Share
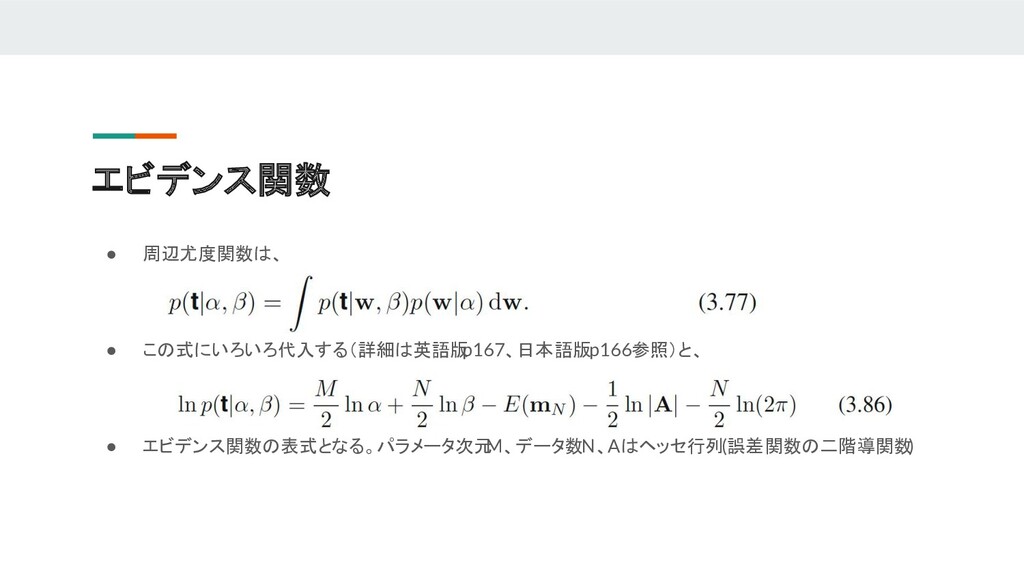
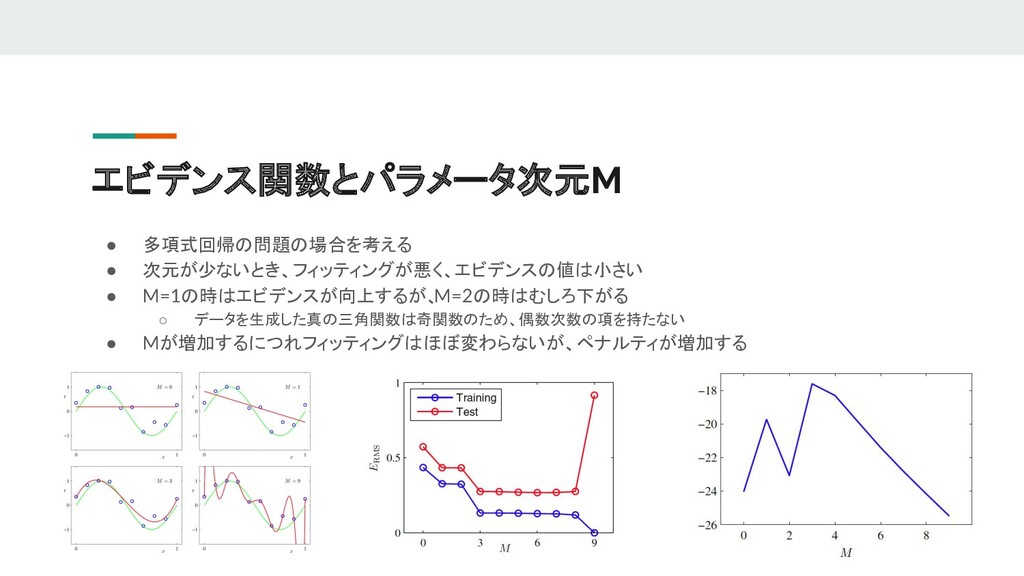
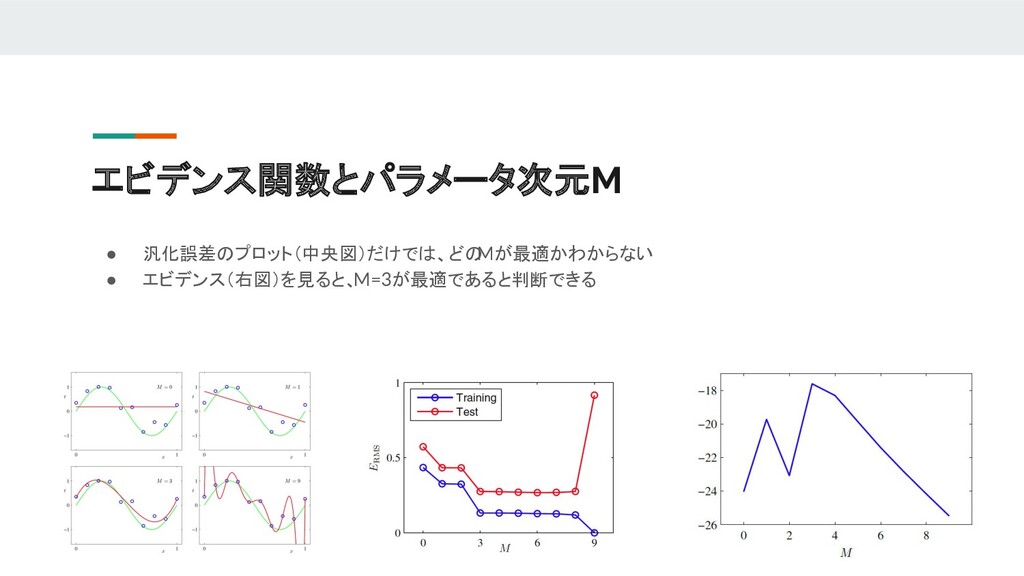
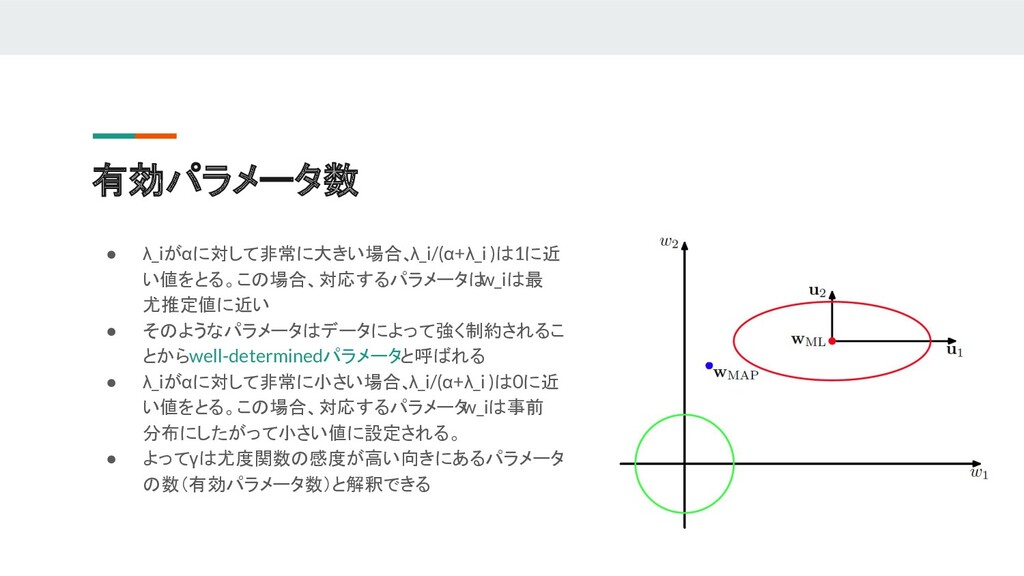
Japanese presentation material of PRML(Pattern