Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jubatusのリアルタイム分散 レコメンデーション
Search
Yuya Unno
February 25, 2012
Technology
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Jubatusのリアルタイム分散 レコメンデーション
Yuya Unno
February 25, 2012
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
25
Other Decks in Technology
See All in Technology
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.7k
Making sense of Google’s agentic dev tools
glaforge
1
200
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
11
7.2k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3.6k
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
110
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
370
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.7k
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
140
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
410
世界、断片、モデル。そして理解
ardbeg1958
1
110
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Bash Introduction
62gerente
615
220k
Designing for Timeless Needs
cassininazir
1
320
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Building a Scalable Design System with Sketch
lauravandoore
463
34k
A Soul's Torment
seathinner
6
3.1k
A Tale of Four Properties
chriscoyier
163
24k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Chasing Engaging Ingredients in Design
codingconduct
0
230
Transcript
Jubatusのリアルタイム分散 レコメンデーション 2012/02/25@TokyoNLP 株式会社Preferred Infrastructure 海野 裕也 (@unnonouno)
⾃自⼰己紹介 l 海野 裕也 (@unnonouno) l unno/no/uno l ㈱Preferred Infrastructure 研究開発部
l 検索索・レコメンドエンジンSedueの開発など l 専⾨門 l ⾃自然⾔言語処理理 l テキストマイニング l Jubatus開発者
今⽇日のお話 l Jubatusの紹介 l 新機能、分散レコメンデーションについて
Jubatusの紹介
Big Data ! l データはこれからも増加し続ける l 多いことより増えていくということが重要 l データ量量の変化に対応できるスケーラブルなシステムが求めら れる
l データの種類は多様化 l 定形データのみならず、⾮非定形データも増加 l テキスト、⾏行行動履履歴、⾳音声、映像、信号 l ⽣生成される分野も多様化 l PC、モバイル、センサー、⾞車車、⼯工場、EC、病院 5
データを活⽤用する STEP 1. ⼤大量量のデータを捨てずに蓄積できるようになってきた STEP 2. データを分析することで、現状の把握、理理解ができる STEP 3. 状況を理理解し、現状の改善、予測ができる
l 世の中的には、蓄積から把握、理理解に向かった段階 6 6 蓄積 理理解 予測 より深い解析へ 本の購買情報 を全て記録で きるように なった! この本が実際 に売れている のは意外にも 30代のおっさ ん達だ! この⼈人は30代 男性なので、 この本を買う のではない か?
