Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
これからの教科学習 - Gunosy データマイニング研究会 #117
Search
Yosuke Abe
April 04, 2017
Technology
4.6k
0
Share
これからの教科学習 - Gunosy データマイニング研究会 #117
Yosuke Abe
April 04, 2017
Other Decks in Technology
See All in Technology
みんなの考えた最強のデータ基盤アーキテクチャ'26前期〜前夜祭〜ルーキーズ_資料_遠藤な
endonanana
0
170
ESP32 IoTを動かしながらメモリ使用量を観測してみた話
zozotech
PRO
0
100
ボトムアップ限界を越える - 20チームを束る "Drive Map" / Beyond Bottom-Up: A 'Drive Map' for 20 Teams
kaonavi
0
170
会社説明資料|株式会社ギークプラス ソフトウェア事業部
geekplus_tech
0
210
Building a Study Buddy AI Agent from Scratch: From Passive Chatbots to Autonomous Systems
itchimonji
0
150
アプリブロック機能のつくりかたと、AIとHTMLの不合理な相性の良さについて
kumamotone
1
230
もっとコンテンツをよく構造化して理解したいので、LLM 時代こそ Taxonomy の設計品質に目を向けたい〜!
morinota
0
230
Digital Independence: Why, When and How
wannesrams
0
310
The 7 pitfalls of AI
ufried
0
200
「背中を見て育て」からの卒業 〜専門技術としてのテスト設計を軸に、品質保証のバトンを繋ぐ〜 #genda_tech_talk
nihonbuson
PRO
1
970
色を視る
yuzneri
0
330
2026年春のAgentCoreアプデ 細かいやつ全部まとめ
minorun365
3
210
Featured
See All Featured
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.4k
A Modern Web Designer's Workflow
chriscoyier
698
190k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
54k
Music & Morning Musume
bryan
47
7.2k
Automating Front-end Workflow
