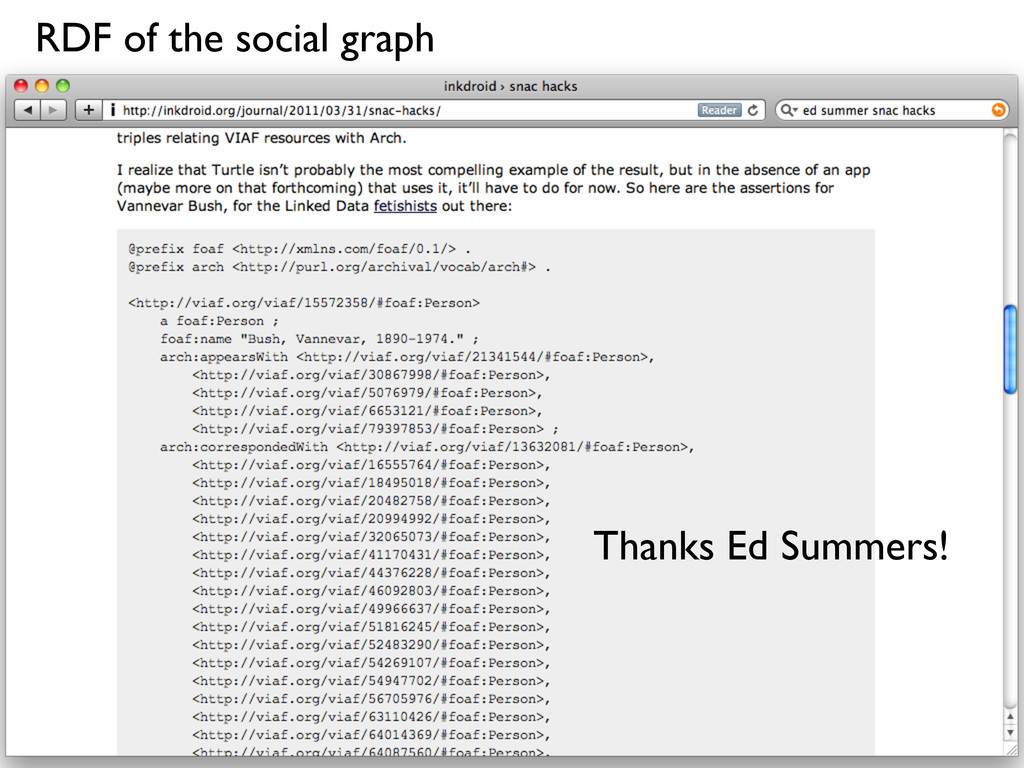
Stack • Web of atomized Data, not a web of documents • RDF; OWL ontologies; SPARQL queries; triple/quad/quint stores • httpRange14; content negotiation; CURIE • No restrictions on data use; free and easy license • Not of direct interest to most "real users"
stuff • Blue underlined text • Pulling in data from multiple sources, in an intelligent way, into a "document" • Understand and discover relationships • Open access for research, education, private study and other fair use
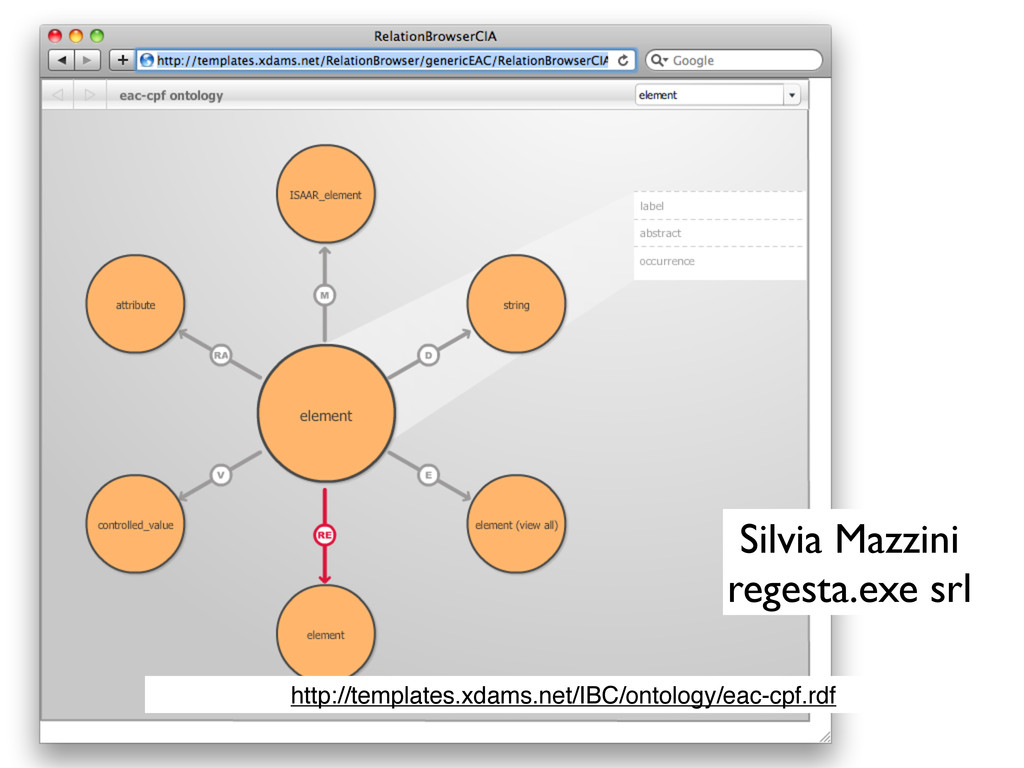
"JDBC for graph databases" [SNAC is using Neo4J for the graphDB] • XPath like "gremlin" for graph query • REST interfaces with "Rexster" • For me, this was 10 to 100 times easier than using RDF
