Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Data_Munging_avec_Spark_-_Partie_II_-_BISBIS.pdf
Search
Toulouse Data Science
April 26, 2016
57
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Data_Munging_avec_Spark_-_Partie_II_-_BISBIS.pdf
Toulouse Data Science
April 26, 2016
More Decks by Toulouse Data Science
See All by Toulouse Data Science
Suivi de la biomasse à large échelle grâce au satellite SMOS - Toulouse Data Science - Emma Bousquet
toulousedatascience
0
68
Des photons aux applications - Toulouse Data Science - Jean-Marc Delvit
toulousedatascience
0
140
#51 - Earth Observation : Ecosystem & Trends - Aravind Ravichandran
toulousedatascience
0
210
#52 [1/2] - Données d'observation de la Terre et données du Web, rencontre entre les 2 univers
toulousedatascience
1
100
#52 [1/2] - Evaluation de dommages aux bâtiments sur images THR par deep learning
toulousedatascience
0
120
Standardizing on a single N-dimensional array API for Python
toulousedatascience
0
200
#45 Computer Vision & Deep Learning applied to GPS signals
toulousedatascience
0
270
#44 Agents conversationnels pour le domaine de l'aéronautique
toulousedatascience
0
230
[Remote] #43 Koalas - Unifions les Data Scientists et les Data Engineers
toulousedatascience
0
360
Featured
See All Featured
A better future with KSS
kneath
240
18k
The Cult of Friendly URLs
andyhume
79
6.9k
Unsuck your backbone
ammeep
672
58k
Embracing the Ebb and Flow
colly
88
5.1k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
350
The untapped power of vector embeddings
frankvandijk
2
1.8k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
570
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Transcript
Data Munging avec Spark Partie II BIS Alexia Audevart Julien
Guillaumin @aaudevart Data NoBlaBla Mardi 26 Avril 2016
Merci à notre sponsor
Merci à notre sponsor
Stagiaire en traitement d'images chez Thales Services. Elève ingénieur à
Télécom Bretagne TOULOUSE DATA SCIENCE Data & Enthusiast chez ekito @aaudevart
Dans l'épisode précédent...
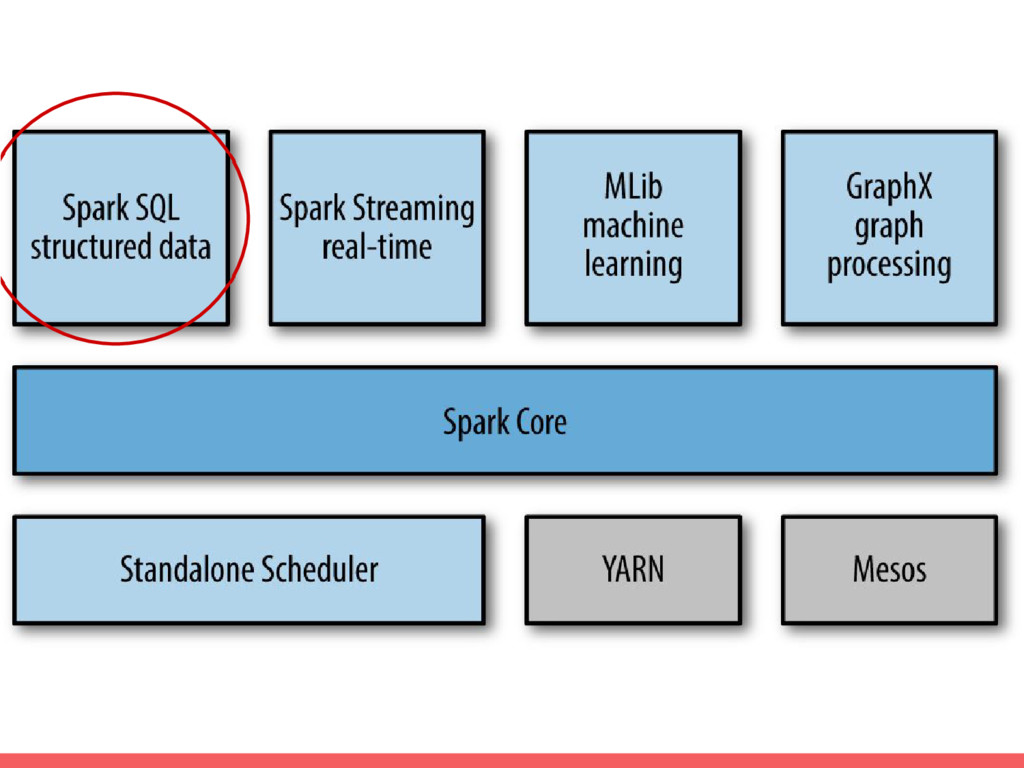
