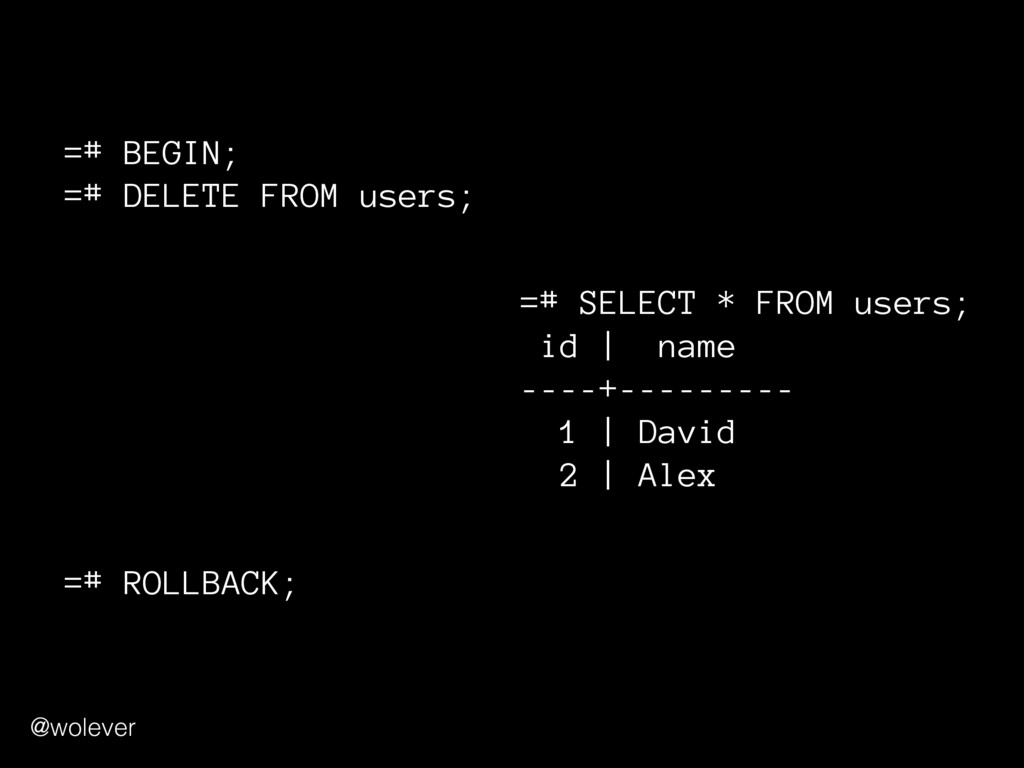
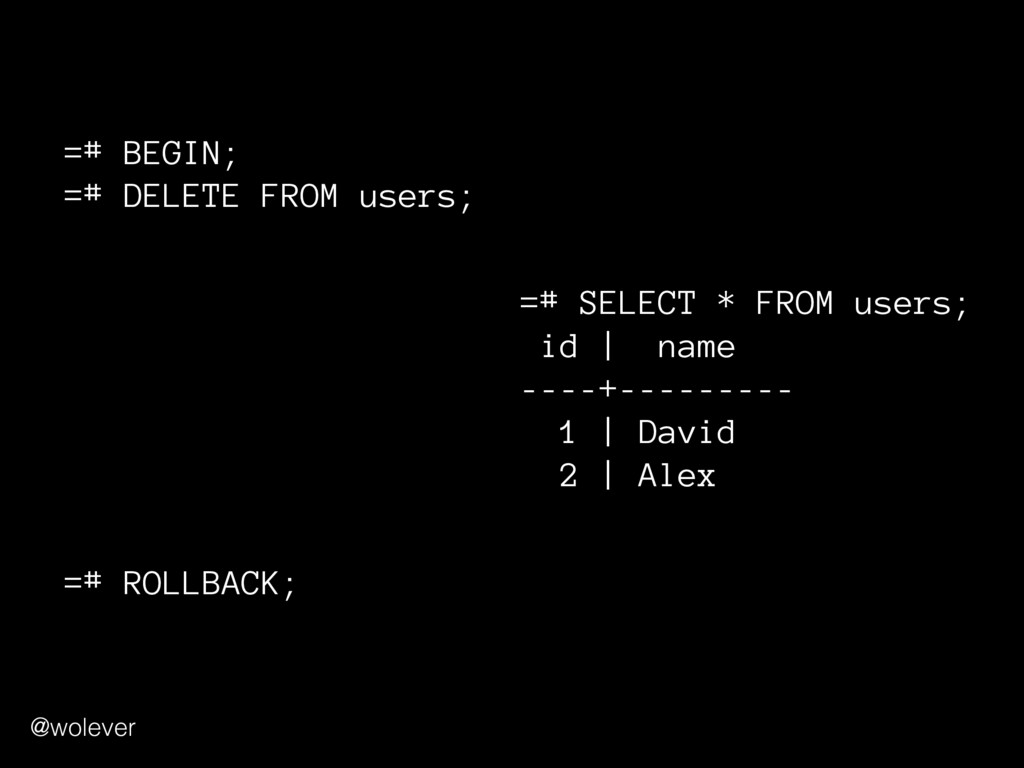
sense when performed together • "Everything succeeds or everything fails" Example: transferring $100 between bank accounts: 1. Withdraw $100 from first account 2. Deposit $100 into second account @wolever
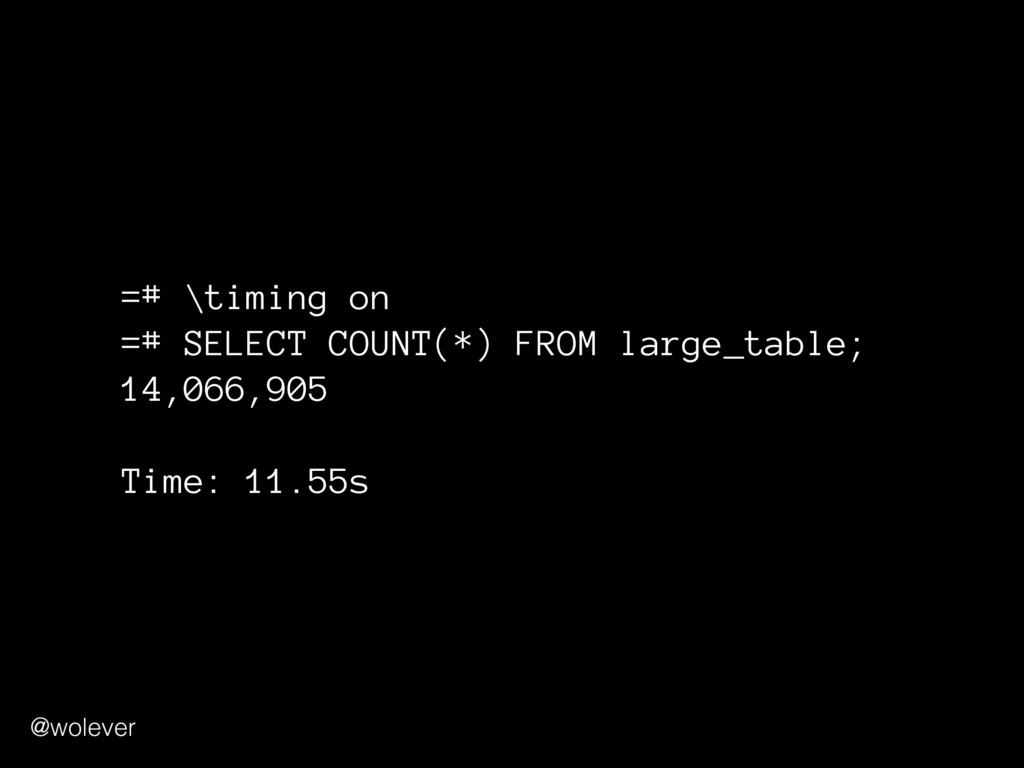