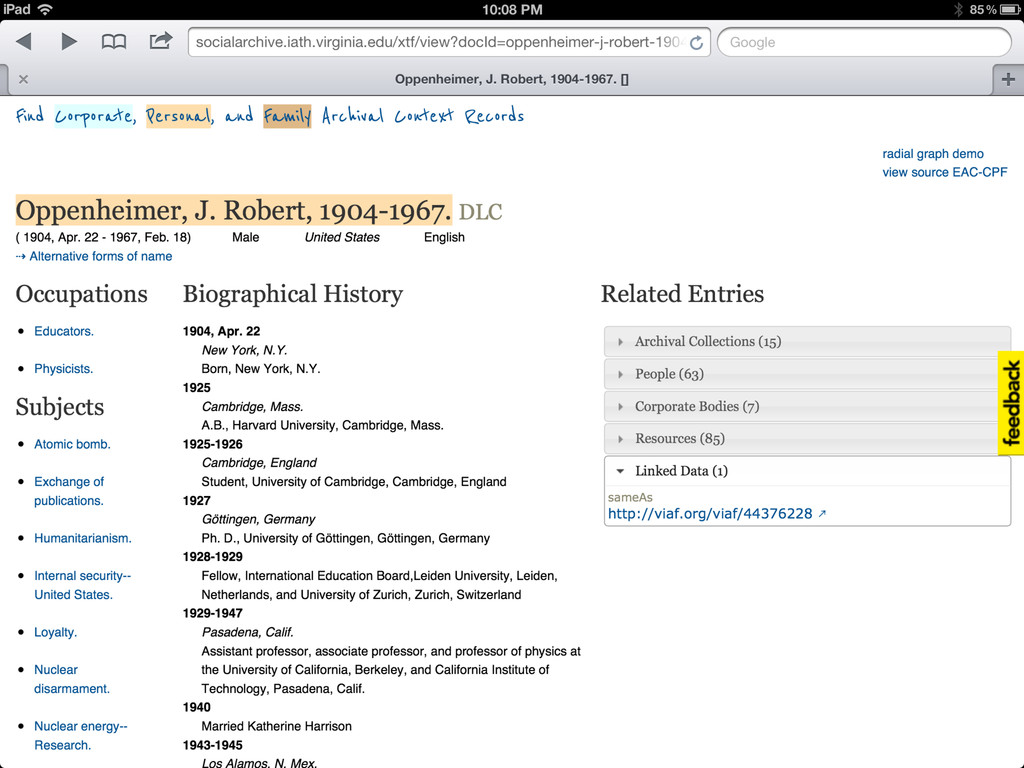
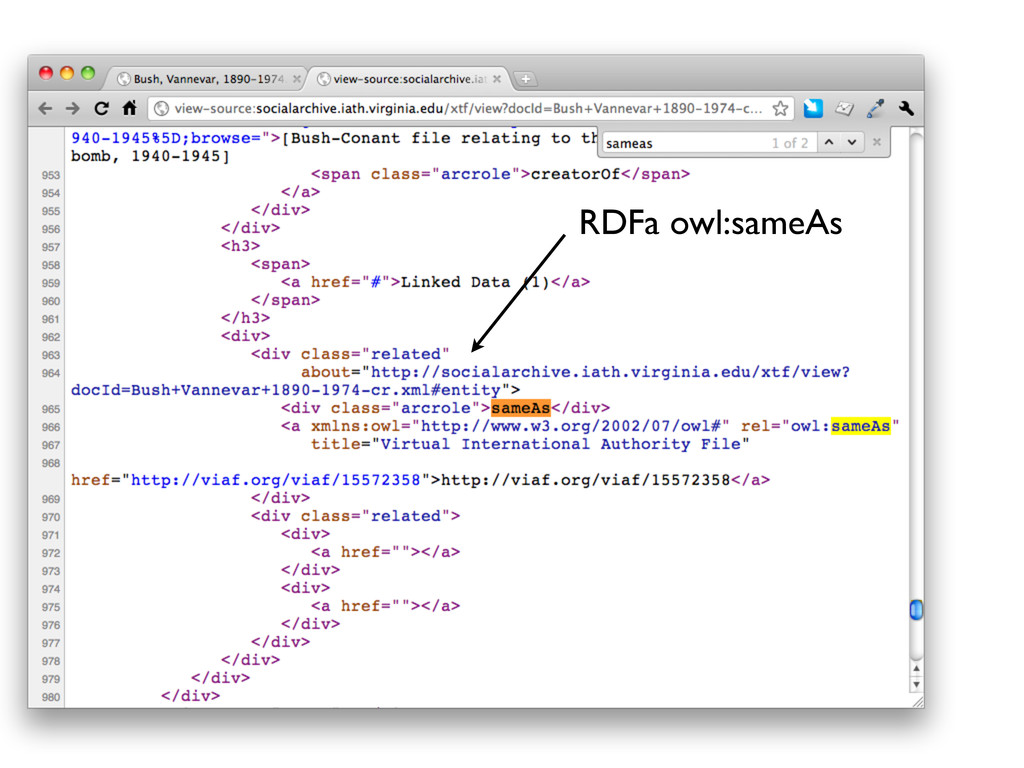
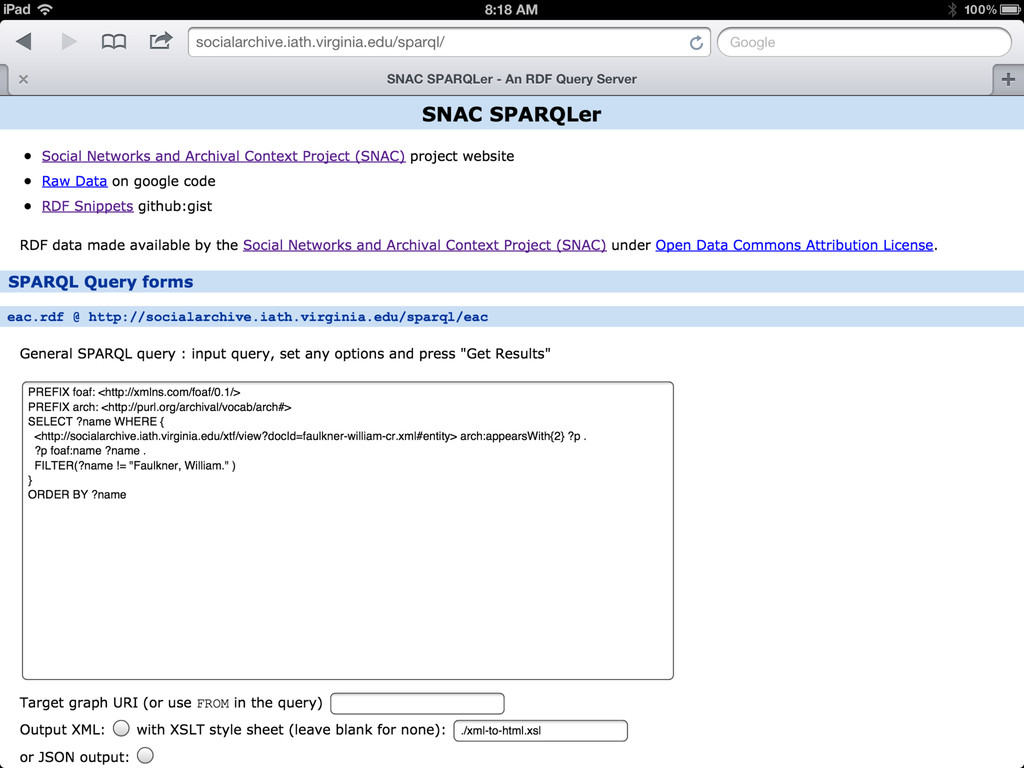
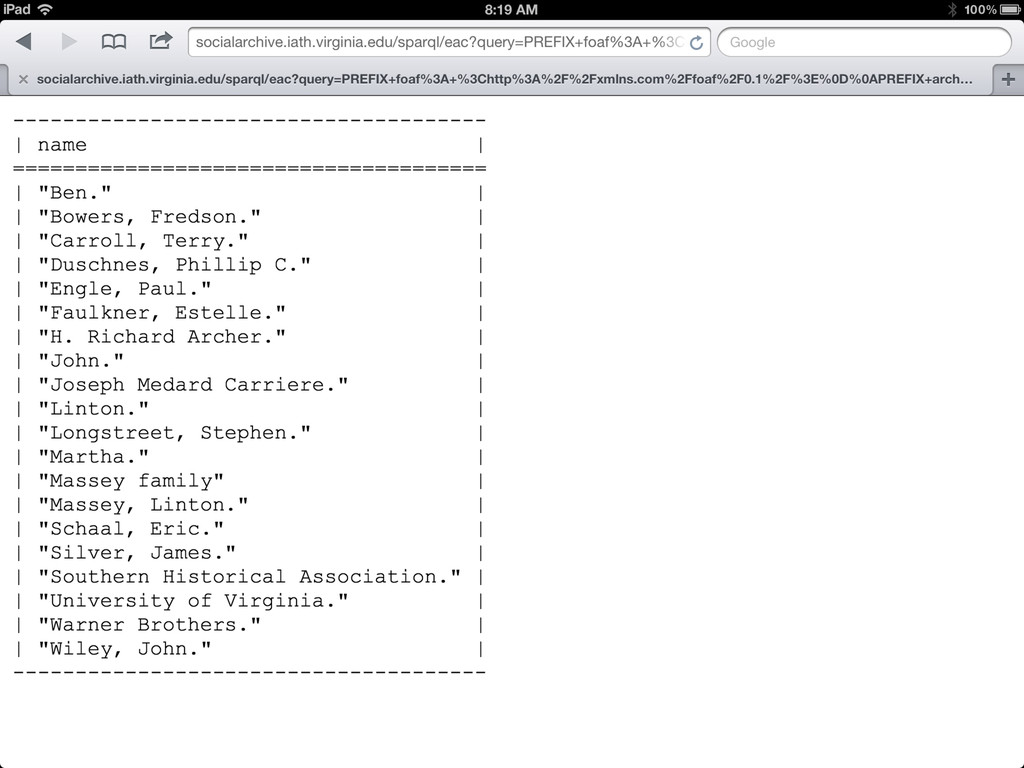
RDF for the page (via SPARQL query). -- content negotiation is not supported, but I think