Apache BigData 2016 Conference: http://sched.co/8U0a
When working with BigData & IoT systems we often feel the need for a Common Query Language. The system specific languages usually require longer adoption time and are harder to integrate within the existing stacks.
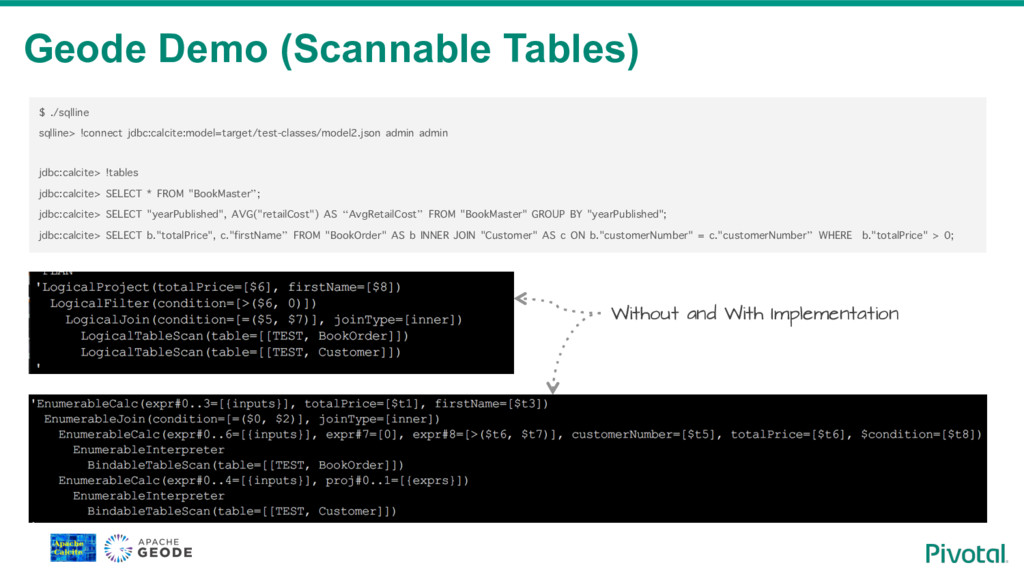
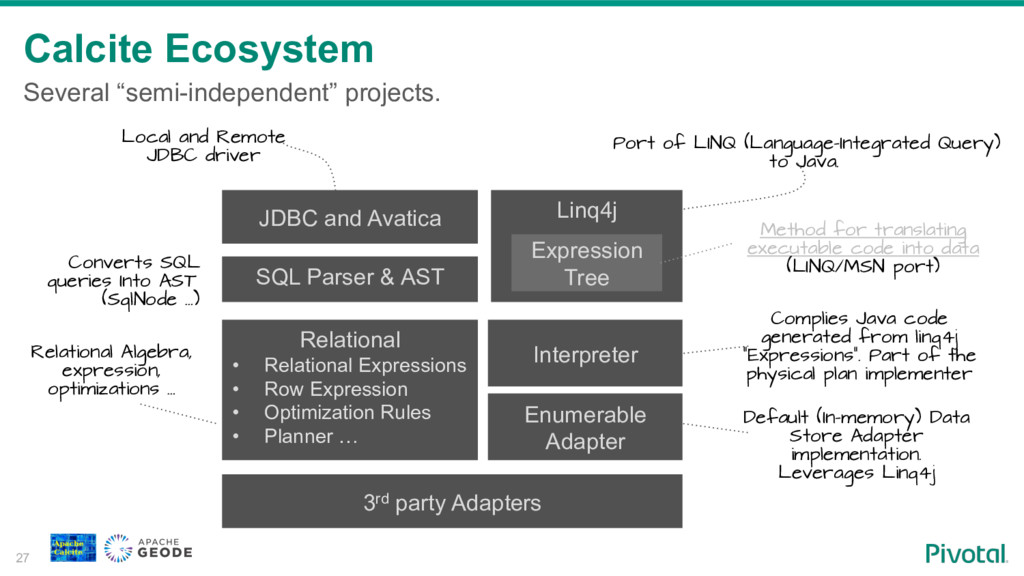
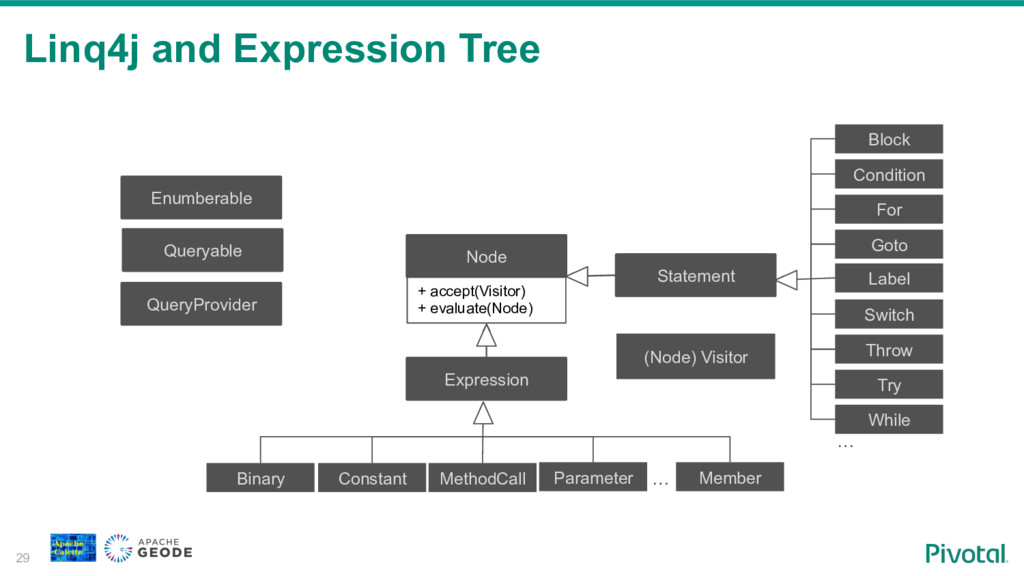
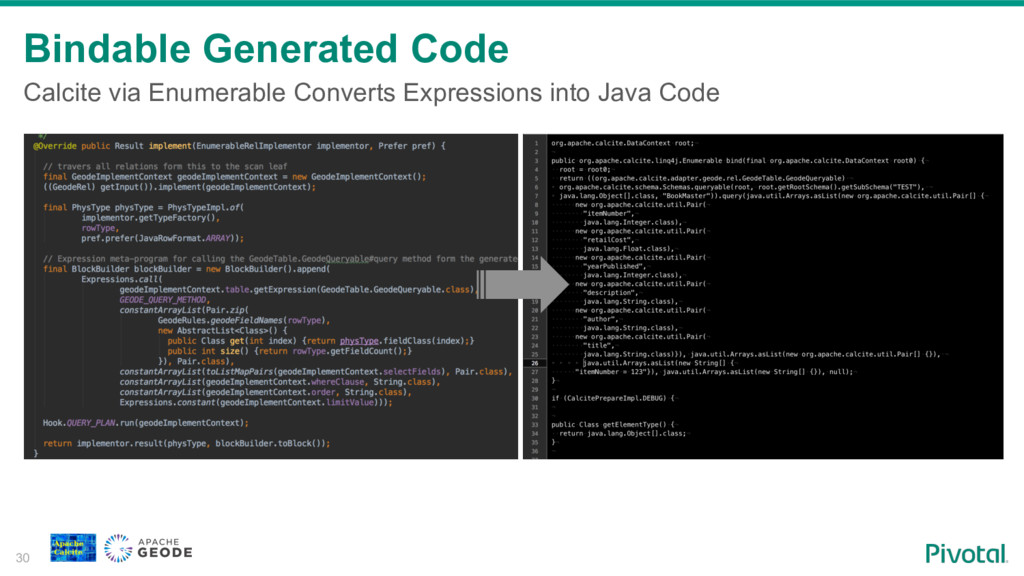
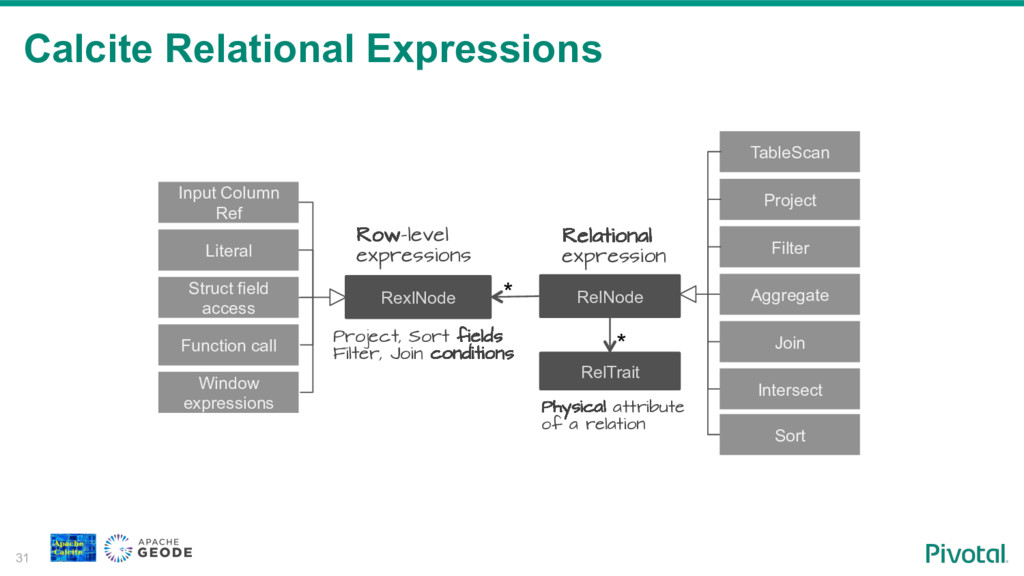
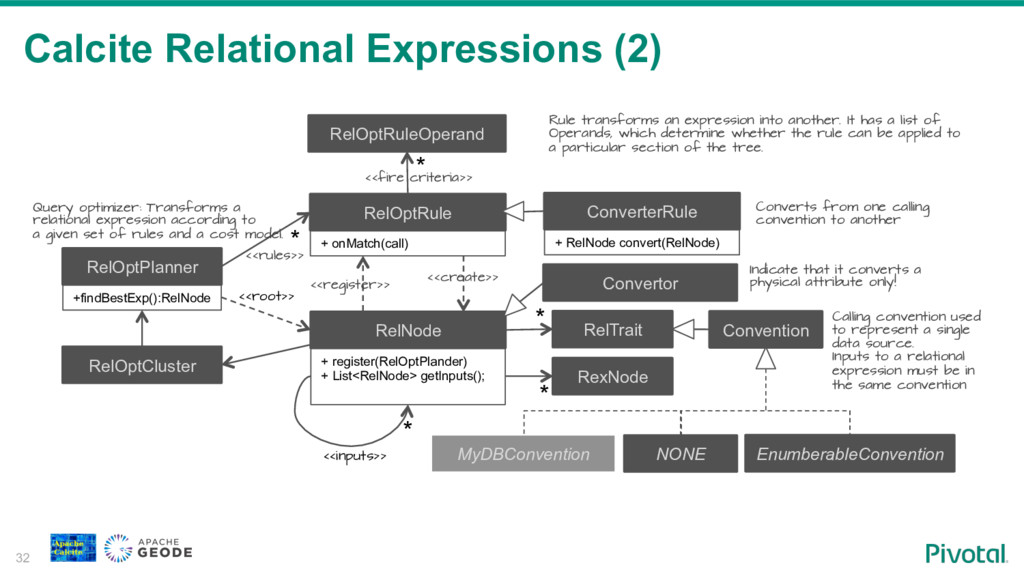
To fill this gap some NoSql vendors are building SQL access to their systems. Building SQL engine from scratch is a daunting job and frameworks like Apache Calcite can help you with the heavy lifting. Calcite allow you to integrate SQL parser, cost-based optimizer, and JDBC with your NoSql system.