addyosmani
1370
200k
Faster Mobile Websites
deanohume
310
31k
Optimising Largest Contentful Paint
csswizardry
37
3.7k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
New Earth Scene 8
popppiees
3
2.2k
WENDY [Excerpt]
tessaabrams
10
37k
A designer walks into a library…
pauljervisheath
211
24k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Transcript
Gunosyデータマイニング研究会 #117
阿部陽介 大学時代の専門は物理(博士) ニュートリノ混合角θ 13 の精密測定 2015.4 大手ネット企業 2016.8 Gunosyデータ分析部 ニュースパスのロジックと分析担当
自己紹介 「データ分析ブログ」で検索!
これからの強化学習 目的:強化学習の現在の研究を俯瞰すること。 これから研究を始める大学院生や研究者向け 第1章 強化学習の基礎的理論 第2章 強化学習の発展的理論 第3章 強化学習の工学応用 第4章 知能モデルとしての強化学習
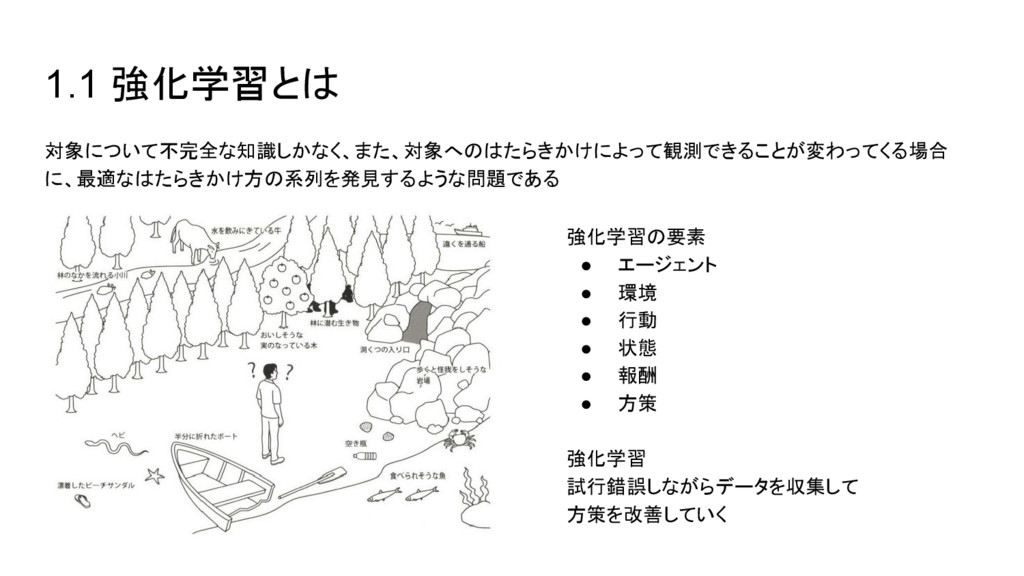
1.1 強化学習とは 対象について不完全な知識しかなく、また、対象へのはたらきかけによって観測できることが変わってくる場合 に、最適なはたらきかけ方の系列を発見するような問題である 強化学習の要素 • エージェント • 環境 •
行動 • 状態 • 報酬 • 方策 強化学習 試行錯誤しながらデータを収集して 方策を改善していく
p.5 探索と利用のトレードオフ 不完全な知識の上で、知識を収集しながら最適な行動を計画するにはどうする? 利用: これまで試した中で一番いい方策を選ぶこと 探索: さらにいい方策がないか試すこと 利用ばかりしていると、探索できずに機会損失となる 探索を増やすとこれまで学習した最良の行動と異なる行動が増え、報酬が減る これを探索と利用のトレードオフという
1.1.2 多腕バンディット問題 腕がK本あるスロットマシン(多腕ってなんだ・・・?) 払い戻される額をR 腕i(kではなく?)を引いたときに、あたりが出る確率をp k とする どうすれば収益を最大化できるか いくつかアルゴリズムがある
1.1.3 greedy アルゴリズム (貪欲法) まず各腕をn回ずつ引く。その後平均報酬の高い腕を引き続ける 問題点 - 最適でない腕をn回ずつ引くので、nを大きくするとコストが大きい - 試行回数が少ない場合は誤って最適でない腕を選択する可能性が増える
