Le data management est la discipline qui assure la qualité des ressources numériques. Par exemple, le contexte des données peut être apporté par l’ajout de métadonnées issues de Master Data ou dictionnaires contrôlés (en science de la vie: code patient, code maladie, en logistique le code produit, ...).
La sémantique et les ontologies sont le graal de la gestion des connaissances. Cependant leur flexibilité extrême les rendent complexes à intégrer dans des applications informatiques.
Au cours de cette présentation, nous allons voir comment tenter de réconcilier ces deux mondes. Nous avons tous à y gagner pour mieux qualifier nos données et les relier entre elles.
Erwan David : CTO chez DEXSTR
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
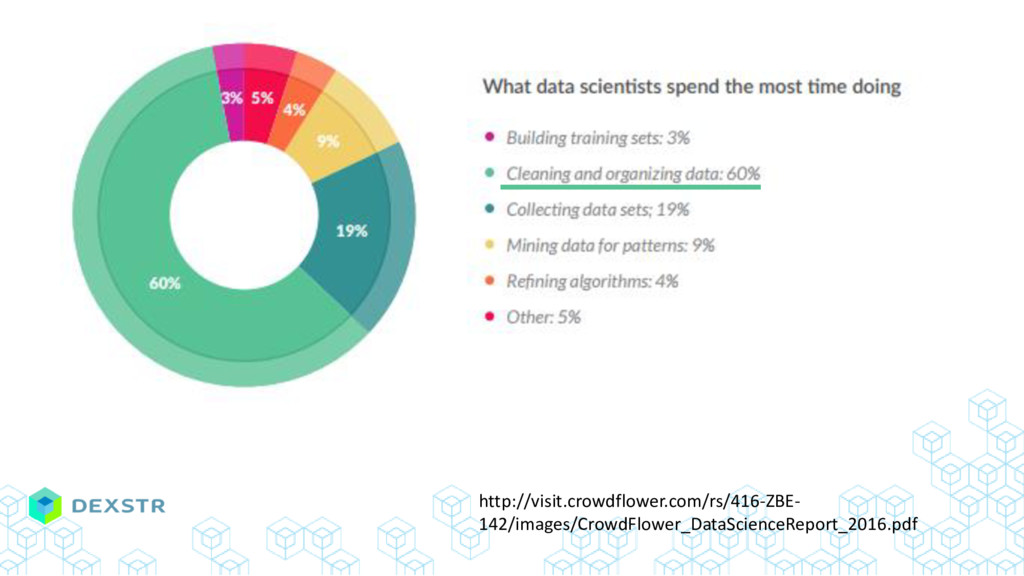{kind=link}
{kind=link}
{kind=link}
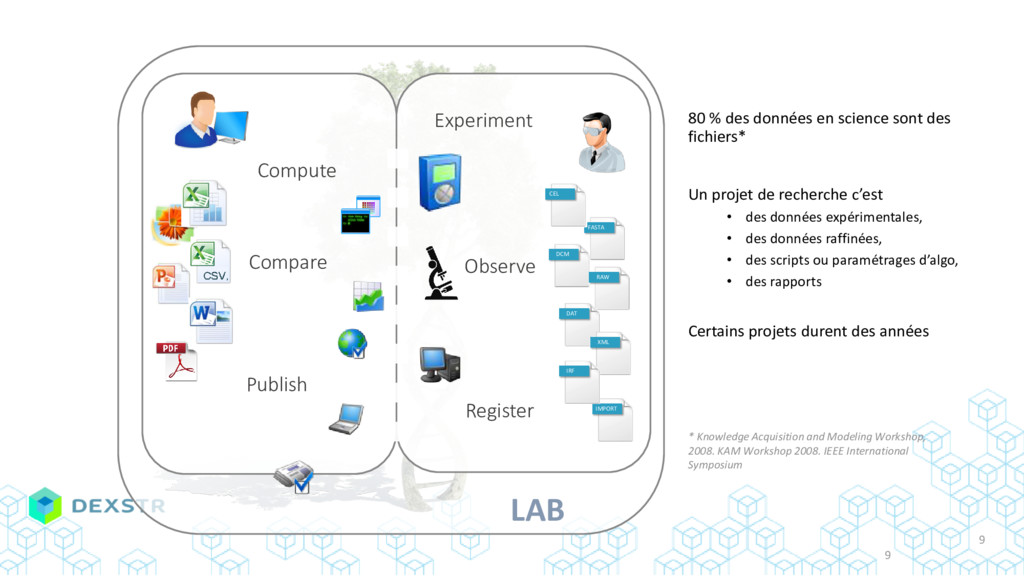{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
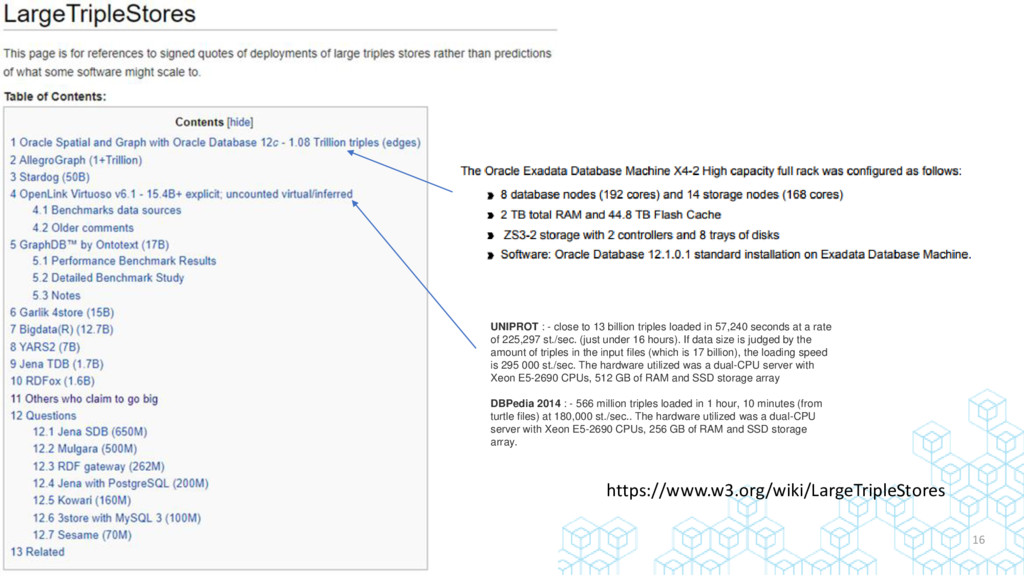{kind=link}
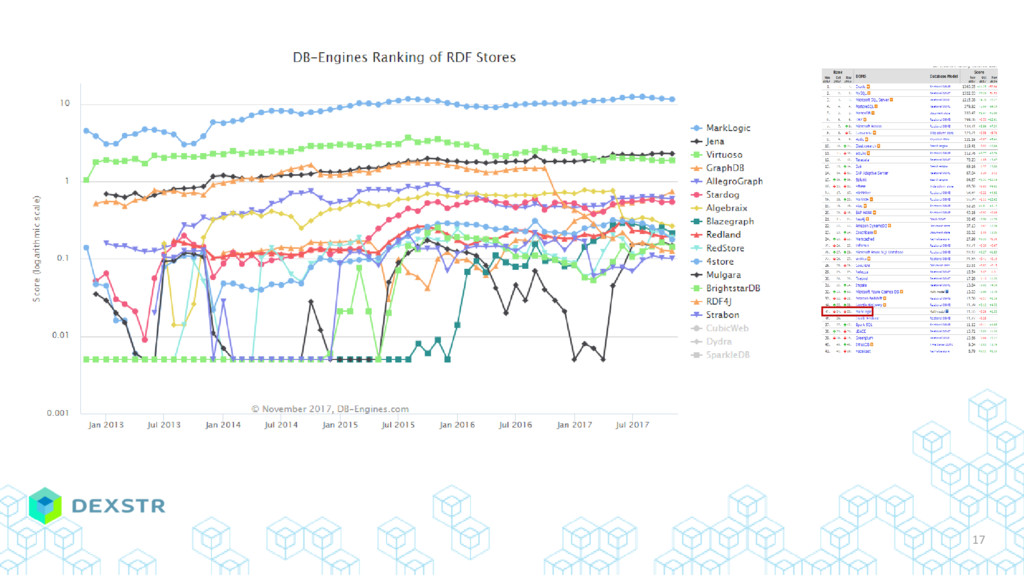{kind=link}