Jubatus 7 リアルタイム ストリーム 分散並列列 深い解析 l NTT PF研とPreferred Infrastructureによる共同開発
10/27よりOSSで公開 http://jubat.us/
Jubatusの技術的な特徴 l オンライン学習をさらに分散化させる l そのための通信プロトコル、計算モデル、死活監視、学 習アルゴリズムなどの⾜足回りを提供する 分散かつオンラインの機械学習基盤
分散かつオンラインの機械学習 l 処理理が速い! l 処理理の完了了を待つ時間が少ない l 5分前のTV番組の影響を反映した広告推薦ができる l 5分前の交通量量から渋滞をさけた経路路を提案できる l
⼤大規模! l 処理理が間に合わなくなったらスケールアウト l ⽇日本全国からデータが集まる状態でも動かしたい l 機械学習の深い分析! l 単純なカウント以上の精度度を 9
他の技術との⽐比較 l ⼤大規模バッチ(Hadoop & Mahout) l 並列列分散+機械学習 l リアルタイム性を確保するのは難しい l
オンライン学習ライブラリ l リアルタイム+機械学習 l 並列列分散化させるのはかなり⼤大変 l ストリーム処理理基盤 l 並列列分散+リアルタイム l 分散機械学習は難しい
例例:組み込みJubatus l ⽇日本全国に散らばったセンサーからデータ収集・分析・ 予測をしたい l ⽣生データを全部送れない l それぞれが⾃自律律的に学習してモデル情報だけ交換する
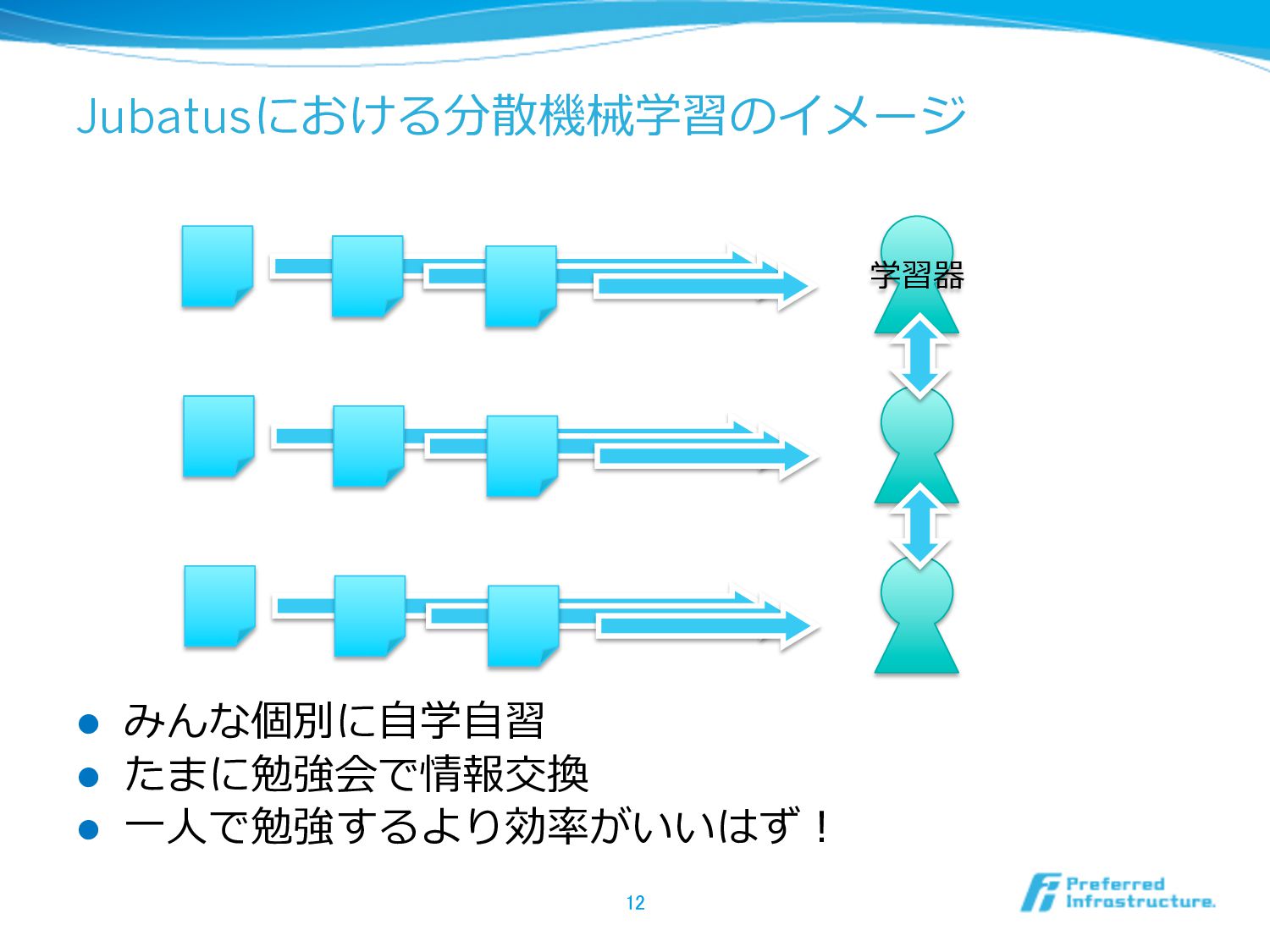
Jubatusにおける分散機械学習のイメージ l みんな個別に⾃自学⾃自習 l たまに勉強会で情報交換 l ⼀一⼈人で勉強するより効率率率がいいはず! 12 学習器
3種類の処理理に分解 l UPDATE l データを受け取ってモデルを更更新(学習)する l ANALYZE l データを受け取って解析結果を返す l
MIX l 内部モデルを混ぜ合わせる l cf. MAP / REDUCE l ver. 0.2.0でこの3操作を書くだけで、残りの ソースを⾃自動⽣生成する仕組みができた 13
