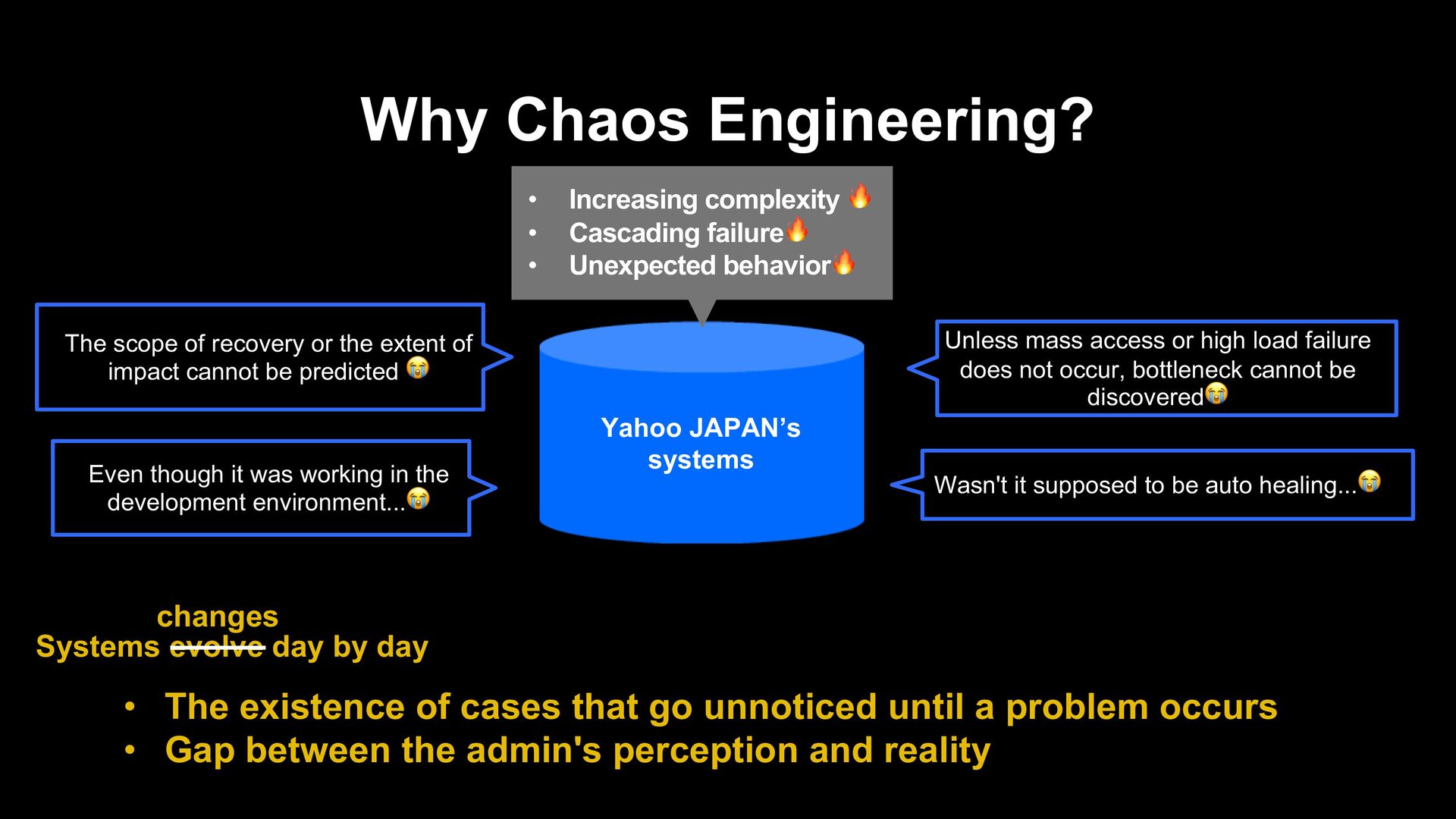
unnoticed until a problem occurs • Gap between the admin's perception and reality The scope of recovery or the extent of impact cannot be predicted ! Even though it was working in the development environment...! Unless mass access or high load failure does not occur, bottleneck cannot be discovered! Wasn't it supposed to be auto healing...! Systems evolve day by day changes Yahoo JAPAN’s systems • Increasing complexity ! • Cascading failure! • Unexpected behavior!
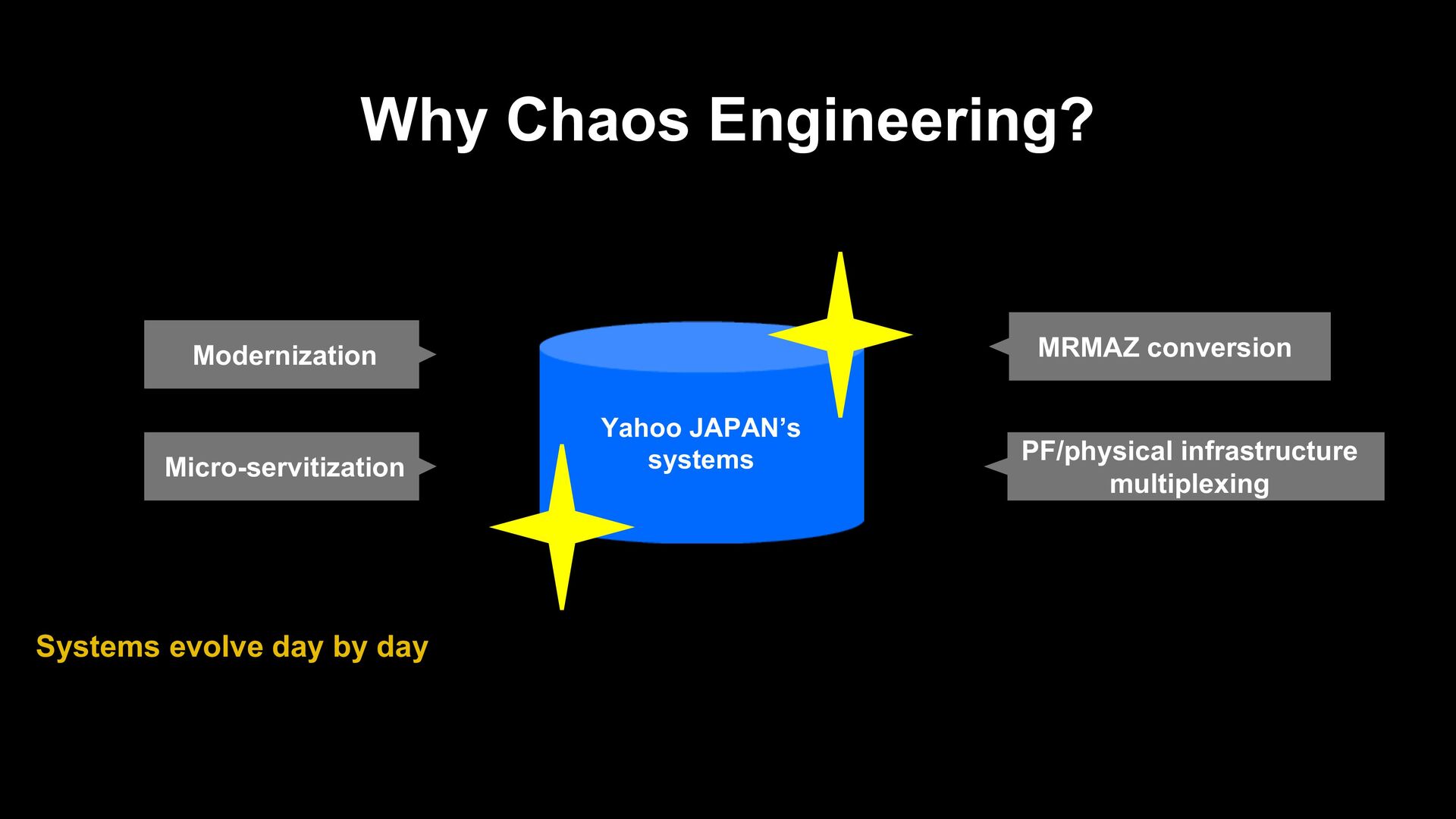
and minimize damage • Is redundancy still maintained even when components go down? • Can the operation flow work as intended? • An approach to prevent failure: CICD automation, observability, pair/mob pro • An approach to mitigate the impact of failures: MRMAZ, canary release Yahoo JAPAN's measures so far: Introducing chaos engineering
experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production. http://principlesofchaos.org A proactive (immunization) approach to the failures of the distributed system
