Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[GTC Japan AI Day 2023] NVIDIA Triton Inference...
Search
tuxedocat
May 01, 2023
Programming
310
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[GTC Japan AI Day 2023] NVIDIA Triton Inference Serverでつくる広告クリエイティブ制作のための深層学習推論基盤
GTC 2023 Japan AI Dayで発表した内容です。
Triton Inference Serverを広告制作AIの実プロダクトで活用する事例です。
tuxedocat
May 01, 2023
Other Decks in Programming
See All in Programming
Claude Team Plan導入・ガイド
tk3fftk
0
240
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.8k
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
880
AI Engineeringは、AIプロダクトだけのものか? 〜AIがソフトウェアを作る時代の新しい当たり前〜 / No AI in your product. AI Engineering in your development.
rkaga
2
120
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
190
複数の Claude Code が"放置"されてしまう問題をCLI ダッシュボードを自作して解決した話
sumihiro3
0
320
jsmini JavaScript Engine を作ってみた話
yosuke_furukawa
PRO
0
250
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.6k
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
230
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
PostgreSQL 18で考えるUUID主キー
kazuhiro1982
0
420
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
150
Featured
See All Featured
Done Done
chrislema
186
16k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Discover your Explorer Soul
emna__ayadi
2
1.2k
First, design no harm
axbom
PRO
2
1.2k
Statistics for Hackers
jakevdp
799
230k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
A better future with KSS
kneath
240
18k
Leo the Paperboy
mayatellez
8
1.9k
Docker and Python
trallard
47
4k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Transcript
©2023 CyberAgent Inc. NVIDIA Triton Inference Server でつくる 広告クリエイティブ制作のための 深層学習推論基盤
株式会社サイバーエージェント AI事業本部 AIクリエイティブDiv. 極LP事業部 DS/MLE 澤井 悠
[email protected]
at GTC 2023 Japan AI Day
©2023 CyberAgent Inc. 本発表で扱うトピック 広告クリエイティブ制作のための深層学習推論基盤とその技術選定について • 広告クリエイティブ制作における深層学習推論基盤 • なぜNVIDIA Triton
Inference Serverか、その理由と特徴の紹介 • MLOpsや開発者体験の視点からの振り返り 以下のトピックは他の資料等をご参照ください: - 登場する深層学習モデルの詳細 - MLOpsの概要 - Kubernetesの概要 2 CyberAgent Dev Blogの 記事が元ネタとなっています
©2023 CyberAgent Inc. スピーカー紹介 名前: 澤井 悠 所属: AI事業本部 AIクリエイティブDiv.
極予測LP 役割: DS/MLE(最近はエンジニアリング注力中) 興味: 自然言語処理, ML向けソフトウェアエンジニアリング, MLOps 3 所属プロダクト 社内での趣味活動 ゲーム好きとして プライベートでも使っています
©2023 CyberAgent Inc. 広告LP制作のための 深層学習推論基盤 どのような要件が求められるか 4
©2023 CyberAgent Inc. 2023年1月31日付 プレスリリース https://www.cyberagent.co.jp/news/detail/id=28484 サイバーエージェントのAI開発体制 5
©2023 CyberAgent Inc. クリエイティブ制作からLP運用改善までのすべてでAIが活躍 6 広告媒体 運用レポート エンドユーザー 極予測LPは LP以降を担当
制作 効果予測 効果予測によるLP制作, 配信, 効果検証 バナー広告 の効果予測 検索連動型広告の効果予測 商材・モデル撮影 バナー広告文生成 広告文生成 Impressions, Clicks, Conversions, … LP (Landing Page)
