At FT we built one of the world's fastest media websites, and release to production dozens of times a day. But the architectural and organisational decisions aimed at allowing us to deliver reliable features quickly and consistently don't always fit neatly with our desire to optimise performance.
In this warts-and-all talk, you'll learn
- how we build FT.com
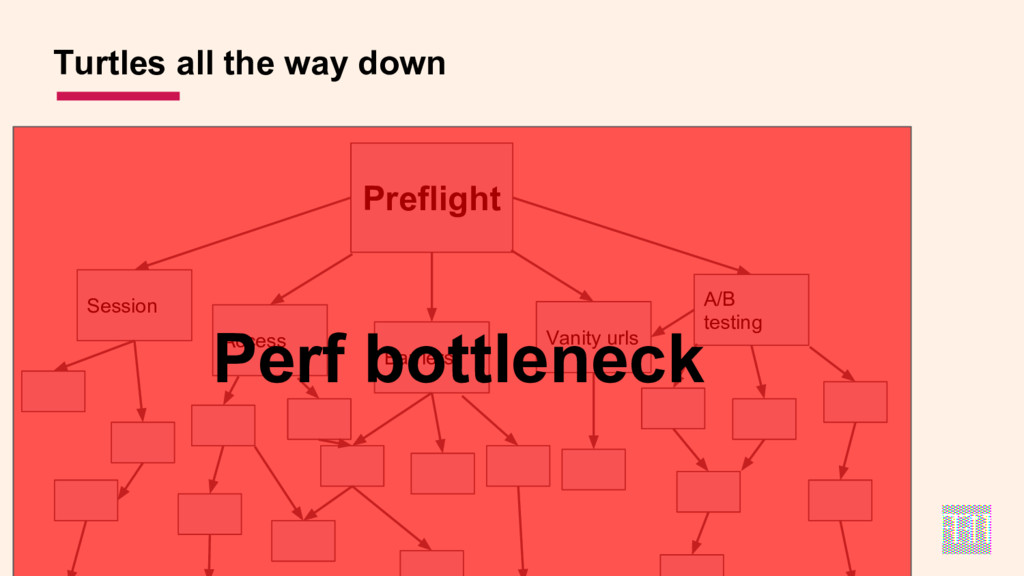
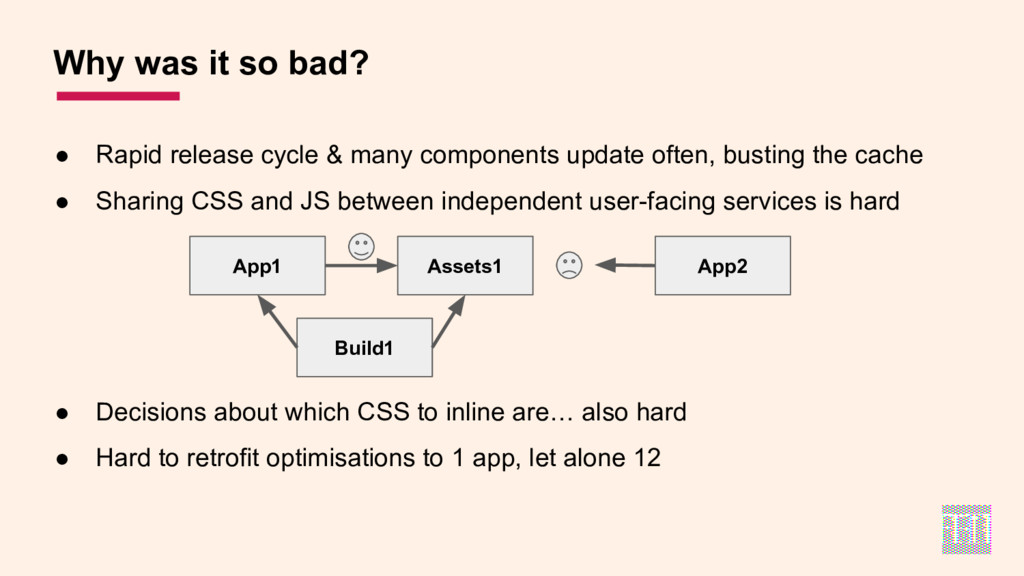
- how a highly componentised, microservices stack with a rapid release cycle can sometimes get in the way of performance
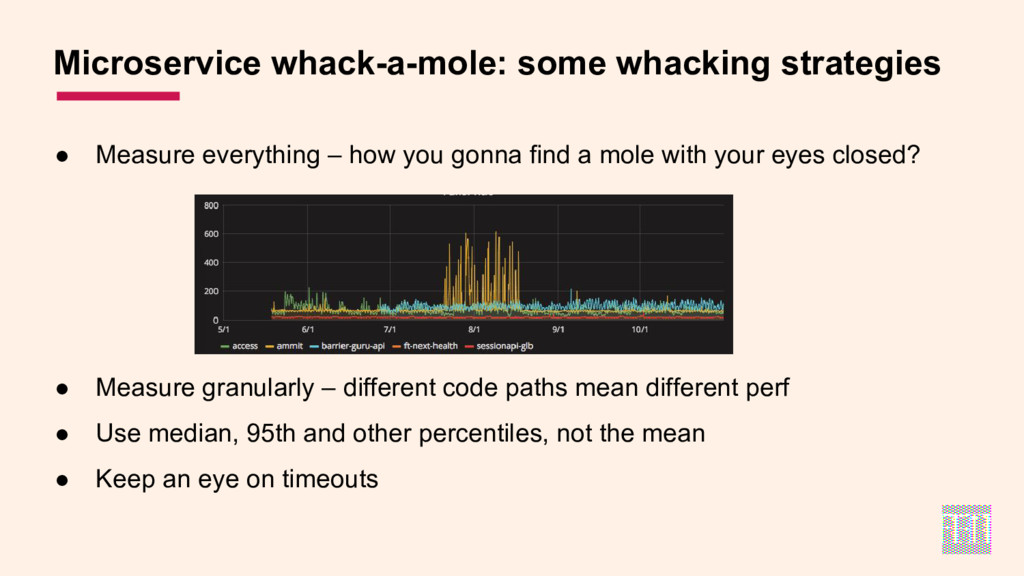
- some ideas for working around these obstacles
- that web performance is hard, and no-one's perfect
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}