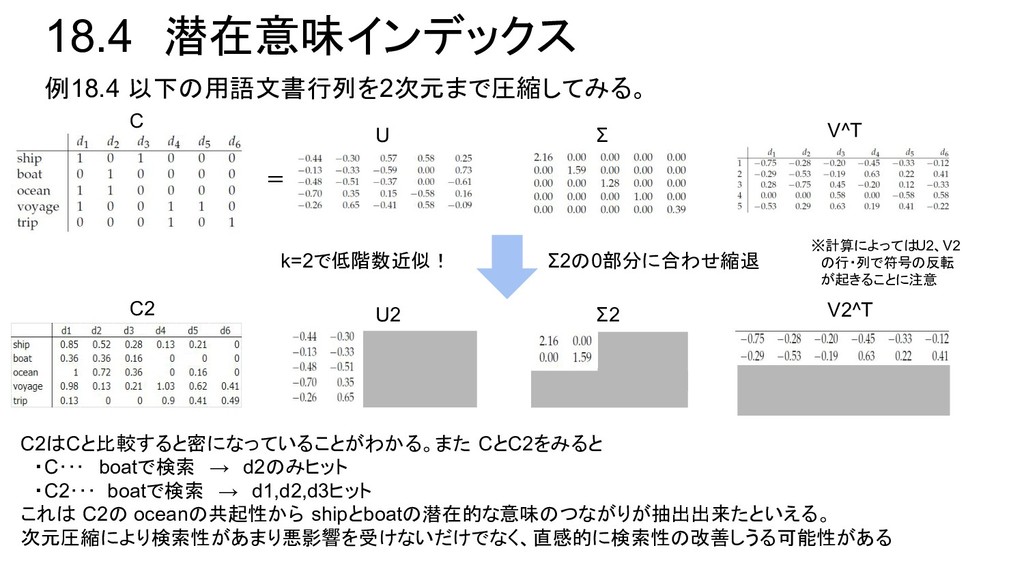
Σ2 V2^T C2はCと比較すると密になっていることがわかる。また CとC2をみると ・C・・・ boatで検索 → d2のみヒット ・C2・・・ boatで検索 → d1,d2,d3ヒット これは C2の oceanの共起性から shipとboatの潜在的な意味のつながりが抽出出来たといえる。 次元圧縮により検索性があまり悪影響を受けないだけでなく、直感的に検索性の改善しうる可能性がある k=2で低階数近似! ※計算によってはU2、V2 の行・列で符号の反転 が起きることに注意 Σ2の0部分に合わせ縮退
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
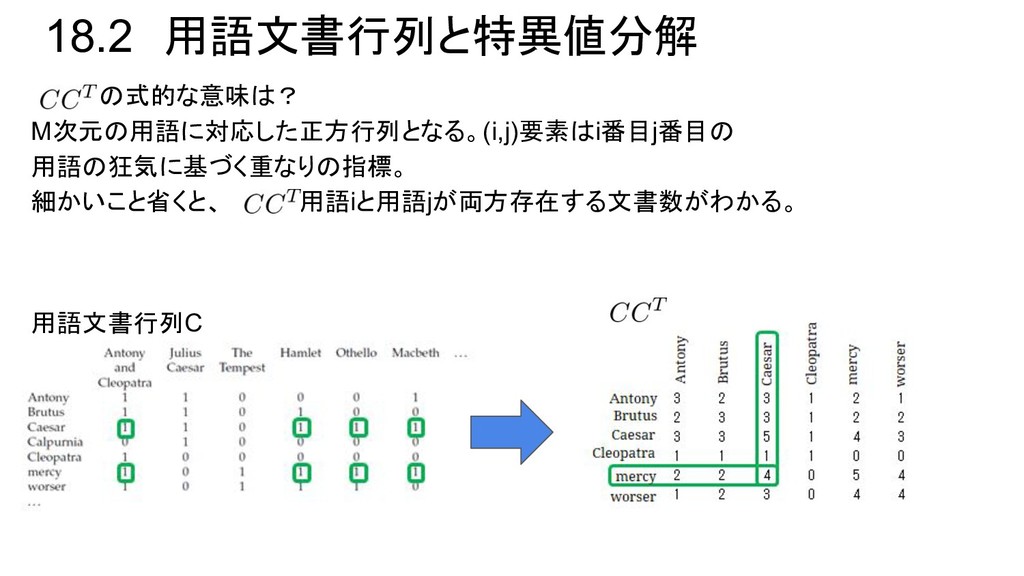
