How your online activity allows recruiters to predict whether you're looking for a job
I look at how a real machine learning model that combines Github, Hacker News posts and career and education data can predict with good accuracy whether tech workers are looking for jobs and its impact on the market
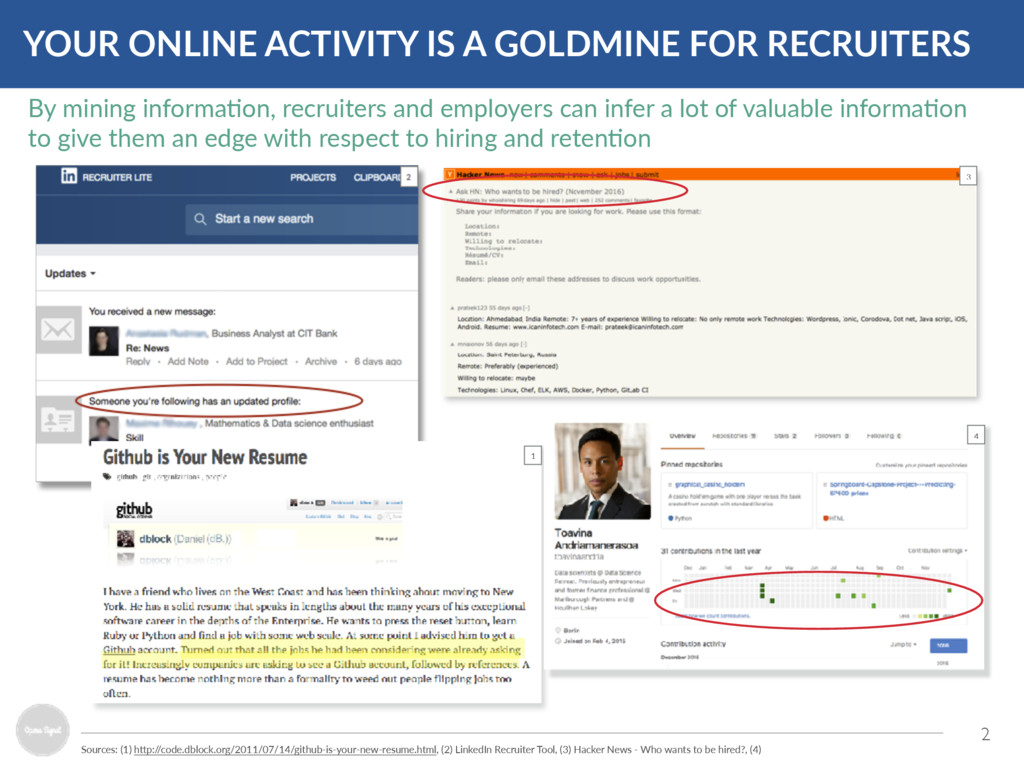
(1) h.p:/ /code.dblock.org/2011/07/14/github-is-your-new-resume.html, (2) LinkedIn Recruiter Tool, (3) Hacker News - Who wants to be hired?, (4) 1 By mining informaOon, recruiters and employers can infer a lot of valuable informaOon to give them an edge with respect to hiring and retenOon 3 4
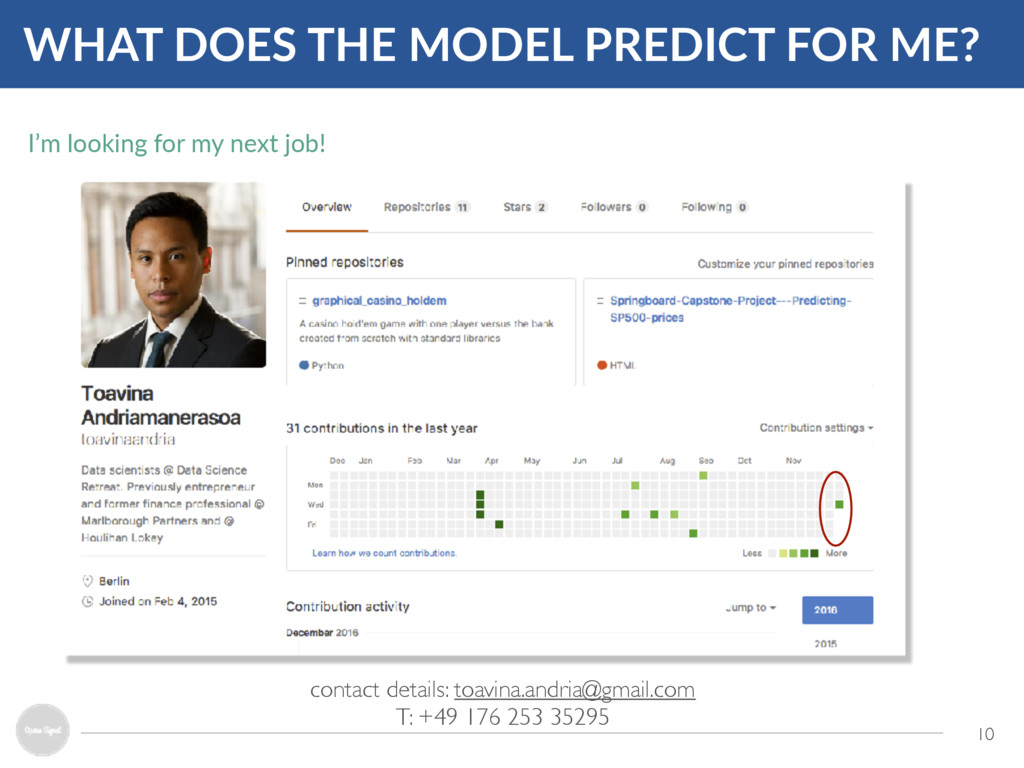
THAT PREDICTS WHETHER YOU ARE LOOKING FOR A JOB By using Hacker News - Who Wants to be Hired and LinkedIn as proxies for when tech workers are looking for jobs, we can see whether Github acOvity spikes precede job changes / events on REST API User profiles Data • GitHub events (creaOng repos, push requests…) by user, date • Personal user data (name, email, locaOon, followers)… • Posts on HN - Who wants to be hired? • User