Databases, Vol. 1, No. 3 (2007) pp. 261-377, 2008. l J. Lafferty, A. McCallum, F . Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. ICML2001. l 岡崎直観, 辻井潤⼀一. ⾼高速な類似⽂文字列列検索索アルゴリズム. 情報処理理学会創⽴立立50周年年記念念全国⼤大会, 1C-1, 2010. l V. Pervouchine, H. Li, B. Lin. Transliteration Alignment. ACL&IJCNLP 2009, pp. 136-144, 2009. 51
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
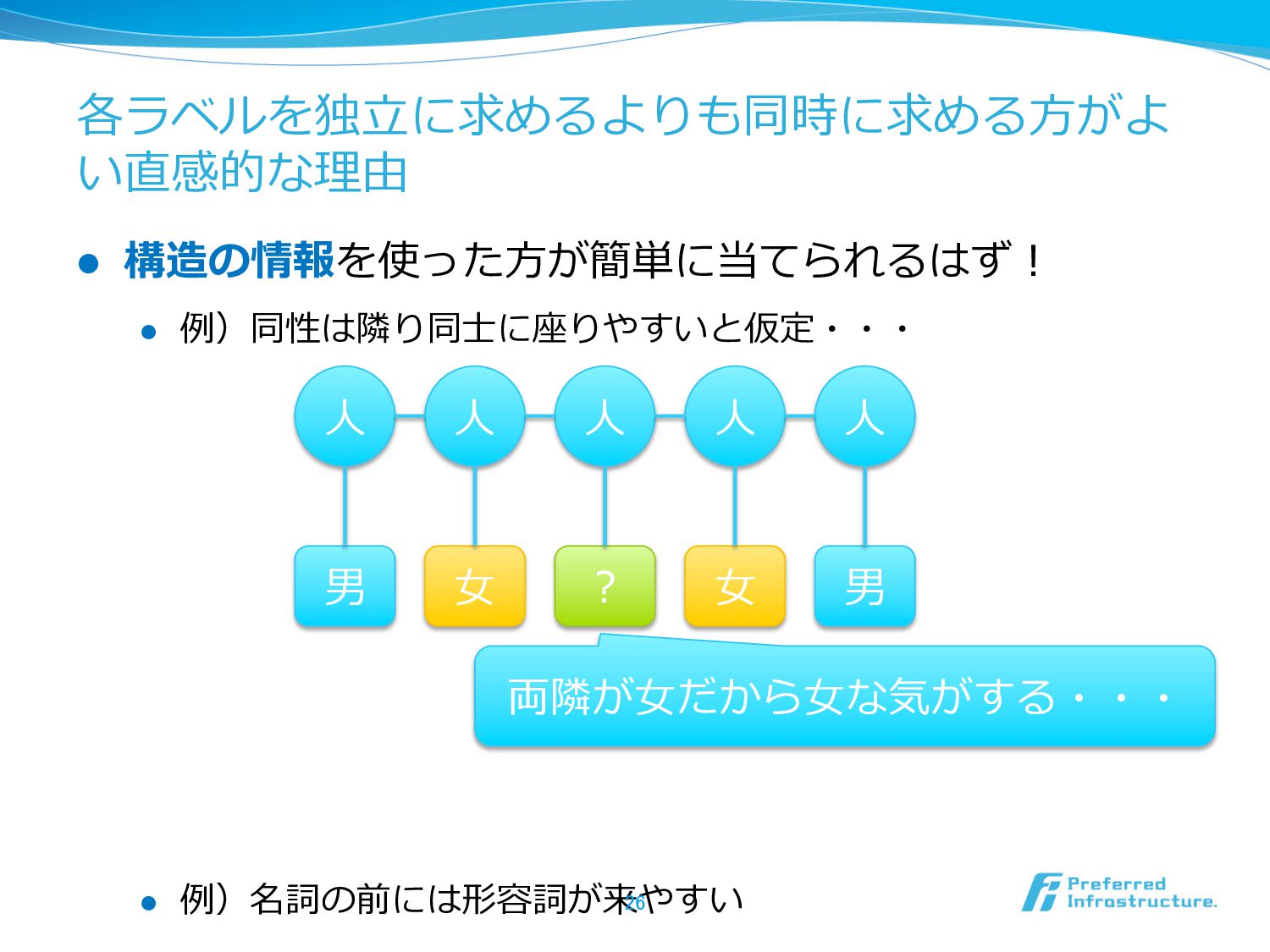{kind=link}
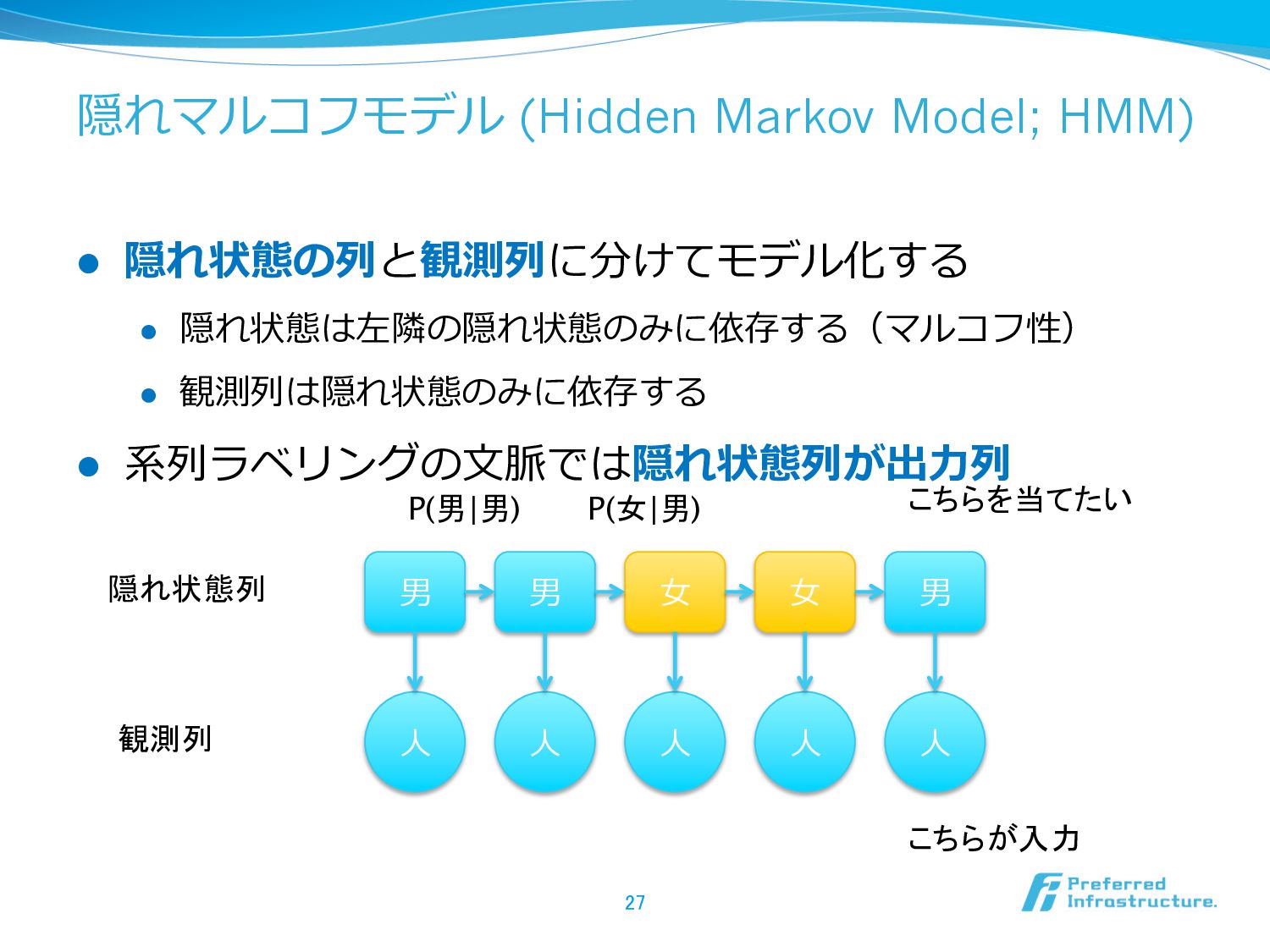{kind=link}
