Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AmazonAthenaで 競馬データをParquet化する
Search
usanchuu
March 11, 2026
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AmazonAthenaで 競馬データをParquet化する
2026/03/11 JAWS-UG茨城 #12春の推しAWSサービスLTまつり!での登壇資料です。
usanchuu
March 11, 2026
More Decks by usanchuu
See All by usanchuu
名古屋の市バスGTFS-JPデータ×スガキヤ 最寄りバス停検索をAmazon ElastiCache Serverless for Valkeyで最適化する
usanchuu
1
31
Server-TimingとDevOpsエージェントを用いたLambdaコンテナの動的ルーティング制御
usanchuu
0
59
AmazonRoute 53ではじめてのドメイン取得!HTTPS化までの道のりを整理してみた
usanchuu
3
170
ラーメンにお酢が馴染む時間を計算したら麺が伸びそうになったので、 AWS Lambda Power TuningとManaged Instancesで爆速化する
usanchuu
1
170
Amazon Rekognitionで 「信玄餅きなこ問題」を解決する
usanchuu
1
1.2k
Amazon S3 Vectorsを使って資格勉強用AIエージェントを構築してみた
usanchuu
4
570
Reachability Analyzer VS Kiro CLI ~ネットワークがつながらないとき、どっちを使う?~
usanchuu
1
100
Other Decks in Technology
See All in Technology
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
460
AI工学特論: MLOps・継続的評価
asei
11
3k
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
780
書籍セキュアAPIについて
riiimparm
0
390
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
150
オートマトンと字句解析でRoslynを読む
tomokusaba
0
120
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
330
データ組織の転換期 一足飛びしない段階的戦略
leveragestech
PRO
0
110
PLaMo 3.0 Primeの構造化出力サポート
pfn
PRO
0
110
LangfuseによるLLMOps基盤の構築と活用事例
zozotech
PRO
1
170
NetBoxを利用した作業効率化の試み_NetDevNight4
tnoha
0
380
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
860
Featured
See All Featured
GraphQLとの向き合い方2022年版
quramy
50
15k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
260
Being A Developer After 40
akosma
91
590k
BBQ
matthewcrist
89
10k
Deep Space Network (abreviated)
tonyrice
0
240
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
The Cult of Friendly URLs
andyhume
79
7k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Transcript
Amazon Athenaで 競馬データをParquet化する 2026/03/11 JAWS-UG 茨城 #12 春の推しAWSサービスLTまつり! 藤井 ひかり
① 推しサービス「Amazon Athena」についてご紹介 ② Amazon Athenaで競馬データをParquet化して万馬券を当てる 検証 今回の内容
発表者について フジイ ヒカリ と申します・x・ 社会人1年目:SIerのアーキテクチャチームでSEしてます データベース初学者ですが楽しく勉強しています AWSについて 保有資格:CLF,AIF,SAA,MLA,DEA ★昨年12月開催のJAWS-UG Presents
- AI Builders Dayを きっかけにAWSに興味をもち、現在絶賛勉強中です! X:@usanchuu
出走直前の馬体重とオッズのデータを分析して期待 値を出したい。 でもDEAの勉強中で悠長に考えてられない…RDS (データベース)を立てる時間も維持費も惜しい。 LT内容の背景:万馬券をあてたい!
DEA勉強中に出てきたAthenaはDB構築ゼロ+S3に データを置くだけで即SQLが使えるらしい! 勉強がてら使ってみよう LT内容の背景:万馬券をあてたい!
