ユーザの質問文をあわせてLLMに渡す事で、回答精度を上げる手法。 チャット画面 or プログラム(スクリプト) LLM (モデル) ①質問文入力 ④ 質問文送信 ⑤ 回答文送信 ⑥ 回答文表示 データ・情報源 ② 必要情報 の取得 ③ 情報提供 ユーザ RAGにより、社内ドキュメントにしか書かれていない情報や ルールへの適用、モデルが知らない最新情報の理解ができるようになる。 一般的なものとしては 以下3つがよくあげられる。 ① Webページ(ネット検索) ② システム・サービスの提供するAPI ③ データベース
{kind=link}
![2 © 2025 NTT TechnoCross Corporation はじめに [概要] 近年AI技術の進歩が凄まじく、特に「生成AI」「LLM」というキーワードを 耳にしたことがない人はもういないのではないでしょうか。](https://files.speakerdeck.com/presentations/864fcfe1b30444fe8b39f9e64e98b0b6/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![13 © 2025 NTT TechnoCross Corporation 3-3. [参考] AWSやAzureのサービスについて 前述のLLMは基本的にはLLM製造元のAPIをたたく事で利用する。](https://files.speakerdeck.com/presentations/864fcfe1b30444fe8b39f9e64e98b0b6/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
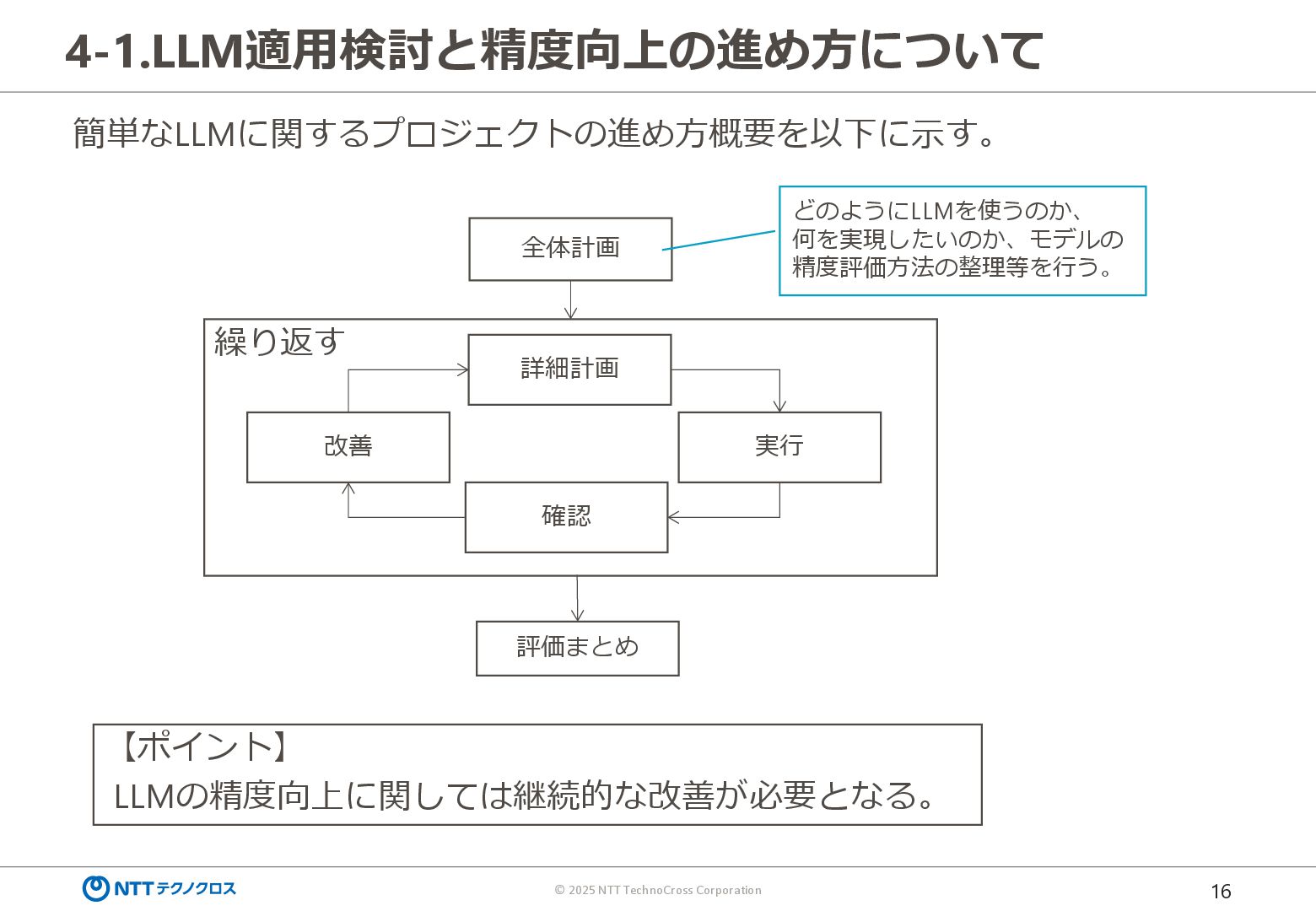{kind=link}