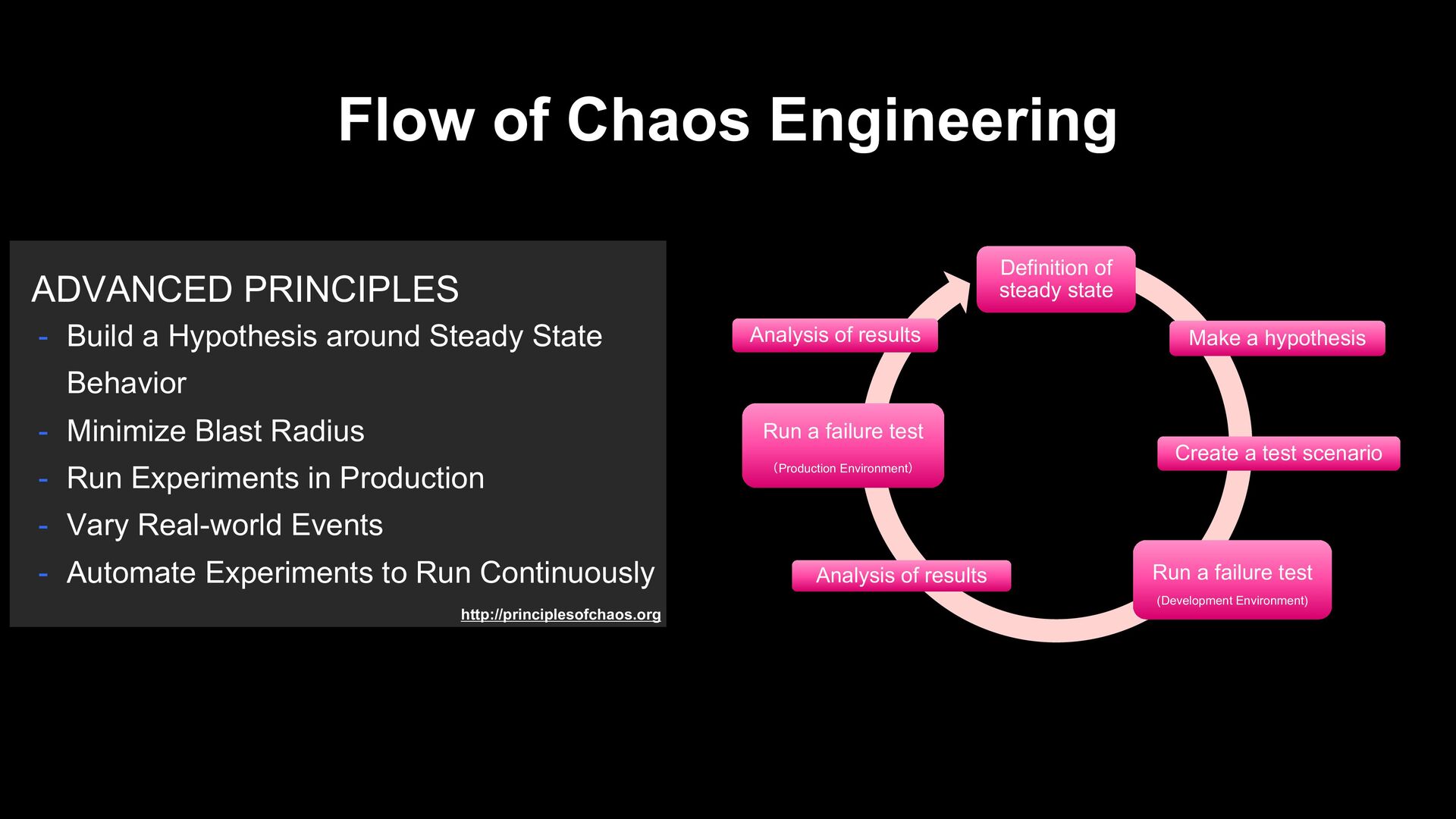
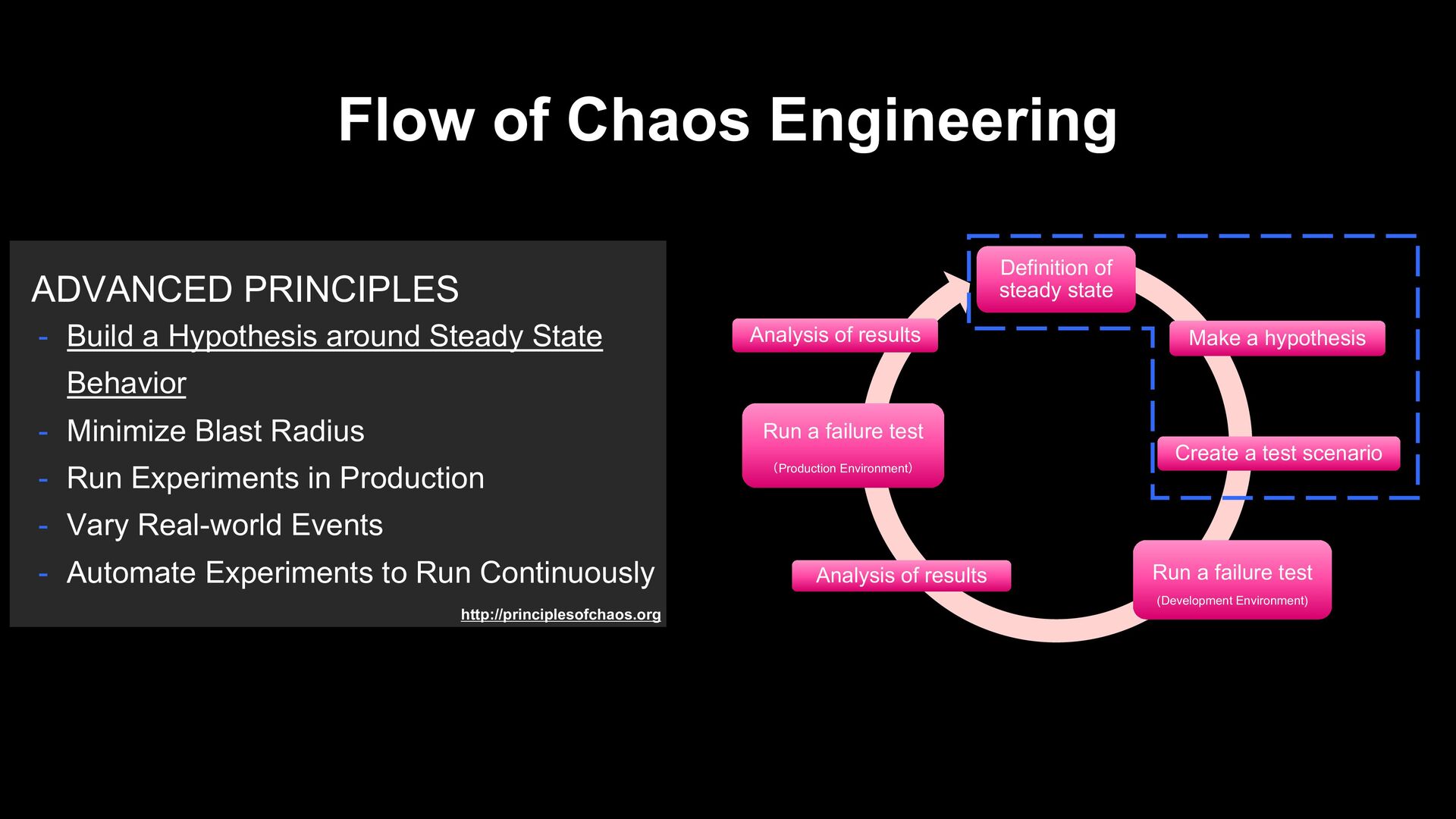
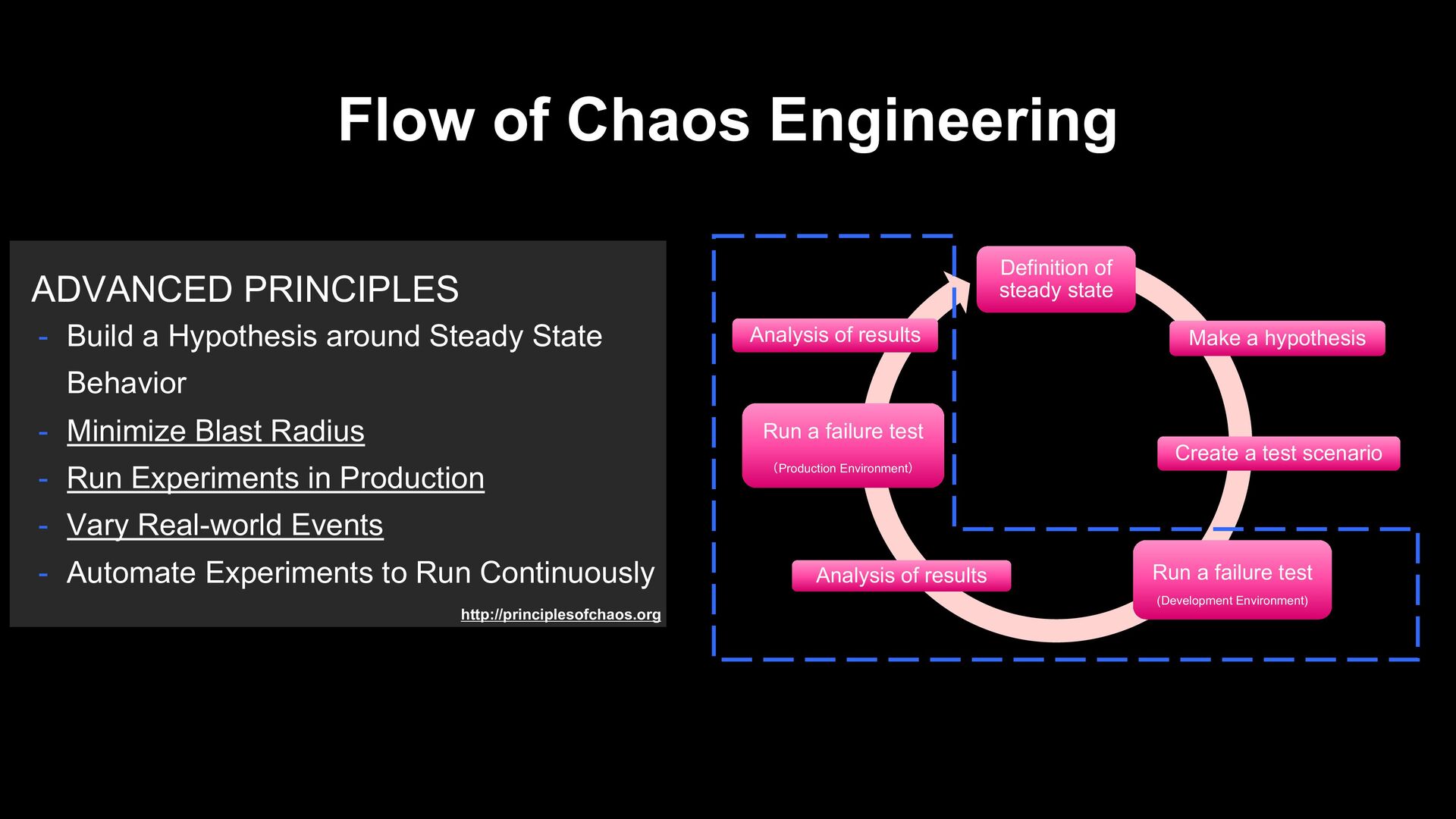
Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously
state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results - Build a Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously
state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results - Build a Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously
state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results - Build a Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously
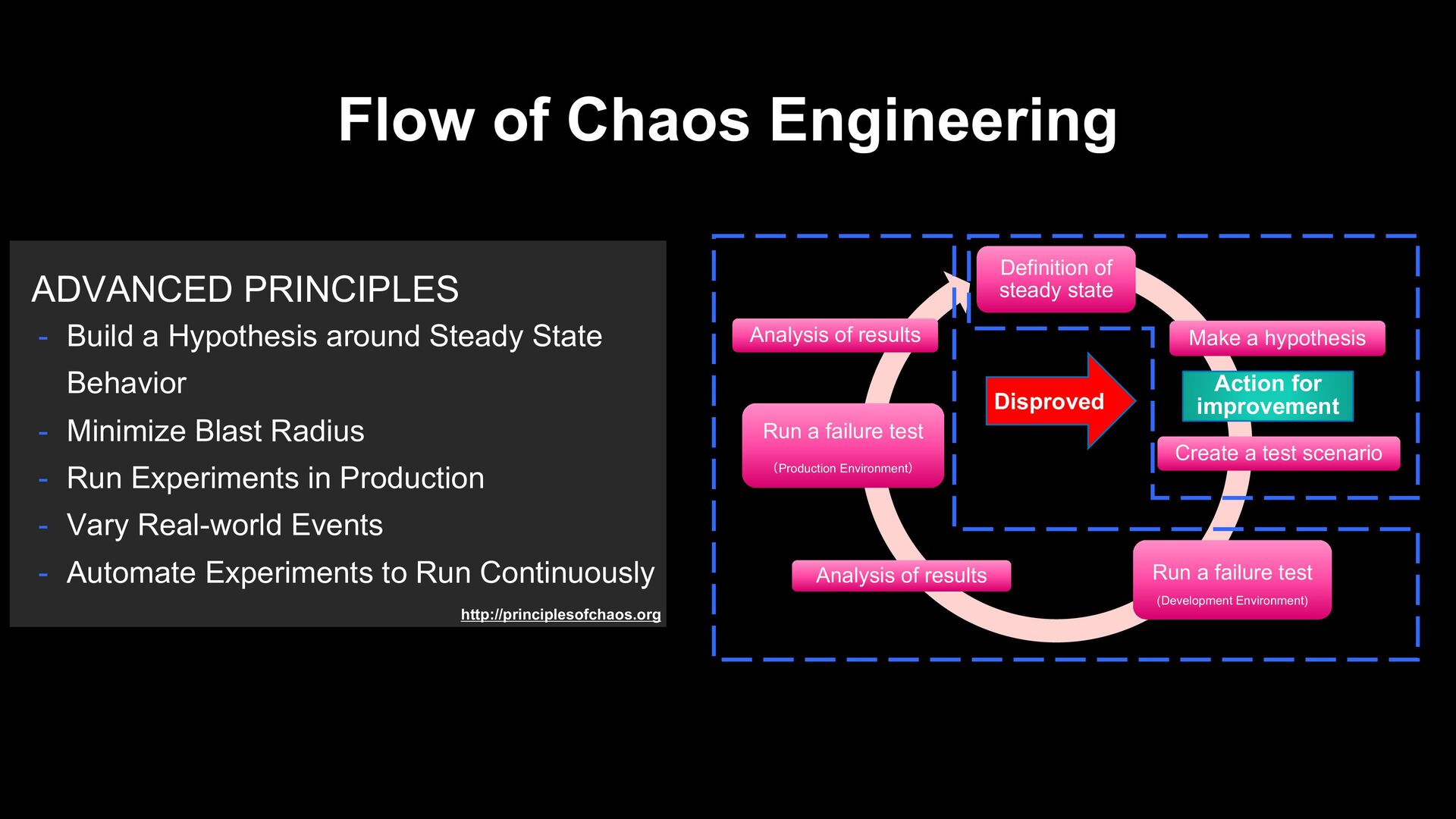
state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results Action for improvement Disproved - Build a Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously
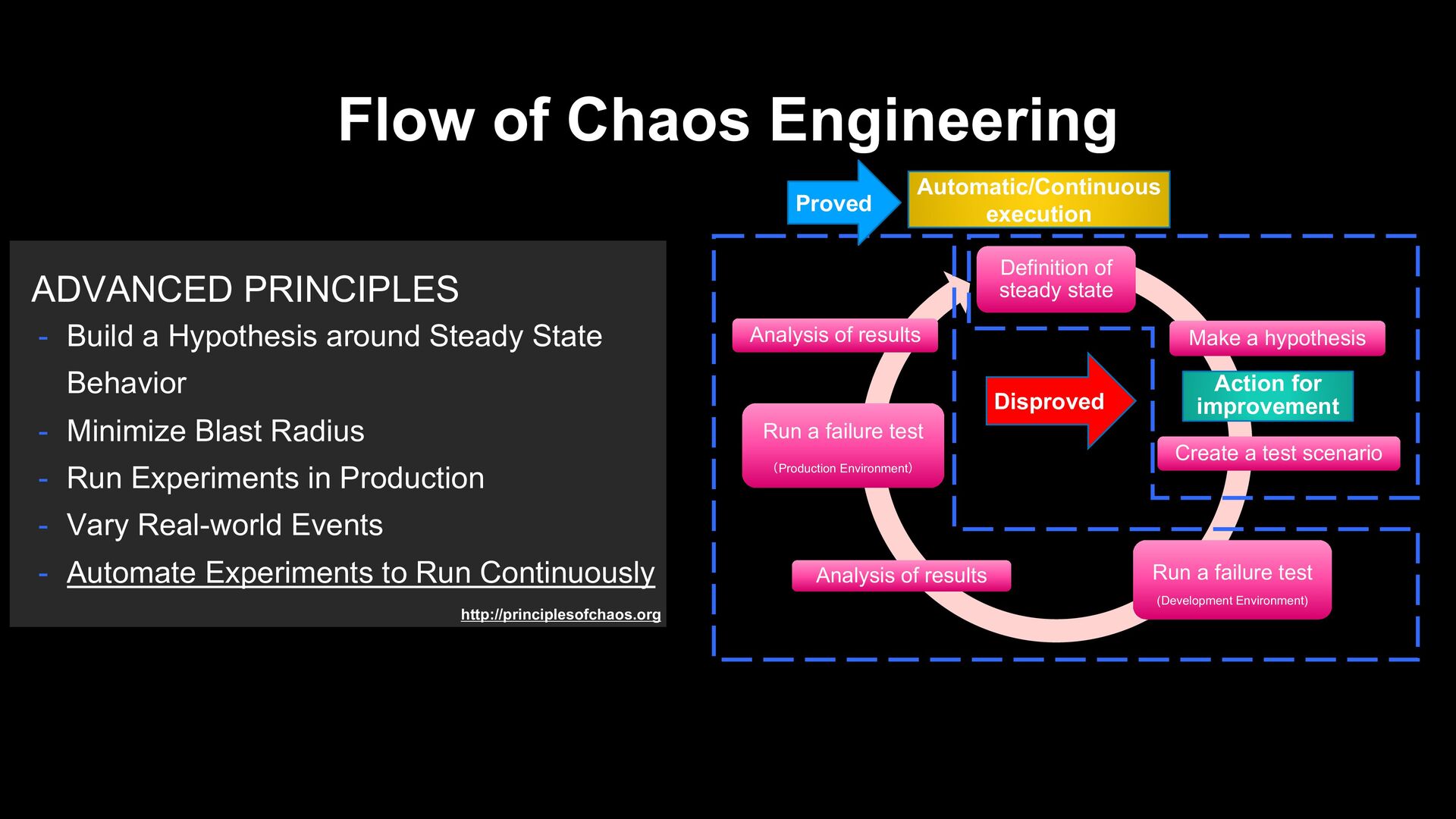
state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results Proved Action for improvement Disproved - Build a Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously Automatic/Continuous execution
