Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層学習フレームワーク Chainerとその進化
Search
Yuya Unno
April 06, 2017
Technology
31
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
深層学習フレームワーク Chainerとその進化
Yuya Unno
April 06, 2017
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
30
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
25
Chainer, Cupy⼊⾨ @Chainer meetup #3
unnonouno
0
34
Other Decks in Technology
See All in Technology
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
170
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
220
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
150
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
240
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
120
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
410
Network Firewallやっていき!
news_it_enj
0
170
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
280
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
12
8.7k
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
4k
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
1
420
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
Featured
See All Featured
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Facilitating Awesome Meetings
lara
57
7k
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Speed Design
sergeychernyshev
33
1.9k
The browser strikes back
jonoalderson
0
1.4k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
280
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
220
Optimizing for Happiness
mojombo
378
71k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Transcript
深層学習フレームワーク Chainerとその進化 Preferred Networks 海野 裕也
http://chainer.org/
Chainerの⽬標 l ⾼い⾃由度で直感的に記述できる l ⼗分に⾼速に実⾏できる l 容易にデバッグできる 社内の深層学習の研究開発を加速させる 世の中
ニューラルネットの学習⽅法 1. ⽬的関数の設計 l RNNなどを利⽤して⾃分で設計 2. 勾配の計算 l ⾃動で計算できる(これから説明) 3.
