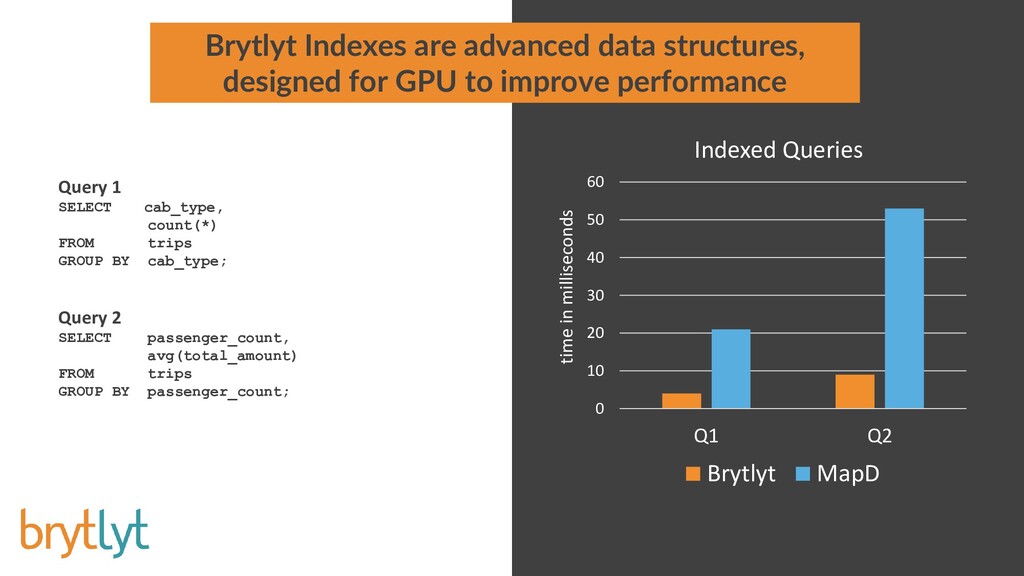
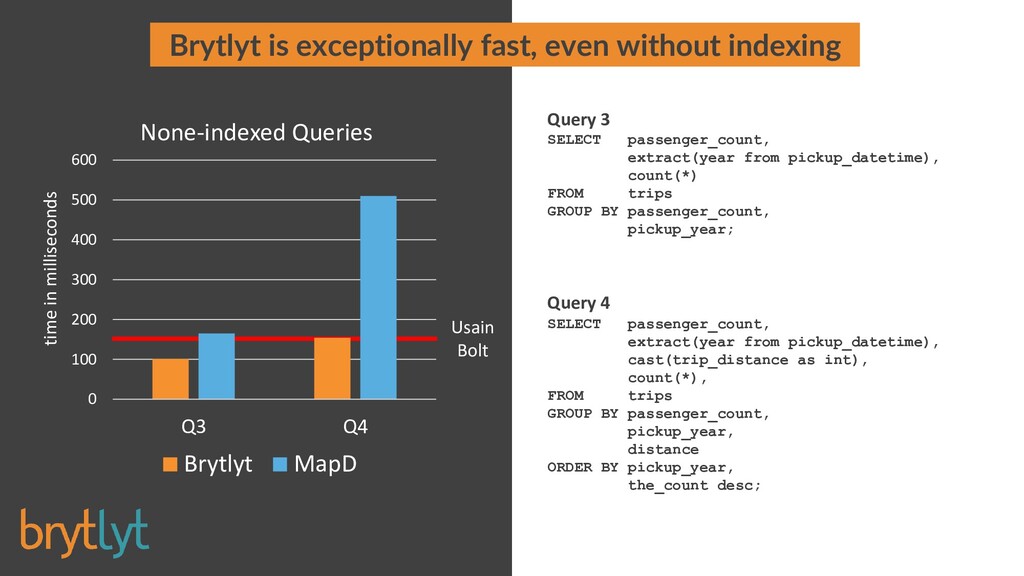
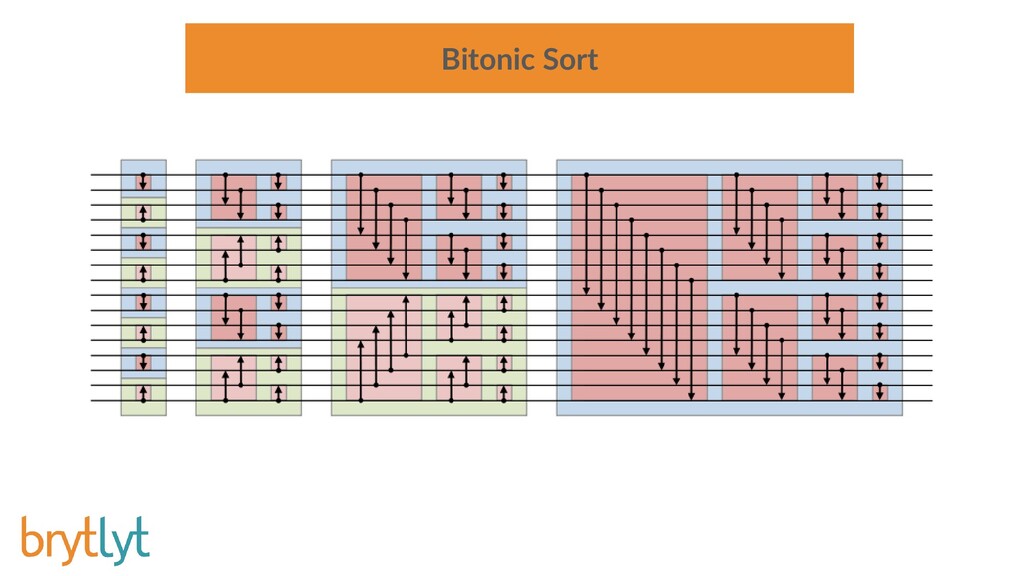
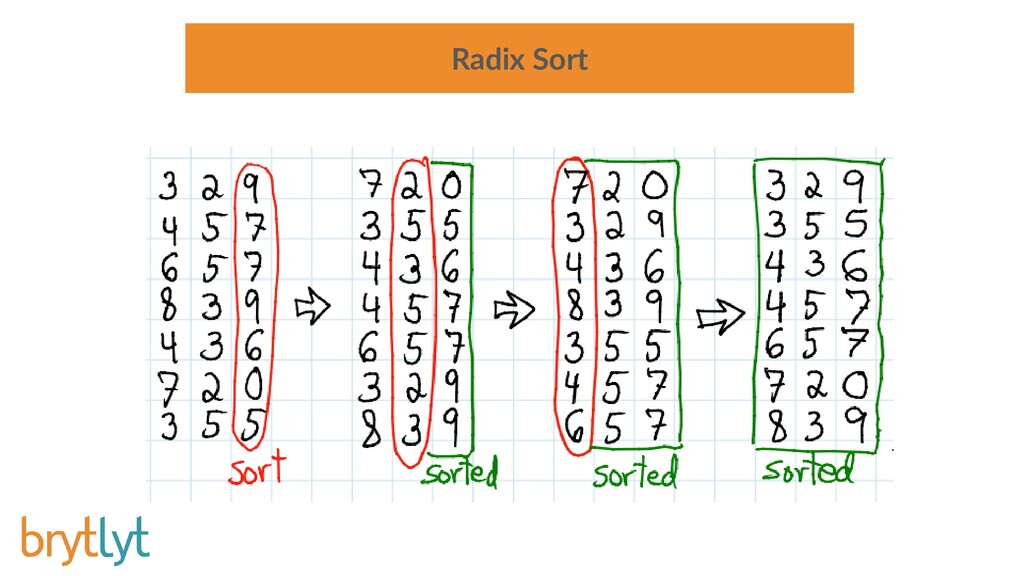
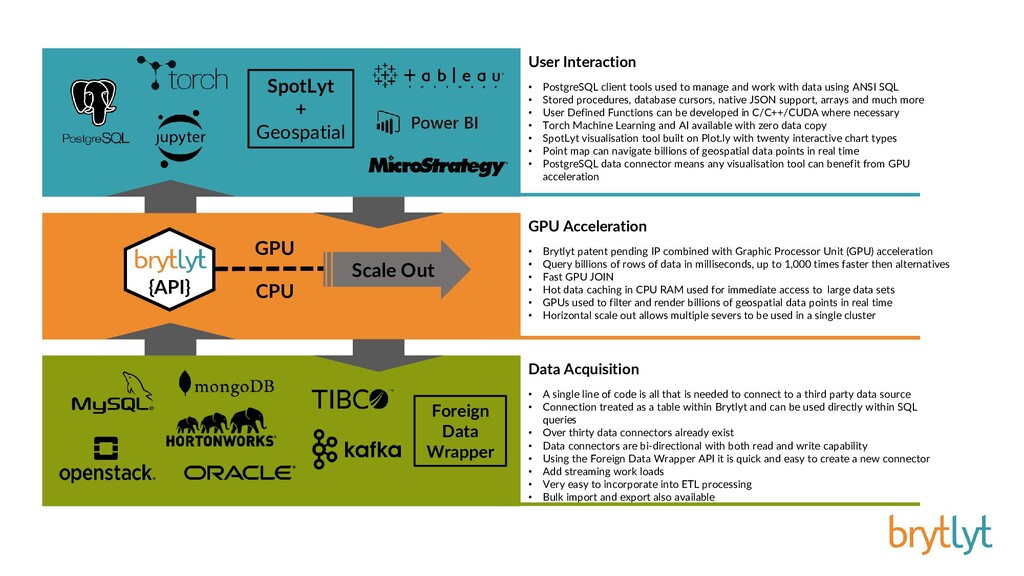