Recognition and Machine Learning). This contains Sec3.3 to Sec 3.6. - Bayesian Model Comparison(ガウスモデル比較) - The Evidence Approximation(エビデンス近似) - Limitation of Fixed Basis Functions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
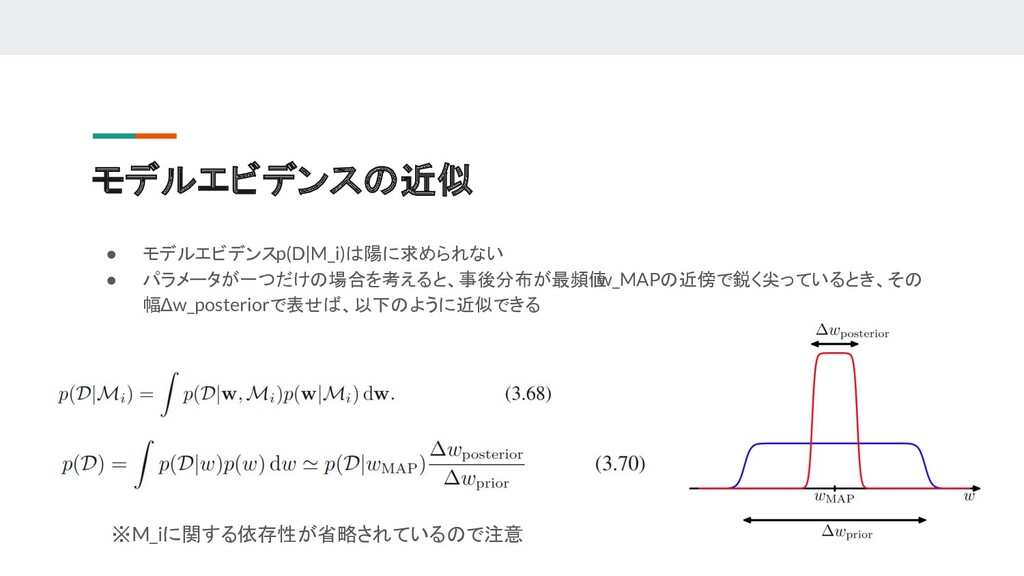{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
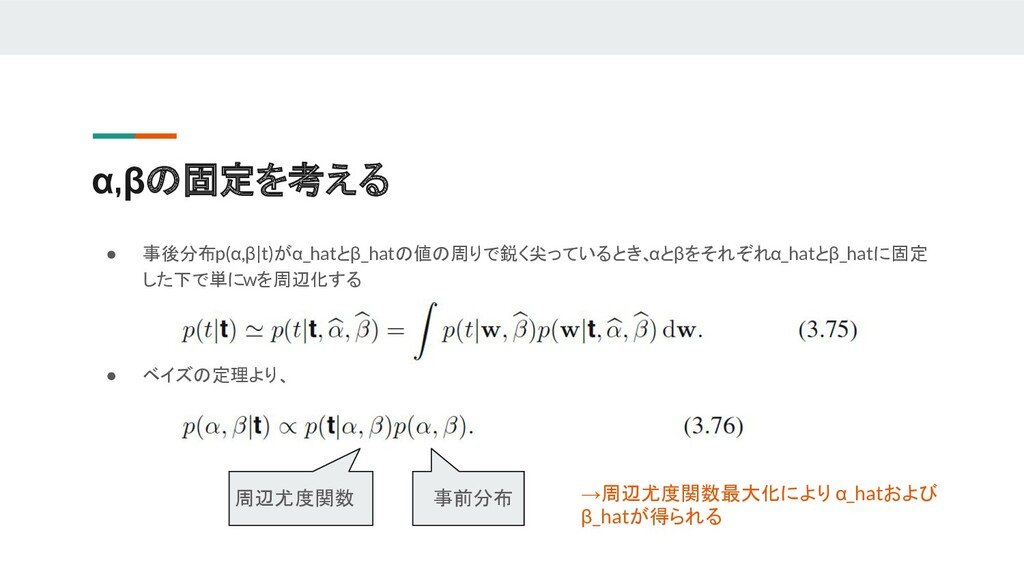{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
