FOSDEM 2017 talk: http://bit.ly/2xRV7By
Talk video: http://bit.ly/2xScodQ
When working with BigData & IoT systems we often feel the need for a Common Query Language. The platform specific languages are often harder to integrate with and require longer adoption time.
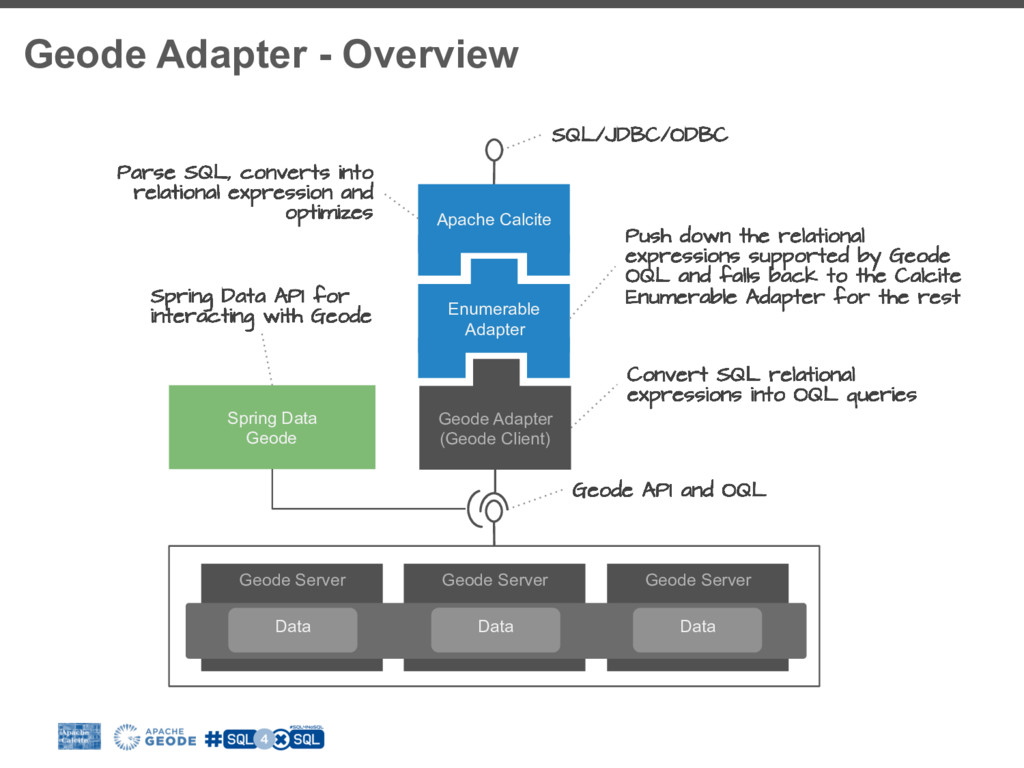
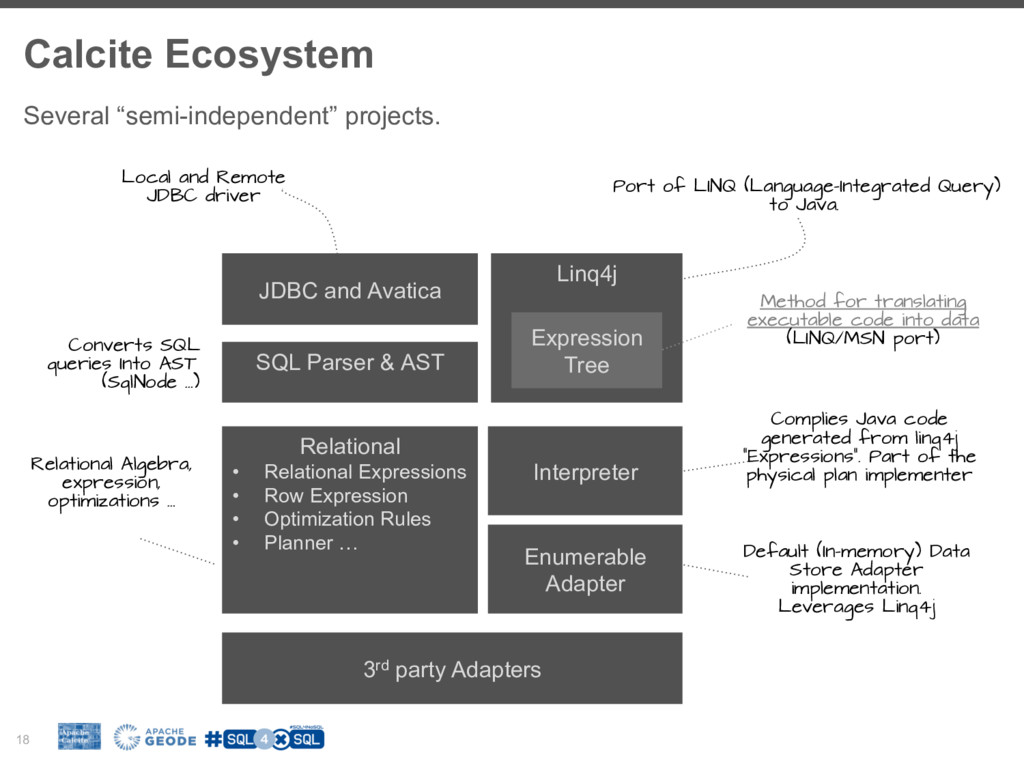
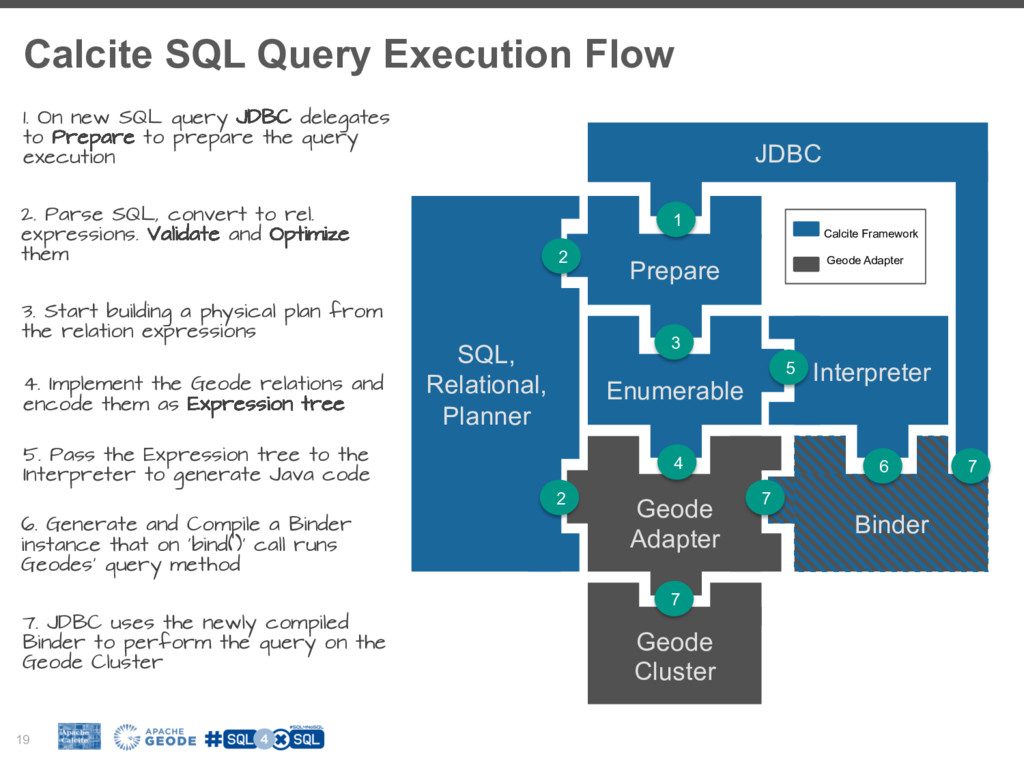
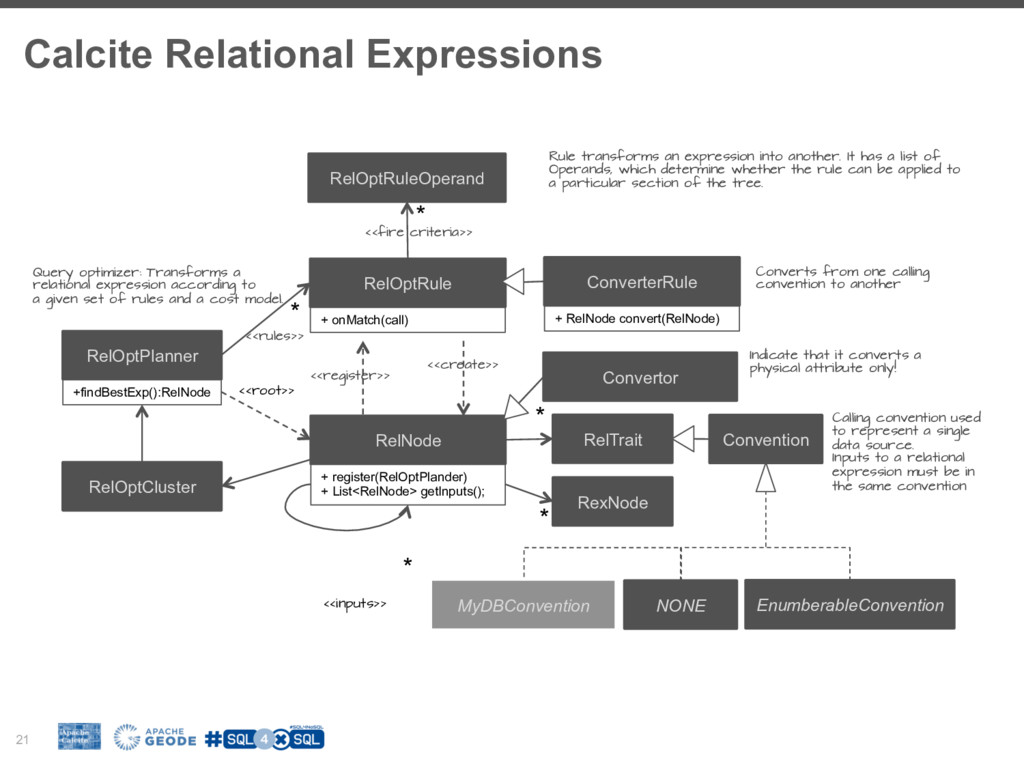