最⼩化のための反復計算 l ライブラリが提供してくれる 4 1さえ設計すれば残りは ほぼ⾃動化されている
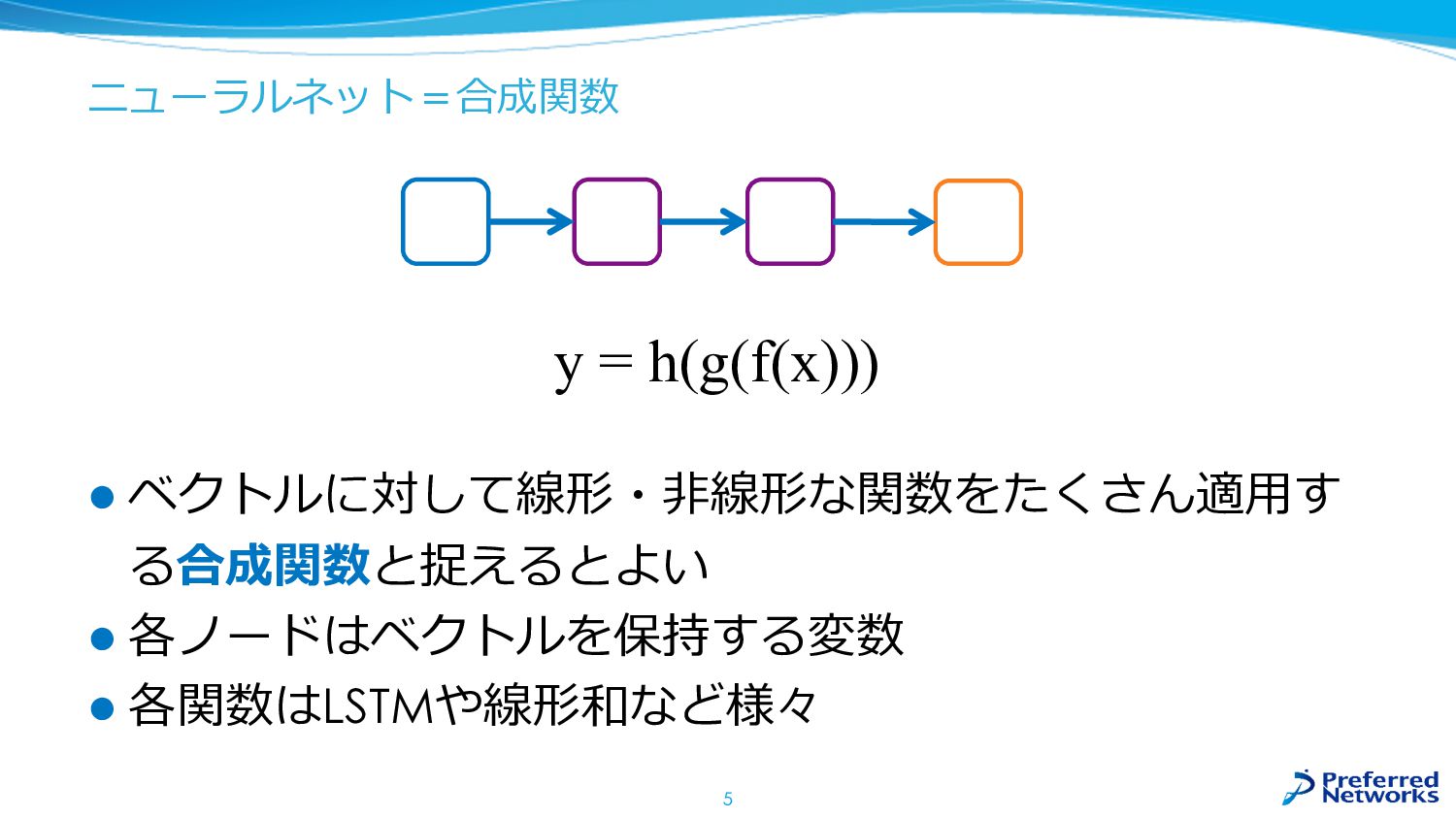
ニューラルネット=合成関数 l ベクトルに対して線形・⾮線形な関数をたくさん適⽤す る合成関数と捉えるとよい l 各ノードはベクトルを保持する変数 l 各関数はLSTMや線形和など様々 5 y
= h(g(f(x)))
計算グラフの例 z = x ** 2 + 2 * x
* y + y 6 x y _ ** 2 2 * _ _ * _ _ + _ z _ + _
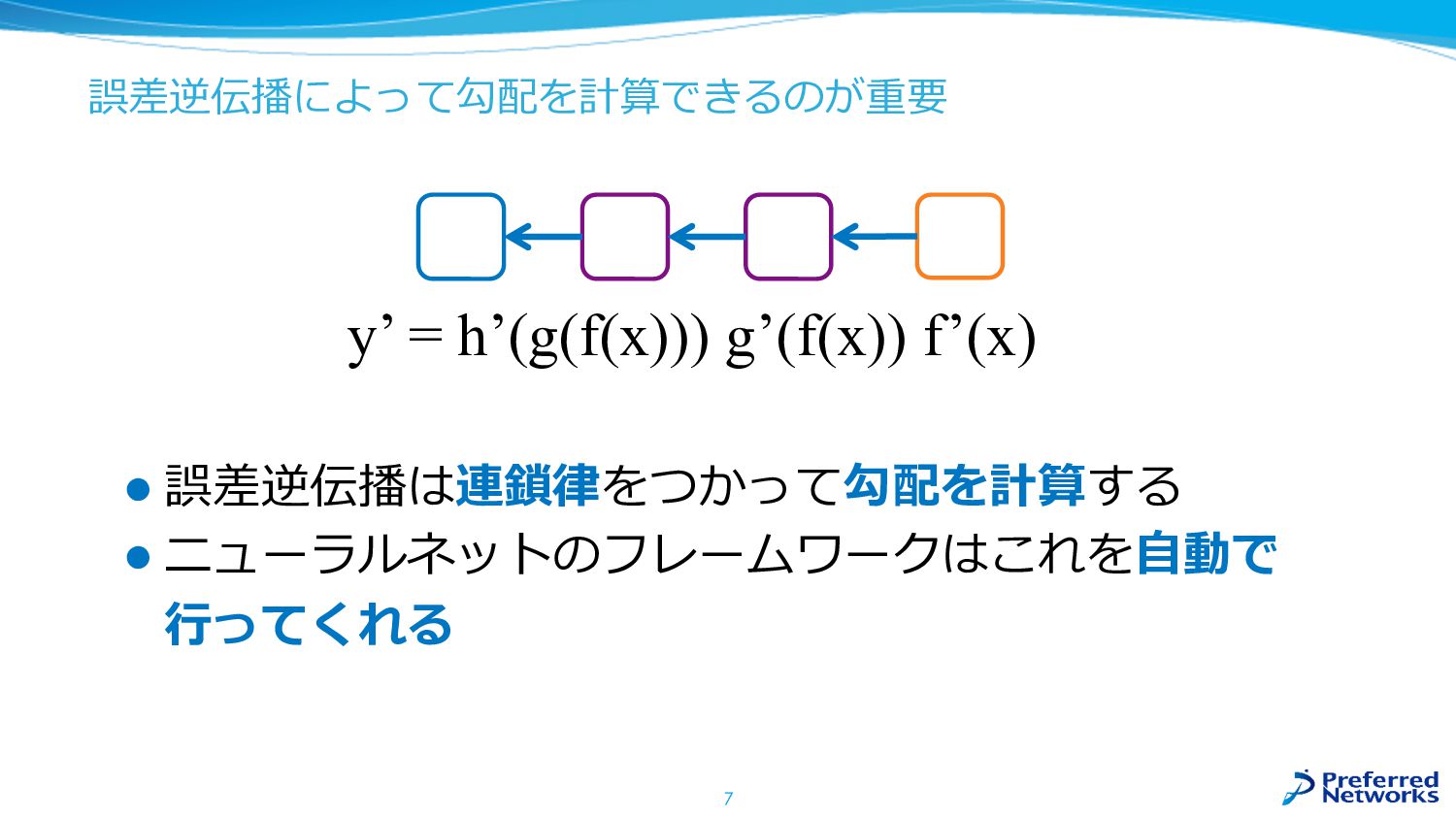
誤差逆伝播によって勾配を計算できるのが重要 l 誤差逆伝播は連鎖律をつかって勾配を計算する l ニューラルネットのフレームワークはこれを⾃動で ⾏ってくれる 7 y’ = h’(g(f(x)))
g’(f(x)) f’(x)
計算グラフの作成戦略 define-and-runとdefine-by-run l define-and-run(静的グラフ) l まず計算グラフを構築し、構築した計算グラフにデータを流すと いう、2ステップから成る l Caffe, theano,