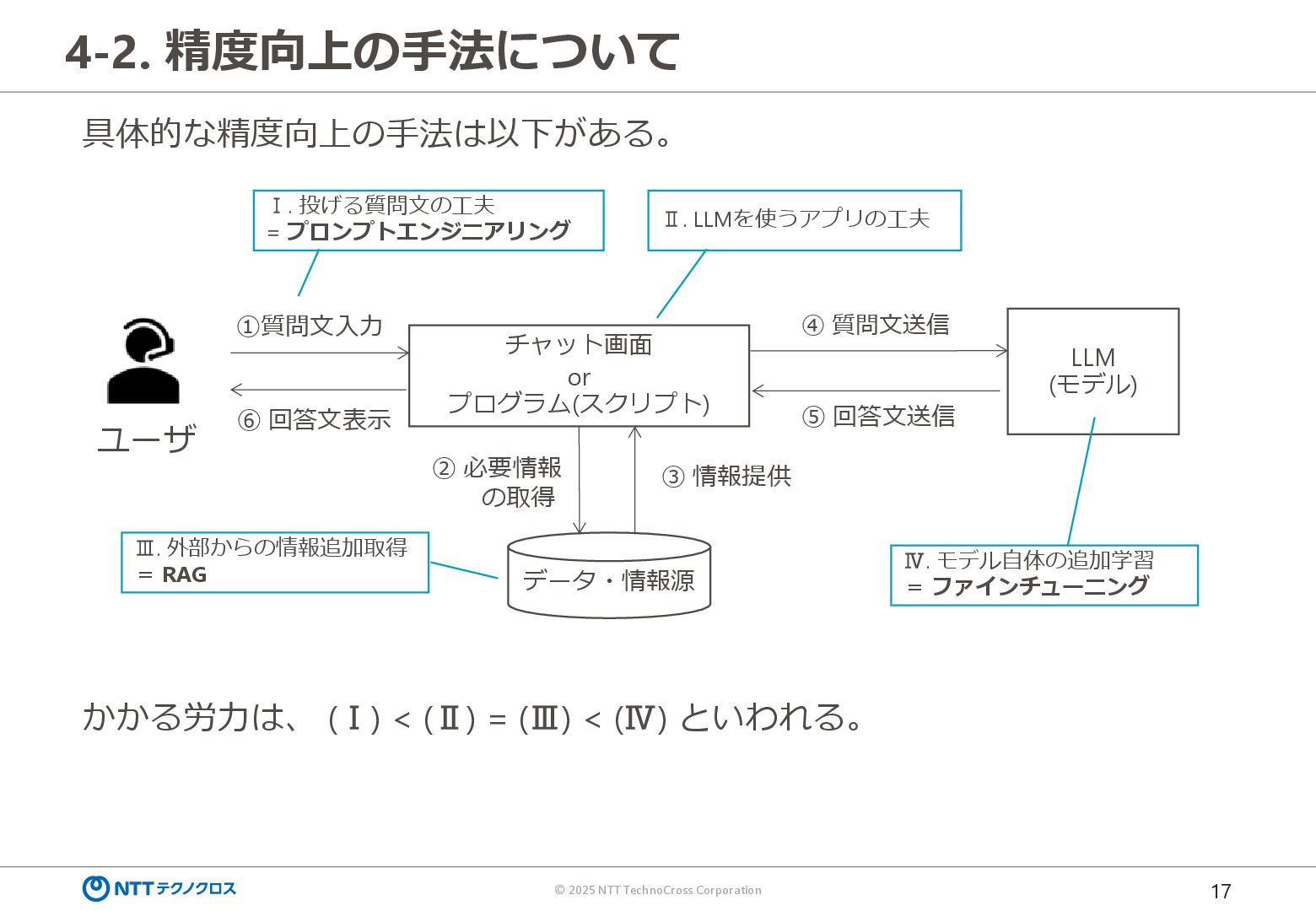{kind=link}
{kind=link}
{kind=link}
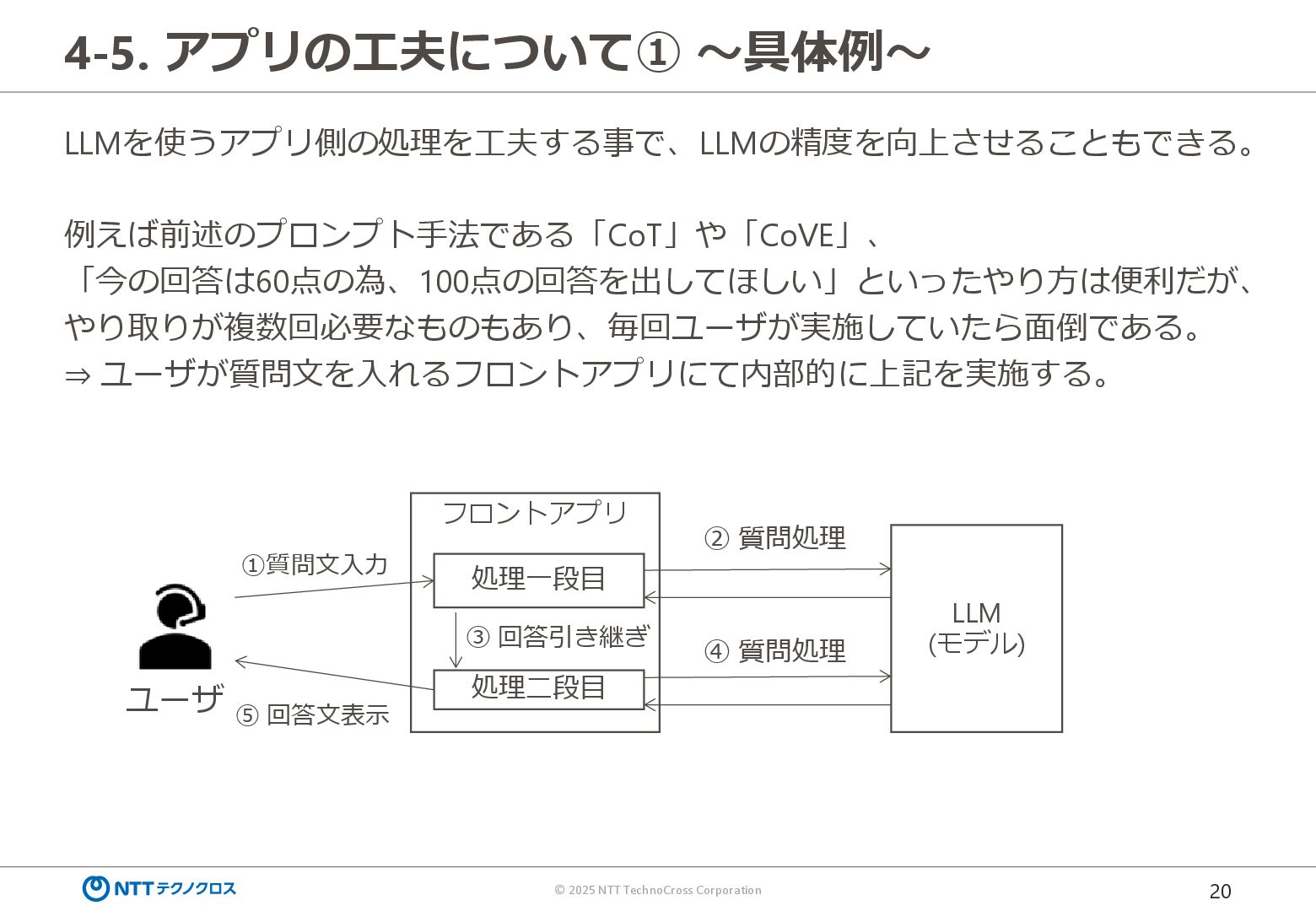{kind=link}
{kind=link}
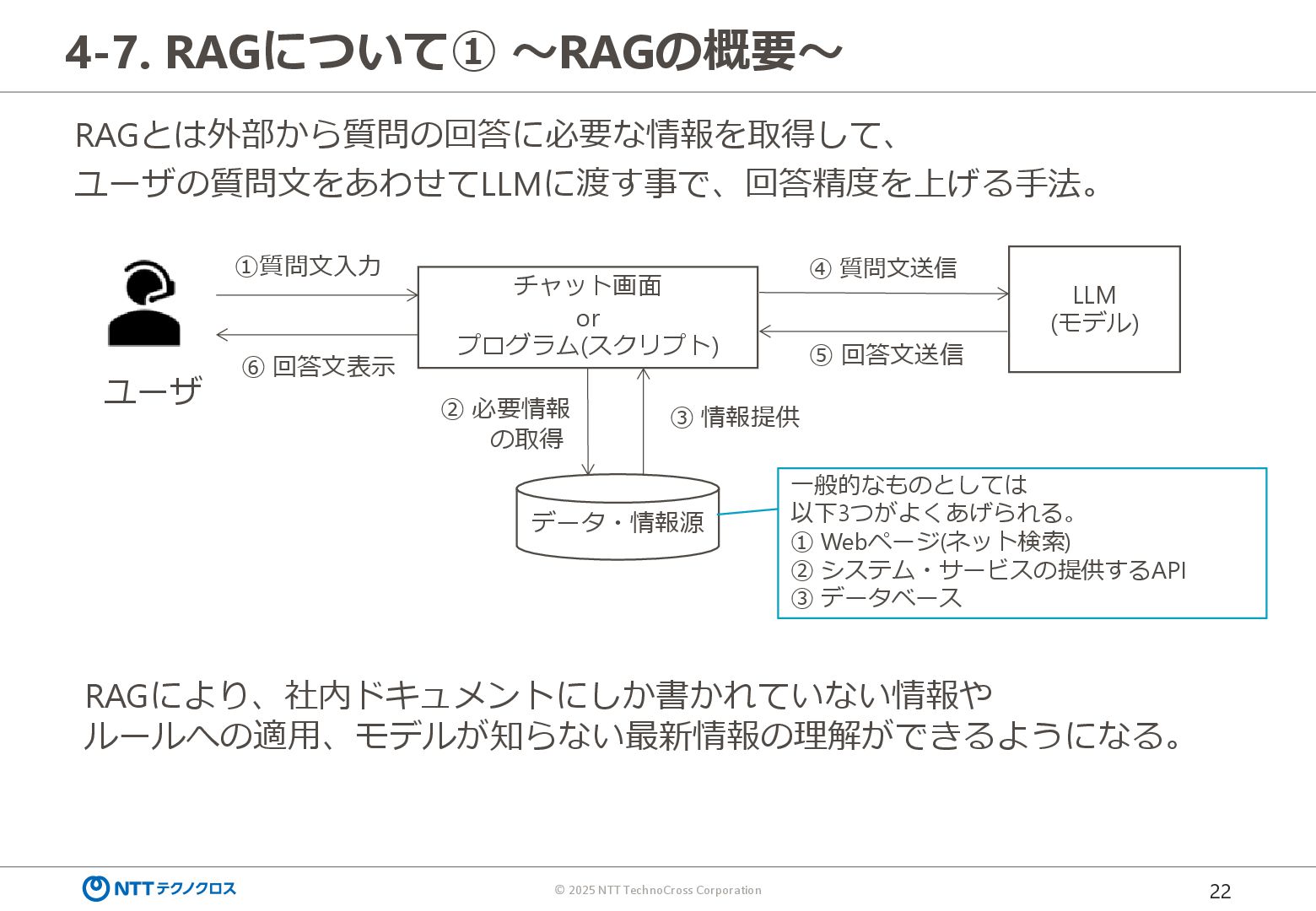{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
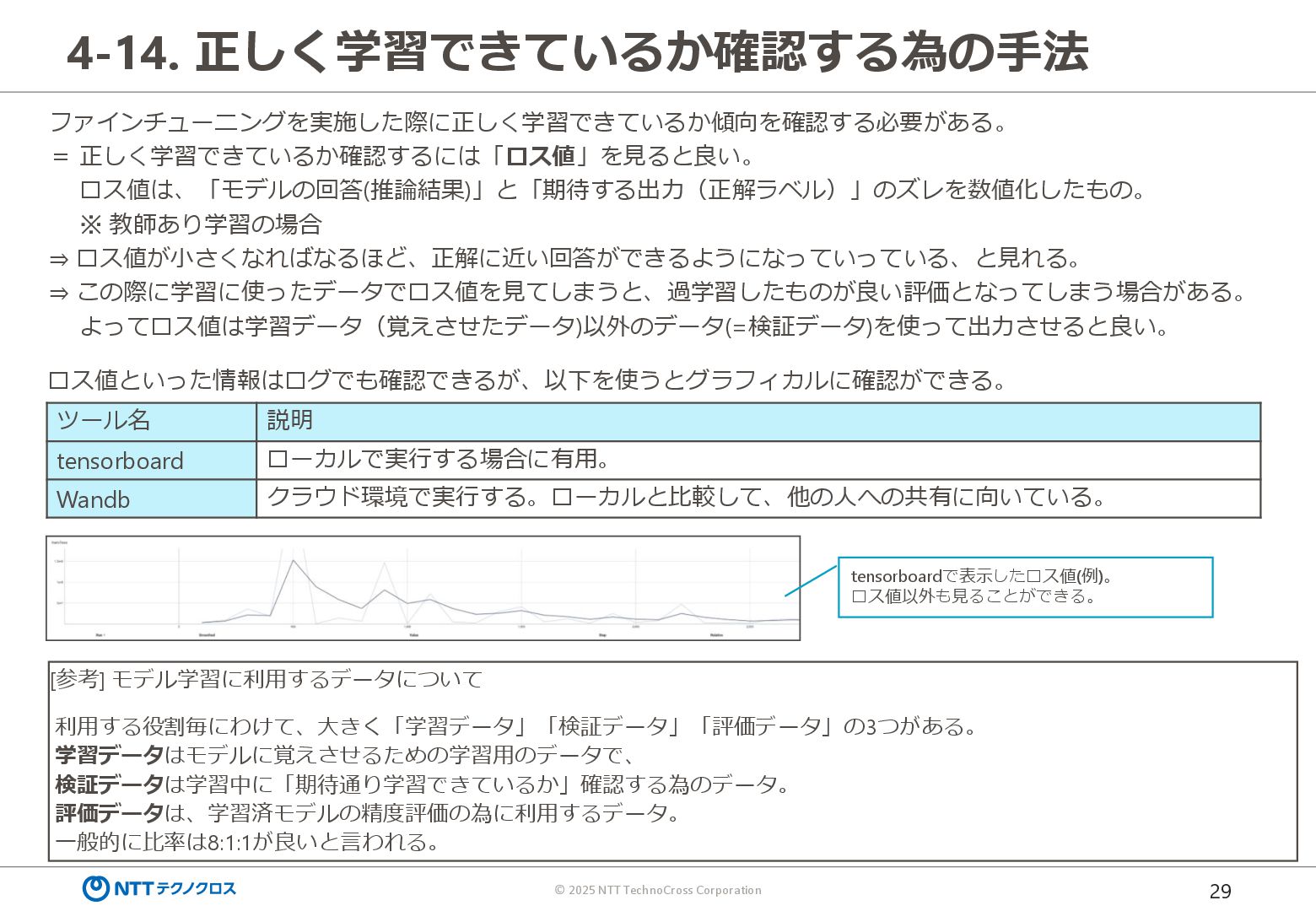{kind=link}
{kind=link}
{kind=link}
{kind=link}
![33 © 2025 NTT TechnoCross Corporation 4-18. [参考] データ並列とモデル並列について 以下にデータ並列とモデル並列に関する説明(概要)を記載する。](https://files.speakerdeck.com/presentations/864fcfe1b30444fe8b39f9e64e98b0b6/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}