① 推しサービス「Amazon Athena」 についてご紹介
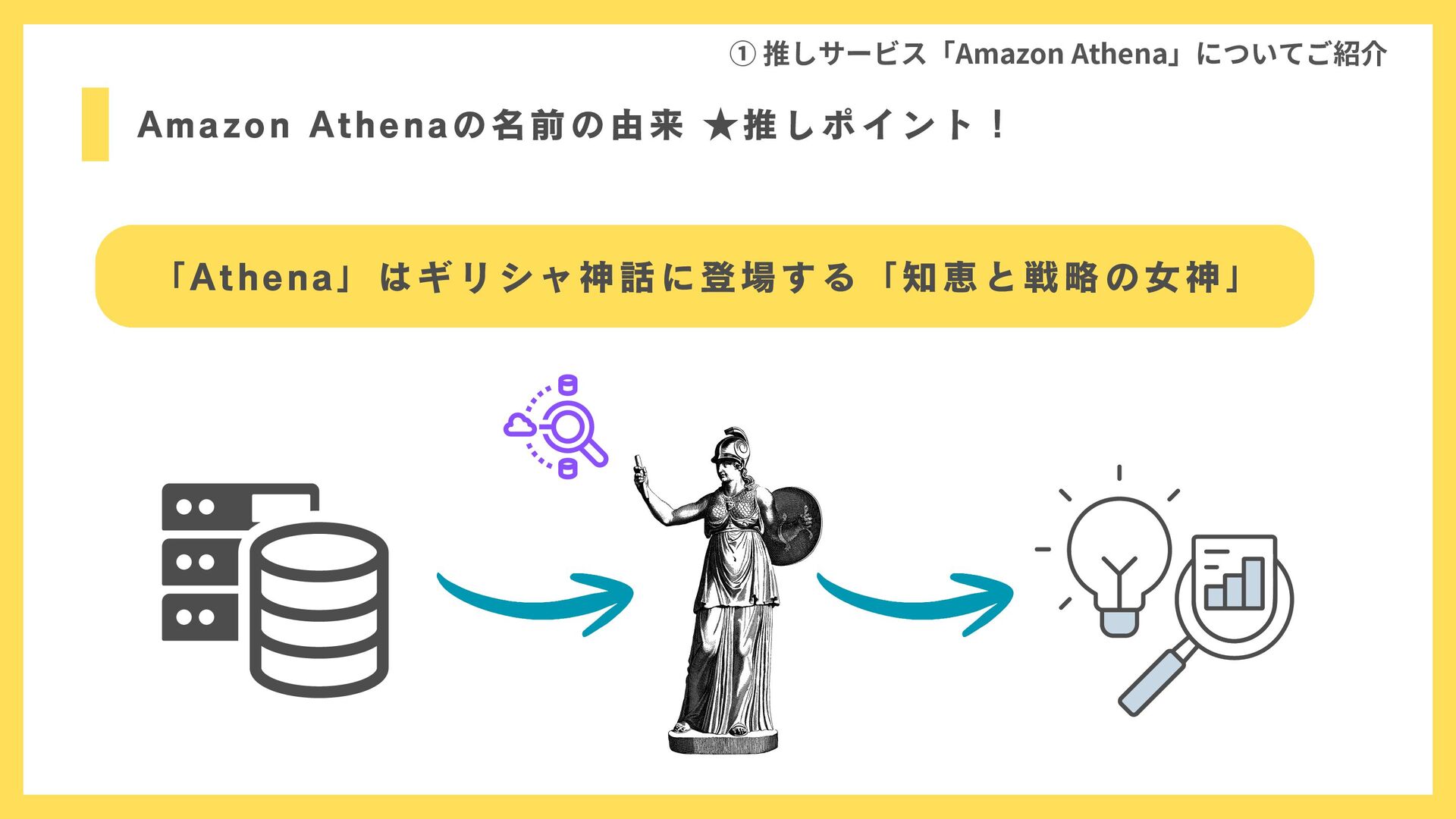
Amazon Athenaの名前の由来 ★推しポイント! ① 推しサービス「Amazon Athena」についてご紹介 「Athena」はギリシャ神話に登場する「知恵と戦略の女神」
Amazon Athenaの特徴 ① 推しサービス「Amazon Athena」についてご紹介 ②学習コストが『ゼロ』 ①DB構築が『ゼロ』 ③使っていない時の維持費が『ゼロ』 S3にファイル(CSVやJSON)を置くだけで、準備完了
標準的なSQLを叩くだけで、すぐにデータが返ってくる 『スキャンしたデータ量(1TBあたり約5ドル) 』だけの従量課金
Athenaの裏側で起こっていること ★Schema-on-Read https://docs.aws.amazon.com/ja_jp/athena/latest/ug/handling- schema-updates-chapter.html より ① 推しサービス「Amazon Athena」についてご紹介 【従来のDB:Schema-on-Write】 「①テーブル設計
→ ②データ投入 → ③検索」 →事前の設計とデータ加工が必須で大変! 【Athena:Schema-on-Read】 →生データに『読む瞬間だけ』枠を被せる!事前準備ゼロ!
・従来のオンプレDB:計算サーバーの中にハードディスク ・Athena:Coordinator(司令塔)がSQLを受け取ってGlue Data Catalog を見る→数百のノードが立ち上がり、並列処理をして即解散する。 Athenaの裏側で起こっていること ★コンピュート(計算処理)とストレージ(データ保存)の分離 https://docs.aws.amazon.com/ja_jp/athena/latest/ug/data-types.htmlより ① 推しサービス「Amazon
Athena」についてご紹介
② Amazon Athenaで競馬データを Parquet化して万馬券を当てる検証
検証方法 ② Amazon Athenaで競馬データをParquet化して万馬券を当てる検証 ダミーの競馬データをAIで生成(馬の名前、重さ、オッズ、レース名) ▶Athenaの画面で結果出力場所を指定▶データベースを作成 ▶検索クエリ実行 スクレイピングはやめておくことに...