TensorFlowなど l define-by-run(動的グラフ) l 通常の⾏列演算をする感覚で順伝播処理をすると同時に、逆伝播 ⽤の計算グラフが構築される l Chainer, DyNet, PyTorchなど 8
擬似コードで⽐較する define-and-run # 構築 x = Variable(‘x’) y = Variable(‘y’)
z = x + 2 * y # 評価 for xi, yi in data: eval(z, (xi, yi)) define-by-run # 構築と評価が同時 for xi, yi in data: x = Variable(xi) y = Variable(yi) z = x + 2 * y 9 データを⾒ながら 違う処理をしてもよい
なぜ、⾃由度の⾼いフレームワークが必要か? 深層学習とは階層の深いだけではなくなってきている l 深いボルツマンマシン l 深い畳込みニューラルネットワーク l 再帰ニューラルネットワーク l 双⽅向再帰ネットワーク
l 注意機構 ⼿法⾃体がどんどん複雑化して、古いフレームワークは新⼿法を扱い づらくなっていく 10
研究開発・実⽤化を加速する様々なプロジェクトを紹介 l ChainerMN l 複数ノード上で分散計算するChainer l ChainerRL l Chainerを利⽤した深層強化学習ライブラリ l
Intel版Chainer l Intel CPU上で最適化されたChainer
