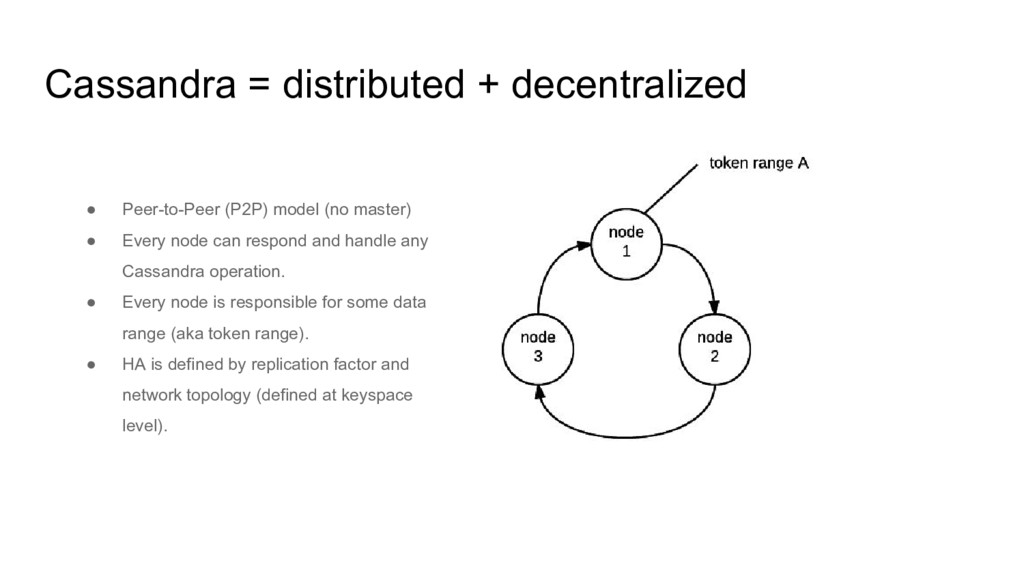
master) • Every node can respond and handle any Cassandra operation. • Every node is responsible for some data range (aka token range). • HA is defined by replication factor and network topology (defined at keyspace level).
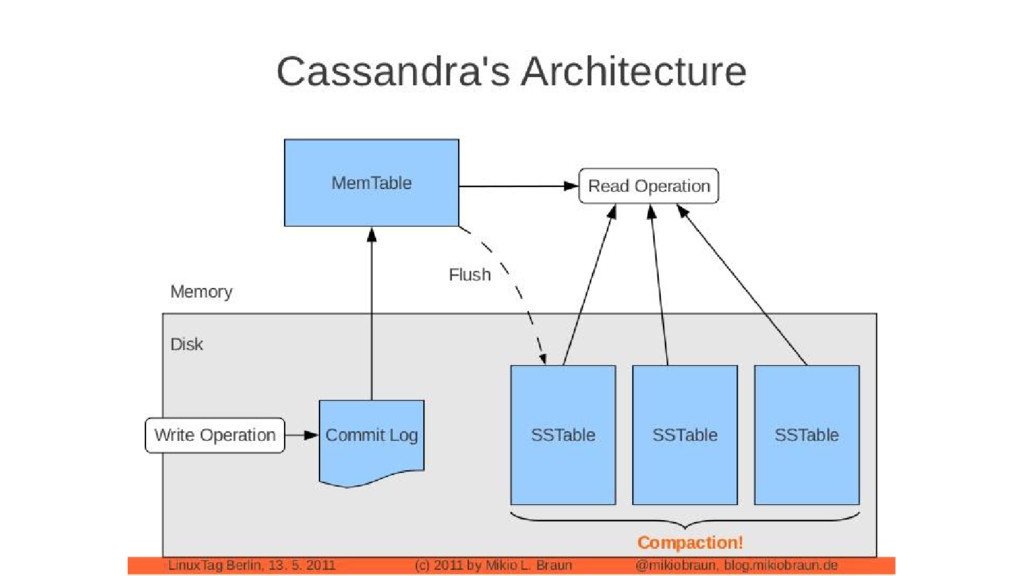
log file and must succeed before moving. Memtable In-memory row data of a column family (there is at most one memtable for each CF). SSTable Made up of several physical files on disk (index, data, filter, etc). Immutable once created.
