Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データルーター?Vector/Getting Started with Vector
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
watawuwu
August 07, 2019
Technology
1.1k
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データルーター?Vector/Getting Started with Vector
watawuwu
August 07, 2019
More Decks by watawuwu
See All by watawuwu
Prometheusでデータの水平分割を試みる/Let's split prometheus data
watawuwu
0
11k
KubernetesでWebアプリケーションをリリースするまでに必要なものは/What you need with Kubernetes
watawuwu
10
1.9k
Thanosってどうですか?/Getting Started with Thanos
watawuwu
1
1.1k
Argo入門/Getting Started with Argo
watawuwu
0
1.1k
Concourse入門 / Concourse Getting Started
watawuwu
3
2.3k
Other Decks in Technology
See All in Technology
最高のシステムプロンプトを作るためにフィードバック機能を導入した話
alchemy1115
1
250
Pavlokで始める電撃駆動開発
sgrsn
0
130
オートマトンと字句解析でRoslynを読む
tomokusaba
0
130
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
350
1台から試せる!Edge IoTを使った位置情報の活用設計【SORACOM Discovery 2026】
soracom
PRO
0
110
信頼できるテスティングAIをどう育てるか?
odan611
0
170
人手不足への挑戦:車両保全を支えるIoTとクラウド内製化の道【SORACOM Discovery 2026】
soracom
PRO
0
170
PLaMoを毎日の開発で使い育てていく
pfn
PRO
0
150
20260801_スクフェス大阪
kgnkhkr
0
130
もう一度考える SRE チームの作り方・育て方 / Rethinking SRE #1: Building and Growing SRE Teams
rrreeeyyy
1
170
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
7
2.8k
Atlassian Cloudサポート業務でのAIエージェント活用事例
smt7174
0
150
Featured
See All Featured
Faster Mobile Websites
deanohume
310
32k
It's Worth the Effort
3n
188
29k
HDC tutorial
michielstock
2
760
Building an army of robots
kneath
306
46k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
360
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
Speed Design
sergeychernyshev
33
2k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Transcript
Getting Started with Vector Cloud native meetup tokyo #9 This
document includes the work that is distributed in the Apache License 2.0