3つの処理理の例例:統計処理理の場合 l 平均値を計算する⽅方法を考えよう l 内部状態は今までの合計(sum)とデータの個数(count) l UPDATE l sum +=
x l count += 1 l ANALYZE l return (sum / count) l MIX l sum = sum1 + sum2 l count = count1 + count2 14
ところで・・・ l 機械学習、⼀一般のエンジニアにまだ普及してないような 気がする・・・ l Jubatusの価値が伝わならない
世の中の機械学習ライブラリの敷居はまだ⾼高い l libsvmフォーマット l +1 1:1 3:1 8:1 l 何よこれ? ←普通の⼈人の反応
l ハイパーパラメータ l 「Cはいくつにしましたか?」 l Cってなんだよ・・・ ←普通の⼈人の反応 l 研究者向き、エンジニアが広く使えない 16
RDBやHadoopから学ぶべきこと l わからない l リレーショナル理理論論 l クエリオプティマイザ l トランザクション処理理 l
分散計算モデル l わかる l SQL l Map/Reduce l 「あとは裏裏でよろしくやってくれるんでしょ?」 17
Jubatus裏裏の⽬目標 l わからない l オンライン凸最適化 l 事後確率率率最⼤大化 l MCMC、変分ベイズ l
特徴抽出、カーネルトリック l わかる l ⾃自動分類、推薦 l 「あとはよろしくやってくれるんでしょ?」 18 全ての⼈人に機械学習を!
⽣生データを突っ込めば動くようにしたい l Jubatusの⼊入⼒力力はキー・バリュー l 最初は任意のJSONだった l twitter APIの⽣生出⼒力力を⼊入⼒力力できるようにしたかった l あとは勝⼿手に適当に処理理してくれる
l ⾔言語判定して l 各キーが何を表すのか⾃自動で推定して l 勝⼿手に適切切な特徴抽出を選ばせる l (予定、まだできない) 19
新機能:分散レコメンド
レコメンデーションとは何か? l 記事や商品のおすすめ機能 l この記事に類似した記事はこの記事です l この商品を買った⼈人はこの商品も買っています l 技術的には「近傍探索索」を使っている
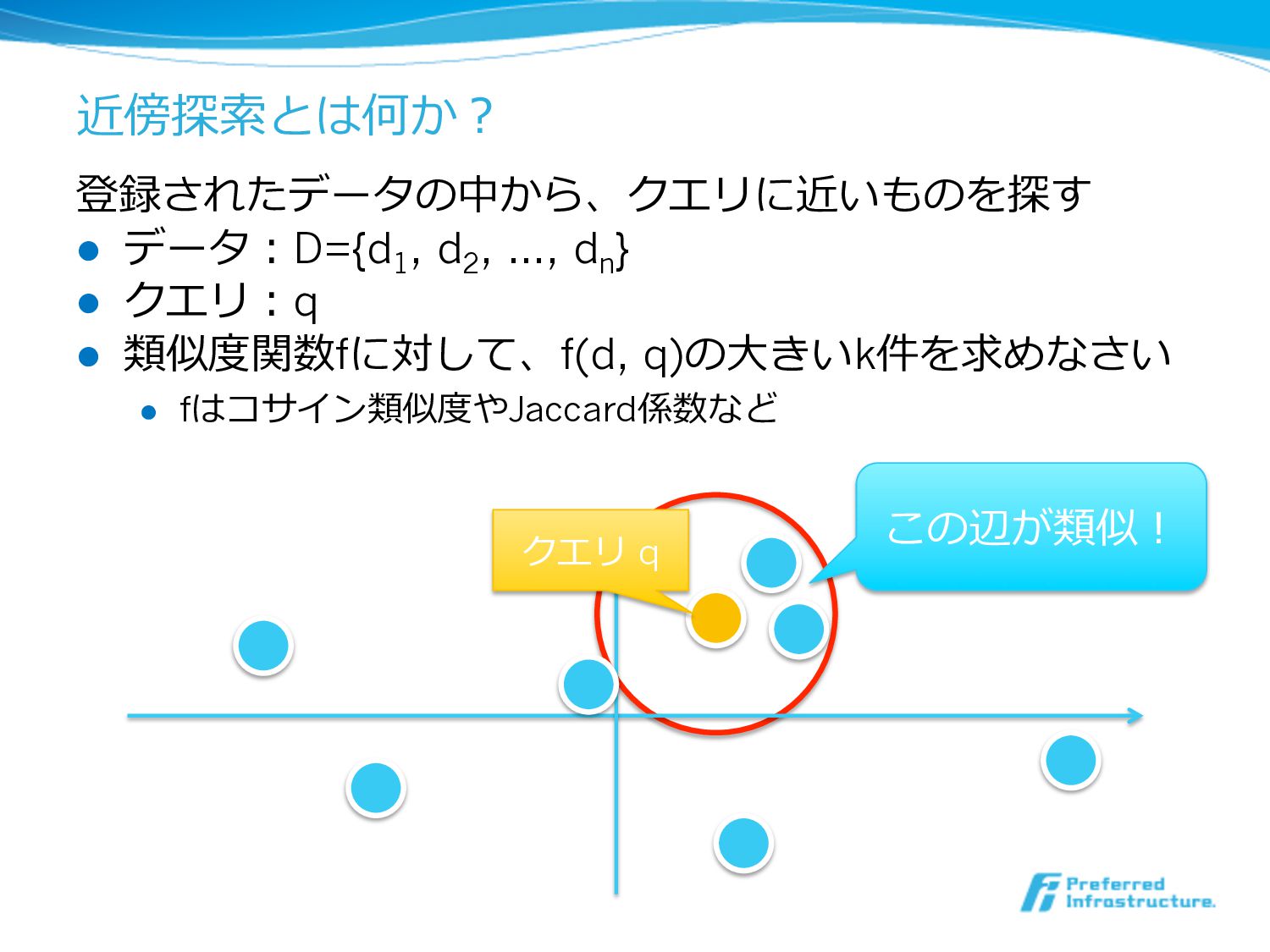
