How Delivery Hero uses Spot Instances in production. The caveats of running on spots can teach you a great deal about the resiliency of your applications.
orders a week Workloads across 4 continents in 3 AWS regions Typically a few hundred Kubernetes nodes running for web and worker workloads Logistics Tech in Delivery Hero
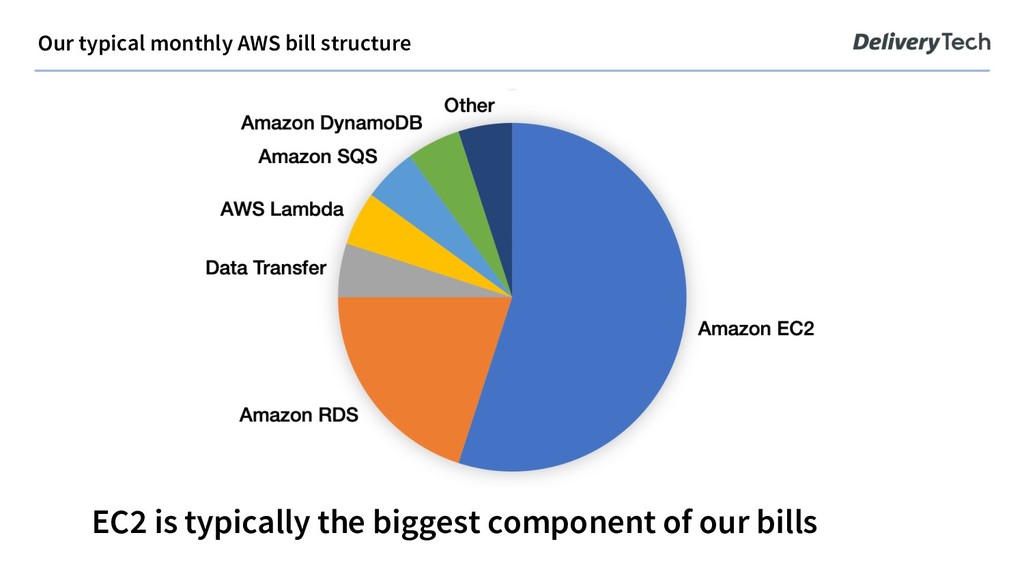
real- time apps, Python, R and various solvers for batch tasks Mostly Amazon RDS for PostgreSQL and Amazon DynamoDB for persistence Kubernetes deployments currently transitioning from kops to Amazon EKS, usually 1-2 minor versions behind Logistics Tech in Delivery Hero
