[論文サーベイ] Survey on Google DeepMind’s Game AI 2
PDFファイルをダウンロードすると,スライド内のリンクを見ることができます.
1.Training Agents Inside of Scalable World Models,
Danijar Hafner et al. (Google DeepMind et al.)
[arXiv'2509] (Cited by: 11 )
2.SIMA 2: A Generalist Embodied Agent for Virtual Worlds,
Adrian Bolton et al. (Google DeepMind et al.)
[arXiv'2512] (Cited by: - )
{kind=link}
![2/21 Prior Research SIMA [arXiv’2404] SIMA2 [arXiv’2512] Dreamer [ICLR’20] DreamerV2](https://files.speakerdeck.com/presentations/c7c14d2d259f4ac8939e169367c2ba89/slide_1.jpg){kind=link}
![3/21 Prior Research SIMA [arXiv’2404] 言語指示で多様な3Dゲームを プレイする汎用エージェント SIMA2 [arXiv’2512] 対話を通じた柔軟なタスク遂行と,未知](https://files.speakerdeck.com/presentations/c7c14d2d259f4ac8939e169367c2ba89/slide_2.jpg){kind=link}
{kind=link}
![- 初めてオフラインデータのみで「ダイヤモンド取得」を達成 - DreamerV4により,環境との相互作用を一切行わずに難関タスクを解決 - 従来のVPT [NeurIPS’22]と比較して1/100のデータ量で上回る性能を実証 - ショートカット・フォーシングによる「正確な物理再現」 -](https://files.speakerdeck.com/presentations/c7c14d2d259f4ac8939e169367c2ba89/slide_4.jpg){kind=link}
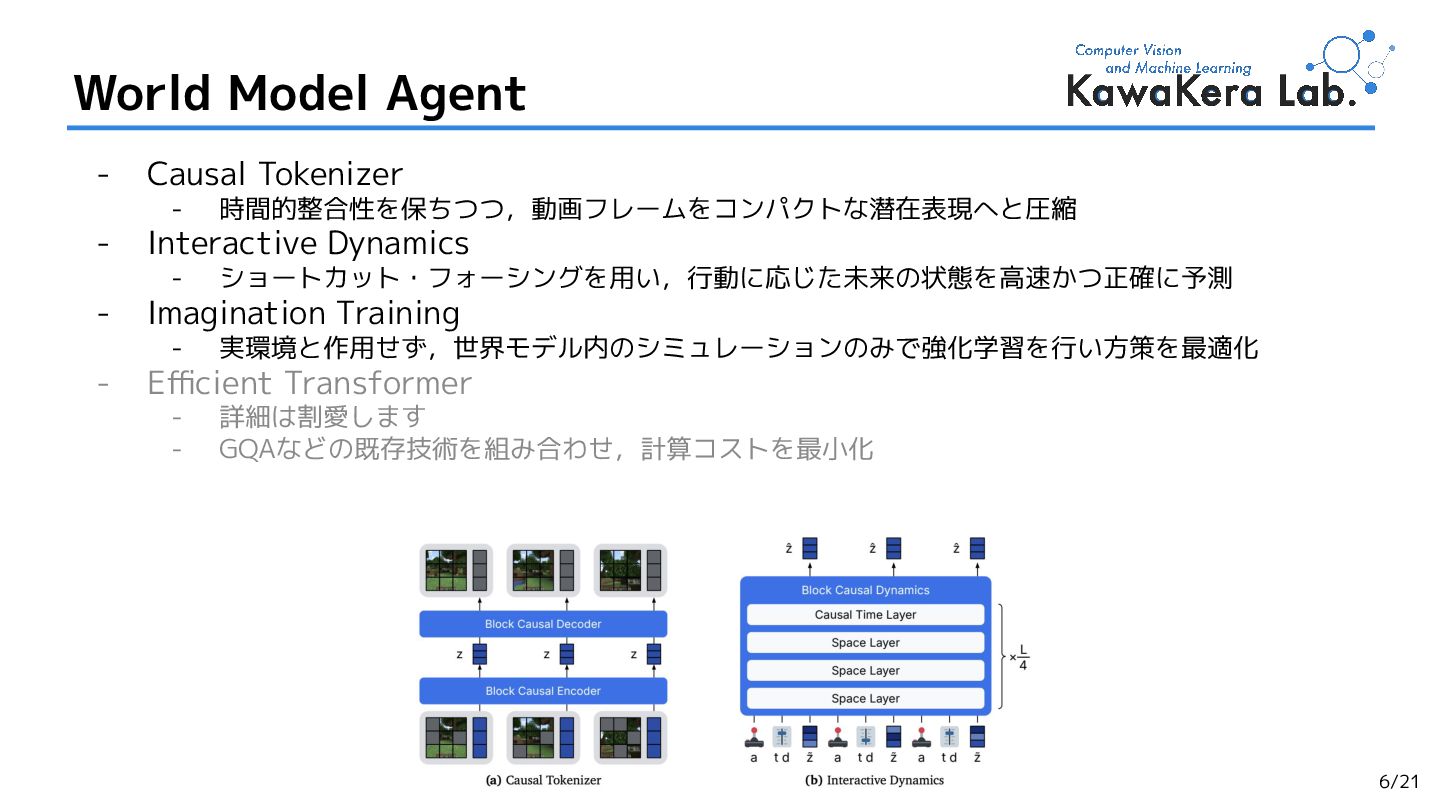{kind=link}
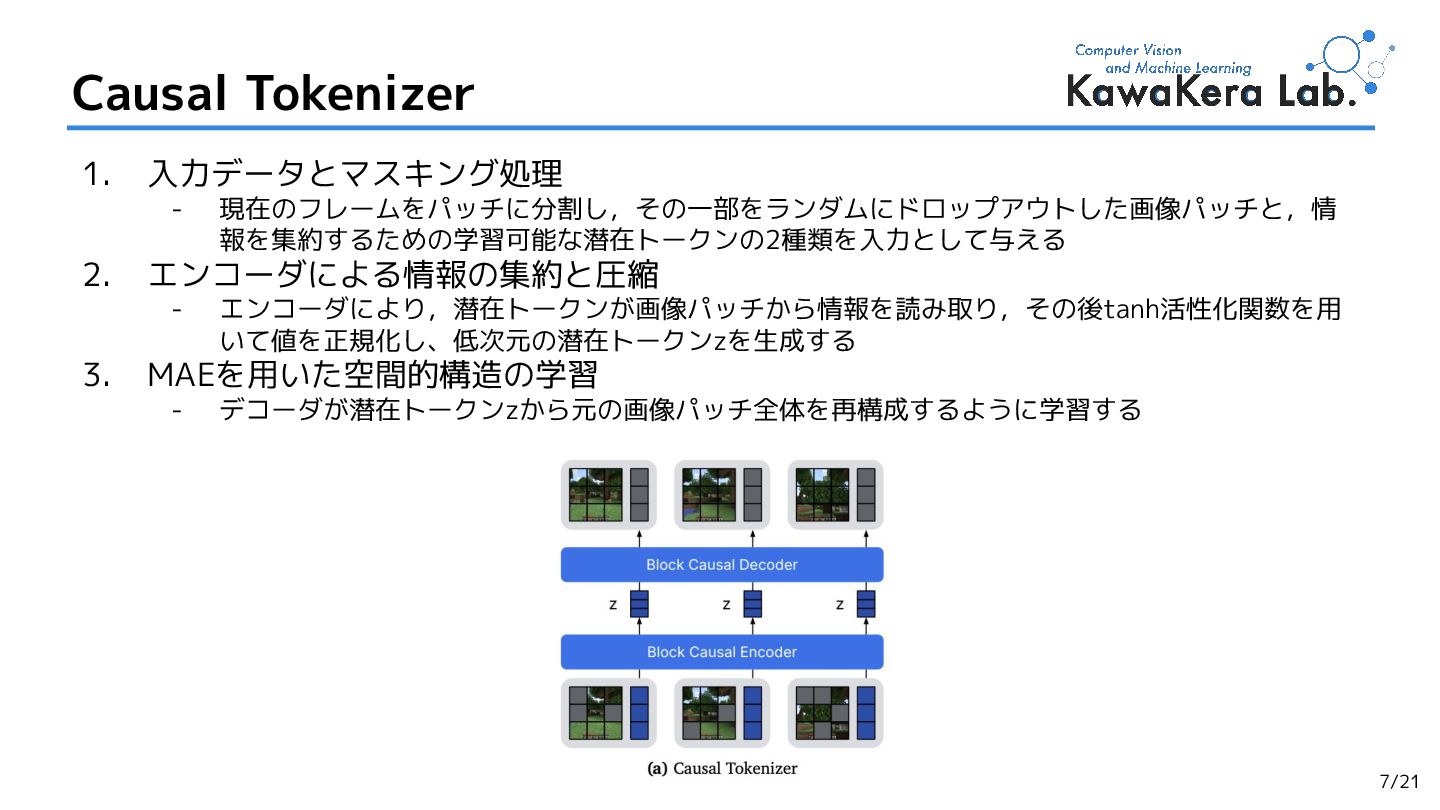{kind=link}
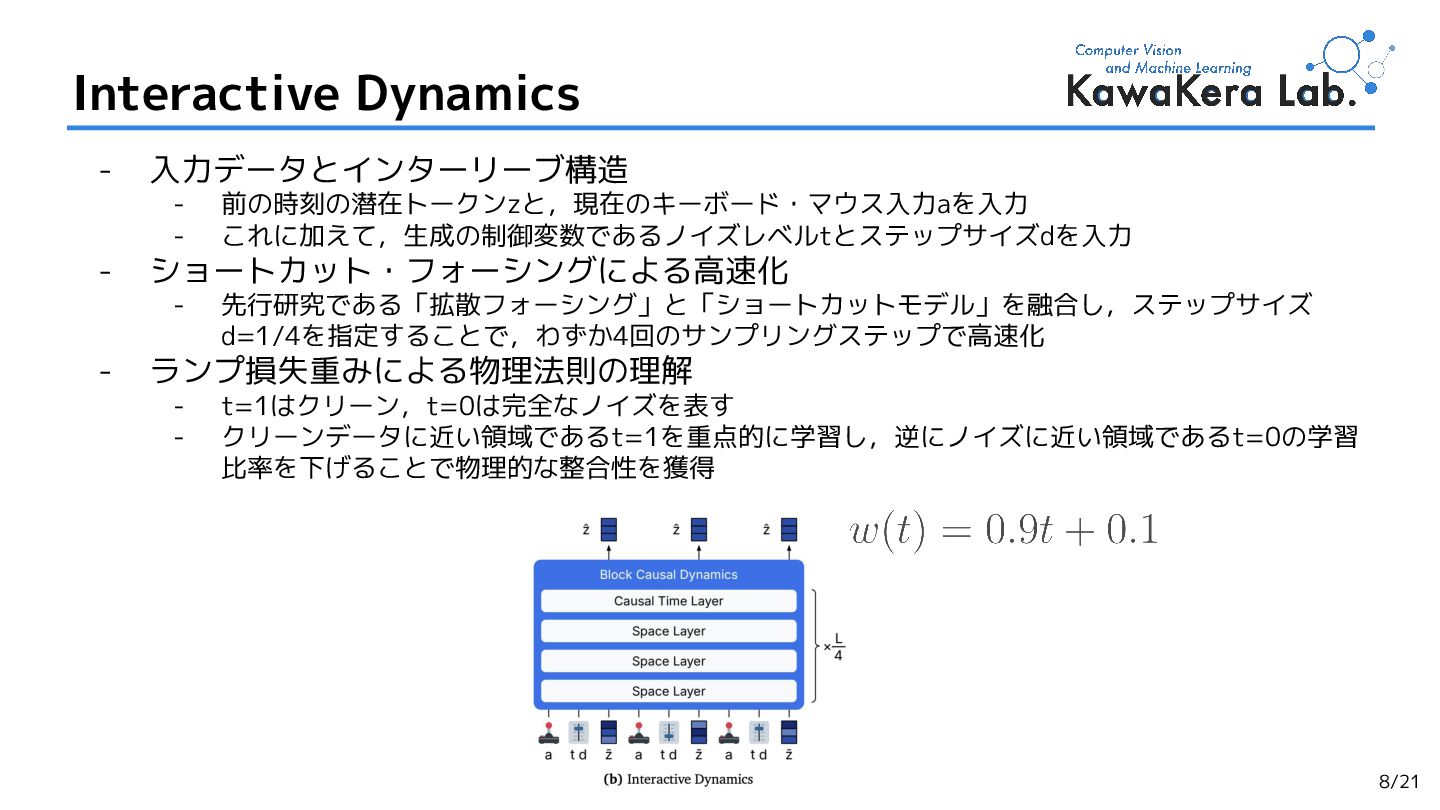{kind=link}
{kind=link}
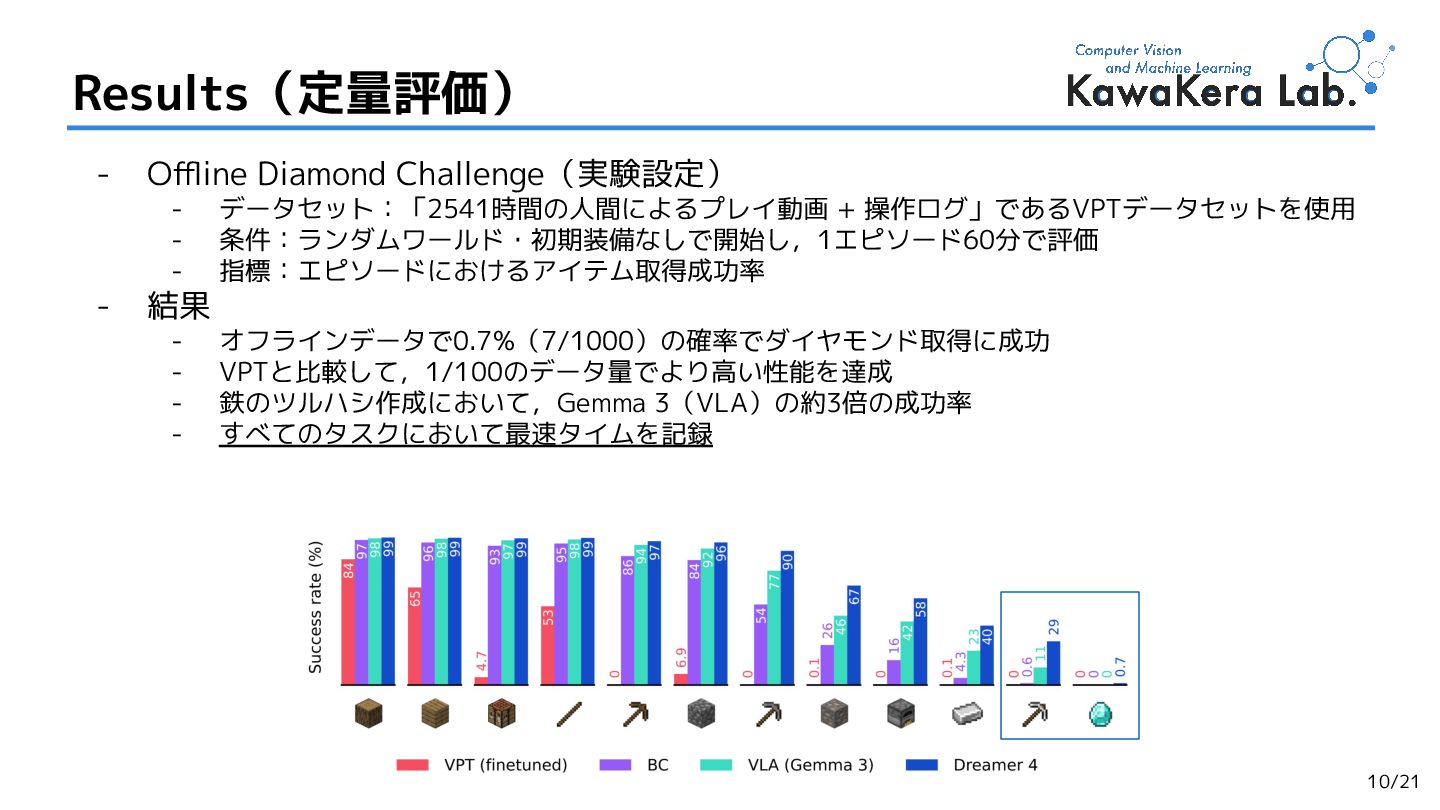{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}