This is an attempt on analyzing and finding correlations between node usage metrics (CPU, IO, etc.) and API level responsiveness. For node and container level metrics collection, prometheus was used. Istio/Jaeger was used to collect API level traces.
![マイクロサービスと kubernetes の性能分析 岩本俊弘 <[email protected]>](https://files.speakerdeck.com/presentations/3e6eededc81d42fa985c843cbd802e20/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
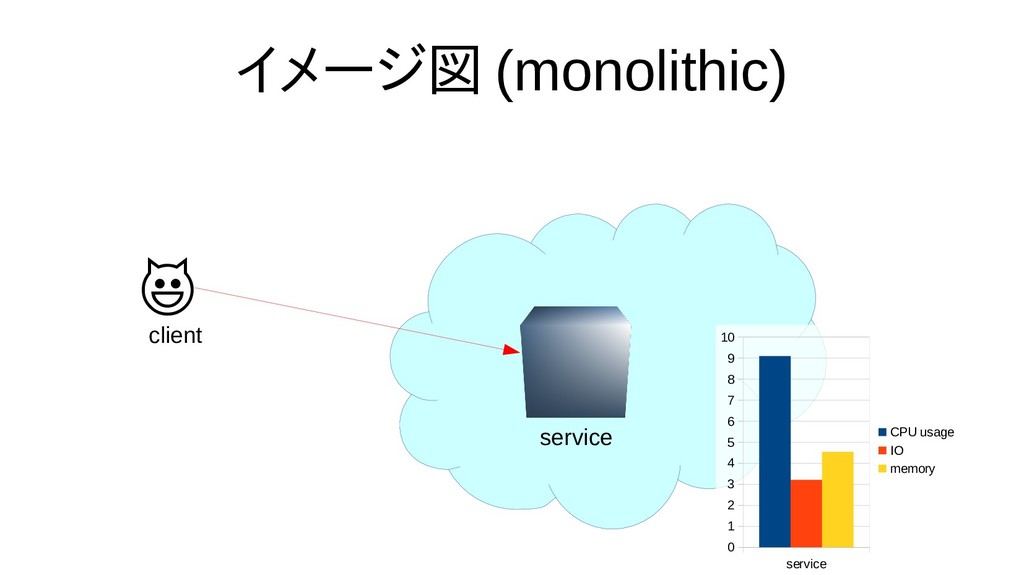{kind=link}