近傍探索索とは何か? 登録されたデータの中から、クエリに近いものを探す l データ:D={d 1 , d 2 , …,
d n } l クエリ:q l 類似度度関数fに対して、f(d, q)の⼤大きいk件を求めなさい l fはコサイン類似度度やJaccard係数など クエリ q この辺が類似!
近傍探索索の技術的課題 l 実⾏行行時間 l 単純な実装だと、データ点のサイズに⽐比例例した時間がかかる l 消費メモリ l すべてのオリジナルデータを保持するとデータが膨⼤大になる
レコメンダーに対する操作 l similar_row l クエリベクトルqに類似した⽂文書IDのリストを返す l 類似度度のスコアも同時に返す l update_row l
指定の⽂文書IDのベクトルを更更新する l complete_row l クエリベクトルqと類似したベクトルの重み付き線形和を返す l similar_rowを利利⽤用して実装されている
準備:よくある類似度度尺度度 l コサイン類似度度 l 2つのベクトルの余弦 l cos(θ(x, y)) = xTy
/ |x||y| l Jaccard係数 l 2つの集合の積集合と和集合のサイズの⽐比 l Jacc(X, Y) = |X∩Y|/|X∪Y| l ビットベクトル間の距離離と思うことができる
近傍探索索アルゴリズム l 転置インデックス l Locality Sensitive Hashing l minhash l
アンカーグラフ
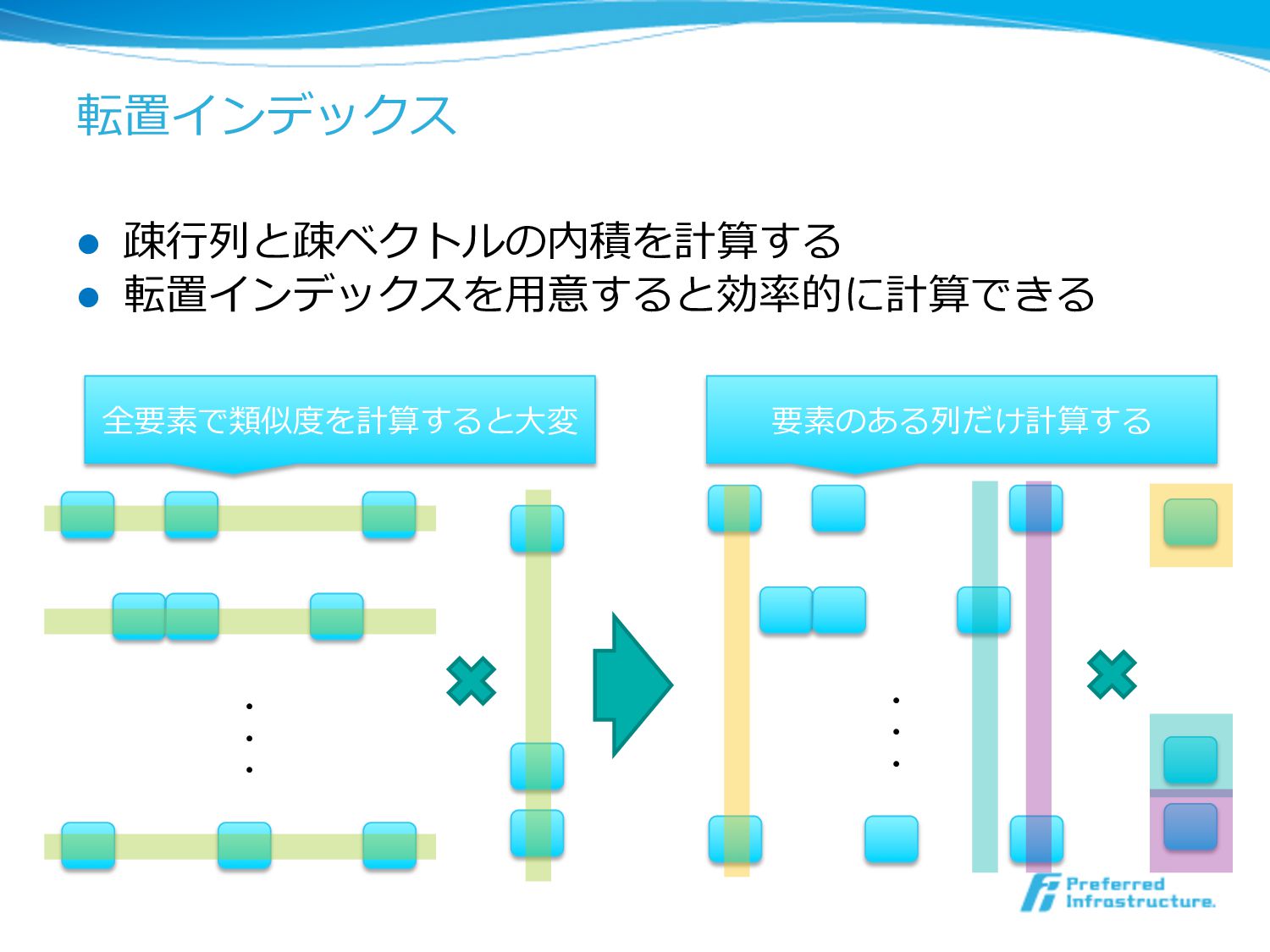
転置インデックス l 疎⾏行行列列と疎ベクトルの内積を計算する l 転置インデックスを⽤用意すると効率率率的に計算できる ・ ・ ・ ・ ・
・ 全要素で類似度度を計算すると⼤大変 要素のある列列だけ計算する
Locality Sensitive Hashing (LSH) l ランダムなベクトル r を作る l このときベクトルx,
yに対してxTrとyTrの正負が⼀一致する 確率率率はおよそ cos(θ(x, y)) l ランダムベクトルをk個に増やして正負の⼀一致率率率を数え れば、だいたいコサイン距離離になる l ベクトルxに対して、ランダムベクトル{r 1 , …, r k }との内 積の正負を計算 H(x) = {sign(xTr 1 ), …, sign(xTr k )} l signは正なら1、負なら0を返す関数 l H(x)だけ保存すればよいので1データ当たりkビット
