permission is strictly prohibited History of the ELK Stack • Logstash was started in 2009 by Jordan Sissel • Elasticsearch was first released in 2010 by Shay Banon • Kibana was begun in 2011 by Rashid Khan • Elasticsearch (the company) was founded in 2012 • Rashid joined Elasticsearch in January, 2013 • Jordan joined Elasticsearch in August, 2013 • Much of the development on all three projects is now done in-house, in addition to open source contributions
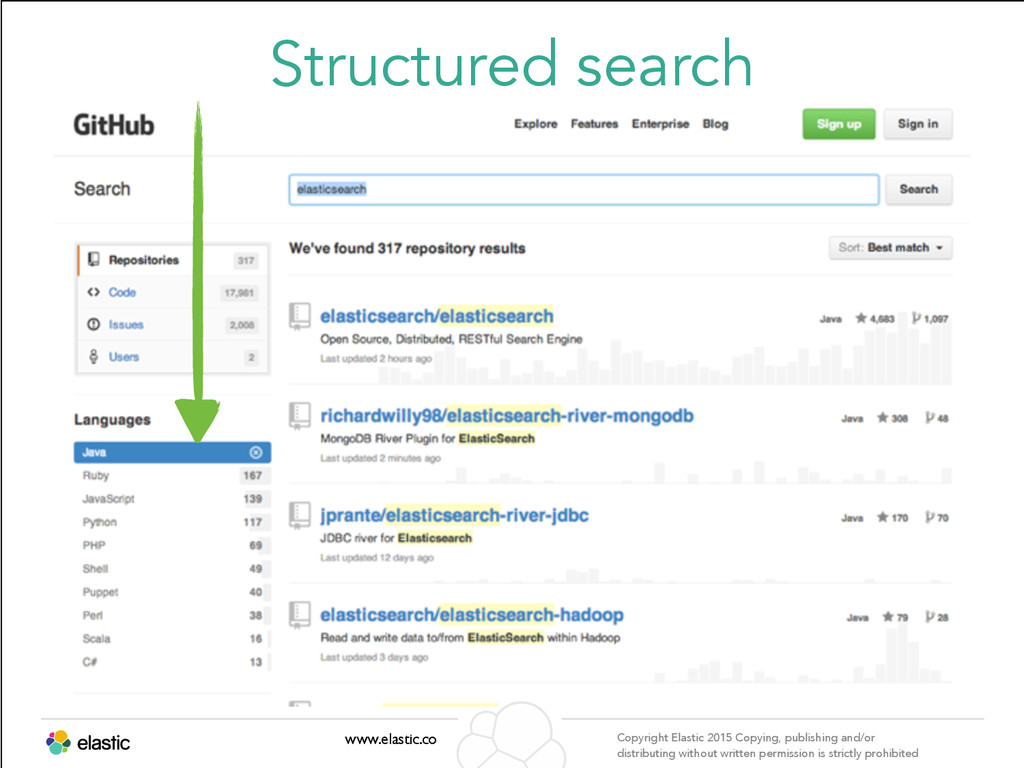
permission is strictly prohibited Structured search www.elastic.co Copyright Elastic 2015 Copying, publishing and/or distributing without written permission is strictly prohibited
permission is strictly prohibited Enrichment www.elastic.co Copyright Elastic 2015 Copying, publishing and/or distributing without written permission is strictly prohibited
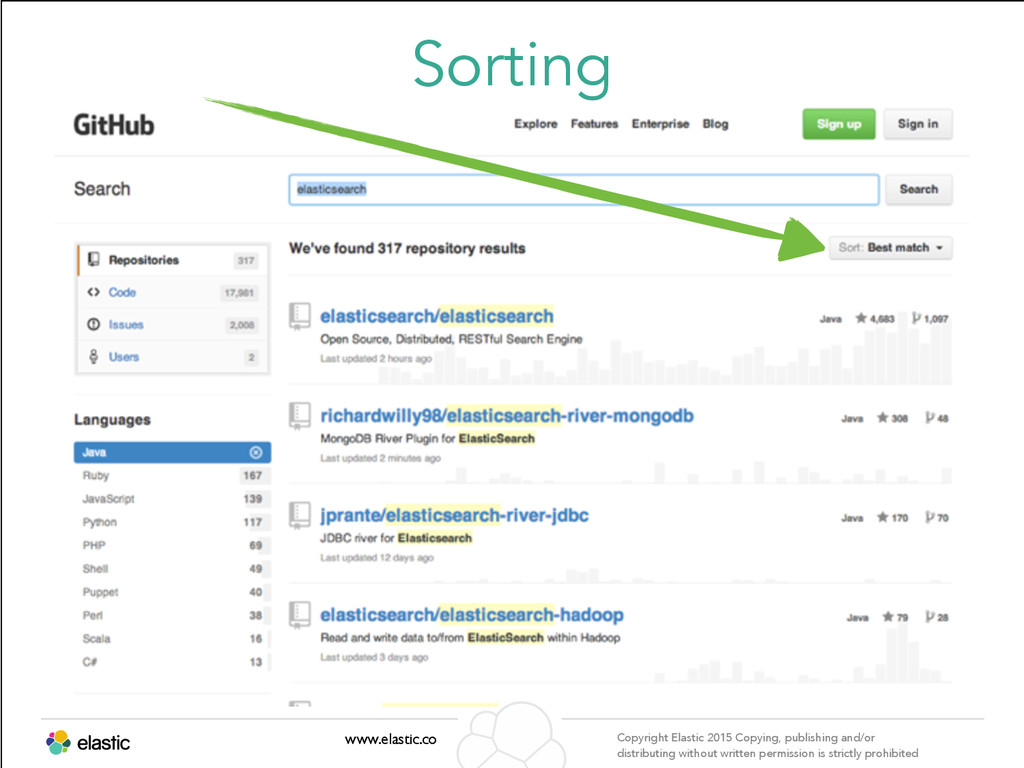
permission is strictly prohibited Sorting www.elastic.co Copyright Elastic 2015 Copying, publishing and/or distributing without written permission is strictly prohibited
