Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データの構造から再検討するパフォーマンスチューニング
Search
久保卓也
January 21, 2020
Programming
720
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データの構造から再検討するパフォーマンスチューニング
久保卓也
January 21, 2020
Other Decks in Programming
See All in Programming
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
240
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.9k
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
540
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
220
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.2k
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1k
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
280
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
180
GitHubCopilotCLIのスラッシュコマンドを自作してみる
htkym
0
100
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
180
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
190
Featured
See All Featured
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Building an army of robots
kneath
306
46k
Mobile First: as difficult as doing things right
swwweet
225
10k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Tell your own story through comics
letsgokoyo
1
1k
Abbi's Birthday
coloredviolet
3
8.8k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Transcript
freee 株式会社 データの構造から再検討するパフォーマンスチューニング 2019.01.21
takuya kubo @tkuboma 所属チーム(雑会計 人間チーム) 2 経歴 • Sierとして複数企業を転々
◦ 主に通信系のバックエンド • 事業会社で介護請求ソフトの開発に従事 ◦ 新規・保守開発、市場調査、コールセンターなど • 2017年7月 freee に join ◦ 会計チーム所属 ▪ 新規・保守開発 ◦ チーム地獄 から チーム人間 へ ▪ 申請ドメインのマイクロサービス化 ▪ 決算ドメイン周辺の保守開発 趣味 • お酒 • 子供
