Recommender systems have become increasingly important in our daily lives since they play an important role in mitigating the information overload problem, especially in many user-oriented online services. Most recommender systems consider the recommendation procedure as a static process and make recommendations following a fixed greedy strategy, which may fail given the dynamic nature of the users’ preferences. Also, they are designed to maximize the immediate reward of recommendations, while completely overlooking their long-term influence on user experiments. To learn adaptive recommendation policy, we will consider the recommendation procedure as sequential interactions between users and recommender agents; and leverage Reinforcement Learning (RL) to automatically learn an optimal recommendation strategy (policy) that maximizes cumulative rewards from users without any specific instructions. Recommender systems based on reinforcement learning have two advantages. First, they can continuously update their strategies during the interactions. Second, the optimal strategy is made by maximizing the expected long-term cumulative reward from users. This talk will introduce the fundamentals and advances of deep reinforcement learning and its applications in recommender systems.
Seminar page: https://wing-nus.github.io/ir-seminar/speaker-arman
YouTube Video recording: https://www.youtube.com/watch?v=IMRgFS7GKB0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
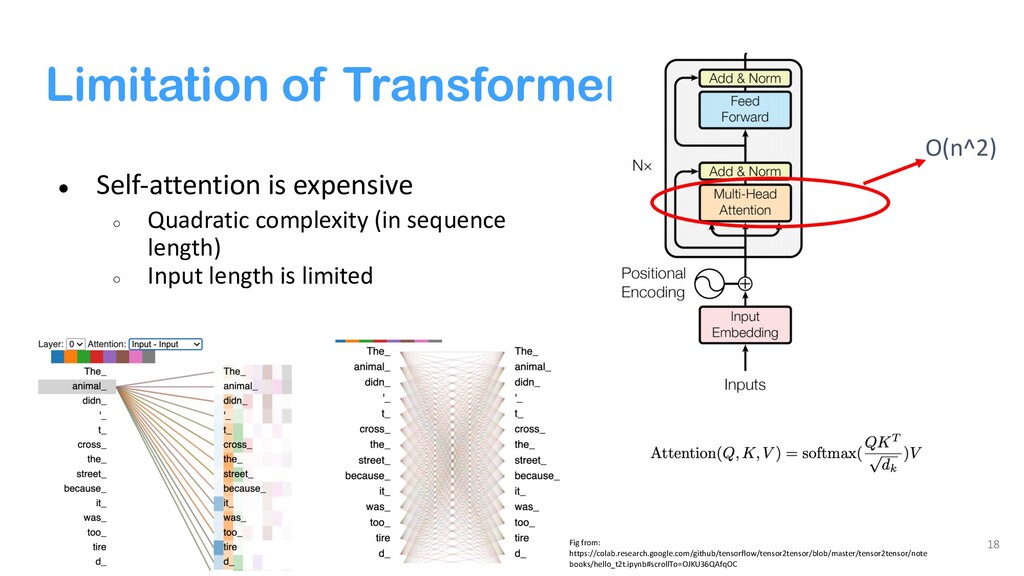{kind=link}
{kind=link}
{kind=link}
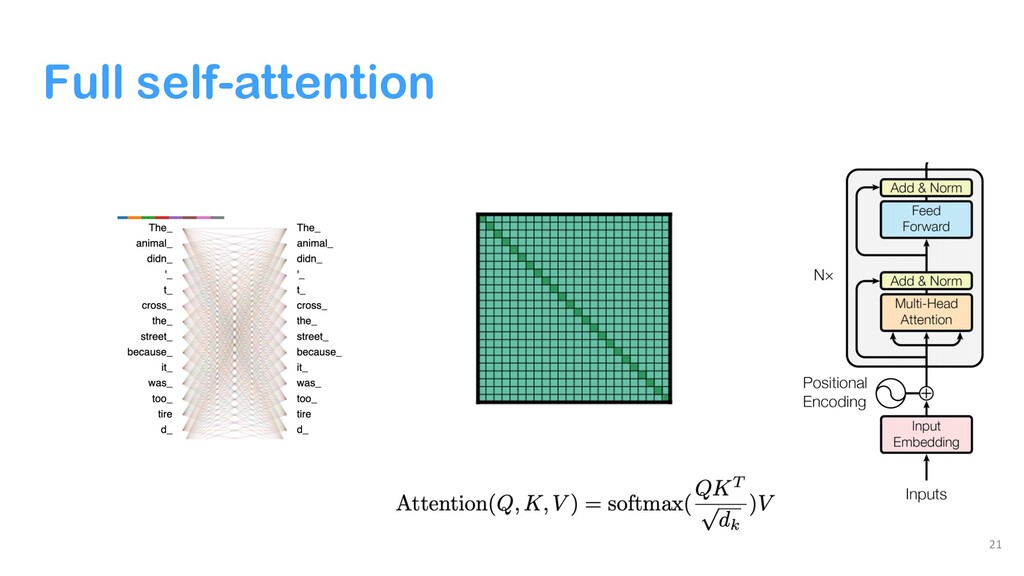{kind=link}
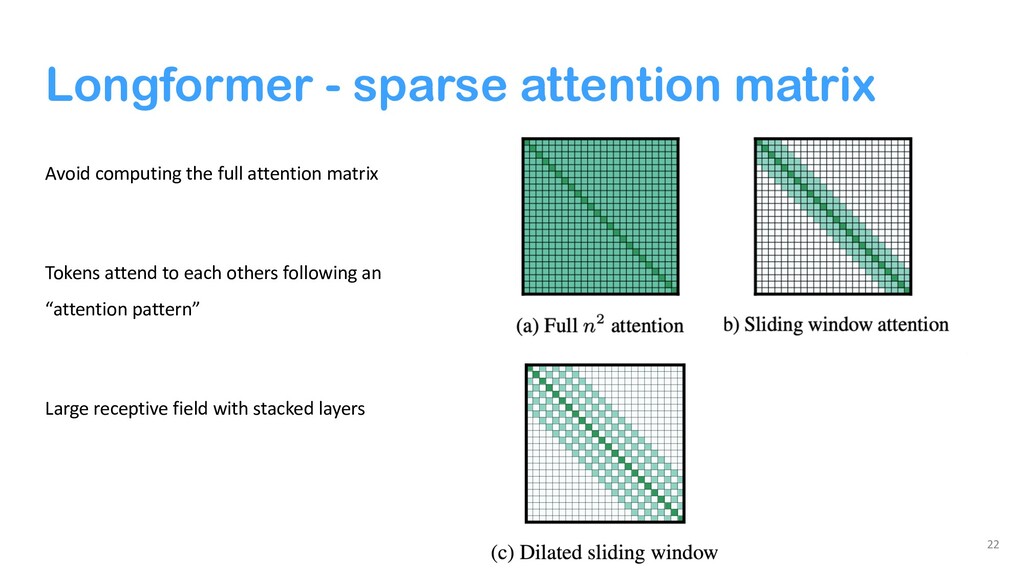{kind=link}