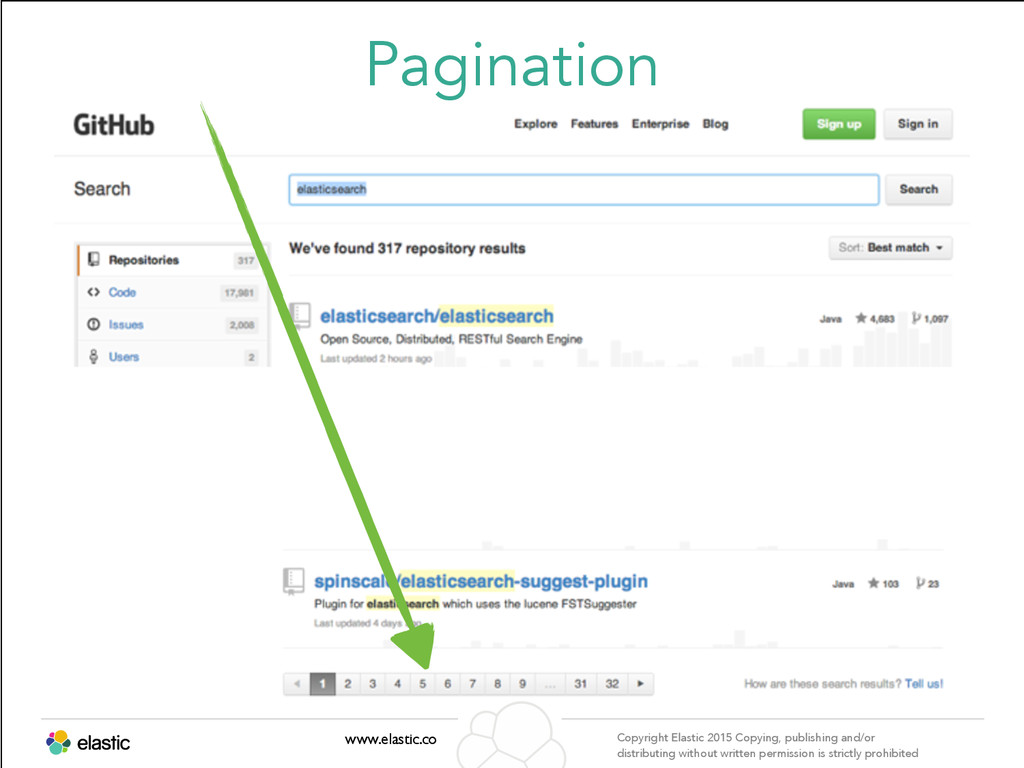
permission is strictly prohibited Pagination www.elastic.co Copyright Elastic 2015 Copying, publishing and/or distributing without written permission is strictly prohibited
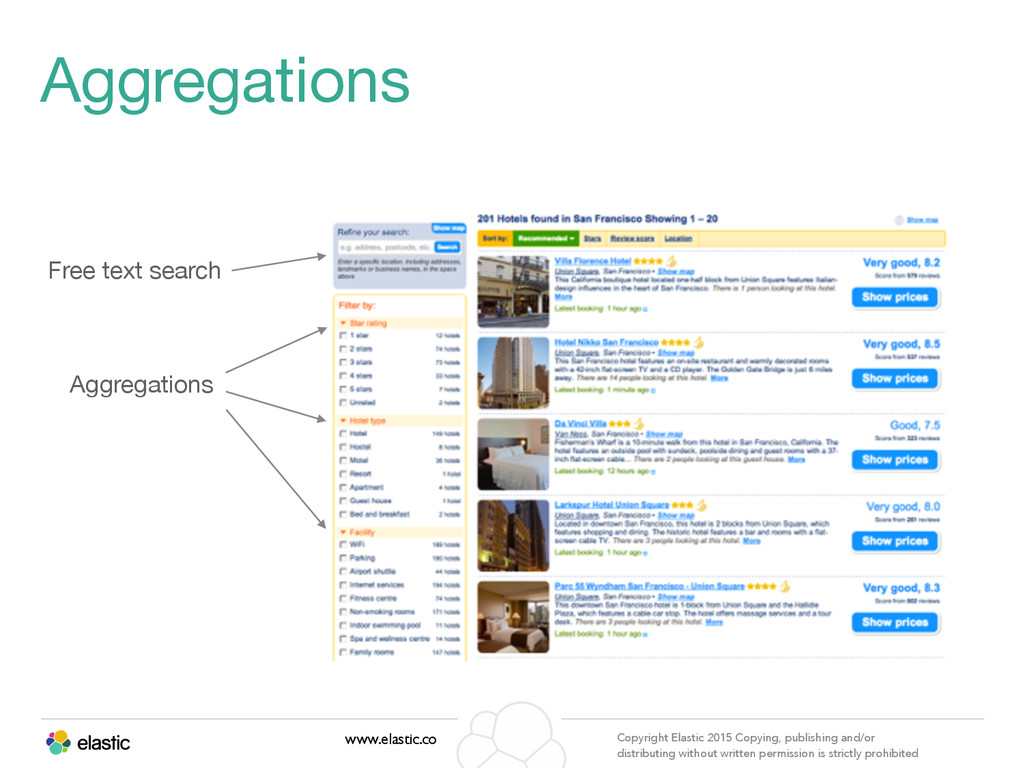
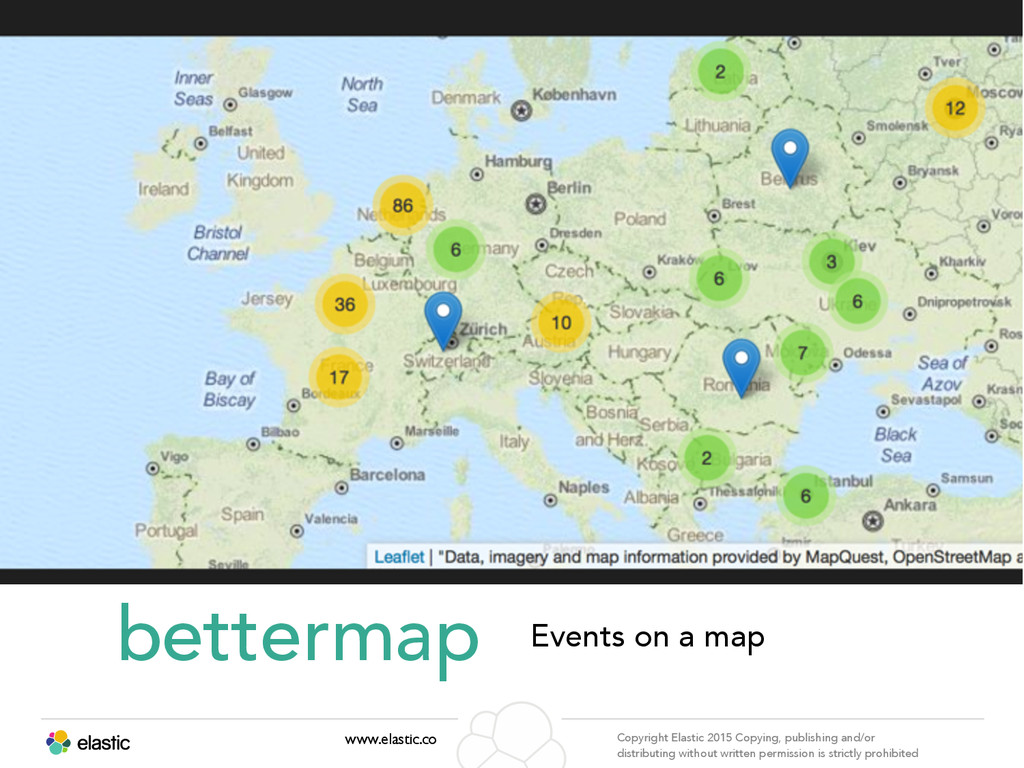
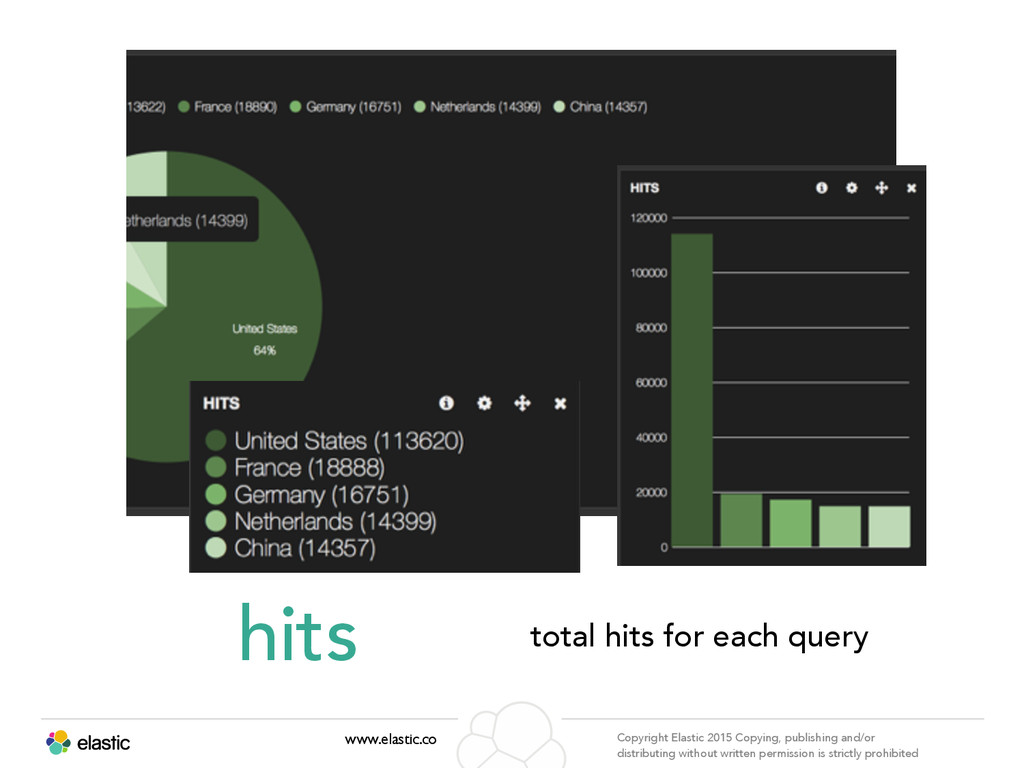
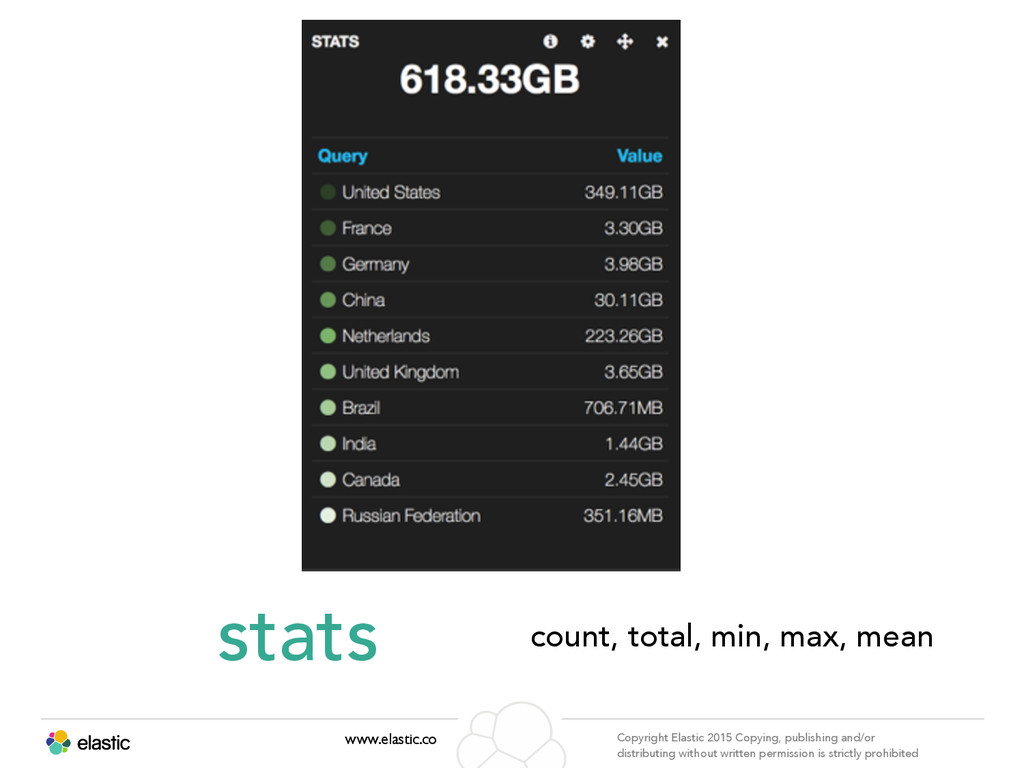
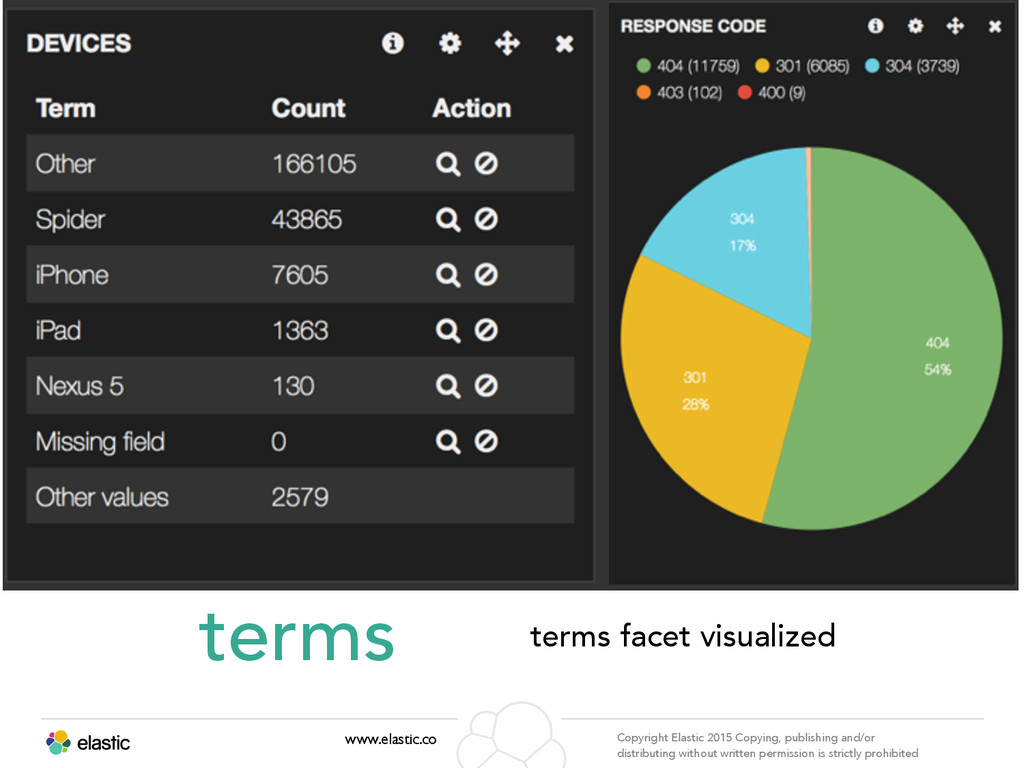
permission is strictly prohibited Aggregation www.elastic.co Copyright Elastic 2015 Copying, publishing and/or distributing without written permission is strictly prohibited
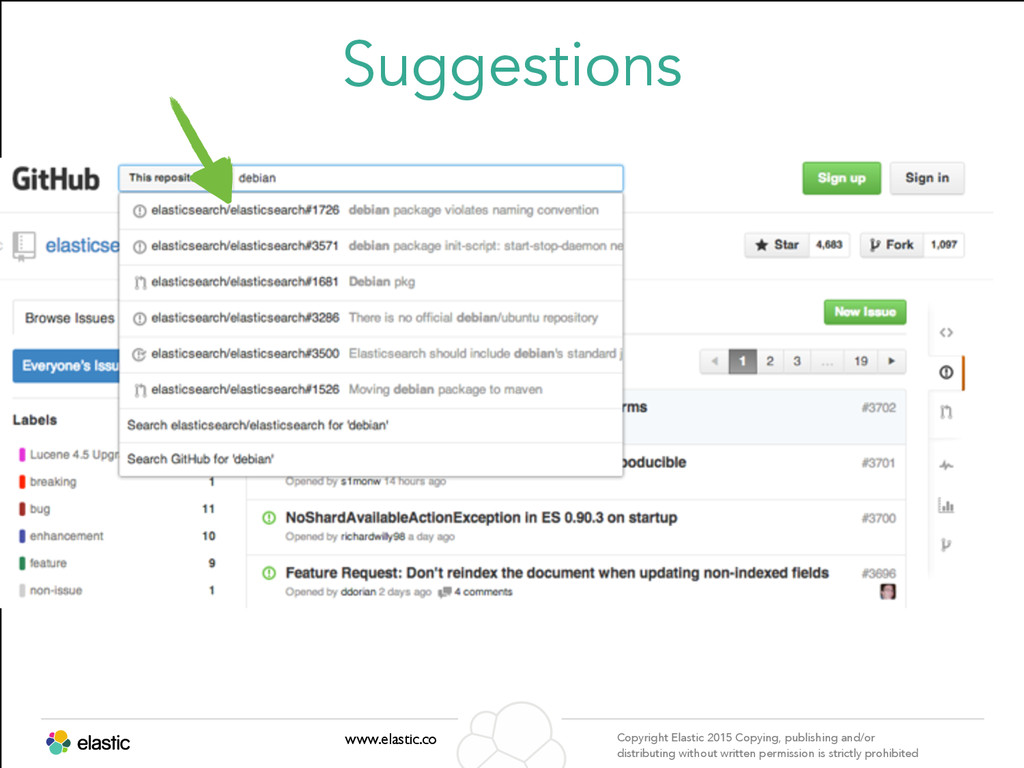
permission is strictly prohibited Suggestions www.elastic.co Copyright Elastic 2015 Copying, publishing and/or distributing without written permission is strictly prohibited