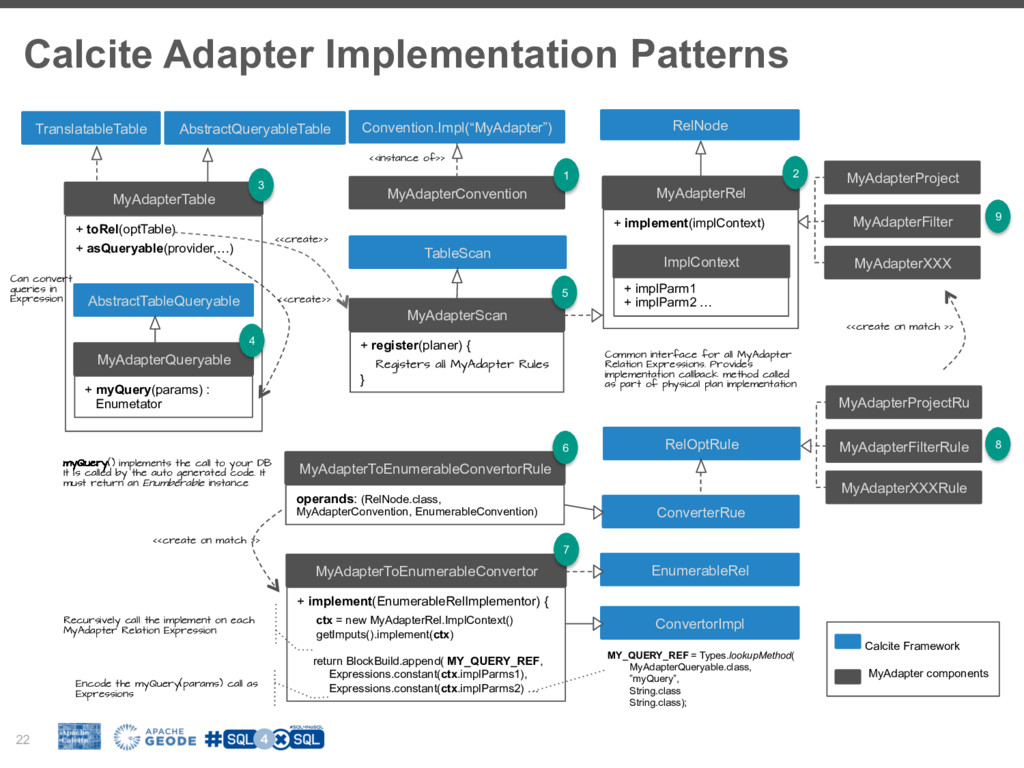
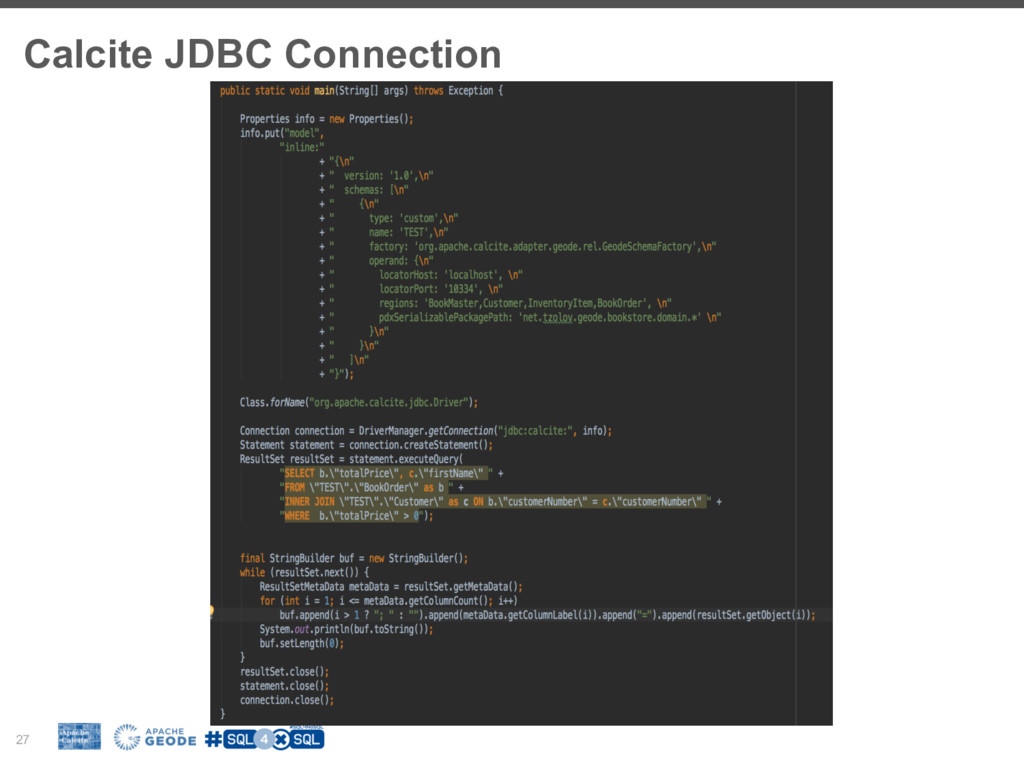
To fill this gap many NoSql (Not-only-Sql) vendors are building SQL layers for their platforms. It is worth exploring the driving forces behind this trend, how it fits in your BigData stacks and how we can adopt it in our favorite tools. However building SQL engine from scratch is a daunting job and frameworks like Apache Calcite can help you with the heavy lifting. Calcite