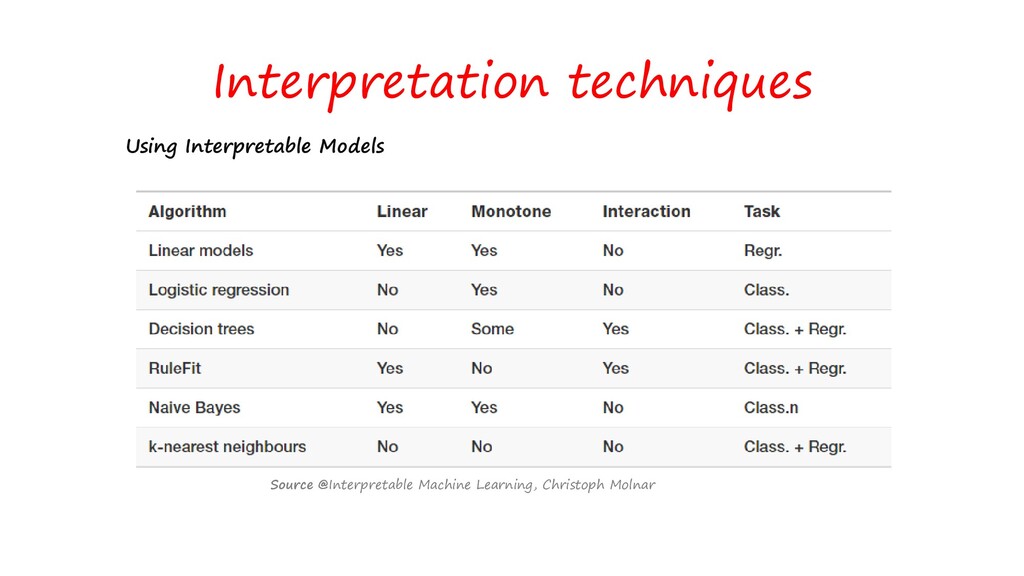
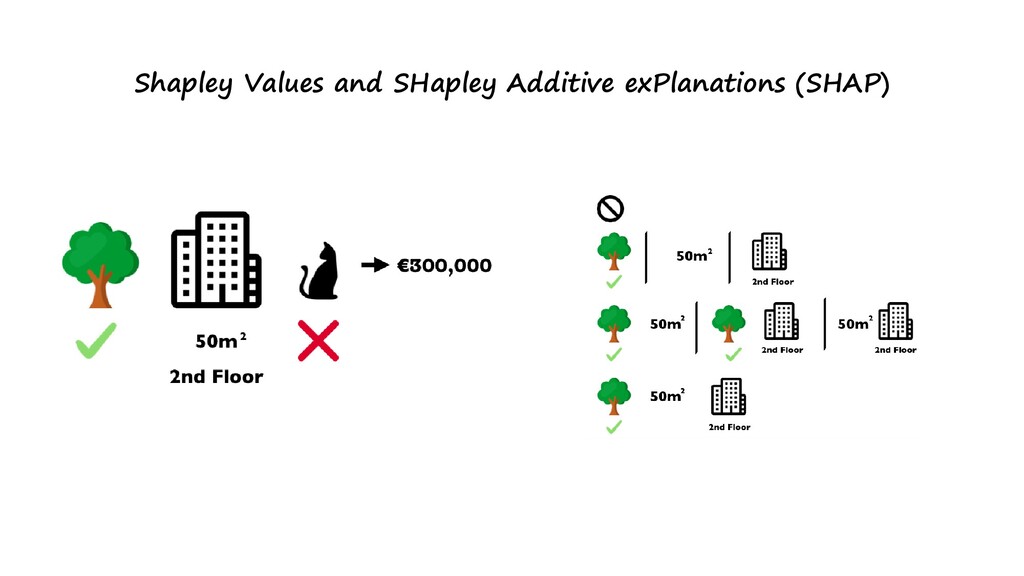
With the more complex algorithms like deep neural networks, random forest with 1000s of trees or dense machine learning models we are achieving the desired accuracy with a sacrifice of interpretability. If we are more interested in interpretability, we are sacrificing accuracy. In domains like finance or banking both are needed in justifying a prediction which helps the client and customers to understand why it predicted in that way. so how do we build interpretable machine learning models or explainable artificial intelligence? In this workshop, I will be explaining why it is important to build Interpretables models and how to draw insights from it and how to trust your model and make human to understand them, with the help of available methods.