profile: name: Wataru Matsui org: [ Z Lab, 3bi.tech ]
twitter: @watawuwu
• What’s Vector? • Usage • VS ... • Roadmap
• Conclusions Agenda
What’s Vector? https://vector.dev
Logs, Metrics & Events Router Is like Fluentd?
Developed by Timber.io https://timber.io
Feature • Log, Metrics, or Events • Agent Or Service
• Fast • Correct • Clear Guarantee • Vendor Neutral • Easy To Deploy • Hot Reload
• Fluentd • Fluent Bit • Filebeat • Logstash Similar
tool
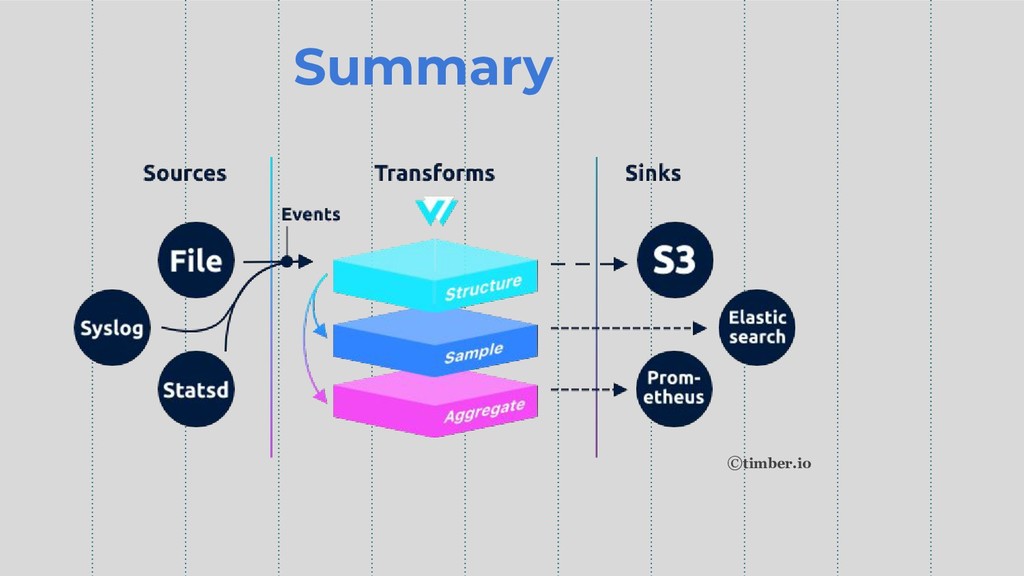
Summary ©timber.io
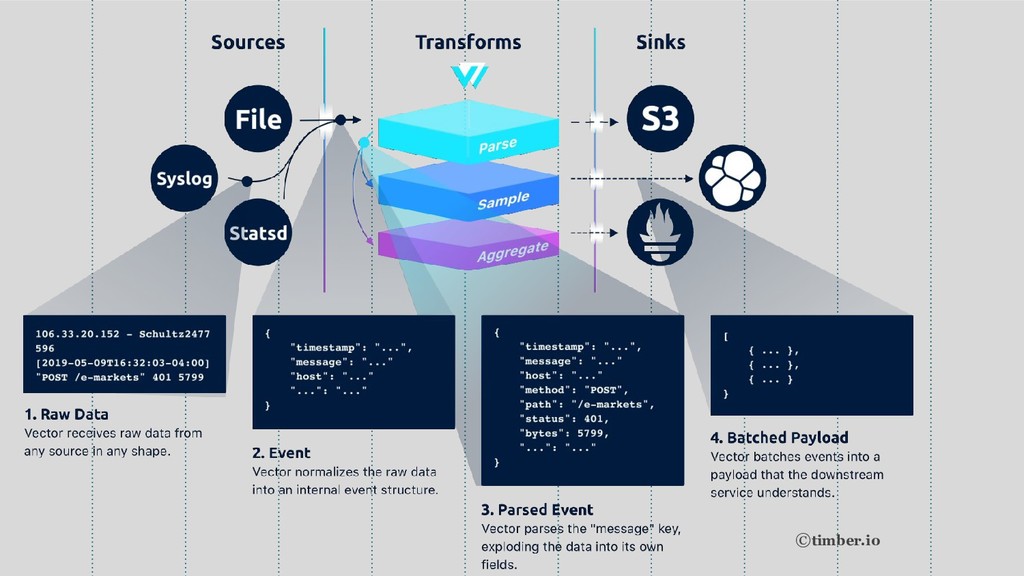
©timber.io
Topologies: Distributed ©timber.io
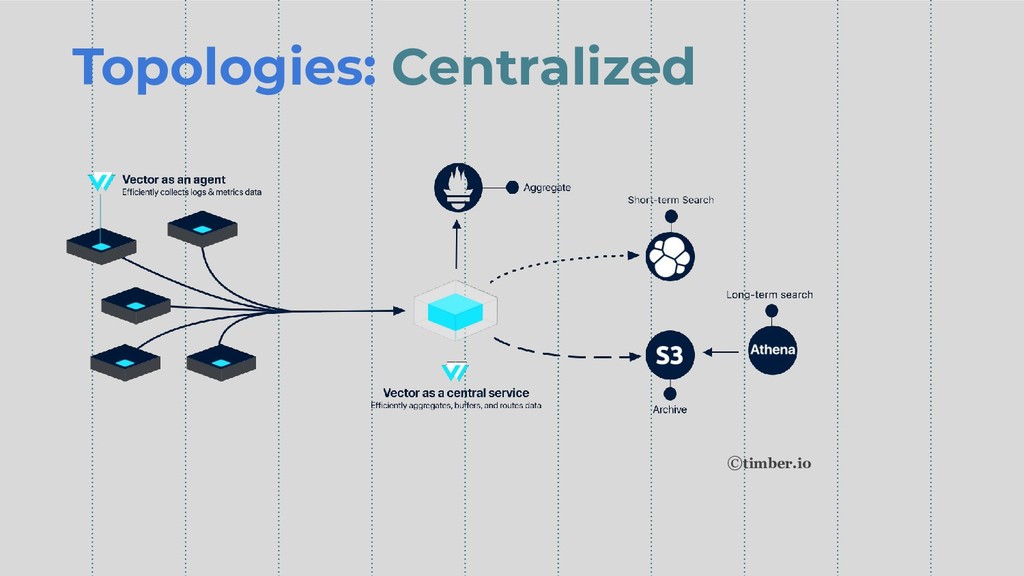
Topologies: Centralized ©timber.io
Topologies: Stream-Based ©timber.io
How to use Vector
Source types • file • statsd • syslog • tcp
• vector • stdin(debug)
[sources.my_file_source_id] # REQUIRED - General type = "file"
# must be: "file" include = ["/var/log/nginx/*.log"] exclude = [""] Source config
[sources.my_tcp_source_id] # REQUIRED - General type = "tcp"
# must be: "tcp" address = ["0.0.0.0:9000"] Source config
Sink types • aws ◦ cloudwatch_logs ◦ kinesis_streams ◦ s3
• elasticsearch • http • kafka • prometheus • splunk_hec • tcp • vector • console • blackhole(/dev/null)
[sinks.my_tcp_sink_id] # REQUIRED - General type = "tcp"
# must be: "tcp" input = ["my_tcp_source_id"] address = ["92.12.333.224:5000"] # OPTIONAL - Requests encoding = "json" # default, enum: "json", "text" Sinks config
[sinks.my_s3_sink_id] # REQUIRED - General type = "s3"
# must be: "s3" input = ["my_file_source_id"] bucket = "my-bucket" region = "ap-northeast-1" encoding = "ndjson" # enum: "ndjson", "text" # OPTIONAL - Requests key_prefix = "date=%F/" # default Sinks config
[sinks.my_prometheus_sink_id] # REQUIRED - General type = "prometheus"
# must be: "prometheus" input = ["my_log2metrics_source_id"] address = "0.0.0.0:9598" Sinks config
Transform types • Fileld ◦ add_fields ◦ remove_filed ◦ filed_filter