allow you to integrate SQL parser, cost-based optimizer, and JDBC with your big data system.
Calcite has been used to empower many Big-Data platforms such as Hive, Spark, Drill Phoenix to name some.
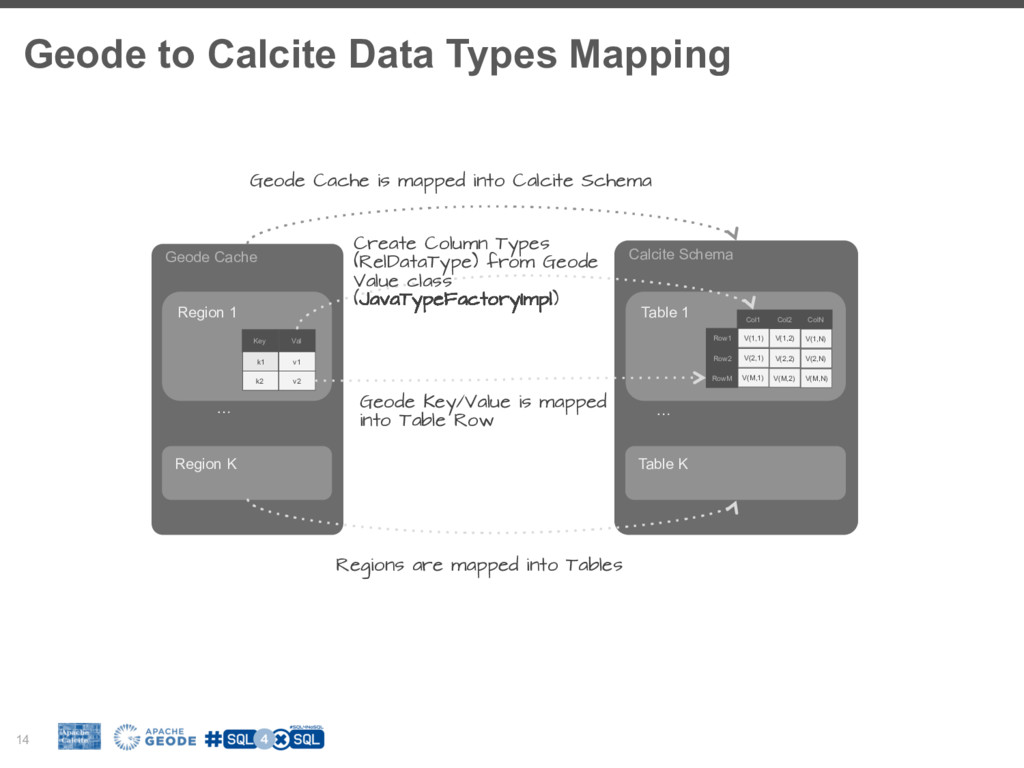
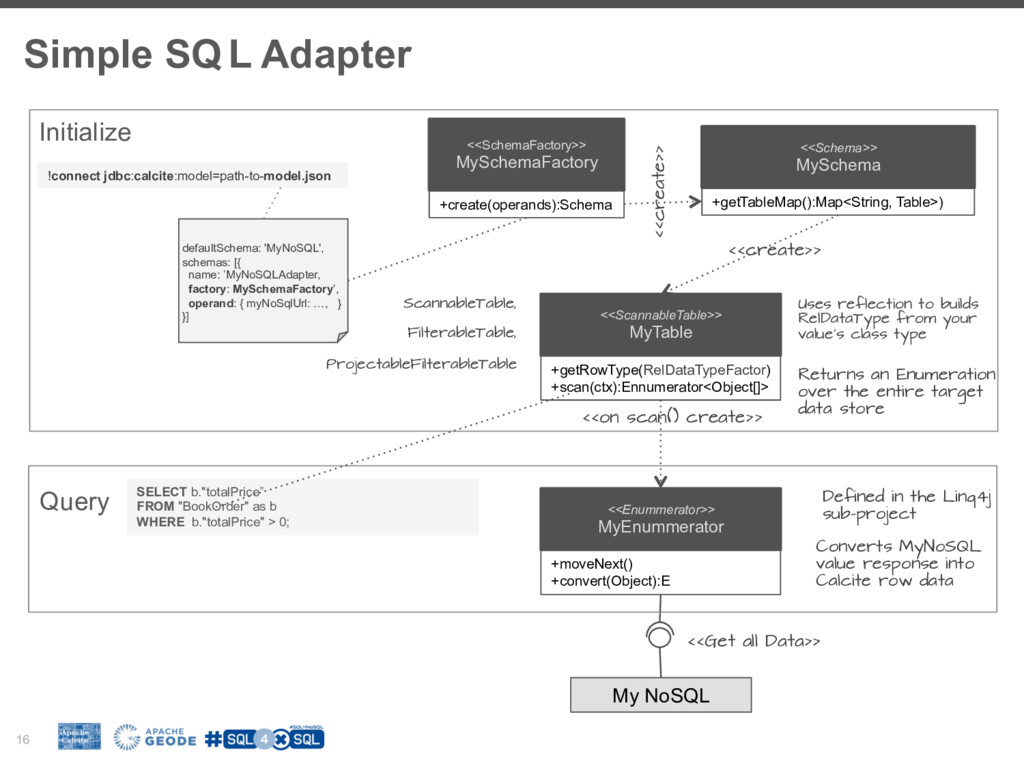
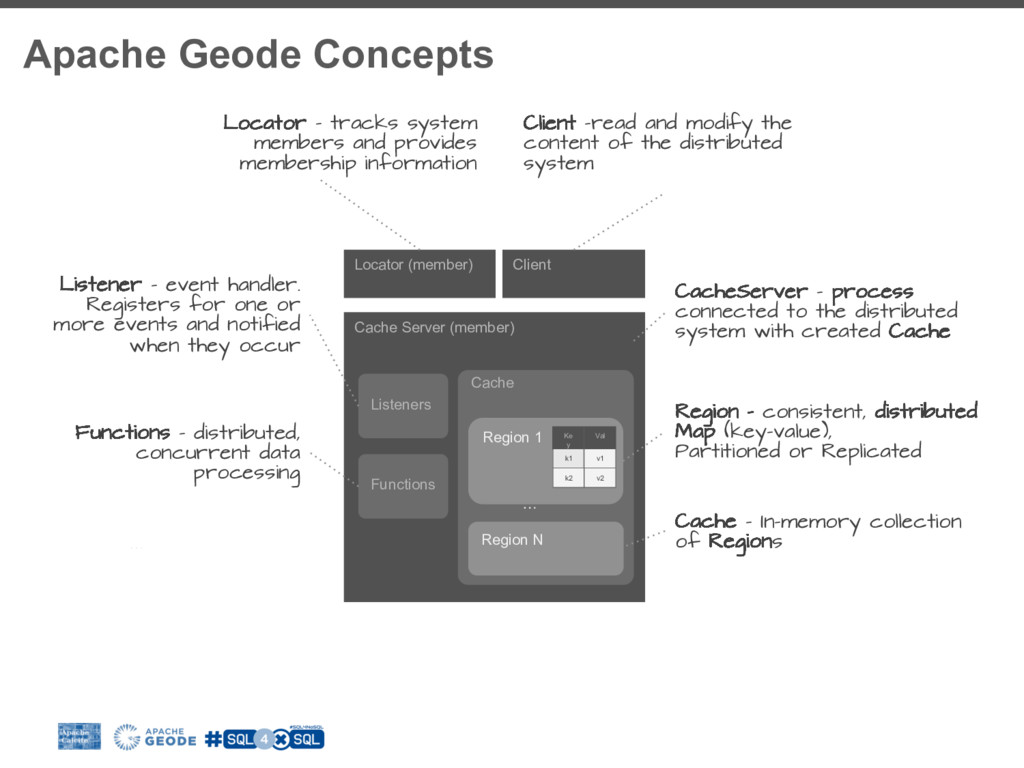
I will walk you through the process of building a SQL access layer for Apache Geode (In-Memory Data Grid). I will share