l 2015/04 Chainer開発開始 l 2015/06 Chainer 1.0.0公開 l 2015/11 TensorFlow公開
l 2017/01 ChainerMNの実験結果公表 l 2017/01 PaintsChainer公開 l 2017/02 ChainerRL公開 l 2017/03 Intel版Chainerのリポジトリが公開 l 2017/05 Chainer 2.0.0公開予定
ChainerMN
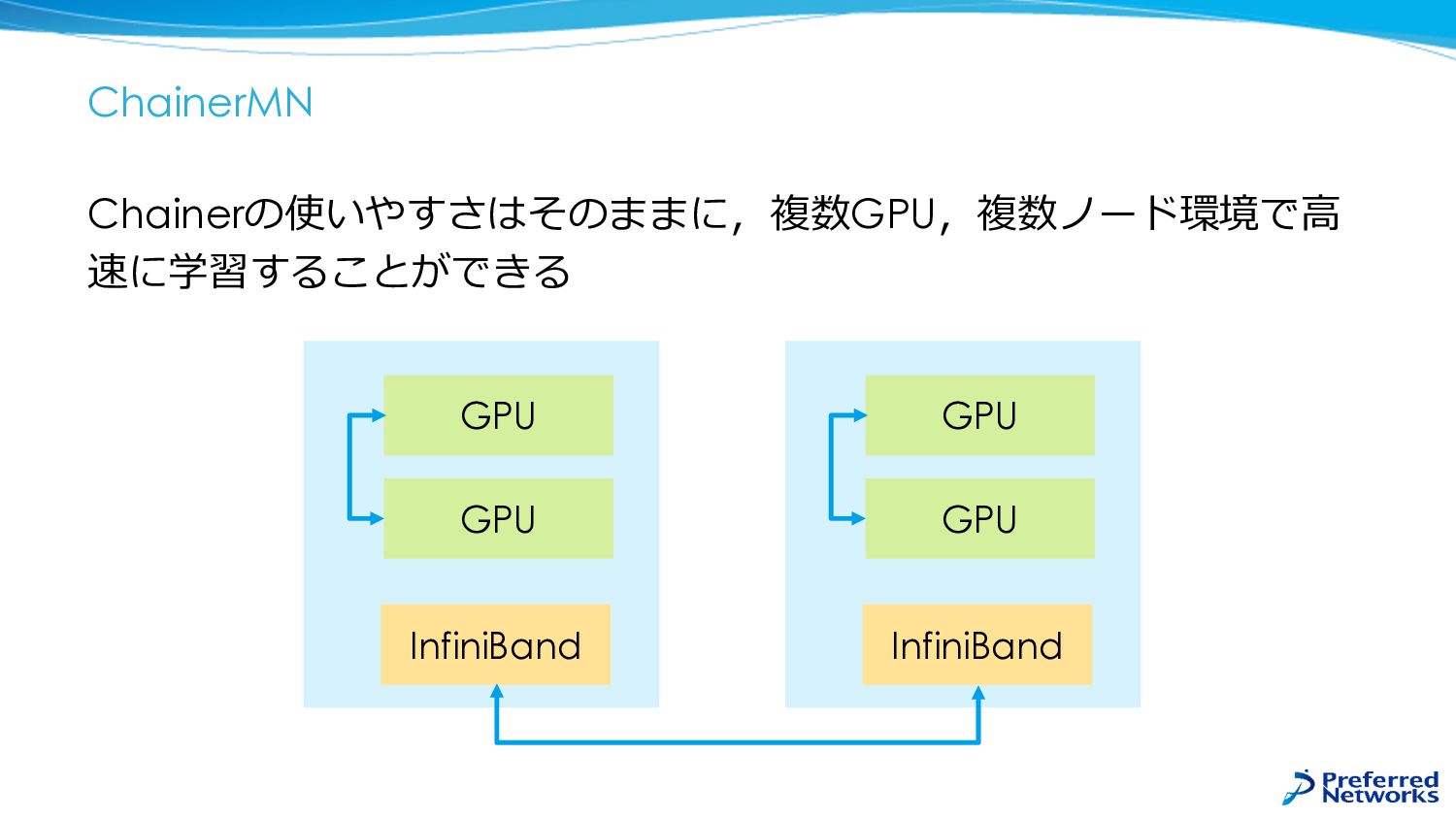
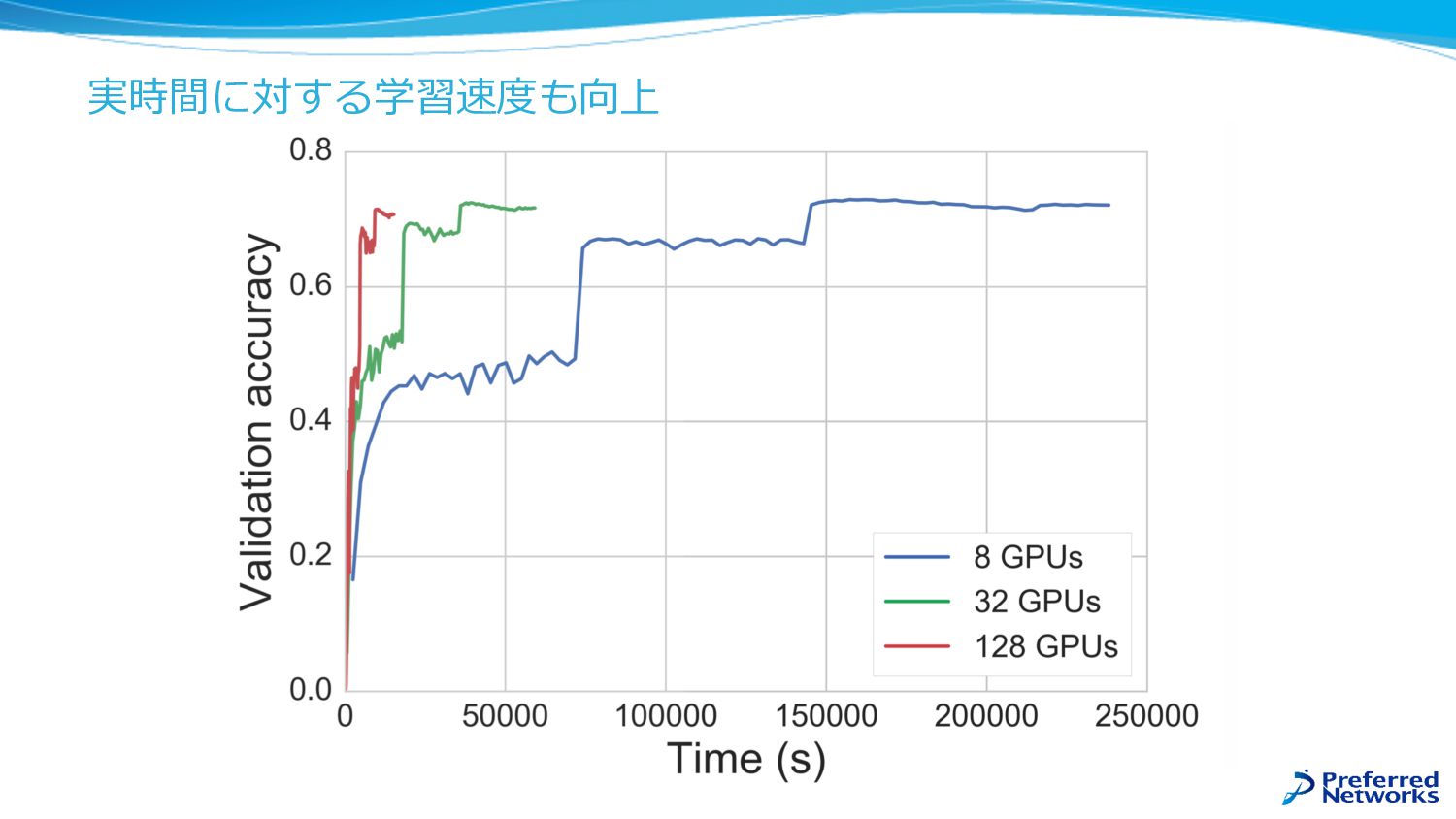
ChainerMN Chainerの使いやすさはそのままに,複数GPU,複数ノード環境で⾼ 速に学習することができる GPU GPU InfiniBand GPU GPU InfiniBand
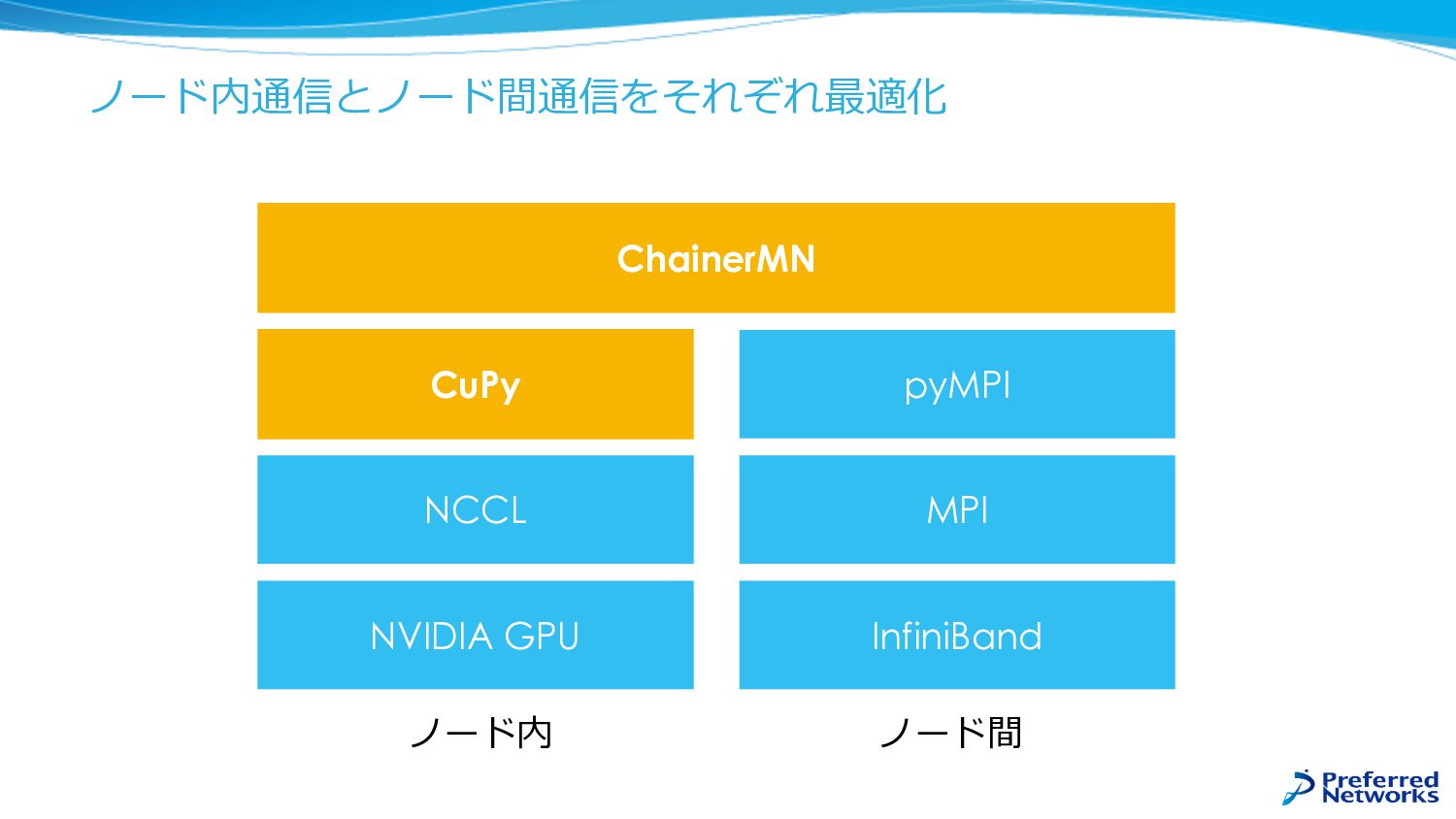
ノード内通信とノード間通信をそれぞれ最適化 InfiniBand MPI ChainerMN pyMPI NCCL NVIDIA GPU ノード内 ノード間
CuPy