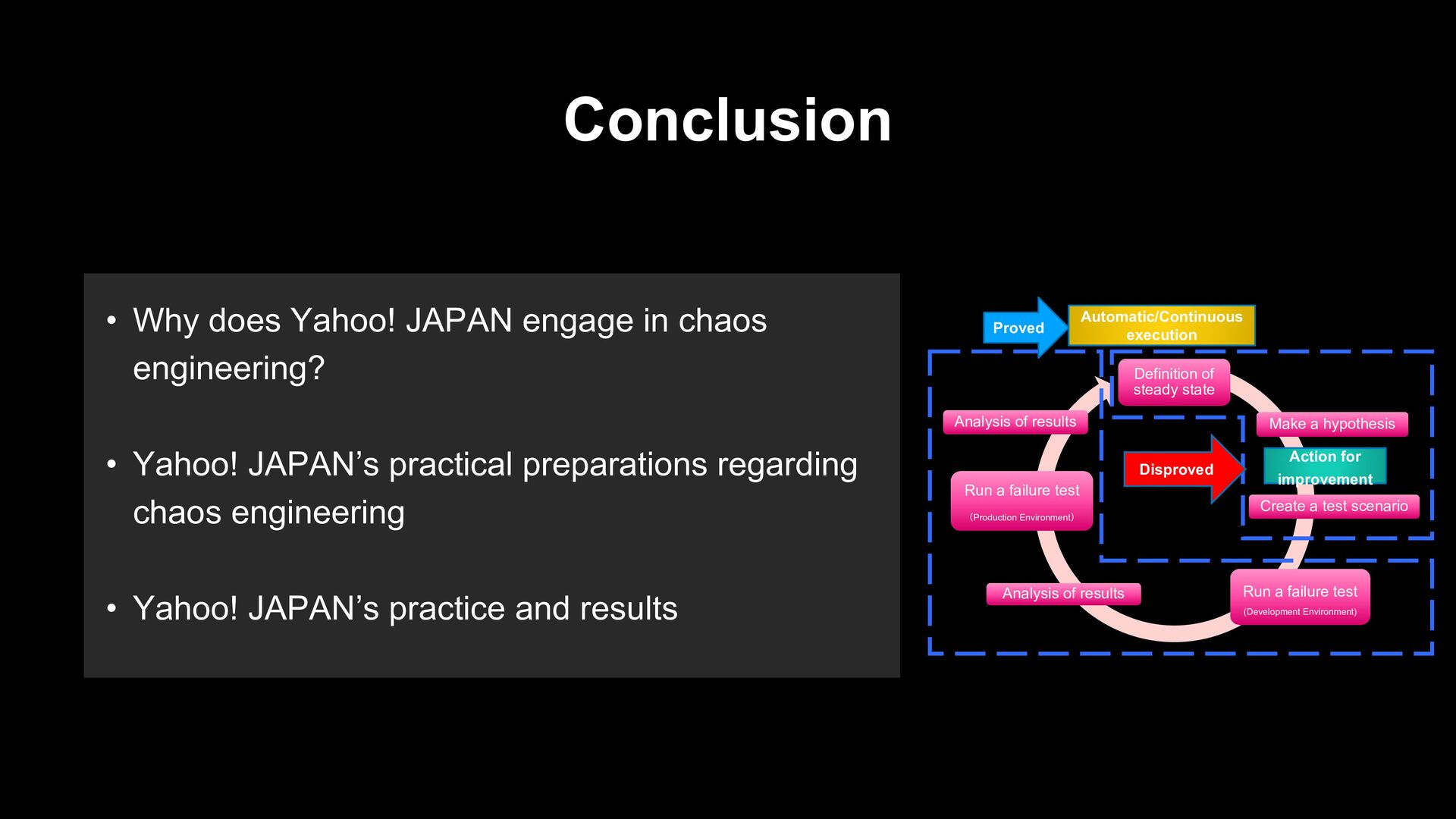
state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results • Continue to find problems • Experiential learning cycle Proved Action for improvement Disproved - Build a Hypothesis around Steady State Behavior - Minimize Blast Radius - Run Experiments in Production - Vary Real-world Events - Automate Experiments to Run Continuously Automatic/Continuous execution
not change even when an event occurs’ to create a hypothesis. Preparation of Chaos Execution Definition of steady state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results
‘The steady state does not change even when an event occurs’ to create a hypothesis. Specific examples of hypotheses created: ***Component *** ***Component ***Component pod What happens to the system when it fails? Create a hypothesis that the steady state does not change even if an event occurs ***Component goes into high load state • Request acceptance is not processed, and it takes time to deploy the app • If it continues for a long time, the automatic recovery will not