![条件付き確率率率場 (Conditional Random Field; CRF) [Lafferty2001] l ラベルの同時確率率率を直接モデル化する l P(y|x)](https://files.speakerdeck.com/presentations/b09ffe06f0014adbb785326b4e7eaaac/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![SimString [岡崎 10] l 閾値 t 以上の類似疎ベクトルを⾼高速に探索索するアルゴリズム l 疎ベクトルの類似度度が t](https://files.speakerdeck.com/presentations/b09ffe06f0014adbb785326b4e7eaaac/slide_31.jpg){kind=link}
{kind=link}
![Transliteration Alignment [Pervouchine09] l 翻字は基本的に同じ⾳音の変換 l ⽂文字と⽂文字の対応をとるアライメント問題とみなせる l アライメント:統計的機械翻訳などで利利⽤用される、単語間の対 応関係](https://files.speakerdeck.com/presentations/b09ffe06f0014adbb785326b4e7eaaac/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関係レベルになると構⽂文情報をうまく使いたい l 関係代名詞などの複雑な構⽂文になると、関係のあるエン ティティー間に別の句句が⼊入り込む l ⽂文の構造を利利⽤用して関係を判断する必要が出てくる 43 [Sarawagi08]](https://files.speakerdeck.com/presentations/b09ffe06f0014adbb785326b4e7eaaac/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
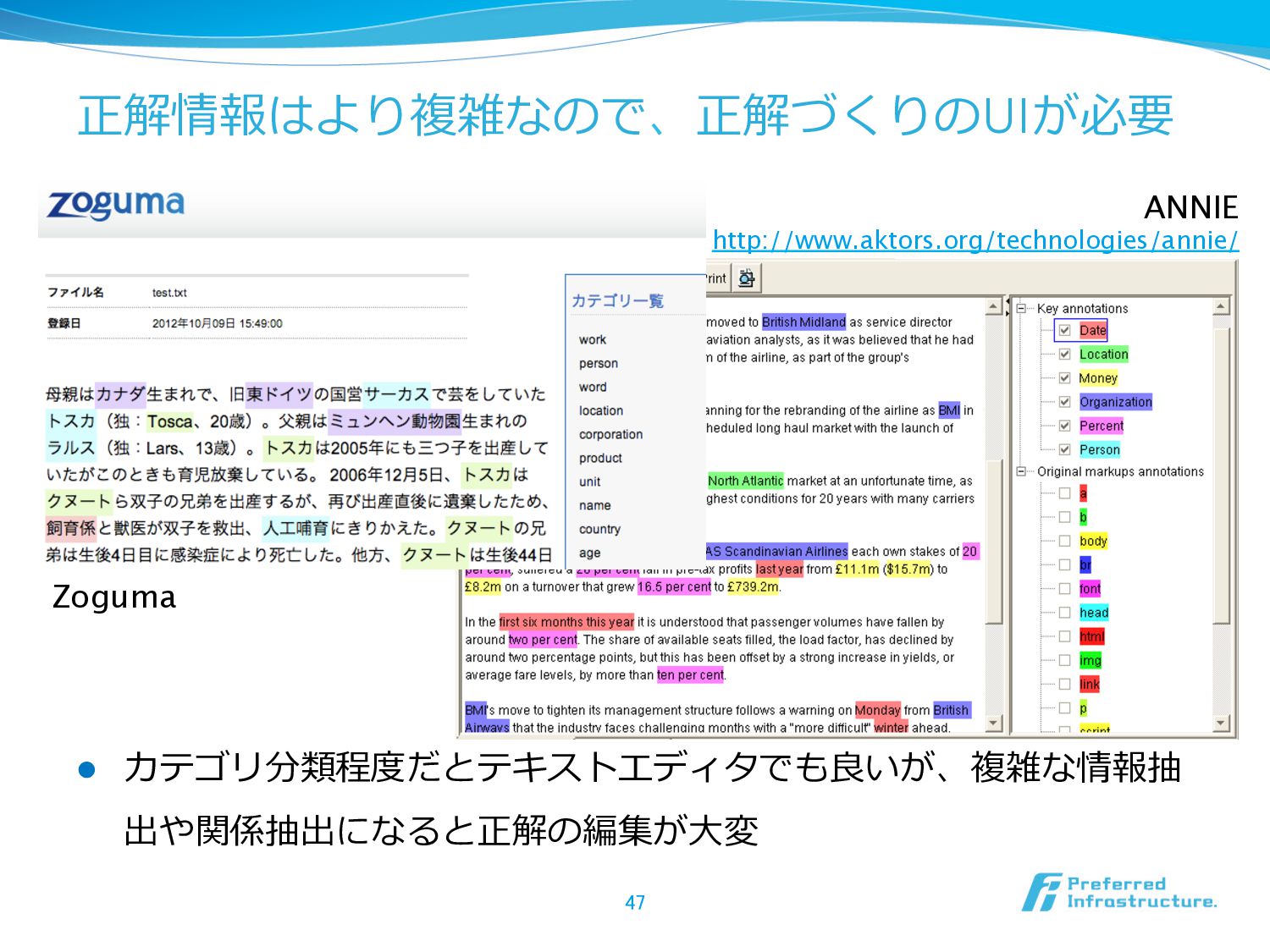{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}