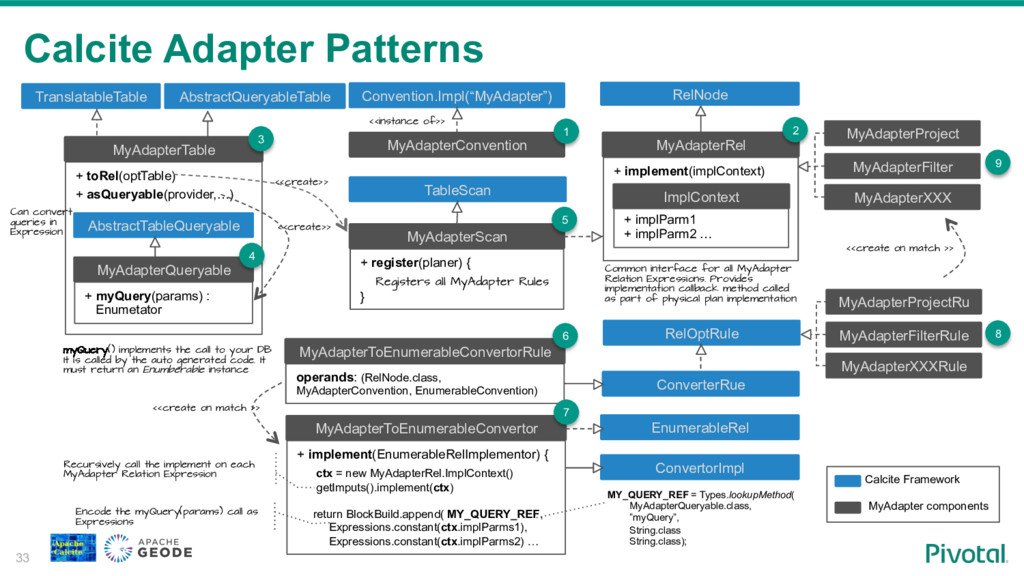
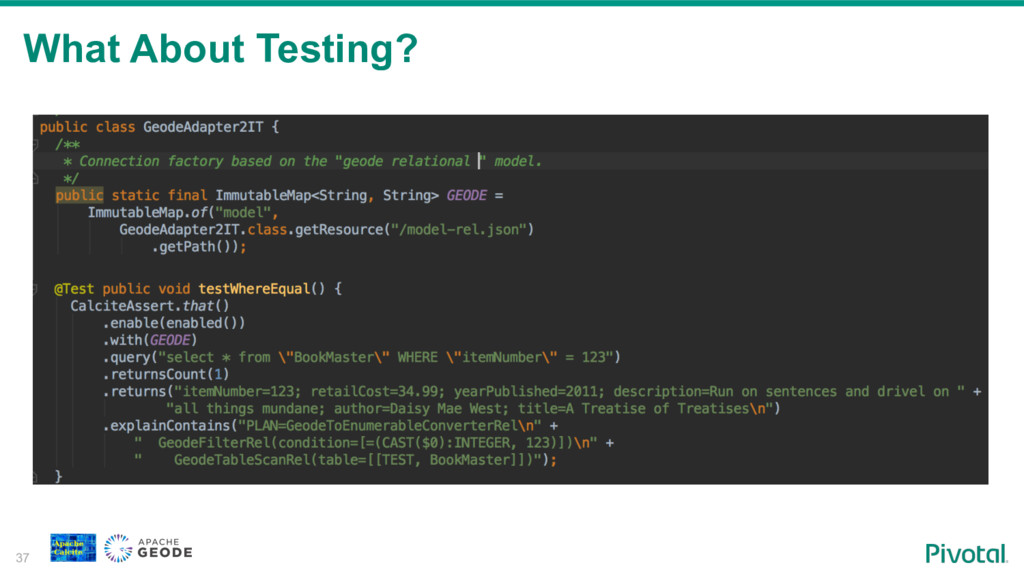
We will walk through the process of building a SQL access layer for Apache Geode (In-Memory Data Grid). I will share my experience, pitfalls and technical consideration like balancing between the SQL/RDBMS semantics and the design choices and limitations of the data system.
