column name for a number of keys • get_slice(): by column name or a range of names - returning columns - returning supercolumns • multiget_slice(): a subset of columns for a set of keys • get_count(): number of columns or subcolumns • get_range_slice(): subset of columns for a range of keys
state_key ON users (state); SELECT * FROM users ... WHERE gender='f' AND ... state='TX' AND ... birth_year='1968'; u'user1' | u'birth_year',1968 | u'gender',u'f' | u'password',u'ch@ngem3' | u'state',u'TX' DROP COLUMNFAMILY users;
Get the friends of a username • Get the followers of a username • Get a timeline for a user • Get a timeline of a specific user’s tweets • Get a tweet from a tweet ID • Create a tweet • Create a user • Add friends to a user • Remove friends from a user
![Apache Cassandra Vova Miguro [email protected] THE END](https://files.speakerdeck.com/presentations/5ab6a46022790130a3fe12313d2ff693/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
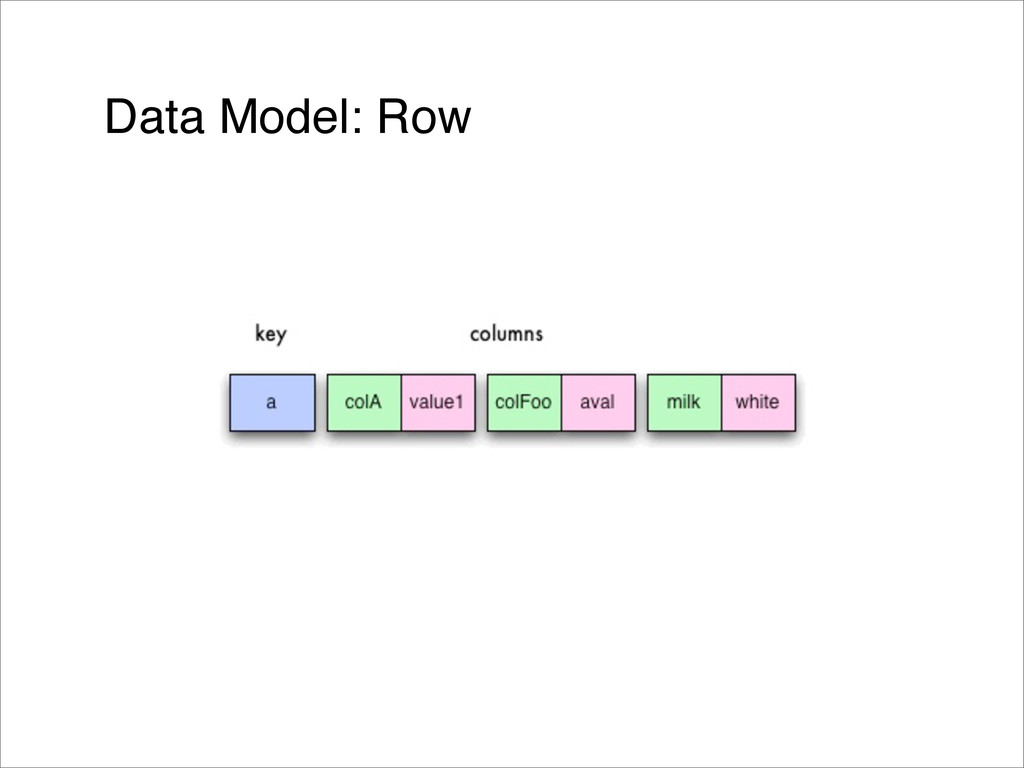{kind=link}
