the models? • Who owns the architecture? • Understand who is responsible for what, and make sure the architecture reflects that organizational structure.
absolutely possible into a scikit-learn pipeline. This is the item to be packaged. Remember type coersion, standardization, feature engineering, dimensionality reduction, probability calibration, class balancing, category encoding, etc., etc., etc. • Use joblib to serialize it. • The data scientist controls this artifact. Document and define inputs and outputs. Define expected ranges of in/out where possible. • Never let someone else send you a serialized model and just run it, this is internal only. Arbitrary code _will_ be executed in your runtime environment.
fraudulent?” “what’s in this picture?”. All of the data you need to issue a prediction is held by whoever is asking for it (so it’s a transaction, trade data for prediction) • Recurring Forecasting Think: “what’s the weather going to be tomorrow?” Some of the data you need to issue a prediction is held by the requester, but you have a bunch of other stuff you need other than just the model (historical data). • Many, many others
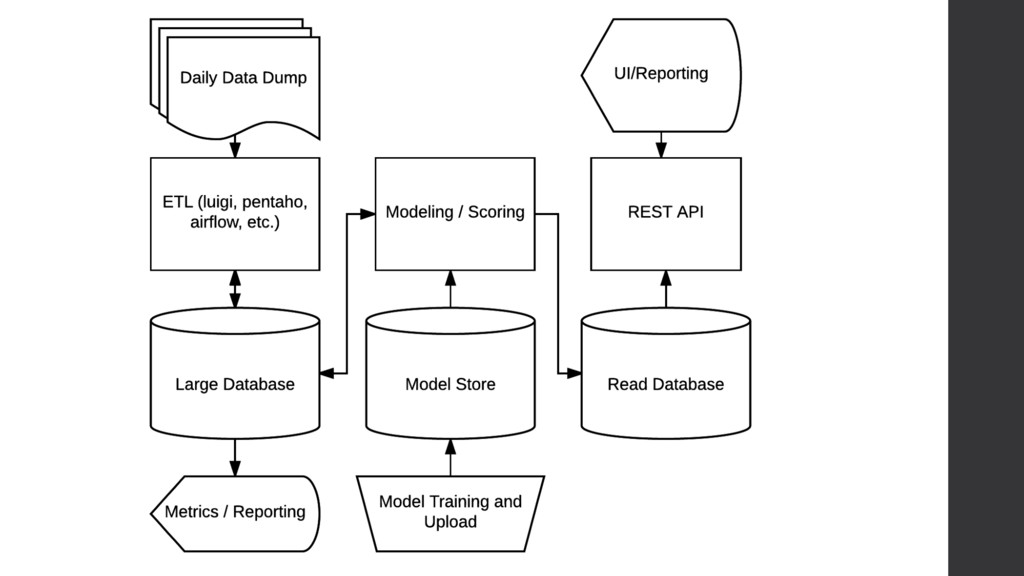
to store: Trained models (big binary blob) Version history of models Data required for issuing predictions Data about predictions we’ve issued Metrics Logs Audit trail • Is there an existing database? Or do you need your own? • Postgresql will store pickled models without too much trouble, but be careful about upgrading scipy/numpy.
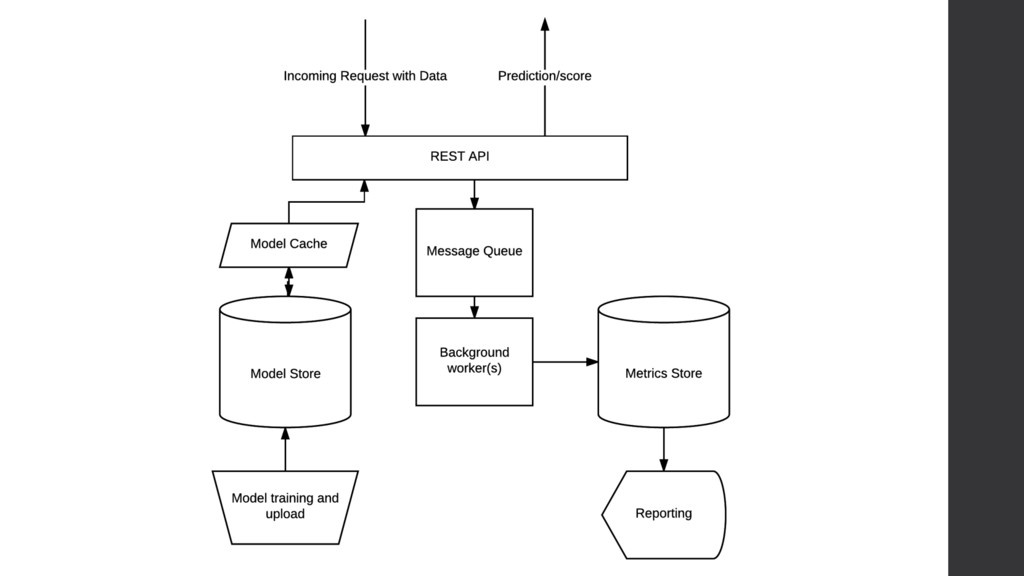
POSTs some data to an endpoint 2. API has a model in memory backed by cache 3. Data is formatted and run through pipeline 4. Output sent back to user 5. Async: write data and prediction to data store
night at midnight, get some new batch of data via whatever 2. Process the data in your data store (hadoop? Spark? Luigi? SQL?) 3. Pull most recent pickled model from model store 4. Use the data to issue a collection of new forecasts 5. Write forecasts, meta-data, metrics to datastore 6. Serve predictions the rest of the day via REST API
to know when model performance is degrading • How to know when predictions are trash (because of bad data, code, whatever) • How to know when input data is trash (it will be eventually) • Non-ML performance (throughput, hardware requirements, uptime, etc.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}