be less elastic The business it too volatile for capacity predictions Our workloads change over time unpredictably (memory vs. CPU intensive) … We use them for Kubernetes masters (at least until we’re migrated to EKS) Why not Reserved Instances?
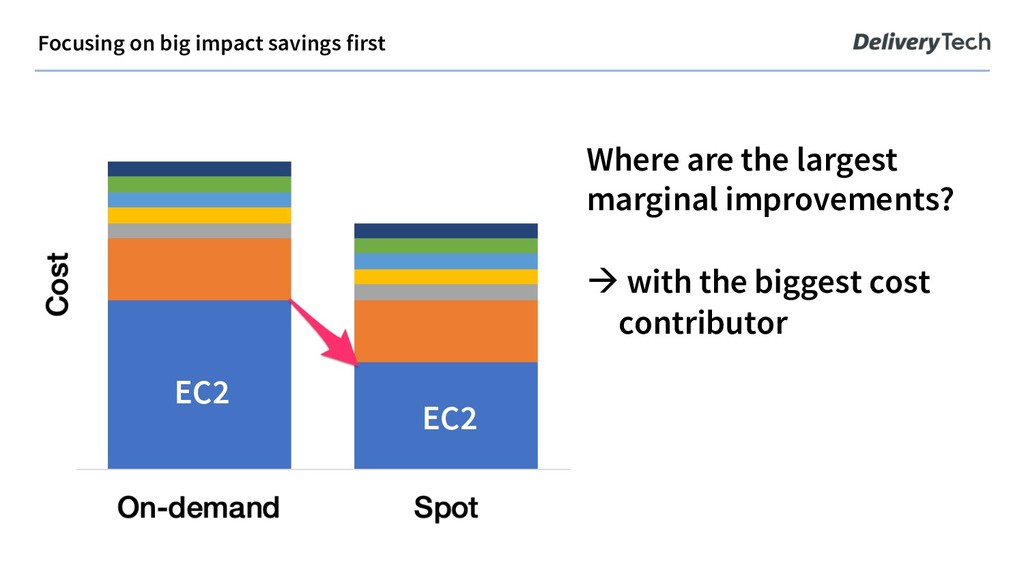
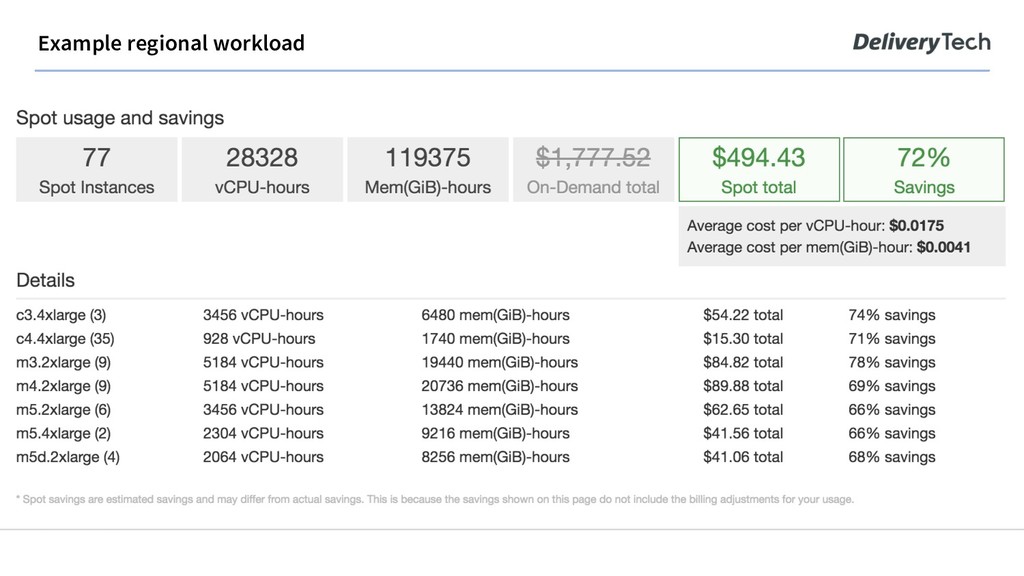
there is a floating market price at which instance types are available. This price is typically less than 50% cheaper than the list price. The catch? 1. AWS can take the instance anytime from you with a 2min warning, if it’s needed elsewhere. 2. Some of your preferred instance types can be sold out.
an AZ and instance type. If you choose 2 instance types in 3 AZs, you are bidding in 6 different instance spot