{kind=link}
{kind=link}
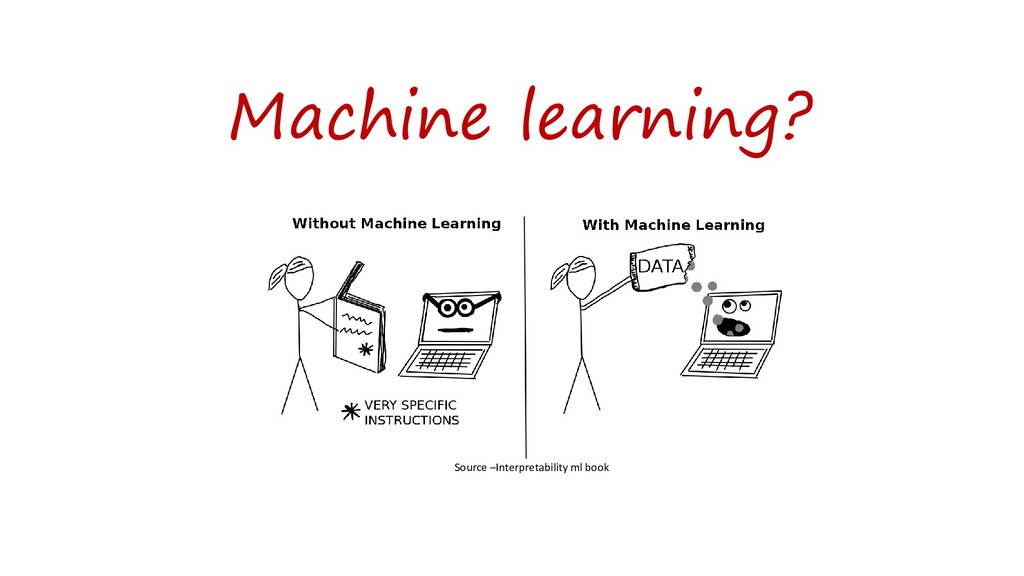{kind=link}
{kind=link}
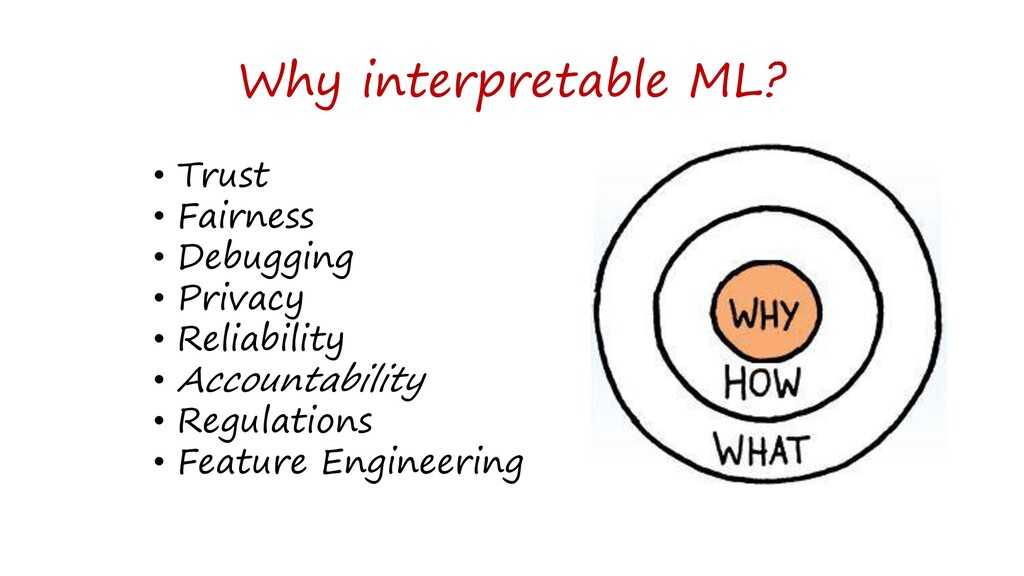{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
