An overview of methods for searching and aggregating data in Riak, covering Riak Search, secondary indexes and MapReduce. Reviews use cases and features for each method, when to use which, and the limitations and advantages of each approach. In addition, it covers query examples and the high-level architecture of each method.
{kind=link}
![• Andy Gross • Architect • @argv0 on Twitter • [email protected]](https://files.speakerdeck.com/presentations/505b6af90fb5de000200244b/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
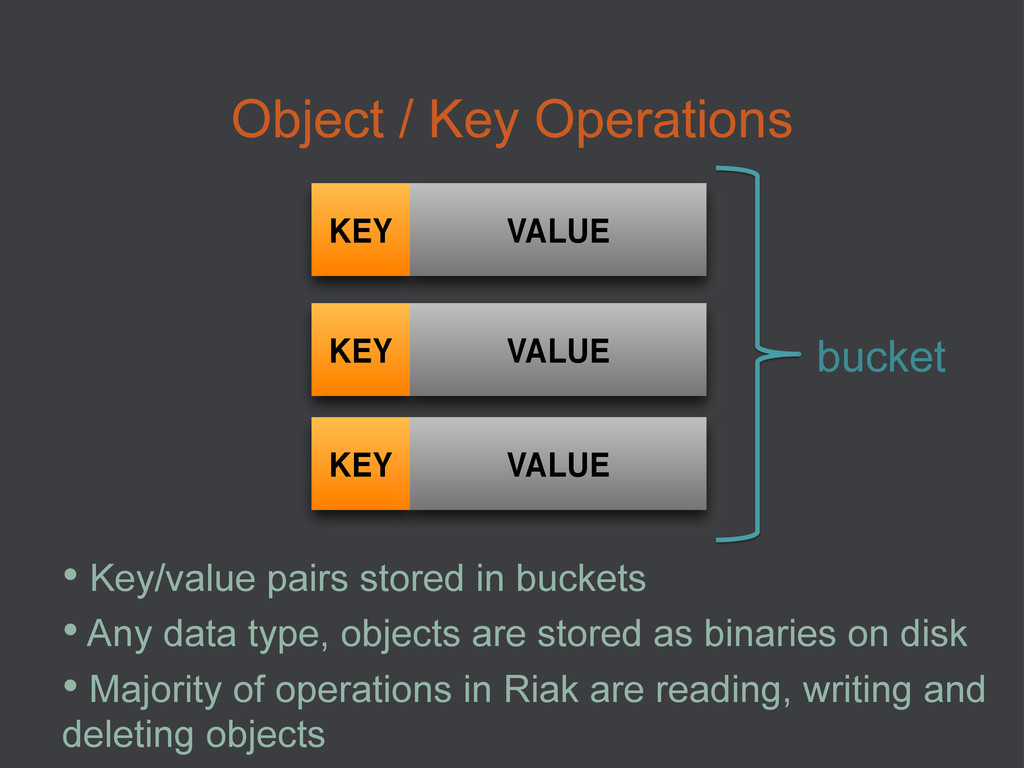{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
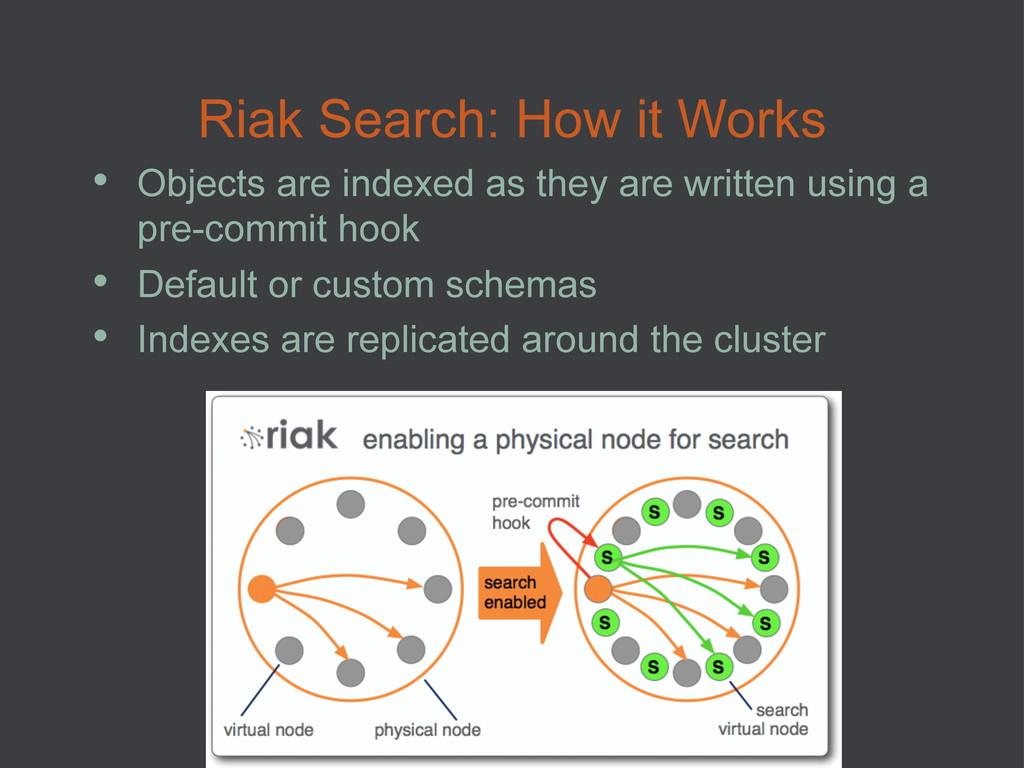{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}