2021 5 • 2021/8/16初出のホワイト ペーパーで登場した⾔葉 • Stanfordの研究機関の名称にも なっている(⻘枠) (Abstractより抜粋) “AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT- 3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character”
2) Masked Language Model ⼤規模Transformer ⼤規模Transformer Input: Language models determine Output: word probability by analyzing text data Input: Language models determine [mask] [mask] by [mask] text data Input: Language models determine word probability by analyzing text data Original: Language models determine word probability by analyzing text data 最近の成功している⾔語モデルはほぼ上記のような構造を利⽤
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
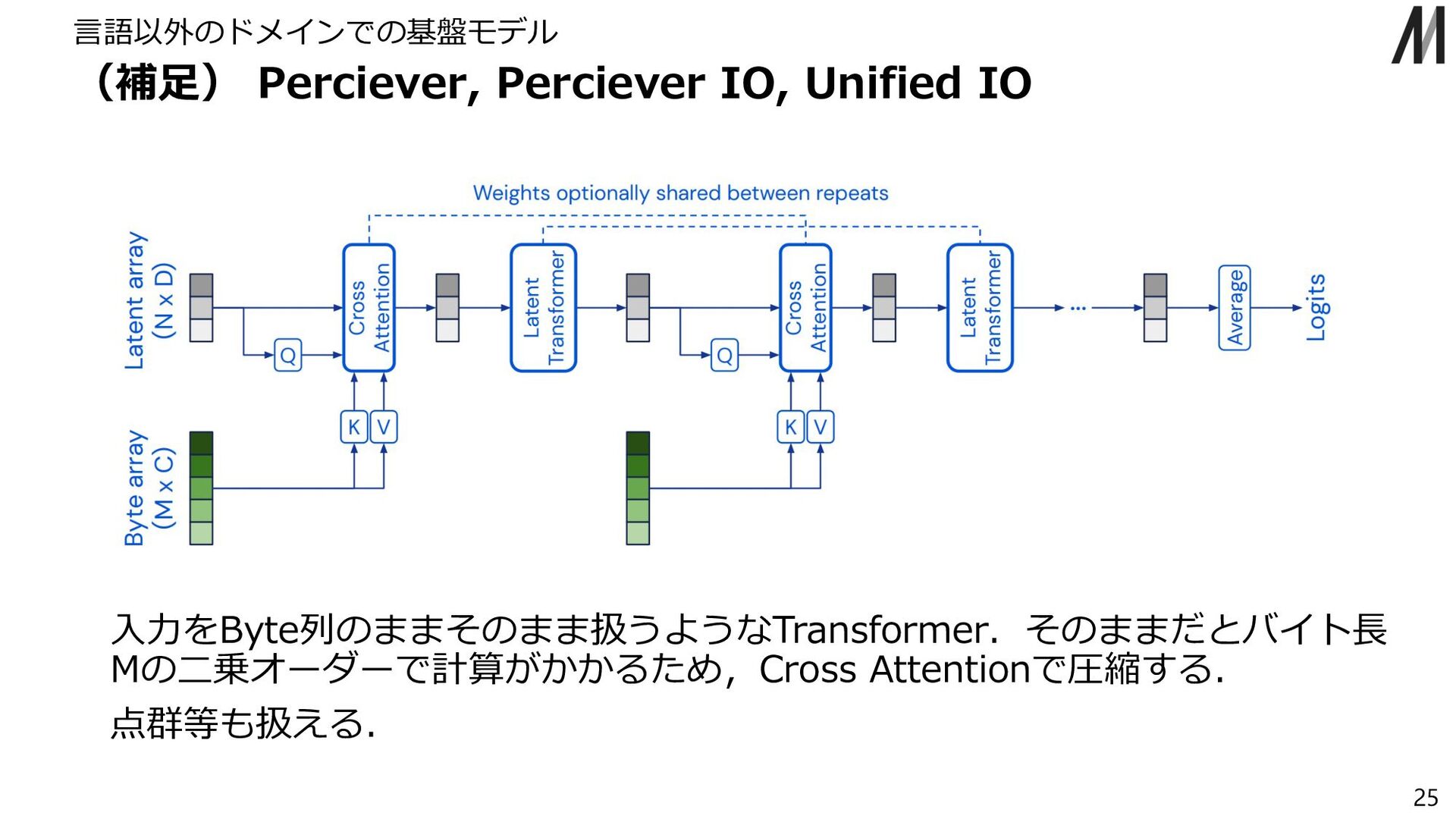{kind=link}