Récap’ • Spark : framework généraliste traitement distribué • Driver,
Executor • API PySpark (Python) • Transformations (Lazy) ◦ map, flatMap, filter, reduceByKey, groupByKey • Actions ◦ count, collect, take, top, takeOrdered, reduce,
None
Représentation de données • RDDs • Data Frame en R
ou Python Pandas • Table (base de données relationnelles)
Problème : Régulation des vélos en libre service
Données • Nombre de location des vélos par heure :
◦ data/bike_sharing/usage_hourly.csv • Données météo (température, vent, humididité) : ◦ data/bike_sharing/weather.csv
None
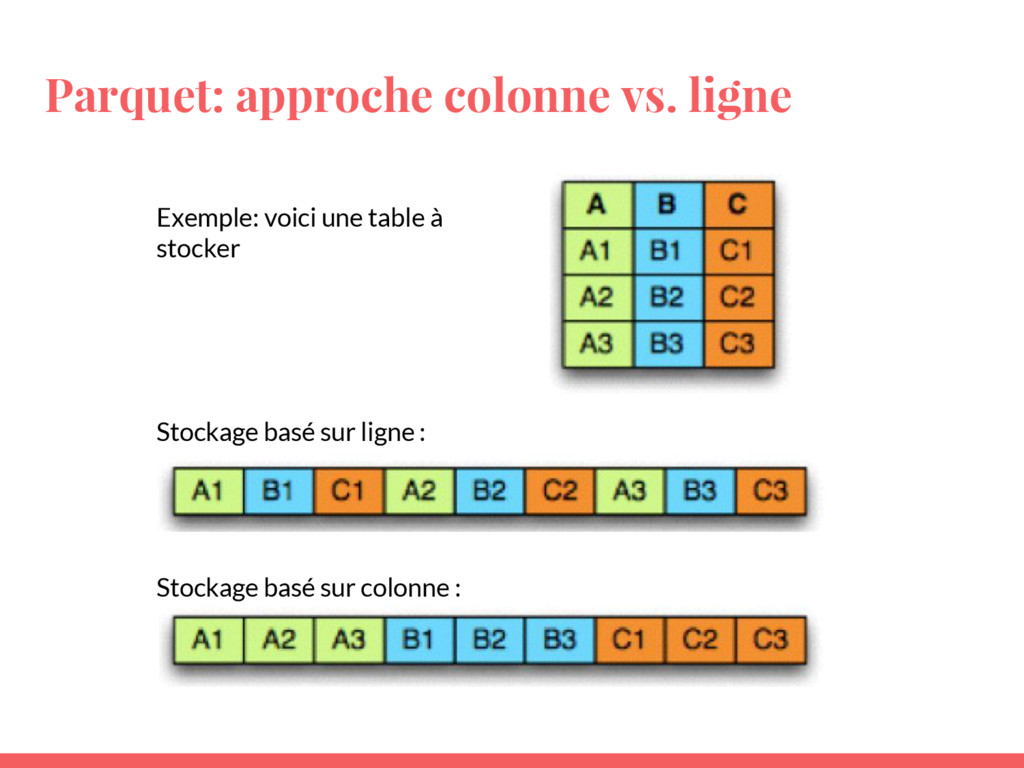
Parquet • Auto- descriptif (schéma, structure, statistiques inclus dans le
fichier) • Format colonnes (optimisation de requêtes) • Compressé (stockage performant, minimise E/S) • Indépendant du langage ou framework d’analyse Source: https://drill.apache.org/docs/parquet-format/
Parquet: approche colonne vs. ligne Exemple: voici une table à
stocker Stockage basé sur ligne : Stockage basé sur colonne :
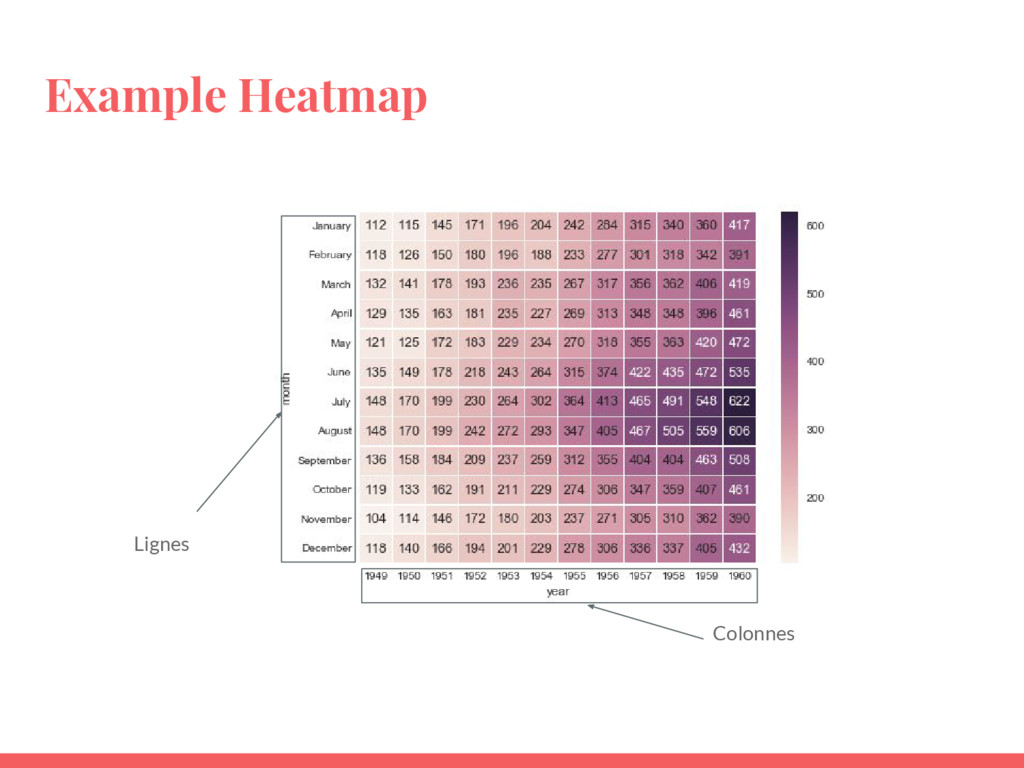