{kind=link}
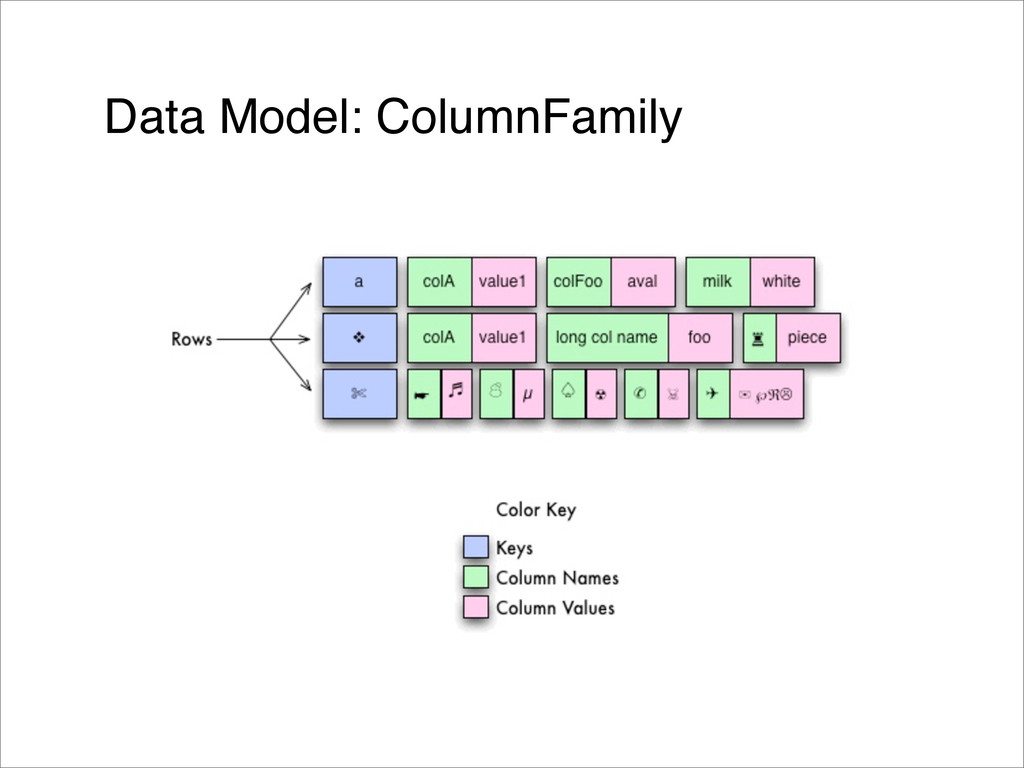{kind=link}
![Writing • simple: put(key,col,value) • complex: put(key,[col,value,...col,value]) • batch: multi](https://files.speakerdeck.com/presentations/5ab6a46022790130a3fe12313d2ff693/slide_21.jpg){kind=link}
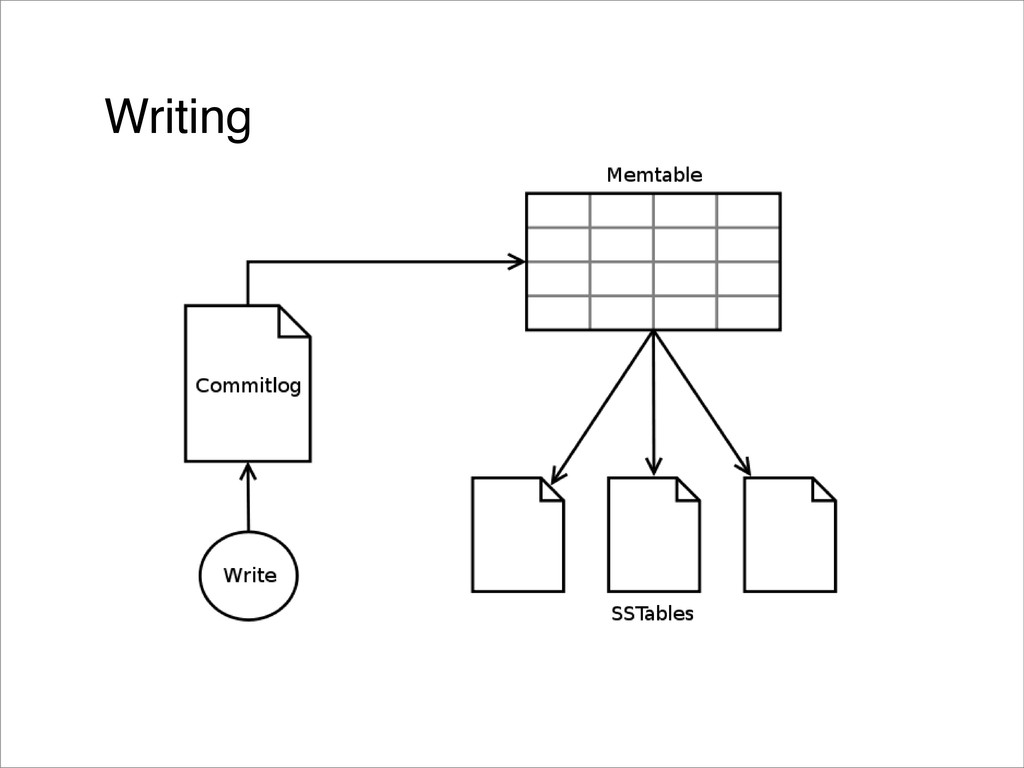{kind=link}
{kind=link}