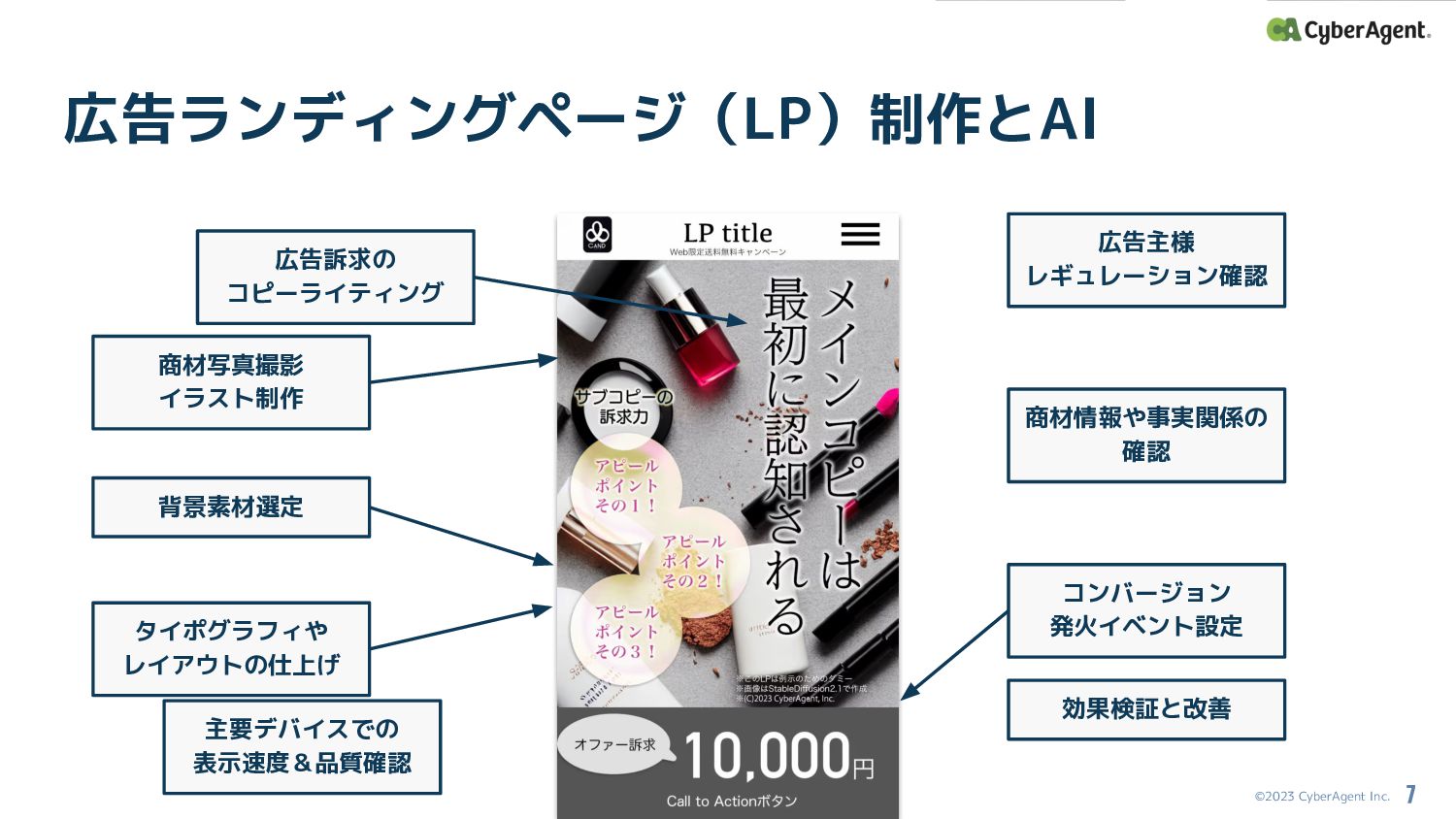
©2023 CyberAgent Inc. 広告ランディングページ(LP)制作とAI 7 広告訴求の コピーライティング 商材写真撮影 イラスト制作 背景素材選定
広告主様 レギュレーション確認 タイポグラフィや レイアウトの仕上げ 主要デバイスでの 表示速度&品質確認 コンバージョン 発火イベント設定 商材情報や事実関係の 確認 効果検証と改善
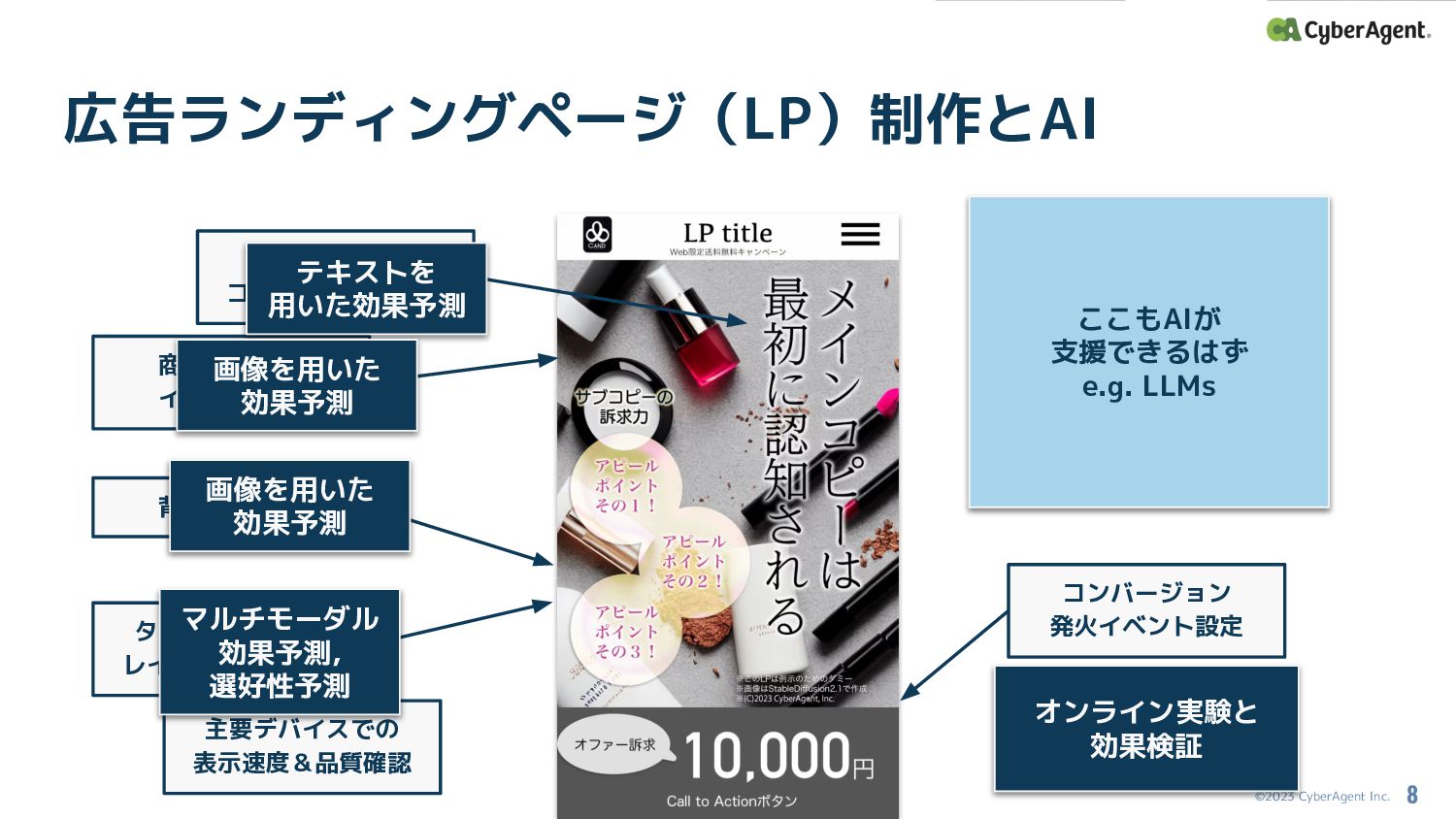
©2023 CyberAgent Inc. タイポグラフィや レイアウトの仕上げ マルチモーダル効果予測と 選好性予測 広告ランディングページ(LP)制作とAI 8 広告主様
レギュレーション確認 コンバージョン 発火イベント設定 商材情報や事実関係の 確認 ここもAIが 支援できるはず e.g. LLMs 広告訴求の コピーライティング 商材写真撮影 イラスト制作 背景素材選定 主要デバイスでの 表示速度&品質確認 テキストを 用いた効果予測 画像を用いた 効果予測 画像を用いた 効果予測 マルチモーダル 効果予測, 選好性予測 効果検証と改善 オンライン実験と 効果検証
©2023 CyberAgent Inc. 極予測LPの問題設定とアーキテクチャ上の特徴 ⇨配信や効果指標の取得まで行うため, モダンWeb技術スタックの比重が高い 1. LP制作〜配信まで行うためWebフロントエンド技術の比重が高め ◦ TypeScriptが第一言語,
Pythonその他は第二言語という様相 ◦ エンドユーザーに届けるLPの品質が第一 2. テキスト・画像・その他のマルチモーダルかつ多様なモデルの同時運用 ◦ 広告LPの広告文やビジュアル表現だけでなく, 各種メタデータも有用な情報 ◦ 効果予測だけでなく各種の制作支援で複数のモデルを活用 3. デザイナーによるオンデマンドな予測実行と大規模バッチ処理の混在 ◦ デザイナー向けの機能は低レイテンシー, バッチ向けは高スループットが必要 9
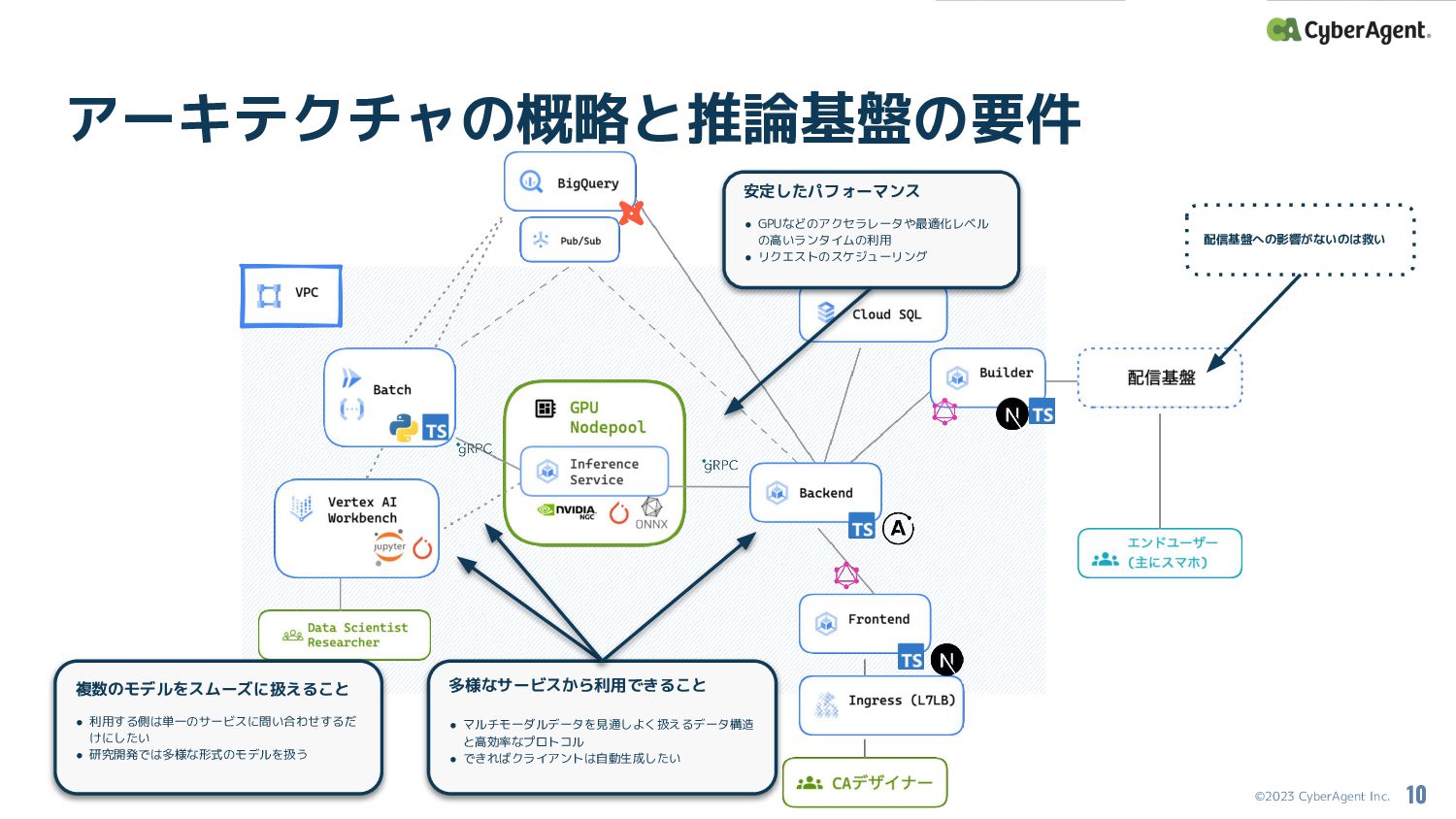
©2023 CyberAgent Inc. アーキテクチャの概略と推論基盤の要件 10 多様なサービスから利用できること • マルチモーダルデータを見通しよく扱えるデータ構造 と高効率なプロトコル •
できればクライアントは自動生成したい 複数のモデルをスムーズに扱えること • 利用する側は単一のサービスに問い合わせするだ けにしたい • 研究開発では多様な形式のモデルを扱う 安定したパフォーマンス • GPUなどのアクセラレータや最適化レベル の高いランタイムの利用 • リクエストのスケジューリング 配信基盤への影響がないのは救い
©2023 CyberAgent Inc. 推論基盤の技術選定と NVIDIA Triton Inference Serverの導入 プロダクトの要件の変化と なぜNVIDIA
Triton Inference Serverを選択したか 11