work. • No impact on apps that are already running All users There is no effect on running apps, but there is an impact on app operations such as creation and deletion. ***Component: cpu high load cpu high load cpu attack for 1 pod with the same running function Success rate for *** command (Life and death monitoring) Not redundant There is an active standby function, but it is unknown at this time whether it will be redundant by enabling it Monitoring and alerting completed 1min/5min/30min Measure every 1 minute and fire if metrics is NG for 5 minutes Steady-state metrics SLI/SLO
to improved stability • It becomes a monitoring as well as SLI check • Know you don’t know • Office work... • Don't add too many scenarios or make it too detailed ***Component *** ***Component What happens to the system when it fails? Create a hypothesis that the steady state does not change even if an event occurs ***Component goes into high load state • Request acceptance is not processed, and it takes time to deploy the app • If it continues for a long time, the automatic recovery will not work. • No impact on apps that are already running All users There is no effect on running apps, but there is an impact on app operations such as creation and deletion. ***Component: cpu high load cpu high load cpu attack for 1 pod with the same running function Success rate for *** command (Life and death monitoring) Not redundant There is an active standby function, but it is unknown at this time whether it will be redundant by enabling it Monitoring and alerting completed 1min/5min/30min Measure every 1 minute and fire if metrics is NG for 5 minutes Steady-state metrics SLI/SLO ***Component pod
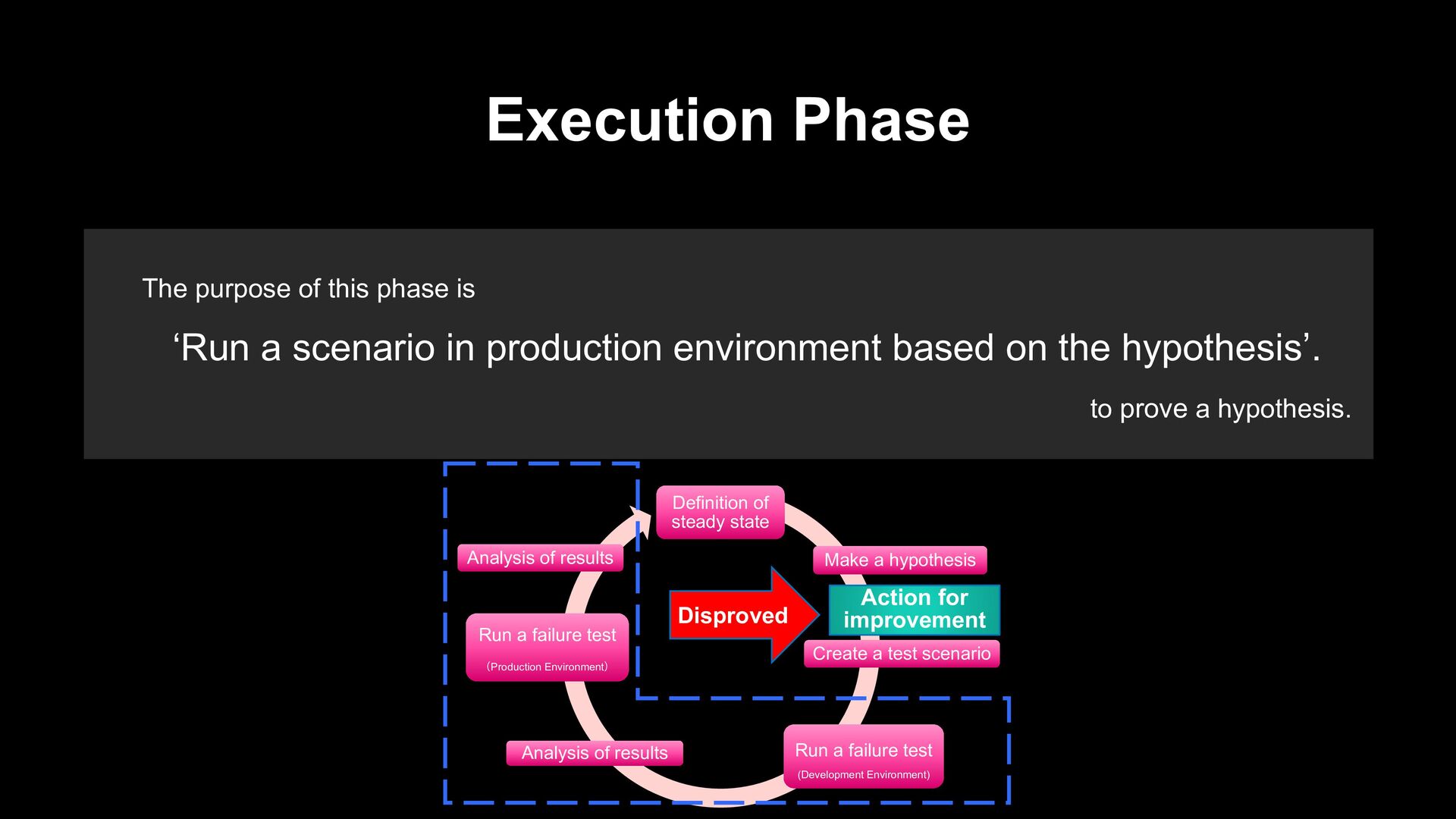
scenario in production environment based on the hypothesis’. to prove a hypothesis. Definition of steady state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results Action for improvement Disproved
chaos engineering in the production environment A common method of implementing chaos engineering - Start in dev/stg environment with recovery procedure - Start with small failure