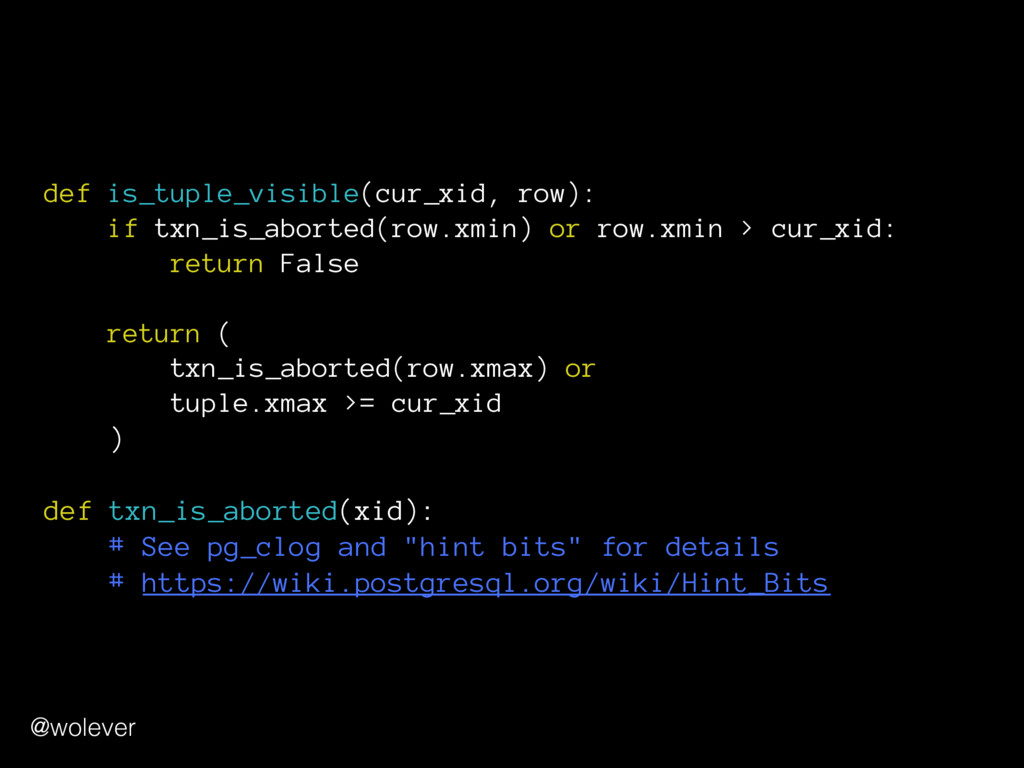
MVCC implementation in PostgreSQL. The fact that multiple transactions can see different states of the data means that there can be no straightforward way for "COUNT(*)" to summarize data across the whole table; PostgreSQL must walk through all rows, in some sense.” - https://wiki.postgresql.org/wiki/Slow_Counting @wolever
