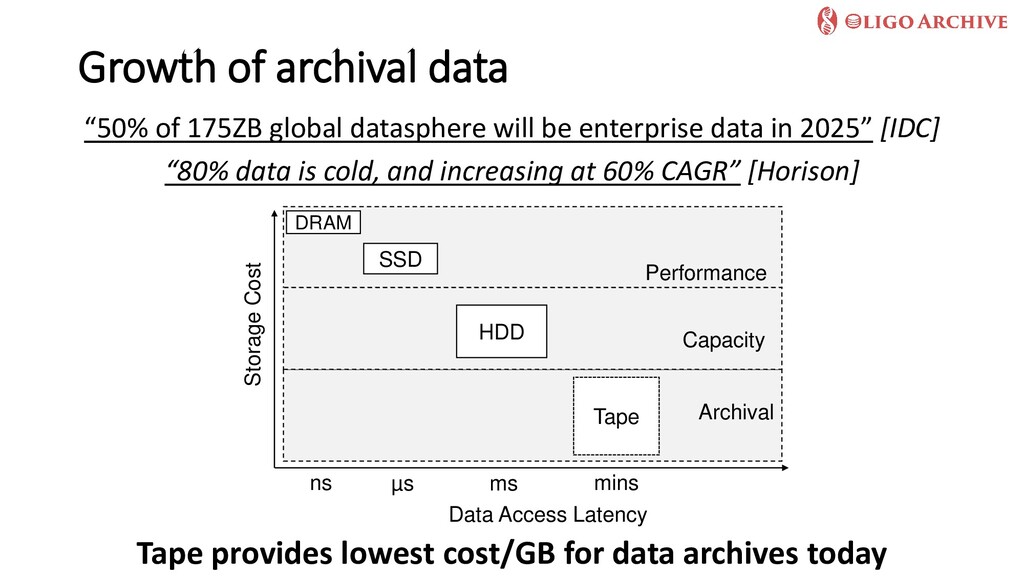
Today, most, if not all, enterprises in our society are driven by data. If data is the oil that fuels the metaphorical AI vehicle, storage technologies are the cog that keep the wheel spinning. For decades, we wanted fast storage devices that can quickly deliver data, and storage technologies evolved to meet this requirement. As data-driven decision making becomes an integral part of enterprises, we are increasingly faced with a new need-–one for cheap, long-term storage devices that can safely store the data we generate for tens or hundreds of years to meet legal and regulatory compliance requirements.
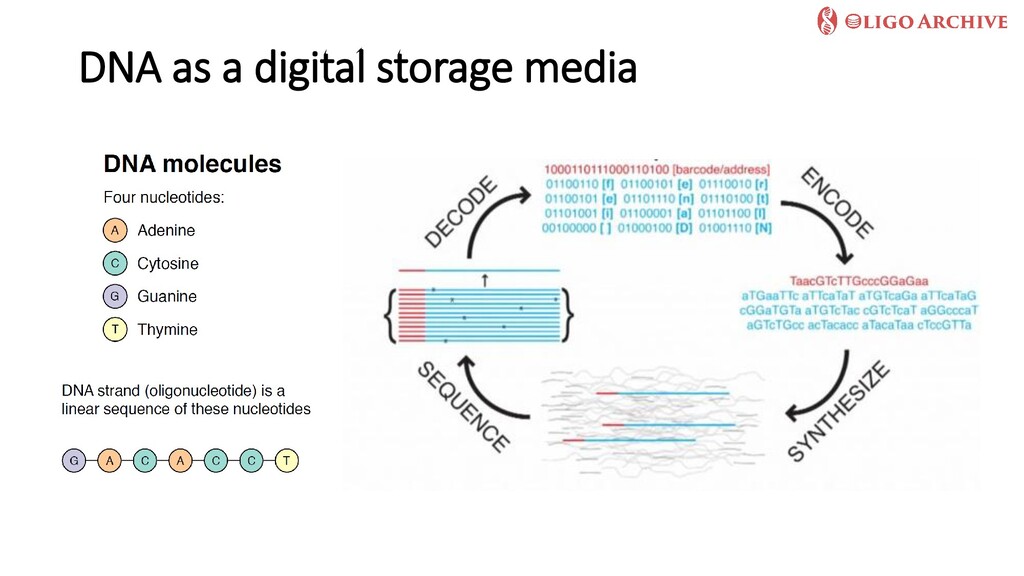
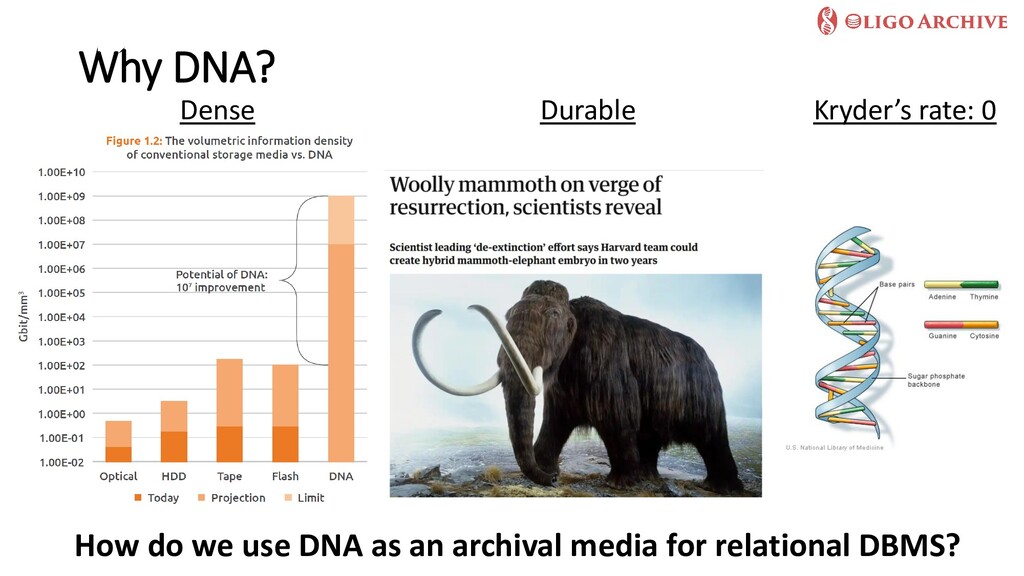
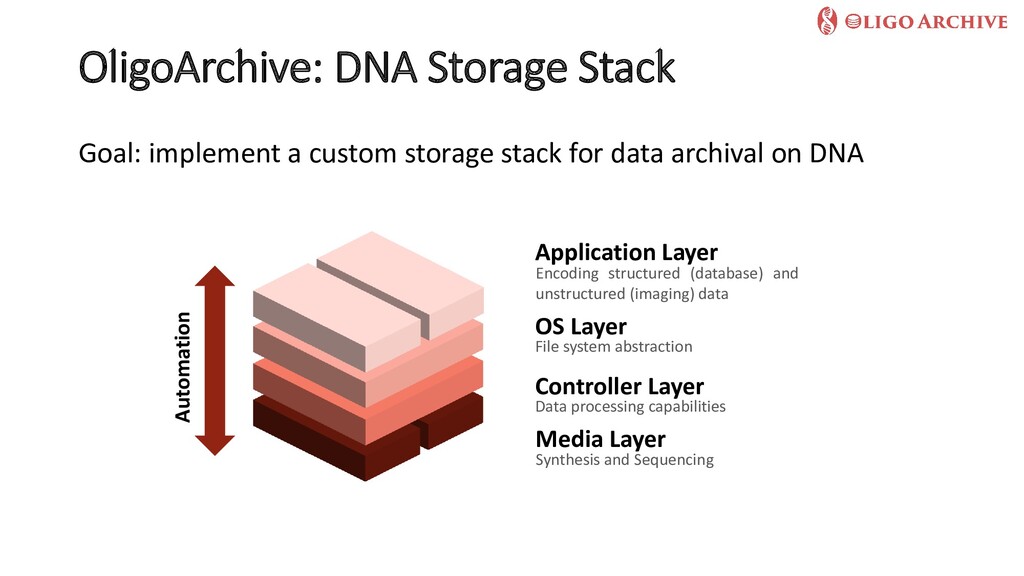
In this talk, we will first explore recent trends in the storage hardware landscape that clearly show that all current storage media face fundamental limitations that threaten our ability to store, much less process, the data we generate over long time frames. We will then focus on a radically new storage media that has received quite some attention recently -synthetic Deoxyribonucleic acid (DNA). After highlighting the pros and cons of using DNA--a biological building block--as a digital storage media, I will present our recent work in the EU-funded Future and Emerging Technologies (FET) project OligoArchive, that focuses on overcoming challenges in using DNA as a deep archival tier of PostgreSQL databases.
Speaker name:
Dr. Raja Appuswamy
Speaker bio:
Raja Appuswamy is an Assistant Professor in the Data Science department at EURECOM--a Grandes Écoles located in the sunny Sophia Antipolis tech-valley of southern France. Previously, he was as a Researcher and Visiting Professor at EPFL, Switzerland, a Visiting Researcher in the Systems and Networking group at Microsoft Research, Cambridge, and as a Software Development Engineer in the Windows 7 kernel team at Microsoft, Redmond.
He received his Ph.D in Computer Science from the Vrije Universiteit, Amsterdam, where he worked under the guidance of Prof. Andrew S. Tanenbaum on designing and implementing a new storage stack for the MINIX 3 microkernel operating system. He also holds dual Masters degrees in Computer Science and Agricultural Engineering from the University of Florida, Gainesville.
{kind=link}
{kind=link}
![“Kryder’s rate of tape: 31%/YR average” [Fontana] Problems with tape](https://files.speakerdeck.com/presentations/e59abd159bcd450b9f9636bddd0ff984/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}