![- QA: [cls] [q1 q2 q3] [sep] [t1 t2 t3](https://files.speakerdeck.com/presentations/2c5d946dda764c84a8eb0646df004243/slide_22.jpg){kind=link}
{kind=link}
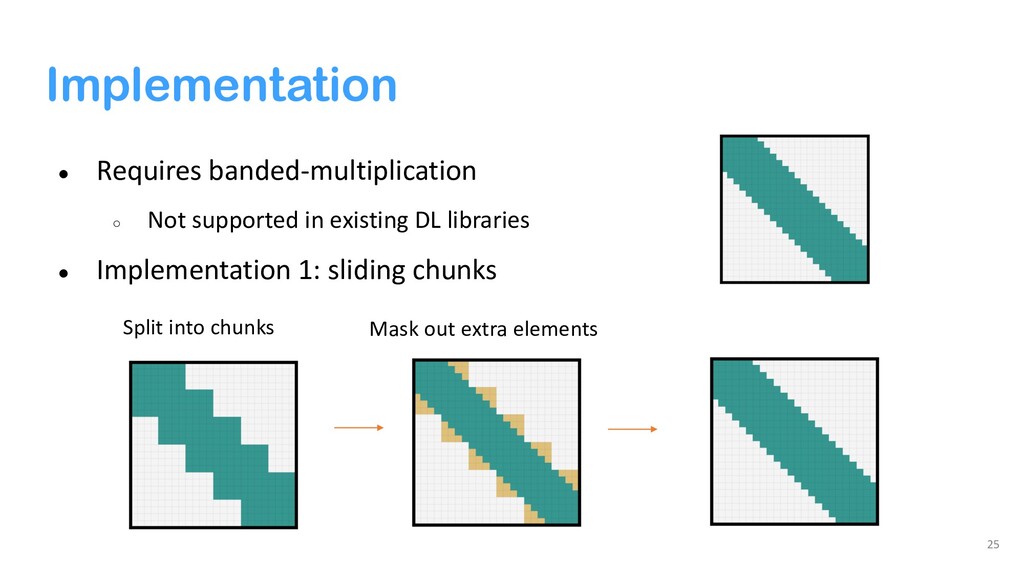{kind=link}
{kind=link}
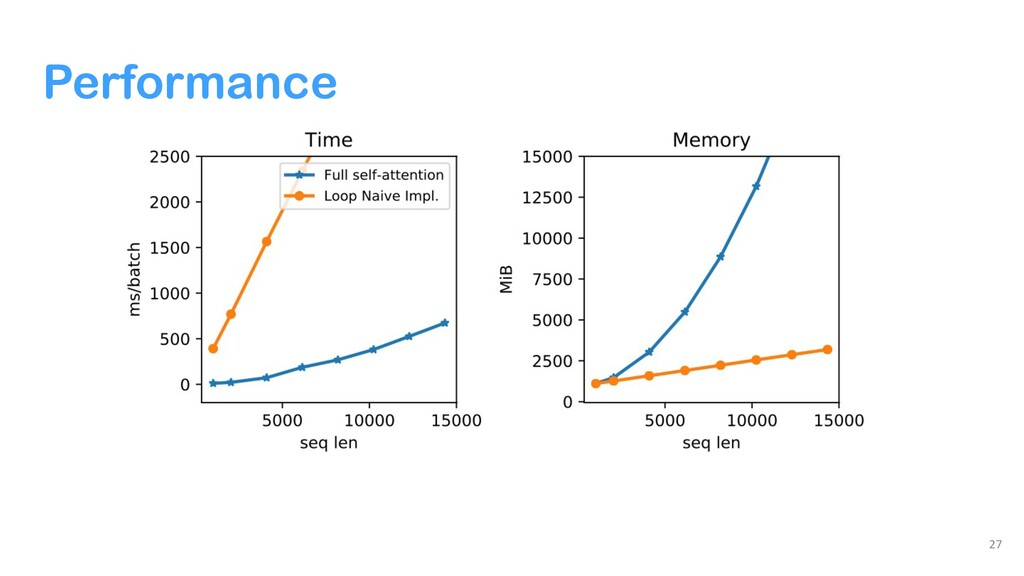{kind=link}
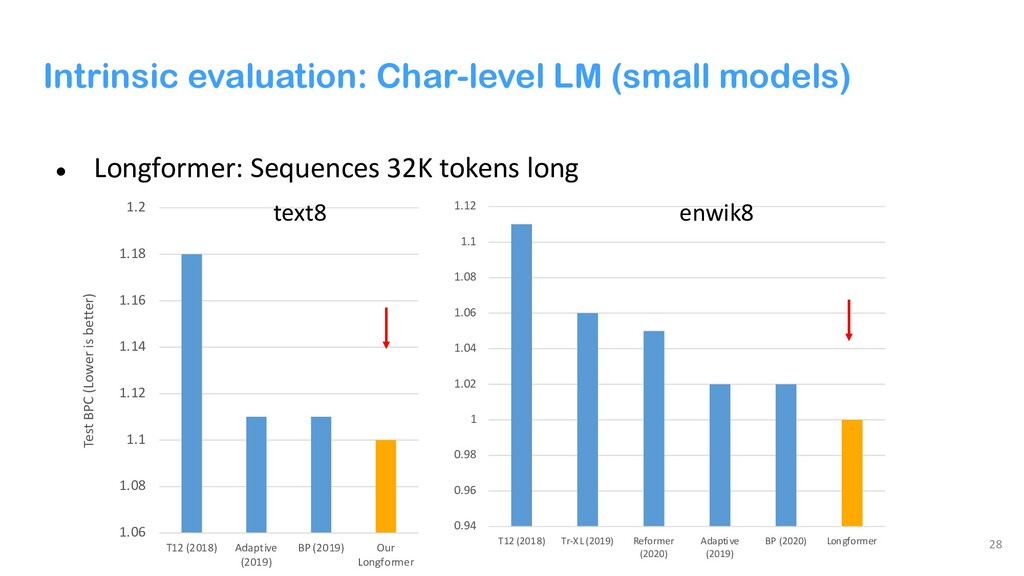{kind=link}