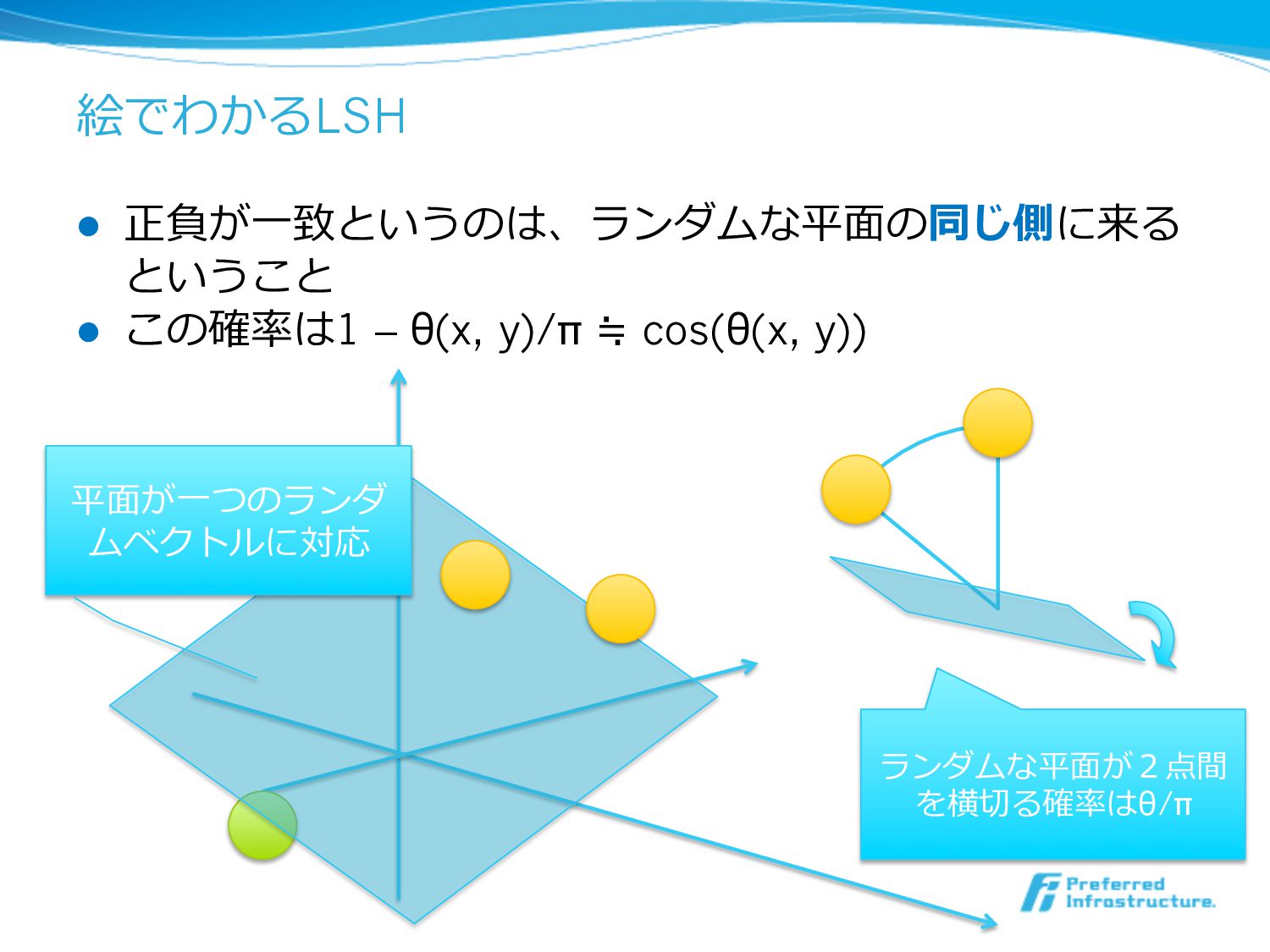
絵でわかるLSH l 正負が⼀一致というのは、ランダムな平⾯面の同じ側に来る ということ l この確率率率は1 – θ(x, y)/π ≒
cos(θ(x, y)) 平⾯面が⼀一つのランダ ムベクトルに対応 ランダムな平⾯面が2点間 を横切切る確率率率はθ/π
Jaccard係数 l 集合の類似度度を図る関数 l 値を0, 1しか取らないベクトルだと思えばOK l Jacc(X, Y) =
|X∩Y| / |X∪Y| 例例 l X = {1, 2, 4, 6, 7} l Y = {1, 3, 5, 6} l X∩Y = {1, 6} l X∪Y = {1, 2, 3, 4, 5, 6, 7} l Jacc(X, Y) = 2/7
minhash l X = { x 1 , x 2
, …, x n } l Xは集合なので、感覚的には⾮非ゼロ要素のインデックスのこと l H(X) = { h(x 1 ), …, h(x n ) } l m(X) = argmin(H(X)) l m(X) = m(Y)となる確率率率はJacc(X, Y)に⼀一致 l ハッシュ関数を複数⽤用意したとき、m(X)=m(Y)となる回数を数 えるとJacc(X, Y)に収束する l m(X)の最下位ビットだけ保持すると、衝突の危険が⾼高 まる代わりにハッシュ関数を増やせる [Li+10a, Li+10b]
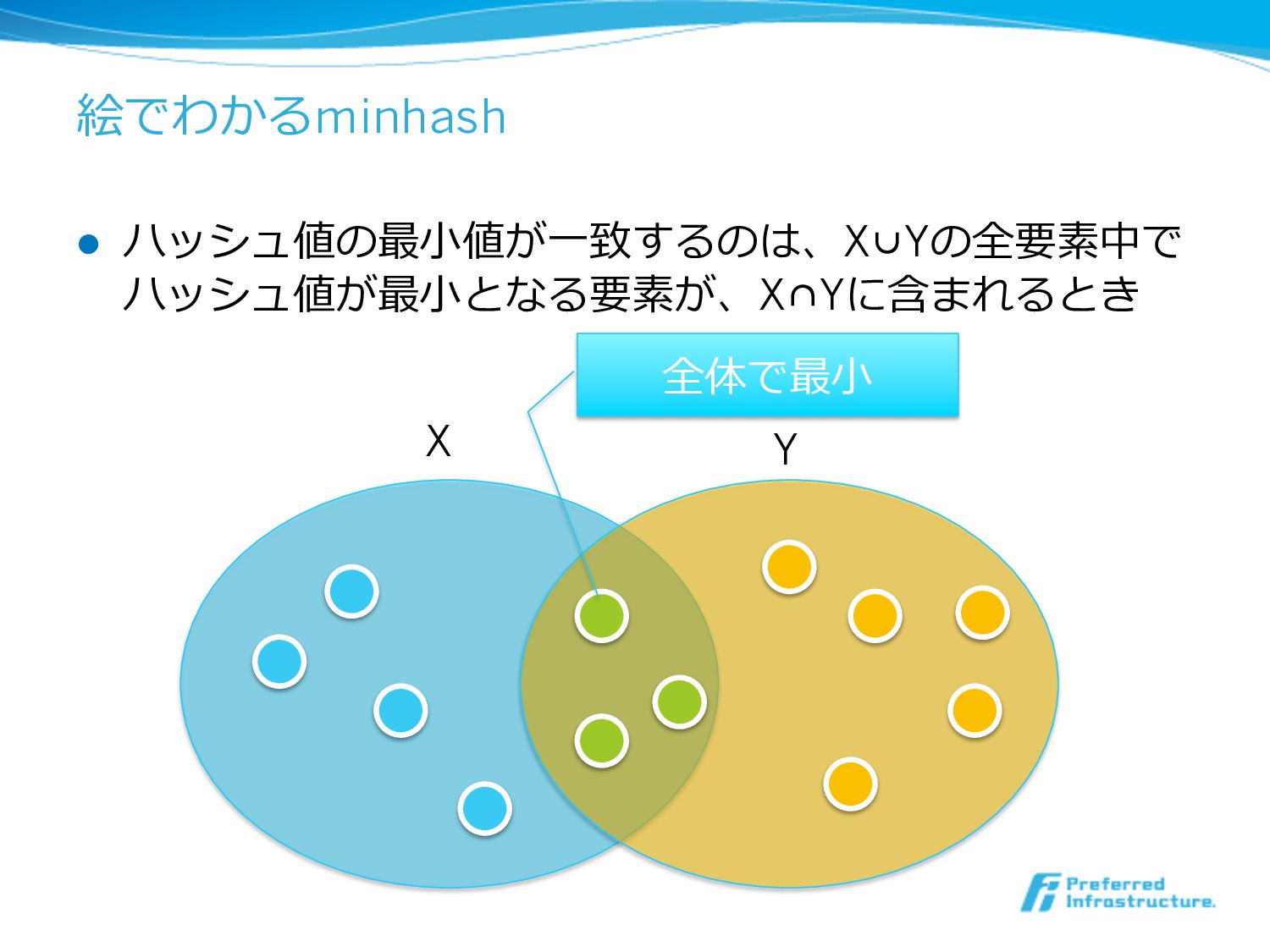
絵でわかるminhash l ハッシュ値の最⼩小値が⼀一致するのは、X∪Yの全要素中で ハッシュ値が最⼩小となる要素が、X∩Yに含まれるとき X Y 全体で最⼩小
重み付きJaccard係数 l 各集合の要素のidfのような重みをつける l wJacc(X, Y) = Σ i∈X∩Y w
i / Σ i∈X∪Y w i l w i が常に1なら先と同じ 例例 l X = {1, 2, 4, 6, 7} l Y = {1, 3, 5, 6} l w = (2, 3, 1, 4, 5, 2, 3) l X∩Y = {1, 6} l X∪Y = {1, 2, 3, 4, 5, 6, 7} l wJacc(X, Y) = (2+2)/(2+3+1+4+5+2+3)=4/20