domain: One API, pod/VM, cluster and AZ Ways devised at Yahoo - Targeted towards new release of the system (CaaS PF) - Chaos Engineering as default - Leading to improved robustness in the app
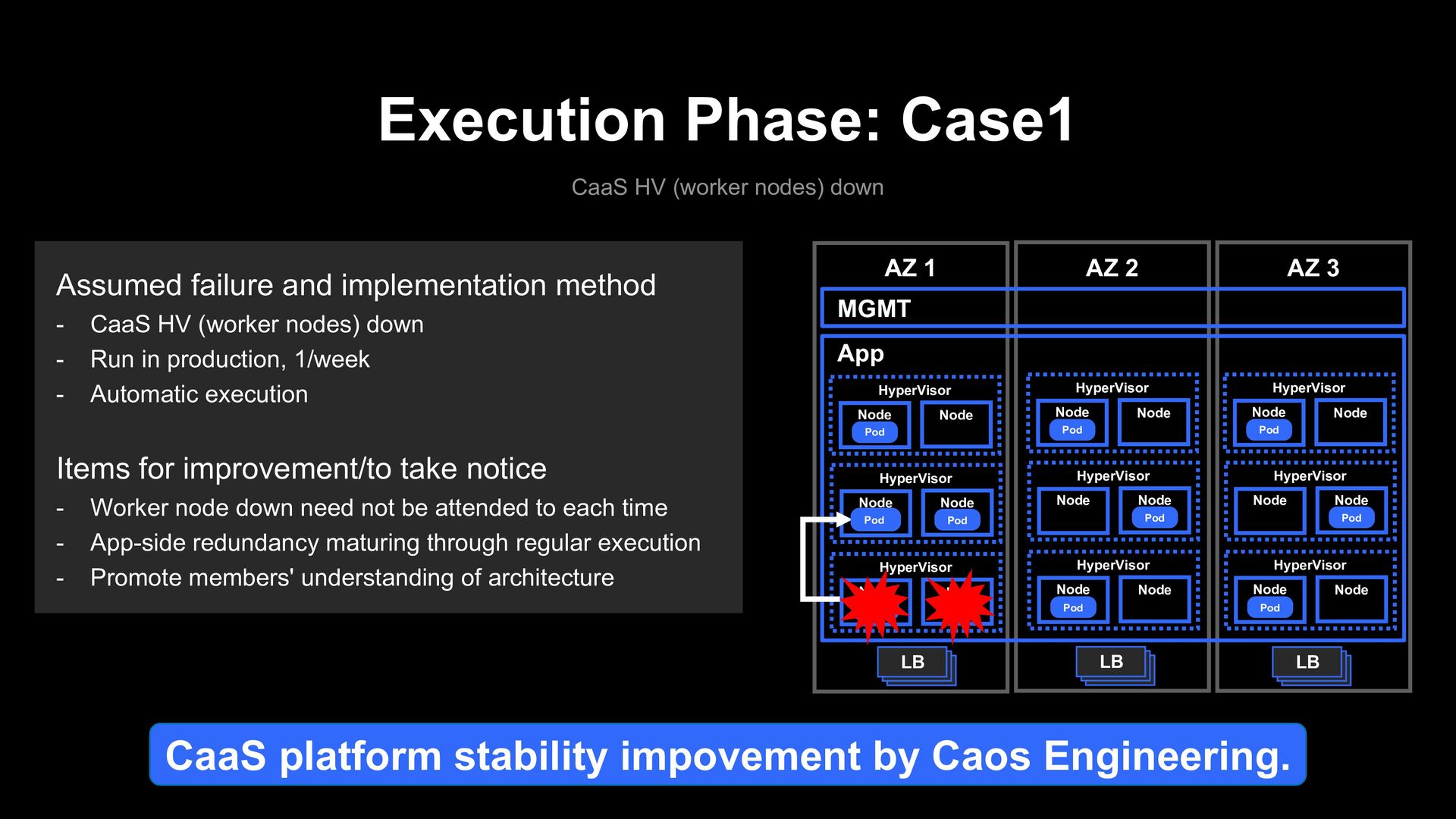
and implementation method - CaaS HV (worker nodes) down - Run in production, 1/week - Automatic execution Node HyperVisor Pod Node App MGMT AZ 1 AZ 2 AZ 3 Node HyperVisor Pod Node Node HyperVisor Pod Node LB Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node LB LB Pod
AZ 3 Node HyperVisor Pod Node Node HyperVisor Pod Node LB Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node LB LB Execution Phase: Case1 CaaS HV (worker nodes) down Assumed failure and implementation method - CaaS HV (worker nodes) down - Run in production, 1/week - Automatic execution Items for improvement/to take notice - Worker node down need not be attended to each time - App-side redundancy maturing through regular execution - Promote members' understanding of architecture Pod CaaS platform stability impovement by Caos Engineering.