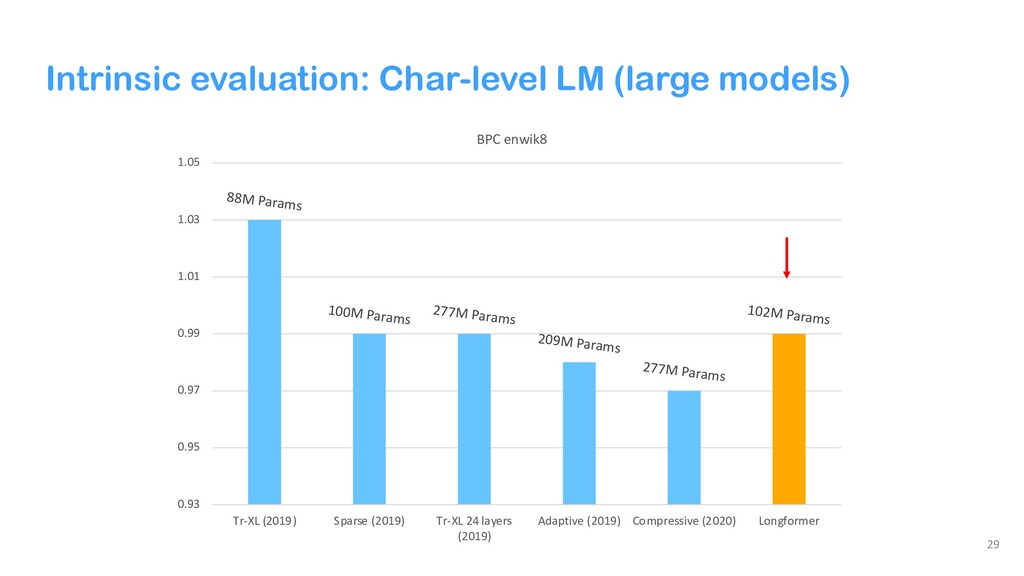{kind=link}
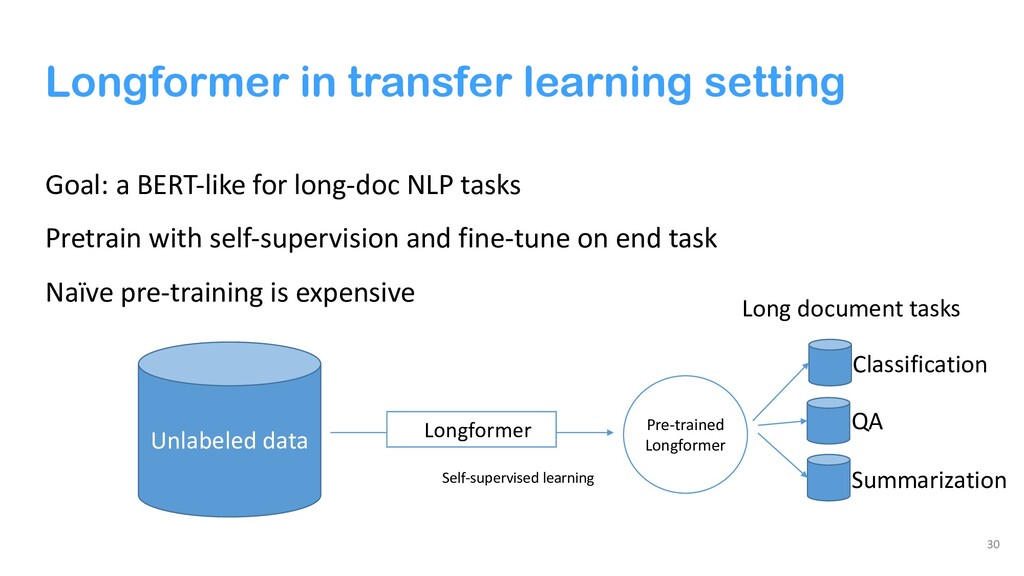{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
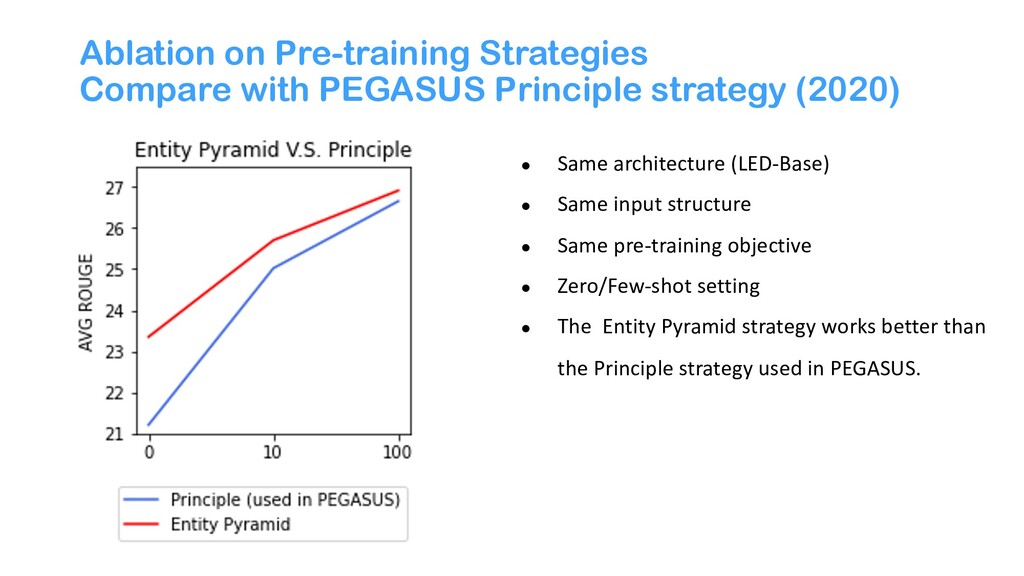{kind=link}
{kind=link}
{kind=link}
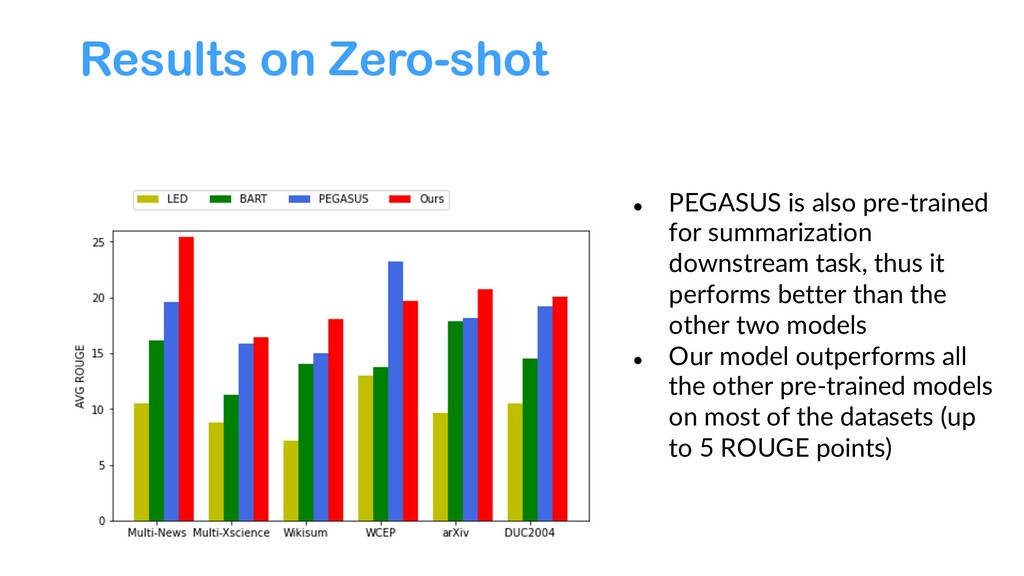{kind=link}
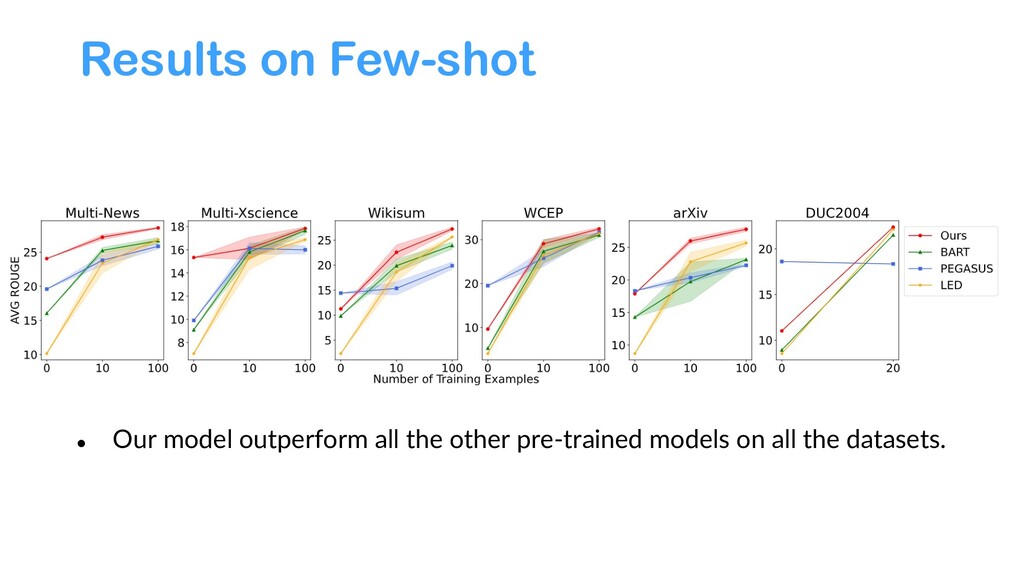{kind=link}
