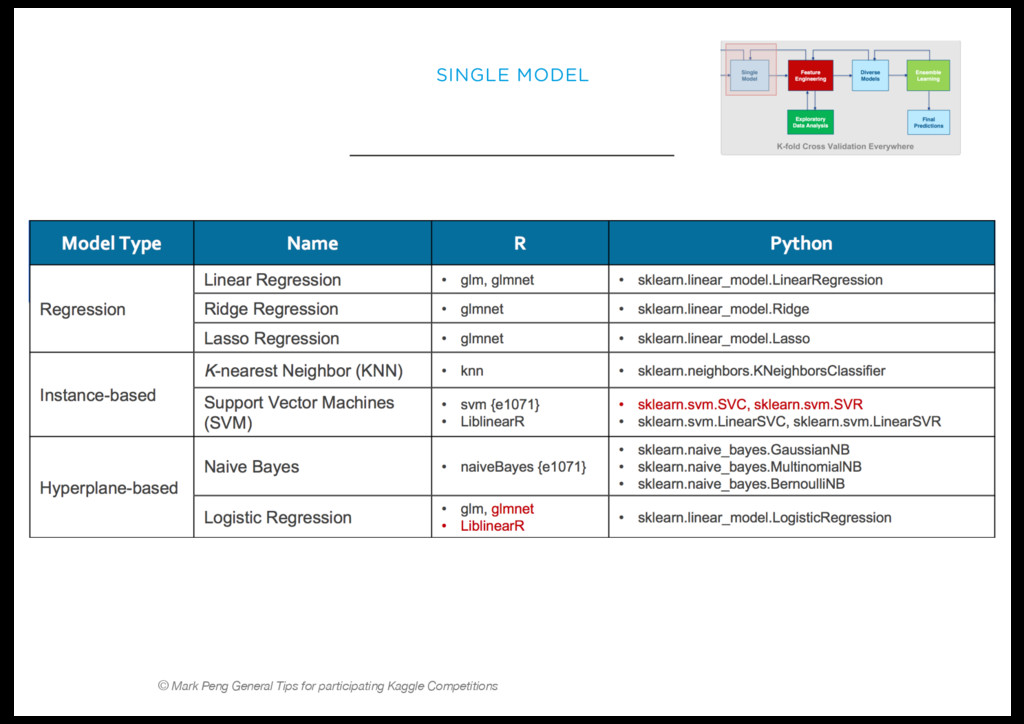
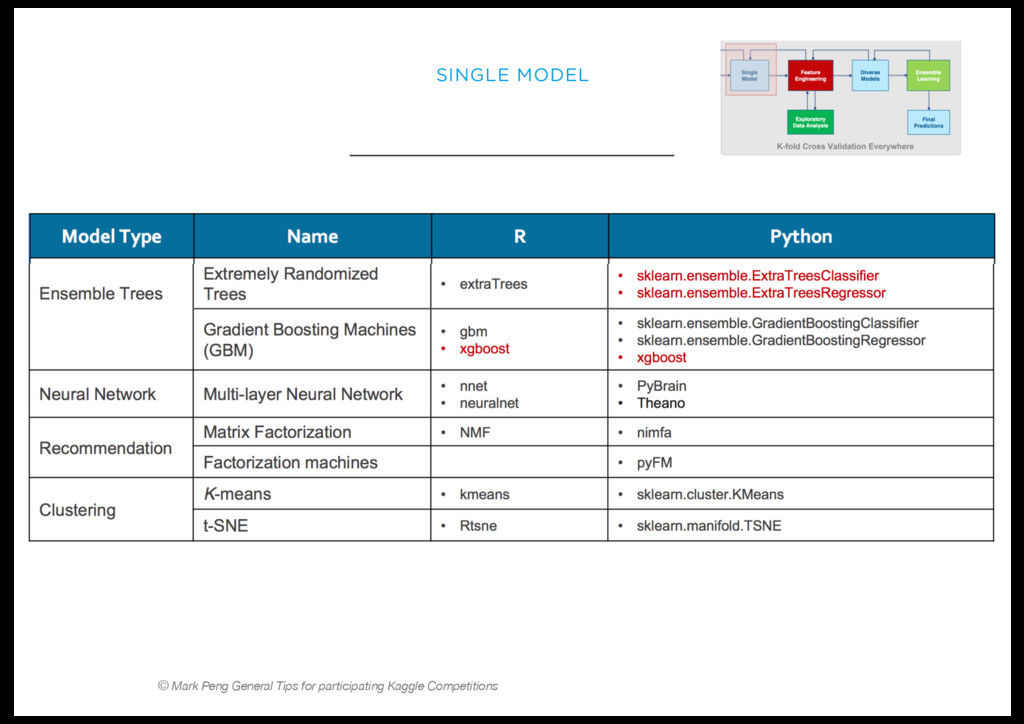
Le cleaning, filtering, feature engineering, création de modèle, stacking, blending, validation, cross-validation, etc… sont les différentes étapes d’une bonne recette de machine learning.
