in conflict • Rises adversarial search problems • Two agents act alternatively • For example, if one player wins a game of chess, the other player necessarily loses
has an average branching factor of about 35, and games often go to 50 moves by each player (100 moves in total for two players), so the search tree has about 35100 nodes. • Games, like the real world problems, therefore require the ability to make some decision even when calculating the optimal decision is infeasible.
is (heuristic) method for finding goal o Heuristics can help find optimal solution o Evaluation function: estimate of cost from start to goal through given node o Examples: path planning, scheduling activities • Games – adversary o Solution is strategy (strategy specifies move for every possible opponent reply) o Time limits force an approximate solution o Evaluation function: evaluate “goodness” of game position o Examples: chess, checkers, tic-tac-toe, backgammon
The initial state, which specifies how the game is set up at the start. • PLAYER(s): Defines which player has the move in a state. • ACTION(s): Returns the set of legal moves in a state. • RESULT(s,a): The transition model, which defines the result of a move. • TERMINAL-TEST(s): A terminal test, which is true when the game is over and false otherwise. o States where the game has ended are called terminal states. • UTILITY (s, p): A utility function (also called an objective function or payoff function), defines the final numeric value for a game that ends in terminal state s for a player p. o In chess, the outcome is a win, loss, or draw, with values +1, 0, or ,1/2 o Some games have wider variety of possible outcomes
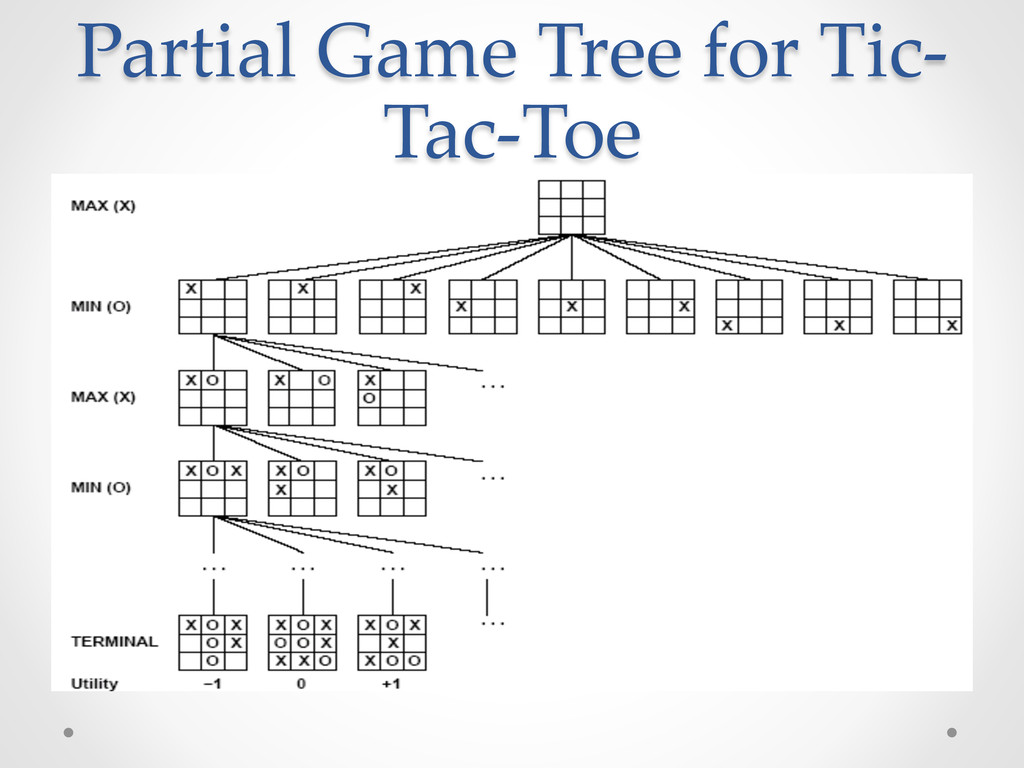
define the game tree, where the nodes are game states and the edges are moves. • Example Game: tic-tac-toe ( X O ). o From the initial state, MAX has 9 possible moves. o Play alternates between MAX 's placing an X and MIN's placing an O o Later we reach leaf nodes corresponding to terminal states such that one player has three in a vertical / horizontal / diagonal row or all the squares are filled.
small – fewer than 9! = 362, 880 terminal nodes. • But for chess, there are over 1040 nodes, so the game tree is best thought of as a theoretical construct that we cannot realize in the physical world. • But regardless of the size of the game tree, it is MAX's job to search for a good move. • We use the term search tree for a tree that is superimposed on the full game tree, and examines enough nodes to allow a player to determine what move to make.