©2023 CyberAgent Inc. 事業フェーズが進んで生じた問題 初期の自前実装の推論基盤では要件が満たせなくなってきた...... 正式リリース🎉 と案件数・ユーザー数の急増 ◦ 導入する案件が急増、デザイナーチームも拡大 ◦
次の一手として準備していた制作支援機能も拡大 制作支援機能は高度化 ◦ 大規模な言語モデル, マルチモーダルなモデル ◦ 研究成果をすぐに実装して実用化する重要性が増大 推論基盤はそのままではいられない ◦ FastAPI (Python) で実装したサーバー内でPyTorchのモデルを動かすのみ ◦ 当初は十分に機能していた実装 12
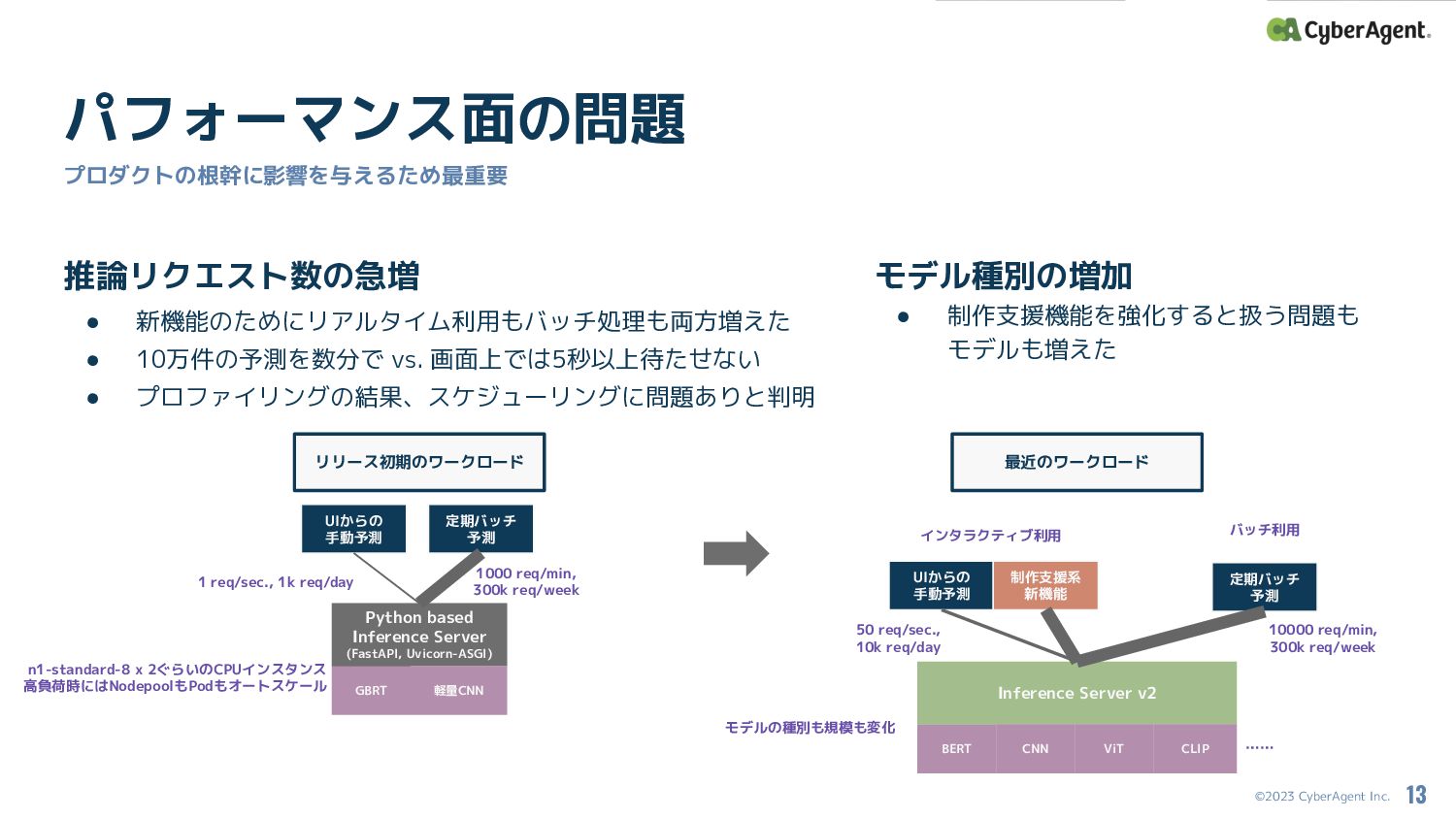
©2023 CyberAgent Inc. パフォーマンス面の問題 プロダクトの根幹に影響を与えるため最重要 推論リクエスト数の急増 • 新機能のためにリアルタイム利用もバッチ処理も両方増えた • 10万件の予測を数分で
vs. 画面上では5秒以上待たせない • プロファイリングの結果、スケジューリングに問題ありと判明 13 GBRT Python based Inference Server (FastAPI, Uvicorn-ASGI) 軽量CNN UIからの 手動予測 定期バッチ 予測 1 req/sec., 1k req/day 1000 req/min, 300k req/week n1-standard-8 x 2ぐらいのCPUインスタンス 高負荷時にはNodepoolもPodもオートスケール BERT Inference Server v2 CNN UIからの 手動予測 定期バッチ 予測 50 req/sec., 10k req/day 10000 req/min, 300k req/week モデルの種別も規模も変化 ViT CLIP …… 制作支援系 新機能 インタラクティブ利用 バッチ利用 リリース初期のワークロード 最近のワークロード モデル種別の増加 • 制作支援機能を強化すると扱う問題も モデルも増えた
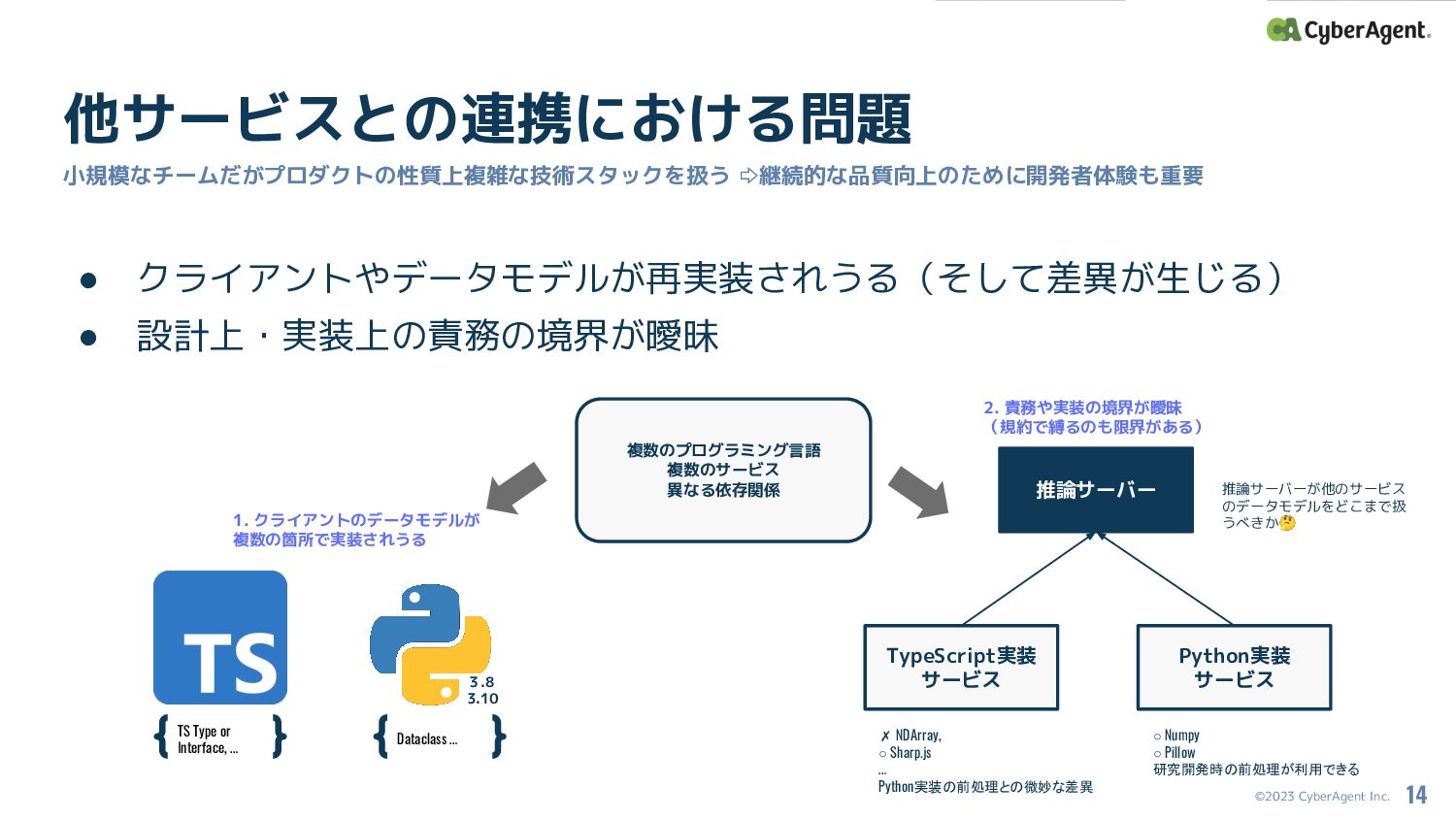
©2023 CyberAgent Inc. • クライアントやデータモデルが再実装されうる(そして差異が生じる) • 設計上・実装上の責務の境界が曖昧 他サービスとの連携における問題 小規模なチームだがプロダクトの性質上複雑な技術スタックを扱う ⇨継続的な品質向上のために開発者体験も重要
14 複数のプログラミング言語 複数のサービス 異なる依存関係 3.8 3.10 1. クライアントのデータモデルが 複数の箇所で実装されうる 推論サーバー Dataclass … TS Type or Interface, … 2. 責務や実装の境界が曖昧 (規約で縛るのも限界がある) TypeScript実装 サービス Python実装 サービス ✗ NDArray, ◦ Sharp.js … Python実装の前処理との微妙な差異 ◦ Numpy ◦ Pillow 研究開発時の前処理が利用できる 推論サーバーが他のサービス のデータモデルをどこまで扱 うべきか🤔