Hopefully this will enable you to add SQL capabilities to your preferred NoSQL data system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
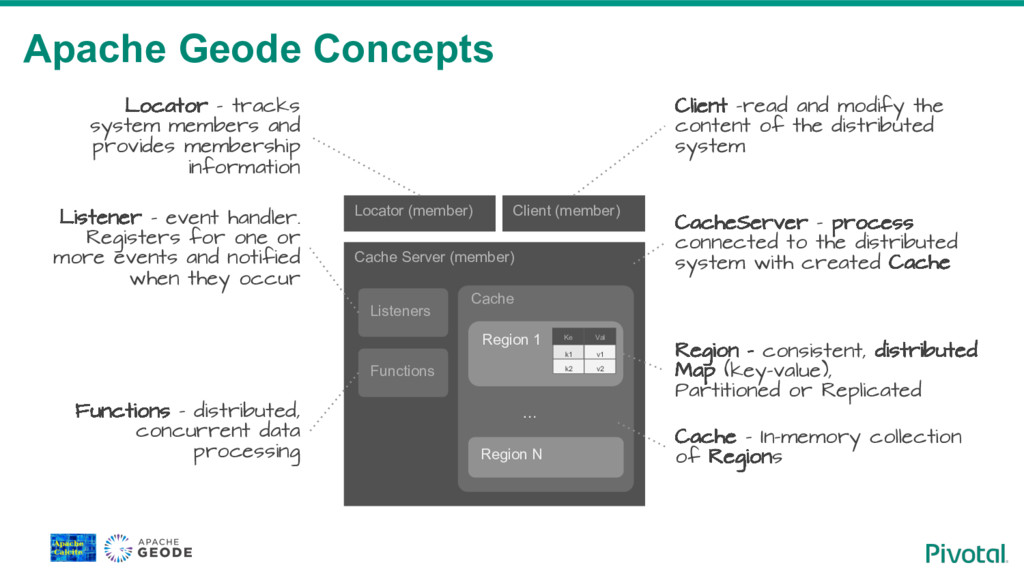{kind=link}
