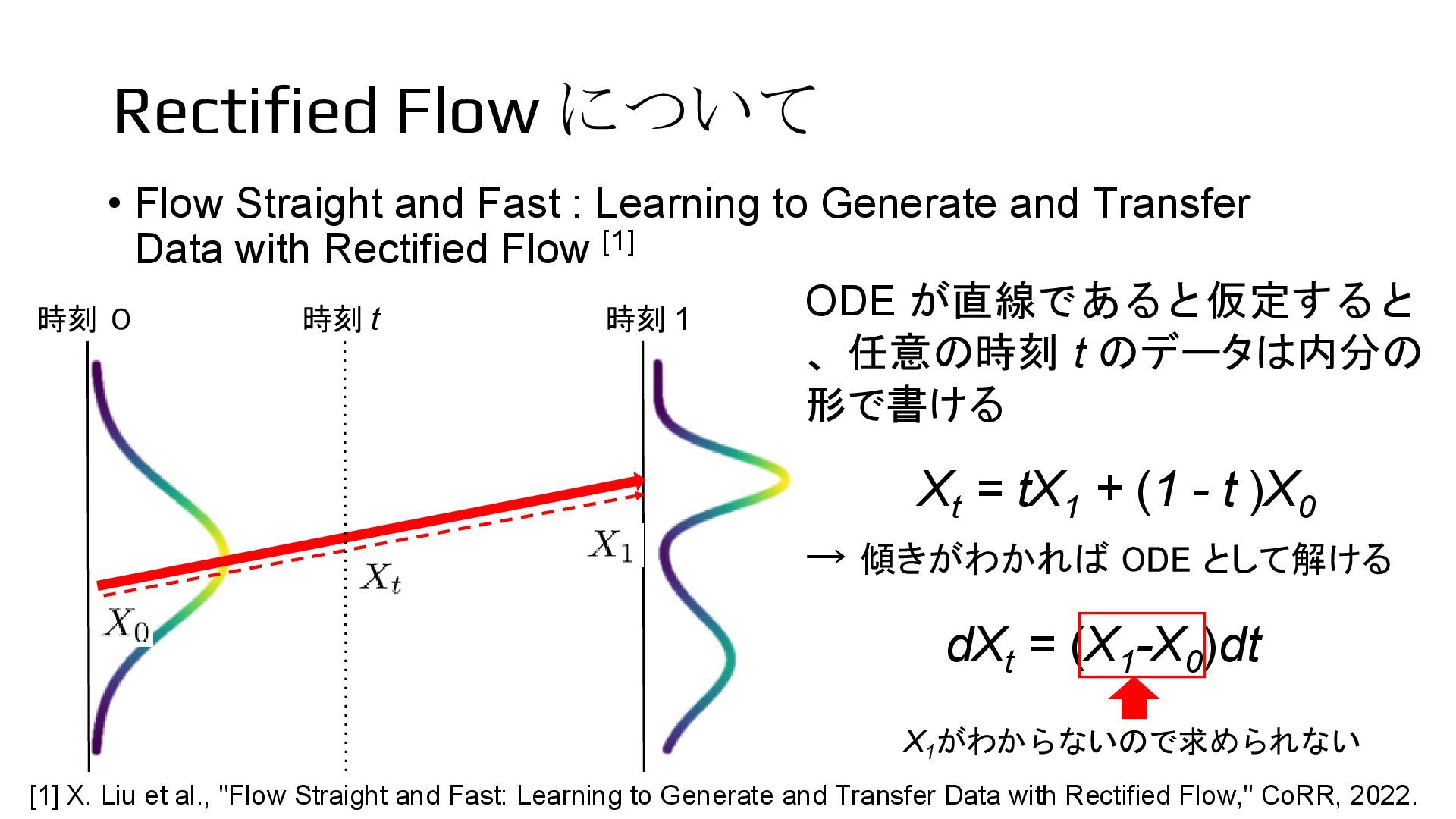
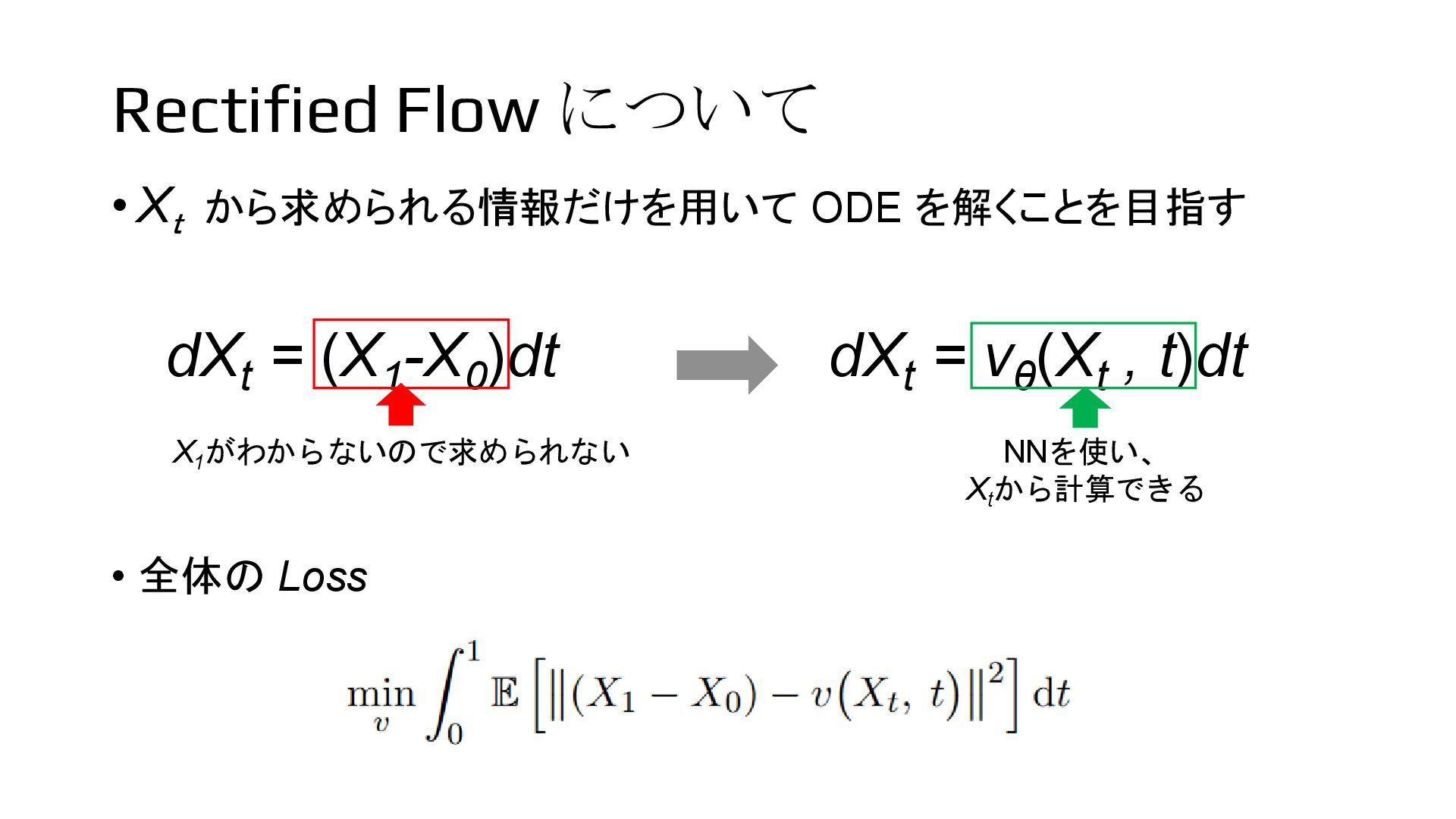
to Generate and Transfer Data with Rectified Flow [1] 時刻 0 時刻 1 時刻 t ODE が直線であると仮定すると 、任意の時刻 t のデータは内分の 