markets (pools). The more pools you specify, the lower the chance of not being able to maintain target capacity of a fleet.
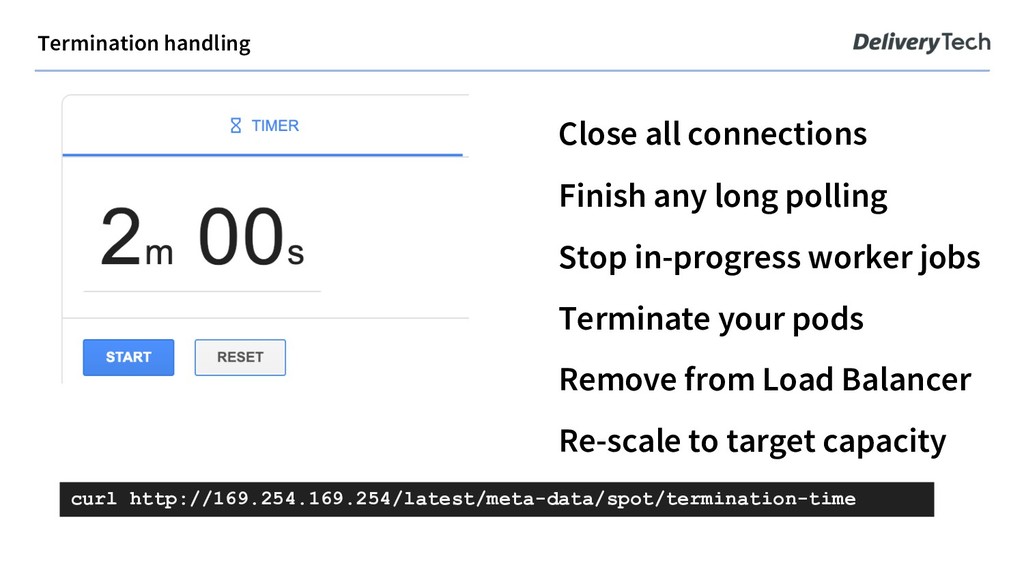
in-progress worker jobs Terminate your pods Remove from Load Balancer Re-scale to target capacity curl http://169.254.169.254/latest/meta-data/spot/termination-time
à abruptly terminated connections, stuck jobs Too much of target capacity being collocated on terminated nodes à too many pods of a deployment being affected New capacity not starting fast enough à a lot of apps starting at the same time can cause CPU starvation
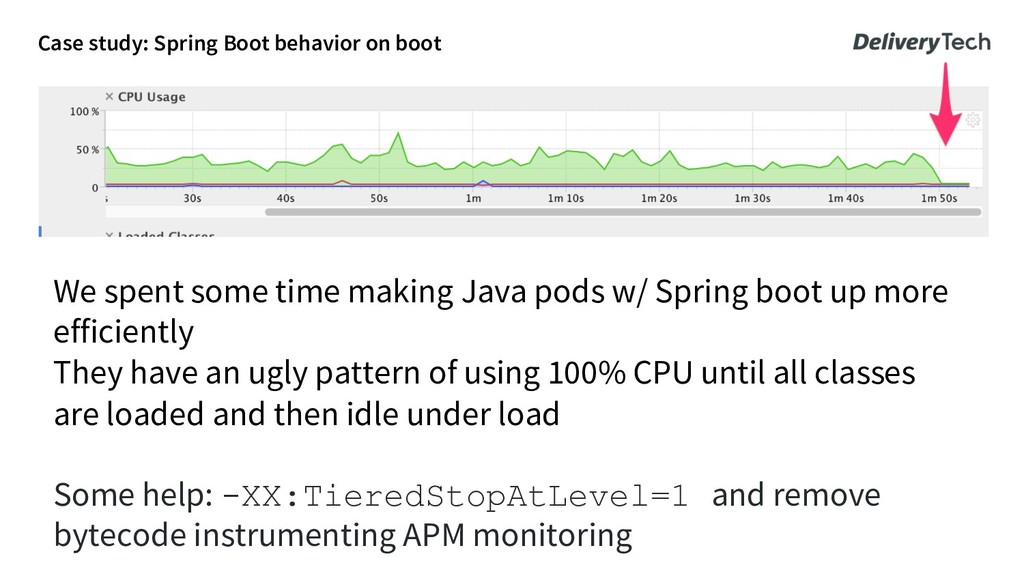