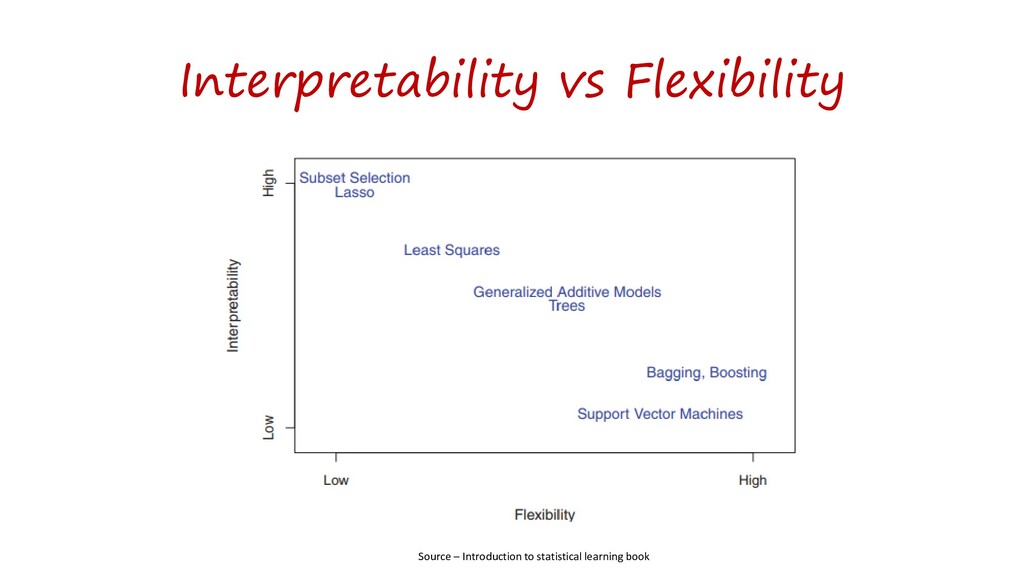{kind=link}
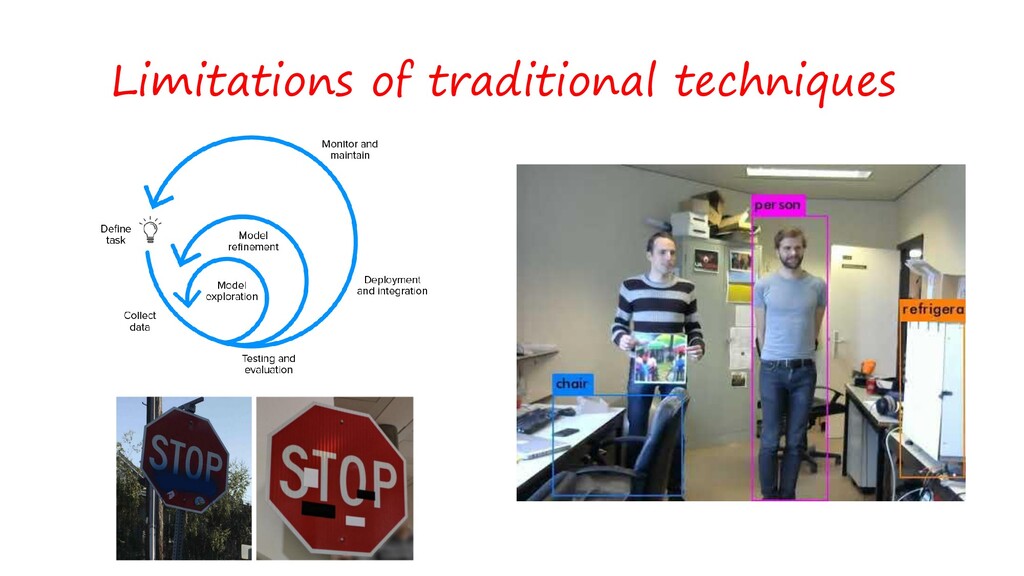{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}