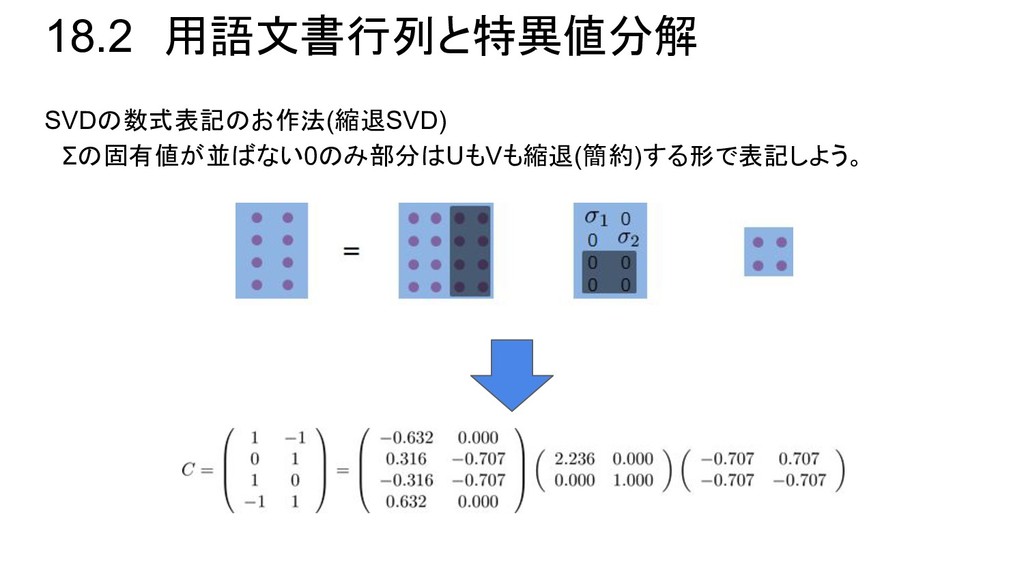
![18.2 用語文書行列と特異値分解 [用語×文書]行列C のサイズは[M×N]で対称行列でもないことがほとんど。 数学的手法で楽に扱えるように、Cを特異値分解(SVD)で対称対角分解できる状態 にしよう。 定理18.3:用語文書行列Cは以下のSVDが可能。 C:任意の行列[M×N](用語文書行列) U、V: の固有値ベクトルの集まりの直交行列 Σ: の固有値の平方根(特異値)を並べた対角行列 直交行列とは?](https://files.speakerdeck.com/presentations/f60e7f37a09e4beeb50bf50481c2dd91/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
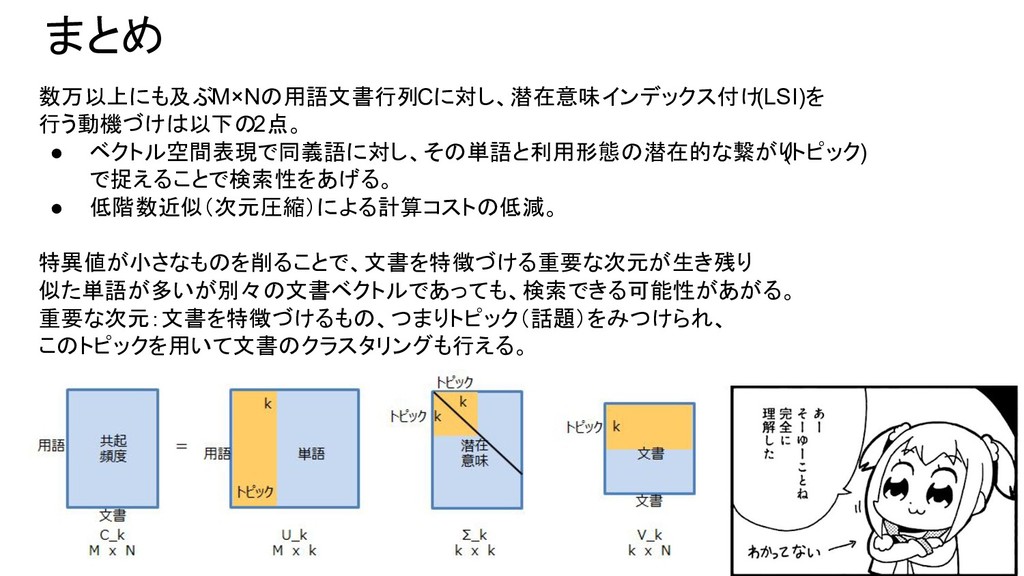{kind=link}