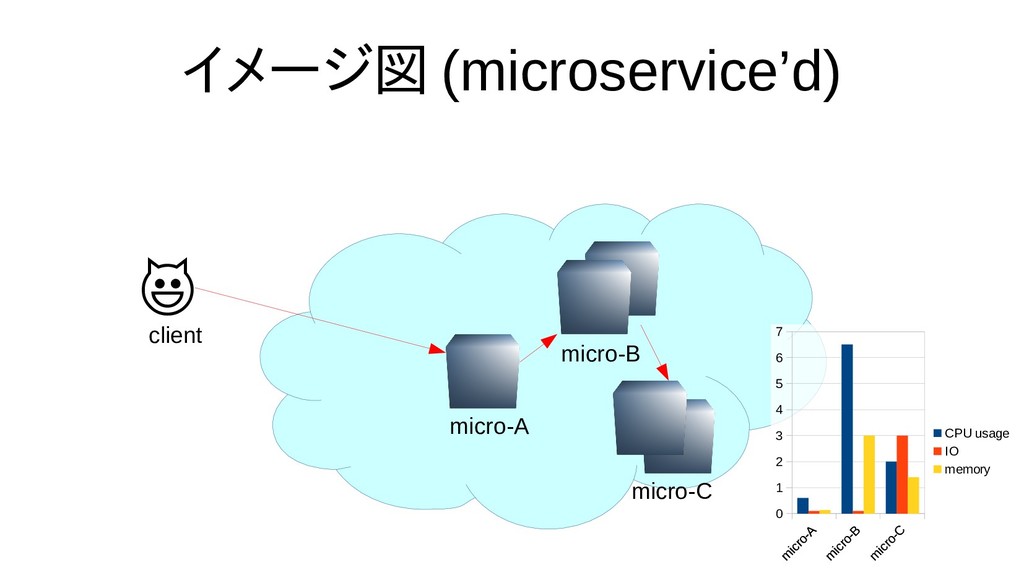
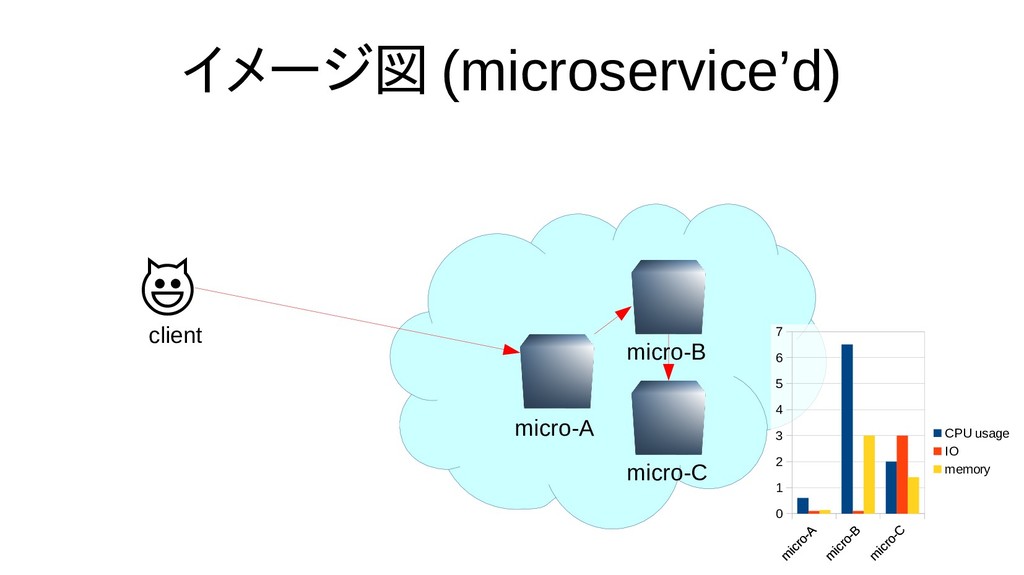{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
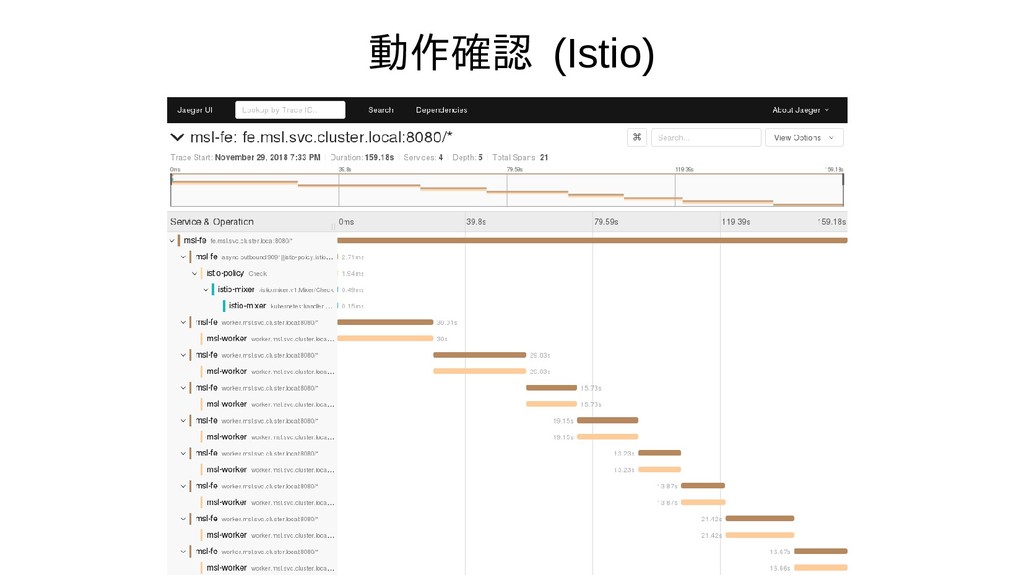{kind=link}
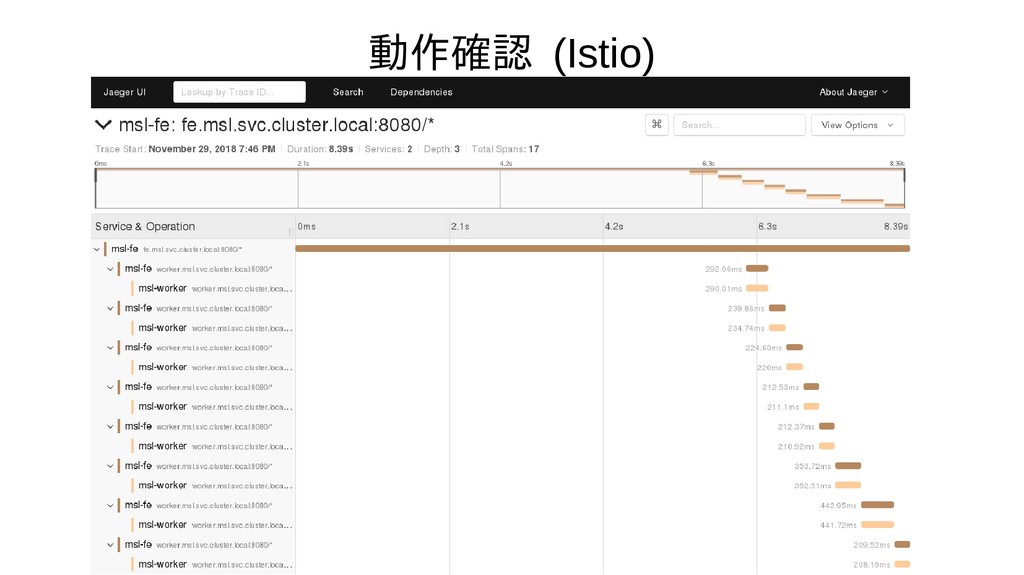{kind=link}
{kind=link}
