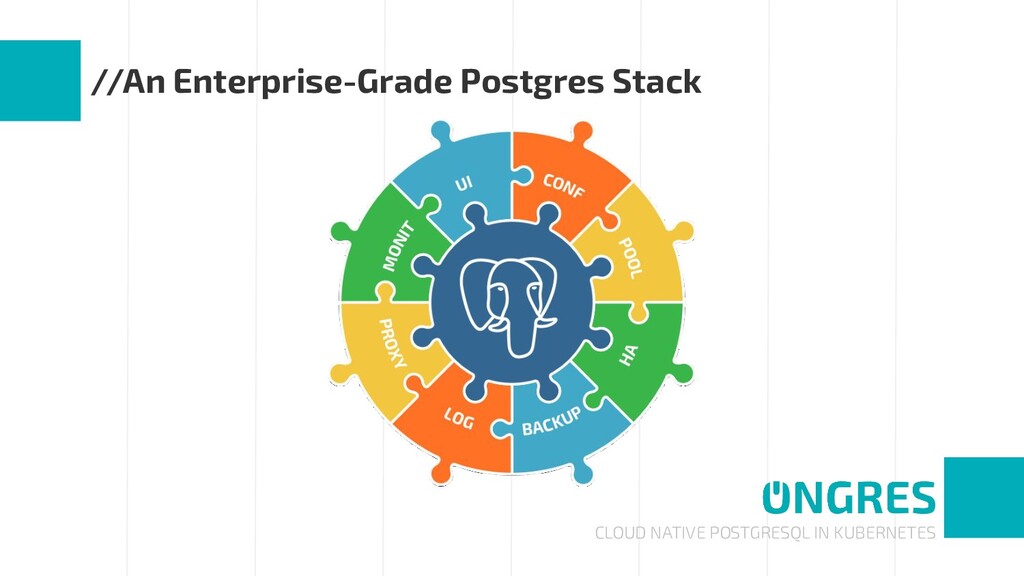
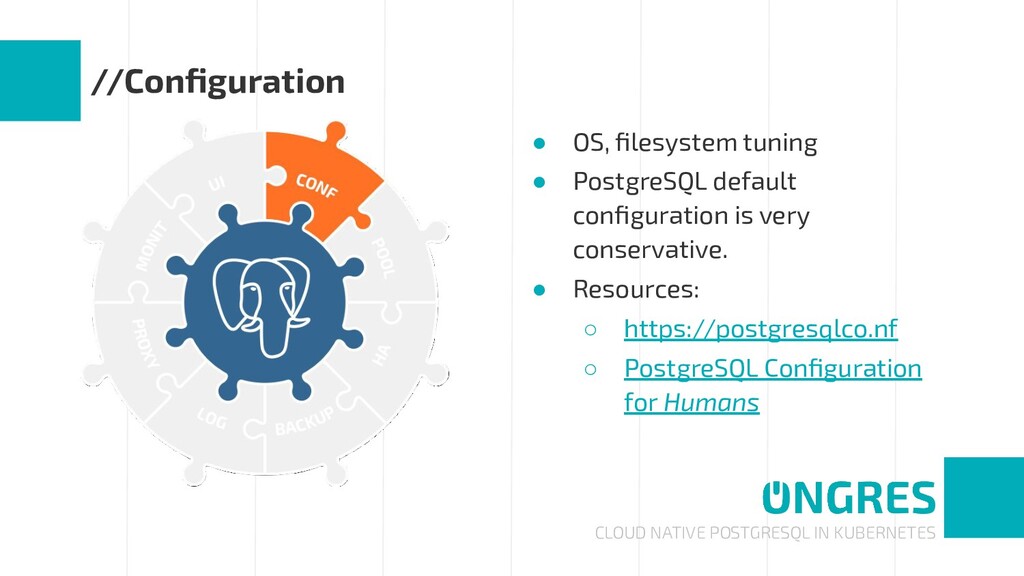
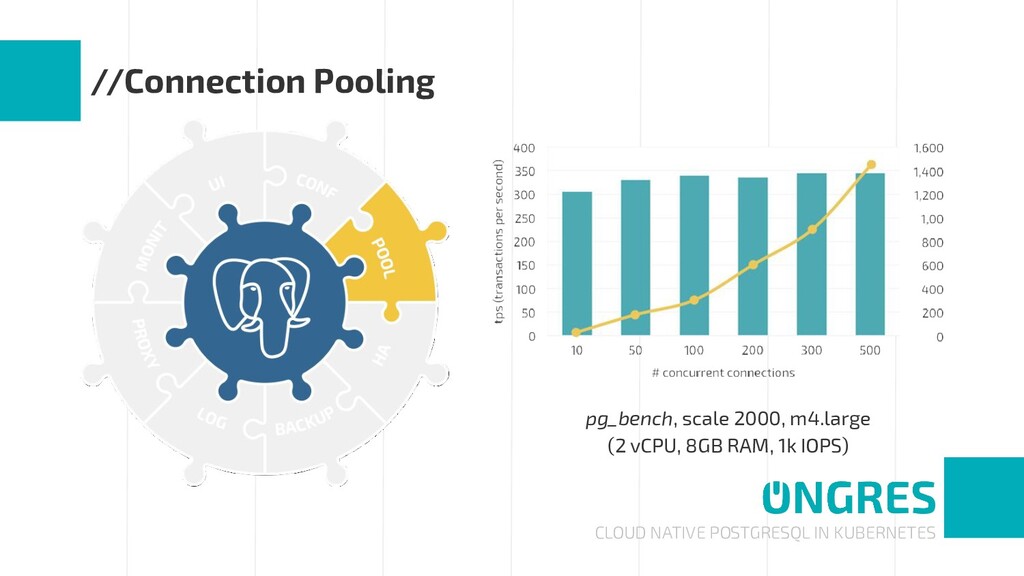
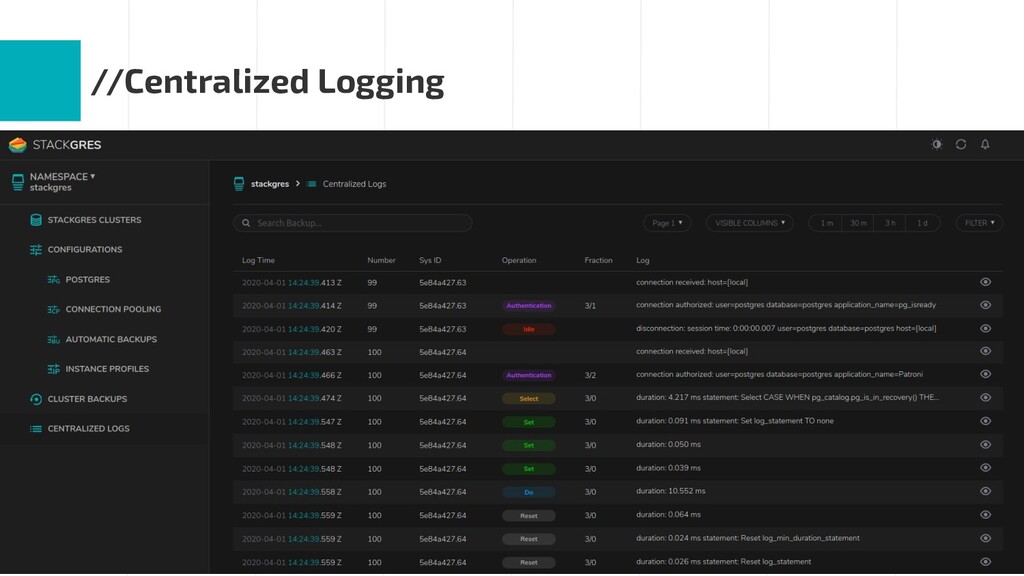
An enterprise-grade PostgreSQL requires many complementary technologies to the database core: high availability and automated failover, monitoring and alerting, centralized logging, connection pooling, etc. That is, a stack of components around PostgreSQL.
Kubernetes has enabled a new model to deploy software abstracting away the infrastructure. However, containers are not lightweight VMs, and the packing of software paradigms that work on VMs are not valid on containers/Kubernetes. How should be PostgreSQL and its stack be deployed on Kubernetes?
Enter StackGres. An open source software that is the result of re-engineering PostgreSQL to become cloud native. Join this talk to learn and see.
Speaker:
Alvaro Hernandez
I am a passionate database and software developer. “Serial” entrepreneur, after several unsuccessful ventures, I founded and work as the CEO of OnGres, a PostGres startup set to disrupt the database market. I have been dedicated to PostgreSQL and R&D in databases since two decades ago.
In my heart, I am an open source advocate and developer. I am a well-known member of the PostgreSQL Community, to which I have contributed founding the non-profit Fundación PostgreSQL and the Spanish PostgreSQL User Group. You will find on this website a list of my open source (code) contributions, as well as my work for open source communities, like PostgreSQL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}