Millisecond response times for large join and aggregation type queries on billion row datasets is possible when tapping the power of Graphics Processor Units. Integrating this GPU accelerated data engine into PostgreSQL provides a solution that is familiar and easy to use and neatly drops into existing investments in software and technology.
Speaker: Richard Heyns
Richard is the Founder and CEO of Brytlyt and led the original research in bringing database operations to GPU. His background is a BSc in Engineering and he has over twenty years’ experience building and leading Business Intelligence and Data Warehousing solutions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
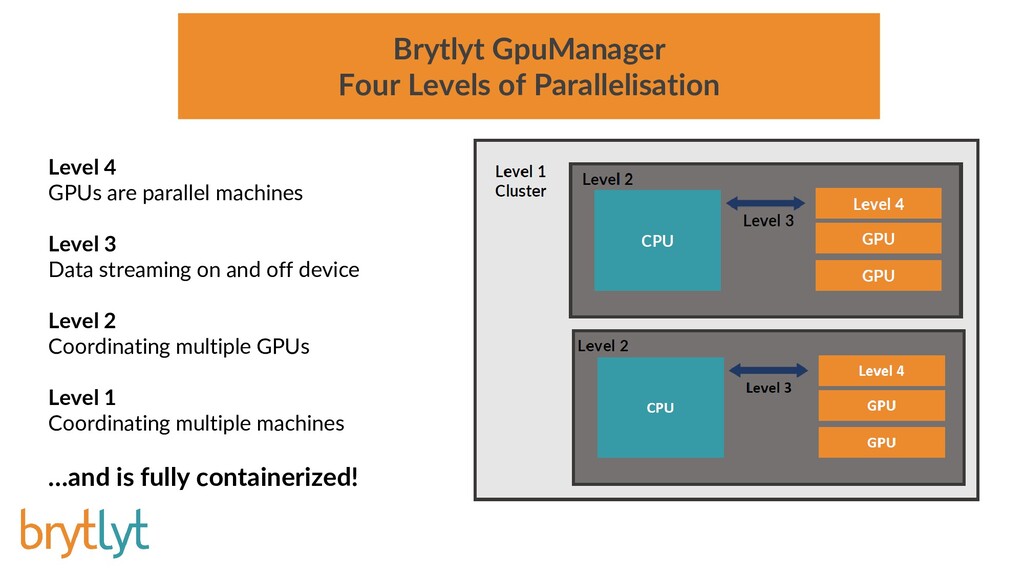{kind=link}