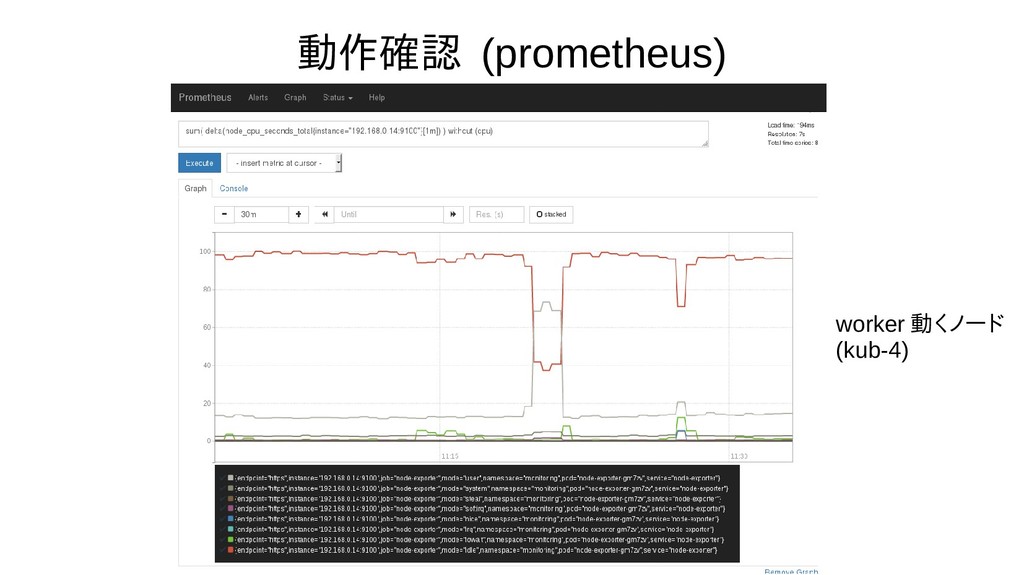{kind=link}
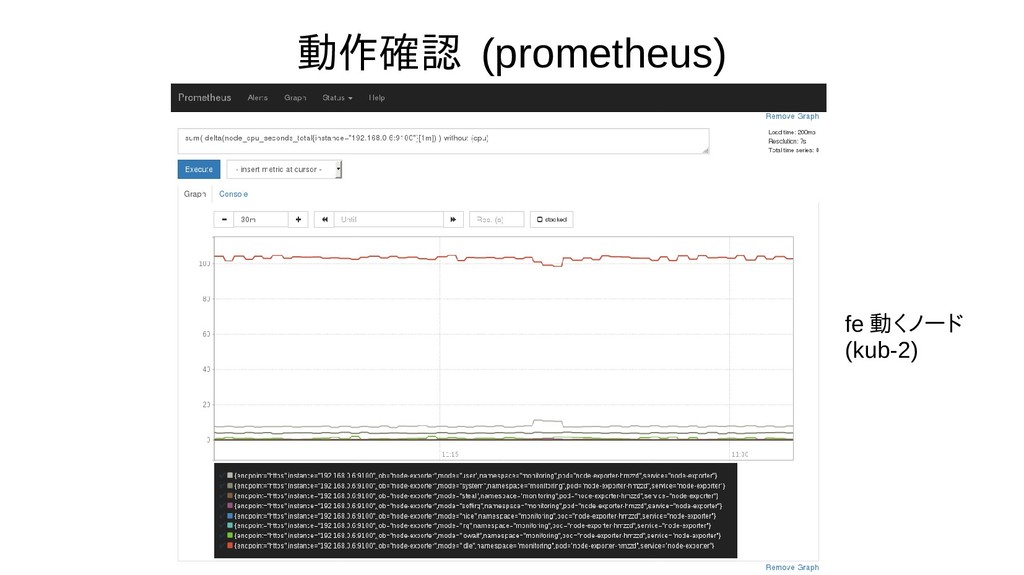{kind=link}
{kind=link}
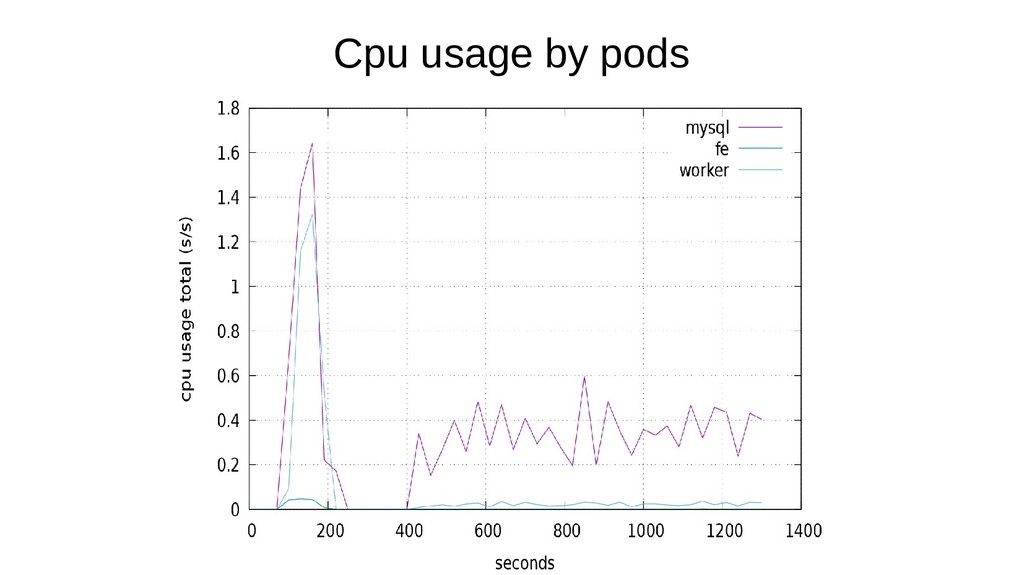{kind=link}
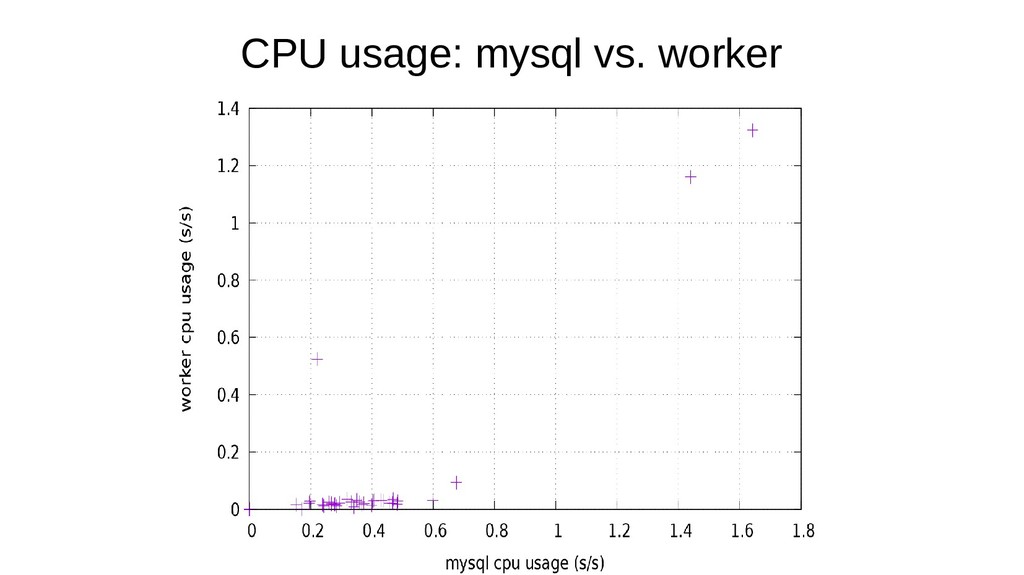{kind=link}
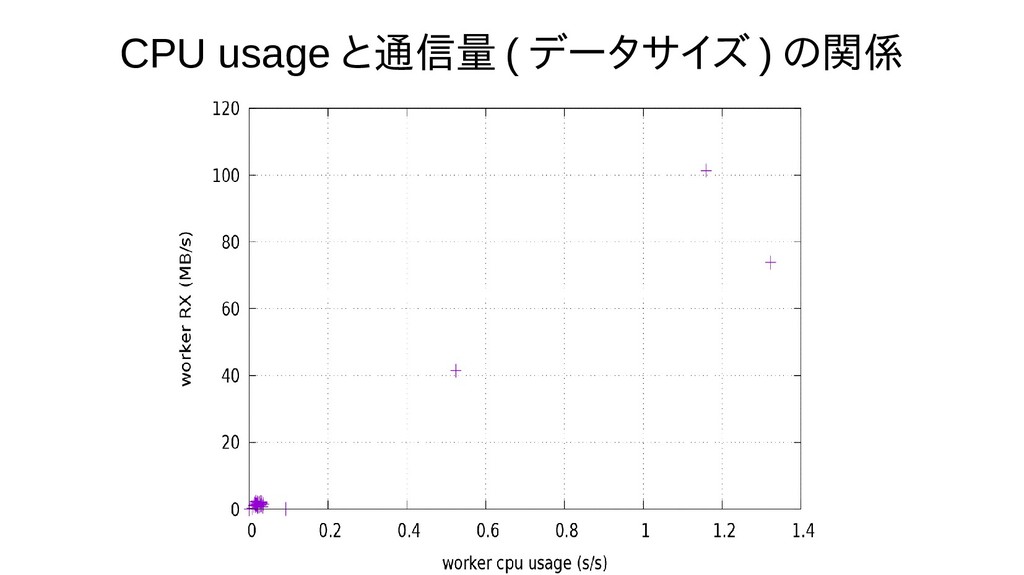{