permission is strictly prohibited What is Elasticsearch? • Document-oriented search engine • JSON based (both document store and REST API) • Built on top of Apache Lucene • Schema Free / Schema-Less • Yet enables control of schema when needed (via mappings) • Distributed Model • Scales Up+Out, Highly Available • Multi-tenant data • Dynamically create/delete indices • API centric & RESTful • Most functionality + cluster statistics are exposed via API
permission is strictly prohibited Basic glossary • Maecenas aliquam maecenas ligula nostra, accumsan taciti. Sociis mauris in integer • El eu libero cras interdum at eget habitasse elementum est, ipsum purus pede • Aliquet sed. Lorem ipsum dolor sit amet, ligula suspendisse nulla pretium, rhoncus cluster A cluster consists of one or more nodes which share the same cluster name. Each cluster has a single master node which is chosen automatically by the cluster and which can be replaced automatically if the current master node fails. node A node is a running instance of elasticsearch which belongs to a cluster. Multiple nodes can be started on a single server for testing purposes, but usually you should have one node per server. At startup, a node will use multicast (or unicast, if specified) to discover an existing cluster with the same cluster name and will try to join that cluster.
permission is strictly prohibited Basic glossary • Maecenas aliquam maecenas ligula nostra, accumsan taciti. Sociis mauris in integer • El eu libero cras interdum at eget habitasse elementum est, ipsum purus pede • Aliquet sed. Lorem ipsum dolor sit amet, ligula suspendisse nulla pretium, rhoncus index An index can be seen as a named collection of documents. It is a logical namespace which maps to one or more primary shards and can have zero or more replica shards. shard A shard is a single Apache Lucene instance. It is a low- level “worker” unit which is managed automatically. Shards are distributed across all nodes in the cluster, and can move shards automatically from one node to another in the case of node failure, or the addition of new nodes. There are two types of shards: primary and replica.