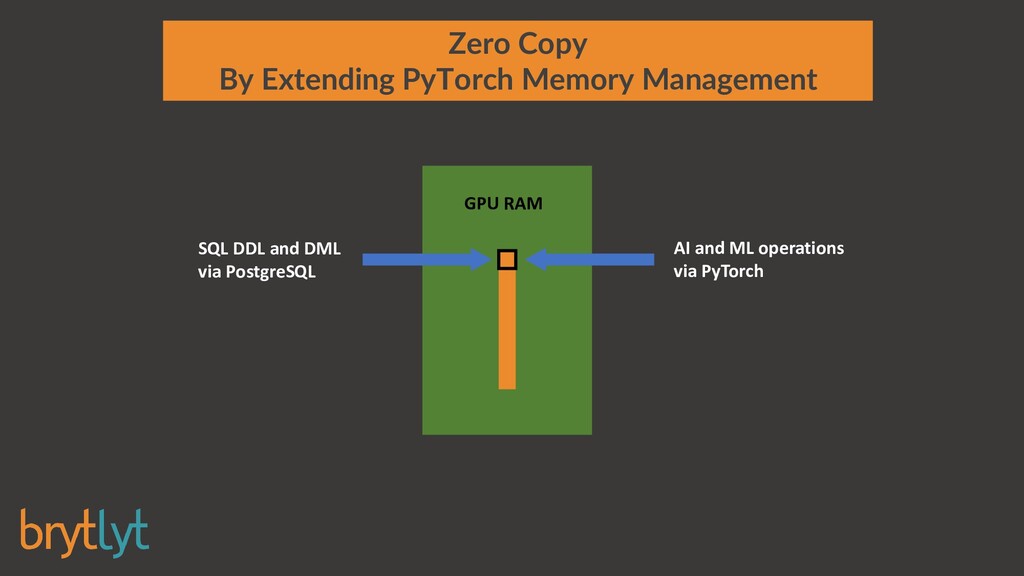{kind=link}
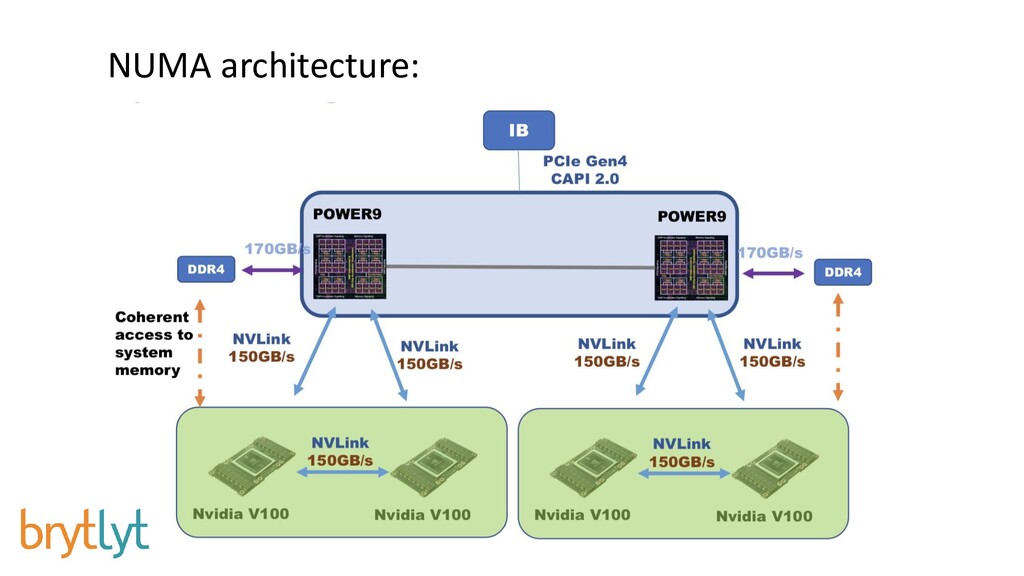{kind=link}
{kind=link}
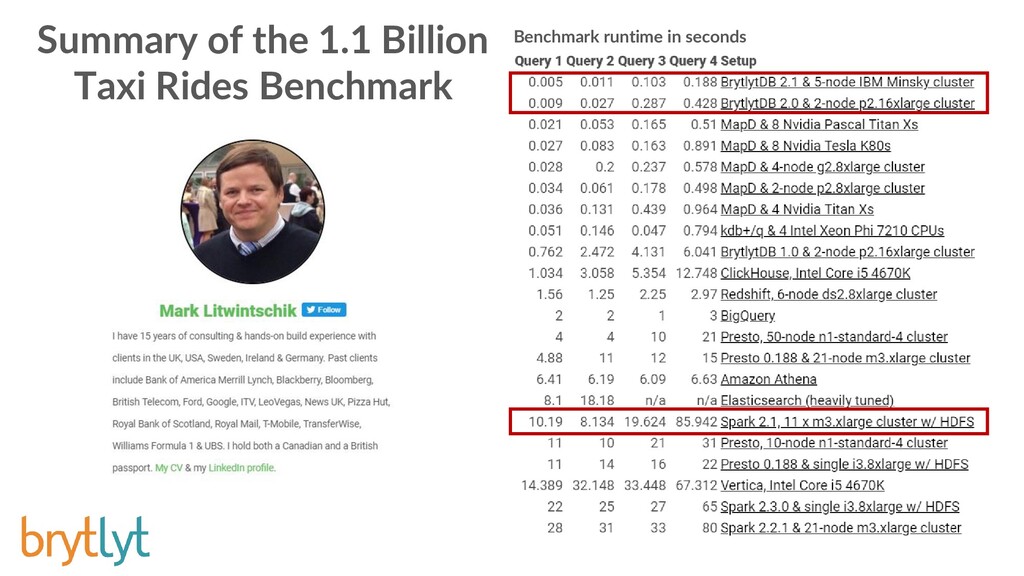{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
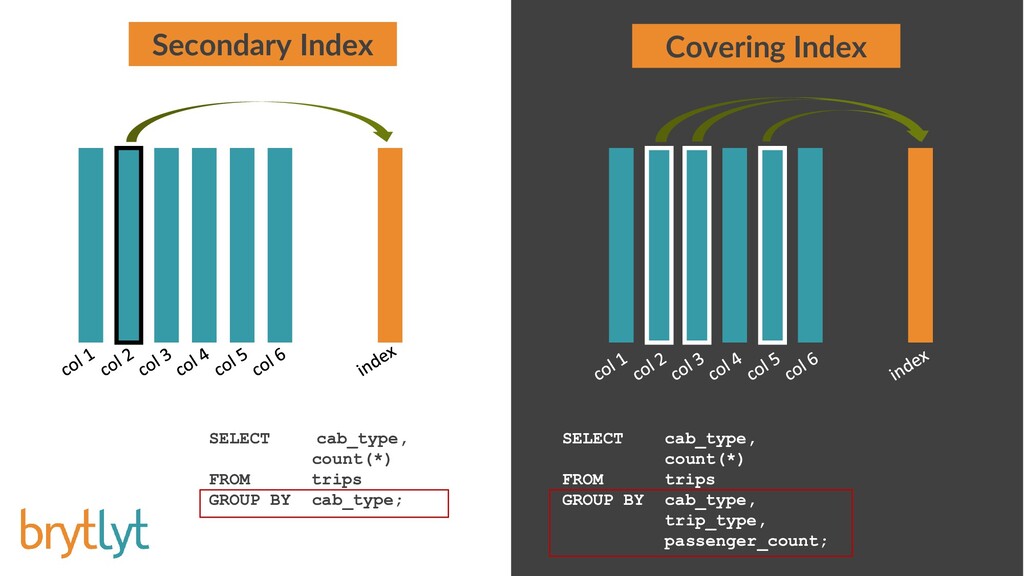{kind=link}