02 DB周りのパフォーマンス改善 01 freeeの監視周りについて簡単に Agenda 03 まとめ
01 Section freeeの監視周りについて簡単に
5 • Mackerel ◦ 外形監視・サーバーレベルで監視 ◦ Slackに通知 • NewRelic ◦
アプリケーションの性能監視 ◦ ボトルネックとなっている End-point 確認 • Monyog ◦ queryレベルで監視 ◦ メール通知 • Datadog (最近導入し始めた) ◦ Kubernetes環境の監視に、より適切なSaaSとして導入 freeeの監視周りについて簡単に SaaSの紹介
02 Section DB周りのパフォーマンス改善
7 DB周りのパフォーマンス改善 1. indexでチューニング 2. クエリの変更でチューニング 3. データの持ち方の見直し 4. テーブル構成の見直し
5. 機能の見直し
8 DB周りのパフォーマンス改善 1. indexでチューニング 2. クエリの変更でチューニング 3. データの持ち方の見直し 4. テーブル構成の見直し
5. 機能の見直し
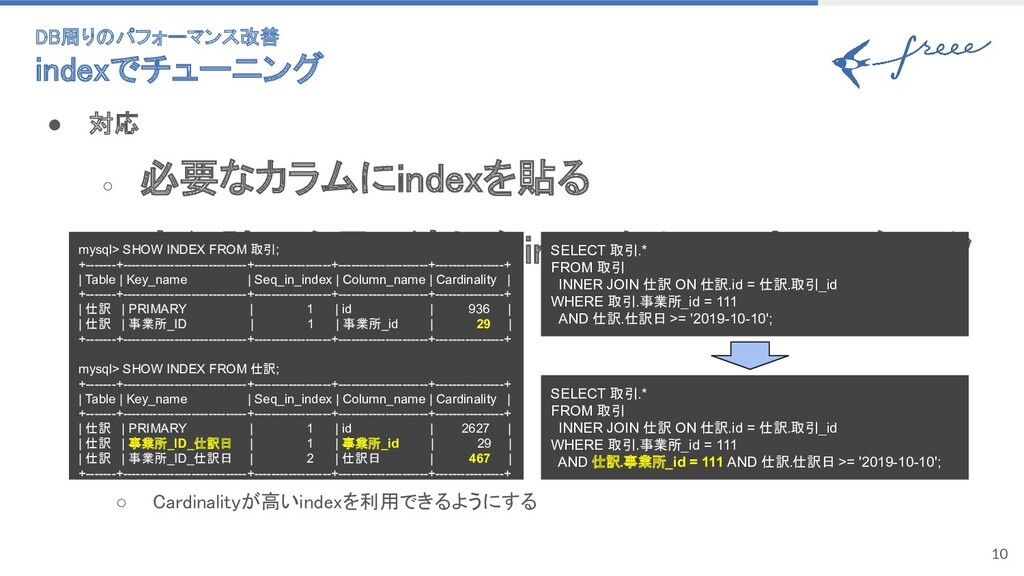
9 • 内容 ◦ 単純にindexを貼る必要がある ◦ indexを利用できていない DB周りのパフォーマンス改善
indexでチューニング explain SELECT * FROM 取引先 WHERE 名前 = '株式会社A' ************* 1. row ************* id: 1 select_type: SIMPLE table: 取引先 partitions: NULL type: ALL explain SELECT 取引.* FROM 取引 INNER JOIN 仕訳 ON 仕訳.id = 仕訳.取引_id WHERE 取引.事業所_id = 111 AND 仕訳.仕訳日 >= '2019-10-10'; *************** 1. row **************** key: index=取引_事業所_id
10 • 対応 ◦ 必要なカラムにindexを貼る ◦ 実行計画を見て適切なindexを利用できていないク エリの修正 SELECT 取引.*
FROM 取引 INNER JOIN 仕訳 ON 仕訳.id = 仕訳.取引_id WHERE 取引.事業所_id = 111 AND 仕訳.事業所_id = 111 AND 仕訳.仕訳日 >= '2019-10-10'; mysql> SHOW INDEX FROM 取引; +-------+-----------------------------+------------------+---------------------+----------------+ | Table | Key_name | Seq_in_index | Column_name | Cardinality | +-------+-----------------------------+------------------+---------------------+----------------+ | 仕訳 | PRIMARY | 1 | id | 936 | | 仕訳 | 事業所_ID | 1 | 事業所_id | 29 | +-------+-----------------------------+------------------+---------------------+----------------+ mysql> SHOW INDEX FROM 仕訳; +-------+-----------------------------+------------------+---------------------+----------------+ | Table | Key_name | Seq_in_index | Column_name | Cardinality | +-------+-----------------------------+------------------+---------------------+----------------+ | 仕訳 | PRIMARY | 1 | id | 2627 | | 仕訳 | 事業所_ID_仕訳日 | 1 | 事業所_id | 29 | | 仕訳 | 事業所_ID_仕訳日 | 2 | 仕訳日 | 467 | +-------+-----------------------------+------------------+---------------------+----------------+ SELECT 取引.* FROM 取引 INNER JOIN 仕訳 ON 仕訳.id = 仕訳.取引_id WHERE 取引.事業所_id = 111 AND 仕訳.仕訳日 >= '2019-10-10'; ◦ Cardinalityが高いindexを利用できるようにする DB周りのパフォーマンス改善 indexでチューニング
11 仕訳model scope :仕訳日以上, ->(日付) do where('仕訳日カラム >= ?', 日付)
end • なぜ漏れる? ◦ ActiveRecord の scope を利用している ◦ 仕訳modelは事業所modelとの関連があり、「事業所.仕訳.scope」と呼び出す為 indexは使われる ◦ joinの時は事業所情報が入らない為、改善前のクエリとなる > 事業所.仕訳.仕訳日以上('2019-10-10') SELECT * FROM 仕訳 WHERE 仕訳.事業所_id = '111' AND 仕訳.仕訳日 >= '2020-01-01' > 事業所.取引.joins(仕訳).merge(仕訳.仕訳日以上('2019-10-10')) SELECT * FROM 取引 INNER JOIN 仕訳 ON 仕訳.取引_id = 取引.id WHERE 取引.事業所_id = '111' AND 仕訳.仕訳日 >= '2020-01-01' 仕訳model scope :仕訳日以上, ->(事業所_id, 日付) do where('事業所_id = ? AND 仕訳日カラム >= ?', 事業所_id, 日付) end > 事業所.取引.joins(仕訳).merge(仕訳.仕訳日以上(111, '2019-10-10')) SELECT * FROM 取引 INNER JOIN 仕訳 ON 仕訳.取引_id = 取引.id WHERE 取引.事業所_id = '111' AND 仕訳.事業所_id = '111' AND 仕訳.仕訳日 >= '2020-01-01' DB周りのパフォーマンス改善 indexでチューニング
12 • 注意している事 ◦ indexを貼る時間(通常デプロイで実施する か、メンテでやるか) ◦ 業務、データを考え無駄にindexを貼らない ◦ 修正を検証する際は本番相当のデータで