permission is strictly prohibited Basic glossary • Maecenas aliquam maecenas ligula nostra, accumsan taciti. Sociis mauris in integer • El eu libero cras interdum at eget habitasse elementum est, ipsum purus pede • Aliquet sed. Lorem ipsum dolor sit amet, ligula suspendisse nulla pretium, rhoncus Primary shard An index can have one or more primary shards (defaults to 5) and it is not possible to change this number after index creation. When you index a document, it is first indexed on the primary shard, then on all replicas of this shard. Replica shard Each primary shard can have zero or more replicas (defaults to 1). A replica is a copy of the primary shard, and serves two purposes: ‣ Increase high availability - a replica is another copy of the data and will be promoted to a primary shard if the primary fails ‣ Increase performance - get and search requests can be handled by primary or replica shards
permission is strictly prohibited Create Index API Creating Index a with 2 shards and 1 replica (a total of 4 shards) Creating Index b with 3 shards and 1 replica (a total of 6 shards) curl -XPUT 'localhost:9200/a' -d '{ "settings" : { "number_of_shards" : 2, "number_of_replicas" : 1 } }' curl -XPUT 'localhost:9200/b' -d '{ "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }'
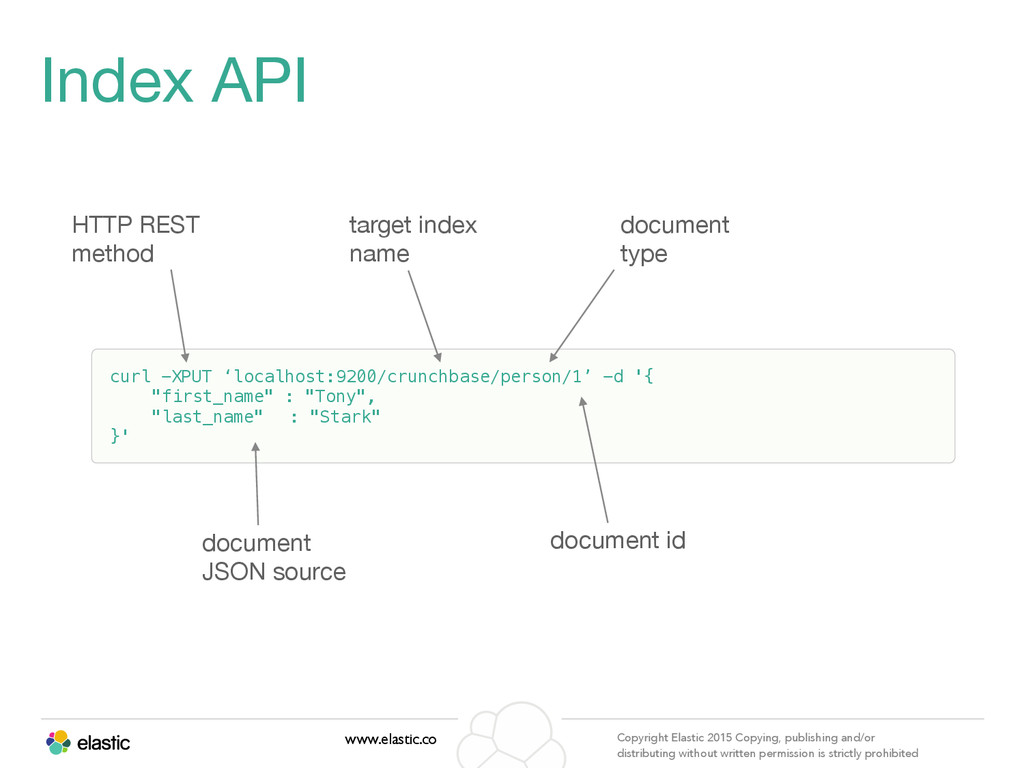
permission is strictly prohibited curl -XPUT ‘localhost:9200/crunchbase/person/1’ -d '{ "first_name" : "Tony", "last_name" : "Stark" }' Index API target index name HTTP REST method document JSON source document type document id
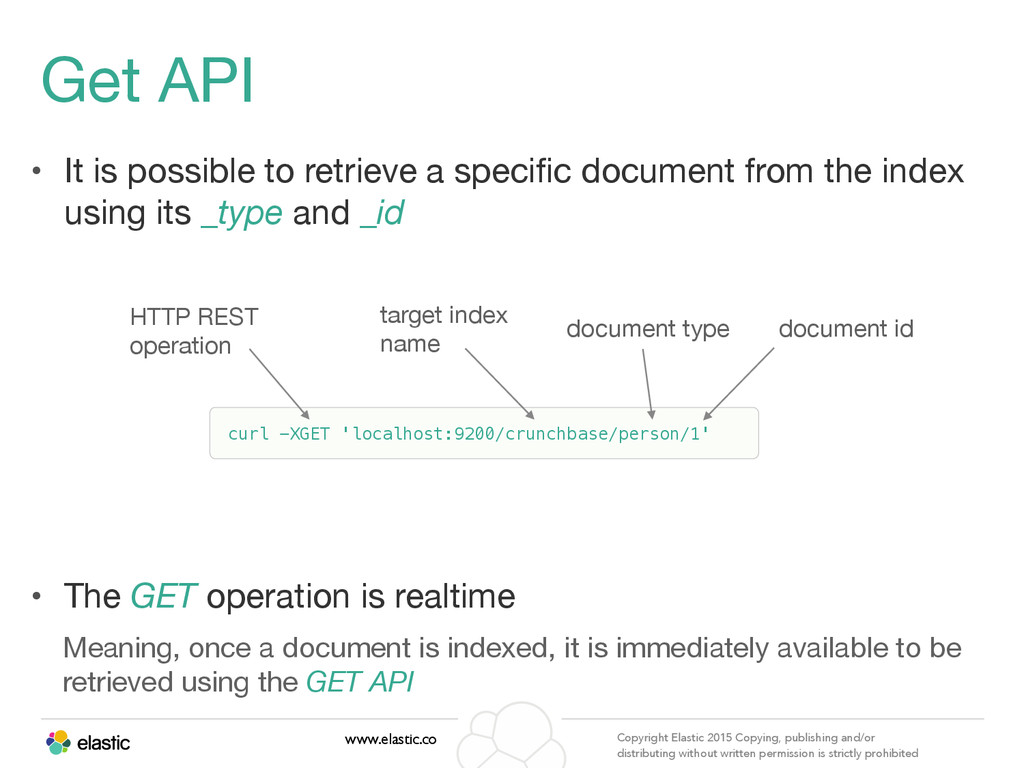
permission is strictly prohibited • It is possible to retrieve a specific document from the index using its _type and _id • The GET operation is realtime Meaning, once a document is indexed, it is immediately available to be retrieved using the GET API curl -XGET 'localhost:9200/crunchbase/person/1' Get API target index name HTTP REST operation document type document id
permission is strictly prohibited Exists API • Check if a document is in the index Without the overhead of loading it • The response is based on HTTP status code 200 (OK) if exists 404 (NOT FOUND) if doesn’t exist curl -XHEAD -i 'localhost:9200/crunchbase/person/1'
permission is strictly prohibited Update API • Update by partial data Partial doc is merged with existing doc Non-object properties with the same key are replaced. Object properties are recursively merged curl -XPOST 'localhost:9200/crunchbase/person/1/_update' -d '{ "doc" : { "first_name" : "Antonio" } }'