{kind=link}
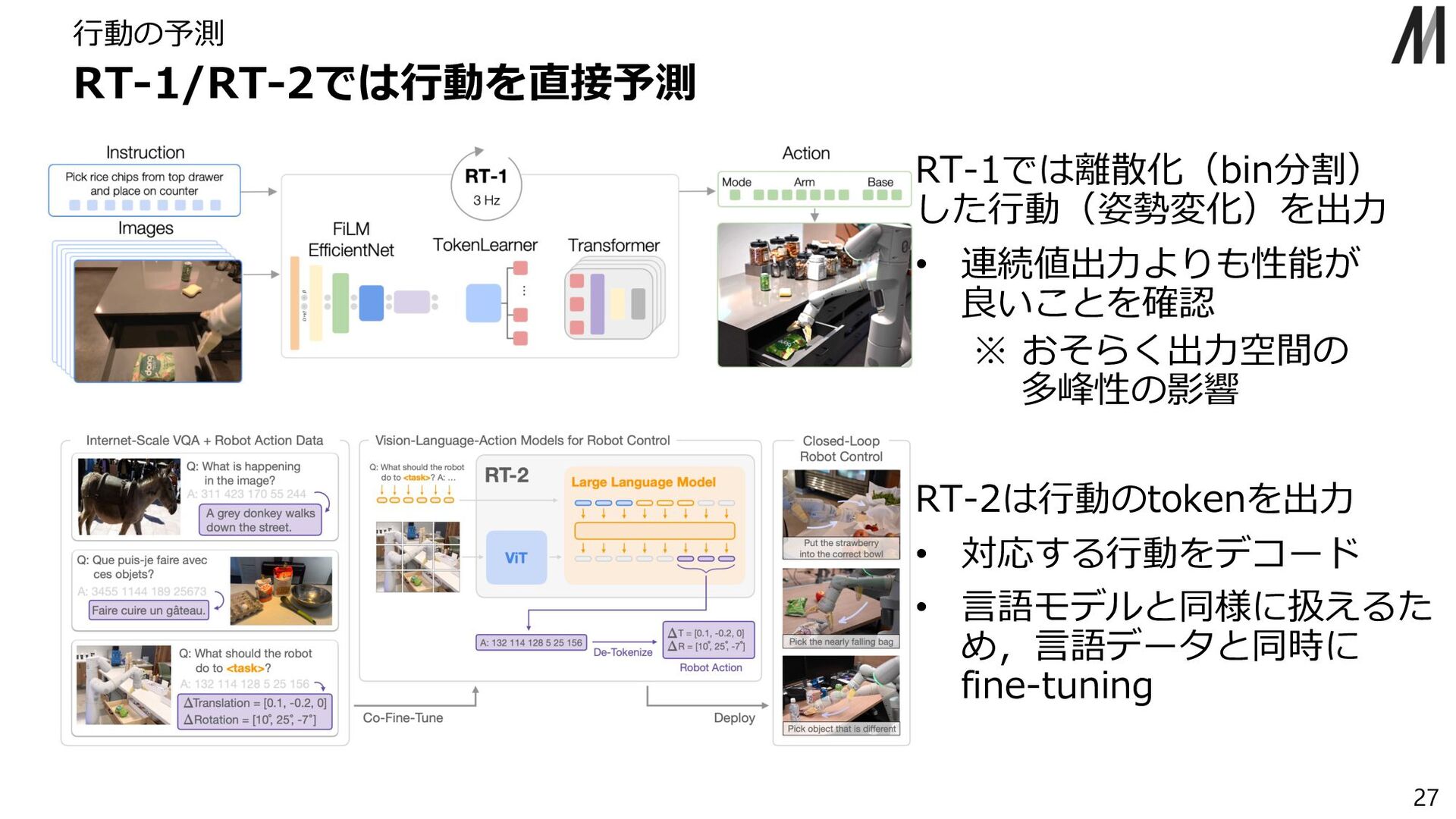{kind=link}
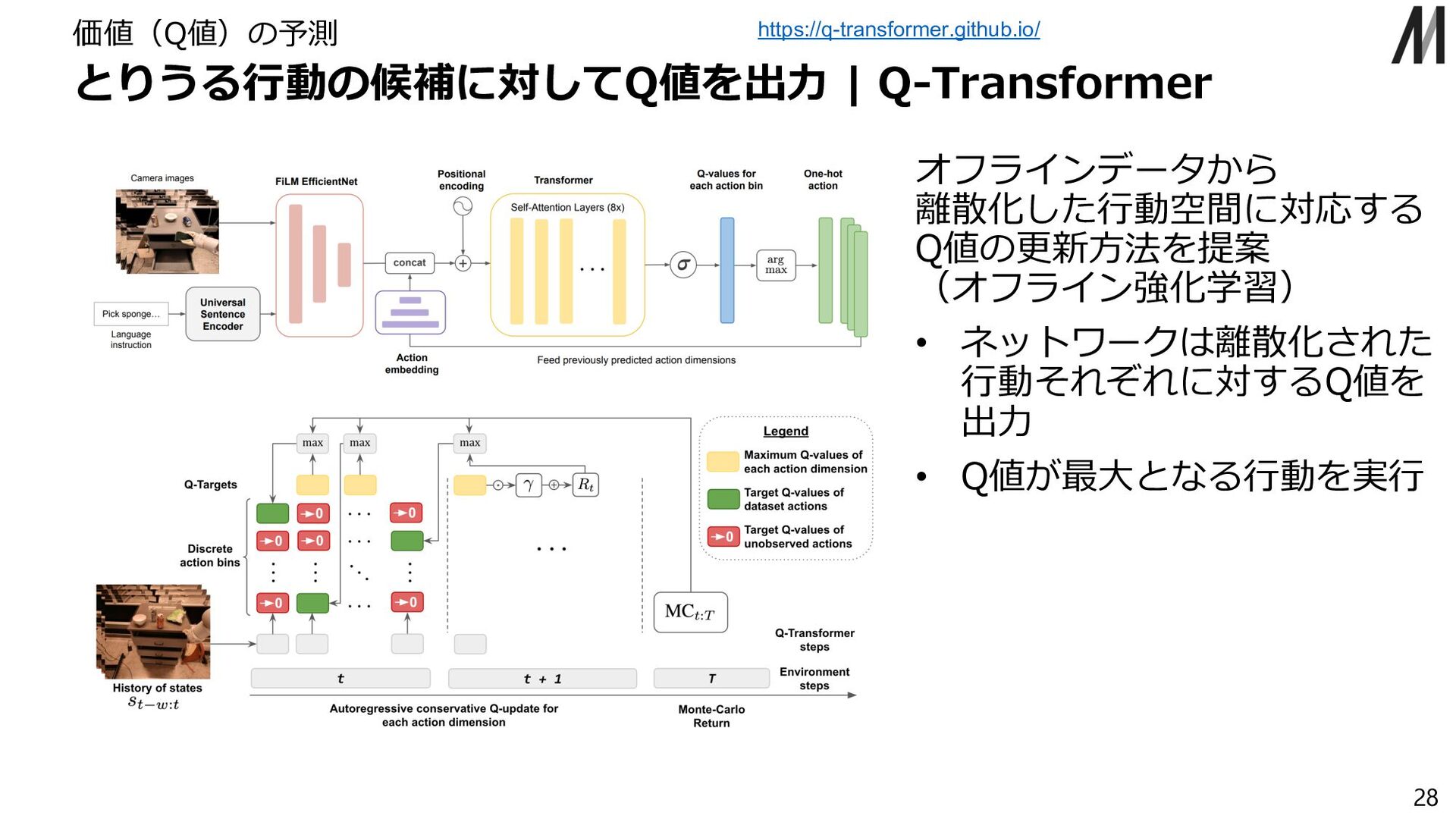{kind=link}
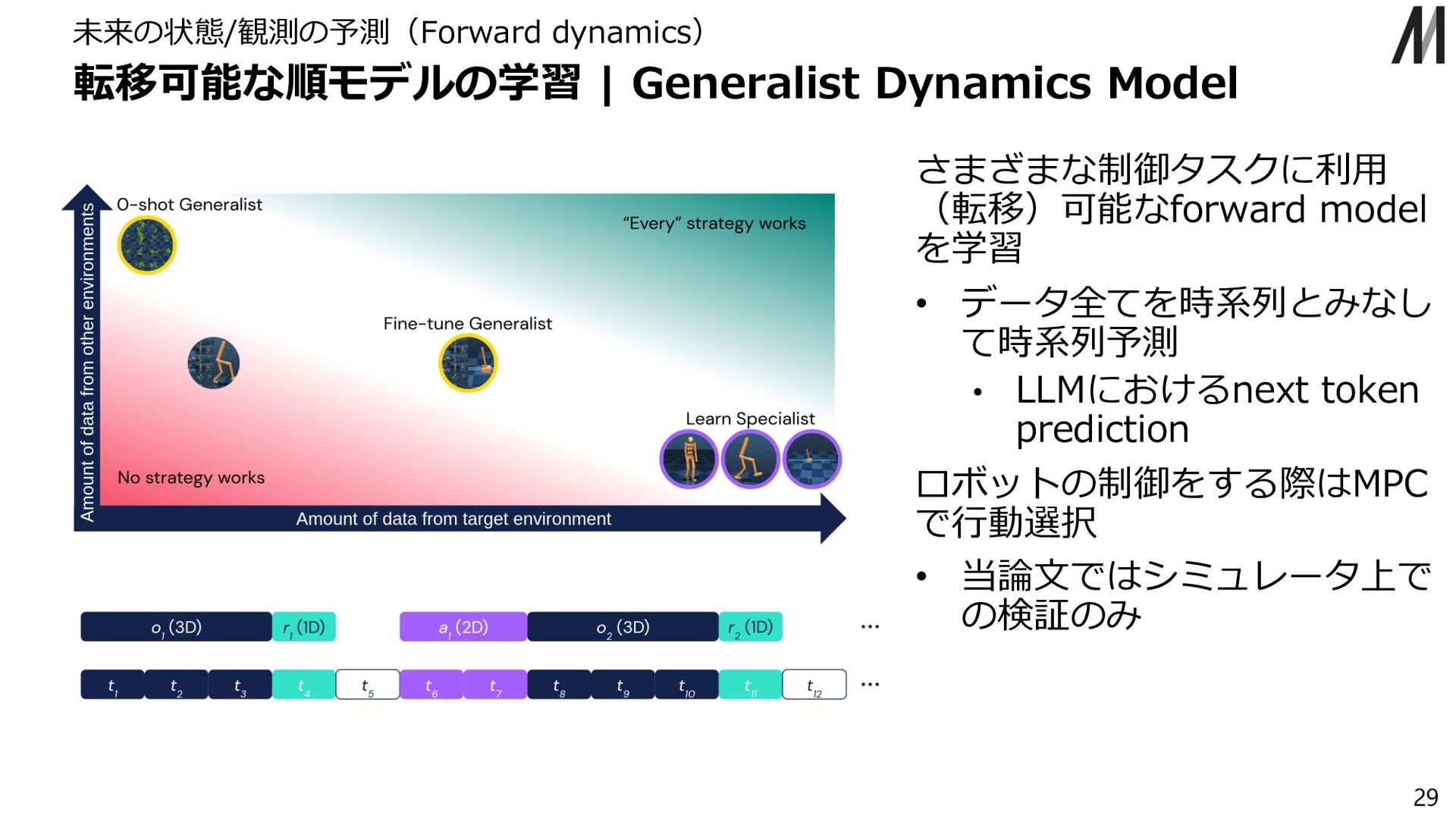{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}