Mission: Créer une heatmap permettant de comprendre l’usage de vélos
par jour de la semaine et heure
Lignes Colonnes Example Heatmap
None
Pour aller plus loin... • Apache Spark: RDD, DataFrame or
Dataset? → http://goo.gl/BFGrwl • Pivoting Data in SparkSQL → http://goo.gl/qtMrgn • From Pandas to Apache Spark’s DataFrame → https://goo.gl/6iyyXd • Comment stocker ses données dans Hadoop ? -> https://goo.gl/Uoxu1V
“If all you have is a hammer, everything looks like
a nail”
A venir • Partie III - Usage avancé et Natural
Language Processing : résoudre un problème de Record Linkage
Merci ! > questions .where (questions.contenu.isNotNull()) .show(5)
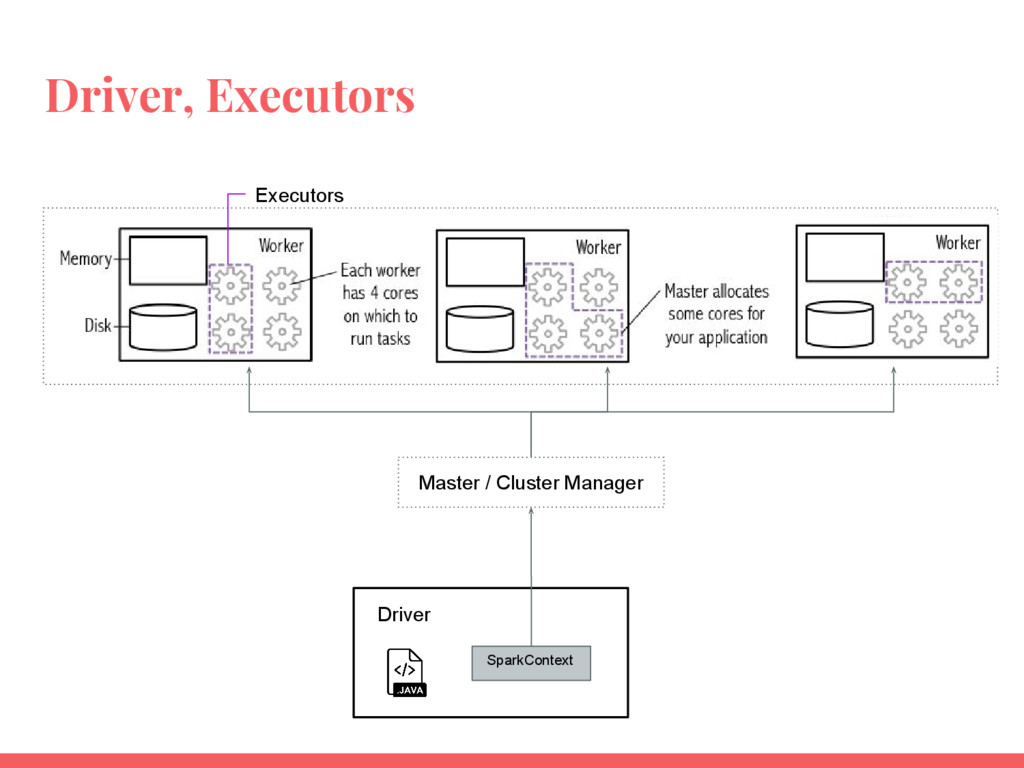
Driver, Executors Driver SparkContext Executors Master / Cluster Manager
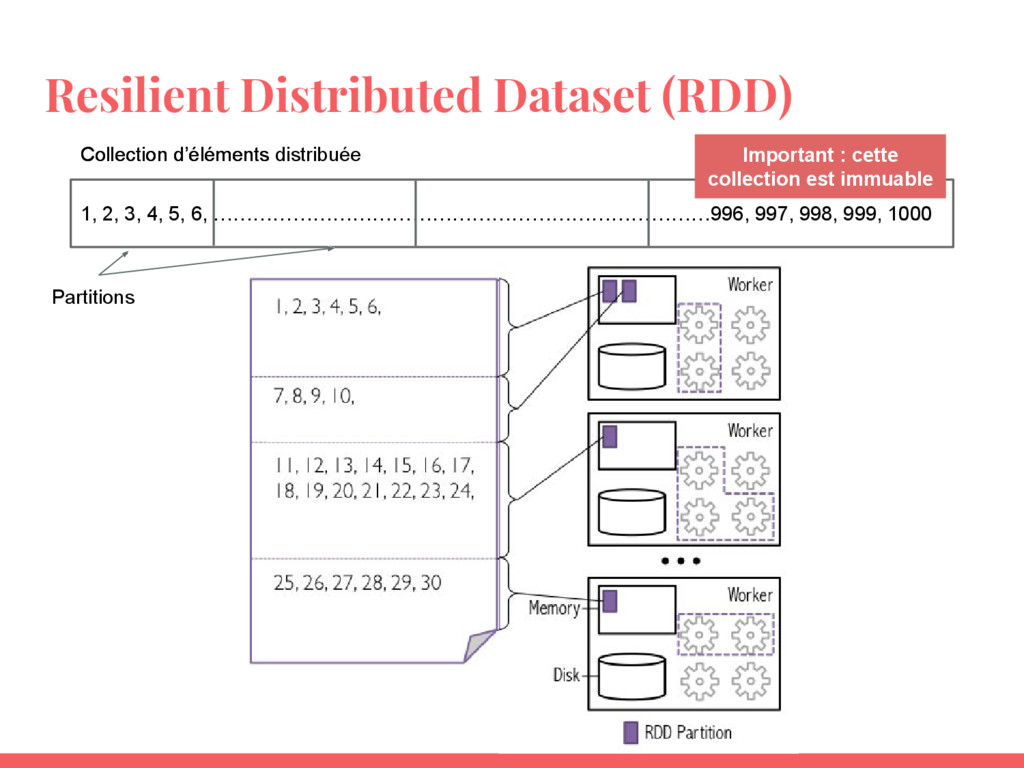
Resilient Distributed Dataset (RDD) 1, 2, 3, 4, 5, 6,
…………………………………………………………………996, 997, 998, 999, 1000 Partitions Collection d’éléments Collection d’éléments distribuée Important : cette collection est immuable
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}