検証する DB周りのパフォーマンス改善 indexでチューニング
13 DB周りのパフォーマンス改善 1. indexでチューニング 2. クエリの変更でチューニング 3. データの持ち方の見直し 4. テーブル構成の見直し
5. 機能の見直し
14 • 内容 ◦ 対象データのrowが大きすぎる mysql> SELECT DISTINCT
仕訳.取引先_id FROM 仕訳 WHERE 仕訳.ユーザー_id = 111; ----------- 4001 rows in set (12.37 sec) explain SELECT DISTINCT 仕訳.取引先_id FROM 仕訳 WHERE 仕訳.事業所_id = 111; ***** 1. row ***** rows: 20000000 ◦ 仕訳はユーザ内で最大級のレコードを誇るテーブル DB周りのパフォーマンス改善 クエリの変更でチューニング
15 • 対応 ◦ rowが絞られるテーブルをクエリに加える mysql> SELECT DISTINCT
仕訳.取引先_id FROM 仕訳 WHERE 仕訳.事業所_id = 111; ----------- 4001 rows in set (12.37 sec) mysql> SELECT DISTINCT 取引先.id FROM 取引先 INNER JOIN 仕訳 ON partners.id = 仕訳.取引先_id WHERE 取引先.事業所_id = 111; ----------- 4000 rows in set (0.10 sec) ***** 1. row ***** rows: 20000000 ***** 1. row ***** rows: 3000 ***** 2. row ***** rows: 40 ◦ より少ない取引先のテーブルを条件に入れることによりrowがへり劇的に早くなる DB周りのパフォーマンス改善 クエリの変更でチューニング
16 • 注意している事 ◦ テーブルのデータの増加の角度 ◦ クエリの結果が変わらないか否か ◦ アプリケーション側に処理を委任する形になる 為、アプリケーション側への負荷増
DB周りのパフォーマンス改善 クエリの変更でチューニング
17 DB周りのパフォーマンス改善 1. indexでチューニング 2. クエリの変更でチューニング 3. データの持ち方の見直し 4. テーブル構成の見直し
5. 機能の見直し
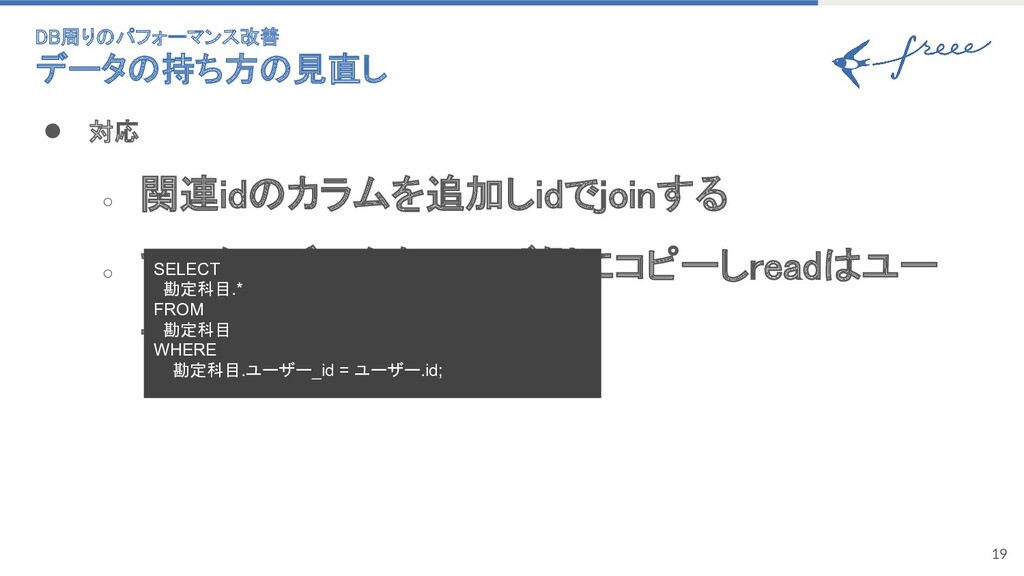
18 • 内容 ◦ idではなくStringでjoinしている ◦ マスターデータと共存する情報が存在する SELECT 勘定科目.*
FROM 勘定科目 WHERE 勘定科目.ユーザー_id = システムユーザー.id UNION SELECT 勘定科目.* FROM 勘定科目 WHERE 勘定科目.ユーザー_id = ユーザー.id; DB周りのパフォーマンス改善 データの持ち方の見直し
19 • 対応 ◦ 関連idのカラムを追加しidでjoinする ◦ マスターデータをユーザ側にコピーしreadはユー ザーデータのみにする SELECT
勘定科目.* FROM 勘定科目 WHERE 勘定科目.ユーザー_id = ユーザー.id; DB周りのパフォーマンス改善 データの持ち方の見直し
20 • 注意している事 ◦ マスターデータをコピーするタイミング ◦ ある程度サービスが大きくなってからだと修正コスト が高い為、設計段階で検討したい ◦ 頻繁にマスターデータが変更されるテーブルの場