• Paser ◦ grok_parser ◦ json_parser ◦ regex_parser ◦ tokenizer • log_to_metric • sampler • lua • vector • console • blackhole(/dev/null)
[transforms.my_regex_trans_id] # REQUIRED - General type = "regex_parser" #
must be: "regex_parser" inputs = ["my_file_source_id"] regex = "^(?P<host>[\\w\\.]+) - (?P<user>[\\w]+) (?P<bytes_in>[\\d]+) \\[(?P<timestamp>.*)\\] \"(? P<method>[\\w]+) (?P<path>.*)\" (?P<status>[\\d]+) (?P<bytes_out>[\\d]+)$" # OPTIONAL - Types [transforms.my_regex_trans_id.types] status = "int" method = "string" bytes_in = "int" bytes_out = "int" Transform config
[transforms.my_prometheus_trans_id] # REQUIRED - General type = "log_to_metric" #
must be: "log_to_metric" inputs = ["my_file_source_id"] # OPTIONAL - Types [[transforms.my_regex_trans_id.metrics]] type = "counter" # enum: "counter", "gauge" field = "duration" increment_by_value = false name = "duration_total" labels = {host = "${HOSTNAME}", region = "us-east-1"} Transform config
[sources.logs] type = 'file' include = ['/var/log/*.log'] [transforms.tokenizer]
inputs = ['logs'] type = 'tokenizer' field_names = ["timestamp", "level", "message"] [transforms.sampler] inputs = ['tokenizer'] type = 'sampler' hash_field = 'request_id' rate = 10 [sinks.search] inputs = ['sampler'] type = 'elasticsearch' host = '123.123.123.123:5000' [sinks.backup] inputs = ['tokenizer'] type = 's3' region = 'ap-northeast-1' bucket = 'log-backup' key_prefix = 'date=%F' Vector config
VS
Vector FluentBit FluentD File to TCP 76.7MiB/s 35MiB/s 26.1MiB/s
Regex Parsing 13.2MiB/s 20.5MiB/s 2.6MiB/s TCP to HTTP 26.7MiB/s 19.6MiB/s <1MiB/s Performance report by Timber.io
Vector FluentBit FluentD Memory 188.1MiB 370MiB 890MiB CPU 1.51
1m avg 0.56 1m avg 0.57 1m avg Performance report by Timber.io
Don't trust the reports. Measure, Measure, Measure!