形で書ける → 傾きがわかれば ODE として解ける dXt = (X1 -X0 )dt Xt = tX1 + (1 - t )X0 X1 がわからないので求められない [1] X. Liu et al., "Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow," CoRR, 2022.
{kind=link}
{kind=link}
![Rectified Flow [1] 簡単に言うと... • Diffusion Model の一手法 • 数](https://files.speakerdeck.com/presentations/89d1ec4c9c4946cbb3b28119ac9e5791/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
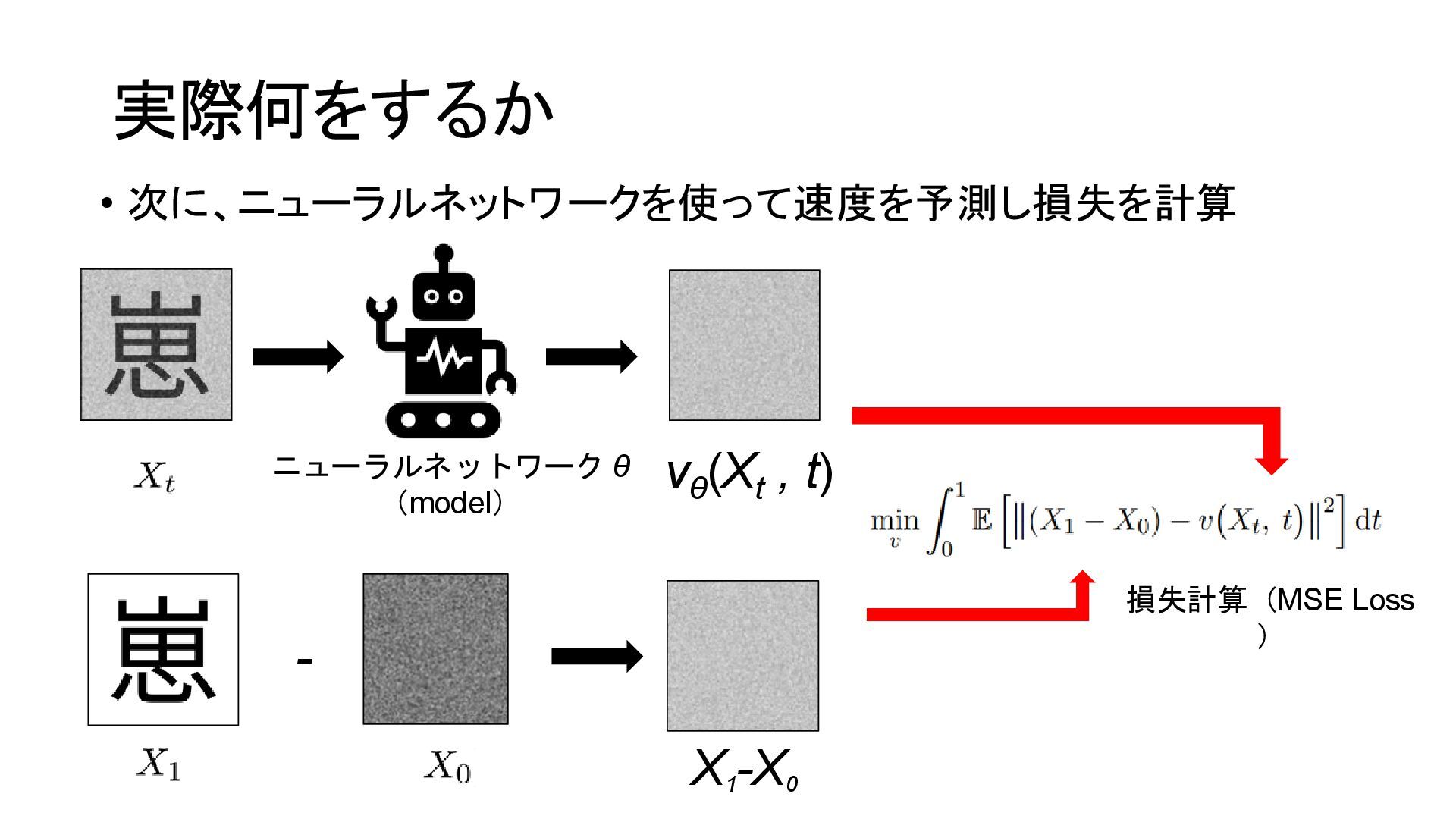{kind=link}
![ニューラルネットワーク θ には何を使う の? • U-Net [2] • 小さいので計算速度 が早い](https://files.speakerdeck.com/presentations/89d1ec4c9c4946cbb3b28119