what we are doing is httpRange14 compliant • Also experimenting with italian RDF via xslt
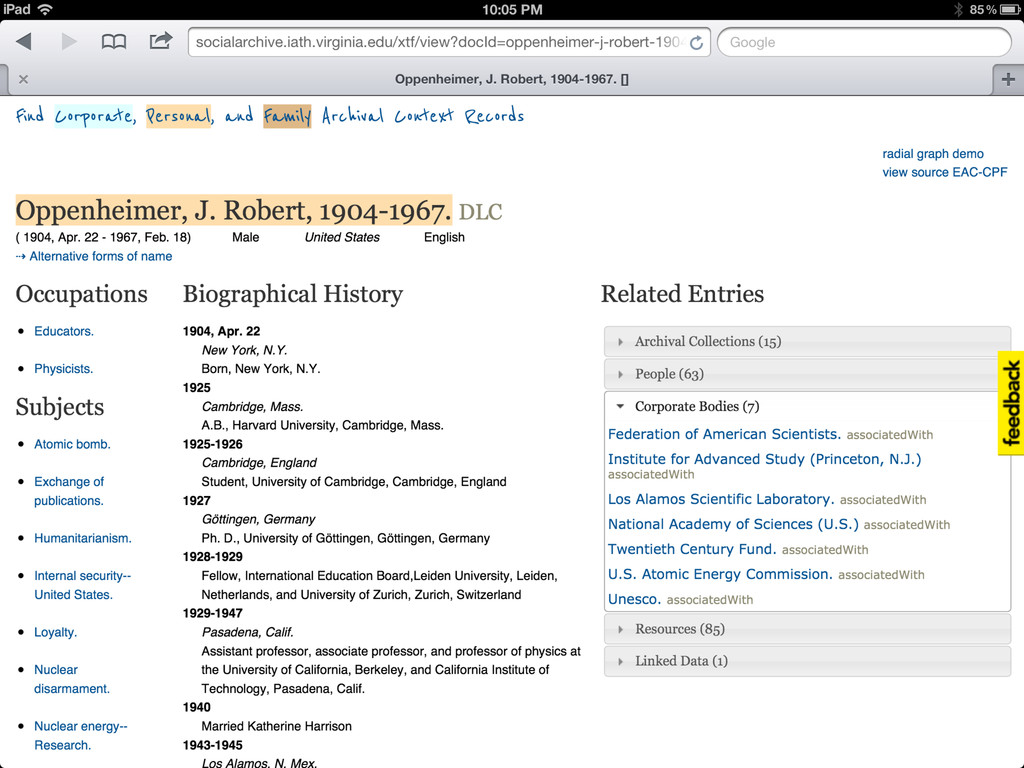
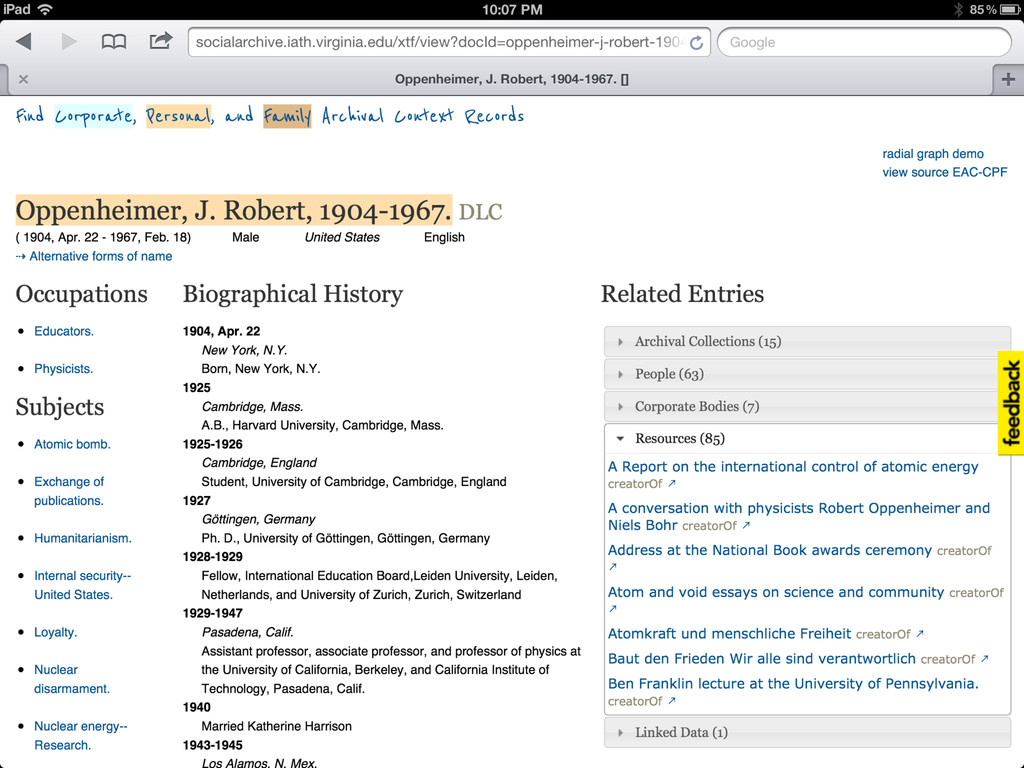
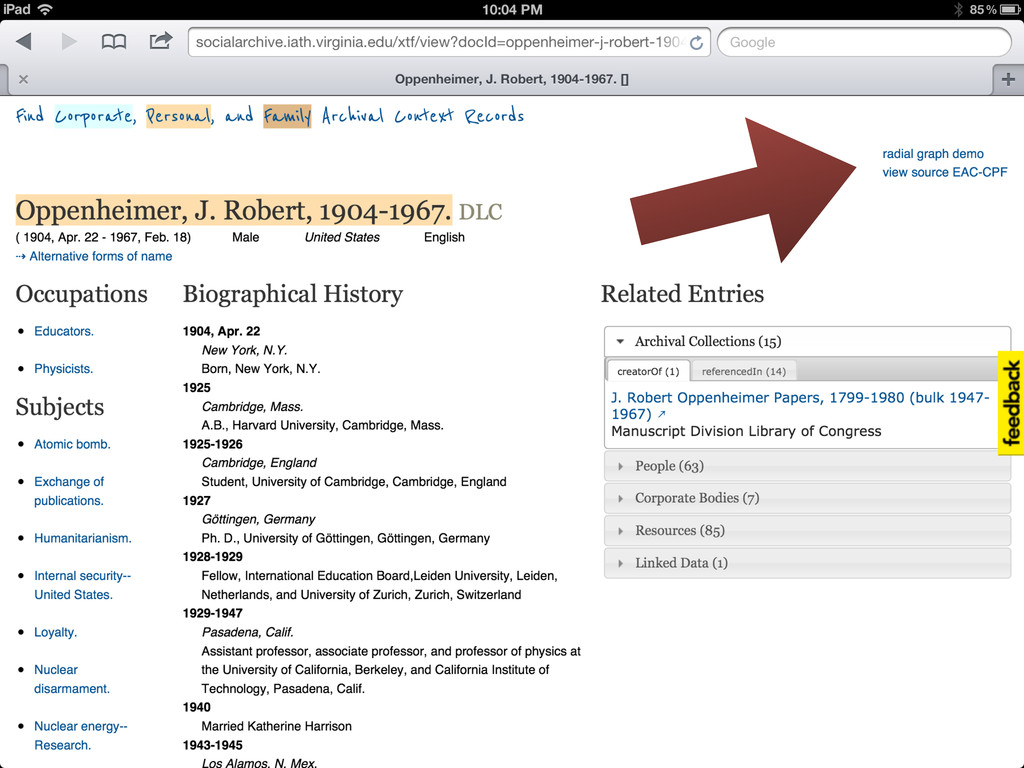
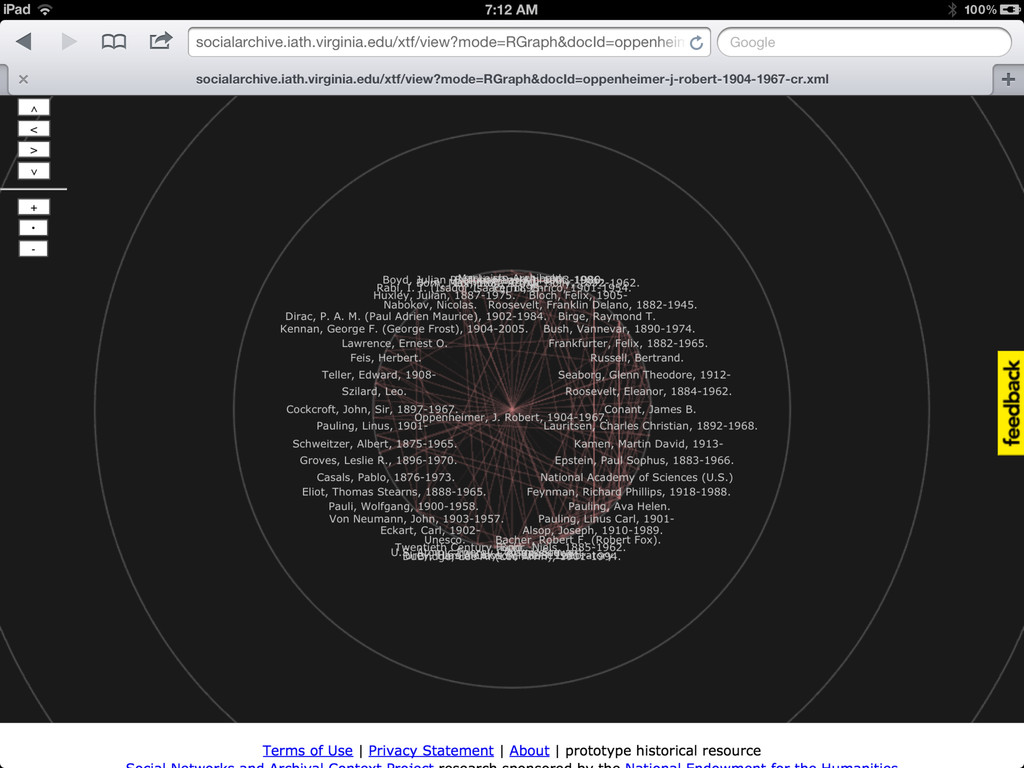