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
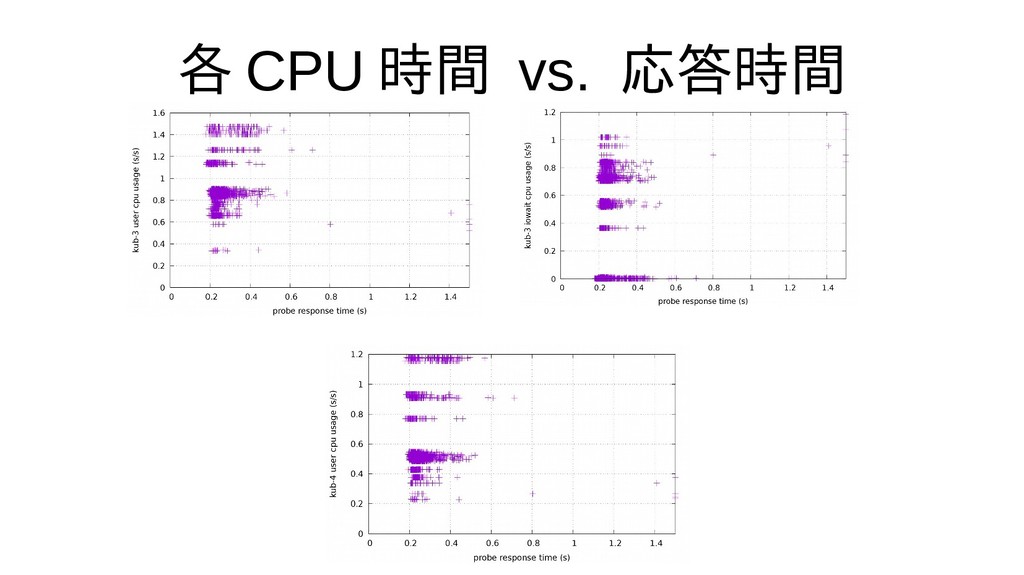{kind=link}
![相関ありません ... >>> i2s=np.loadtxt('30-i2scatter.data') >>> print(np.array2string(np.corrcoef(i2s[...,1:5],rowvar=0),pre cision=4)) [[ 1.0000e+00 