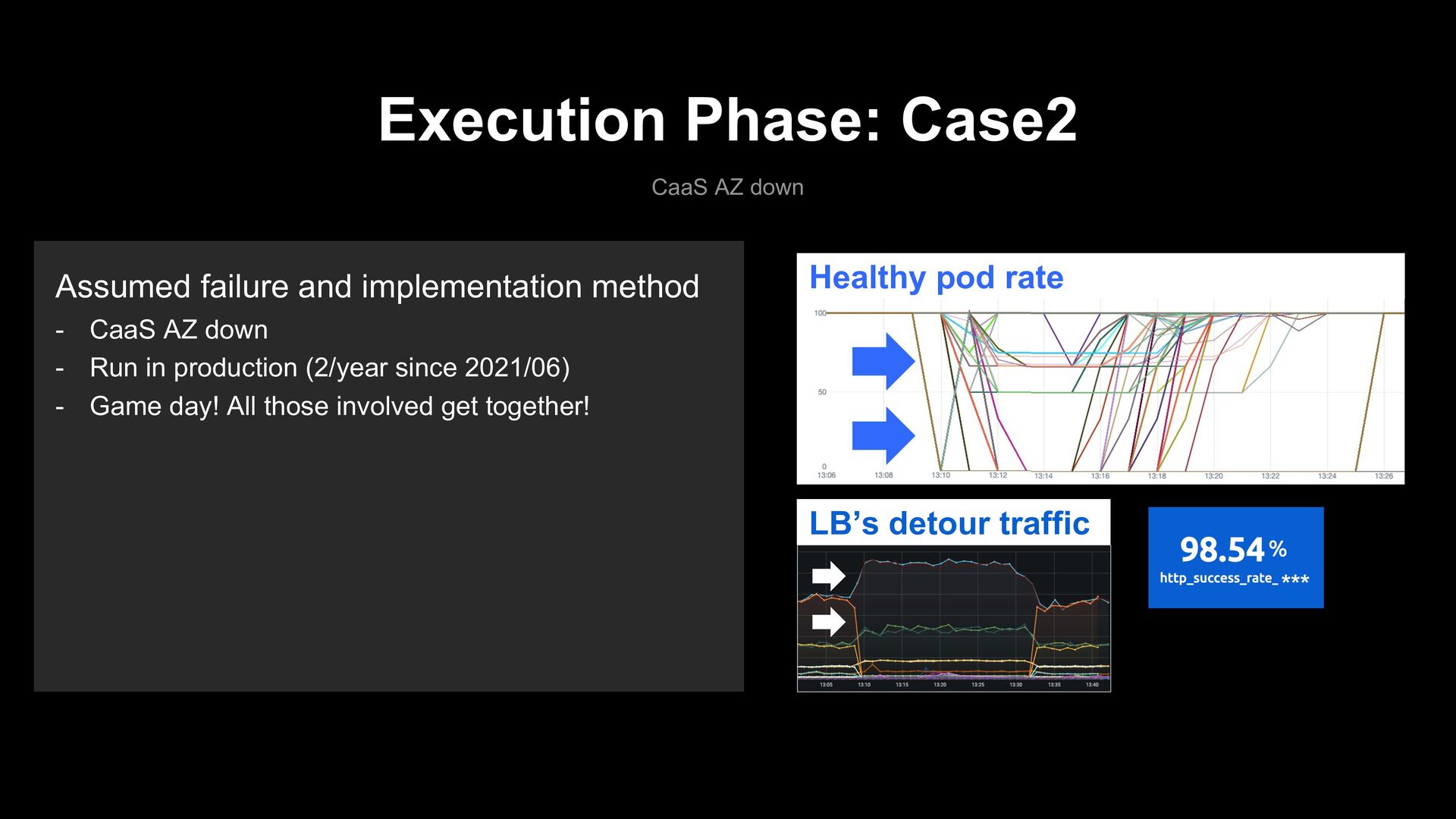
AZ 3 Node HyperVisor Pod Node Node HyperVisor Pod Node LB Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node Node HyperVisor Pod Node LB LB Execution Phase: Case2 CaaS AZ down Assumed failure and implementation method - CaaS AZ down - Run in production (2/year since 2021/06) - Game day! All those involved get together!