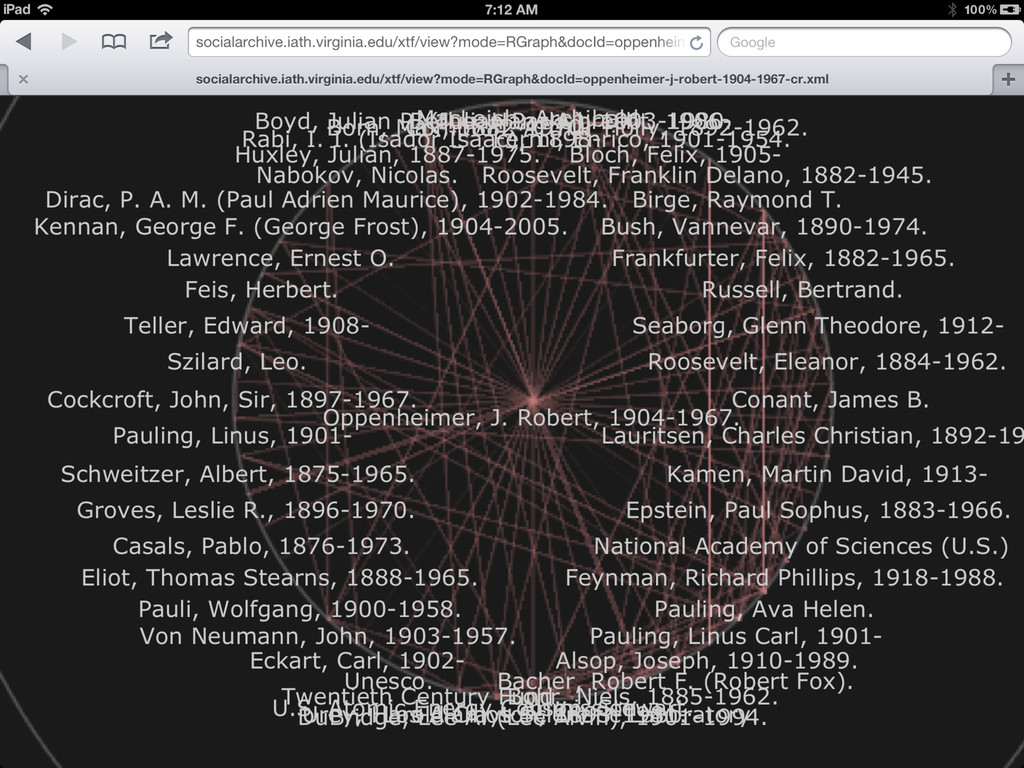
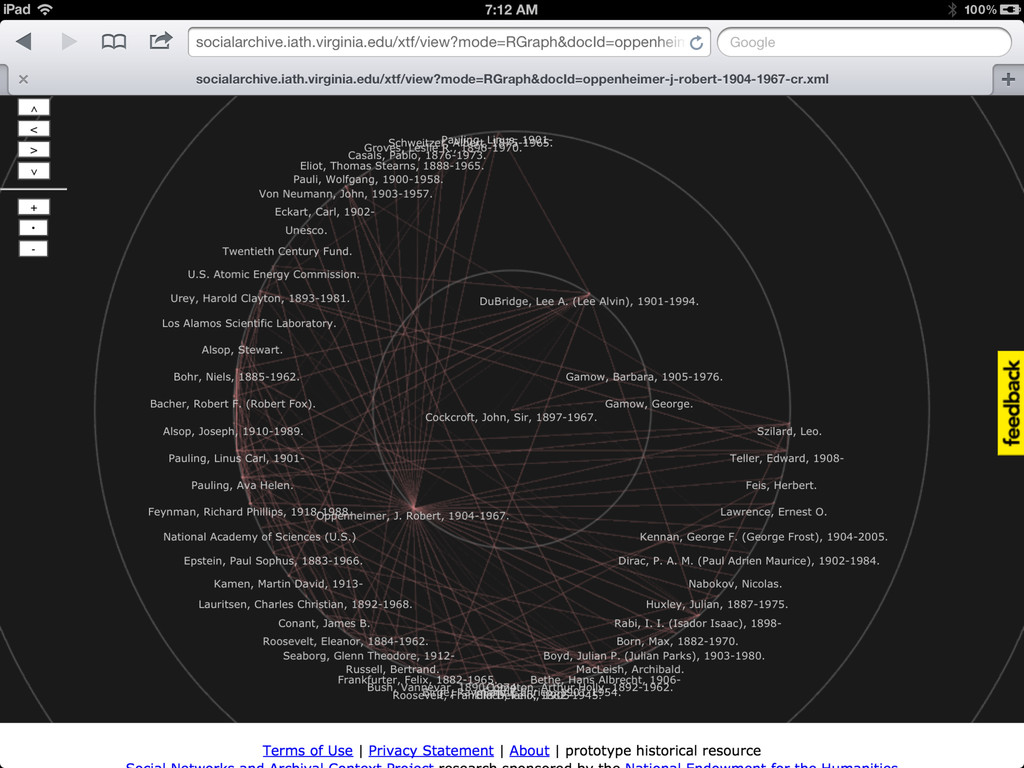
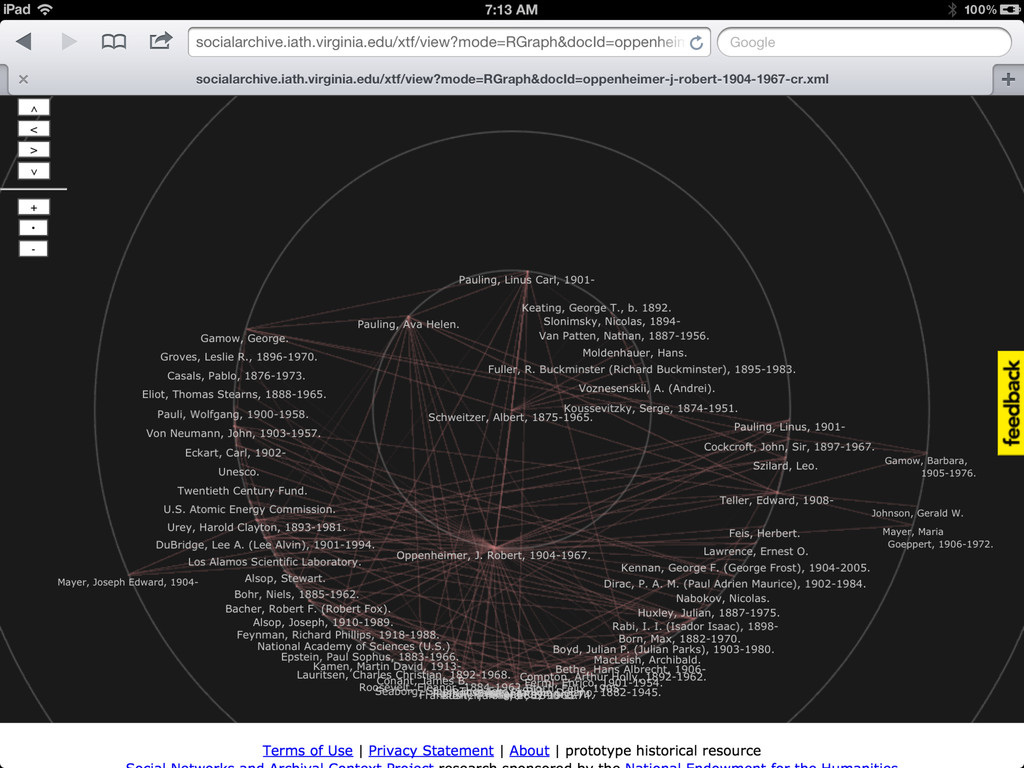
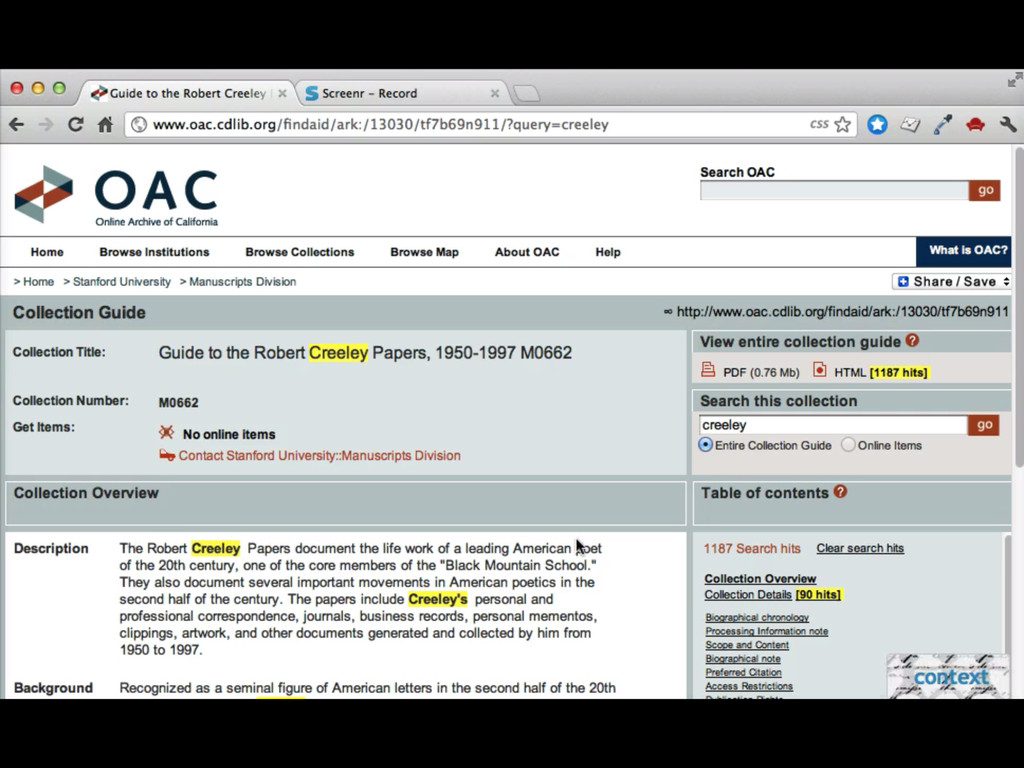
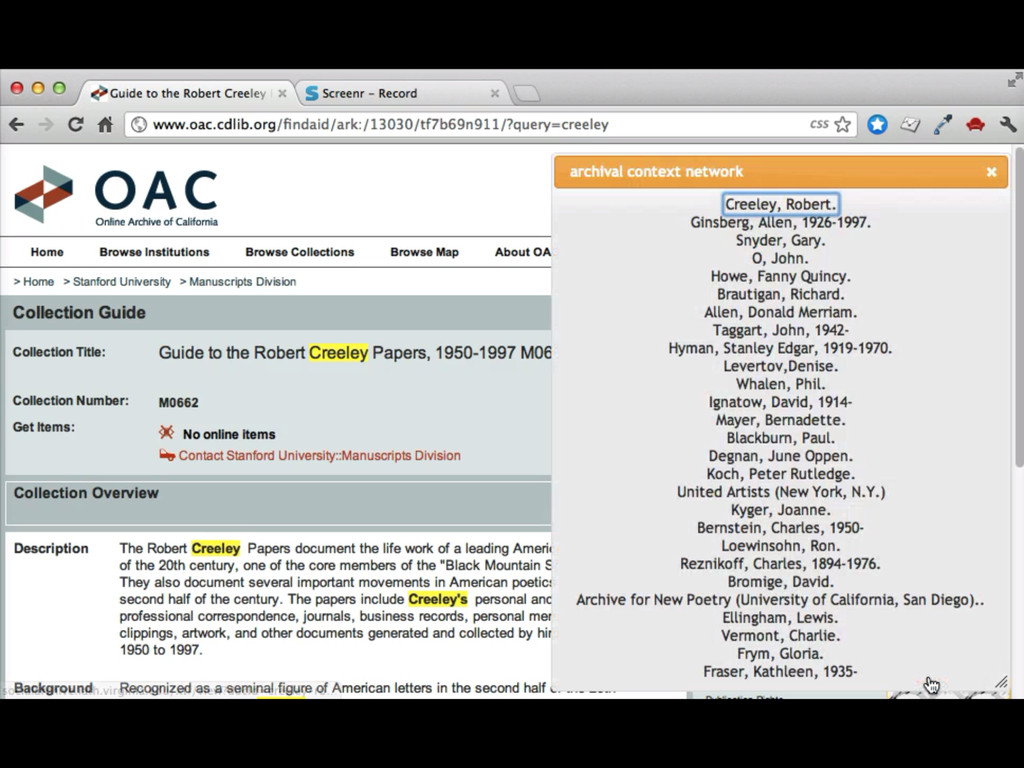
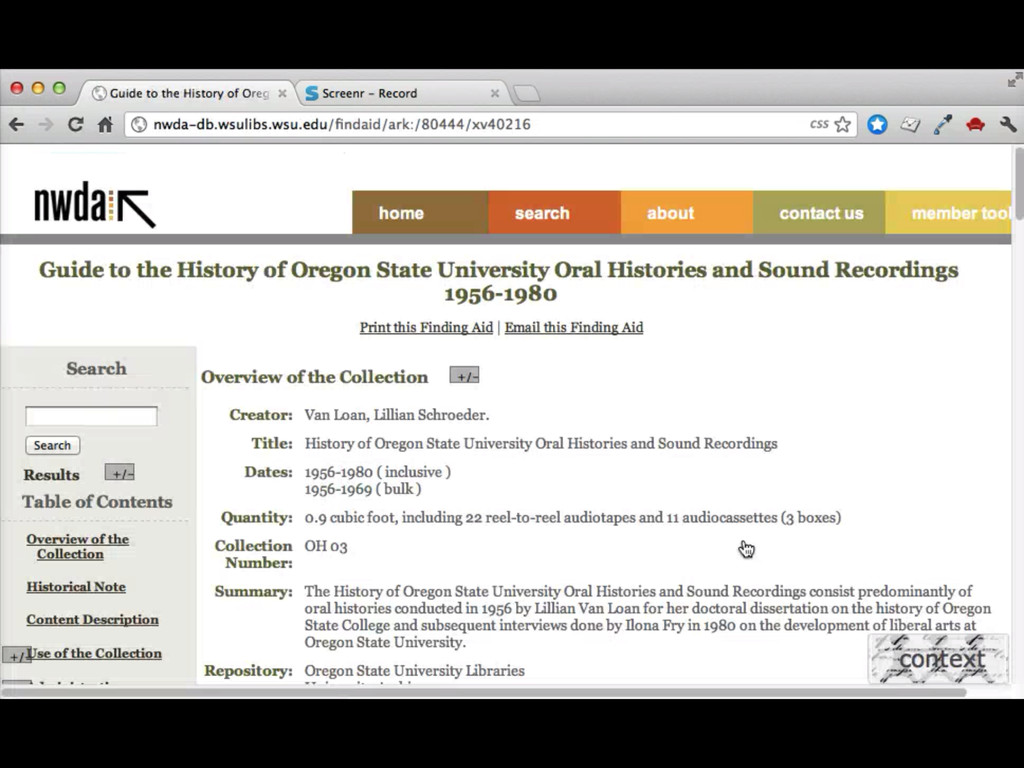
• More links to related sources such as dbpedia, IMDB, familysearch, id.loc.gov • Content negotiation (in SNAC 2 I'll have control over the front end apache, so this should be easy enough) • Visualizations useful and integrated (network and geospatial) • Integration with local systems (such as with the context widget)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![&mode=xml2owl [experimental]](https://files.speakerdeck.com/presentations/4fe9fc0bcd9eca001f006c64/slide_33.jpg){kind=link}
{kind=link}