my experience, pitfalls and technical consideration like balancing between the SQL/RDBMS semantics and the design choices and limitations of the data system.
Hopefully this will enable you to add SQL capabilities to your prefered NoSQL data system.
"It will be interesting to see what happens if an established NoSQL database decides to implement a reasonably standard SQL; the only predictable outcome for such an eventuality is plenty of argument. - NoSQL Distilled, Martin Fowler - 2012"
The Relational Databases (RDBMS) are an essential component of the computing ecosystem. Yet in the past decade we have witnessed a wave of alternative data management technologies often branded as NoSQL and BigData - an ambiguous and lacking prescriptive definition names.
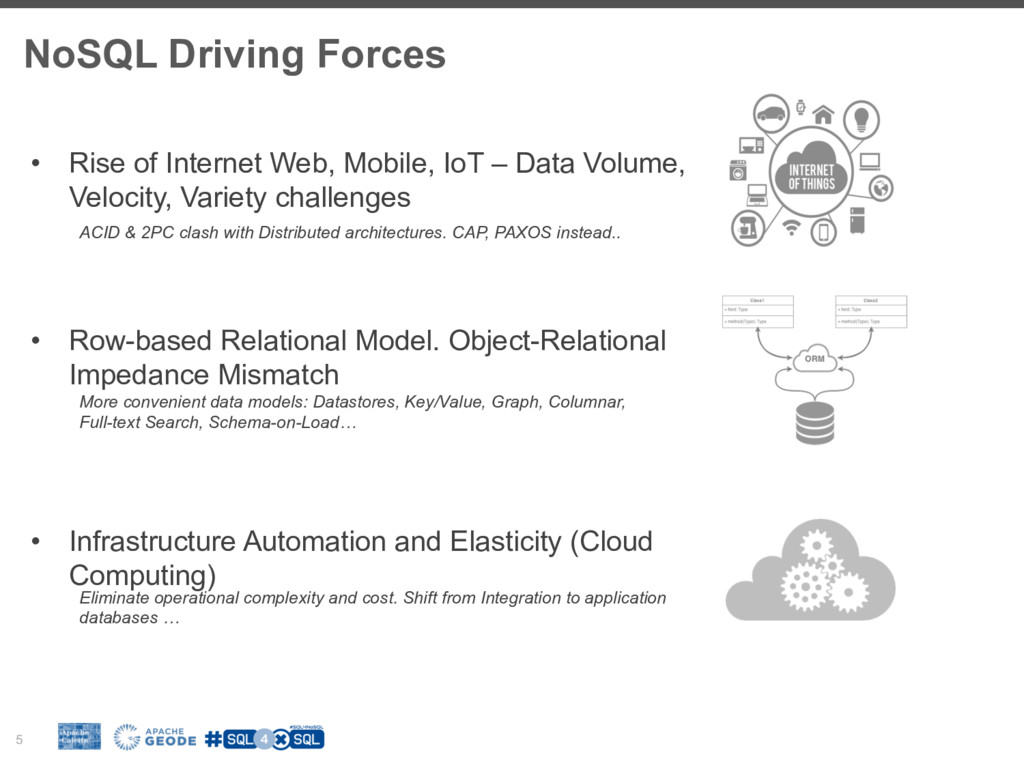
To understand the NoSQL/BigData "movement" one need to understand the forces fueling it:
* The rise of Internet (Web, Mobile, IoT...) leading to Data {Volume, Velocity and Variety} challenges
* Object-relational impedance mismatch
* Cloud computing - Infrastructure Automation and Elasticity
* Shift from Integration to Application databases
* Data-Value vs. Storage-Cost Economics Shift
The various approaches in addressing those challenges have led to a multitude of over 150 commercially supported NoSQL/BigData platforms.
