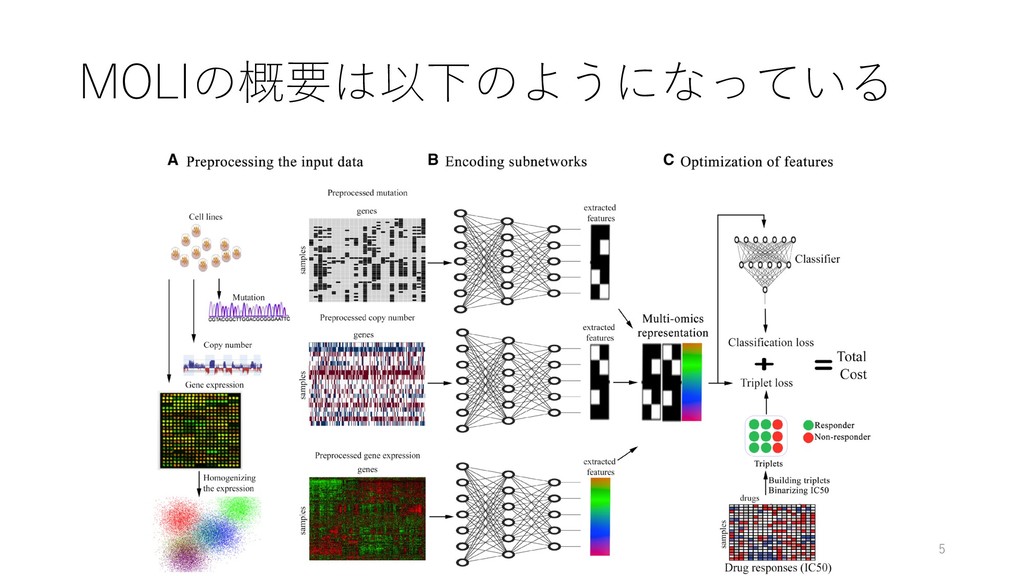
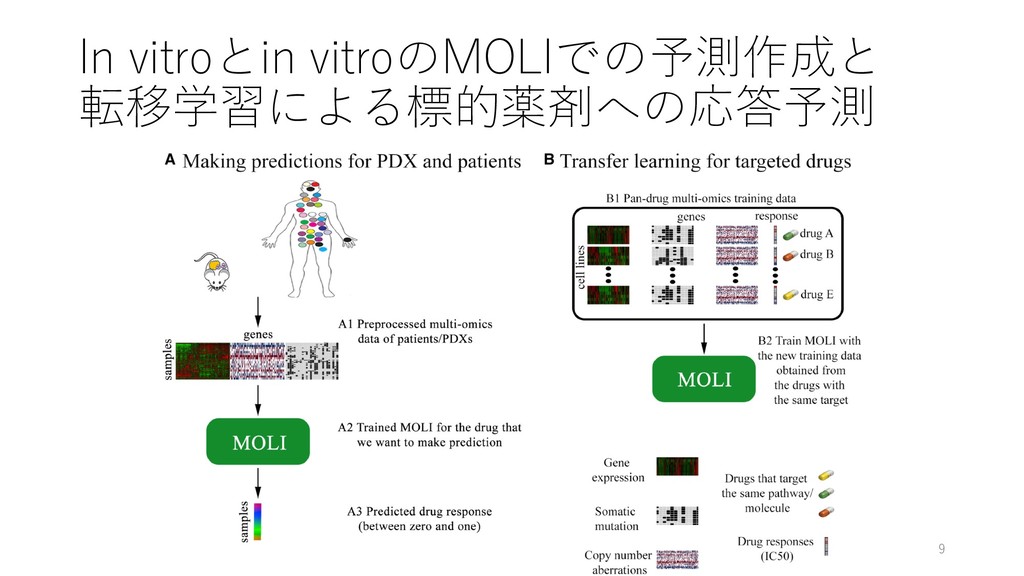
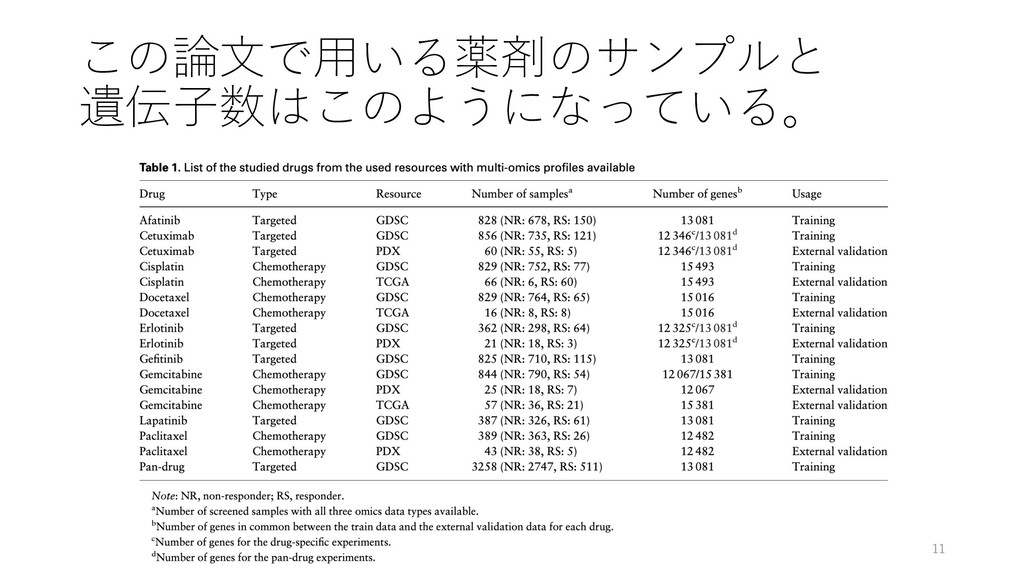
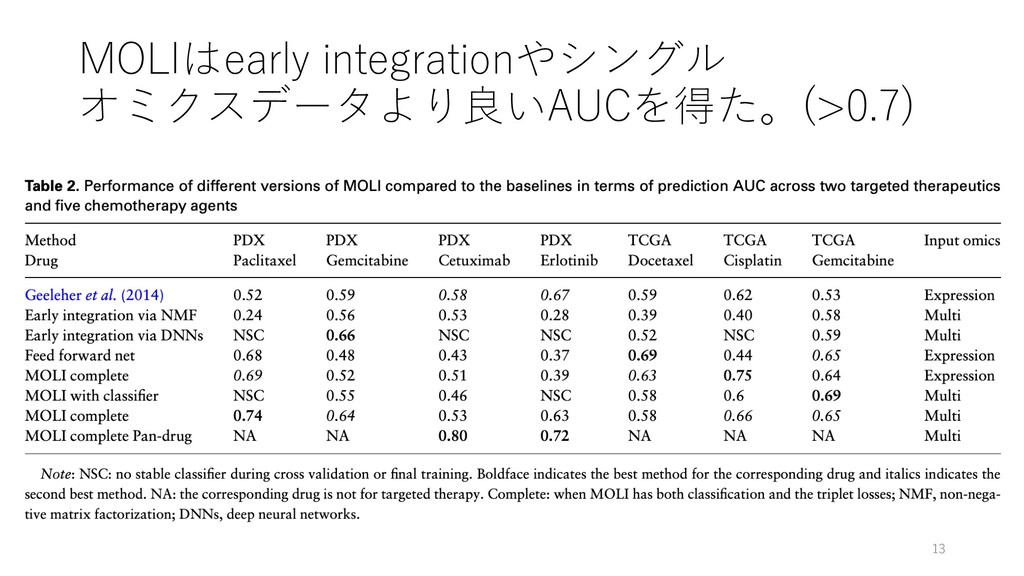
response prediction Hossein Sharifi-Noghabi, Olga Zolotareva, Colin C Collins, Martin Ester Bioinformatics, Volume 35, Issue 14, July 2019, Pages i501‒i509, https://doi.org/10.1093/bioinformatics/btz318 紹介者 たかとー @takatoh1 2019/08/21 ISMB/ECCB 2019読み会 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}