with basic authentication, # these settings provide the username and password that the # Kibana server uses to perform maintenance on the Kibana # index at startup. Your Kibana users still need to # authenticate with Elasticsearch, which # is proxied through the Kibana server. elasticsearch.username: "elastic" elasticsearch.password: "changeme"
has changed and # reload the pipeline # This can also be triggered manually through the SIGHUP signal # config.reload.automatic: true xpack.monitoring.elasticsearch.url: "http://localhost:9200" xpack.monitoring.elasticsearch.username: elastic xpack.monitoring.elasticsearch.password: changeme
as fast as it comes in • Unless dropped or eliminated by conditional, each event will exit each output. • If a filter or output plugin is slow or blocked, the entire pipeline will back up • Filters will slow the pipeline–Some a little, some a lot. • Logstash can only ship data as fast as the slowest output. • No, really. Not kidding.
in logstash.yml • Each with auto-reload • Pipeline viewer (may be only in X-Pack at release) • See throughput not just as a sum of input/output, but at each plugin and conditional.
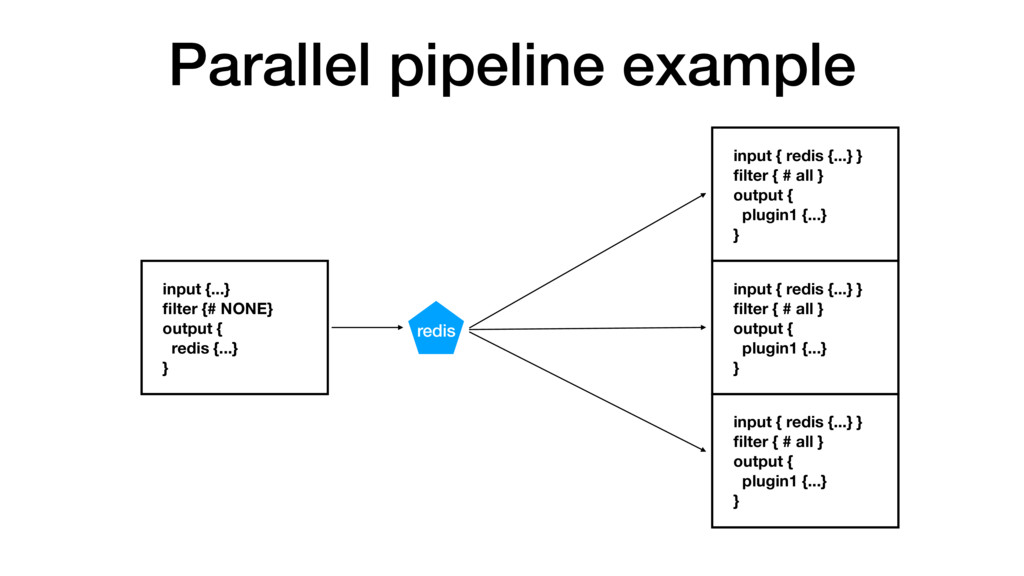
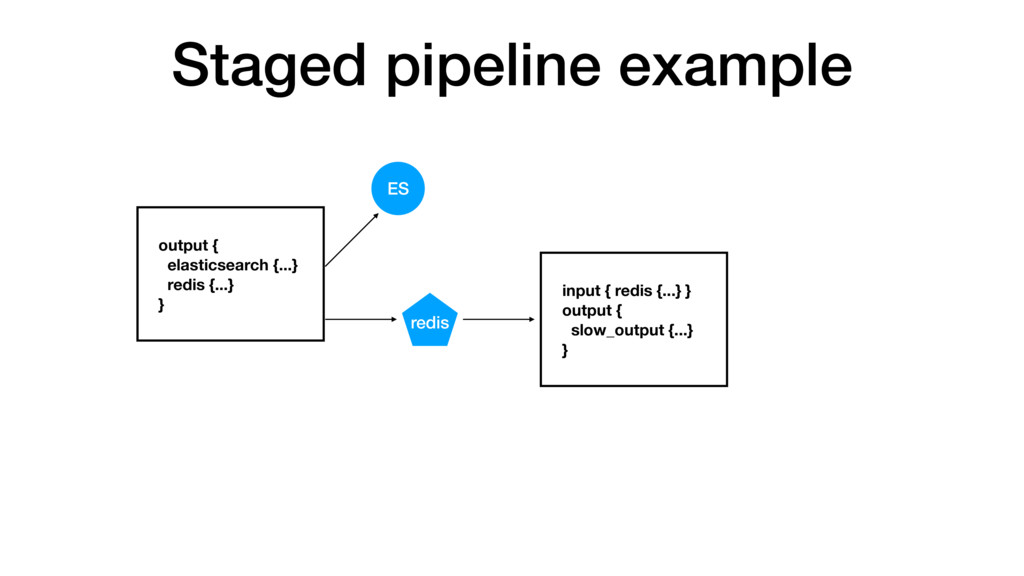
it, so monitor it. A lot. • Use grok and regular expressions... • ...as sparingly as possible • Don't put all of your pipeline eggs in one basket... • ...unless you've measured it and it meets your expectations • Parallelize and stage your pipeline with brokers FTW
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}