{kind=link}
{kind=link}
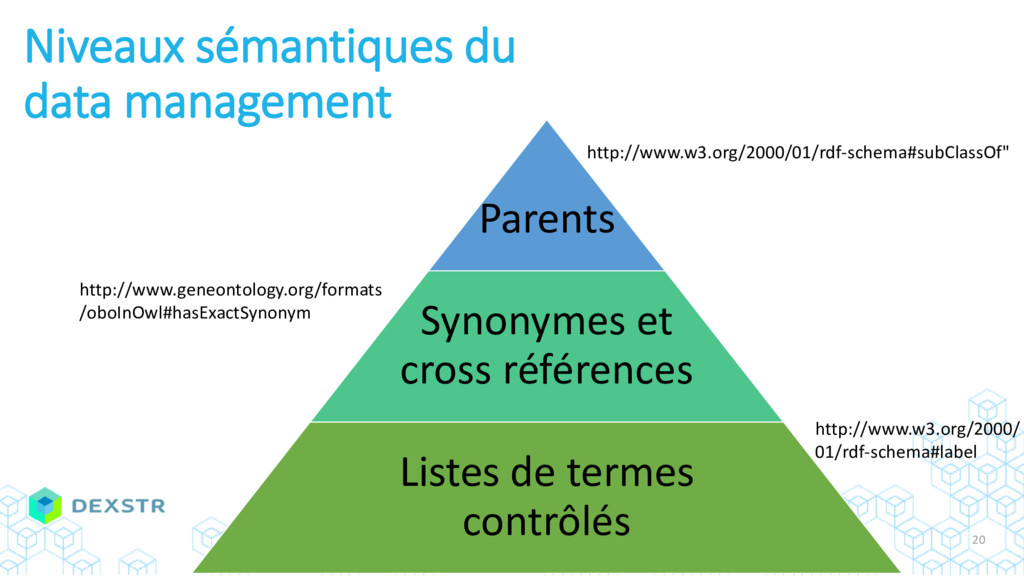{kind=link}
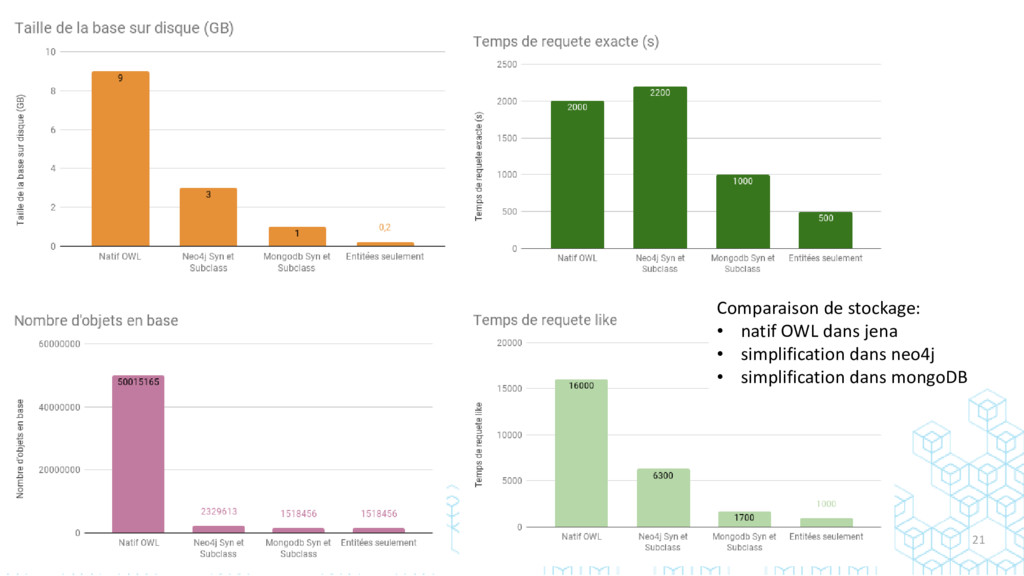{kind=link}
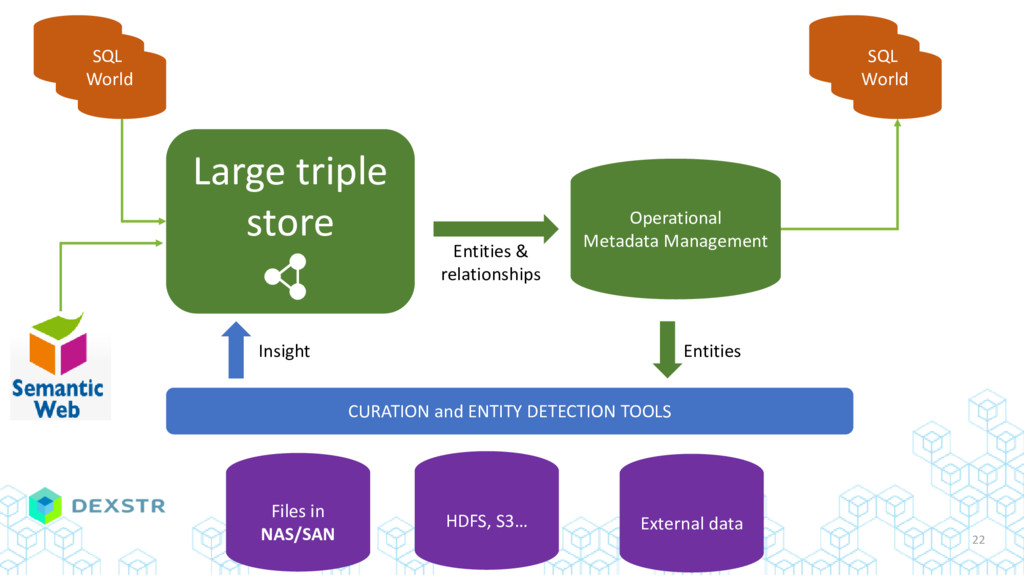{kind=link}
{kind=link}
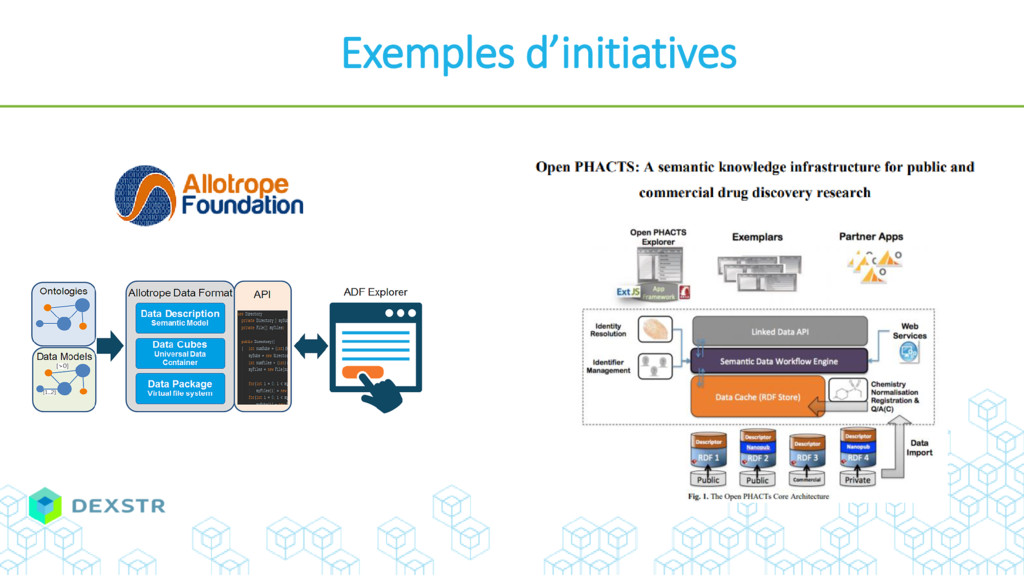{kind=link}
{kind=link}
{kind=link}
{kind=link}
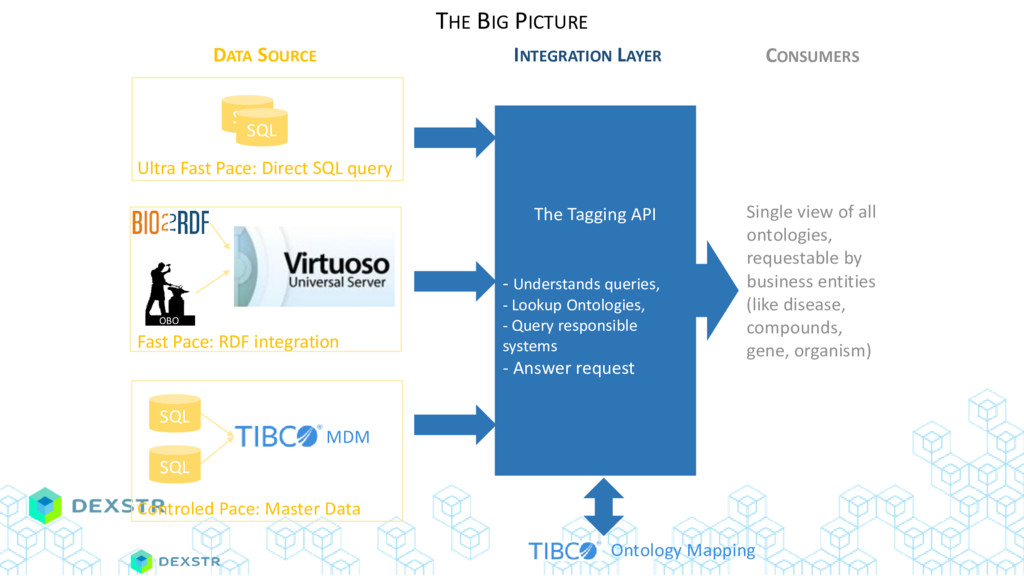{kind=link}