Consistency = “level of comfort of my data integrity and safety” • Replication factor = total number of replica nodes (RF=3 means 3 nodes will have the same data written) • Some common consistency choice: ◦ LOCAL_QUORUM (majority of replicas within same data center must respond OK) ◦ QUORUM (majority or replicas must respond OK regardless of DC configuration) ◦ LOCAL_ONE (at least one node within same data center must respond OK) ◦ ALL (every replica node must respond OK)
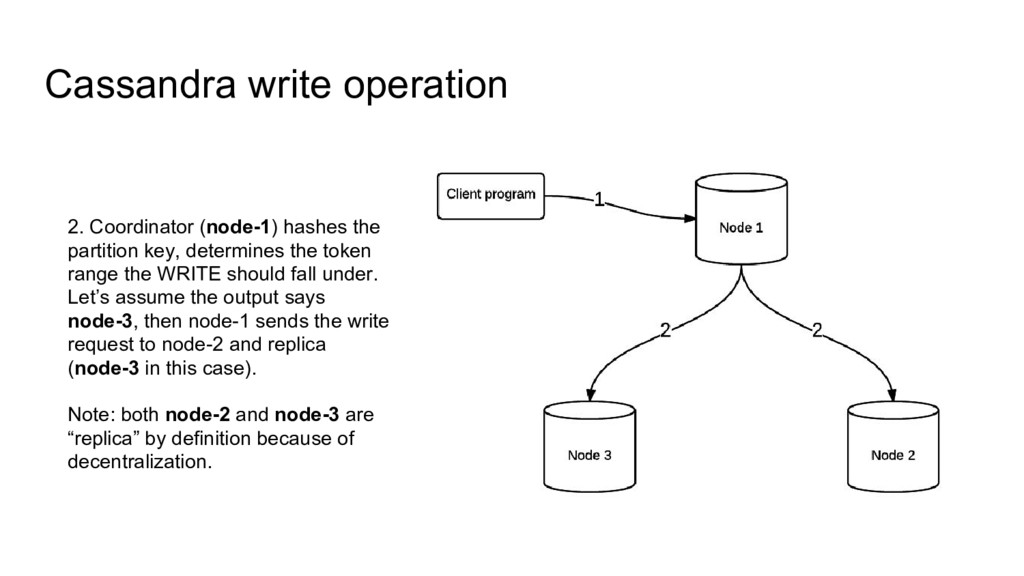
determines the token range the WRITE should fall under. Let’s assume the output says node-3, then node-1 sends the write request to node-2 and replica (node-3 in this case). Note: both node-2 and node-3 are “replica” by definition because of decentralization.
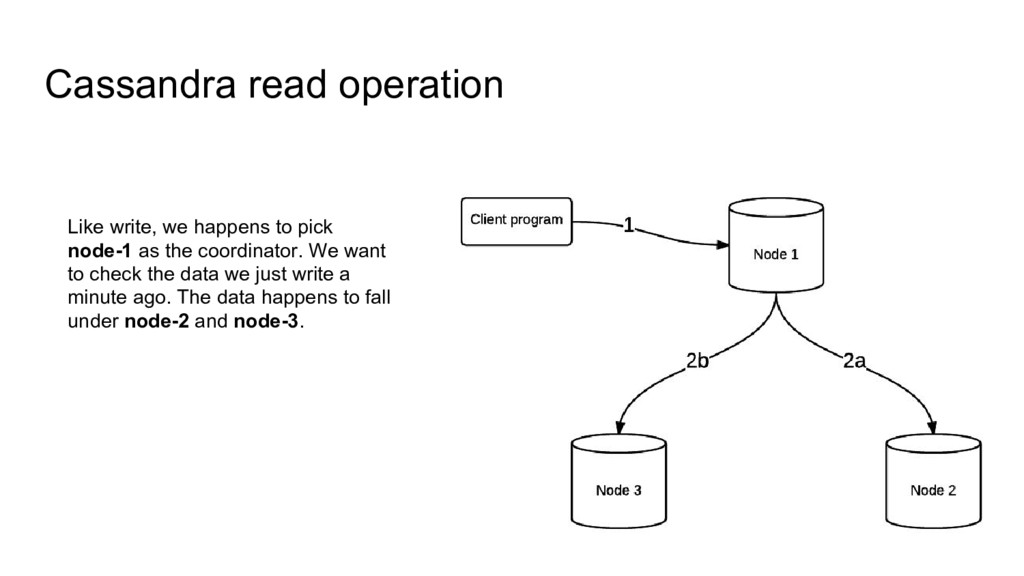
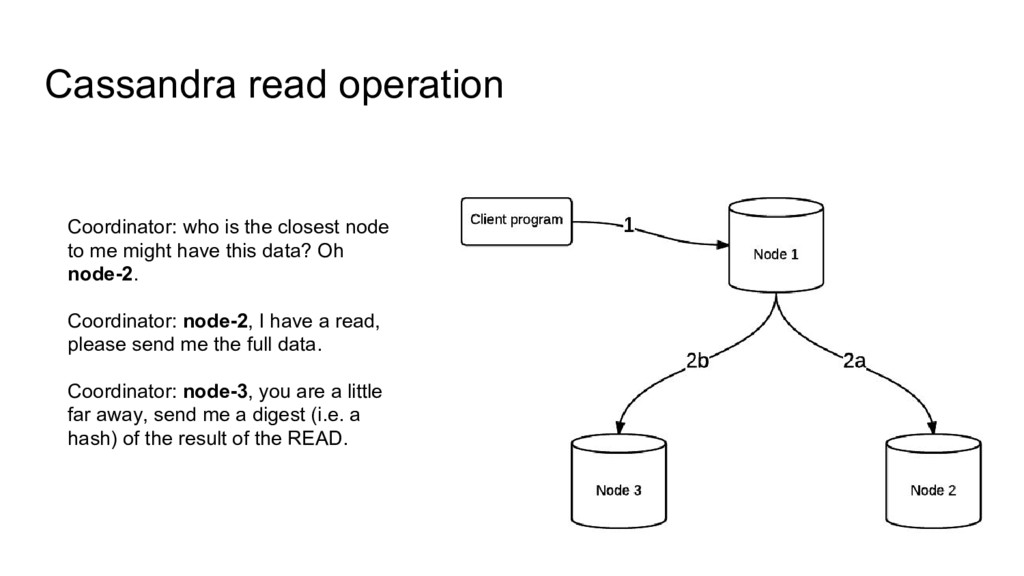
me might have this data? Oh node-2. Coordinator: node-2, I have a read, please send me the full data. Coordinator: node-3, you are a little far away, send me a digest (i.e. a hash) of the result of the READ.
