Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データのマスタが変わっても継続的に分析したい!
Search
momochi29
June 25, 2024
Programming
410
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データのマスタが変わっても継続的に分析したい!
Kyoto Tech Talk #5 (
https://lycorptech-jp.connpass.com/event/320723/
) の発表資料です
momochi29
June 25, 2024
More Decks by momochi29
See All by momochi29
いかにして不足・不整合なくデータ移行したか
tjmtmmnk
1
1.7k
初めてのデータ移行プロジェクトから得た学び
tjmtmmnk
0
1.2k
Other Decks in Programming
See All in Programming
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
110
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
140
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
110
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
500
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
0
290
関数型プログラミングのメリットって何だろう?
wanko_it
0
180
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.9k
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
150
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
4.4k
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
520
フィードバックで育てるAI開発
kotaminato
1
120
Featured
See All Featured
Into the Great Unknown - MozCon
thekraken
41
2.6k
Leo the Paperboy
mayatellez
8
1.9k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
390
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Faster Mobile Websites
deanohume
310
32k
How to build a perfect <img>
jonoalderson
1
5.8k
Transcript
データのマスタが変わって も継続的に分析したい! id:momochi29 2024/06/25 Kyoto Tech Talk #5 1
自己紹介 2 • id: momochi29 • 所属: 株式会社はてな マンガメディア開発チーム •
職種: Webアプリケーションエンジニア • 好きなマンガ: ワールドトリガー
突然ですが… 3
ジャンプ+リニューアル! 4 https://hatena.co.jp/press/release/entry/2024/03/29/120000
裏側で何が起きていたか 5 • foo社(以下f社)が管理していたデータをはてなが管 理することになった ◦ f社のデータをはてなに移行して、はてながデータのマスタになる • 何もしないとデータ分析できなくなる ◦
リニューアル後ははてなしかデータを持っていない ◦ f社とはてなではテーブル設計が異なる
裏側で何が起きていたか 6 • foo社(以下f社)が管理していたデータをはてなが管 理することになった ◦ f社のデータをはてなに移行して、はてながデータのマスタになる • 何もしないとデータ分析できなくなる ◦
リニューアル後ははてなしかデータを持っていない ◦ f社とはてなではテーブル設計が異なる 困る!
今日話す内容 7 • データ移行に伴う分析基盤の移行対応の事例紹介 • 目次 ◦ ゴールを達成するための構成 ◦ データ連携
◦ データ再現 ◦ 継続的な分析 ◦ まとめ
ゴールを達成するための構成 8
ゴールを決める 9 1. これまでの分析をはてなのデータを使ってできる 2. 新規の分析をはてなのデータを使ってできる
f社の構成を知る 10
ゴールを達成するには? 11
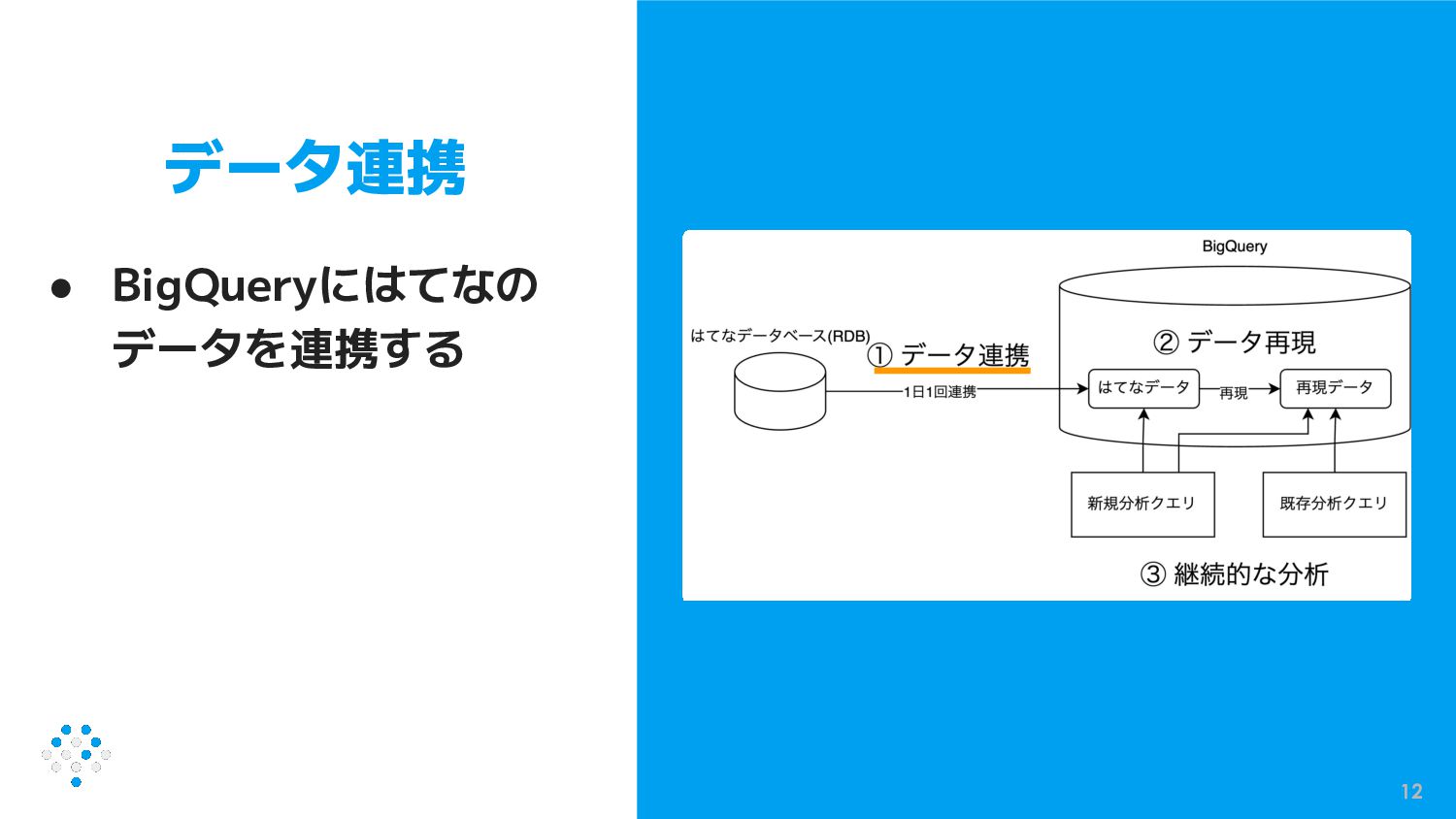
データ連携 • BigQueryにはてなの データを連携する 12
データ再現 • f社のデータ形式で作ら れている分析クエリを はてなのデータ形式に 対応させる 13
継続的な分析 • 既存の分析クエリを使 えるように書き換える • 新規の分析クエリを書 けるようにはてなの データ形式を理解する 14
データ連携 15 BigQueryにはてなのデータを連携する
Datastreamによるデータ連携 16 • データベースとBigQueryのデータ連携に Datastreamを採用
Datastream 17 • Google Cloudのレプリケーションサービス • 連携対象のテーブルを選択するだけで自動で連携 • データの追加・削除・変更を自動で追従 ◦
バイナリログでレプリケーションするのと同じ
Datastreamを採用した理由 18 • 運用容易性を重視した ◦ サーバの管理が不要 ◦ リカバリが容易 • 一部のテーブルは日次ではなく、より高頻度に連携