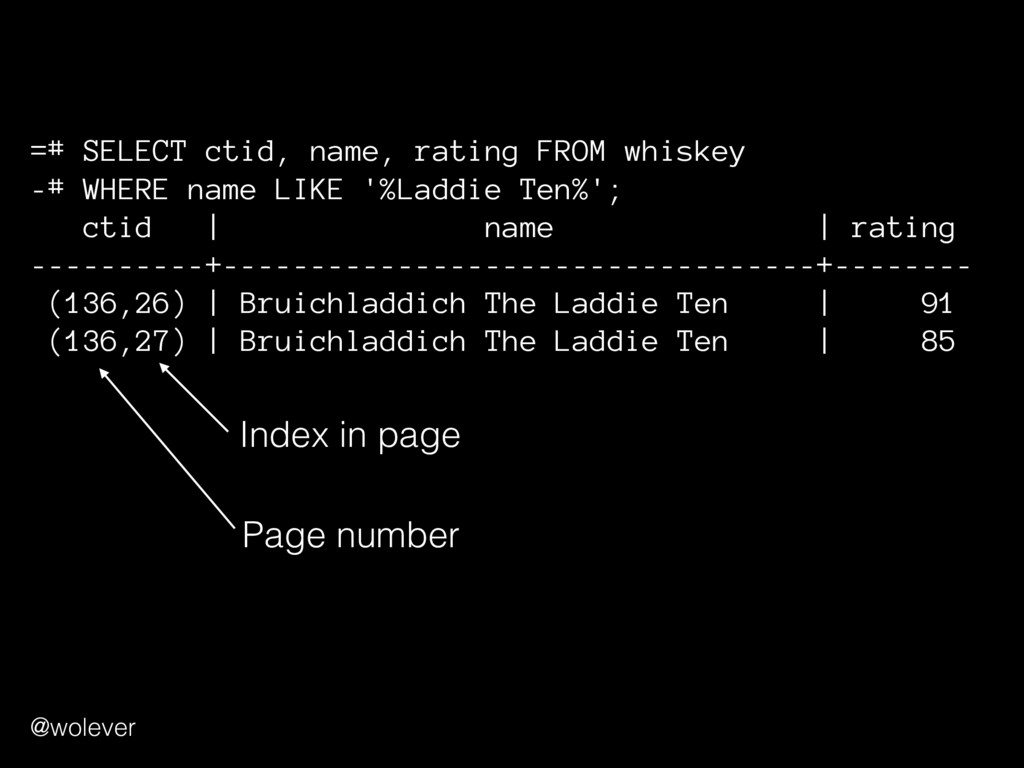
LIKE '%Laddie Ten%'; ctid | name | rating ----------+----------------------------------+-------- (136,26) | Bruichladdich The Laddie Ten | 91 (136,27) | Bruichladdich The Laddie Ten | 85 Page number Index in page @wolever
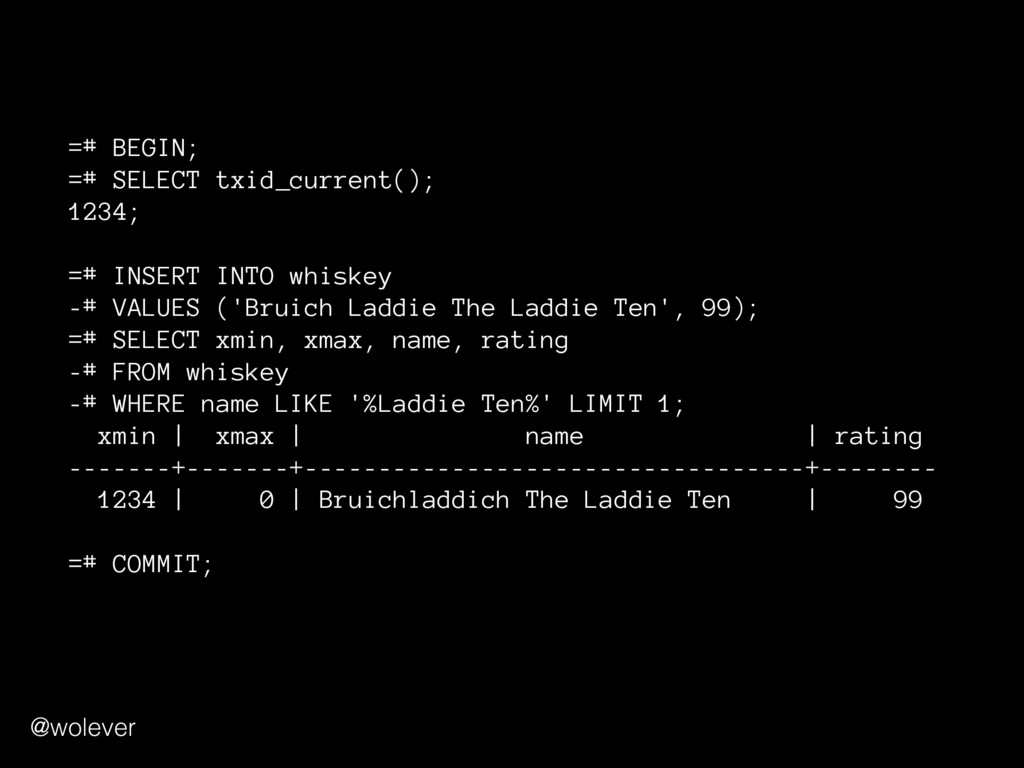
