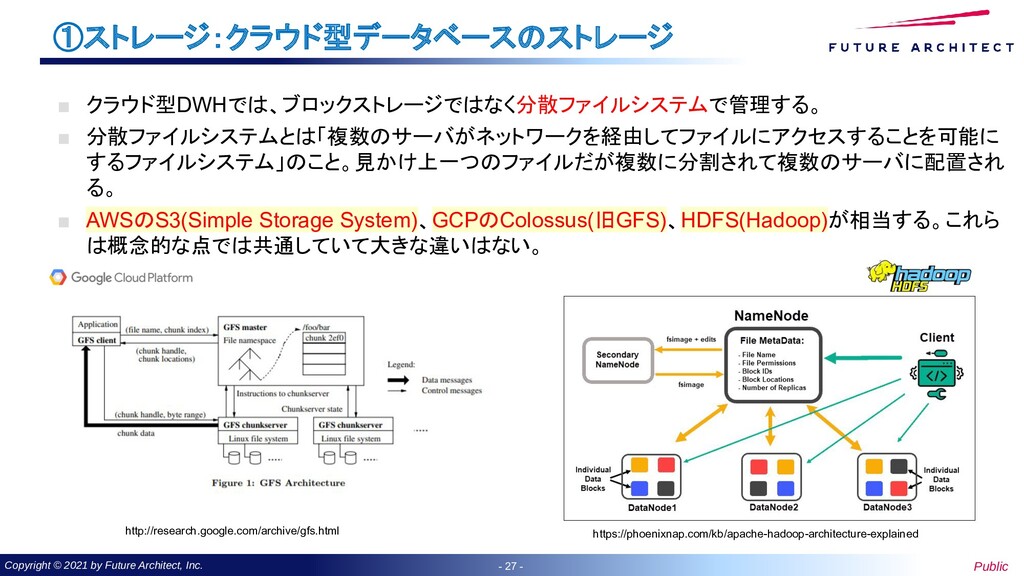
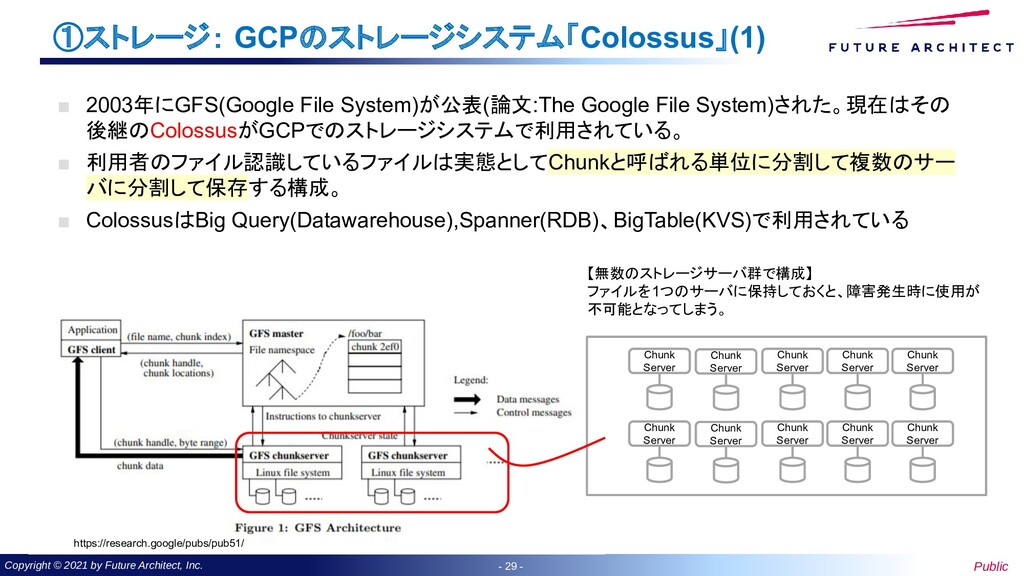
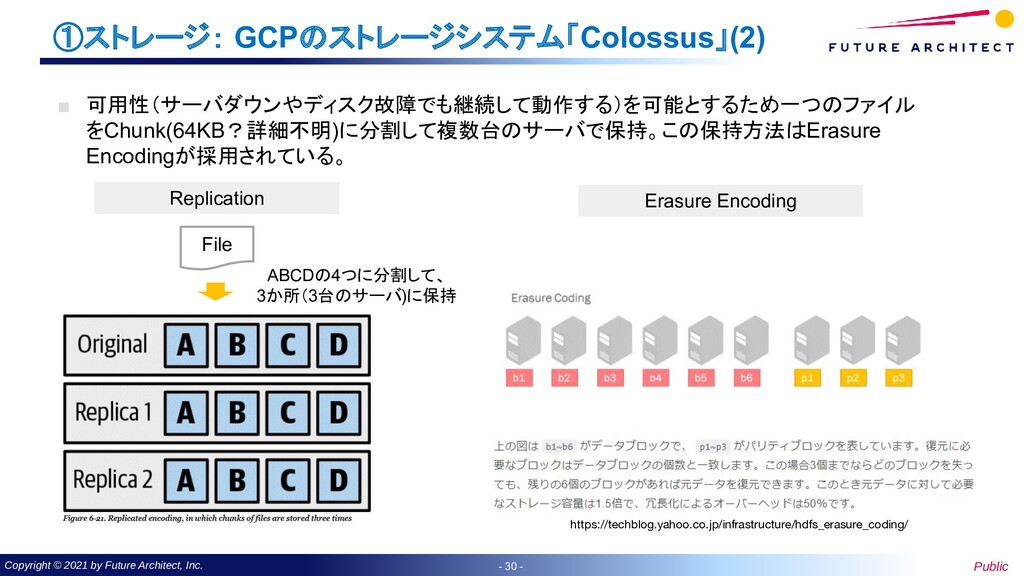
- ①ストレージ: GCPのストレージシステム「Colossus」(1) ▪ 2003年にGFS(Google File System)が公表(論文:The Google File System)された。現在はその 後継のColossusがGCPでのストレージシステムで利用されている。 ▪ 利用者のファイル認識しているファイルは実態としてChunkと呼ばれる単位に分割して複数のサー バに分割して保存する構成。 ▪ ColossusはBig Query(Datawarehouse),Spanner(RDB)、BigTable(KVS)で利用されている Chunk Server Chunk Server Chunk Server Chunk Server Chunk Server Chunk Server Chunk Server Chunk Server Chunk Server Chunk Server 【無数のストレージサーバ群で構成】 ファイルを1つのサーバに保持しておくと、障害発生時に使用が 不可能となってしまう。 