permission is strictly prohibited • Deleting a specific document by _id • Response 200 (OK) if deleted 404 if not found { "found" : true, "_index" : "test", "_type" : "person", "_id" : "1", "_version" : 3 } Delete API Indication if it was actually found curl -XDELETE 'localhost:9200/crunchbase/person/1'
permission is strictly prohibited • Sometimes you'd like to get multiple documents in one go Avoid round trips when using the Get API curl 'localhost:9200/_mget' -d '{ "docs" : [ { "_index" : "crunchbase", "_type" : "person", "_id" : "1" }, { "_index" : "marvels", "_type" : "hero", "_id" : "2" "_source" : [ "first_name" ] } ] }' Multi Get API index name document type document id Optionally specify what fields should be returned
permission is strictly prohibited Grep! • Which plays contain the word “darling” in the complete works of Shakespeare? ‣ Grep it! ‣ Go over each play, word by word, and mark the play that contains it • Linear to the number of words • Fails at large scale
permission is strictly prohibited Inverted Index • Inverting Shakespeare ‣ Take all the plays and break them down word by word ‣ For each word, store the ids of the documents that contain it ‣ Sort all tokens (words) • Search First look for the relevant word (fast as words are sorted), if found, iterate over the document ids that are associated it
permission is strictly prohibited Analyzers • Analysis => Tokenization and normalization • Analyzers => Analysis and token filters • Token filters act on the token stream - can drop and modify existing tokens, or add new ones. • Out of the box, many analyzers are available — Standard analyzer, Whitespace analyzer, language analyzers • Can define/build custom analyzers
permission is strictly prohibited Rich Search via Query DSL • Queries • Unstructured search, enables to query the data based on textual analysis (free text search). Queries score documents by relevancy (supports powerful custom scoring algorithms). To name a few: • match ‣ bool (boolean) ‣ histogram ‣ Filters • Structured search, enables narrowing the search context based on known document structure (no scoring and very fast). To name a few: ‣ term ‣ range ‣ bool (boolean)
permission is strictly prohibited Querying Powerful and rich Query DSL Queries are analyzed too Near real time (from indexing to querying) GET /_search -d '{ { "query": { "match": { "tweet": "elasticsearch" } } }
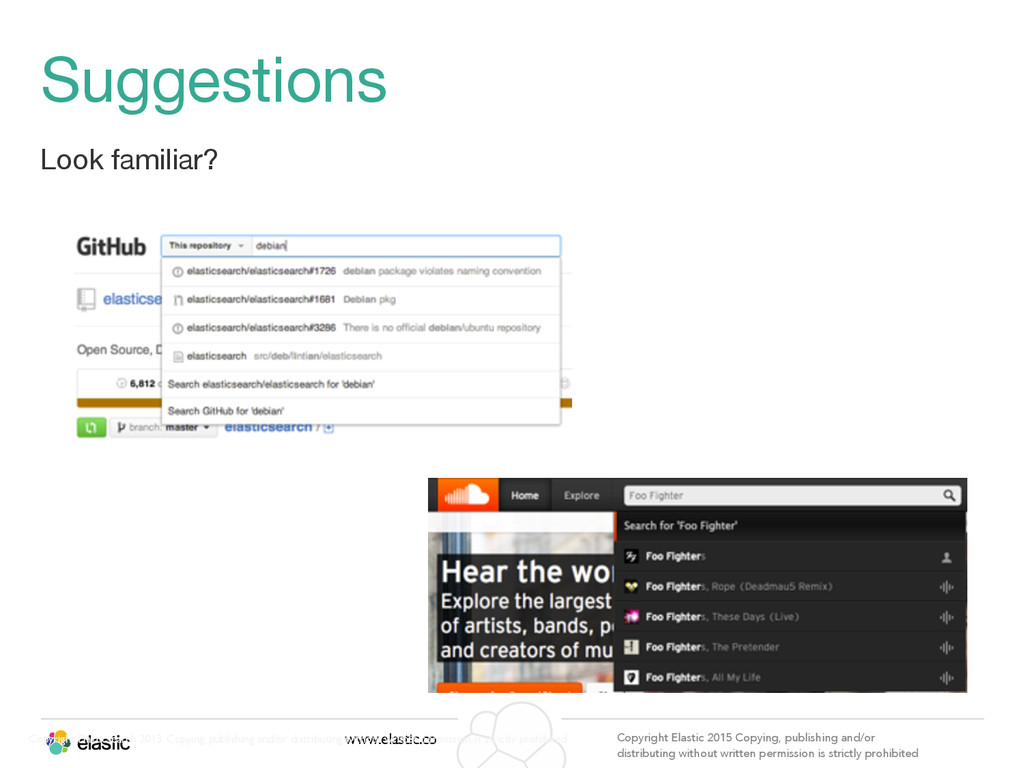
permission is strictly prohibited Copyright Elasticsearch 2013. Copying, publishing and/or distributing without written permission is strictly prohibited Suggestions Look familiar?