up more efficiently They have an ugly pattern of using 100% CPU until all classes are loaded and then idle under load Some help: -XX:TieredStopAtLevel=1 and remove bytecode instrumenting APM monitoring Case study: Spring Boot behavior on boot
upon seeing the notice. Optional Slack notification to give you a log to correlate monitoring noise / job disruptions with terminations. github.com/helm/charts/tree/master/incubator/kube-spot-termination-notice-handler (don’t worry, you’ll find all the links on the last slide) Spot Termination Notice Handler DaemonSet
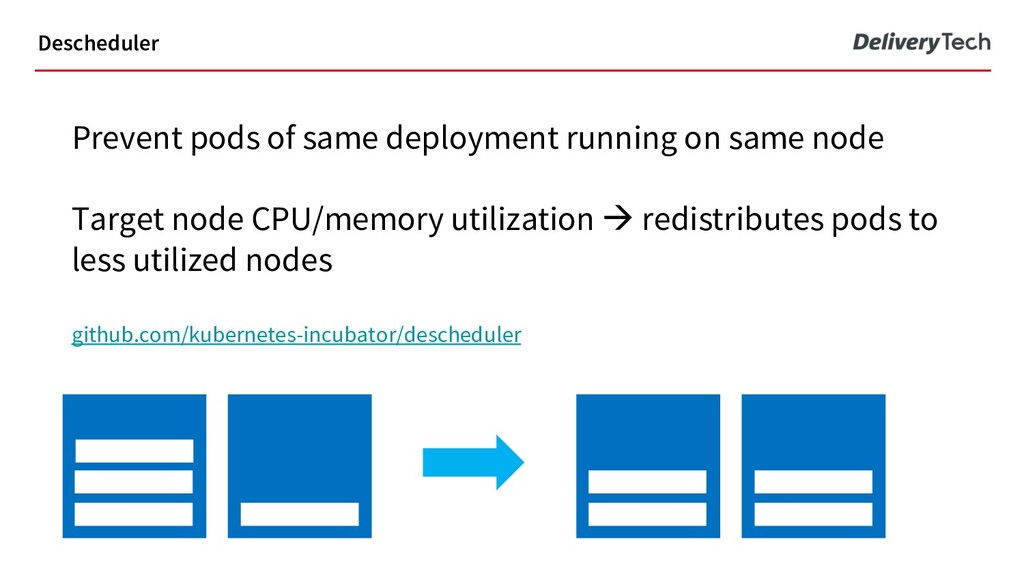
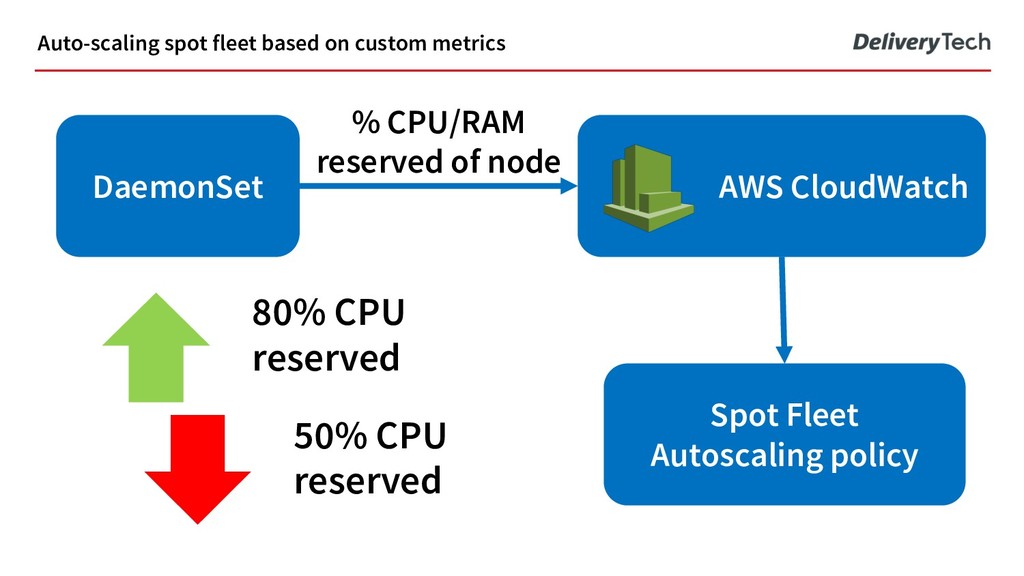
