher by negative example for those who will build data infrastructure in the future
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}