既存のコードを多少書き換えるだけで利⽤できる optimizer = chainer.optimizers.MomentumSGD() optimizer = chainermn.DistributedOptimizer( chainer.optimizers.MomentumSGD())
GPUの数にほぼ⽐例した性能向上
実時間に対する学習速度も向上
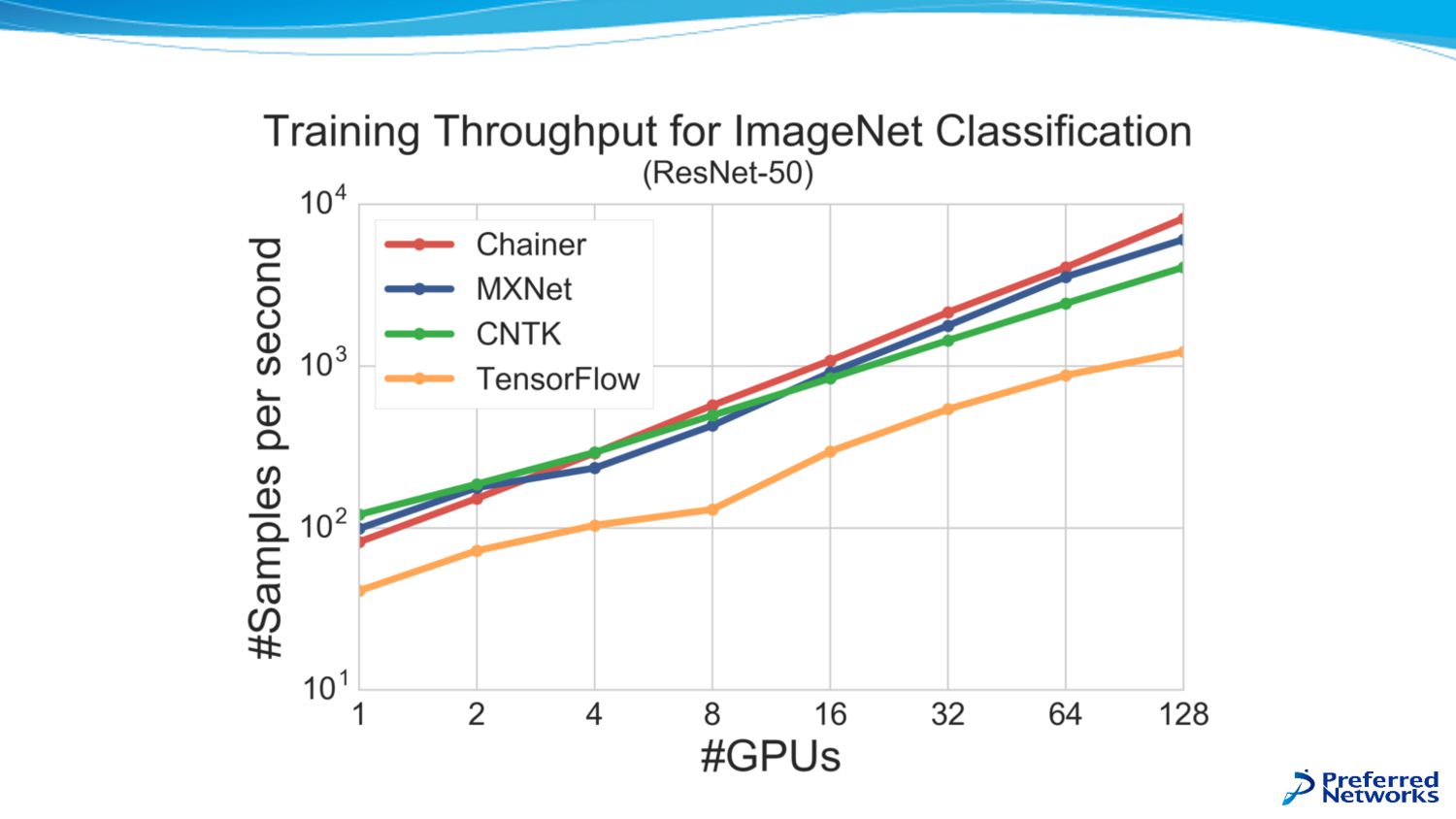
他のフレームワークに⽐べても⾼速
None
ChainerRL
ChainerRL Chainerを使った深層強化学習フレームワーク https://github.com/pfnet/chainerrl
強化学習は試⾏錯誤で学習する⼿法 どうすればいいか(教師データ)を教えるのではなく,試 ⾏錯誤して正しい⽅法を探す学習⽅法 教師あり学習:いつペダルを踏むかを教える 強化学習:倒れずに前に進む⽅法を試⾏錯誤
24
深層学習が簡単になったため,⼿法が複雑化 Chainer 全部⾃作 深層学習 Chainer 深層学習 が複雑化 Chainer ChainerRL 深層学習
Intel版Chainer
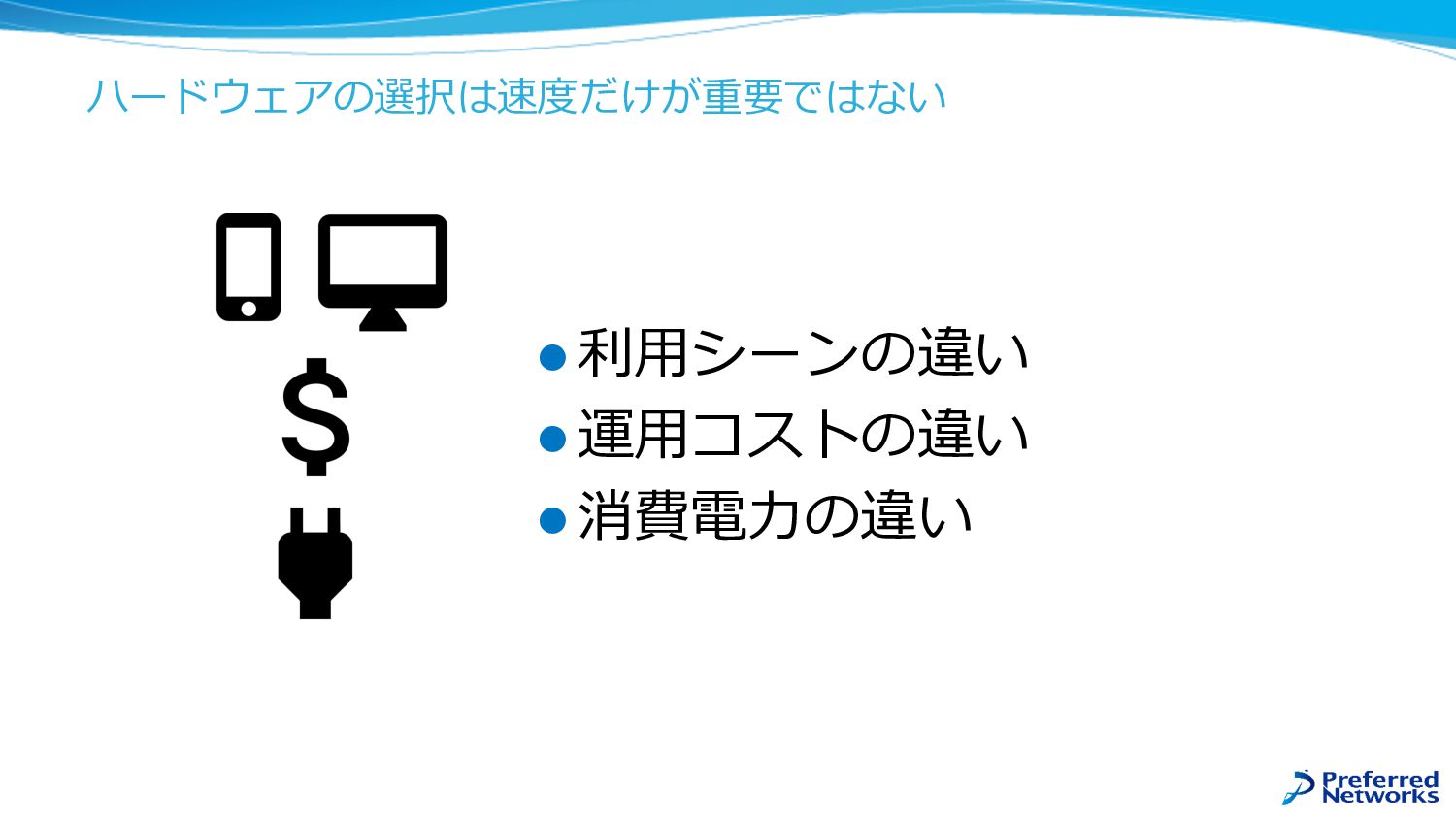
ハードウェアの選択は速度だけが重要ではない l 利⽤シーンの違い l 運⽤コストの違い l 消費電⼒の違い
Intel版Chainer Github上でIntel CPU向けに最適化されたChainerの開発 が開始 https://github.com/intel/chainer