©2023 CyberAgent Inc. MLOpsの一部としての問題 試行錯誤サイクルの高速化とプロダクション品質を両立したい • モデル形式が研究だけに都合が良い形だったり、その逆だったり...... ◦ PythonのPickle形式は処理系やライブラリの依存関係が変わると動作が保証できない ◦
ランタイム固有の形式はモデルのエクスポートにコツが要る ◦ 論文の再現実装をする際に元論文が使っているフレームワークに縛られる • 研究開発からプロダクション化の責務の境界が曖昧 ◦ MLOpsを実現する際にきれいに分業できることは実際には稀? ◦ 研究者が前処理・後処理コードを書こうとすると、それぞれのプロダクトの知識が要る ◦ 研究者はMLモデル単体で確実に機能するようにエクスポートしたり、Model Cardを書く ◦ MLエンジニアはモデルの入出力とプロダクトのデータモデル間をつなぎこみ、 最適化し、デプロイする 15
©2023 CyberAgent Inc. 推論基盤の技術選定 重要視したポイント • 堅牢で高機能なサーバー(リクエストのスケジューリング等) • KServe APIのような機械学習向け汎用APIとデータモデル
• 主要なモデルフォーマットへの対応と複数モデル同時実行 • 既存のKubernetesクラスタ上へのデプロイが容易 検討に上がった方法・OSS実装 • 自前実装: サーバー実装部分が実装コスト的に厳しい • KServe API系(KServe, TFServing, TorchServeなど): 当時はサーバー部分の機能が... • マネージドサービス: 検討していたが要件に合わず 16
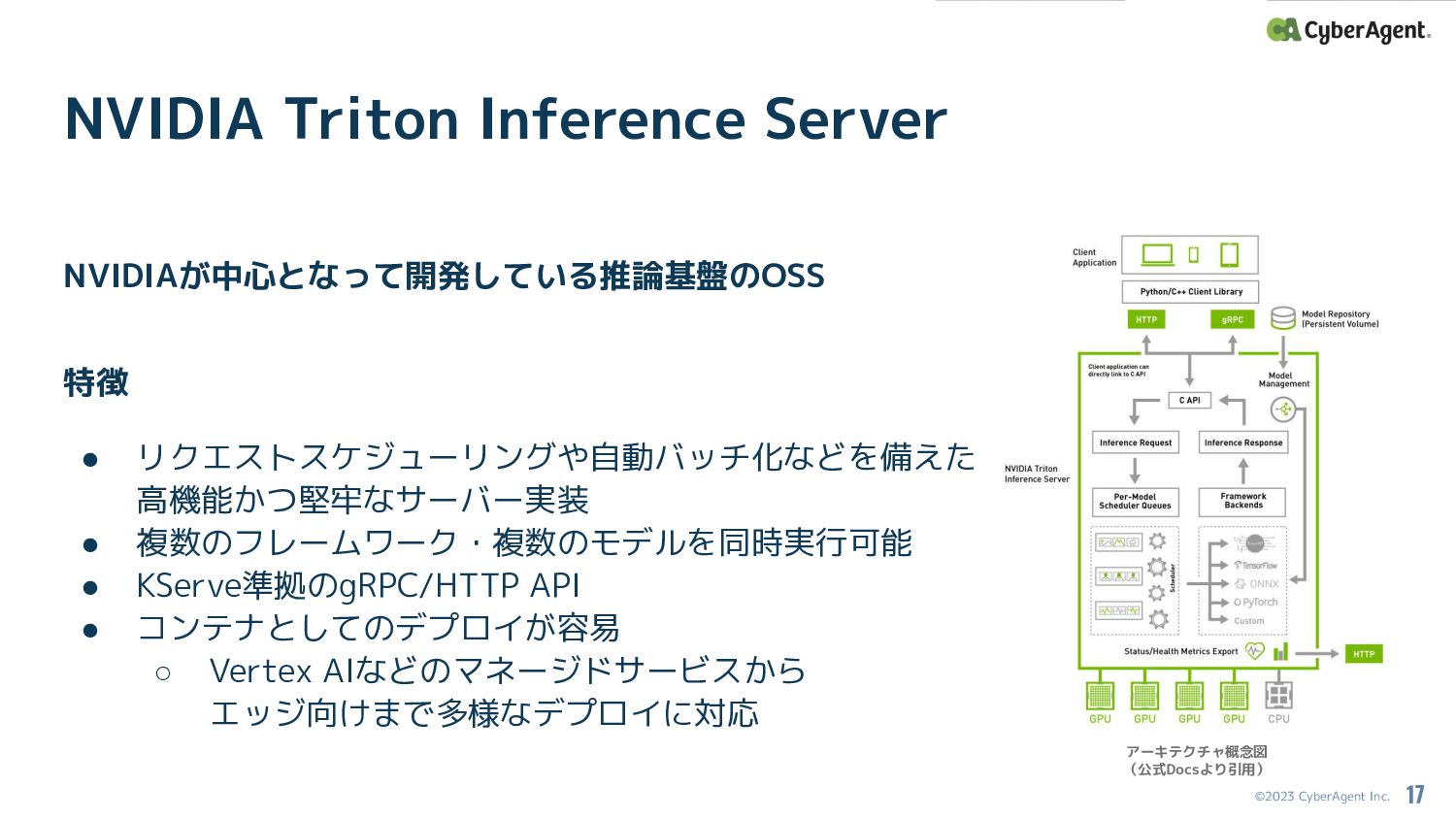
©2023 CyberAgent Inc. NVIDIAが中心となって開発している推論基盤のOSS 特徴 • リクエストスケジューリングや自動バッチ化などを備えた 高機能かつ堅牢なサーバー実装 • 複数のフレームワーク・複数のモデルを同時実行可能
• KServe準拠のgRPC/HTTP API • コンテナとしてのデプロイが容易 ◦ Vertex AIなどのマネージドサービスから エッジ向けまで多様なデプロイに対応 NVIDIA Triton Inference Server 17 アーキテクチャ概念図 (公式Docsより引用)
©2023 CyberAgent Inc. • 移行はMLエンジニア(私)が担当 ◦ 期間3ヶ月 ◦ 調査から段階的なプロダクション環境への反映まで •
以下のような詳細部分を除いてはとてもスムーズに移行できた ◦ モデルエクスポート時の細かい問題 ◦ 前処理・後処理含めた挙動調整 ◦ Node.jsエコシステム側からの利用時のパフォーマンスチューニング 自前推論サーバーからの段階的移行 18
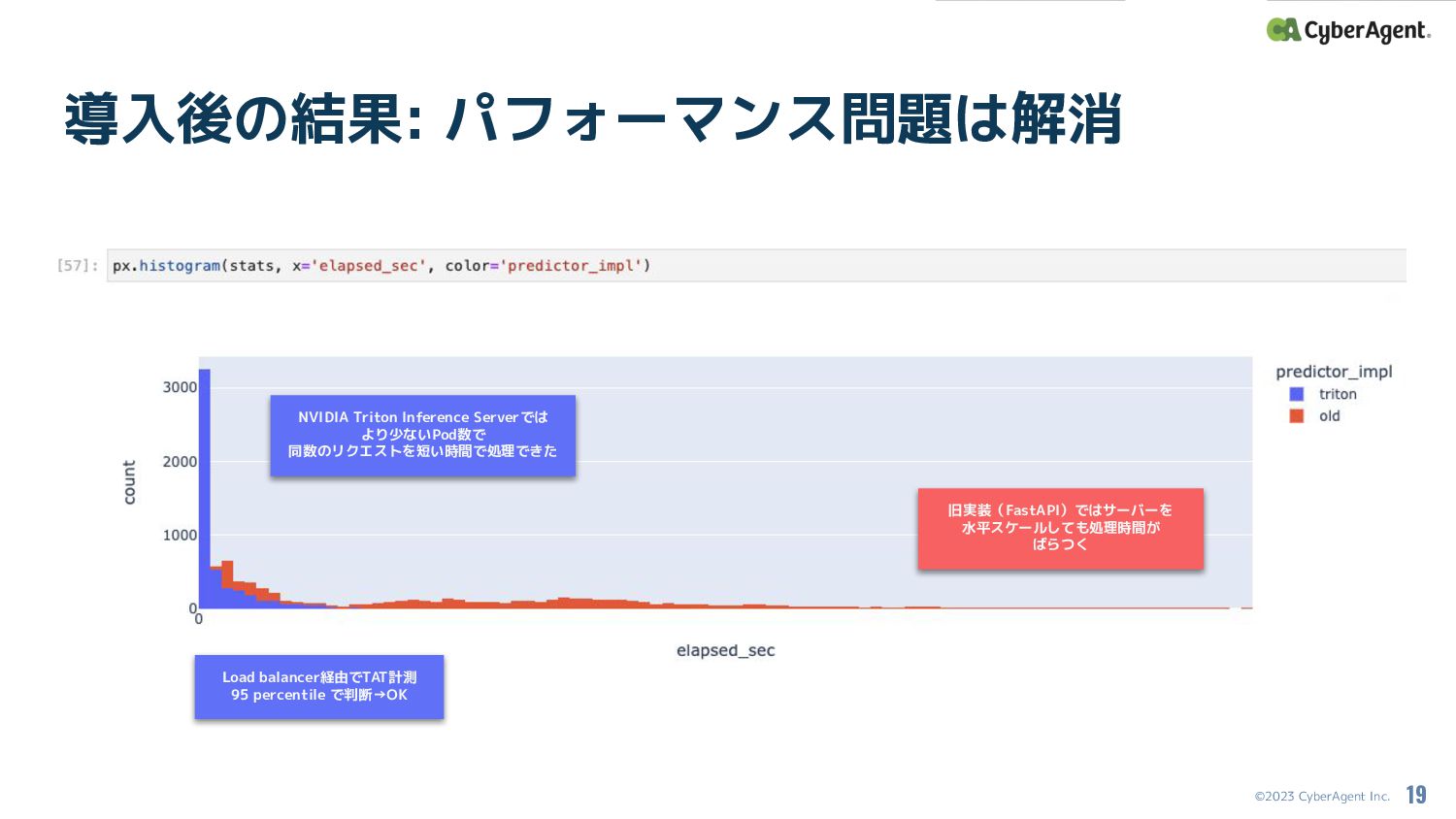