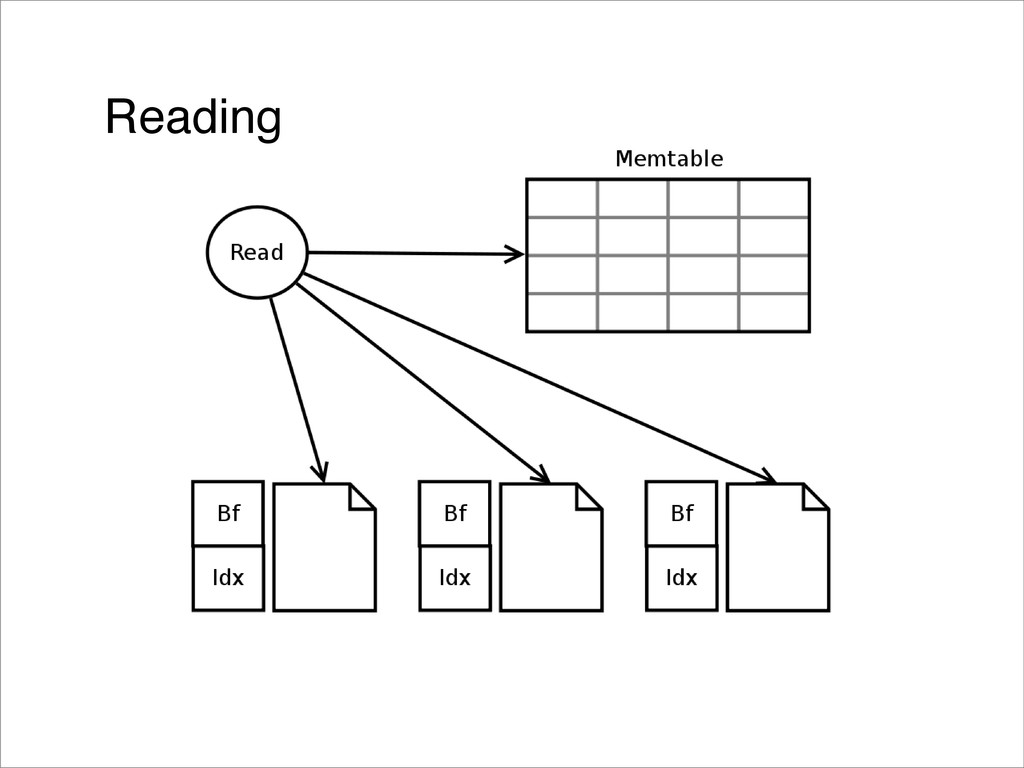{kind=link}
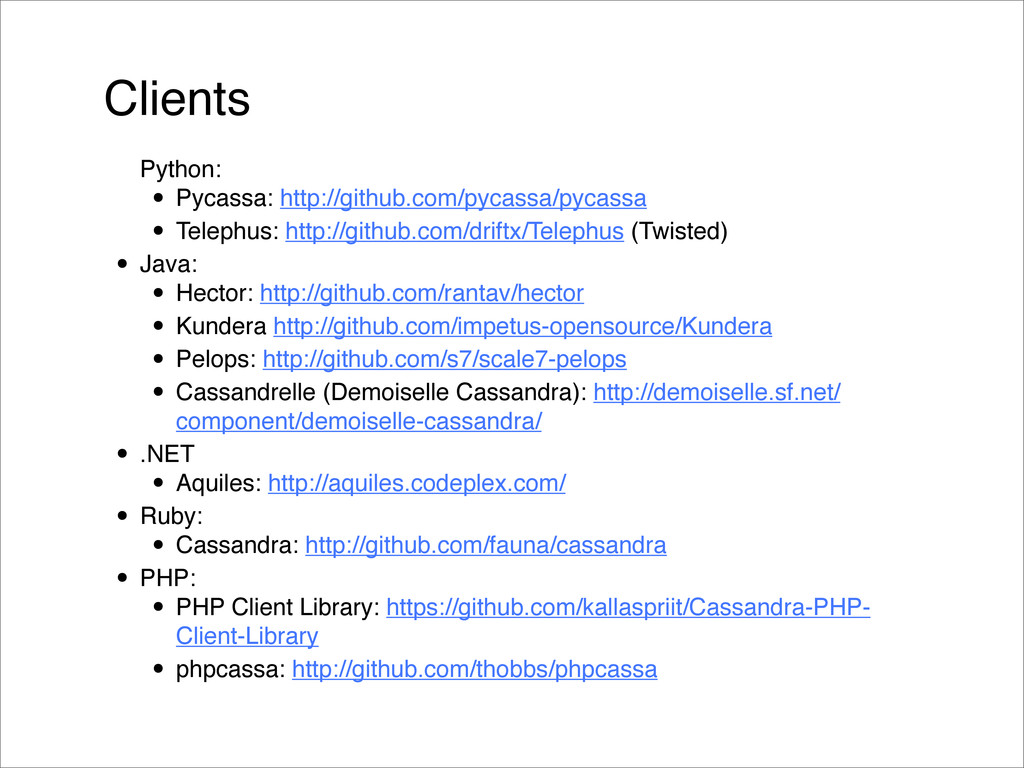{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
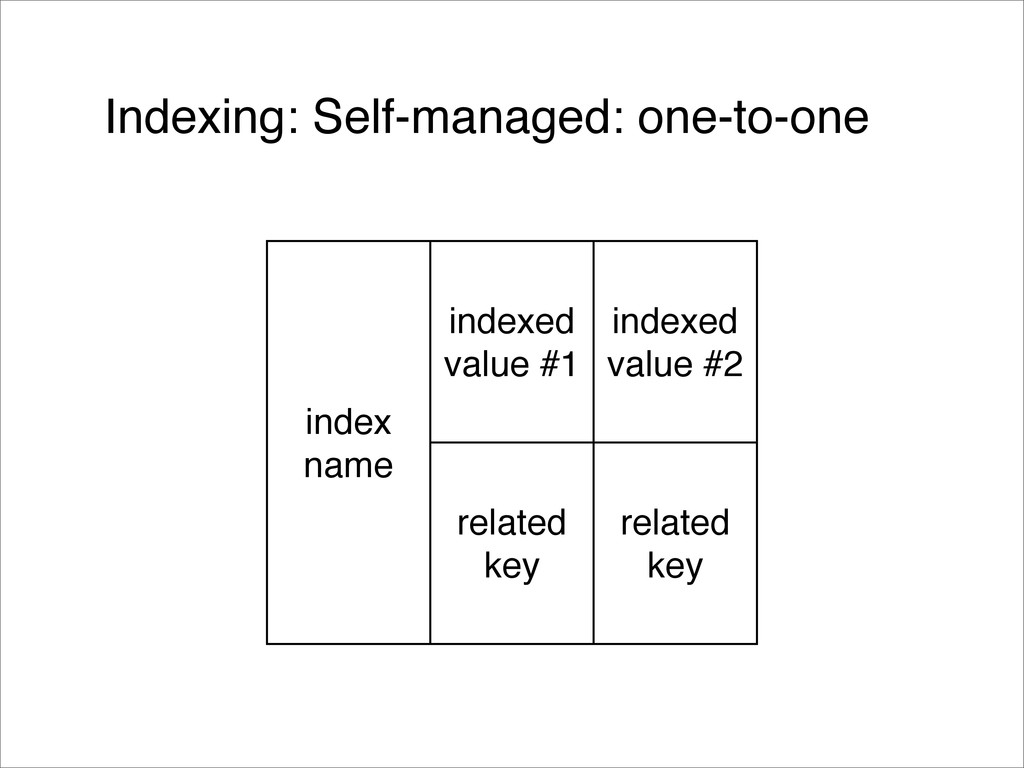{kind=link}
{kind=link}
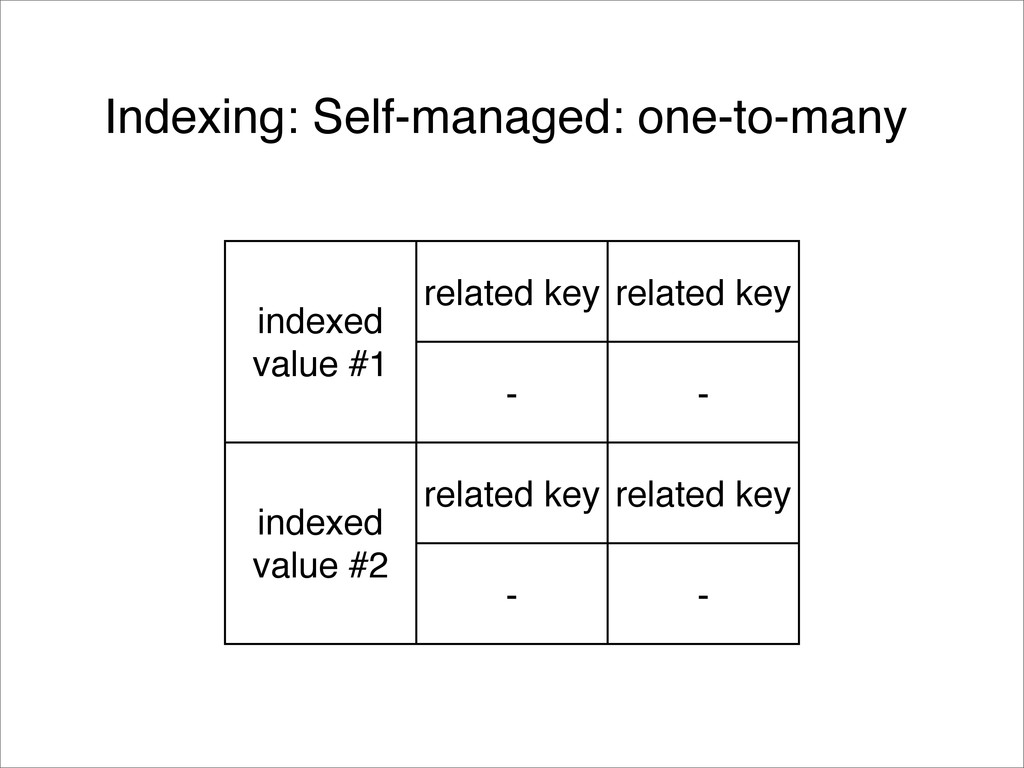{kind=link}
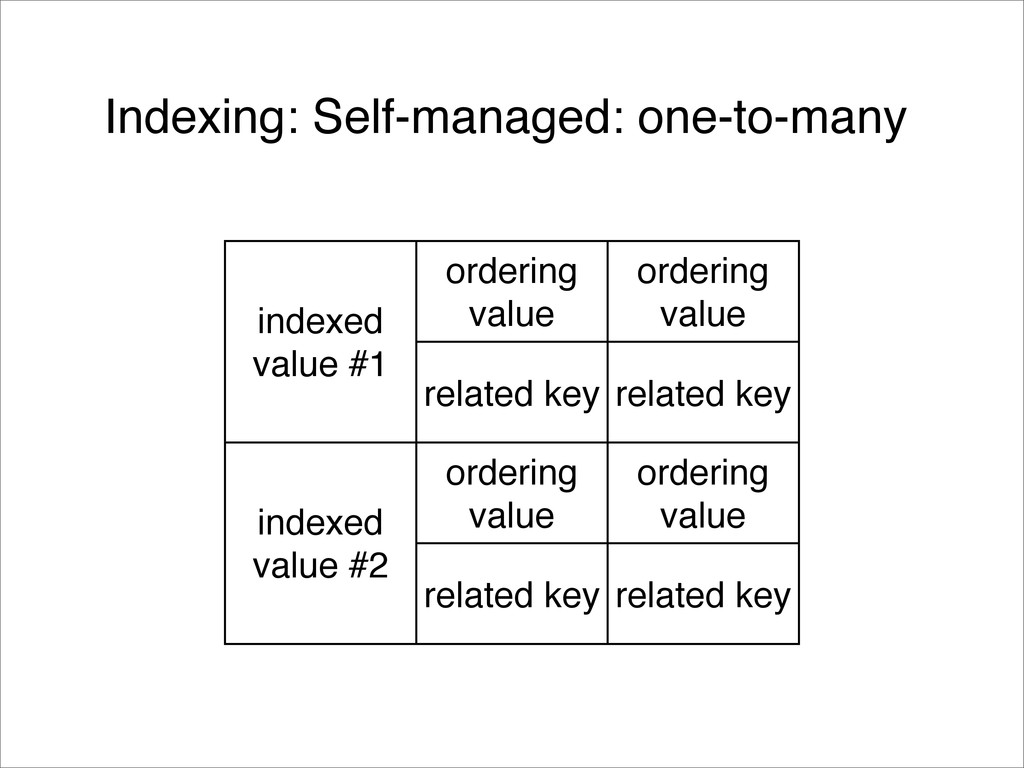{kind=link}
{kind=link}
{kind=link}
{kind=link}