7.6919e-03](https://files.speakerdeck.com/presentations/3e6eededc81d42fa985c843cbd802e20/slide_25.jpg){kind=link}
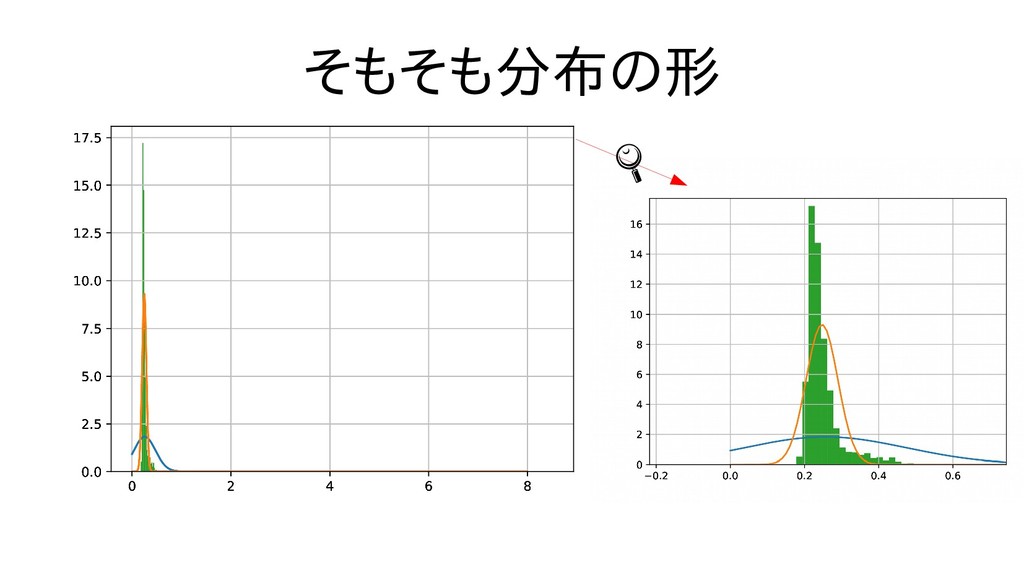{kind=link}
{kind=link}
![>>> print(np.array2string(np.corrcoef(i2s[...,1:5], rowvar=0),precision=4)) [[ 1. 