誤り方には2種類ある(次ページ)
最適でない腕を選択してしまうパターン まだ良い 局所解への落ち込み 払戻率が悪い腕を引き続けてしまう
ε-greedy アルゴリズム まだ選んだことのない腕がある場合は、その腕から選ぶ 確率εでランダムな腕を選ぶ 確率1-εで平均報酬が最大の腕を選ぶ • 局所最適への落ち込みを避けることができる • 確率εでランダムの腕を選び続けるコスト •
εを減らしていくというアプローチもある(2.2)
1.1.5 不確かなときは楽観的に 楽観主義原理 局所解への落ち込みを避ける ある選択肢の期待値が真の値より小さく見積もられる場合は,間違いを修正することは 困難であるが,ある選択肢の期待値を真の値より大きく見積もった場合には,何度かその 選択肢を選ぶうちに間違いが修正されるのである そのため,期待値に不確実性があるときには,その不確実性の範囲のなかで,大きい期待 値を仮定すべき (楽観的に見積もるべき)
楽観的初期値法 μ' i が最大の腕を選ぶ r sup : 報酬の上界 K: 定数
あまり引いていない腕の結果がよく見えるように下駄をはかせる 最初は探索多め、時間ステップの経過とともに利用が多くなる
UCB1アルゴリズム すべての選択肢に対して必要な探索が行われることを保証しつつ、探索のコストも最適 解を間違えるリスクも少なくできることが証明されている μ i +U i が最大となる腕iを選ぶ
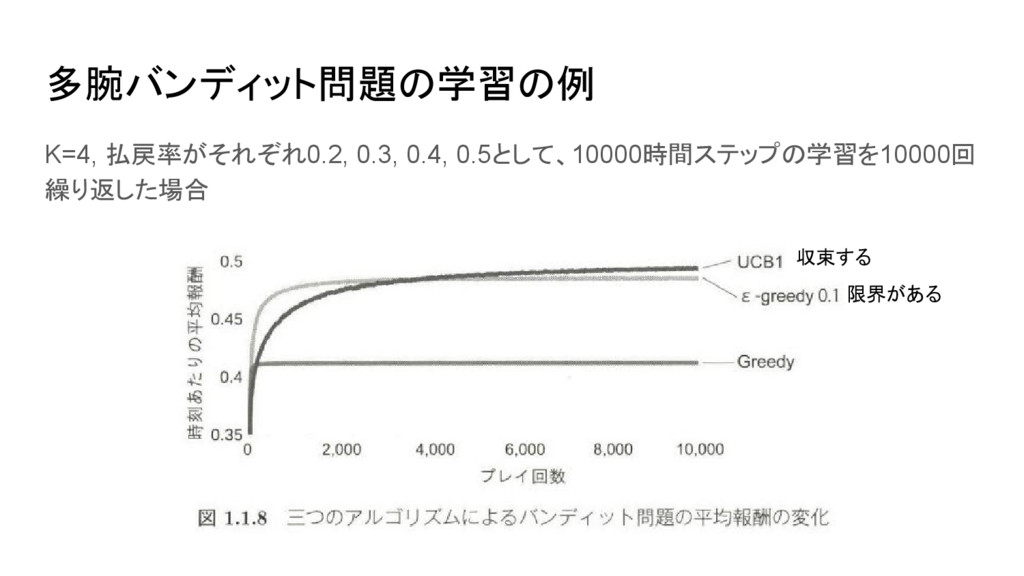
多腕バンディット問題の学習の例 K=4, 払戻率がそれぞれ0.2, 0.3, 0.4, 0.5として、10000時間ステップの学習を10000回 繰り返した場合 限界がある 収束する
多腕バンディット問題と一般の強化学習問題の違い 多腕バンディット問題 強化学習の特別な場合で、腕の選択という行動のみを考慮していて状態は考慮してい ない 一般の強化学習問題 状態は行動によって変化するため、時間的な経過を取り扱う必要がある。
1.2 強化学習の構成要素 強化学習の理論を組み立てていくために必要な概念について マルコフ決定過程: 強化学習の基本的な枠組みと相互作用を記述する数理モデル 収益、価値、方策の定式化
1.2.1 強化学習の基本的な枠組み エージェント: 行動決定の主体 環境: エージェントが相互作用を行う対象 相互作用: 情報の受け取りと引き渡しを行うこと 強化学習ではエージェントの内部構造を設計できるが環境は与えられたもの ただし、エージェントと環境はあいまい。
例: ロボット制御のアクチュエーターの指令値を行動とするのか、出力そのものを行動と するのか
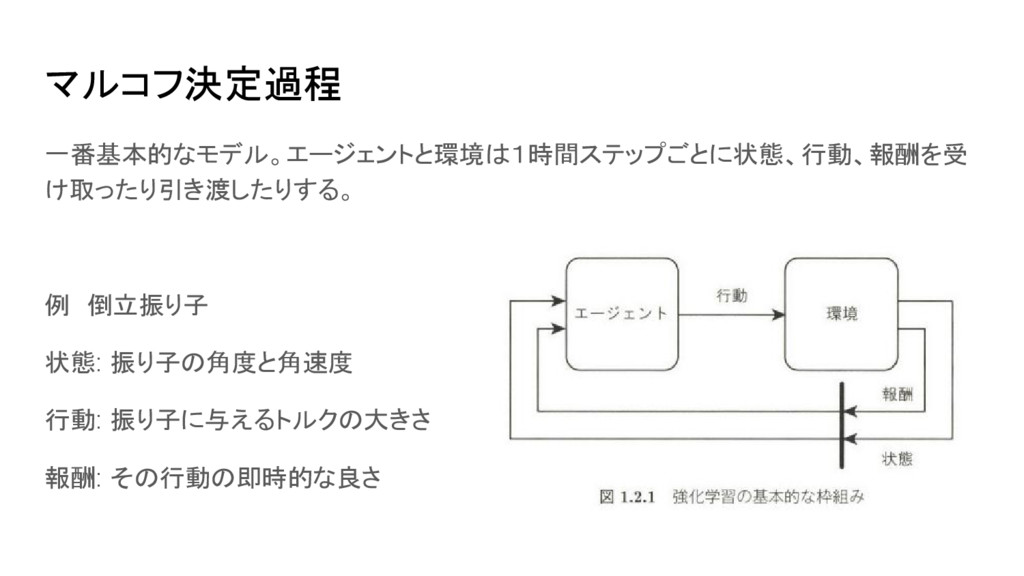