failure and implementation method - CaaS AZ down - Run in production (2/year since 2021/06) - Game day! All those involved get together! LB’s detour traffic ***
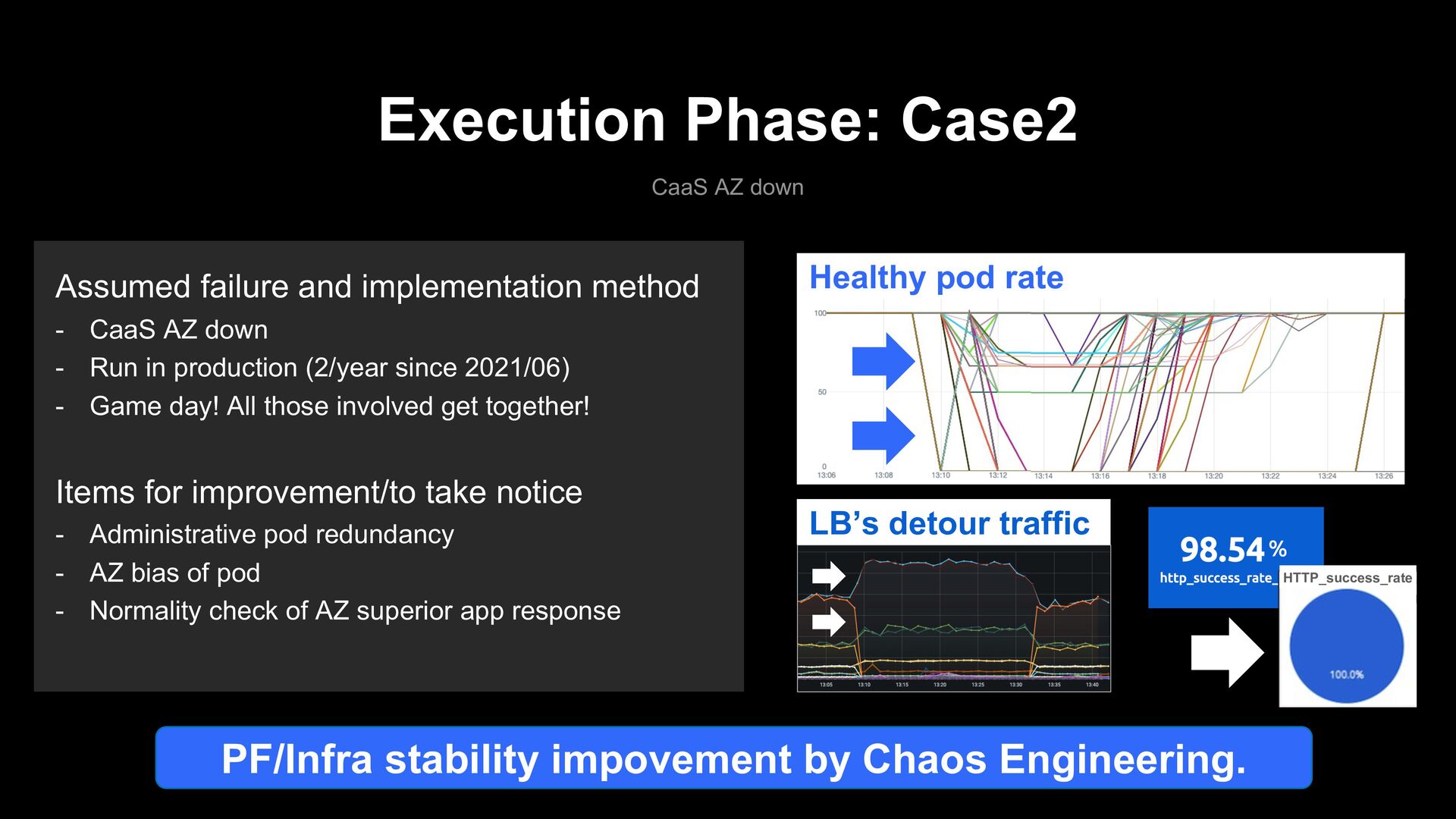
failure and implementation method - CaaS AZ down - Run in production (2/year since 2021/06) - Game day! All those involved get together! Items for improvement/to take notice - Administrative pod redundancy - AZ bias of pod - Normality check of AZ superior app response LB’s detour traffic *** HTTP_success_rate PF/Infra stability impovement by Chaos Engineering.
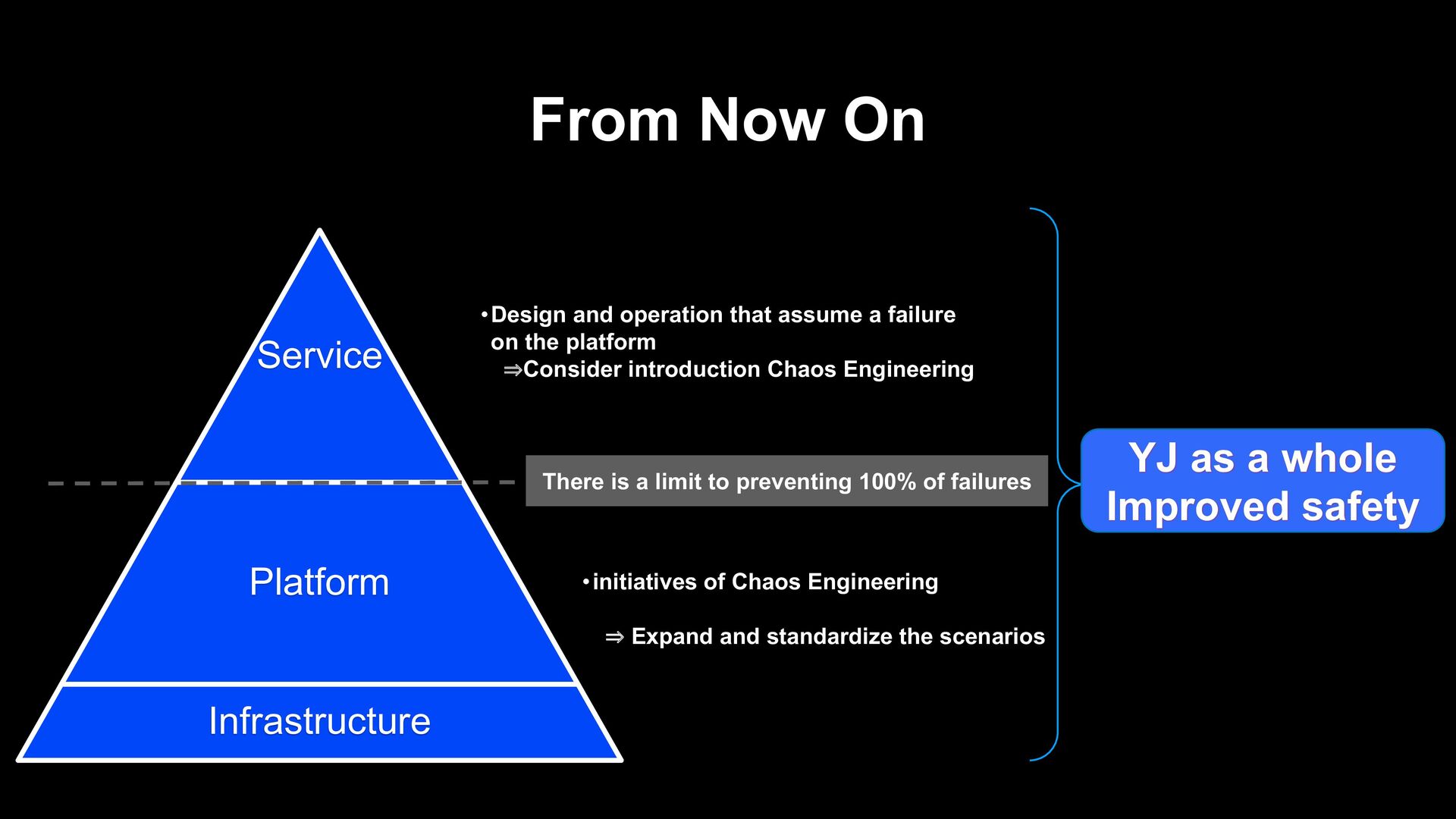
⇒ Expand and standardize the scenarios There is a limit to preventing 100% of failures YJ as a whole Improved safety •Design and operation that assume a failure on the platform ⇒Consider introduction Chaos Engineering
• Yahoo! JAPAN’s practical preparations regarding chaos engineering • Yahoo! JAPAN’s practice and results Definition of steady state Make a hypothesis Create a test scenario Run a failure test (Development Environment) Analysis of results Run a failure test (Production Environment) Analysis of results Proved Action for improvement Disproved Automatic/Continuous execution
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}