が求められる予定がある
他に検討した案 19 • Embulkを使う ◦ 運用容易性を重視したため採用せず • Auroraのスナップショット(parquet)で洗替 ◦ スナップショットのエクスポートに時間がかかり過ぎて日次の連携
が困難と判断したので採用せず
結果 20 Datastreamは良 いぞ! 自動復旧がすごく優秀
結果 21 • 課題もあったが今は元気に動いている ◦ バックフィル(初期化処理)が遅すぎる ▪ 20億レコードのバックフィルに10日かかる ▪ Auroraのスナップショットでバックフィルして1日に短縮できた
◦ 前日分の変更が反映されているのか不明 ▪ データの鮮度を指定できるがいつ更新されるのかわからない ▪ 鮮度のパラメータ(max_staleness)を動的に変更することで確実に 変更を反映させることができた
結果 22 • 課題もあったがなんとかなった ◦ バックフィル(初期化処理)が遅すぎる ▪ 20億レコードのバックフィルに10日かかる ▪ Auroraのスナップショットでバックフィルして1日に短縮できた
◦ 前日分の変更が反映されているのか不明 ▪ データの鮮度を指定できるがいつ更新されるのかわからない ▪ 鮮度のパラメータ(max_staleness)を動的に変更することで確実 に変更を反映させることができた 詳しくはブログに 書いています/書く予定です! https://tjmtmmnk.hatenablog.com /search?q=Datastream
データ再現 23 f社のデータ形式で作られている分析クエリを はてなのデータ形式に対応させる
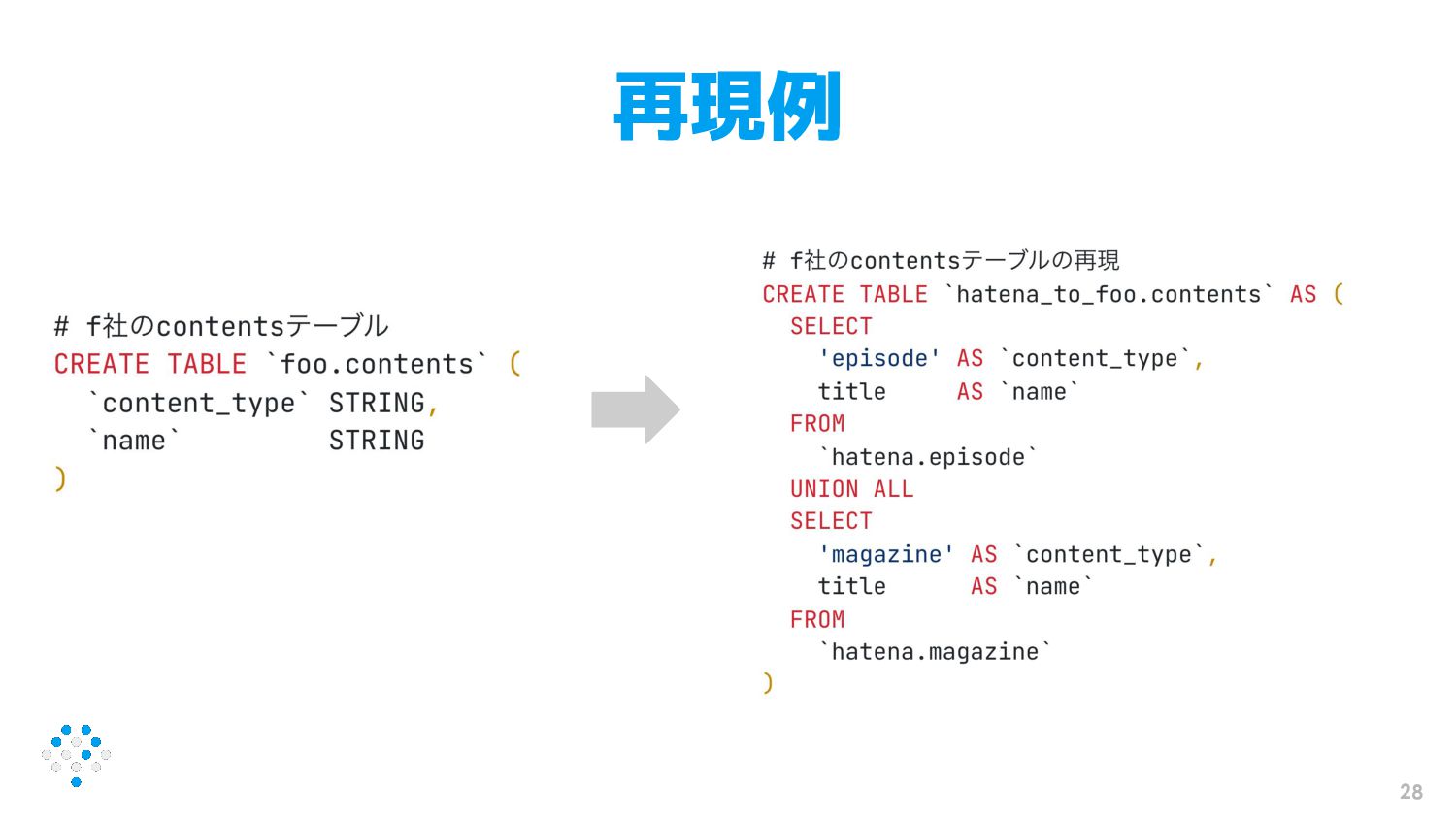
データ形式の違いを知る 24 • 読み物(エピソード、雑誌など)を例にする • f社では読み物を統一的に扱うcontentsテーブルがあ る • はてなではepisodeテーブル、magazineテーブルの ように種類ごとに分かれている
クエリを直接書き換える? 25 • contentsテーブルを使っているクエリを一個ずつ episode, magazineテーブルを参照するように書き 換えていく?
クエリを直接書き換える? 26 • contentsテーブルを使っているクエリを一個ずつ episode, magazineテーブルを参照するように書き 換えていく? • 大変すぎる!!! ◦
クエリは数百個ある ◦ 動作確認が難しい ◦ 対応が間違っていた場合の影響範囲大
テーブルを再現する 27 • f社のテーブルをはてなのデータを使って再現する ◦ テーブルが再現できていれば書き換え工数減らせる & 動作確認しや すいだろうという発想 •
BigQuery上で再現する ◦ いわゆるデータウェアハウス層での変換と捉える
再現例 28
再現例 29 歯を食いしばって全テーブルやる!!