https://research.google/pubs/pub51/
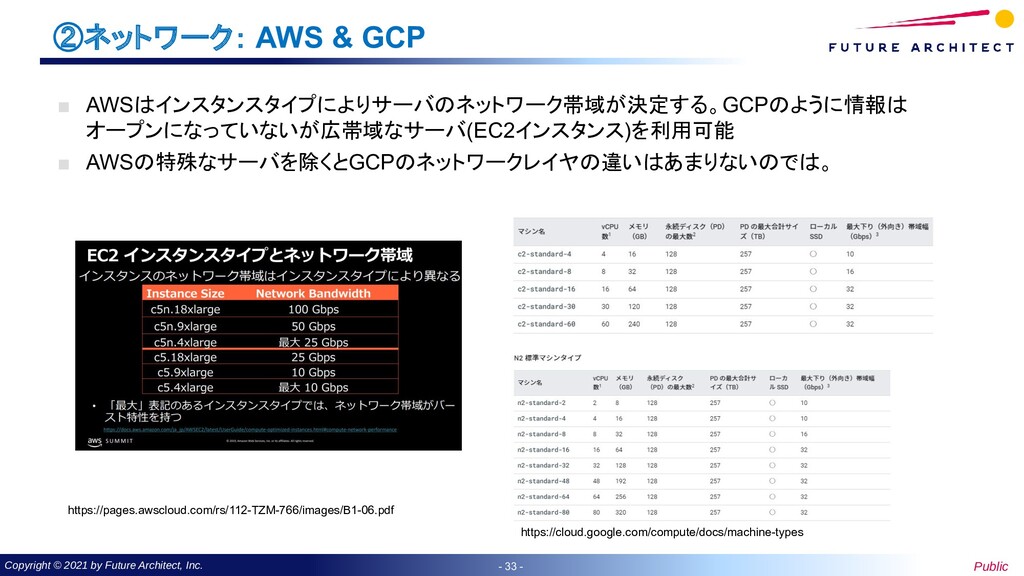
- ②ネットワーク: GCPのネットワーク「Jupiter」 ▪ 2015年にGCPでのDC内ネットワークについての論文が公開された。(Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network) SDNを利用したネットワークの経路にボトルネックを生じさせない「複数の経路を利用した 負荷分散」構成 ※SDN: Software Defined Network 普及期に入った40GbEを利用して最大構成で1.3Pbps(1つのサーバ間では10Gbps)が可 能な広帯域ネットワーク構成 https://research.google/pubs/pub43837/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}