the leader of Birmingham. 2. John Madin was born in this city. 3. He was the architect of 103 Colmore Row. John Clancy is a labour politican who leads Birmingham, where architect John Madin, who designed 103 Colmore Row, was born. 2 Complex Sentence
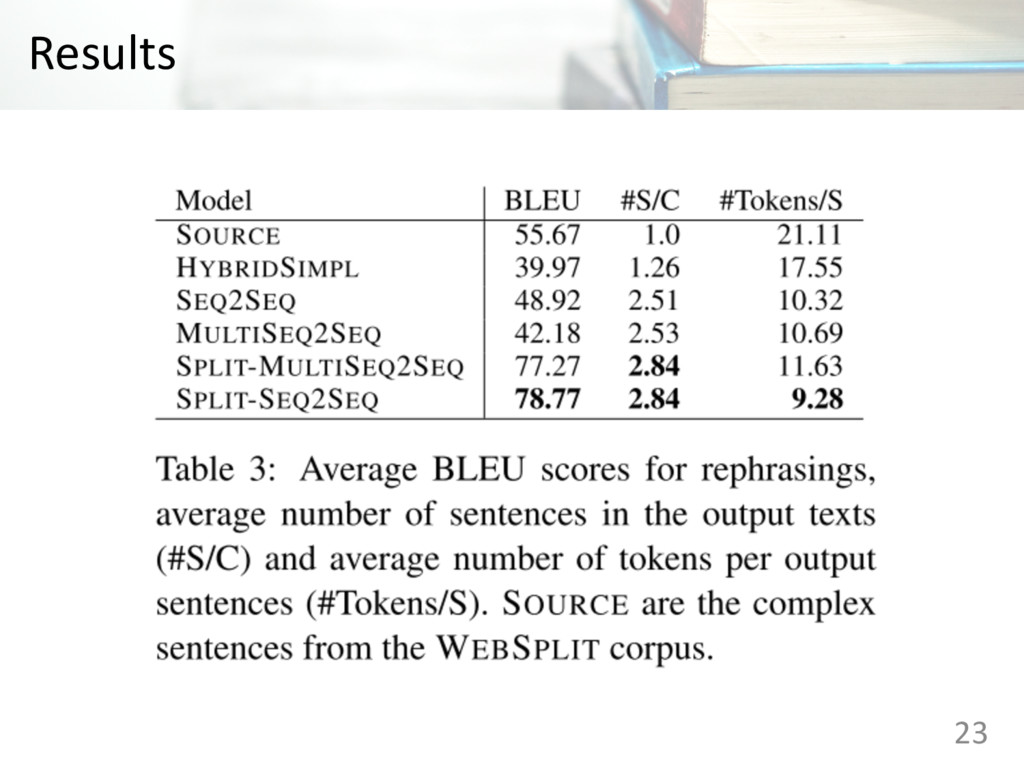
• Creating and making available benchmark for Split-and-Rephrase systems https://github.com/shashiongithub/Split-and-Rephrase • Providing five models to understand difficulty of this task 5
consists of a set of RDF triples and one or more text Ø RDF (Resource Description Format) triple • Framework for representing information in the Web • Format: (subject | property | object) “John was born in New York.”: (John | Birth place |New York) subject John object New York property Birth place 7
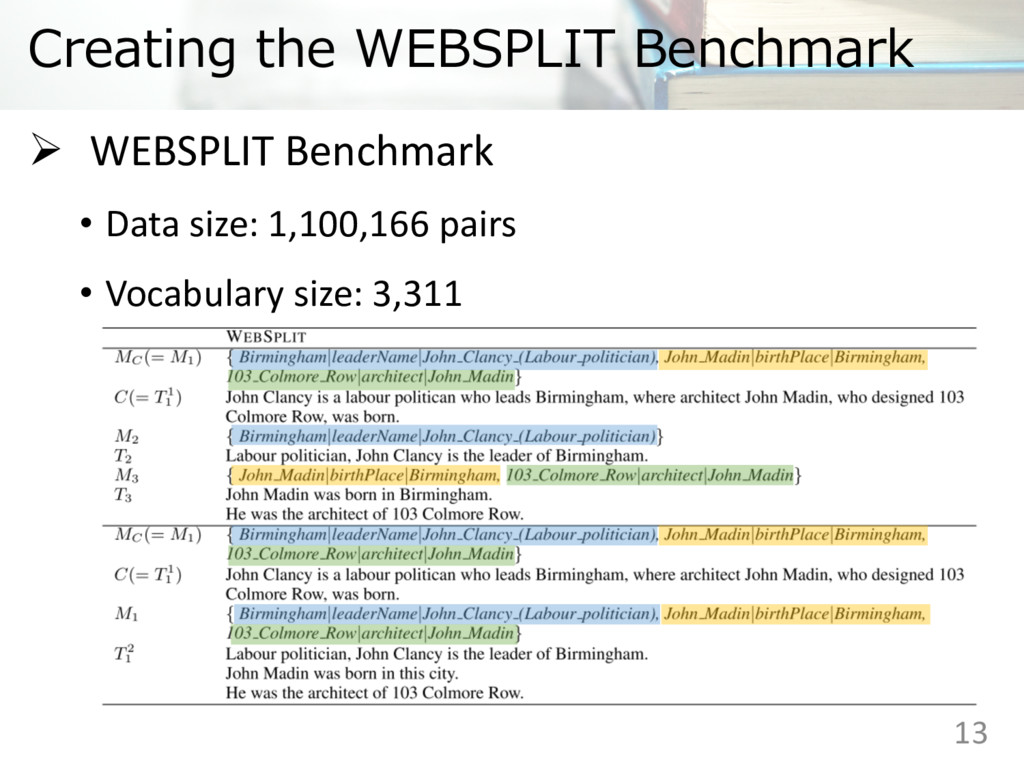
WEBSPLIT dataset 1. Sentence segmentation − 13,308 verbalisations contained WEBNLG corpus − Using Stanford CoreNLP pipeline 2. Pairing using semantic information 3. Ordering on sequences of texts 10
, , , … , : Sequence of texts , … , : Meaning representation of , … , : Single complex sentence : Meaning representation of = ∪ ⋯ ∪ Ø 3 steps of creating the WEBSPLIT dataset 1. Sentence segmentation 2. Pairing using semantic information 3. Ordering on sequences of texts
WEBSPLIT dataset 1. Sentence segmentation 2. Paring using semantic information 3. Ordering on sequences of texts − Corresponding to left-to-right depth-first traversal of RDF triple 12
Multi-source encoder-decoder model • To encode : − Complex sentence () − Meaning representation (4) which linearized by doing depth-first left-right RDF tree traversal 19 Encoder Decoder
and making available benchmark for Split-and-Rephrase systems https://github.com/shashiongithub/Split-and-Rephrase Ø Providing five models to understand difficulty of this task 25
Loria, “Creating Training Corpora for NLG Micro-Planning,” In Proceedings of ACL, 2017. [2] S. Narayan, D. Lorraine, and C. Gardent, “Hybrid Simplification using Deep Semantics and Machine Translation,” Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, pp. 435–445, 2014. [3] M. Luong, H. Pham, and C. D. Manning, “Effective Approaches to Attention based Neural Machine Translation,” Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pp. 1412–1421, 2015. [4] B. Zoph and K. Knight, “Multi-Source Neural Translation,” Proceedings of NAACL-HLT, pp. 30–34, 2016.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] C. Gardent, A. Shimorina, S. Narayan, and P.](https://files.speakerdeck.com/presentations/242276f789be477387b26c3067fc9741/slide_25.jpg){kind=link}