重み付きJaccard版minhash [Chum+08] l X = { x 1 , x
2 , …, x n } l H(X) = {h(x 1 )/w 1 , …, h(x n )/w n } l 論論⽂文中では-log(h(x))としている l 差分はw i で割っているところ l 感覚的にはw i が⼤大きければ、ハッシュ値が⼩小さくなりやすいの で、選ばれる確率率率が⼤大きくなる l m(X) = argmin(H(X)) l m(X) = m(Y)となる確率率率はwJacc(X, Y)に⼀一致
アンカーグラフ [Liu+11] l 予めアンカーを定めておく l 各データは近いアンカーだけ覚える l アンカーはハブ空港のようなもの l まず類似アンカーを探して、その周辺だけ探せばOK
アンカー
それぞれのアルゴリズムをオンライン化・・・でき るか? Jubatusのポイントはオンライン学習! 近傍探索索のオンライン化とは? l データ集合Dに新しいデータdを追加・変更更できる l 追加したら、直ちにL(d, q)の⼩小さいdを求められる
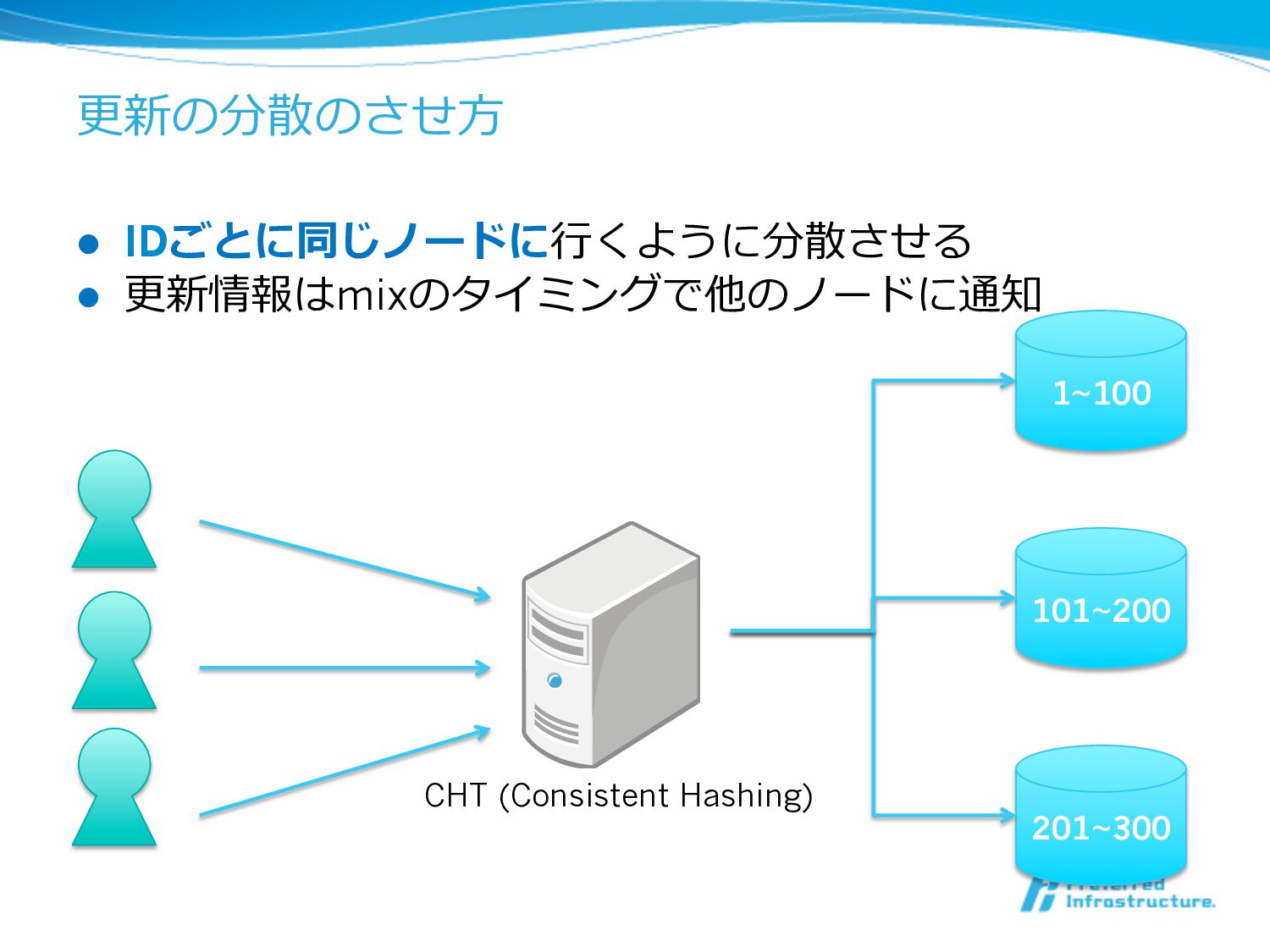
更更新の分散のさせ⽅方 l IDごとに同じノードに⾏行行くように分散させる l 更更新情報はmixのタイミングで他のノードに通知 1~100 101~200 201~300 CHT (Consistent
Hashing)
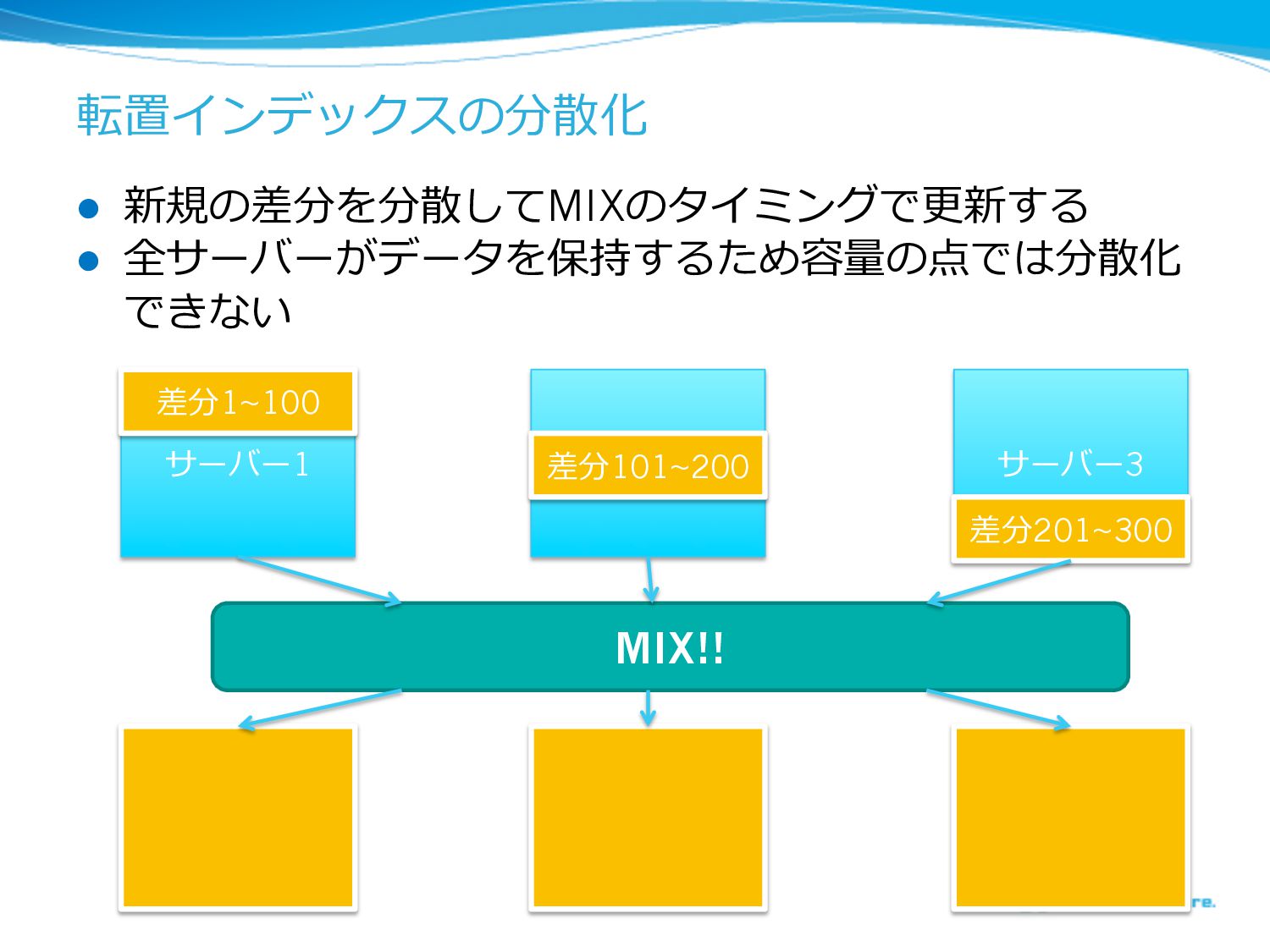
転置インデックスの分散化 l 新規の差分を分散してMIXのタイミングで更更新する l 全サーバーがデータを保持するため容量量の点では分散化 できない サーバー1 サバー2 サーバー3 差分1~100
差分101~200 差分201~300 MIX!!
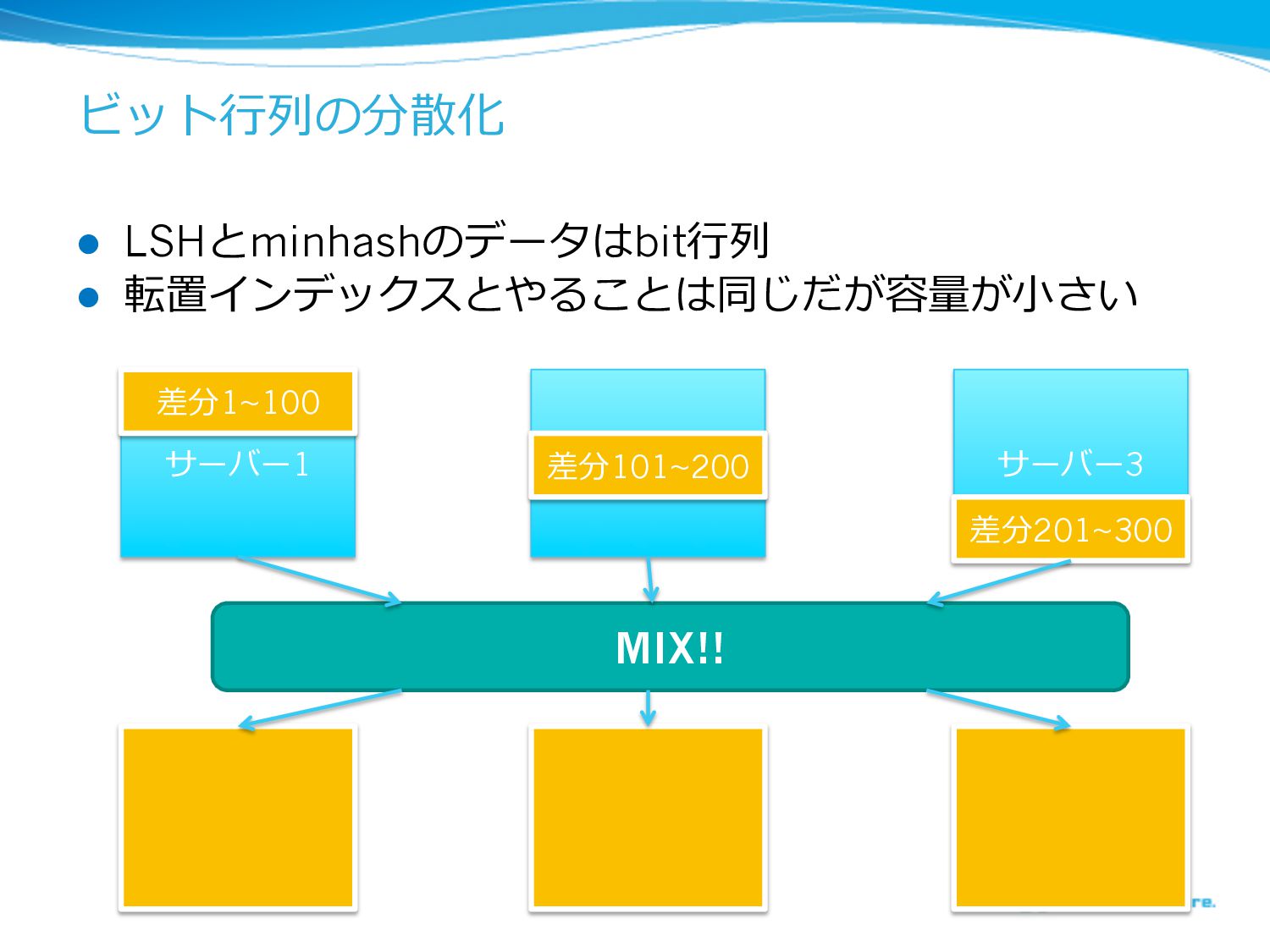
ビット⾏行行列列の分散化 l LSHとminhashのデータはbit⾏行行列列 l 転置インデックスとやることは同じだが容量量が⼩小さい サーバー1 サバー2 サーバー3 差分1~100 差分101~200
差分201~300 MIX!!