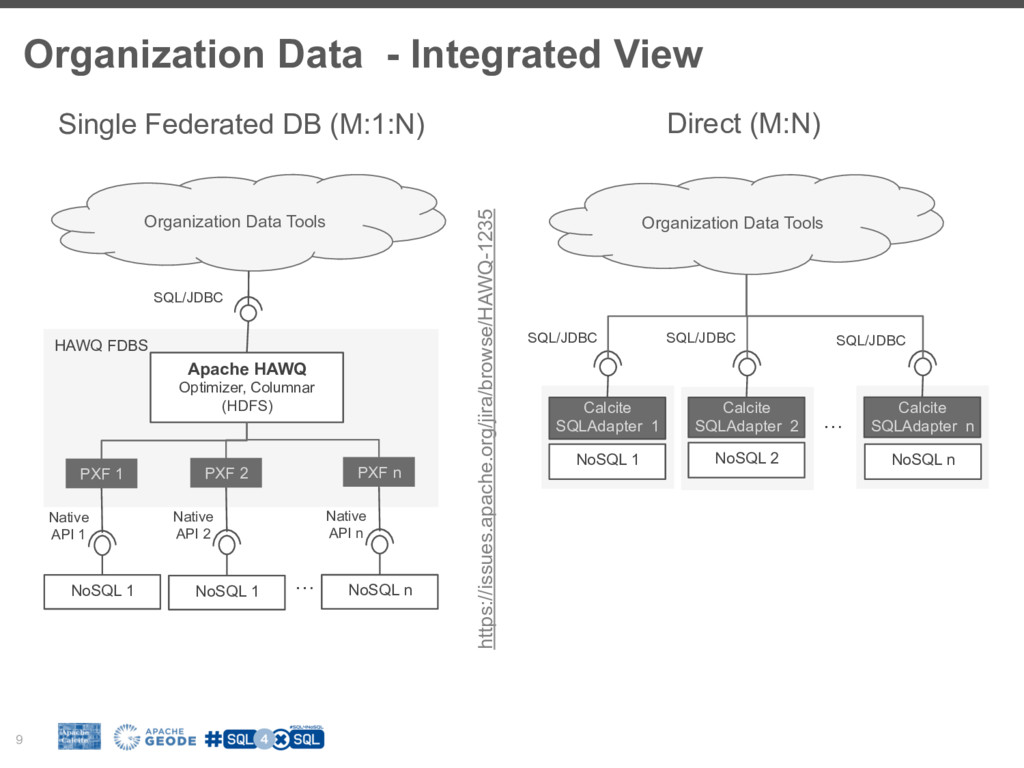
Such diversity means that an organization will adopt a mixture of data storage technologies for handling different circumstances (Polyglot Persistence).
How does an organization integrate the mix of data technologies?
To fill the gap many NoSql/BigData vendors are (or are considering) building SQL and SQL-based layers for their platforms.