strategies in Delivery Hero: 1. Scaling spot fleet based on CPU/RAM reservations, not usage 2. Overprovisioning using PodPriority github.com/helm/charts/tree/master/stable/cluster-overprovisioner Auto-scaling strategy
framework for distributed and concurrent apps The volatility of spots forced us to fix very broken cluster formation and split brain situations Case Study: beyond stateless apps, resiliency with stateful components
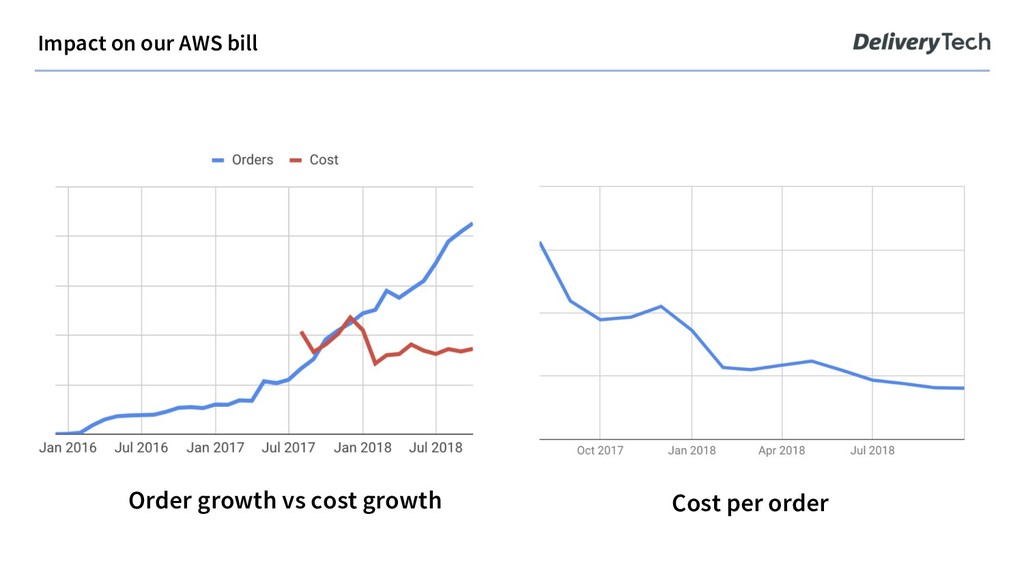
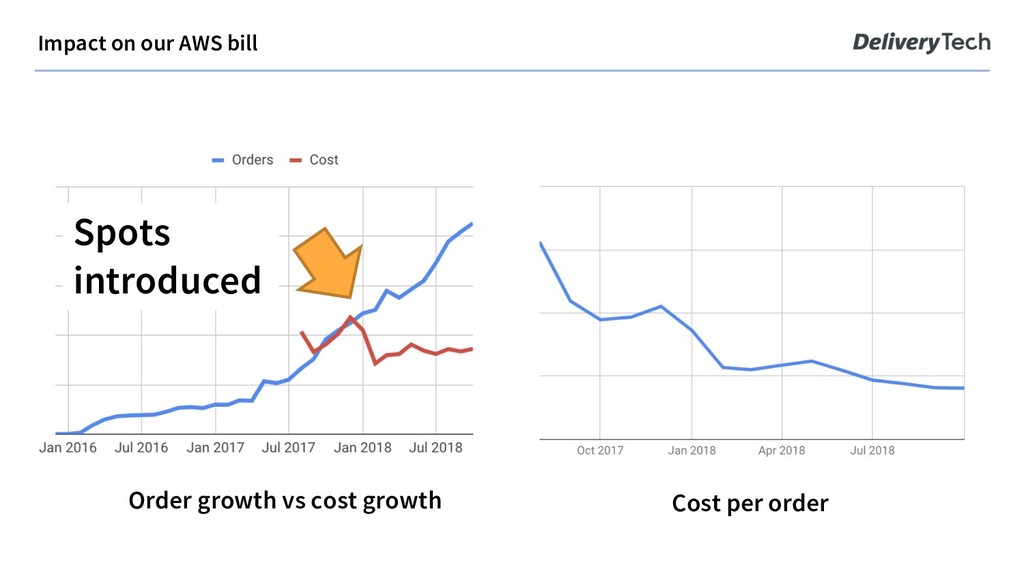
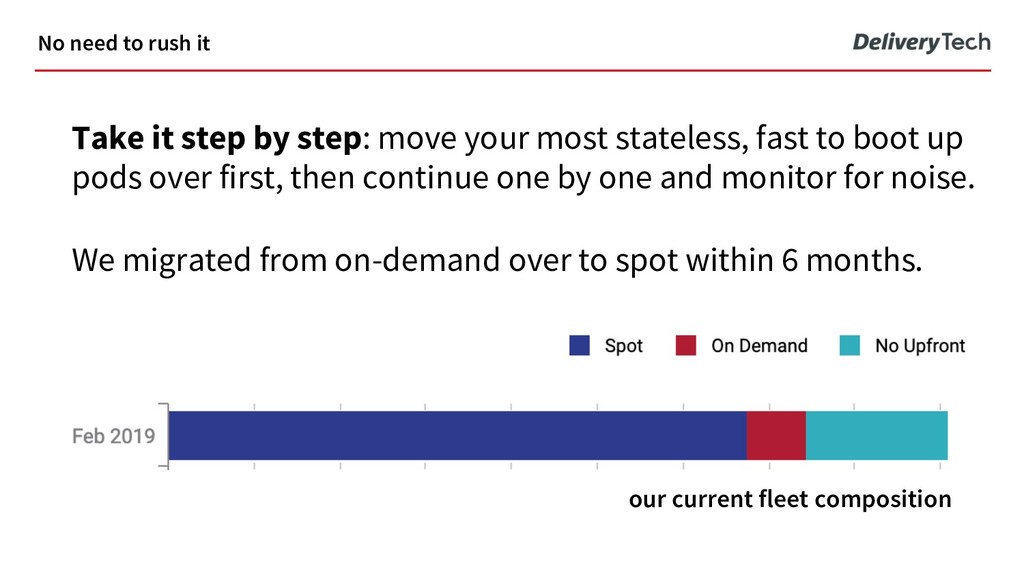
to boot up pods over first, then continue one by one and monitor for noise. We migrated from on-demand over to spot within 6 months. No need to rush it our current fleet composition
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}