profiles - Jobs, educaOon, tenure… Purpose • Inferring Github acOvity • AddiOonal features • IdenOfying users on other databases • Source for dependent variable - i.e. people post that they are looking for jobs • AddiOonal features • Source for dependent variable ex-post
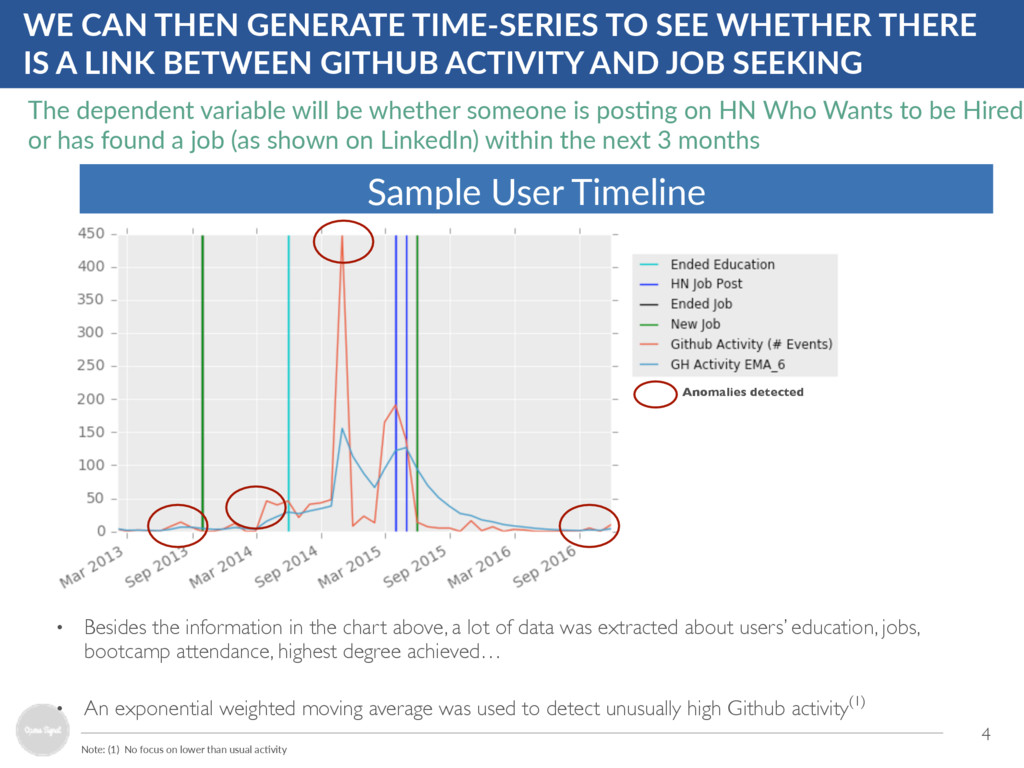
of data was extracted about users’ education, jobs, bootcamp attendance, highest degree achieved… • An exponential weighted moving average was used to detect unusually high Github activity(1) 4 WE CAN THEN GENERATE TIME-SERIES TO SEE WHETHER THERE IS A LINK BETWEEN GITHUB ACTIVITY AND JOB SEEKING Note: (1) No focus on lower than usual acOvity The dependent variable will be whether someone is posOng on HN Who Wants to be Hired or has found a job (as shown on LinkedIn) within the next 3 months Anomalies detected Sample User Timeline
HELPED IMPROVE PREDICTION PERFORMANCE SIGNIFICANTLY PCA & Scaling Resampling Model SelecOon & Tweaking • Imbalanced dataset (c. 74% in class 0) • Combined over-sampling minority class and under- sampling other class • Tried many models • Extremely