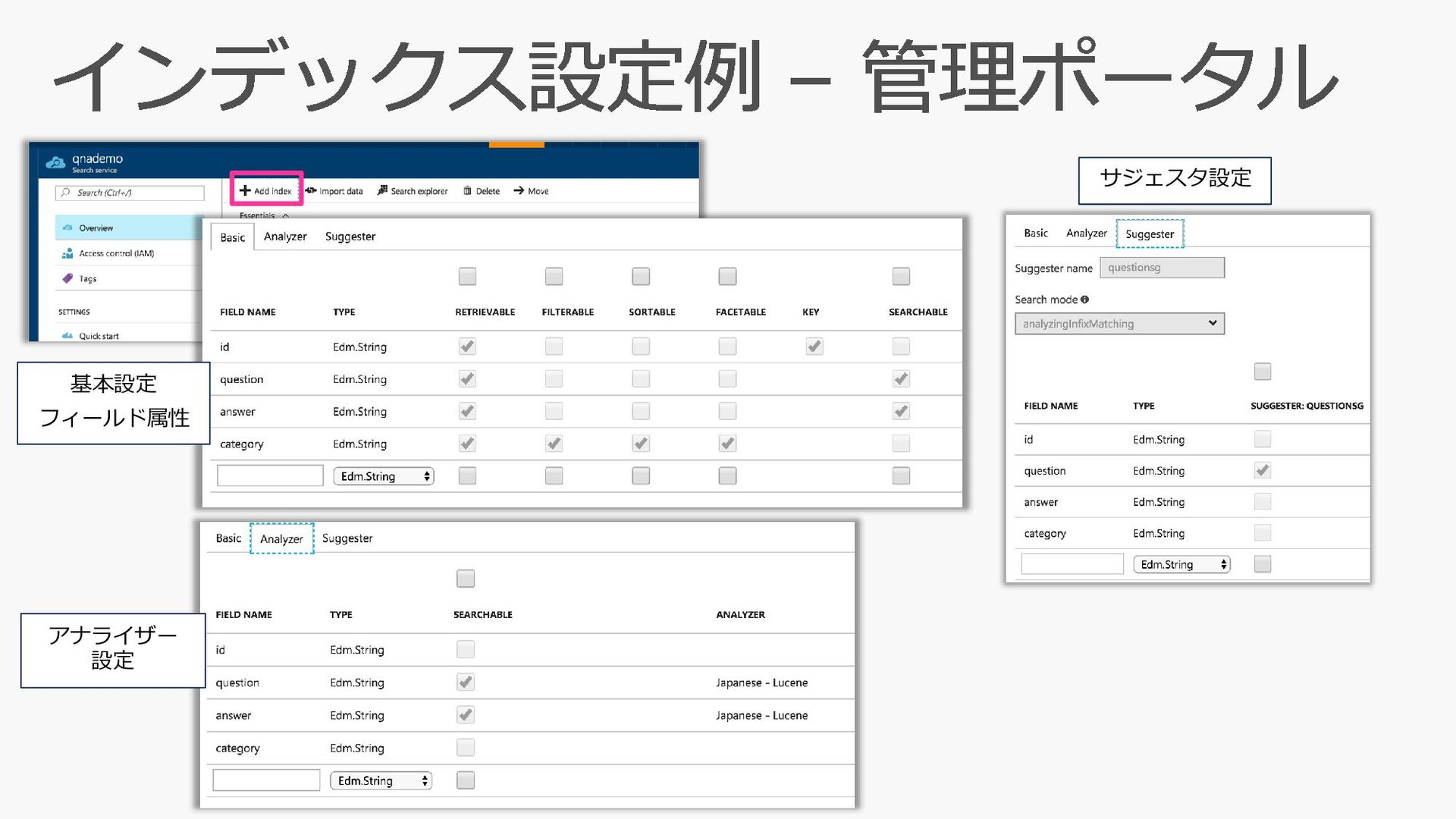
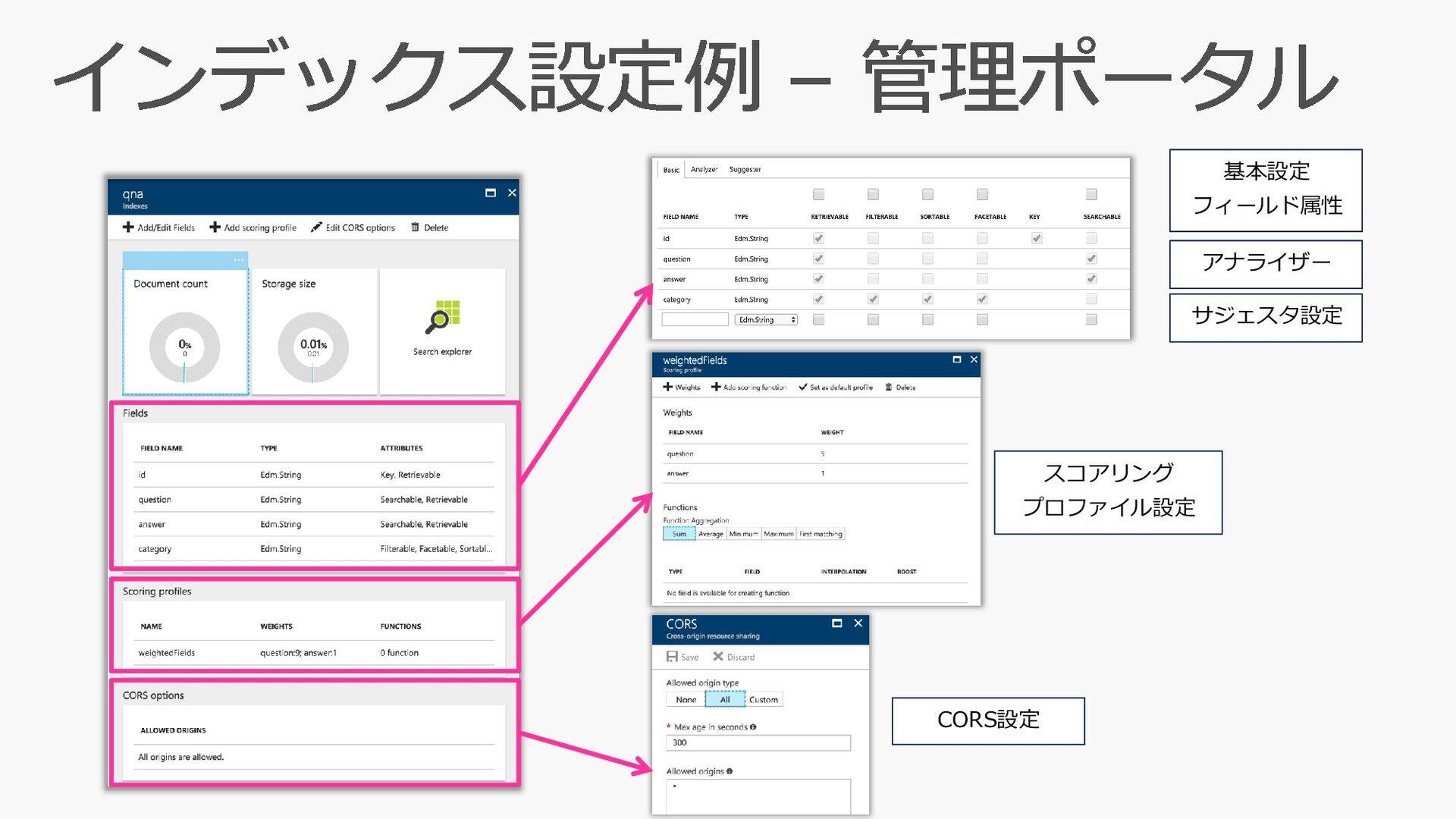
"qna", "fields": [ { "name":"id", "type":"Edm.String", "key":true, "retrievable":true, "searchable":false, "filterable":false, "sortable":false, "facetable":false }, { "name":"question", "type":"Edm.String", "retrievable":true, "searchable":true, "filterable":false, "sortable":false, "facetable":false,"analyzer":"ja.lucene"}, { "name":"answer", "type":"Edm.String", "retrievable":true, "searchable":true, "filterable":false, "sortable":false, "facetable":false,"analyzer":"ja.lucene"}, { "name":"category", "type":"Edm.String", "retrievable":true, "searchable":false, "filterable":true, "sortable":true, "facetable":true } ], "suggesters": [ { "name":"questionsg", "searchMode":"analyzingInfixMatching", "sourceFields":["question"] } ], "scoringProfiles": [ { "name": "weightedFields", "text": { "weights": { "question": 9, "answer": 1 } } } ], "corsOptions": { "allowedOrigins": ["*"], "maxAgeInSeconds": 300 } } 基本設定 フィールド属性 アナライザー サジェスタ設定 CORS設定 スコアリング プロファイル設定
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
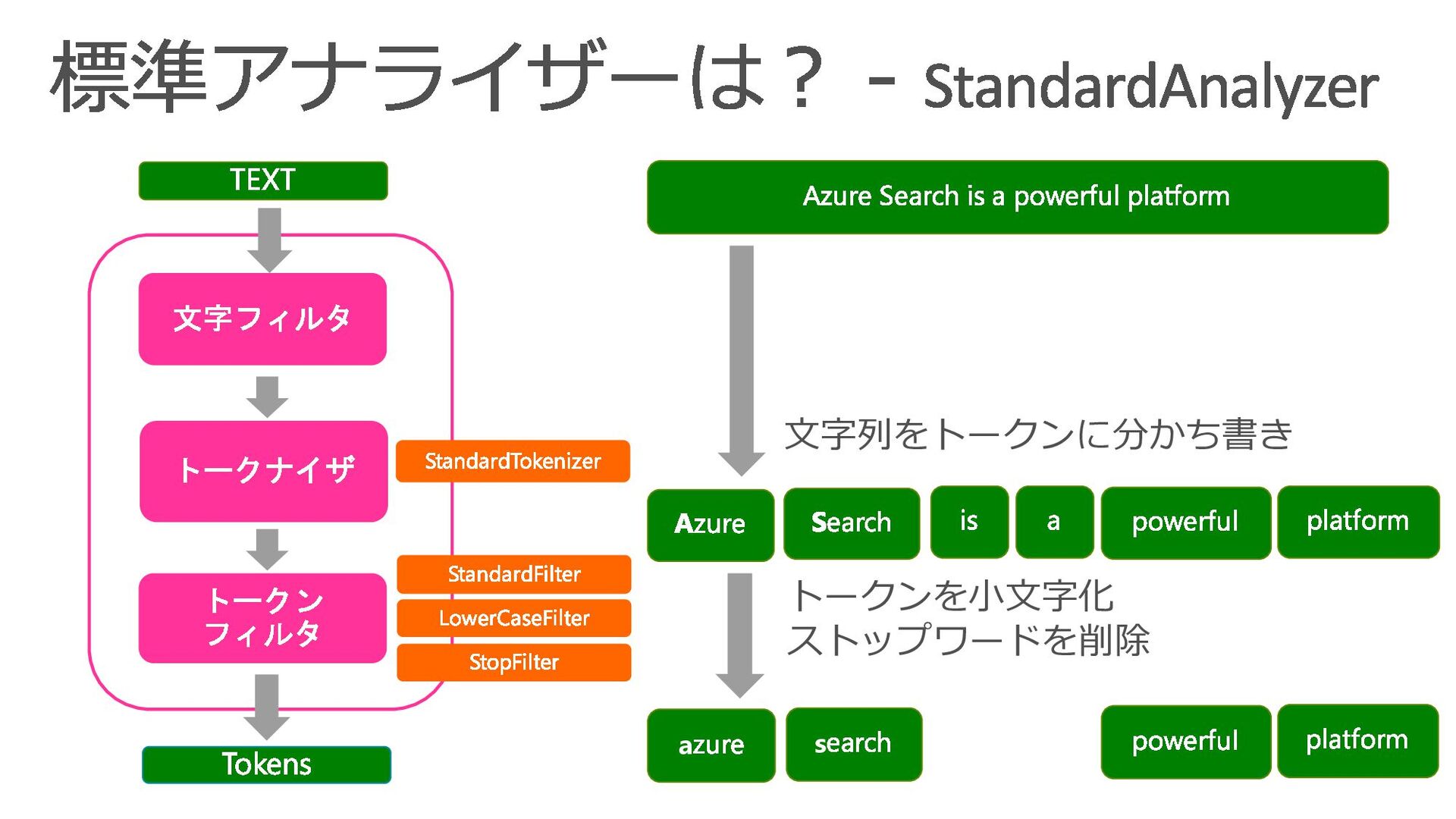{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
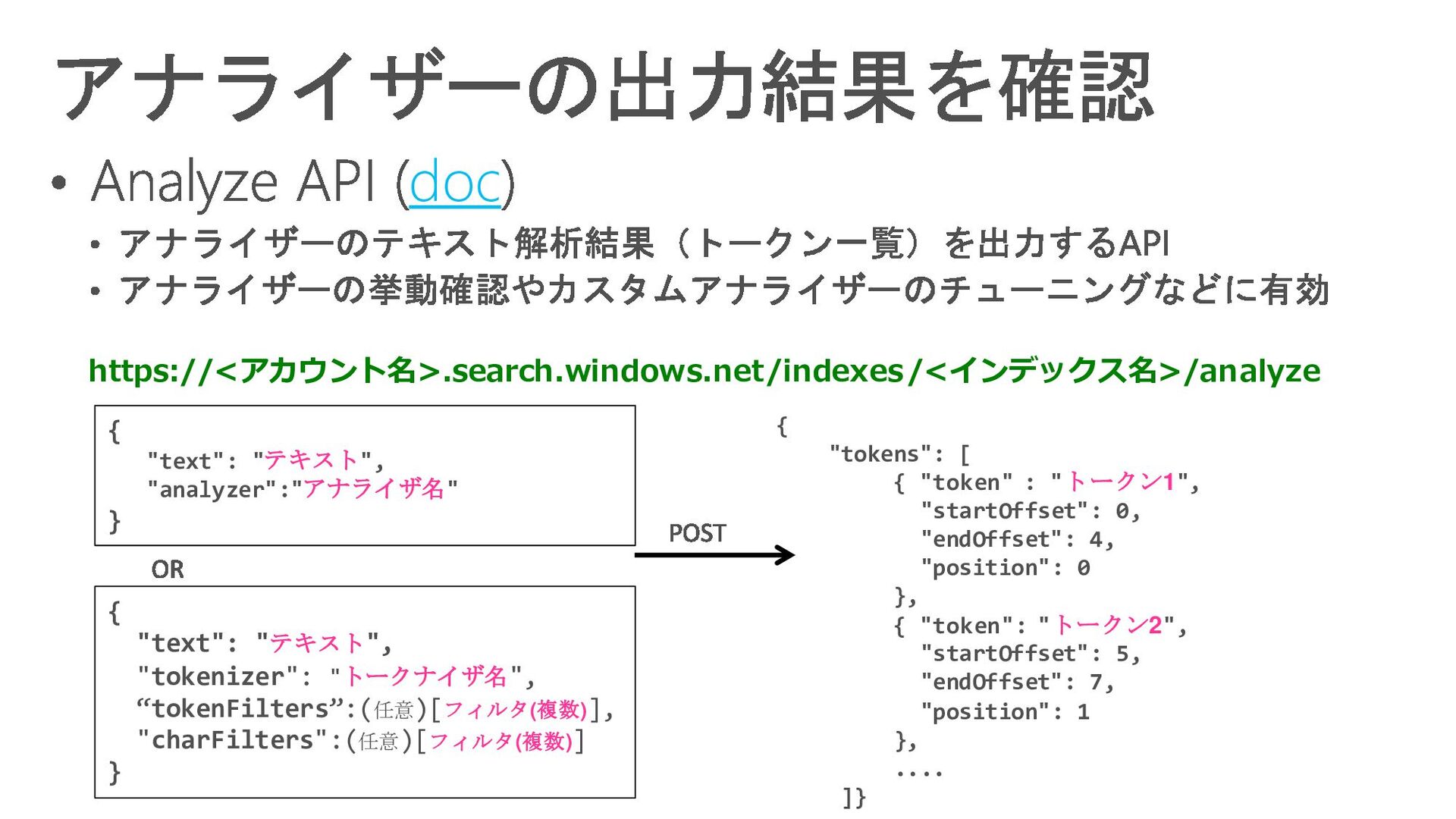{kind=link}
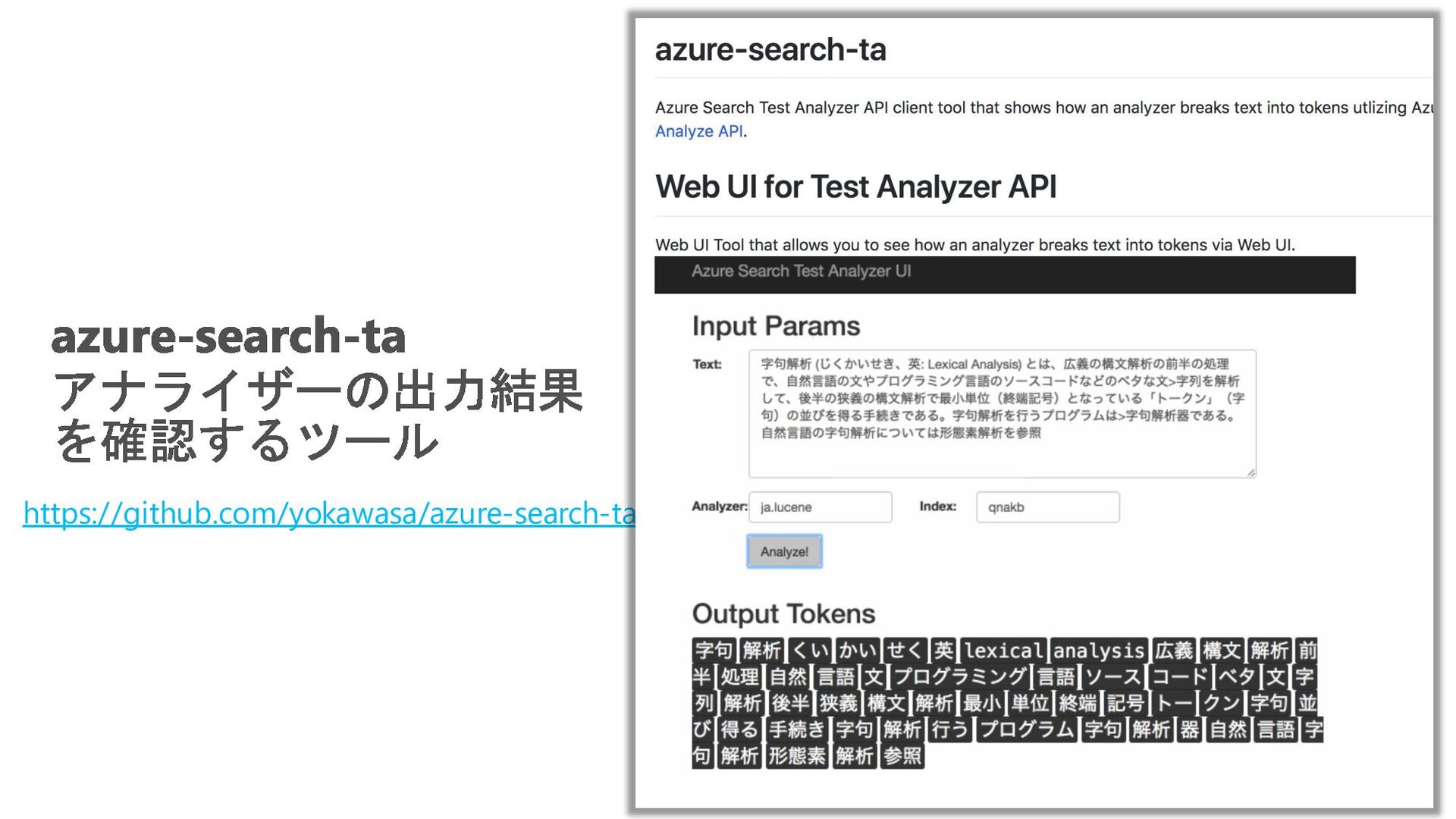{kind=link}
{kind=link}
{kind=link}
{kind=link}
!["analyzers":(optional)[ { "name":"analyzer_name_1", "@odata.type":"#Microsoft.Azure.Search.CustomAnalyzer", "charFilters":[ "char_filter_name_1", "char_filter_name_2" ], "tokenizer":"tokenizer_name", "tokenFilters":[](https://files.speakerdeck.com/presentations/3010627c6e5843de9922368c6479fd60/slide_36.jpg){kind=link}
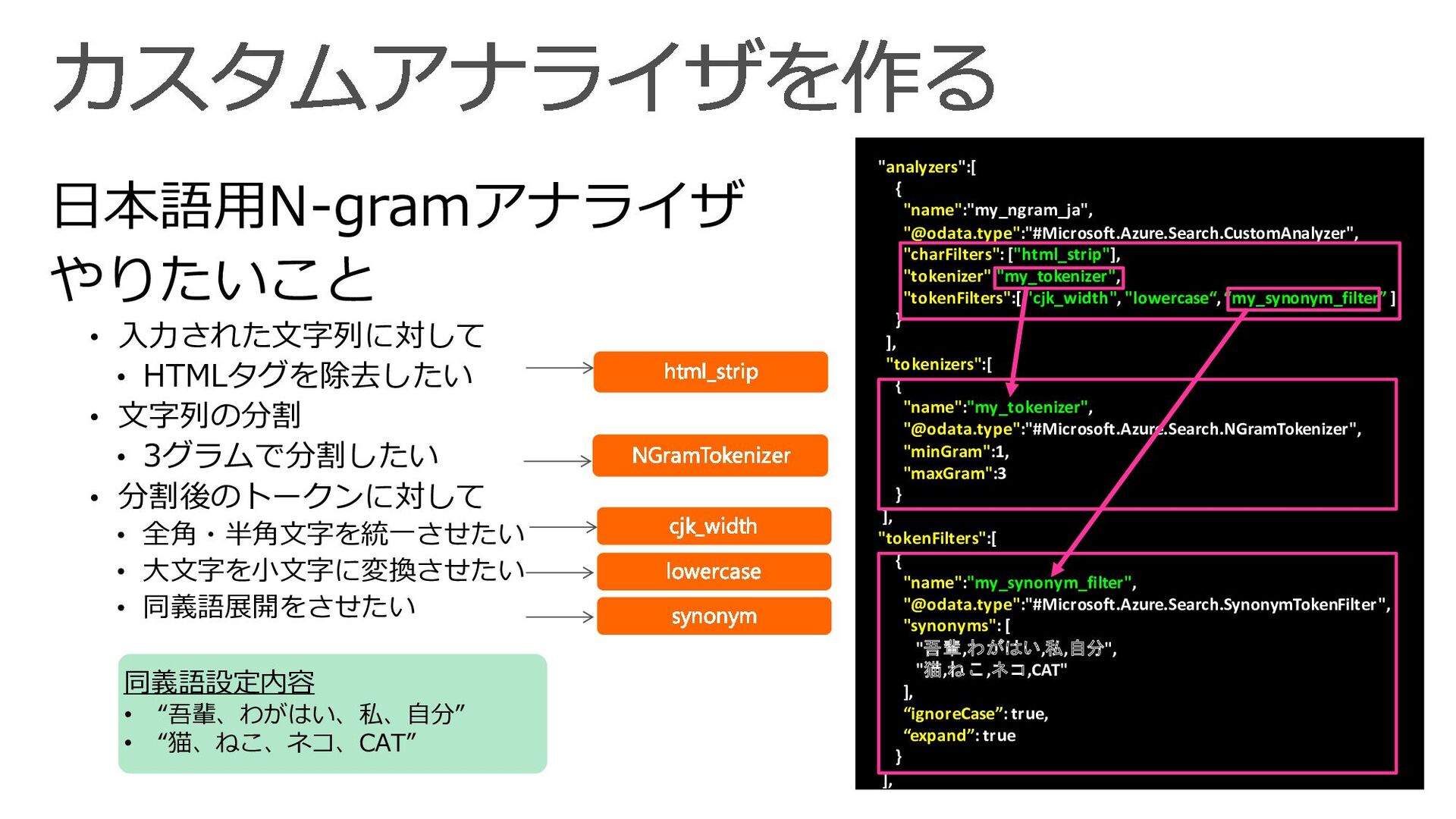{kind=link}
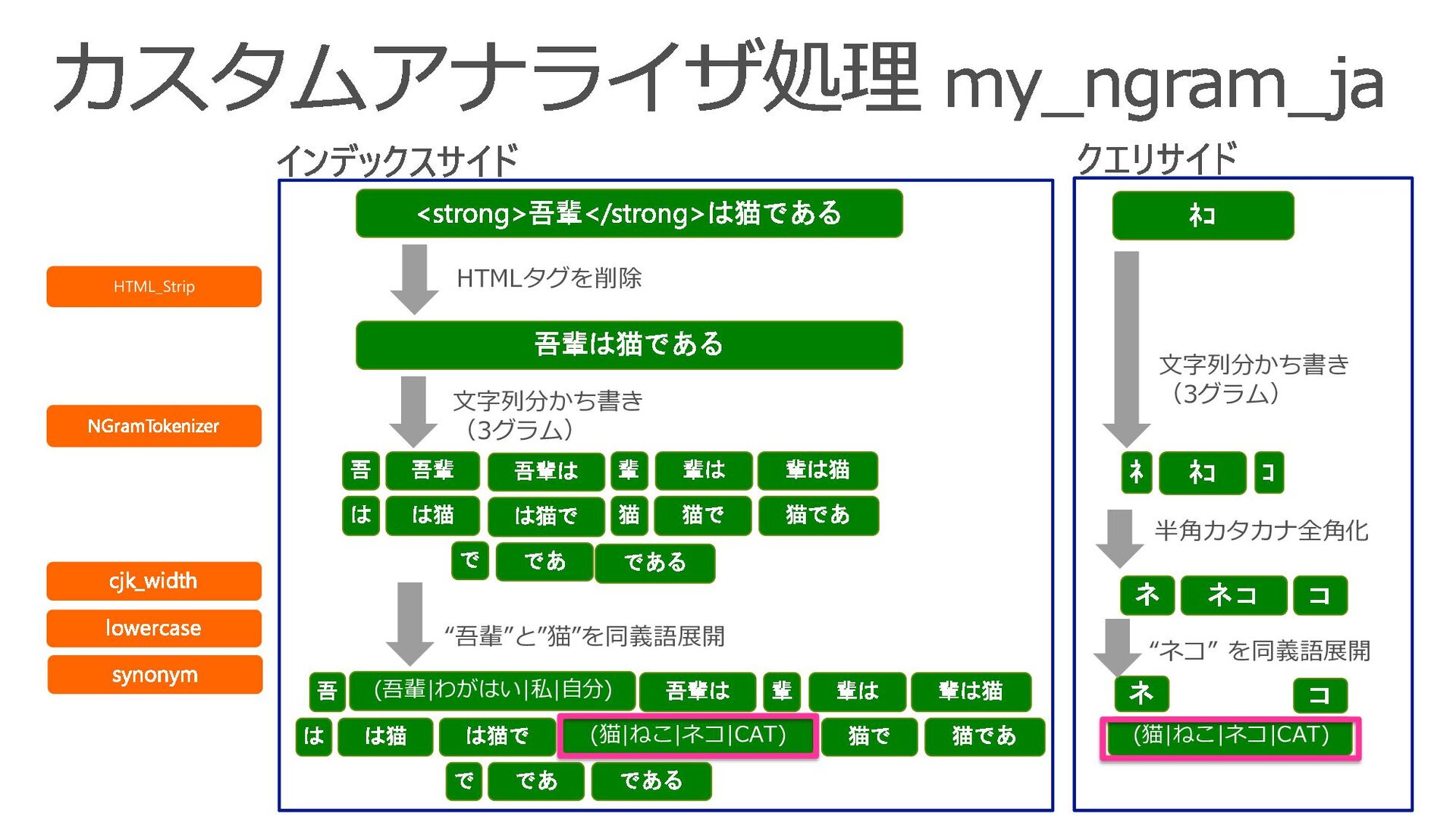{kind=link}
{kind=link}
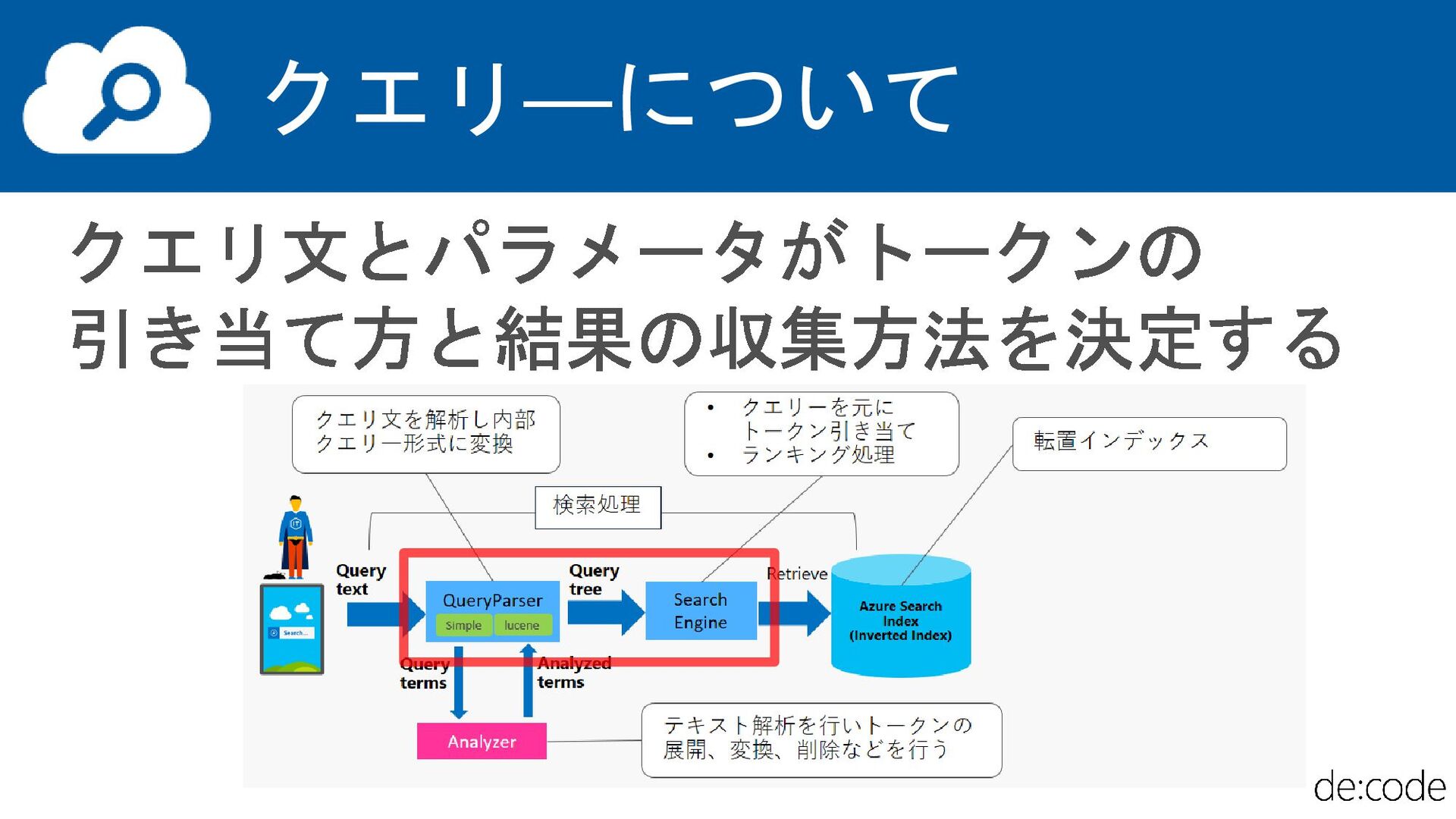{kind=link}
{kind=link}
{kind=link}
{kind=link}
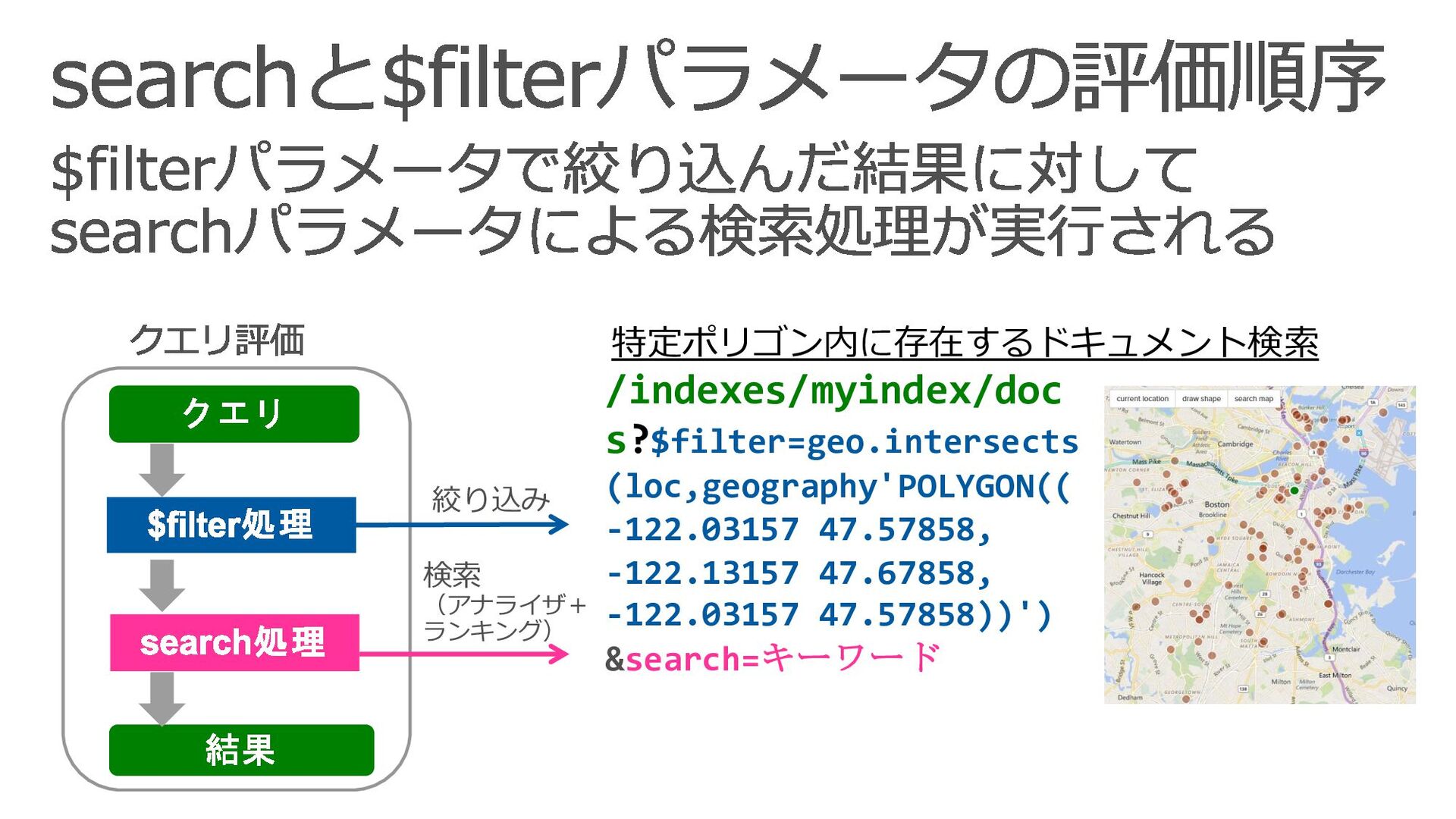{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