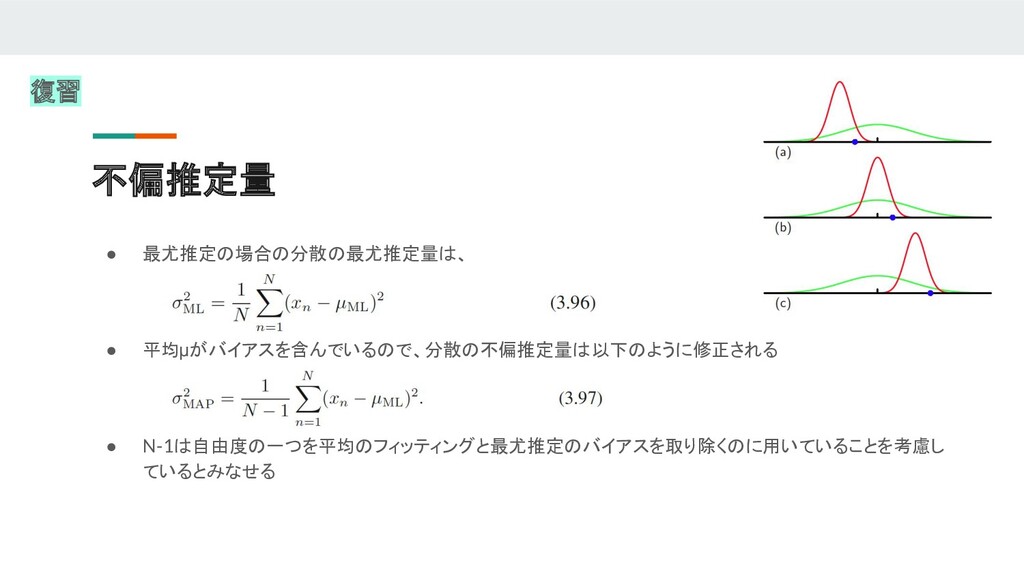{kind=link}
{kind=link}
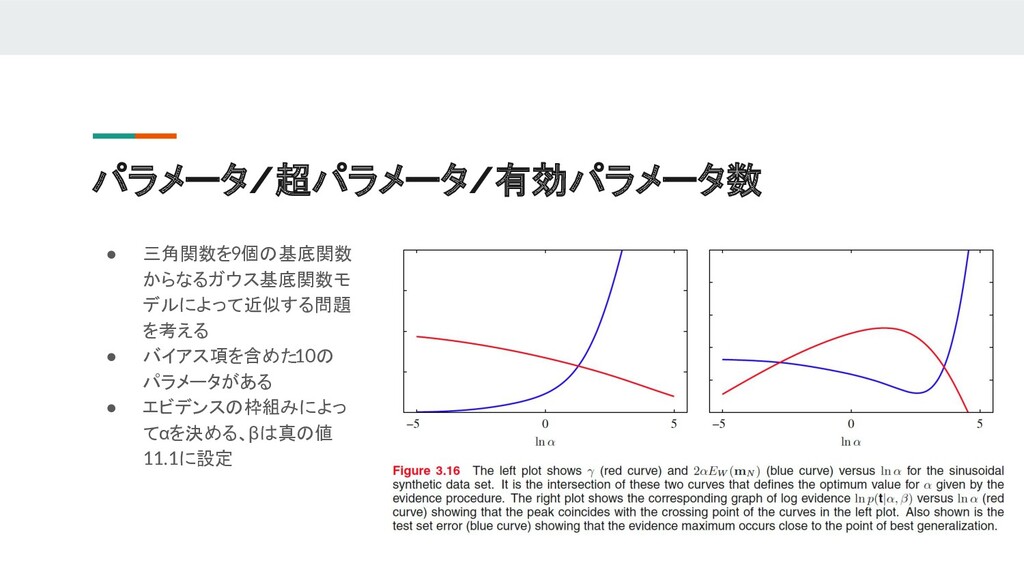{kind=link}
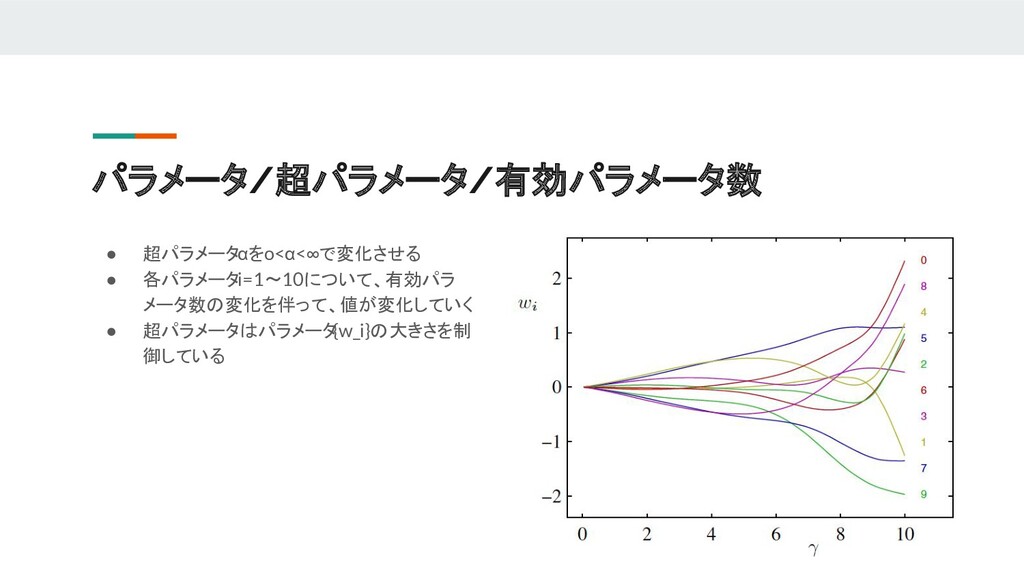{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}