It is worth exploring the driving forces behind this trend ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
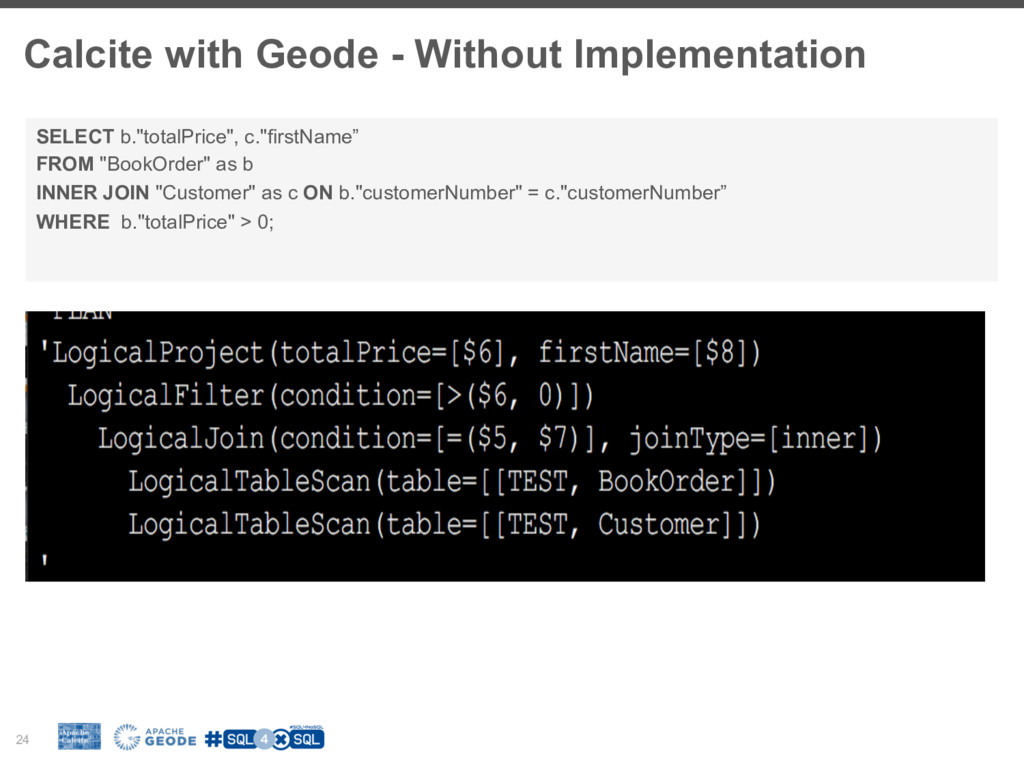
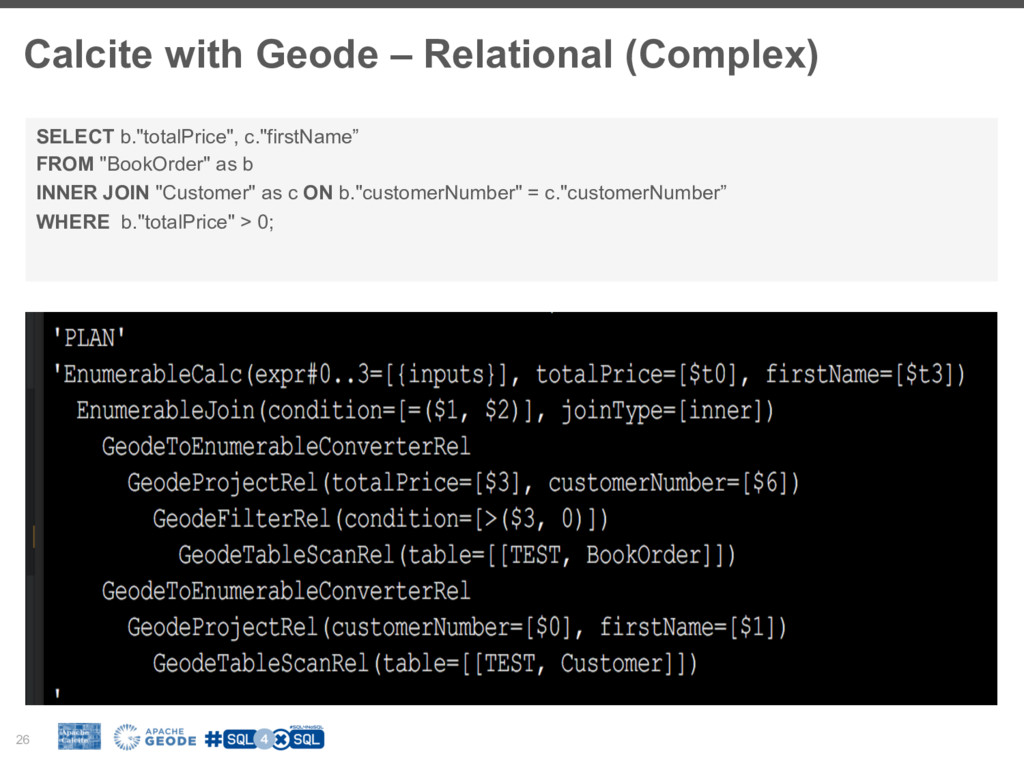
![Relational Algebra 23 Scan Scan Join Filter Project Customer [c]](https://files.speakerdeck.com/presentations/5c12d8cffdbb49caaf503d475b3cba6b/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}