ac9e5791/slide_8.jpg){kind=link}
![ニューラルネットワーク θ には何を使う の? • Diffusion Transformer [3] • 大きいので計算速度が遅い](https://files.speakerdeck.com/presentations/89d1ec4c9c4946cbb3b28119ac9e5791/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
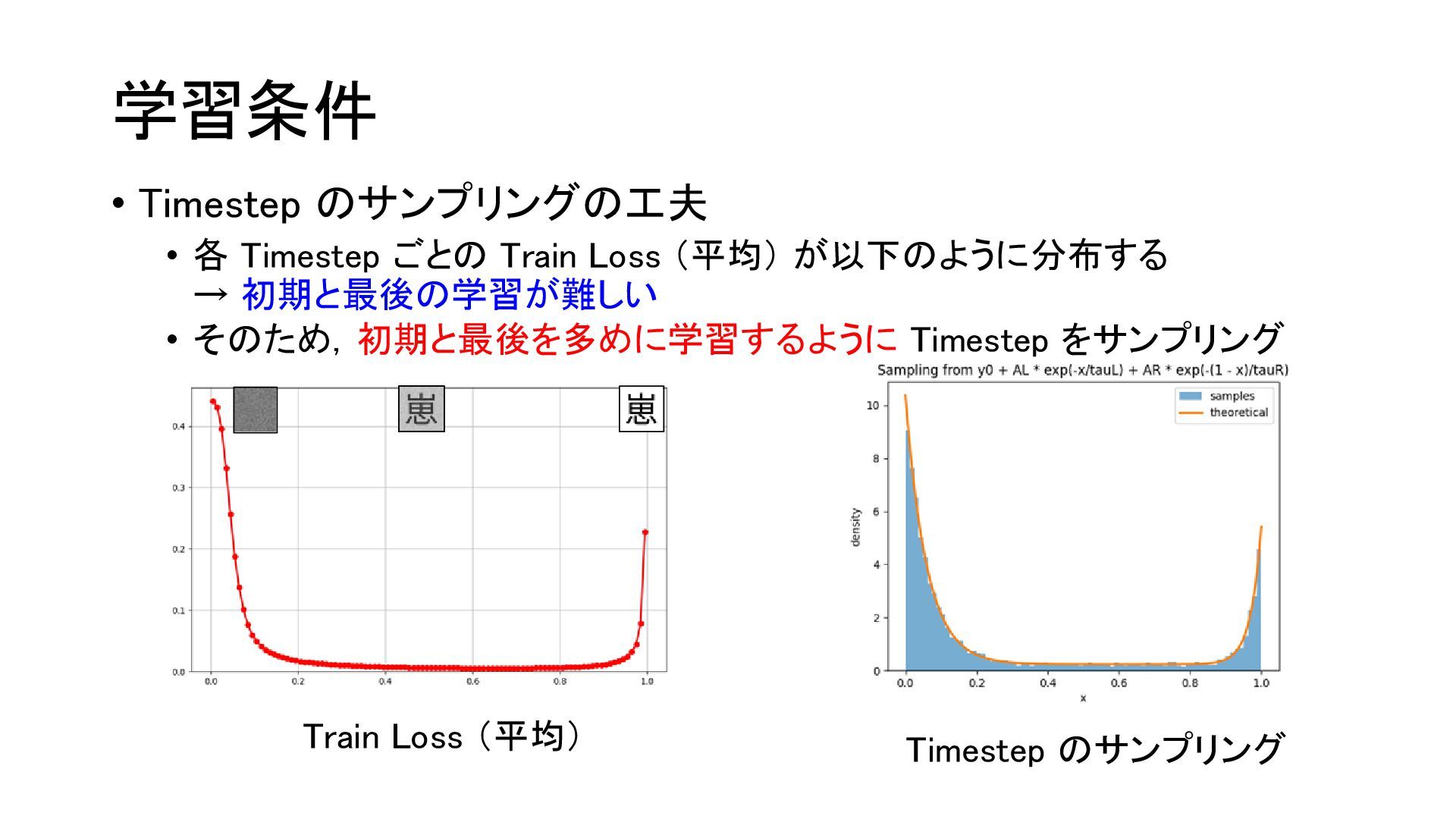{kind=link}
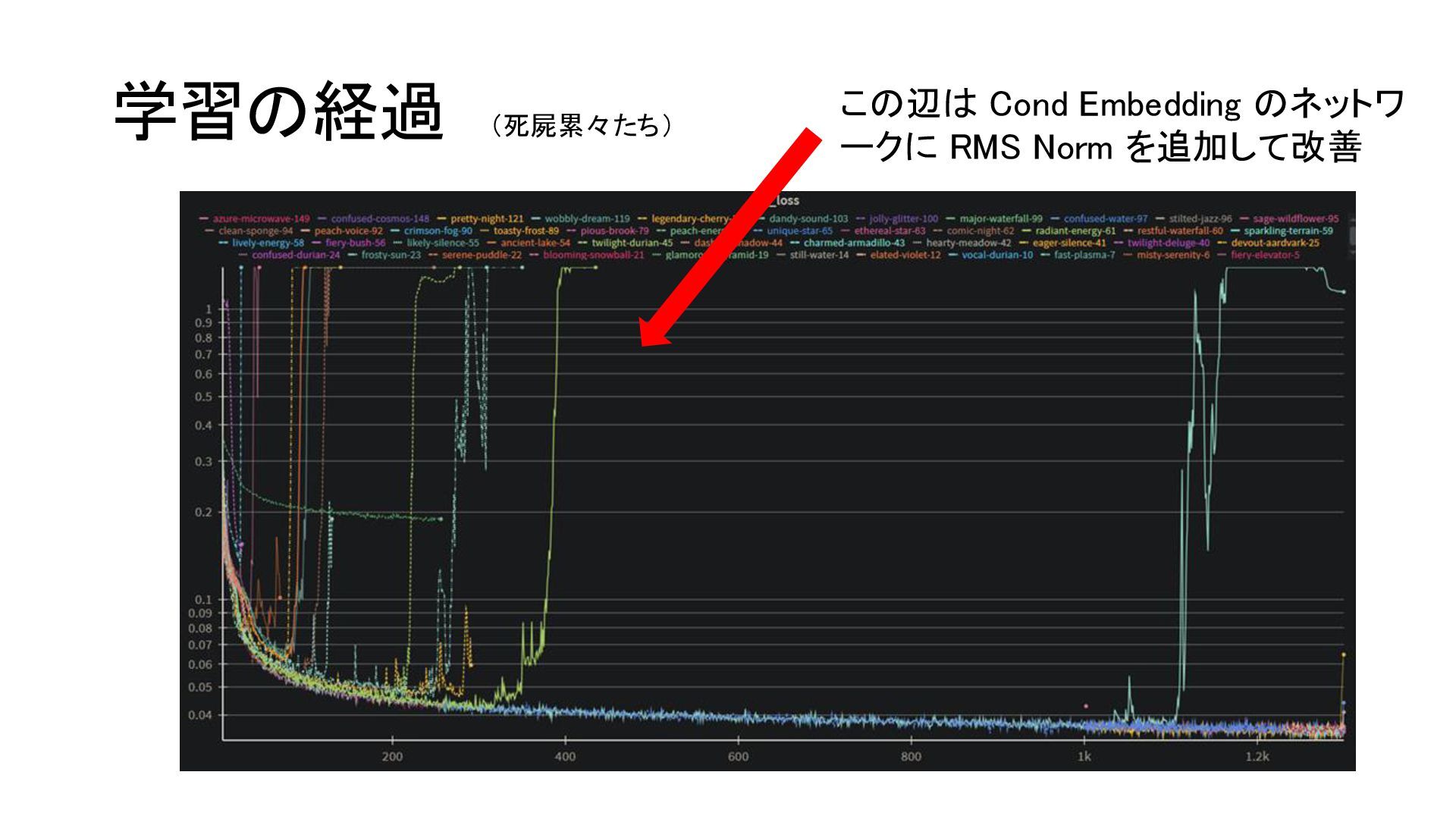{kind=link}
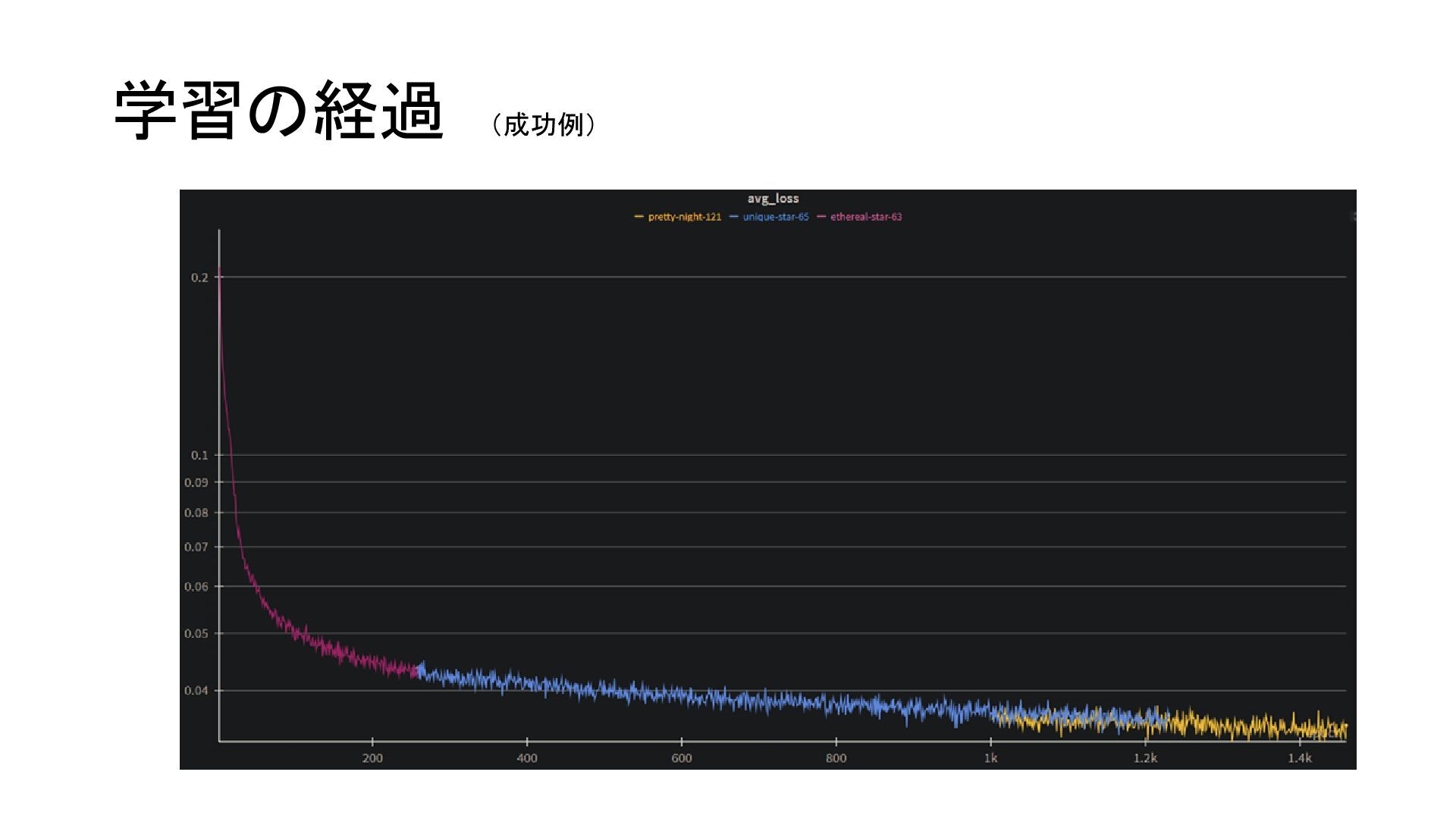{kind=link}