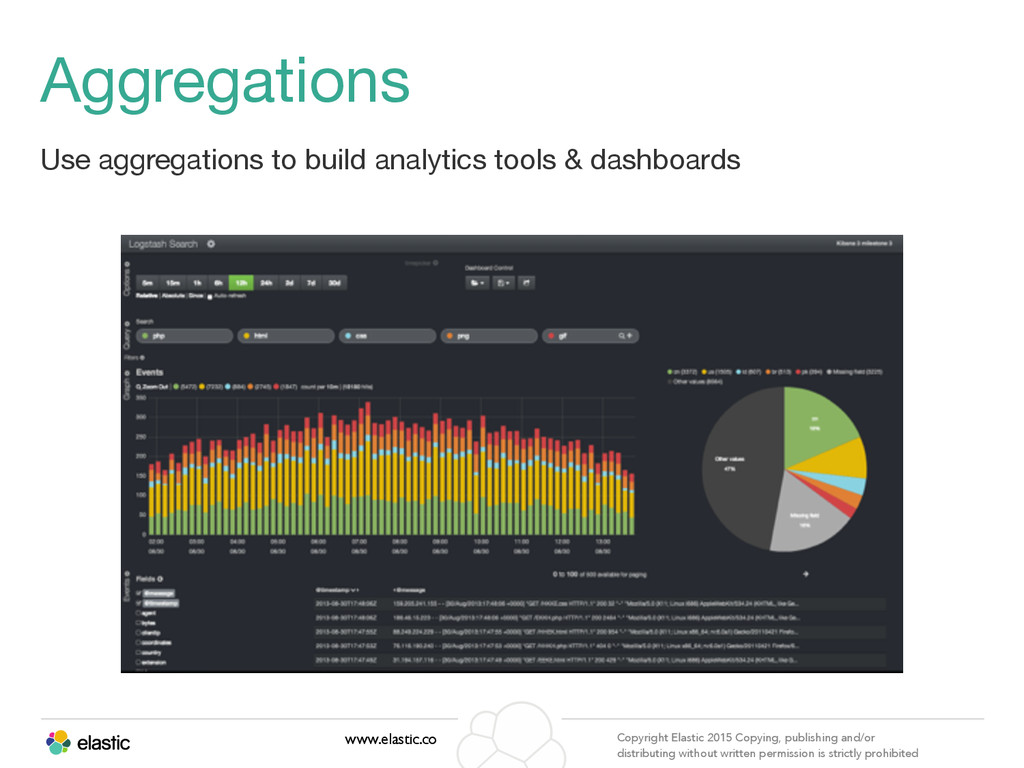
permission is strictly prohibited Analytics Un-invert the inverted index (Field data) Load the field data to memory Group By — popular terms, significant terms, ranges, dates, geolocation Metrics — count, min, max, sum, avg, percentiles, cardinality, Nested aggregations helps slice and dice data
permission is strictly prohibited Aggregations: Buckets & Metrics • Two categories of aggregations - Buckets & Metrics • Buckets Aggregations that build buckets. Each bucket is associated with some criteria over documents. During query execution, each document is evaluated against the created buckets and each bucket keeps track of what documents “fall” in it. Each bucket effectively defines a set of documents derived from the document set within the aggregations scope. • Metrics Aggregations that given a set of documents, produce a single/multiple scalar/s. Typically, metrics aggregations generate numeric stats that are computed over a specific document set
permission is strictly prohibited Bucket - *_range • date_range A dedicated range aggregations that works on date fields. Ranges can be defined as date math expressions • ip_range A dedicated range aggregation that works on ip fields. Ranges can be defined as ipv4 strings or CIDR masks { "from" : "now-1M", "to" : "now" } { "from" : "10.0.0.0", "to" : "10.0.0.128" } { "mask" : "10.0.0.0/25" }
permission is strictly prohibited Aggregations • Enables slicing & dicing the data • Provides multi-dimensional grouping of results. e.g. Top URLs by country. • Many types available • All operate over values extracted from the documents - usually from specific fields of the documents, but highly customizable using scripts ‣ terms ‣ range / date_range / ip_range ‣ geo_distance / geohash_grid ‣ histogram / date_histogram ‣ stats / avg / max / min / sum / percentiles
permission is strictly prohibited Problem 1: No Consistency • Every application and device logs in its own special way. • Expert in each log format required to use the logs. • Difficult to search across because of this formatting problem.
permission is strictly prohibited No Consistency 120707 0:37:09 [Note] Plugin 'FEDERATED' is disabled. 120707 0:37:09 InnoDB: The InnoDB memory heap is disabled 120707 0:37:09 InnoDB: Mutexes and rw_locks use GCC atomic builtins 120707 0:37:09 InnoDB: Compressed tables use zlib 1.2.5 120707 0:37:09 InnoDB: Using Linux native AIO 120707 0:37:09 InnoDB: Initializing buffer pool, size = 128.0M 120707 0:37:09 InnoDB: Completed initialization of buffer pool
permission is strictly prohibited Problem 2: Time Formats 130460505 Oct 11 20:21:47 [29/Apr/2011:07:05:26 +0000] 020805 13:51:24 @4000000037c219bf2ef02e94
permission is strictly prohibited Problem 3: Decentralized • Logs are spread across all of your servers • Many servers have many different kinds of logs • ssh + grep aren’t scalable
permission is strictly prohibited Problem 4: Experts Required • People interested in the logs often… • Do not have access to read the logs. • Do not have expertise to understand the data. • Do not know where the logs are.
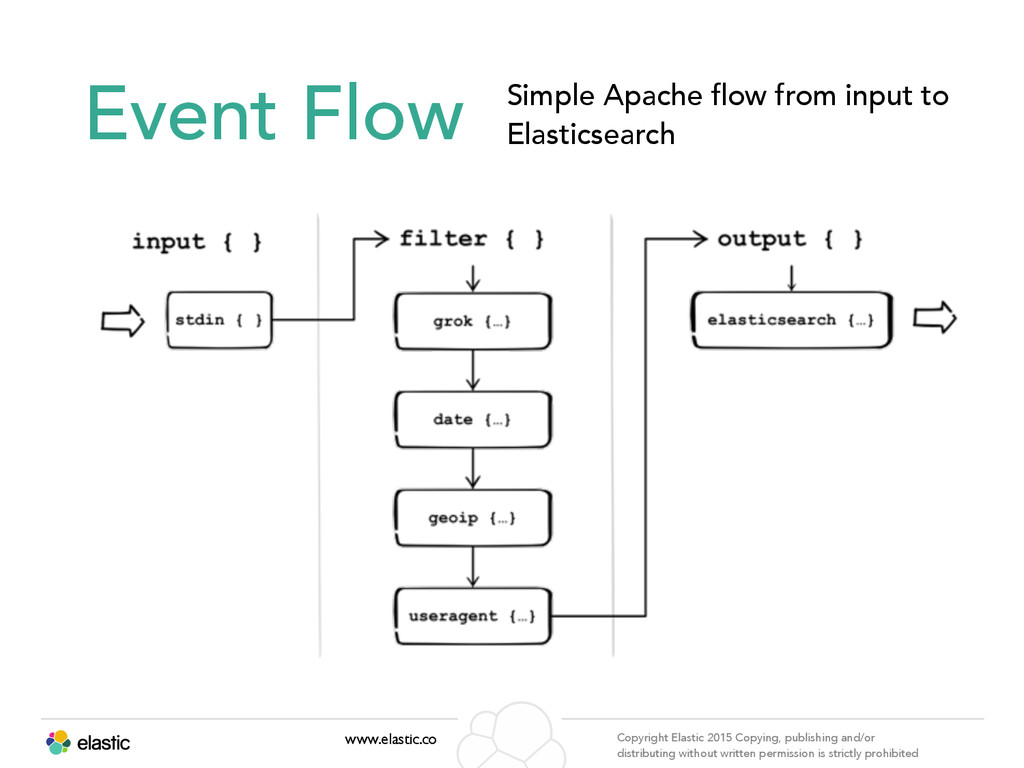
permission is strictly prohibited What is Logstash? • Event processing engine, optimized for logs • raw data in, enriched data out • Written in Ruby, runs on JRuby • Simple to extend, efficient to run • Events pass through a pipeline • Inputs: receive data from files, network, etc. • Filters: enrich, massage, process the event data • Outputs: send event data to other systems • Designed to be extremely flexible • Most commonly used to index data in Elasticsearch
permission is strictly prohibited Inputs (50+) • Network (TCP/UDP) + File: most common • syslog / rsyslog: supports multiple simultaneous clients • RabbitMQ, Redis, Kafka: used in larger clusters • stdin: handy for "backfilling" data, or testing • Twitter: follow your brand's social media activity • Email (IMAP): so you don't need to read it all yourself! • Lumberjack: resilient, compressed, secure • Amazon S3, gelf, ganglia, sqs, varnishlog, etc. etc.