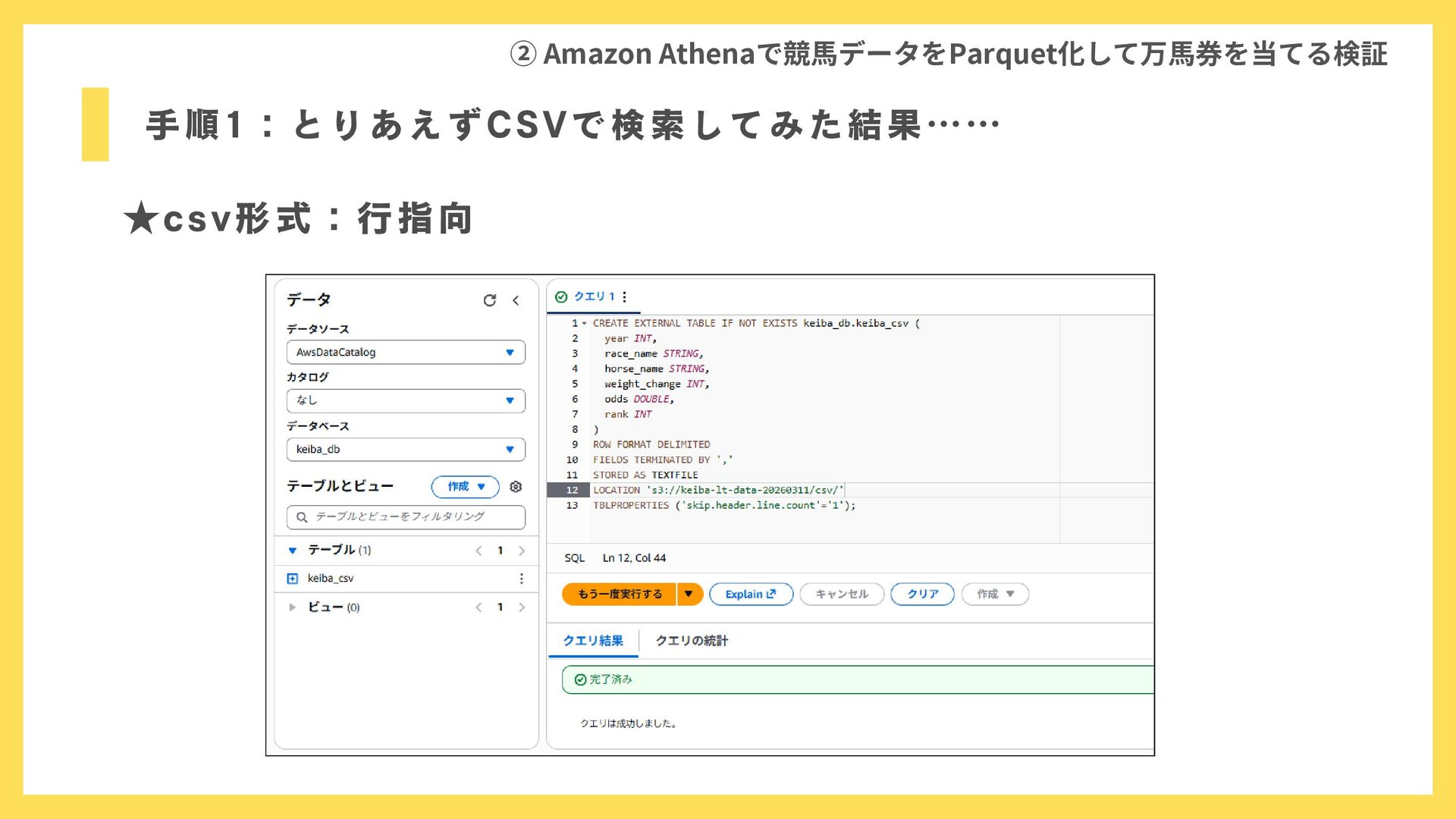
手順1:とりあえずCSVで検索してみた結果…… ② Amazon Athenaで競馬データをParquet化して万馬券を当てる検証 ★csv形式:行指向
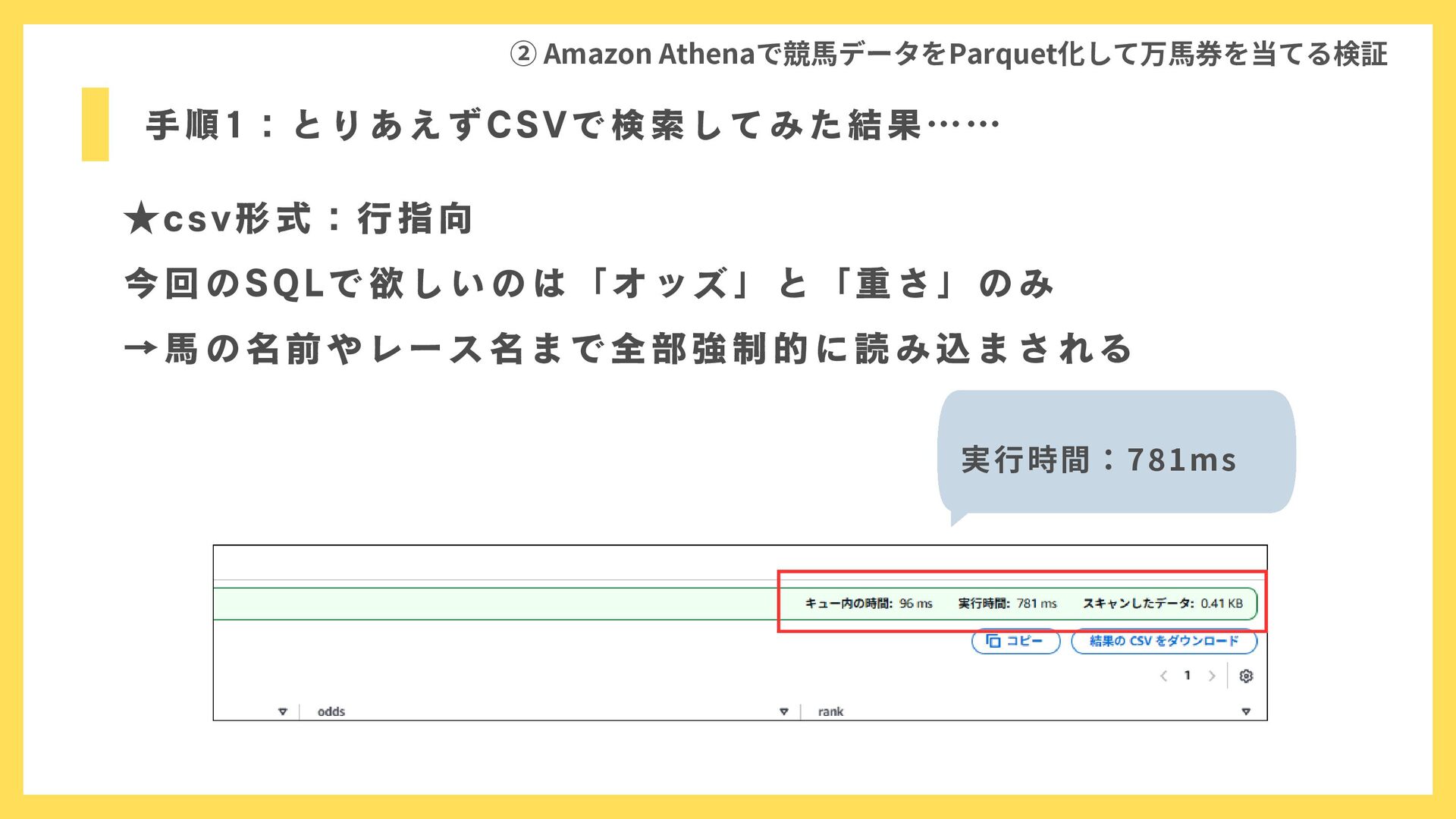
実行時間:781ms 手順1:とりあえずCSVで検索してみた結果…… ② Amazon Athenaで競馬データをParquet化して万馬券を当てる検証 ★csv形式:行指向 今回のSQLで欲しいのは「オッズ」と「重さ」のみ →馬の名前やレース名まで全部強制的に読み込まされる