Randomised Trees best performing model by far • Through tweaking and GridSearch, selected optimal parameters for the main model Reducing dimensionality, resampling, selecOng the appropriate model led to significant improvements in Area under ROC curve Note: (1) vs. Scikitlearn’s standard Extremely Randomised Trees model with default parameters Improved AUC by c. 286 basis points(1) Improved AUC by c. 156 basis points(1) Improved AUC by c. 40 basis points(1)
features as shown by feature importance when running the tree model were: • Moving average of GitHub activity and their difference with actual value • Number of GitHub events in that particular month • Number of public repos, GitHub Followers • Number of public Gists
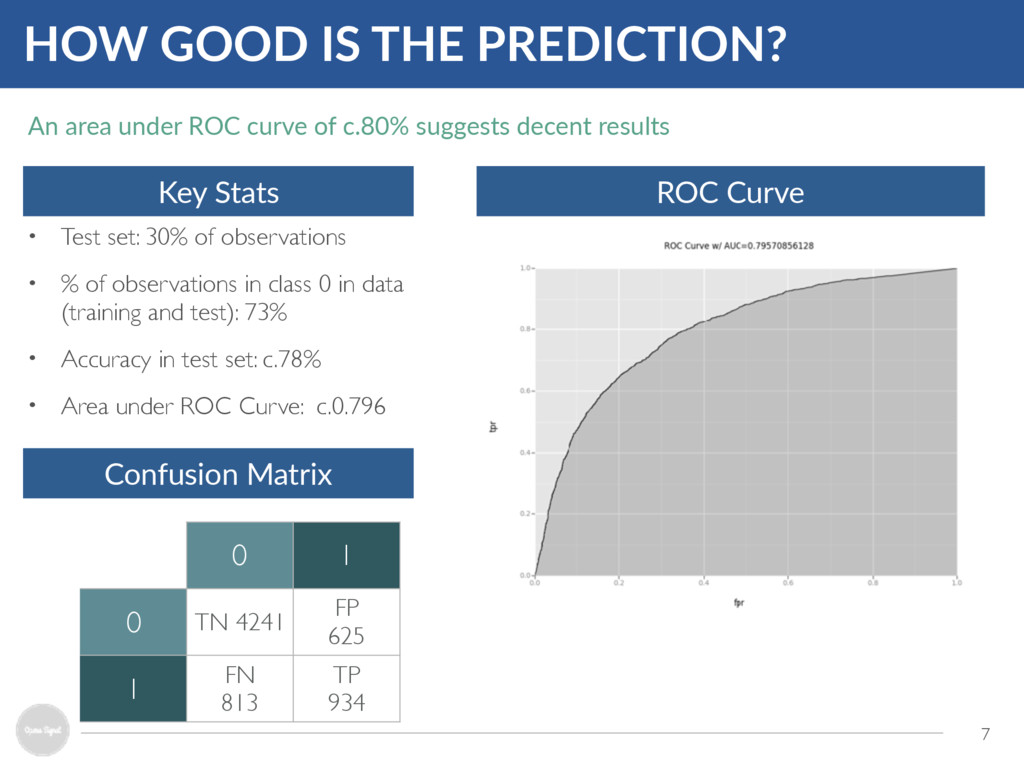
in class 0 in data (training and test): 73% • Accuracy in test set: c.78% • Area under ROC Curve: c.0.796 7 HOW GOOD IS THE PREDICTION? Key Stats ROC Curve An area under ROC curve of c.80% suggests decent results Confusion Matrix 0 1 0 TN 4241 FP 625 1 FN 813 TP 934
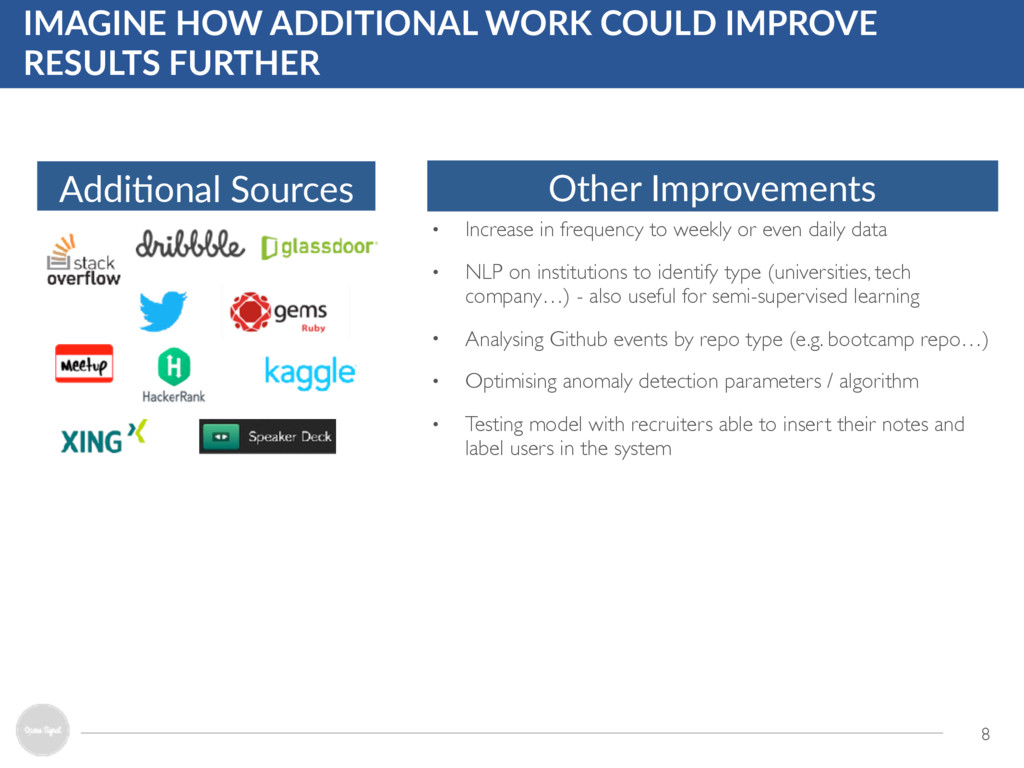
Sources Other Improvements • Increase in frequency to weekly or even daily data • NLP on institutions to identify type (universities, tech company…) - also useful for semi-supervised learning • Analysing Github events by repo type (e.g. bootcamp repo…) • Optimising anomaly detection parameters / algorithm • Testing model with recruiters able to insert their notes and label users in the system
will continue to use more and more data to identify the best potential employees • Should result in better targeting, timing and less nuisance calls / cold emails for you - Great! • If you do not have much online presence (especially if junior), you may miss out and be ignored vs. other users - Good or bad, depending on situation • More time required to curate online presence and create portfolio, but • Great potential rewards from increased visibility • However employers can also use the same information • If you are not anonymous, employers could identify employees looking to leave the ship - good if they are retaining you, but could make it easier to let you go
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}