{kind=link}
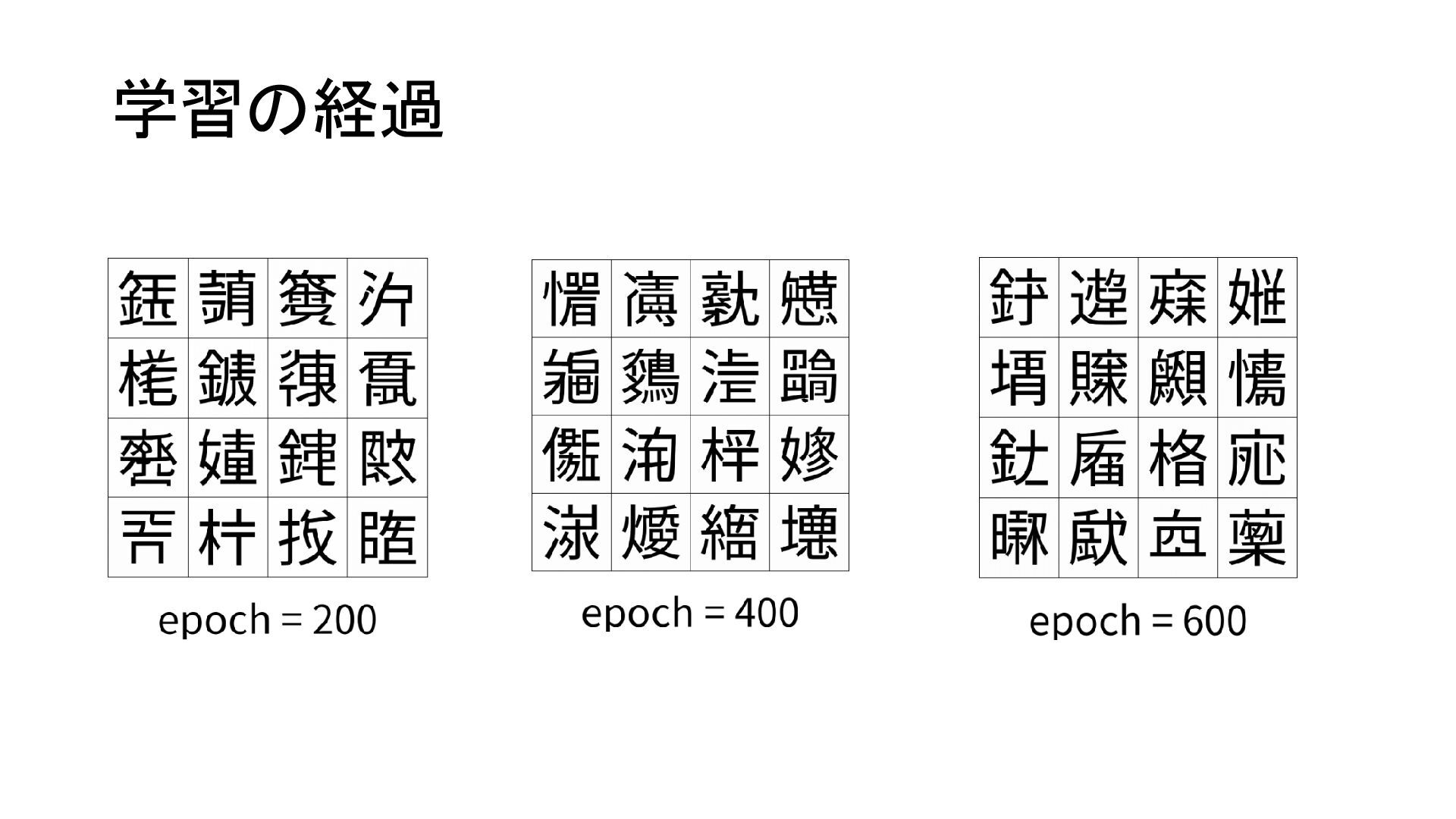{kind=link}
{kind=link}
{kind=link}
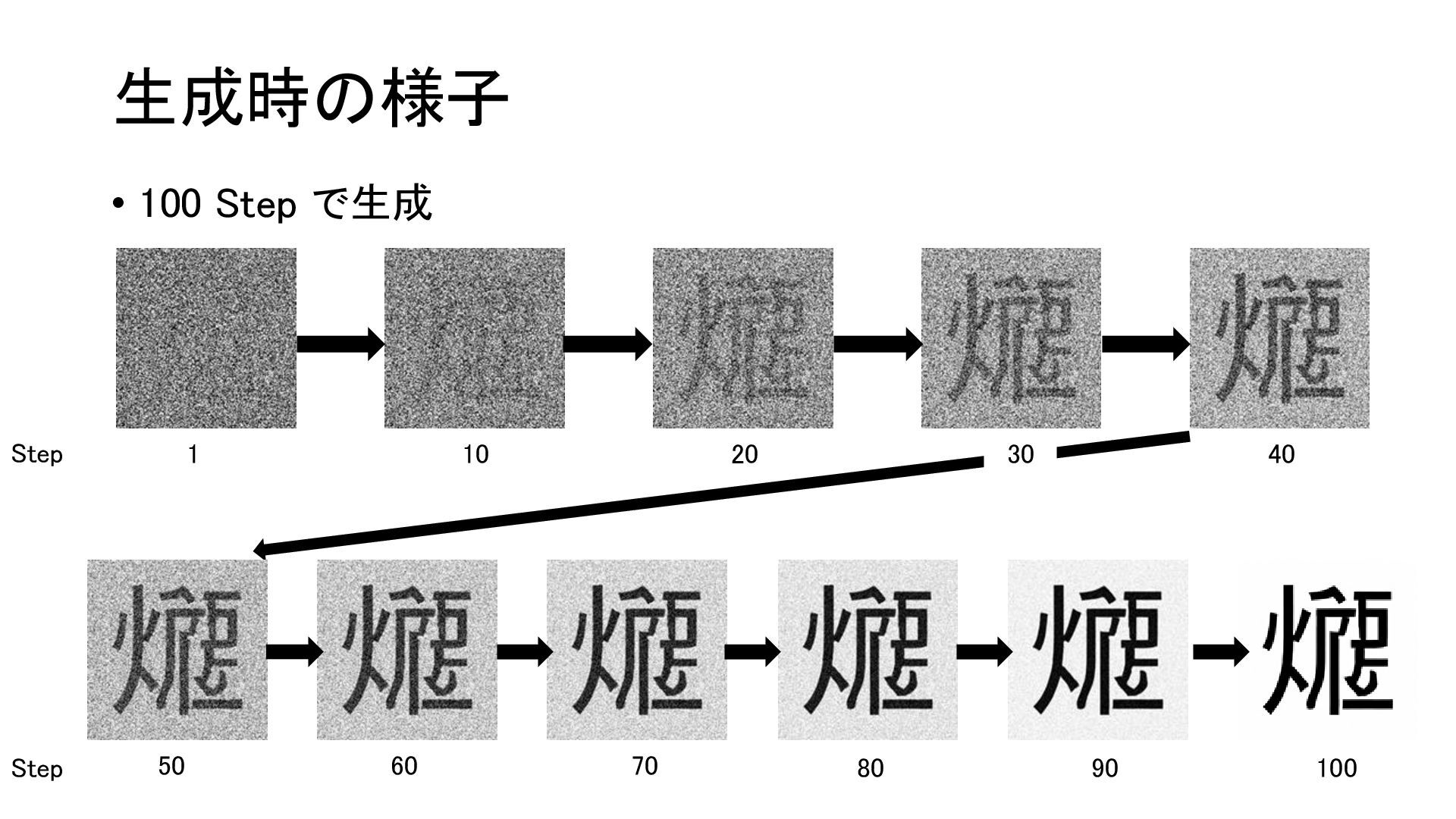{kind=link}
{kind=link}