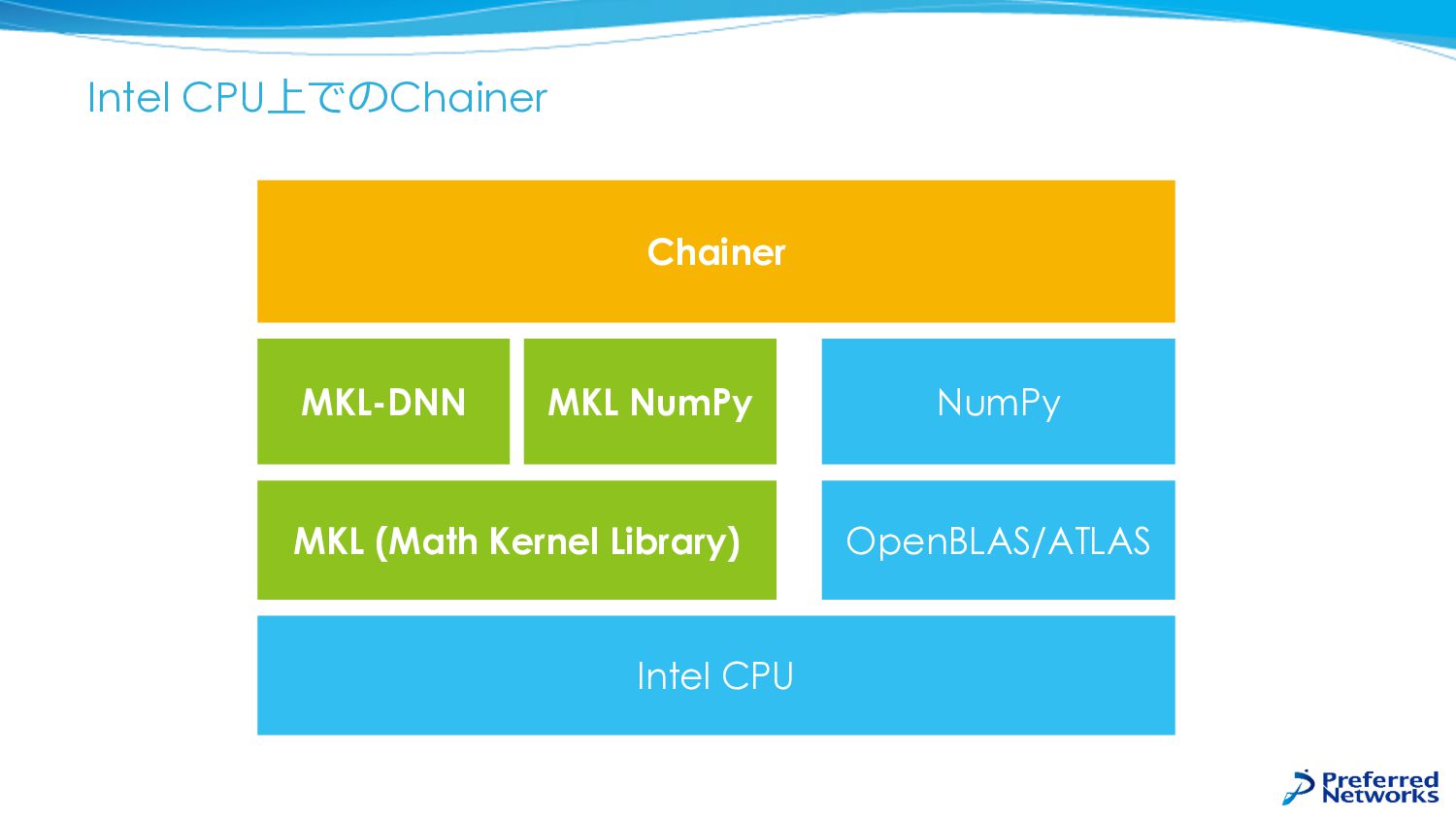
Intel CPU上でのChainer Chainer MKL-DNN MKL (Math Kernel Library) Intel CPU
MKL NumPy OpenBLAS/ATLAS NumPy
MKL-DNNはCPU向けの最適化された深層学習ライブラリ l MKL (Intel Math Kernel Library) l Intel製の数値計算ライブラリ l
NumPyのバックエンドとして利⽤可能 l MKL-DNN l Intel CPU向けに最適化された深層学習ライブラリ l https://github.com/01org/mkl-dnn
まとめ l Chainerは⾃由度の⾼い深層学習フレームワーク l Chainerの周辺で様々なプロジェクトが進⾏中 l ChainerMN:⼤規模分散学習 l ChainerRL:深層強化学習ライブラリ l
Intel版Chainer:CPU向けの最適化 l 深層学習のみならず,HPCや⾼度な機械学習,コードの最適化な ど,様々な分野の専⾨家を求めています
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}