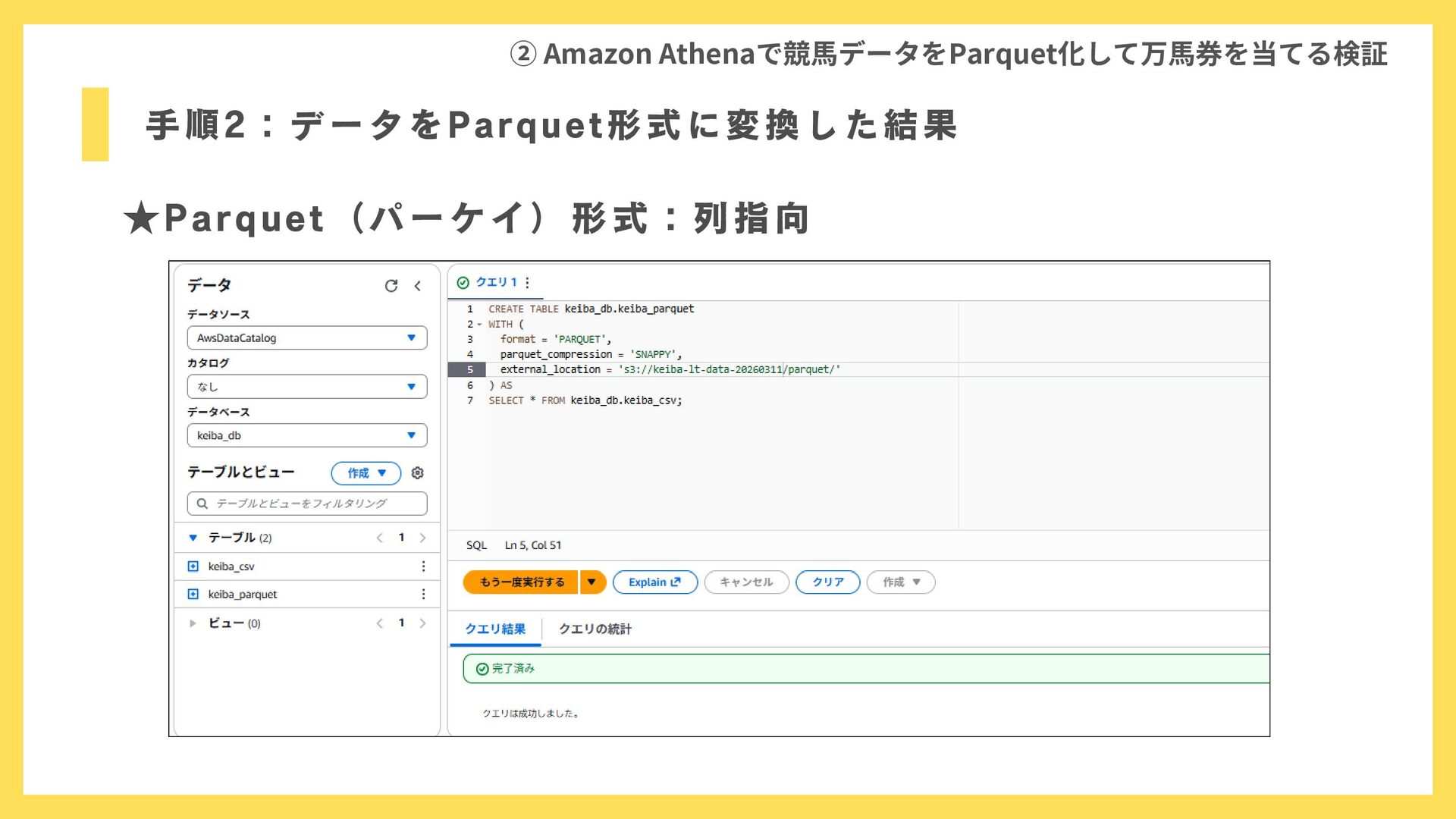
手順2:データをParquet形式に変換した結果 ② Amazon Athenaで競馬データをParquet化して万馬券を当てる検証 ★Parquet(パーケイ)形式:列指向
手順2:データをParquet形式に変換した結果 ② Amazon Athenaで競馬データをParquet化して万馬券を当てる検証 ★Parquet(パーケイ)形式:列指向 データを「列(カラム) 」ごとに縦にまとめて保存 →「オッズ」と「重さ」のデータブロックだけをピンポイントで 読み込める。 実行時間:385ms ★396ms短縮!
いざ!レース本番!!
とおもったのですが、レースの時間が過ぎていました... Parquet変換のお勉強に夢中になって しまった;;
まとめ ★サーバーレスで手軽な反面、 『スキャンしたデータ量』に直接課金される ためデータの持ち方がコストに直結する! Athenaの課金体系 =「スキャン量」がすべて ★Parquet(パーケイ)などの列指向フォーマットへの変換が必須!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}