{kind=link}
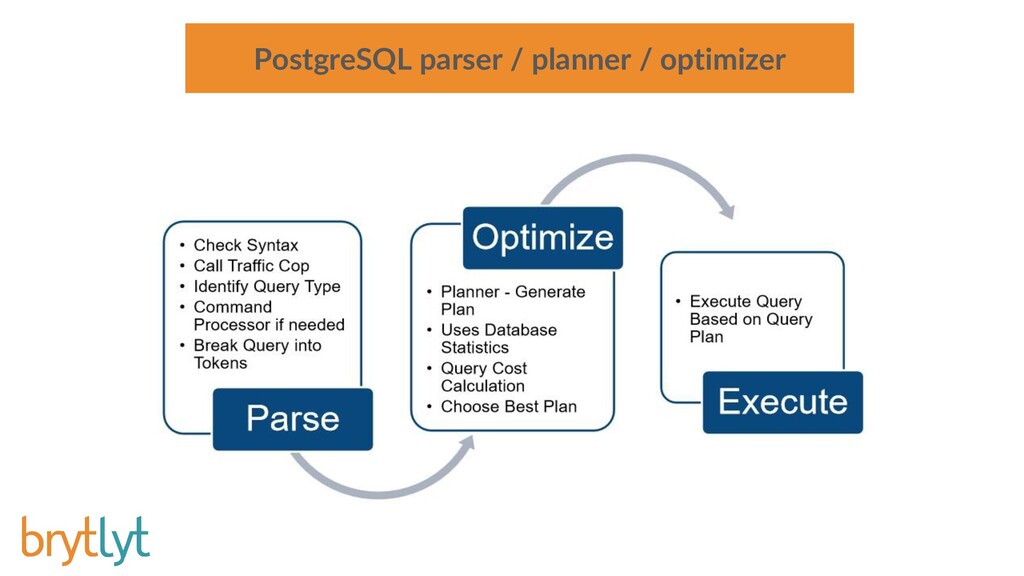{kind=link}
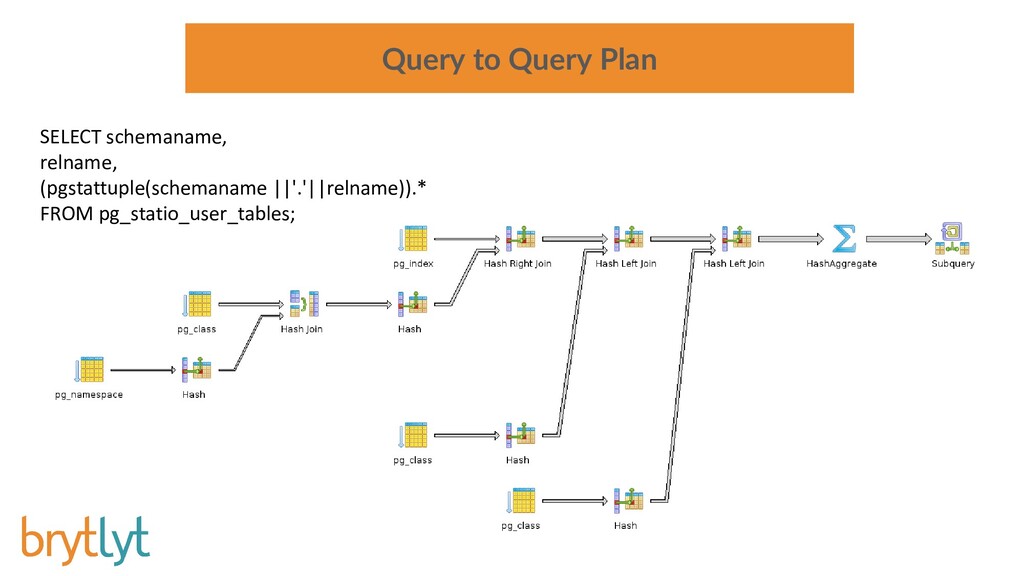{kind=link}
{kind=link}
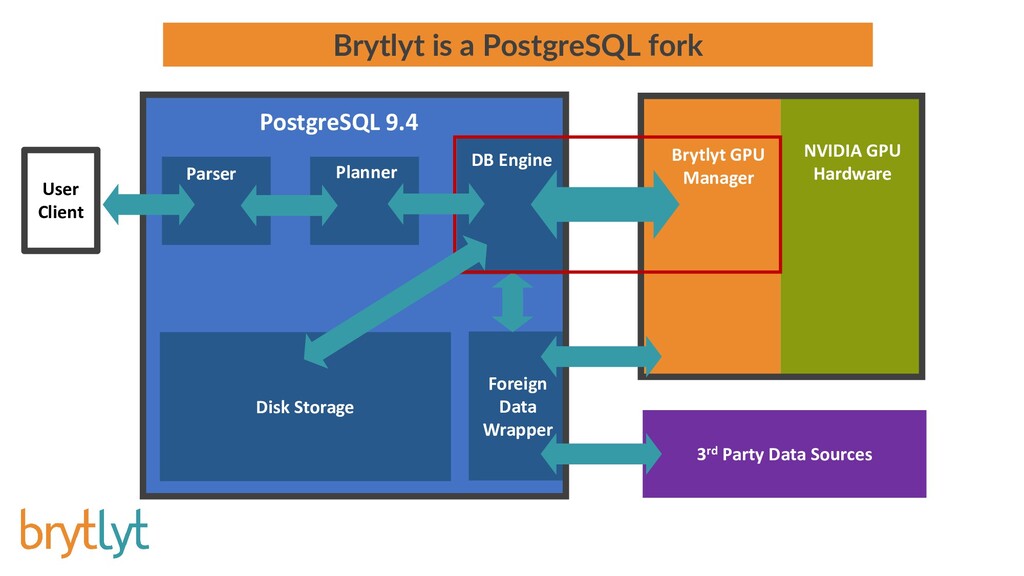{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}