合、メンテコストが高くなる為別の対処を検討 ▪ 最初からクエリを分けるなど DB周りのパフォーマンス改善 データの持ち方の見直し
21 DB周りのパフォーマンス改善 1. indexでチューニング 2. クエリの変更でチューニング 3. データの持ち方の見直し 4. テーブル構成の見直し
5. 機能の見直し
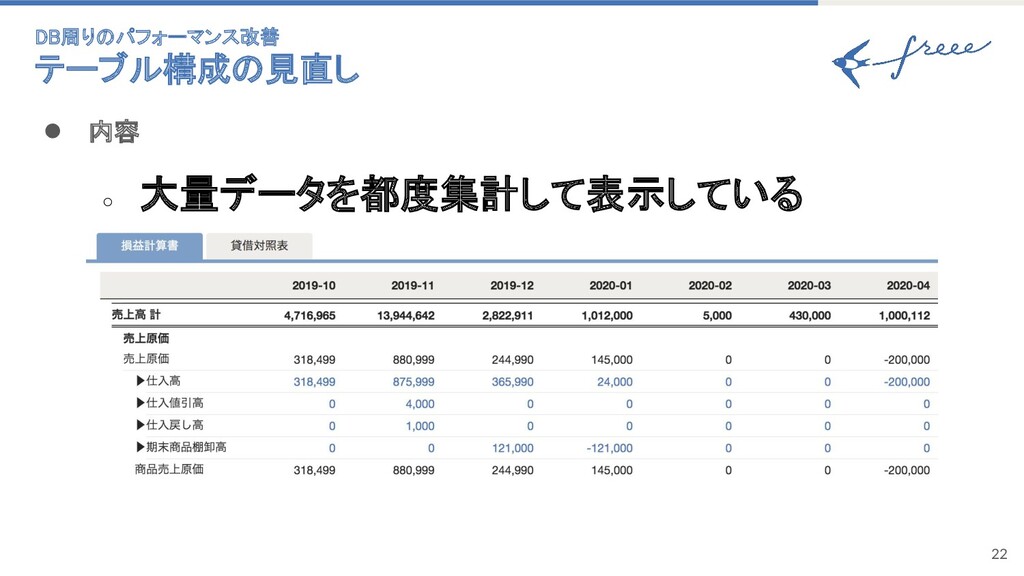
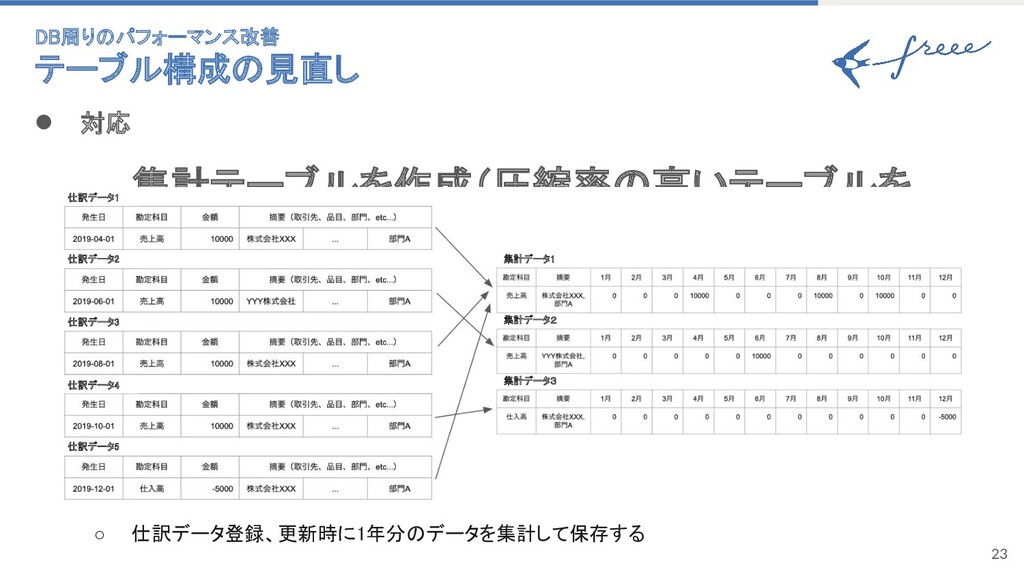
22 • 内容 ◦ 大量データを都度集計して表示している DB周りのパフォーマンス改善 テーブル構成の見直し
23 • 対応 ◦ 集計テーブルを作成(圧縮率の高いテーブルを 作成) ◦ 仕訳データ登録、更新時に1年分のデータを集計して保存する
仕訳データ1 仕訳データ2 仕訳データ3 仕訳データ4 仕訳データ5 集計データ1 集計データ2 集計データ3 DB周りのパフォーマンス改善 テーブル構成の見直し
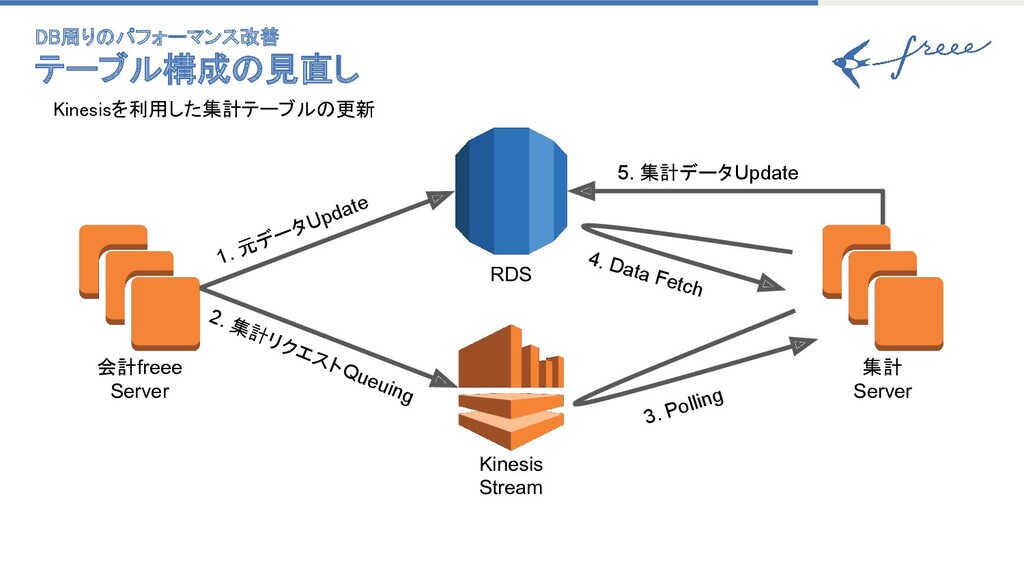
24 • 新たな問題も発生 ◦ 登録時のパフォーマンス ◦ 楽観ロックエラー ◦ ギャップロックによるロック待ち ◦
ファントムリードによるデータ不整合 • 対策 ◦ 集計データの保存を別トランザクションで非同期 に 仕訳データ の保存 集計データ の保存 DB周りのパフォーマンス改善 テーブル構成の見直し
Kinesisを利用した集計テーブルの更新 Kinesis Stream RDS 集計 Server 会計freee
Server 1. 元データUpdate 2. 集計リクエストQueuing 3. Polling 4. Data Fetch 5. 集計データUpdate DB周りのパフォーマンス改善 テーブル構成の見直し
26 • 注意している事 ◦ 集計テーブルのデータの切り方 ◦ 登録時のコスト増 ◦ 集計データ表示のリアルタイム性を損なうため ユーザーへの告知など
◦ 改善にはかなりの時間がかかる DB周りのパフォーマンス改善 テーブル構成の見直し
27 DB周りのパフォーマンス改善 1. indexでチューニング 2. クエリの変更でチューニング 3. テーブル構成の見直し 4. データの持ち方の見直し
5. 機能の見直し
28 • 内容 ◦ 必要以上に実行されている可能性を疑う ▪ Home画面アクセスで呼ばれる DB周りのパフォーマンス改善 機能の見直し
29 • 対応 ◦ ユーザーアクションベースでの取得に変更 ◦ 非同期化 • 注意している事 ◦
ビジネスサイド(ユーザー)とのコミュニケーション ◦ ユーザーメリットと運用コストについて DB周りのパフォーマンス改善 機能の見直し
30 • slaveへ ◦ 影響ないselect系はslaveへ ◦ writeが多いサービスは replication latency に注
意 • N + 1の解消 ◦ bullet の導入 • 検索部分の Elasticsearch 化 ◦ 大量データの条件検索時 DB周りのパフォーマンス改善 その他
03 Section まとめ
32 • チューニングは適宜実施しましょう • マスターデータとの共存は可能な限り避けましょう • 構成の見直しは早めにしましょう まとめ
スモールビジネスを、 世界の主役に。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}