アンカーグラフの分散化? l 類似アンカーの情報しか残ってないため、データの⼀一部 を更更新するのが困難 l オリジナルデータを持っておけばよい? l 実装・デバッグはかなり激しい l うまく⾏行行っているのかどうかわかりにくい
現在の実装 l 転置インデックスとLSHが実装されている l minhashとアンカーグラフは⼤大⼈人の事情で有りませ ん・・・
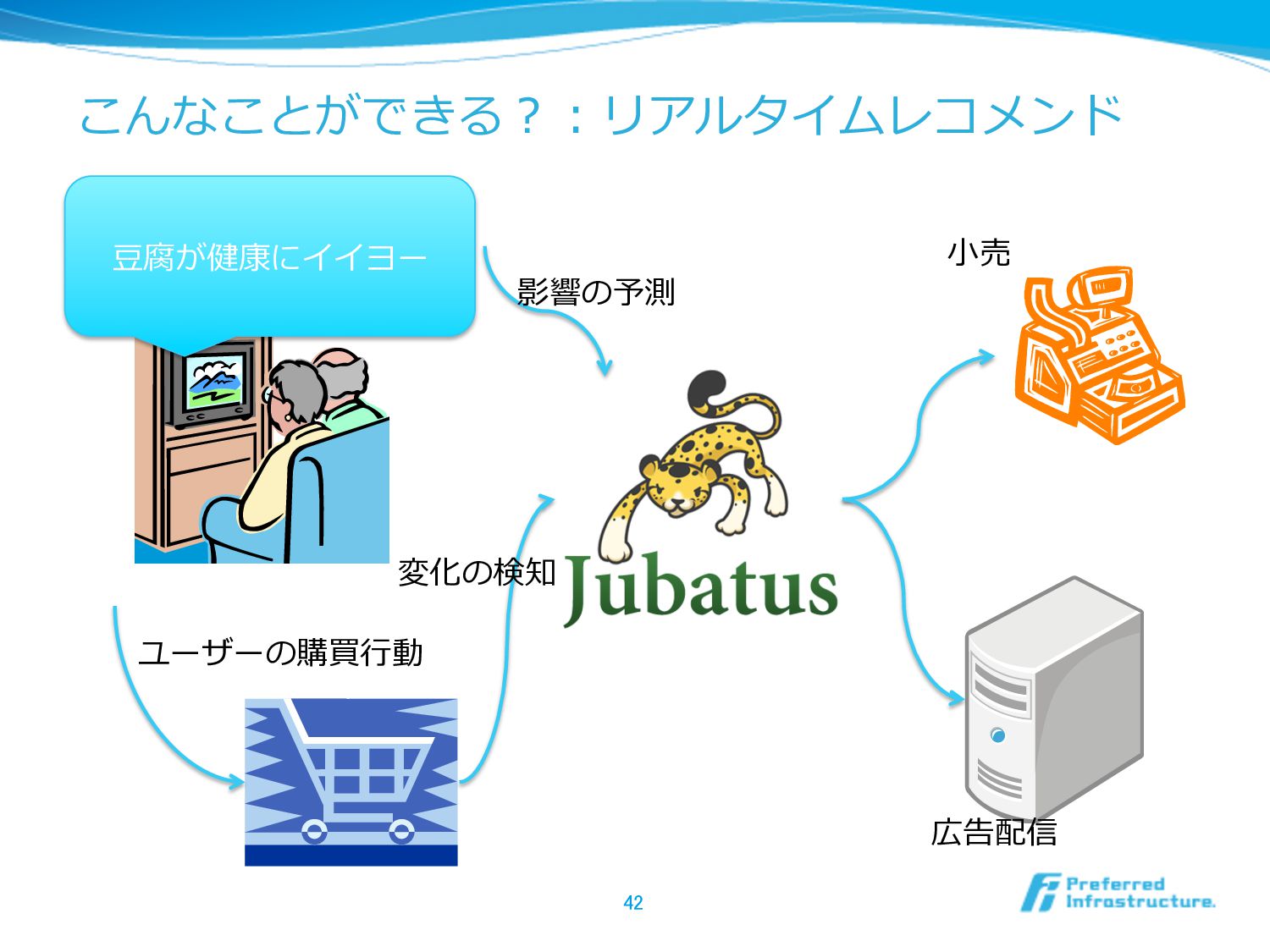
こんなことができる?:リアルタイムレコメンド 42 ⾖豆腐が健康にイイヨー ユーザーの購買⾏行行動 変化の検知 ⼩小売 広告配信 影響の予測
まとめ l Jubatusの3つの軸 l リアルタイム l 分散 l 深い解析 l
MIX操作による緩い同期計算モデル l レコメンドの4⼿手法 l 転置インデックス l Locality Sensitive Hashing l minhash l アンカーグラフ l Jubatusでは前者2つを実装
参考⽂文献 l [Chum+08] Ondrej Chum, James Philbin, Andrew Zisserman. Near
Duplicate Image Detection: min-Hash and tf-idf Weighting. BMVC 2008. l [Li+10a] Ping Li, Arnd Christian Konig. b-Bit Minwise Hashing. WWW 2008. l [Li+10b] Ping Li, Arnd Christian Konig, Wenhao Gui. b-Bit Minwise Hashing for Estimating Three-Way Similarities. NIPS 2008. l [Liu+11] Wei Liu, Jun Wang, Sanjiv Kumar, Shin-Fu Chang. Hashing with Graphs. ICML 2011.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![重み付きJaccard版minhash [Chum+08] l X = { x 1 , x](https://files.speakerdeck.com/presentations/c825767297c544749271e09629a1898f/slide_33.jpg){kind=link}
![アンカーグラフ [Liu+11] l 予めアンカーを定めておく l 各データは近いアンカーだけ覚える l アンカーはハブ空港のようなもの l まず類似アンカーを探して、その周辺だけ探せばOK](https://files.speakerdeck.com/presentations/c825767297c544749271e09629a1898f/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考⽂文献 l [Chum+08] Ondrej Chum, James Philbin, Andrew Zisserman. Near](https://files.speakerdeck.com/presentations/c825767297c544749271e09629a1898f/slide_43.jpg){kind=link}