Measure using GKE • Kubernetes: v1.13.7 • Node x4 ◦
4 CPU ◦ 3.6 GB Memory ◦ 100 GB Storage(Standard) • Manifests ◦ https://github.com/watawuwu/vector-test
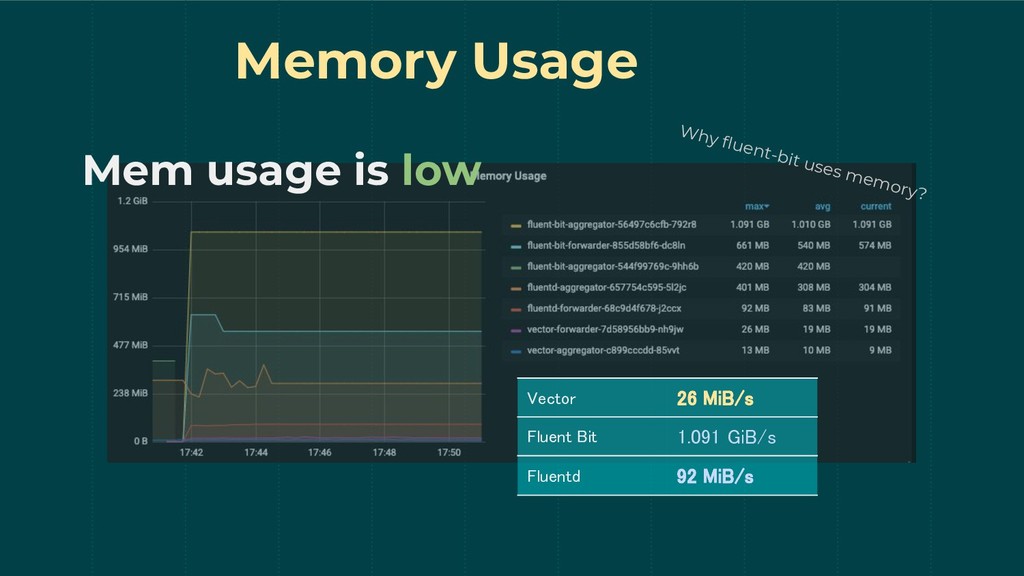
Memory Usage Mem usage is low Why fluent-bit uses memory?
Vector 26 MiB/s Fluent Bit 1.091 GiB/s Fluentd 92 MiB/s
CPU Usage CPU usage is high Vector 1.84 core Fluent
Bit 0.26 core Fluentd 1.25 core
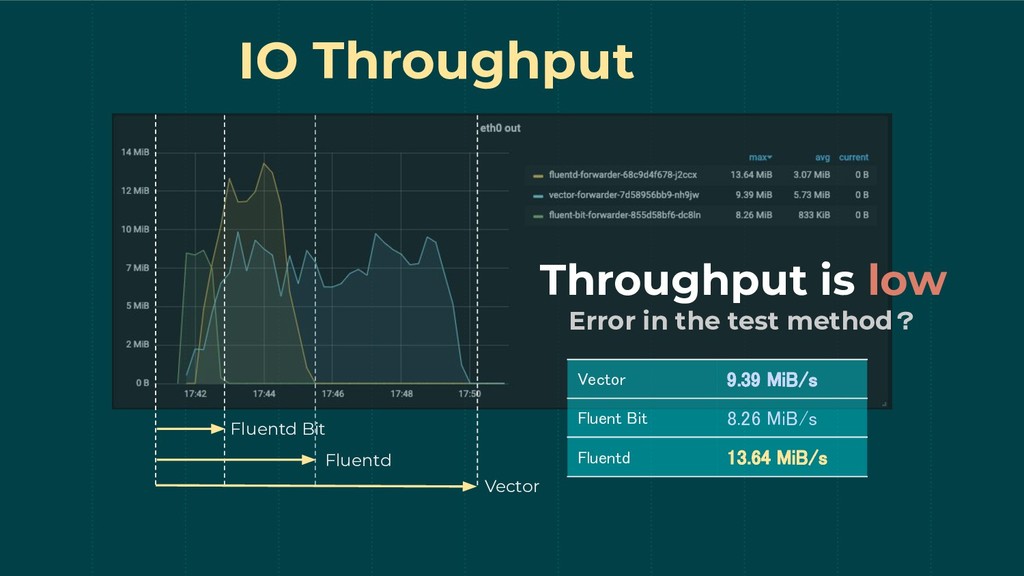
IO Throughput Vector Fluentd Fluentd Bit Throughput is low Error
in the test method? Vector 9.39 MiB/s Fluent Bit 8.26 MiB/s Fluentd 13.64 MiB/s
Roadmap
Roadmap • v0.4 Schemas(current) • v0.5 Stream Consumers • v0.6
Columnar Writing • v0.7 CLI • v0.8 Wire Level Tailing • v1.0 Stable => 2019/12 Release!!