マルコフ決定過程 一番基本的なモデル。エージェントと環境は1時間ステップごとに状態、行動、報酬を受 け取ったり引き渡したりする。 例 倒立振り子 状態: 振り子の角度と角速度 行動: 振り子に与えるトルクの大きさ 報酬: その行動の即時的な良さ
方策 エージェントが行動を決定するためのルール 振り子の傾きに比例して反対にトルクをかけるみたいな。 できるだけ多くの報酬を受け取れるように方策を設計することが目的
1.2.2 マルコフ決定過程による時間発展の記述 以下の要素によって記述される確率過程 状態空間 S: すべての状態からなる集合 行動空間 A(s): ある状態sにおける選択可能なすべての行動 初期状態分布
P 0 状態遷移確率 P(s' | s, a): 状態sにおいて行動aを決定したとき、s'に遷移する確率 報酬関数 r(s, a, s'): 確率分布として定義することもあるが、ここでは一意に定まる関数 とする
マルコフ性の由来 どこがマルコフ? t+1時間ステップにおける状態S t+1 はtステップ目の状態S t とその状態で選ばれた行動を A t としたとき、
S t+1 ~ P(s' | S t , A t ) によって定まる。 S t+1 はS t-1 やA t-1 に依存せず、直前の状態のみにより決まる
エージェントの行動決定の定式 方策はπで表す 状態sで行動aが選択される確率 π(a | s) 行動選択確率
1.2.3 良い方策とは何か? A. 収益を最大化する方策が良い方策 収益は自由に定義できる。 例. ある期間を決めて報酬を足し合わせたもの 例. 割引報酬和 近い未来に価値を置く
(0 < γ < 1)
状態価値 収益は区間の開始時点での状態に依存して相互作用の内容が確率的に決定されるた め、収益も確率的に変動してしまう。 収益そのものは、このままでは行動指標として扱いづらい。 状態を条件として収益の期待値をとる。これが状態価値もしくは価値 これを使って良い方策を定義する。
例えば、T=1の有限区間収益のとき G t = R t+1 を考える。 t+1で状態がs'となる確率 これを使って、状態価値が以下のように表される 状態遷移確率
行動選択確率
良い方策とは何か?(再) 収益を最大化する方策 = 価値を最大化する方策 π*: 最適方策, V*(s): 最適状態価値観数 tのときの行動も条件とする場合 (A
t =a) 行動価値観数 最適行動価値観数
1.2.4 良い方策はどのように求めるか? greedy方策 ε-greedy方策 ボルツマン方策 Tは時間ではなくて、温度。T→0でgreedy方策、T→∞で一様にランダムな行動 (熱力学だとexpの中にマイナスがつく)
おわり 価値を推定できれば方策を求めることができる。 価値の推定の仕方は1.3から。 価値を使わない方策も求め方もあるらしい。これは1.4から。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}