©2023 CyberAgent Inc. 導入後の結果: パフォーマンス問題は解消 19 Load balancer経由でTAT計測 95 percentile
で判断→OK 旧実装(FastAPI)ではサーバーを 水平スケールしても処理時間が ばらつく NVIDIA Triton Inference Serverでは より少ないPod数で 同数のリクエストを短い時間で処理できた
©2023 CyberAgent Inc. Pros and Cons 実運用半年経過時の所感です • 良かったところ ◦
パフォーマンス面の問題が改善された ◦ 開発者体験: 前処理・後処理込で推論基盤の責務が明確になった ボイラープレート的なコードを削減できた ◦ MLOps: 研究側で作ったモデルをプロダクション化する方法が明確になった 研究者側もプロダクト側も互いの技術スタックに制約されなくなった デリバリーの品質も頻度も改善された • まだ解決できていないところ ◦ 技術スタック的には重くなった(gRPCコード生成, モデルエクスポートのテクニック等) ◦ ランタイムイメージのサイズが大きくk8s上での取り回しは悪い 20
©2023 CyberAgent Inc. NVIDIA Triton Inference Serverの概要と 実用上嬉しい機能について 細かいTipsもあります 21
©2023 CyberAgent Inc. コンテナランタイム 基本的なモデルデプロイの流れ 22 model_1 model repository model_2
model_… TorchScript形式 Python backend用 スクリプト …… 1. モデルの準備 2. 推論サーバーの実行と利用 Kubernetes, SageMaker, VertexAI, Docker等だけでなく, ビルドしたサーバーのバイナリでももちろん実行可能 サービス1 サービス2 KServe HTTP API KServe gRPC API 推論リクエストに含まれるもの • 実行対象のモデルとそのバージョン • 入力(複数) ◦ 入力名 ◦ データ型 ◦ 型に応じた形式のデータ
©2023 CyberAgent Inc. • スケジューラー側で自動的に一連のリクエストをバッチ化する • 有用な場面 ◦ GPUの演算ユニットを十分に利用したい場合 ◦
スループットが重要な場合 • パラメータ ◦ バッチのサイズ ◦ バッチ化の条件(時間窓) ◦ perf_analyzerでこれらのパラメータを変えて実測するのがよい • モデル側の要件 ◦ バッチ次元が付与されているモデル [batch, …] であればOK • 弊社事例では... ◦ 全モデルで使用中 ◦ クライアント側はSDKの制約等でbatch_size=1となっていても効率化できる 特に有用な機能: Dynamic Batching 23
©2023 CyberAgent Inc. • 複数のモデルの入出力を組み合わせられる簡易DAG機能 ◦ アンサンブル機械学習とは関係がない(紛らわしい名前) • 有用な場面 ◦