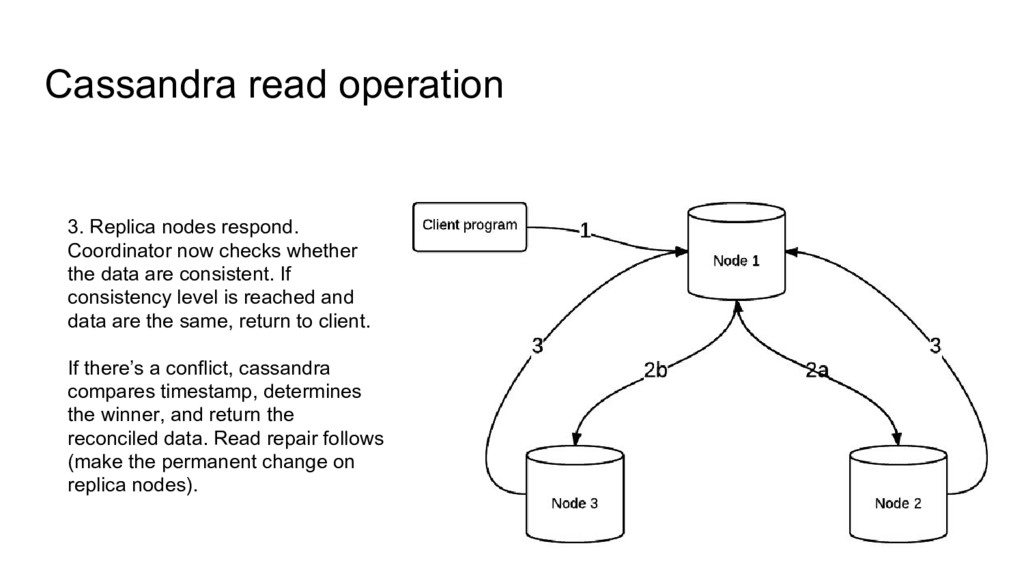
whether the data are consistent. If consistency level is reached and data are the same, return to client. If there’s a conflict, cassandra compares timestamp, determines the winner, and return the reconciled data. Read repair follows (make the permanent change on replica nodes).
is corresponds to one column family. Perhaps the threshold is 100MB, and when we are near that number, Cassandra will flush that particular Memtable to disk and create a bundle called SSTable. ubuntu@ip-10-0-1-137:/mnt/raid/data/adv2_ci_data/airplay_1$ ls adv2_ci_data-airplay_1-ic-1-CompressionInfo.db adv2_ci_data-airplay_1-ic-1-Data.db adv2_ci_data-airplay_1-ic-1-Filter.db adv2_ci_data-airplay_1-ic-1-Index.db adv2_ci_data-airplay_1-ic-1-Statistics.db adv2_ci_data-airplay_1-ic-1-Summary.db adv2_ci_data-airplay_1-ic-1-TOC.txt
(host-ip is required - this is the value set for ‘rpc_address’ in cassandra.yaml). Create keyspace CREATE KEYSPACE devops_mentorship_keyspace WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 };
keyspace and column families. DESC KEYSPACES List all keyspaces available. DESC COLUMNFAMILY <keyspace-name>.<cf-name> Describe the schema of a particular column family. You can skip <keyspace-name> if you have already ran USE <keyspace-name> command. DESC COLUMNFAMILIES List all CF available.
Cassandra != SQL database, so for example you can’t do WHERE clause on ANY column at will. You must make more secondary index (or reverted index) if you want to do some comparison / WHERE clause outside of the primary key.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}