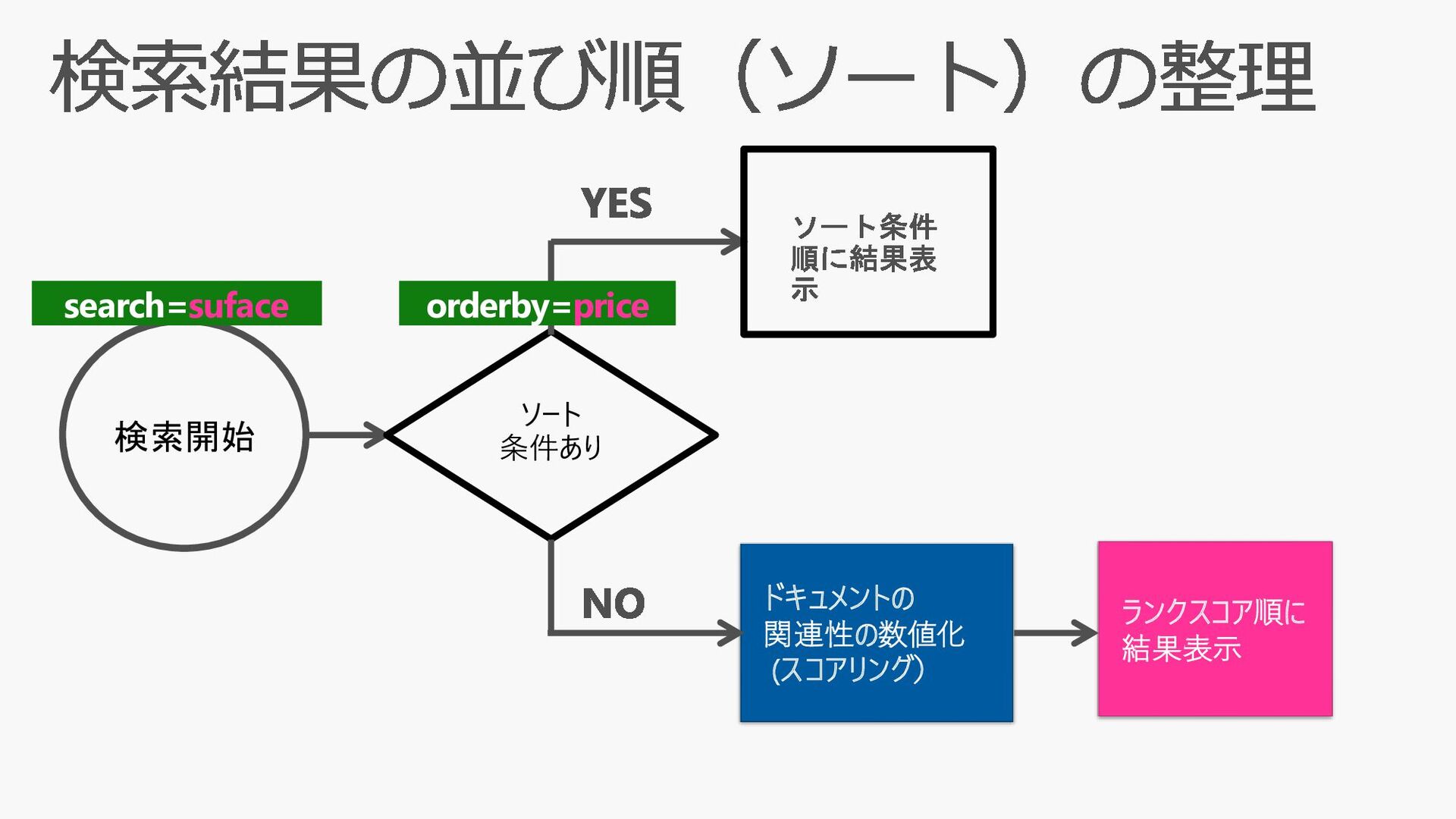{kind=link}
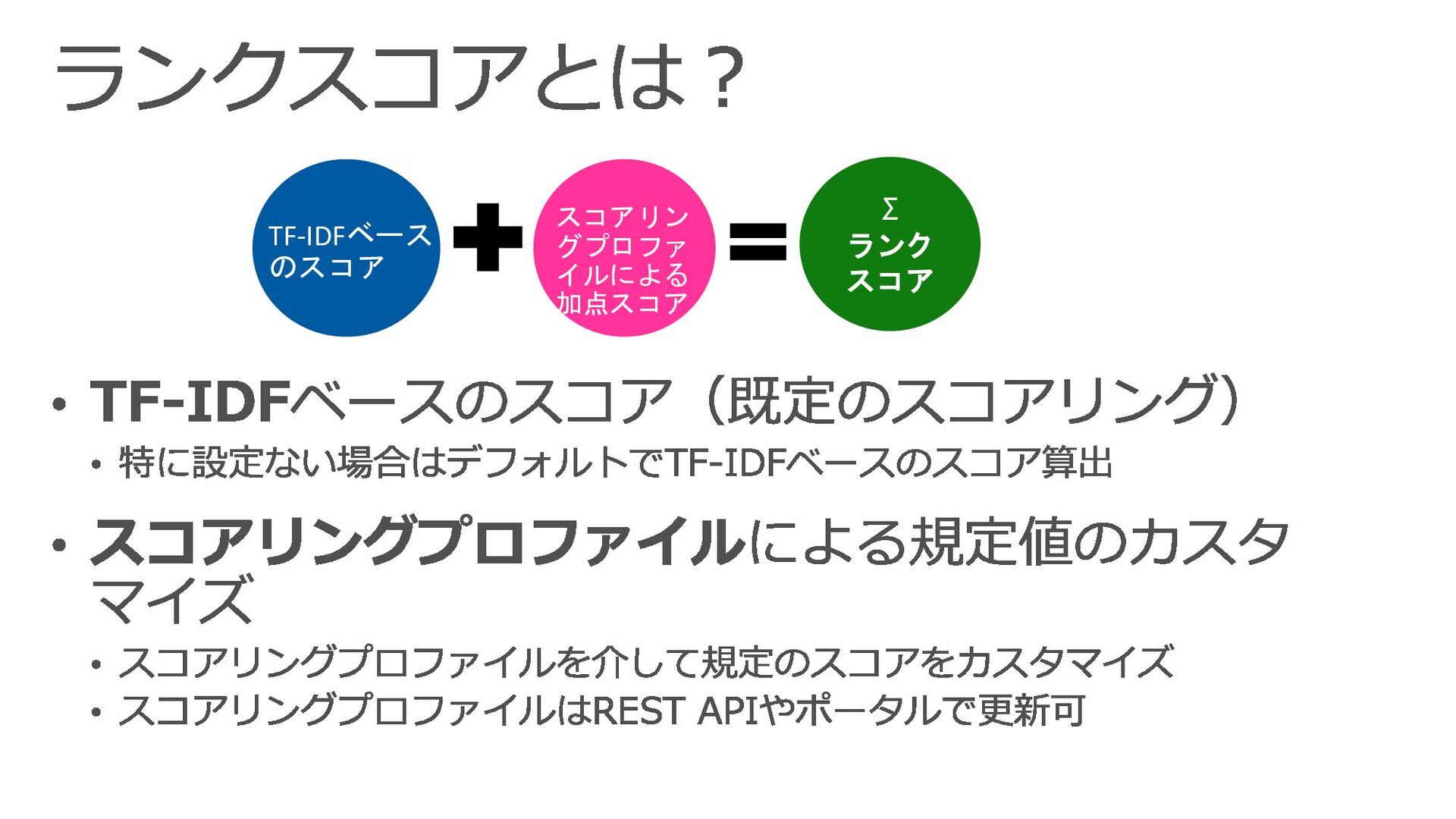{kind=link}
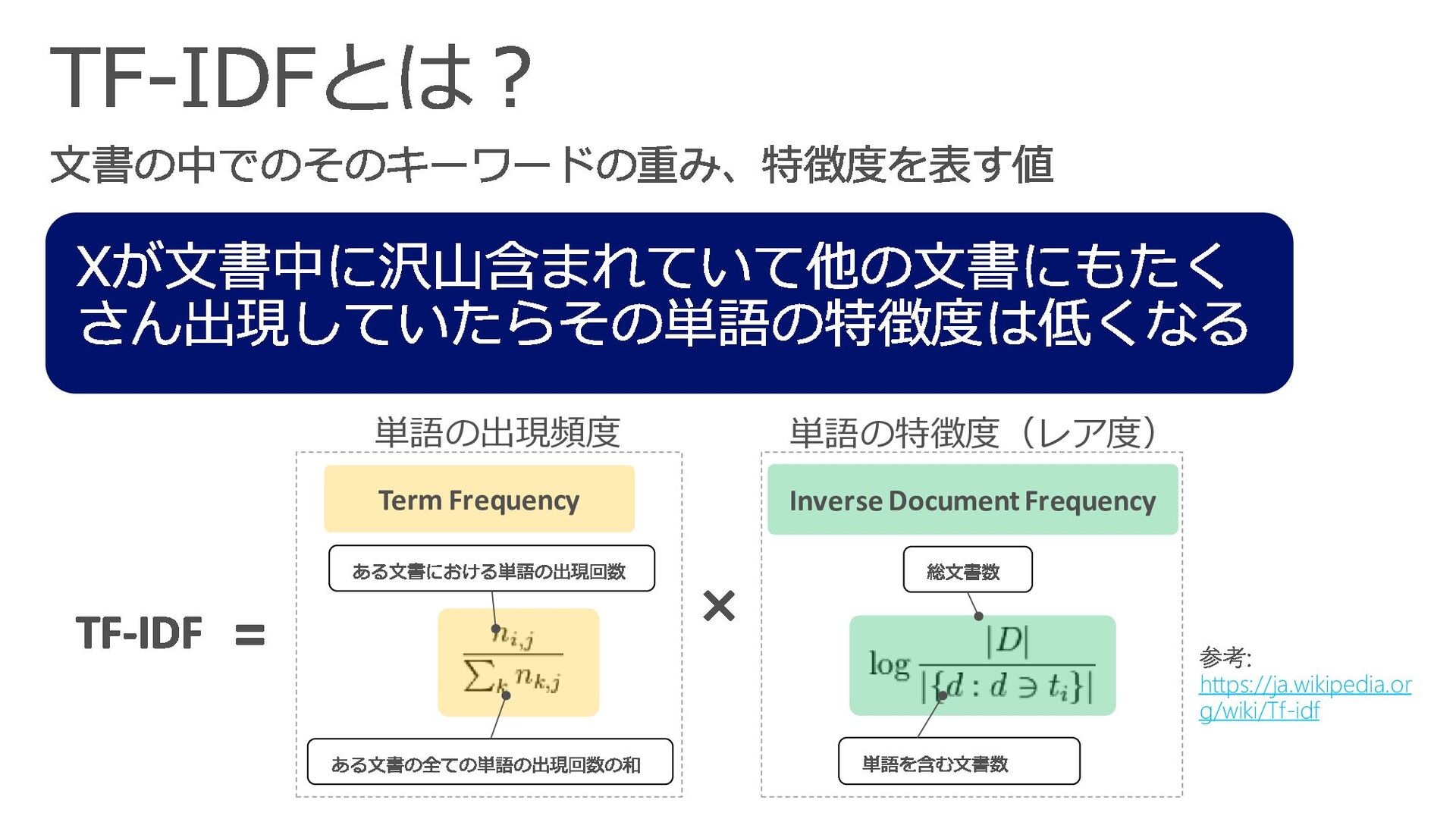{kind=link}
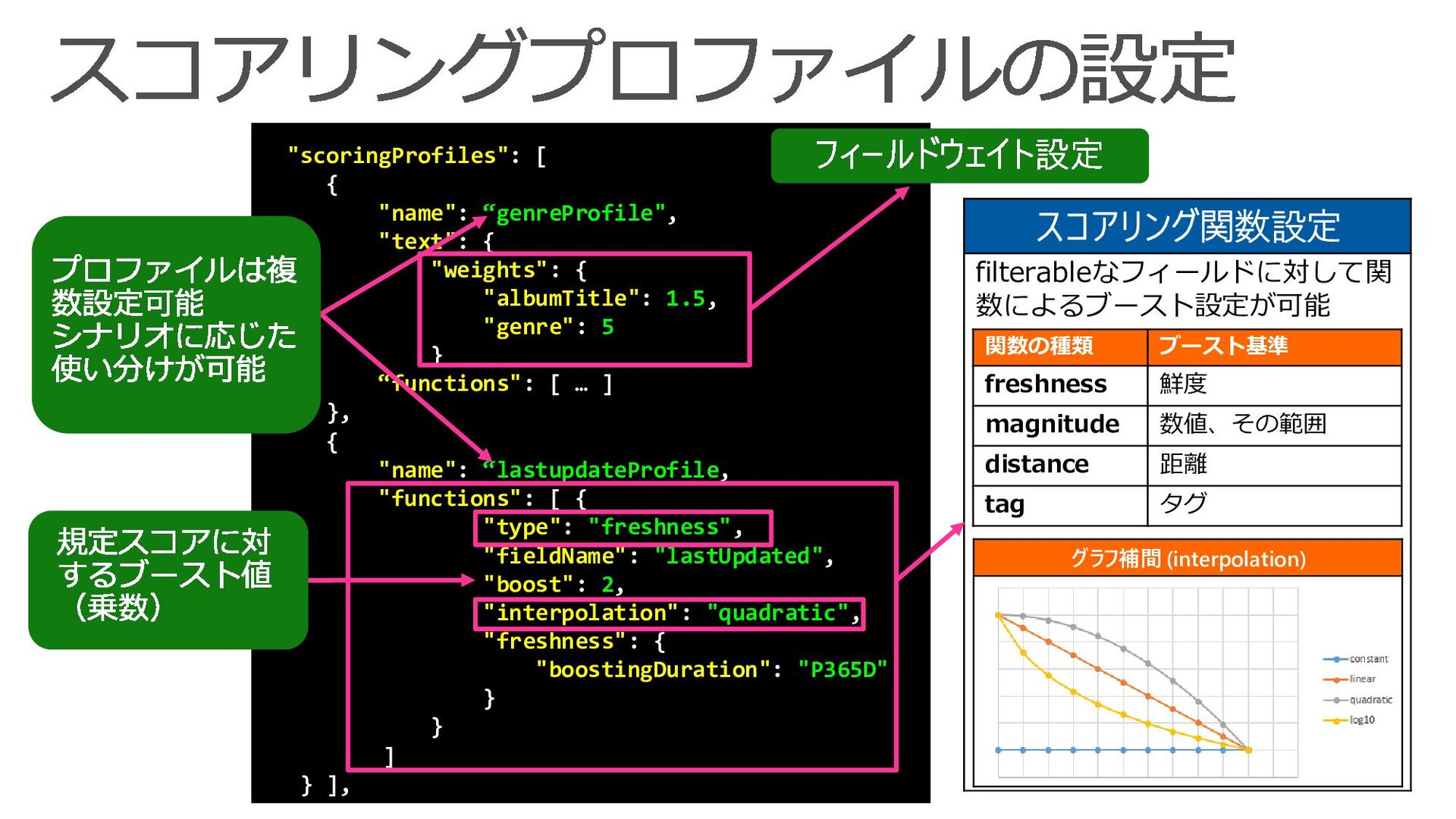{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}