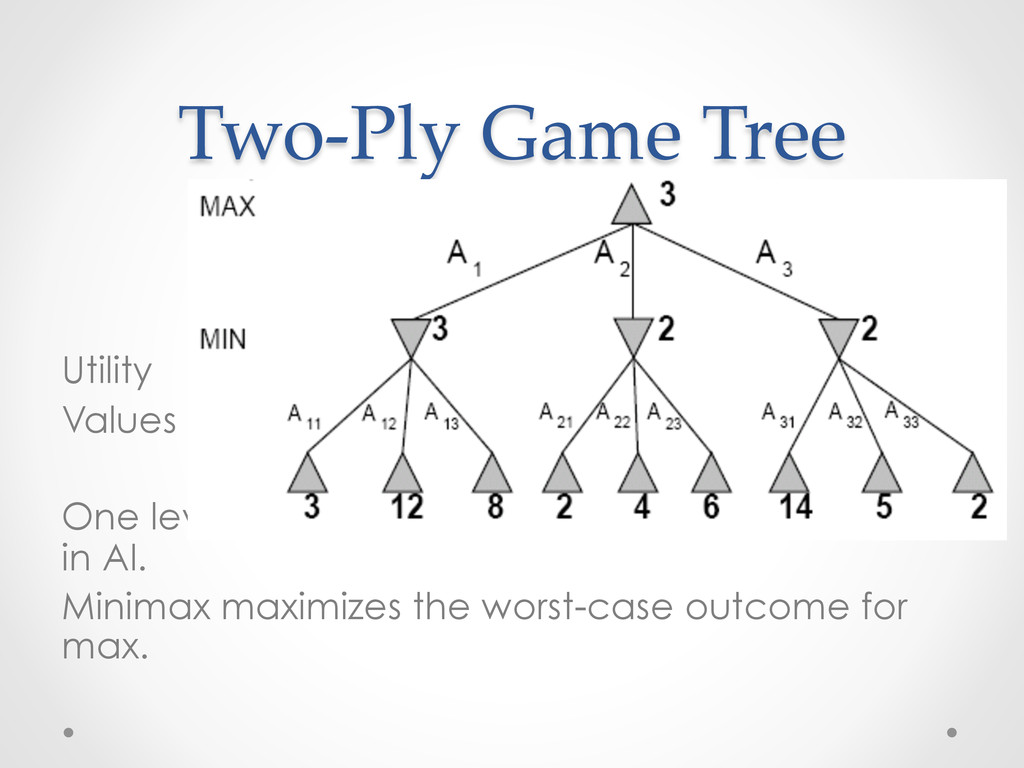
contingent strategy assuming an infallible MIN opponent. • Namely, we assume that both players play optimally !! • Given a game tree, the optimal strategy for MAX can be determined by using the minimax value of each node: MINIMAX-VALUE(s)= UTILITY(s) If TERMINAL-TEST(s) maxa ∈ Action(s) MINIMAX(RESULTS(s,a)) If PLAYER(s)=MAX mina ∈ Action(s) MINIMAX(RESULTS(s,a)) If PLAYER(s)=MIN
state in game V⇓MAX-VALUE(state) return the action in ACTIONS(state) with value v function MAX-VALUE(state) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v ß ∞ for each a in ACTIONS(state) do v ß MAX(v, MIN-VALUE(RESULT(s,a))) return v function MIN-VALUE(state) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v ß ∞ for each a in ACTIONS(state) do v ⇓ MIN(v, MAX-VALUE(RESULT(s,a))) return v
that minimax search has to examine is exponential to the depth of the tree • Solution: Do not examine every node • Alpha-beta pruning: o Alpha = value of best choice (i.e highest-value) found so far at any choice point along the MAX path o Beta = value of best choice (i.e lowest-value) found so far at any choice point along the MIN path
current state in game V⇓MAX-VALUE(state, -∞, +∞) return the action in ACTIONS(state) with value v function MAX-VALUE(state, α, β) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v ß ∞ for each a in ACTIONS(state) do v ß MAX(v, MIN-VALUE(RESULT(s,a), α, β)) if v >= β then return v α ß MAX(α, v) return v function MIN-VALUE(state, , α, β) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v ß+ ∞ for each a in ACTIONS(state) do v ß MIN(v, MAX-VALUE(RESULT(s,a), α, β)) if v <= α then return v β ß MIN(β, v) return v
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}