0.1716 0.019 0.1387] [ 0.1716](https://files.speakerdeck.com/presentations/3e6eededc81d42fa985c843cbd802e20/slide_28.jpg){kind=link}
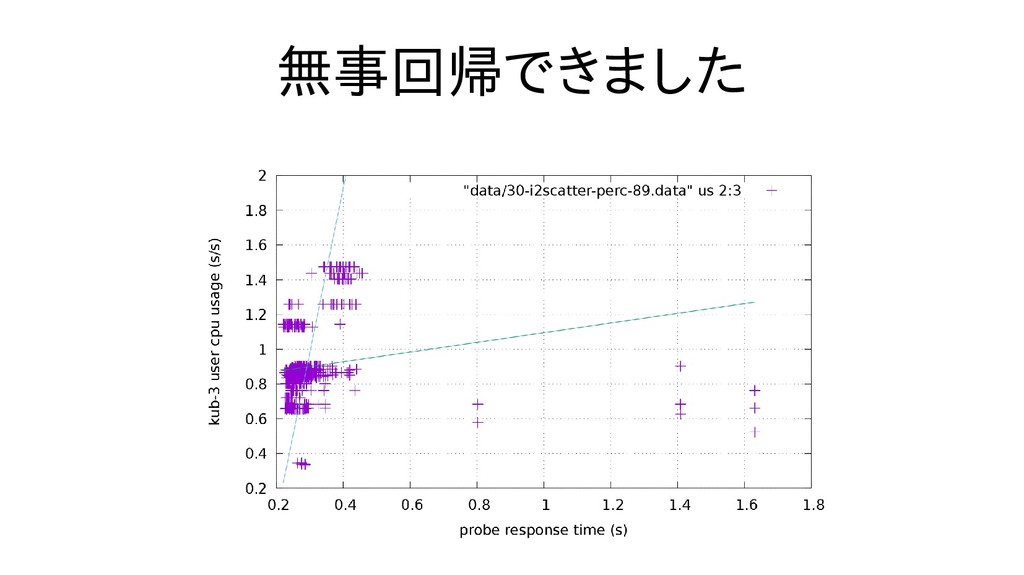{kind=link}
{kind=link}
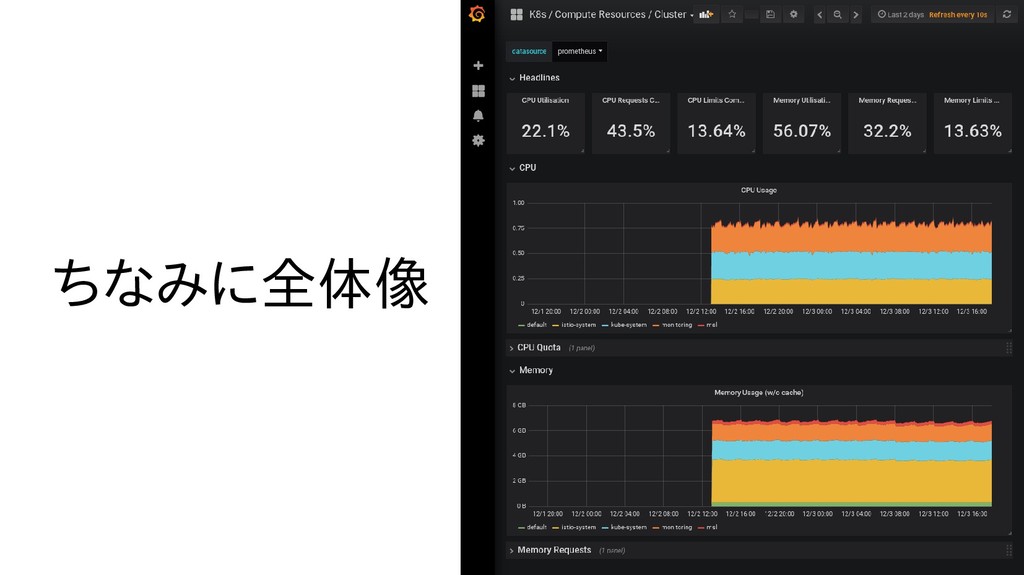{kind=link}
{kind=link}