Curieux de découvrir ce qui se cache derrière la théorie? Une bonne dose d'expérience, et une pincée de vaudou.
Alexia Audevart et Reynald Rivière s’appuieront sur le concours de data science: “Le Meilleur Data Scientist de France” pour introduire ces concepts.
La première édition de ce challenge éclair, organisé par FrenchData, a réuni au cours d’une soirée 250 passionnés de data.
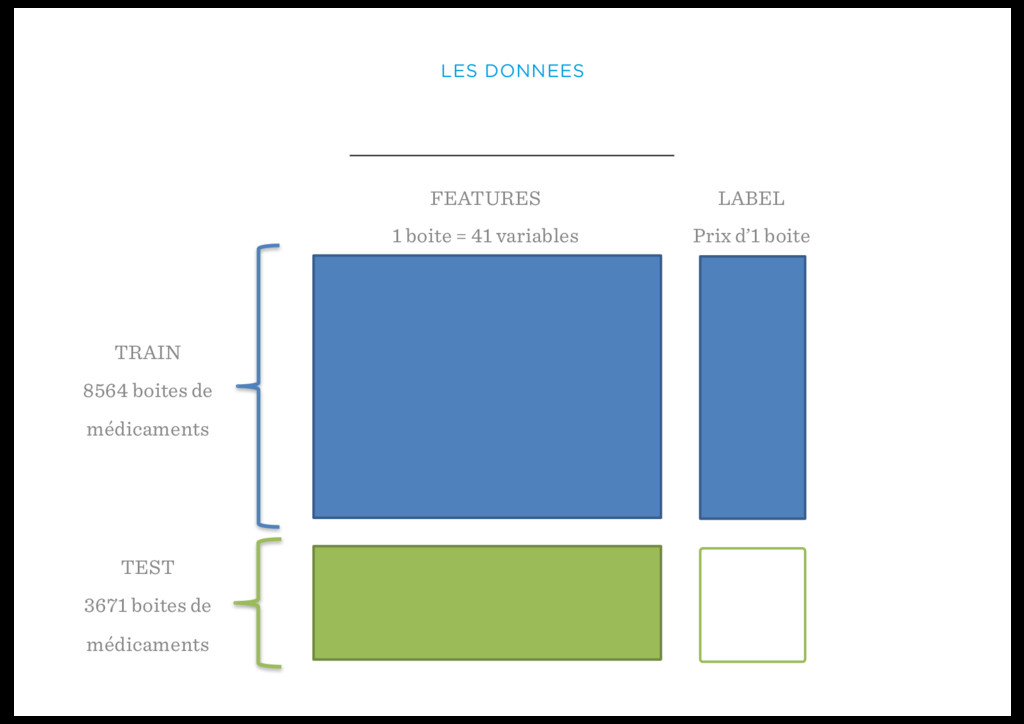
Ce challenge est désormais ouvert à tous. Le thème étant : combien coute une boite de médicament ?
L’objectif de ce challenge est de mettre au point un modèle prédictif pour estimer combien coûte une boite de médicament, afin par exemple d’aider à en fixer le prix, ou de détecter des anomalies dans les tarifs.
------------------------------------------------------------------
Bio :
• Alexia Audevart est “Data & Enthusiasm” chez ekito et présidente du Toulouse Data Science. #Kaggler et #MOOC_friendly
• Reynald Rivière est “Data Scientist” chez Continental Digital Services. #Kaggler_expert
Lien vers le code source : https://github.com/aaudevart/MDF-TDS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}