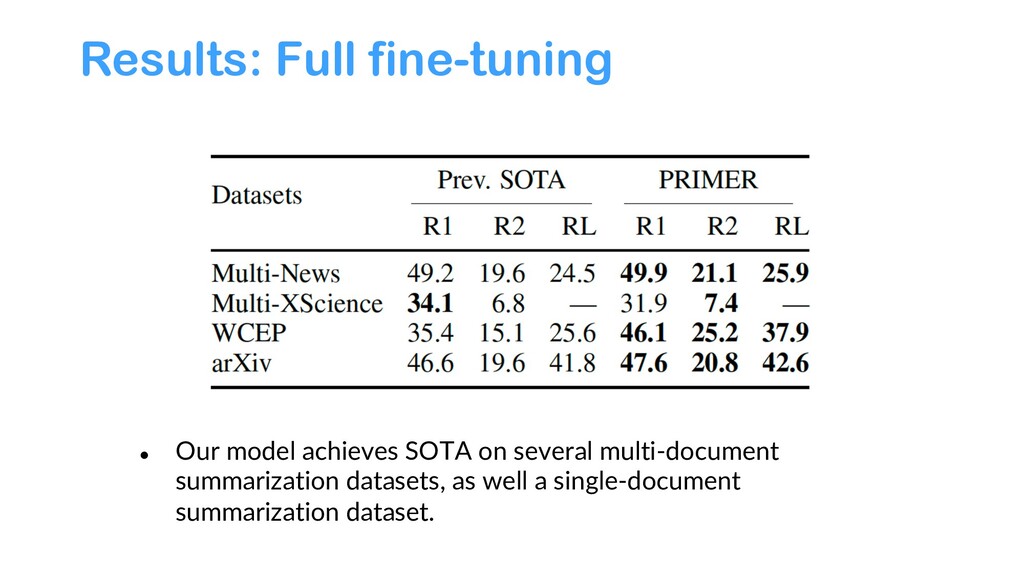{kind=link}
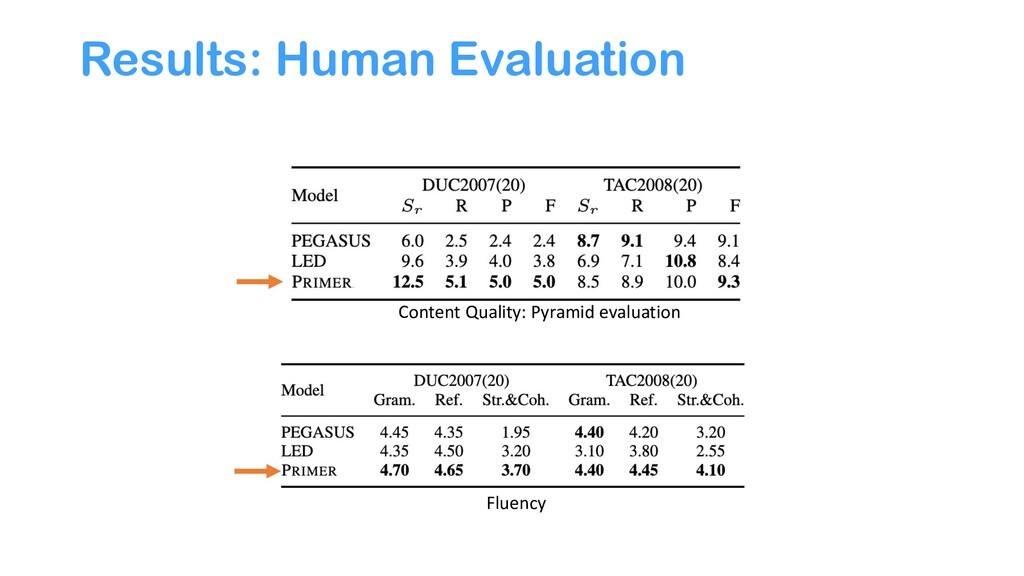{kind=link}
{kind=link}
{kind=link}
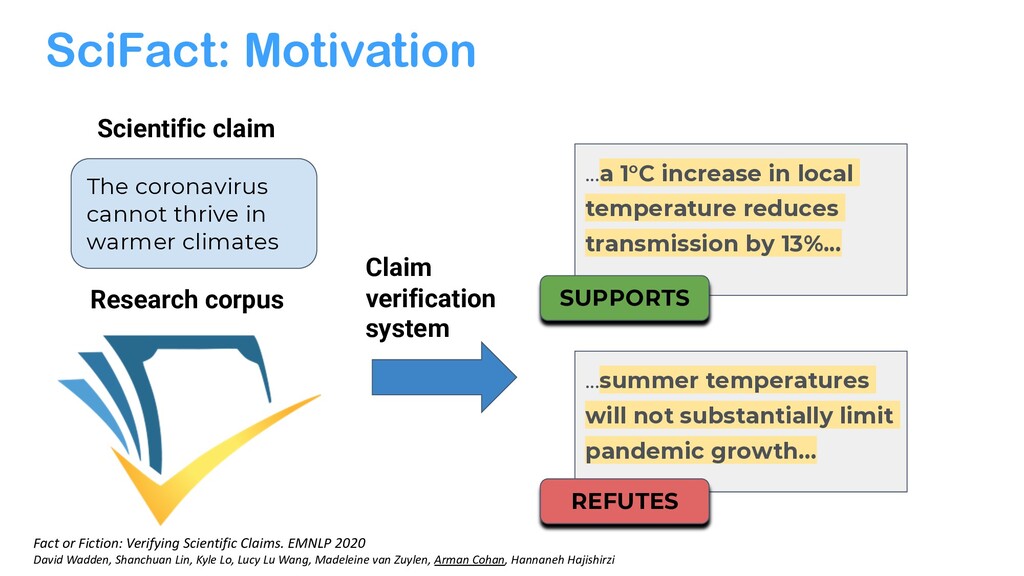{kind=link}
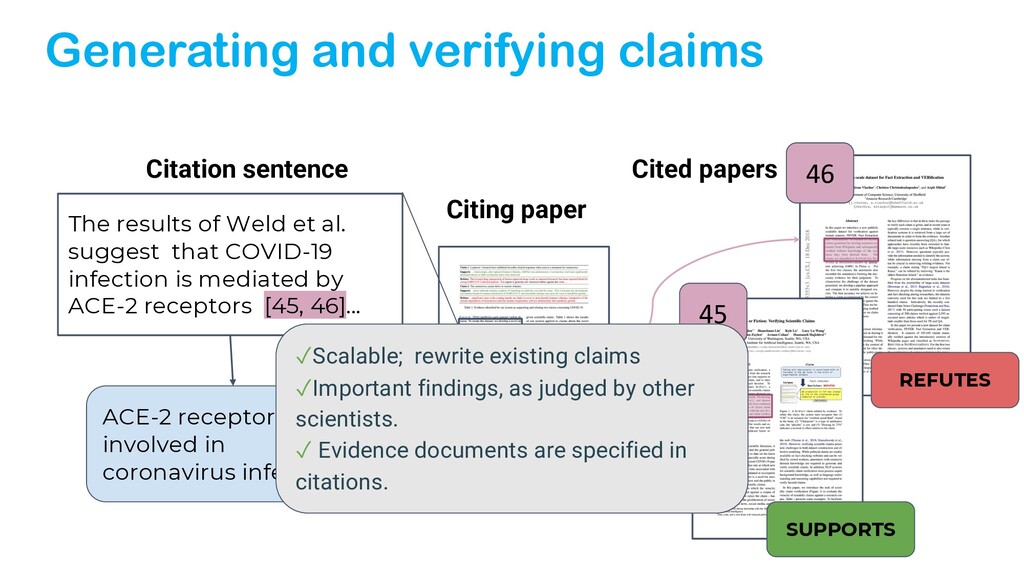{kind=link}
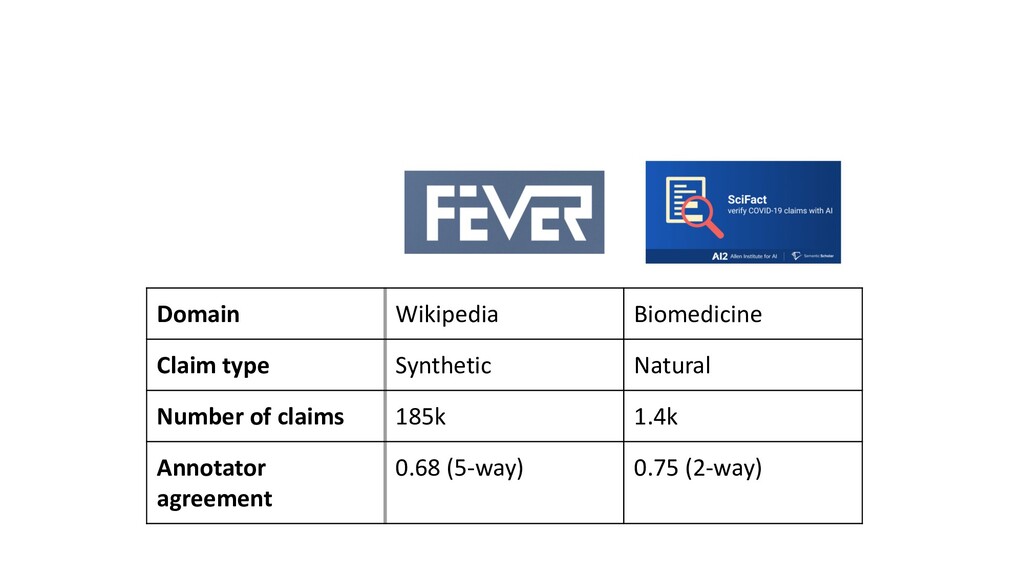{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}