=# SELECT xmin, xmax, name, rating -# FROM whiskey -# WHERE name LIKE '%Laddie Ten%'; xmin | xmax | name | rating --------+---------+----------------------------------+-------- 122406 | 0 | Bruichladdich The Laddie Ten | 91 122406 | 1831785 | Bruichladdich The Laddie Ten | 85 xmin: XID which created the row xmax: XID which updated or deleted the row @wolever
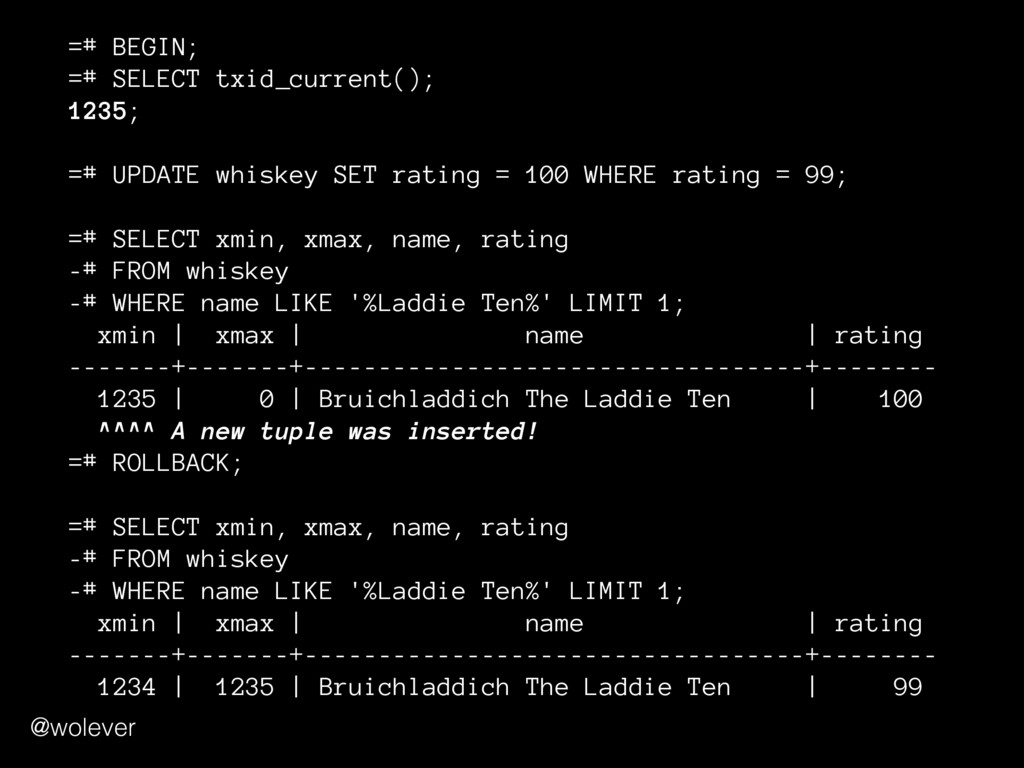
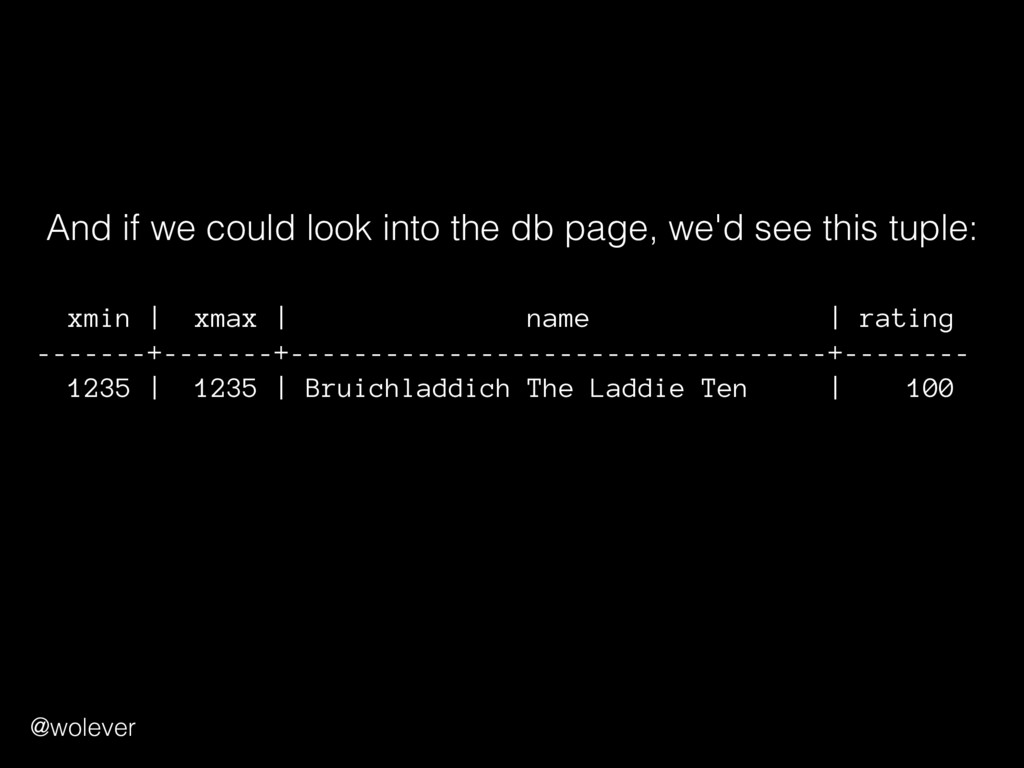
rating = 100 WHERE rating = 99; =# SELECT xmin, xmax, name, rating -# FROM whiskey -# WHERE name LIKE '%Laddie Ten%' LIMIT 1; xmin | xmax | name | rating -------+-------+----------------------------------+-------- 1235 | 0 | Bruichladdich The Laddie Ten | 100 ^^^^ A new