Conclusions
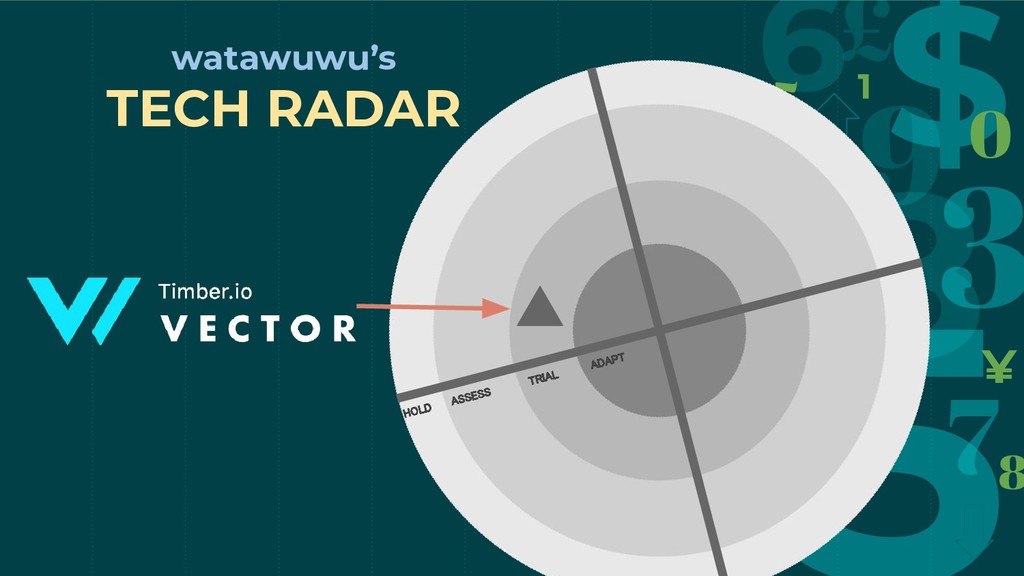
ADAPT TRIAL ASSESS HOLD watawuwu’s TECH RADAR
Thanks! Kubernetes, Cloud Native zlab.co.jp
{kind=link}
![profile: name: Wataru Matsui org: [ Z Lab, 3bi.tech ]](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[sources.my_file_source_id] # REQUIRED - General type = "file"](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_15.jpg){kind=link}
![[sources.my_tcp_source_id] # REQUIRED - General type = "tcp"](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_16.jpg){kind=link}
{kind=link}
![[sinks.my_tcp_sink_id] # REQUIRED - General type = "tcp"](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_18.jpg){kind=link}
![[sinks.my_s3_sink_id] # REQUIRED - General type = "s3"](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_19.jpg){kind=link}
![[sinks.my_prometheus_sink_id] # REQUIRED - General type = "prometheus"](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_20.jpg){kind=link}
{kind=link}
![[transforms.my_regex_trans_id] # REQUIRED - General type = "regex_parser" #](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_22.jpg){kind=link}
![[transforms.my_prometheus_trans_id] # REQUIRED - General type = "log_to_metric" #](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_23.jpg){kind=link}
![[sources.logs] type = 'file' include = ['/var/log/*.log'] [transforms.tokenizer]](https://files.speakerdeck.com/presentations/04483c8ecd0c4e348ada9e04a76047c4/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}