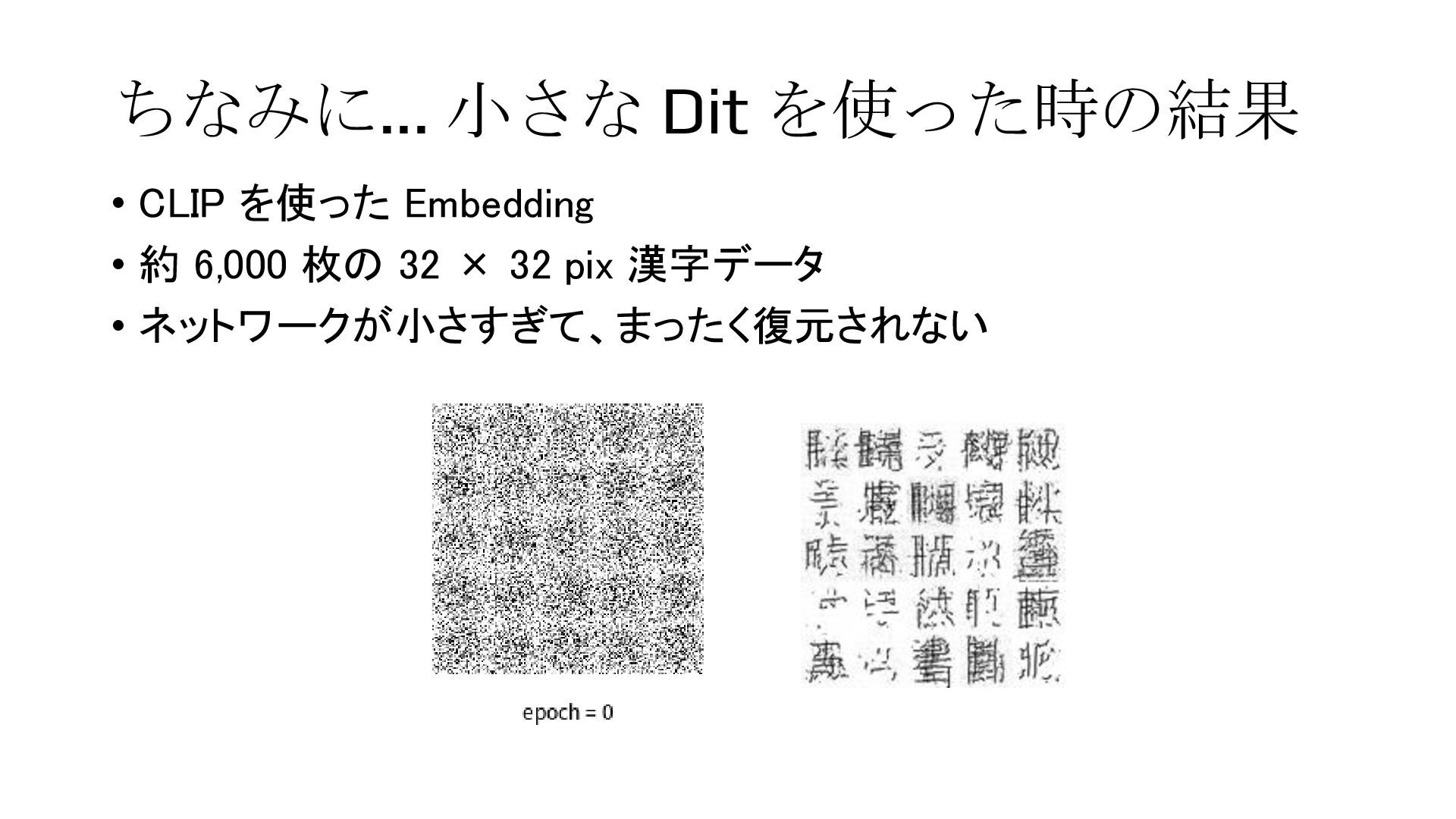{kind=link}
{kind=link}
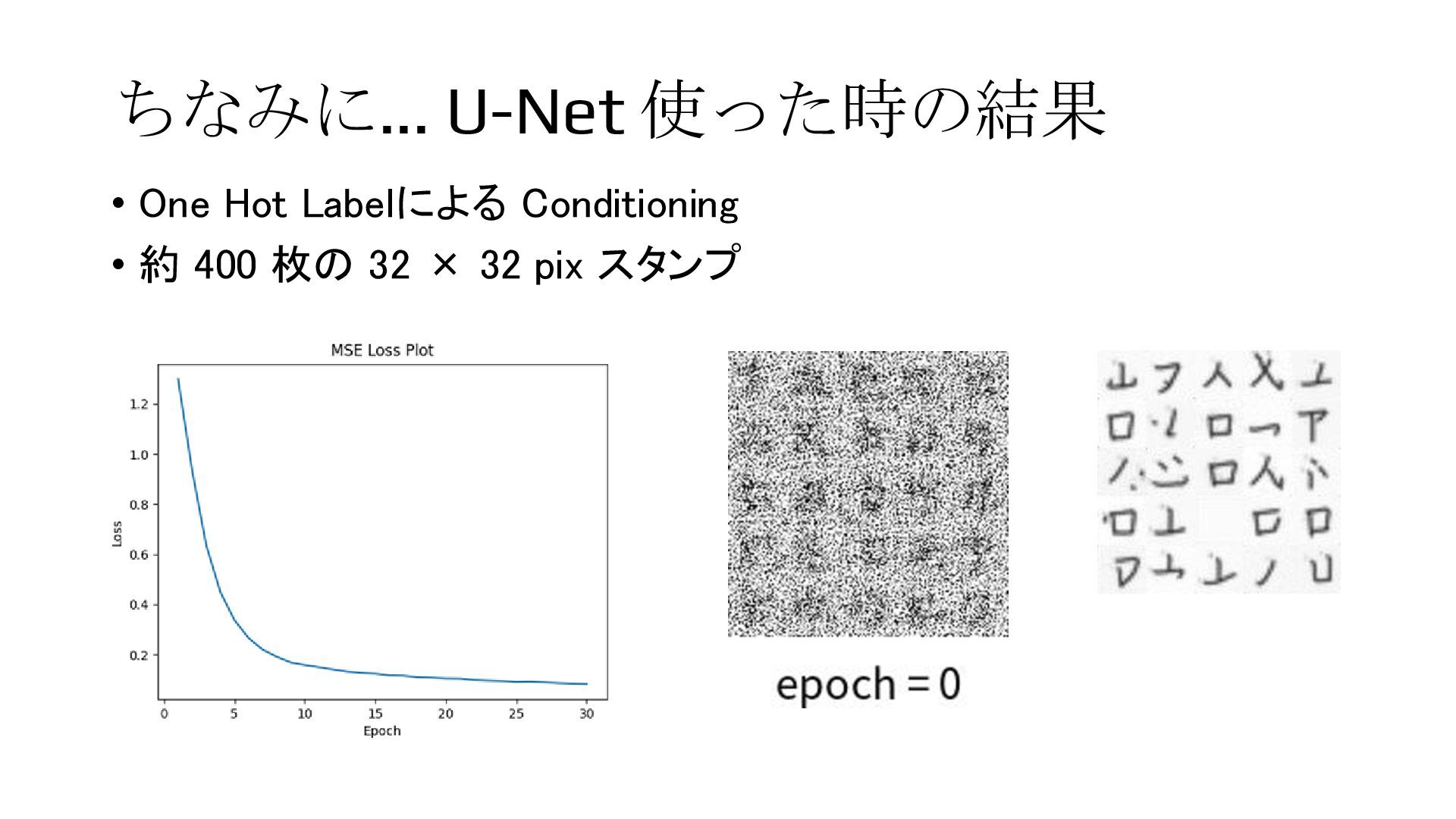{kind=link}
{kind=link}
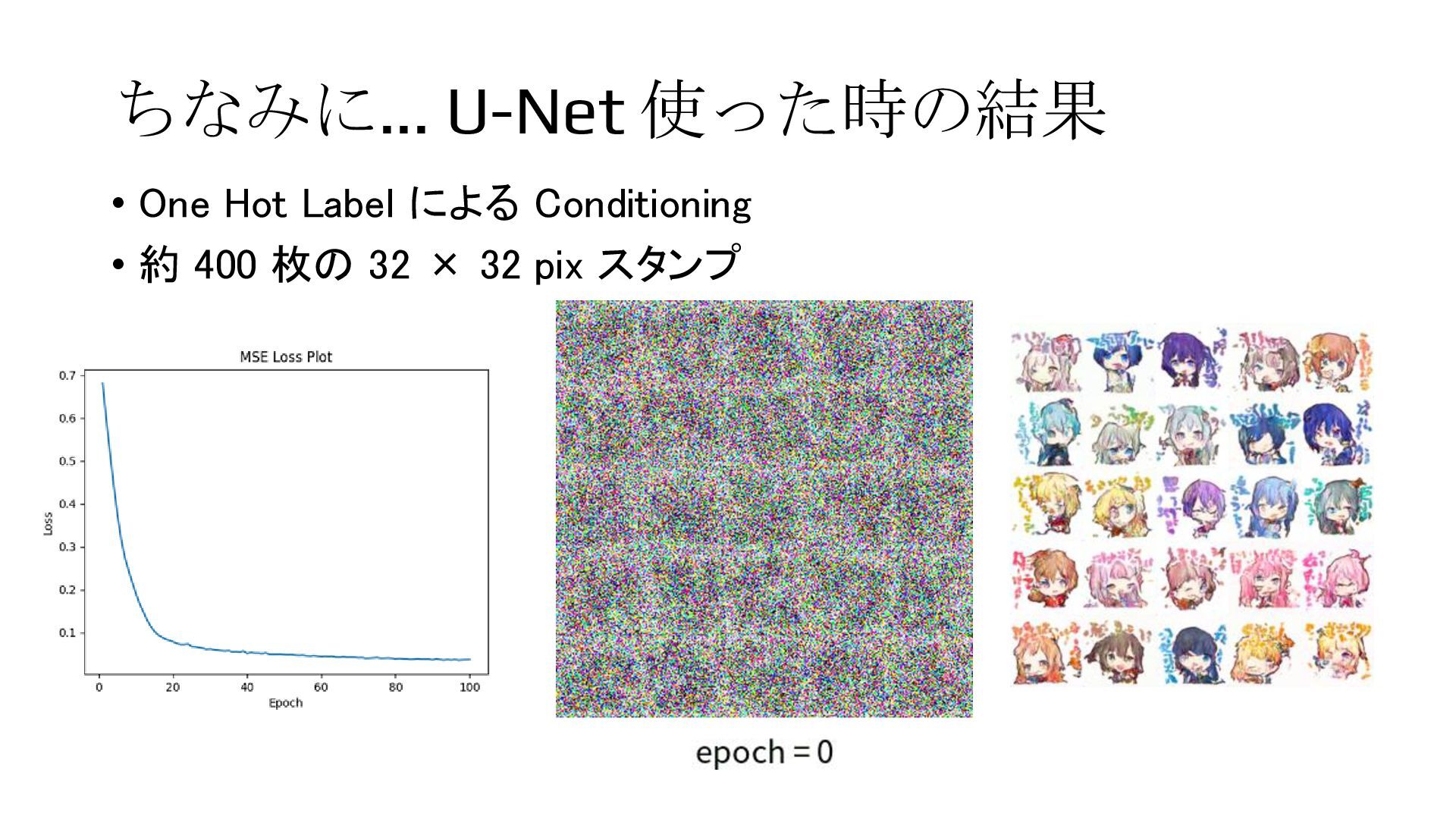{kind=link}
{kind=link}
{kind=link}