permission is strictly prohibited Filters (60+) • grok: for extracting data using pattern matching • date: parse timestamps from fields, for use as "official" timestamps • mutate: rename, remove, replace, and modify fields in your events • ruby: run arbitrary Ruby code in the pipeline • geoip: determine geographical location based on IP address • csv: parse CSV data (or any pattern-separated data) • kv: parse key-value pairs in event data • And many, many, more
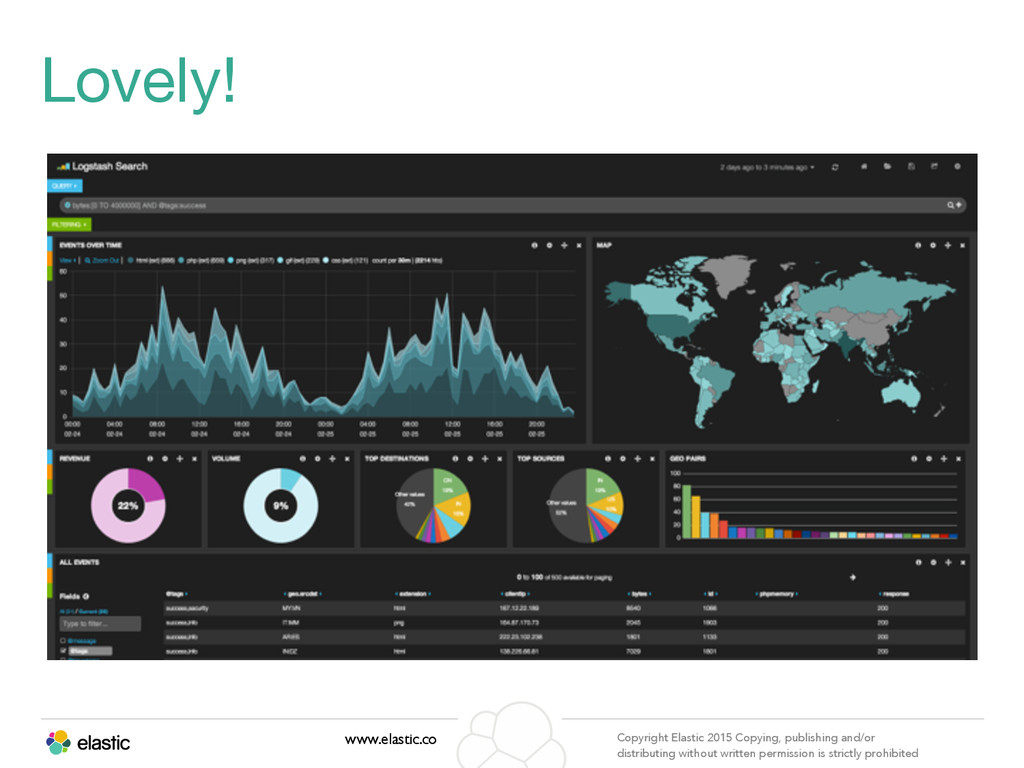
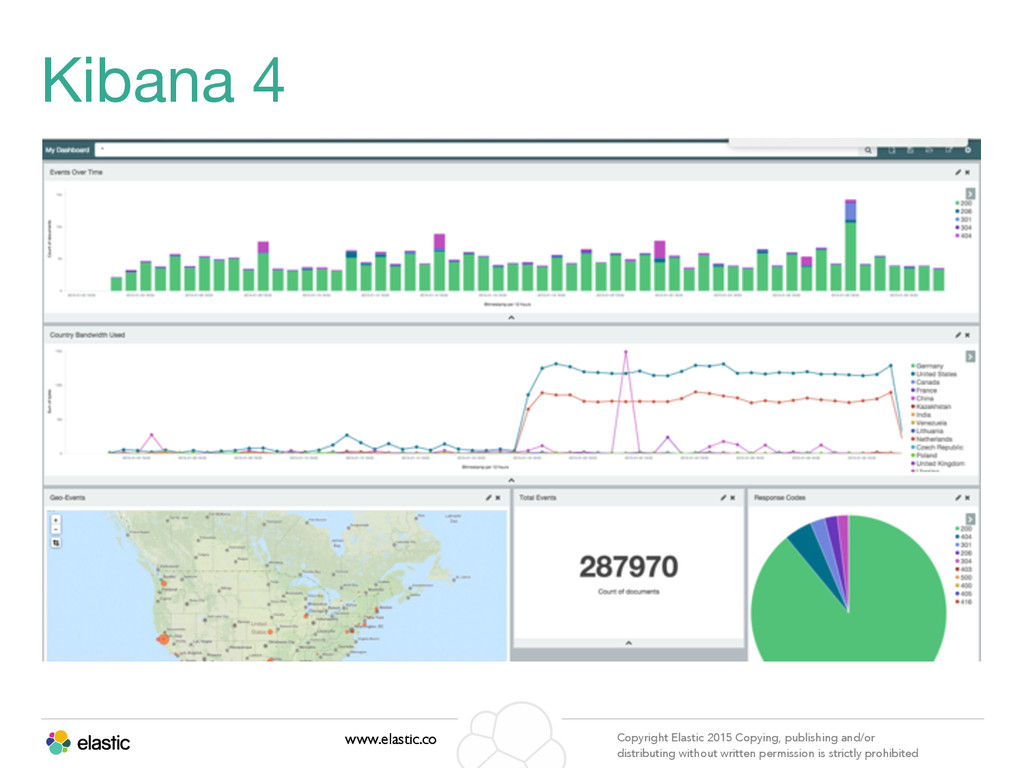
permission is strictly prohibited What is Kibana? • Data Visualization tool • K3: Client-side. K4: Node.js server. • No programming necessary • Reads data from Elasticsearch • Multiple panel types • Save and share dashboards • Democratize your data!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}