複雑な前処理・後処理を推論サーバーに隠蔽したいとき ◦ 手法が複数のモデルで構成されており、個別での利用も想定されるとき • 制約 ◦ Dynamic Batching等のスケジューリング設定はそれぞれに依る ◦ 現時点ではEnsemble設定時にモデルのバージョン管理はできない • 弊社事例では... ◦ クライアント側で個別実装されていた前処理を集約するために使用 特に有用な機能: Ensemble Scheduler 24
©2023 CyberAgent Inc. • 例: 画像の埋め込みとテキストの埋め込みを取得する ◦ 画像、テキストそれぞれに前処理が必要 • NVIDIA
Triton Inference Server上での構成例 “Ensemble”機能による前処理の統合 25 multimodal-embedder (Ensemble) image-preprocessor text-preprocessor image-embedder text-embedder Input: { image: <BASE64PNG>, text: <UTF8 bytes> } Output: { image_emb: Float32[b, dim], text: Float32[b, dim] }
©2023 CyberAgent Inc. 🤔 モデルエクスポート時とランタイムの不一致にハマる ◦ たとえばPyTochの `torch.jit.trace` を利用してTorchScriptを出力する ▪
ランタイムイメージに含まれているLibTorchではエラーになる ▪ なぜ?活性化関数のシグネチャが異なっていた ▪ NGCランタイムイメージではPyTorchのリリース版ではなくパッチが当たったバージョンだった ◦ NGCイメージ上でエクスポートまで行うのが安全ではあるが...... 🤔 gRPC定義からのTypeScriptクライアント自動生成でハマる ◦ KServe APIからの拡張仕様、特に入出力に注意 ▪ たとえば出力はバイト列として `raw_output_contents` に入る ▪ 型に応じて適切にデコードする必要がある ◦ Python, C++, Javaの場合はクライアント実装が提供されており、各種Utilsも付属 ▪ 他の言語でクライアントコードを自動生成して使用する場合、それらを参考に再実装する 実は簡単ではない?いくつかのハマりどころ 26
©2023 CyberAgent Inc. Python処理系のバージョン ◦ マネージドサービスの多くでPython3.8となっている ▪ NGCも3.8😢 ◦ 最近のバージョンの恩恵を受けられない
◦ 他のPython実装のサービスと微妙な不一致がある ◦ 現状、手間のかかるカスタムPython処理系のビルドが必要 Node.js + gRPC環境のパフォーマンスチューニング ◦ Node.js環境からの利用例が少ない(この発表で利用例が増えるとうれしいです) ◦ メモリやコネクションまわりのパラメータ調整は実測ベース モデル自体の最適化 ◦ ONNXやNVIDIA TensorRTの機能を使ってモデル自体の実行を最適化したい 実運用半年経過時の所感です 現時点での課題 27