対応関係を知る 30 • f社のテーブル定義に対応するはてなの情報を埋める ◦ ヌケモレ防止 ◦ 新規にはてなのデータを使って分析するときのドキュメントになる contents content_type
name … 対応するはてな のデータ はてな側に持っていない のでハードコード (episode | magazine).title …
様々な環境に対応する 31 • 開発環境、ステージング環境、本番環境が必要 • 環境分の再現クエリを用意する?
様々な環境に対応する 32 • 開発環境、ステージング環境、本番環境が必要 • 環境分の再現クエリを用意する? ◦ 面倒すぎる!!!
1つのクエリで複数環境に対応する 33 • 環境によって異なるのはデータのみ ◦ `dataset_develop.episode`, `dataset_prod.episode` • クエリのロジックは変わらない •
dbt(dbt-core)を利用して1つのクエリで複数環境に 対応する
dbt 34 • ELT(Extract/Load/Transform)のTを担うツール • テンプレートエンジンのJinjaが使える ◦ 変数やマクロを使って処理を共通化できる • テスト機能がある
◦ 条件を満たさないレコードがあればfail
dbtで複数環境に対応する 35 設定 再現クエリ
dbtで複数環境に対応する 36 dbt compile --target develop
データ品質を保証する 37 • 分析クエリには数値のズレが許されないレポートも 含まれる • dbtでテーブルの再現後にテストすることで品質保証 ◦ 一意性チェック ◦
レポートに影響する項目のチェック
結果 38 • テーブルを再現することで、分析者はこれまでの データ形式と変わらずにはてなのデータを扱えるよ うになった • 対応関係を洗い出すことで、漏れなくテーブルを再 現できた。さらに、仕様の差異や仕様上再現が不要 な項目を洗い出すことができた
継続的な分析 39 既存の分析クエリを使えるように書き換える 新規の分析クエリを書けるようにはてなのデータ形式を理解する
既存の分析クエリを書き換える 40 • テーブルの再現によってデータセットの書き換えだ けで大体OK! ◦ `foo.contents` -> `hatena_to_foo.contents` ◦
“誰でも” 書き換えが可能に! • 仕様差異がある箇所は手動で書き換える
はてなのデータ形式を理解する 41 • これまではデータベースのスキーマファイルに コメントを書いてそれをドキュメントとしていた ◦ 開発者に閉じていたのでスキーマファイルを直接見に行く運用で 事足りていた • これからは他社の分析者がはてなのデータ形式を理
解する必要がある
テーブル定義書を作る 42 • テーブル定義書の作成にtblsというツールを採用
tbls • データベースに接続し て良い感じに定義書を 作ってくれる • 設定が柔軟 ◦ コメントの上書き ◦
ER図を外部キーなし でも作れる 43 https://github.com/k1LoW/tbls/blob/main/sample/mysql/logs.md
これまでの運用を大きく変えない工夫 44 • データベースのスキーマファイルのコメントから コメントを自動生成する仕組みを入れている ◦ COMMENT属性を使っていないのでtblsで自動生成できない ◦ これまでのスキーマファイルにコメント書く運用は変えなくて良い
テーブル定義書を共有する 45 • GitHub Pagesでホスティング ◦ privateにして関係者をリポジトリに招待することで共有している • Just the
Docsというテーマを採用 ◦ 検索機能が優秀
結果 46 • 数百個ある分析クエリをコマンド一発で書き換える ことができた • テーブル定義書を作ることで分析者だけでなく開発 者にとってもテーブルの理解に役立っている。ま た、定義書が対外的になることでコメントの質を高 める意識が向上している
まとめ 47 • 様々なツールを組み合わせて分析基盤を移行するこ とができた • 今回の事例はレアケースとは思いますがなにか役立 つことがあれば幸いです
想定質問 48
COMMENT属性使わないの? 49 • 一行のコメントなら便利だが複数行のコメントの場 合は大変なので使っていない • また、これまでの運用を変えなくてよいというメ リットも大きいと判断している
再現クエリをずっと使うの? 50 • 読み物の例でも示した通り、はてな側のテーブル設計は細かく 分かれており分析時に不便なことが多い • 分析においてはある程度の粒度でまとまっている方が扱いやす いと考えているのでfoo社のデータ形式のようにまとめる方針 は変わらない •
その上で要求に応じて育てていくつもり ◦ もはや再現ではないのでより適切な名前で運用する予定
クエリの動作確認どうやった? 51 • csvdiffというツールを使って書き換え前後で結果が 変わっていないことを確かめた • 普通のdiffコマンドじゃだめ? ◦ diffコマンドは行単位で比較する ◦
どこがズレているのか知りたいので列単位で比較したい
テーブル定義書のメンテ方法は? 52 • tblsのlinterをCIで動かすことでコメント必須にした ◦ 開発者には自明でも他社の分析者には非自明なこともある • コメントのガイドラインがあるのが望ましいと思う がそこまではできていない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}