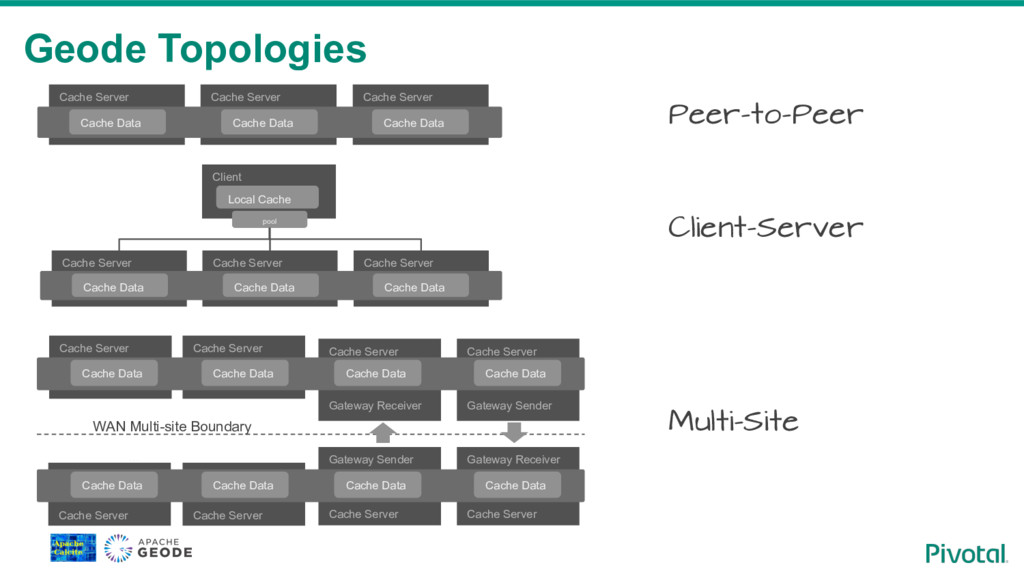{kind=link}
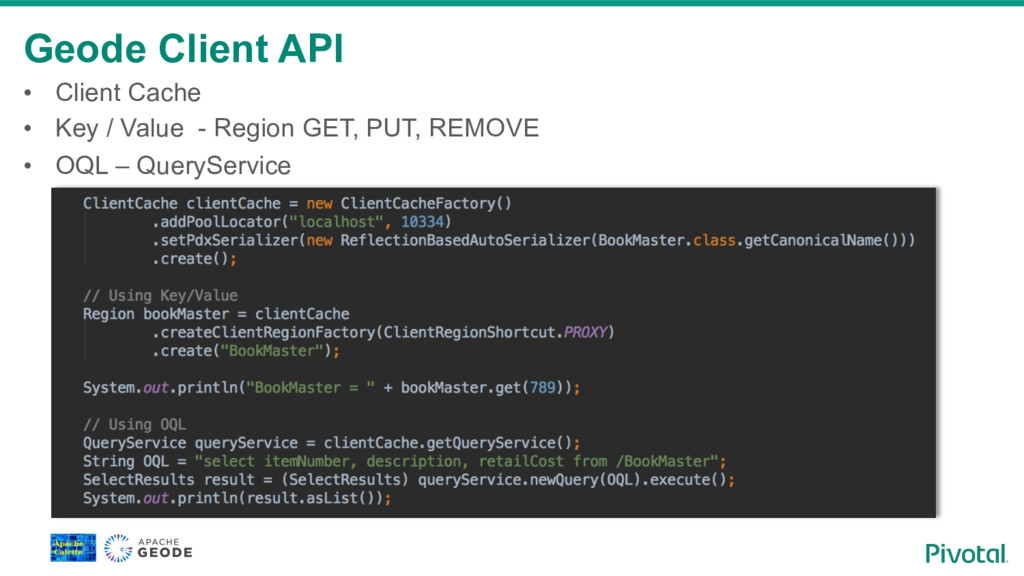{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
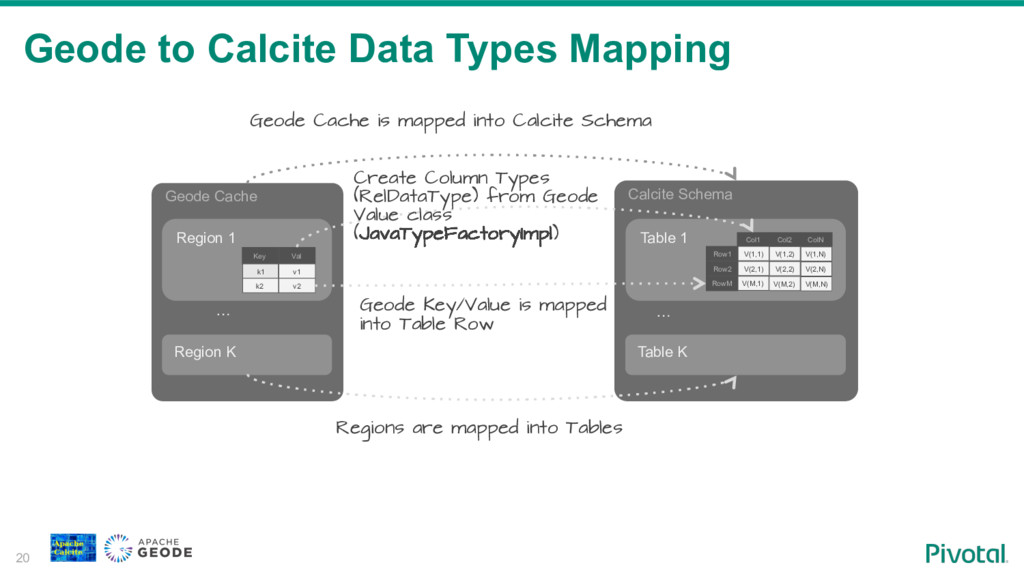{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}