©2023 CyberAgent Inc. 今後と本発表のまとめ 28
©2023 CyberAgent Inc. MLOpsの視点から推論基盤を改善したい • ✅安定した推論パフォーマンスとより良い開発サイクル • 🤔柔軟な研究開発環境と堅牢で高品質なプロダクション設計・実装との両立 さらに強力な手法も運用できる基盤にしたい •
大規模事前学習言語モデル(LLM: GPTなど) • マルチモーダルモデル(CLIP, BLIPなど) • 画像生成モデル • 音声合成モデル …… and more! • 巨大なモデルの分散デプロイなどの課題山積 今後の展望 29
©2023 CyberAgent Inc. • 広告制作における深層学習の利用例を紹介 • NVIDIA Triton Inference Serverという選択肢
◦ Dynamic Batchingのような強力なスケジューリング機能 ◦ Ensemble Schedulerのような柔軟なワークフロー機能 • 導入の結果と振り返り ◦ Kubernetes上の既存推論サーバーを置き換え、パフォーマンス上の課題を改善 ◦ 責務の明確化や実装の共通化など開発者体験も改善 ◦ 技術スタックの重さやモデル実行の最適化は今後の課題 広告制作における深層学習と推論基盤の技術選定を紹介 本発表のまとめ 30
©2023 CyberAgent Inc. 1. 発表内容の元となった弊社ブログ記事(自著) ◦ Triton Inference Server を深層学習モデル推論基盤として導入したので振り返る
| CyberAgent Developers Blog 2. Model Repositoryの例、TypeScript向けクライアントのコード生成方法やユーティリティの実装サンプル(自著) ◦ GitHub - tuxedocat/triton-client-polyglot-example 3. TypeScript向けクライアントのコード生成に関する記事(自著) ◦ Triton Inference Serverを色々な環境から使いたい: TypeScript (Node.js) 編 4. NVIDIA Triton Inference ServerのDocs ◦ アーキテクチャ、特にSchedulerについて server/architecture.md triton-inference-server/server · GitHub ◦ パフォーマンス計測 server/perf_analyzer.md triton-inference-server/server · GitHub ◦ ランタイム側の最適化オプション Optimization - triton-inference-server/server · GitHub 付録と参考文献 31
©2023 CyberAgent Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}