tuple was inserted! =# ROLLBACK; =# SELECT xmin, xmax, name, rating -# FROM whiskey -# WHERE name LIKE '%Laddie Ten%' LIMIT 1; xmin | xmax | name | rating -------+-------+----------------------------------+-------- 1234 | 1235 | Bruichladdich The Laddie Ten | 99 @wolever
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
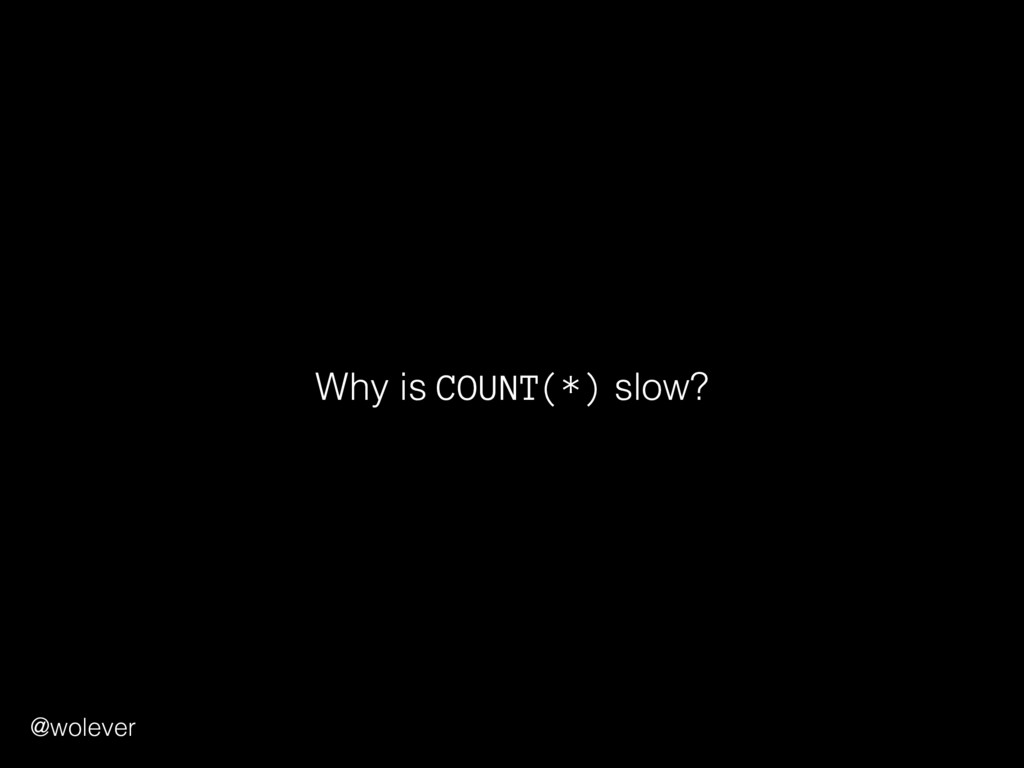{kind=link}
{kind=link}
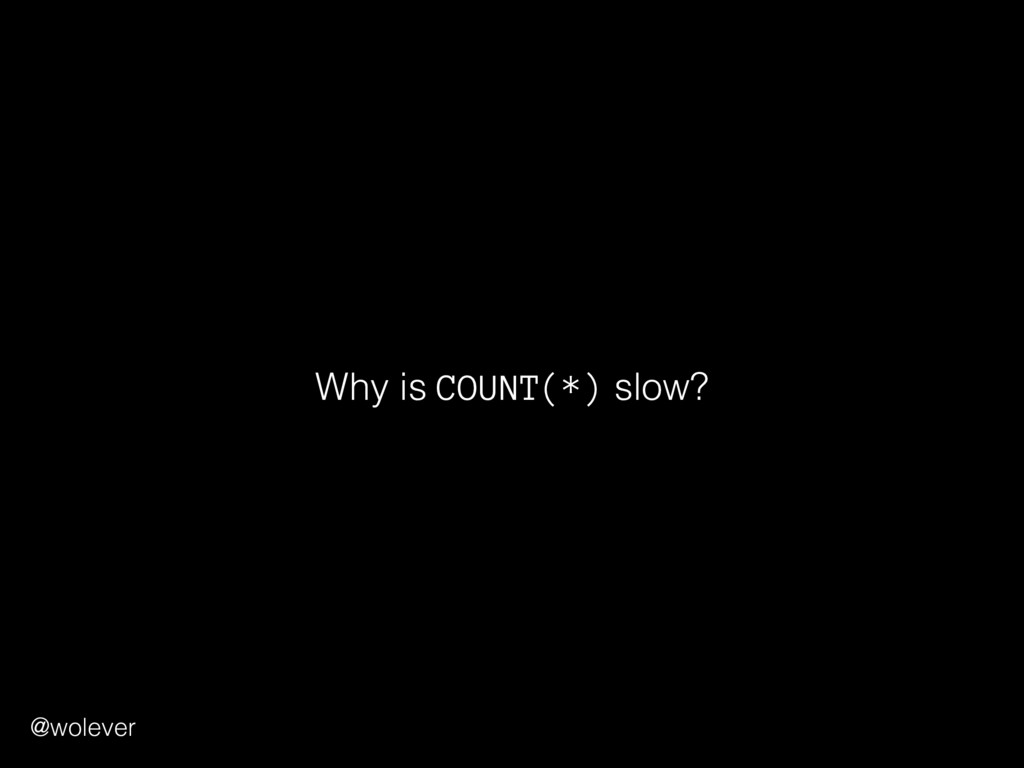{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![David Wolever @wolever Work with me: [email protected] https://akindi.com/pages/jobs](https://files.speakerdeck.com/presentations/8a831601b75042b0a2c422bf91e9f443/slide_44.jpg){kind=link}
{kind=link}